



 本文深入探讨了Kubernetes的调度机制,包括kube-scheduler如何选择最优节点运行Pod,以及预选和打分策略的详细解释。同时介绍了自定义调度器的方法。
本文深入探讨了Kubernetes的调度机制,包括kube-scheduler如何选择最优节点运行Pod,以及预选和打分策略的详细解释。同时介绍了自定义调度器的方法。


作者 | 阿文,责编 | 郭芮
头图 | 优快云 下载自东方IC
出品 | 优快云(ID:优快云news)
自互联网出现以来 ,云计算的概念已经提出了有 50 年。从1957 年,John McCarthy 将计算机中的分时共享概念设计成了一种工具。从此以后,这个概念的名字经历过数次变化:从“服务中心(service bureau)”到应用服务提供商,到互联网即服务,到云计算,再到软件定义的数据中心。
一直以来基础设施是云计算的基础核心,基础设施服务(Infrastructure as a Service,IaaS)将IT基础设施资源(计算、网络与存储)以一种弹性的服务方式对外提供。近十余年来随着云计算不断发展与落地,云基础设施技术架构也在不断往前演进,从传统虚拟化、基础设施资源管理走向软件定义架构。随着近5年来以容器和微服务为代表的云原生技术兴起,云基础设施架构需要演进以全面拥抱云原生技术。
以容器、容器编排、微服务、服务网格为代表的云原生技术正在日益体现出期在云计算领域的非凡价值,众所周知,容器编排中 Kubernetes 已经成为容器编排领域的事实标准。
kubernetes 可以提供所需的编排和管理功能,以便针对工作负载大规模部署容器。借助 Kubernetes 编排功能,可以快速的构建跨多个容器的应用服务、跨集群调度、扩展这些容器,并长期持续管理这些容器的健康状况。在 Kubernetes 中,调度 是指将 Pod 放置到合适的 Node上,然后对应 Node 上的 Kubelet才能够运行这些 pod。
那么kubernetes 是如何进行调度的呢?我们来一起看下。

Kubernetes 是如何调度的?
kube-scheduler 是 Kubernetes 集群的默认调度器,并且是集群 控制面的一部分。同时 kube-scheduler 在设计上是允许你自己写一个调度组件并替换原有的 kube-scheduler。
对每一个新创建的 Pod 或者是未被调度的 Pod,kube-scheduler 会选择一个最优的 Node 去运行这个 Pod。那么kube-scheduler 是如何选择最优的 Node 呢?
kube-scheduler监听apiserver的/api/pod/,当发现集群中有未得到调度的pod(即PodSpec.NodeName为空)时,会查询集群各node的信息,经过Predicates(过滤)、Priorities(优选器),得到最适合该pod运行的node后,再向apiserver发送请求,将该容器绑定到选中的node上。
Kubernetes Scheduler 提供的调度流程分三步:
过滤, 遍历nodelist,选择出符合要求的候选节点,Kubernetes内置了多种预选规则供用户选择。
打分, 在选择出符合要求的候选节点中,采用优选规则计算出每个节点的积分,最后选择得分最高的。
绑定, 选出其中得分最高的 Node 来运行 Pod。之后,调度器将这个调度决定通知给 kube-apiserver,这个过程叫做绑定。
整个过程,如图所示:
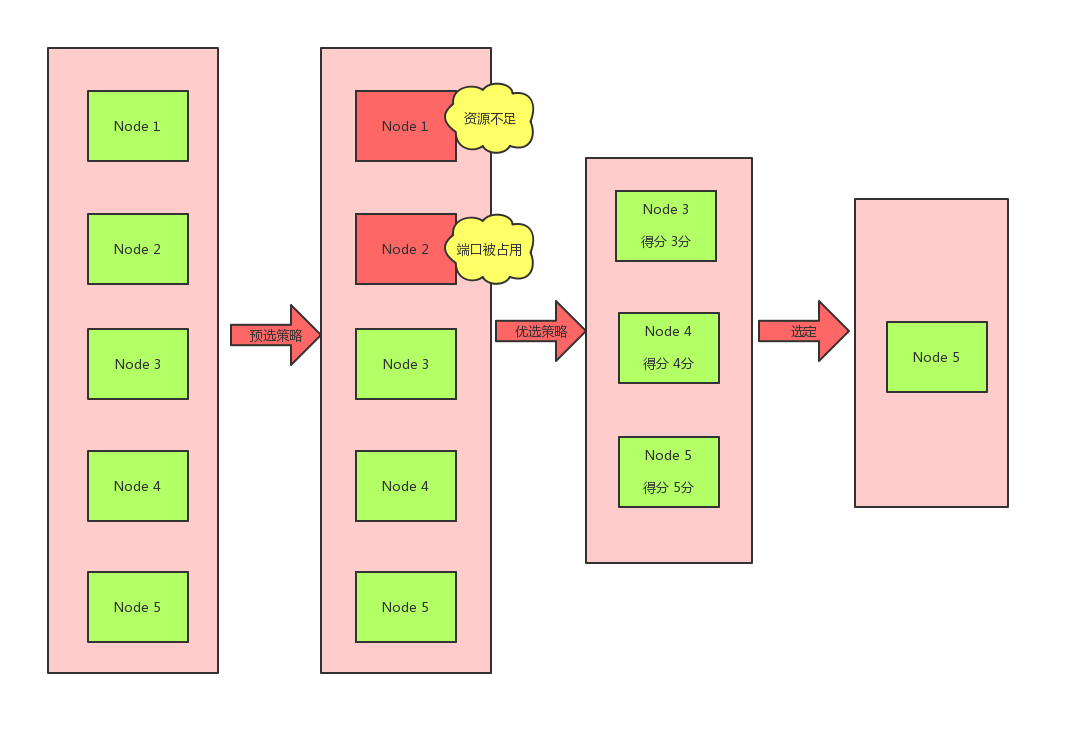
预选的算法可以参考源码predicates.go(https://github.com/kubernetes/kubernetes/blob/master/pkg/scheduler/algorithm/predicates/predicates.go):
const (
// MatchInterPodAffinityPred defines the name of predicate MatchInterPodAffinity.
MatchInterPodAffinityPred = "MatchInterPodAffinity"
// CheckVolumeBindingPred defines the name of predicate CheckVolumeBinding.
CheckVolumeBindingPred = "CheckVolumeBinding"
// GeneralPred defines the name of predicate GeneralPredicates.
GeneralPred = "GeneralPredicates"
// HostNamePred defines the name of predicate HostName.
HostNamePred = "HostName"
// PodFitsHostPortsPred defines the name of predicate PodFitsHostPorts.
PodFitsHostPortsPred = "PodFitsHostPorts"
// MatchNodeSelectorPred defines the name of predicate MatchNodeSelector.
MatchNodeSelectorPred = "MatchNodeSelector"
// PodFitsResourcesPred defines the name of predicate PodFitsResources.
PodFitsResourcesPred = "PodFitsResources"
// NoDiskConflictPred defines the name of predicate NoDiskConflict.
NoDiskConflictPred = "NoDiskConflict"
// PodToleratesNodeTaintsPred defines the name of predicate PodToleratesNodeTaints.
PodToleratesNodeTaintsPred = "PodToleratesNodeTaints"
// CheckNodeUnschedulablePred defines the name of predicate CheckNodeUnschedulablePredicate.
CheckNodeUnschedulablePred = "CheckNodeUnschedulable"
// CheckNodeLabelPresencePred defines the name of predicate CheckNodeLabelPresence.
CheckNodeLabelPresencePred = "CheckNodeLabelPresence"
// CheckServiceAffinityPred defines the name of predicate checkServiceAffinity.
CheckServiceAffinityPred = "CheckServiceAffinity"
// MaxEBSVolumeCountPred defines the name of predicate MaxEBSVolumeCount.
// DEPRECATED
// All cloudprovider specific predicates are deprecated in favour of MaxCSIVolumeCountPred.
MaxEBSVolumeCountPred = "MaxEBSVolumeCount"
// MaxGCEPDVolumeCountPred defines the name of predicate MaxGCEPDVolumeCount.
// DEPRECATED
// All cloudprovider specific predicates are deprecated in favour of MaxCSIVolumeCountPred.
MaxGCEPDVolumeCountPred = "MaxGCEPDVolumeCount"
// MaxAzureDiskVolumeCountPred defines the name of predicate MaxAzureDiskVolumeCount.
// DEPRECATED
// All cloudprovider specific predicates are deprecated in favour of MaxCSIVolumeCountPred.
MaxAzureDiskVolumeCountPred = "MaxAzureDiskVolumeCount"
// MaxCinderVolumeCountPred defines the name of predicate MaxCinderDiskVolumeCount.
// DEPRECATED
// All cloudprovider specific predicates are deprecated in favour of MaxCSIVolumeCountPred.
MaxCinderVolumeCountPred = "MaxCinderVolumeCount"
// MaxCSIVolumeCountPred defines the predicate that decides how many CSI volumes should be attached.
MaxCSIVolumeCountPred = "MaxCSIVolumeCountPred"
// NoVolumeZoneConflictPred defines the name of predicate NoVolumeZoneConflict.
NoVolumeZoneConflictPred = "NoVolumeZoneConflict"
// EvenPodsSpreadPred defines the name of predicate EvenPodsSpread.
EvenPodsSpreadPred = "EvenPodsSpread"
)
常用的预选策略:
PodFitsHostPorts:如果 Pod 中定义了 hostPort 属性,那么需要先检查这个指定端口是否 已经被 Node 上其他服务占用了。
PodFitsHost:若 pod 对象拥有 hostname 属性,则检查 Node 名称字符串与此属性是否匹配。
PodFitsResources:检查 Node 上是否有足够的资源(如,cpu 和内存)来满足 pod 的资源请求。
PodMatchNodeSelector:检查 Node 的 标签 是否能匹配 Pod 属性上 Node 的 标签 值。
NoVolumeZoneConflict:检测 pod 请求的 Volumes 在 Node 上是否可用,因为某些存储卷存在区域调度约束。
NoDiskConflict:检查 Pod 对象请求的存储卷在 Node 上是否可用,若不存在冲突则通过检查。
MaxCSIVolumeCount:检查 Node 上已经挂载的 CSI 存储卷数量是否超过了指定的最大值。
CheckNodeMemoryPressure:如果 Node 上报了内存资源压力过大,而且没有配置异常,那么 Pod 将不会被调度到这个 Node 上。
CheckNodePIDPressure:如果 Node 上报了 PID 资源压力过大,而且没有配置异常,那么 Pod 将不会被调度到这个 Node 上。
CheckNodeDiskPressure:如果 Node 上报了磁盘资源压力过大(文件系统满了或者将近满了), 而且配置异常,那么 Pod 将不会被调度到这个 Node 上。
CheckNodeCondition:Node 可以上报其自身的状态,如磁盘、网络不可用,表明 kubelet 未准备好运行 pod。如果 Node 被设置成这种状态,那么 pod 将不会被调度到这个 Node 上。
PodToleratesNodeTaints:检查 pod 属性上的 tolerations 能否容忍 Node 的 taints。
CheckVolumeBinding:检查 Node 上已经绑定的和未绑定的 PVCs 能否满足 Pod 对象的存储卷需求。
打分策略如下:
SelectorSpreadPriority:尽量将归属于同一个 Service、StatefulSet 或 ReplicaSet 的 Pod 资源分散到不同的 Node 上。
InterPodAffinityPriority:遍历 Pod 对象的亲和性条目,并将那些能够匹配到给定 Node 的条目的权重相加,结果值越大的 Node 得分越高。
LeastRequestedPriority:空闲资源比例越高的 Node 得分越高。换句话说,Node 上的 Pod 越多,并且资源被占用的越多,那么这个 Node 的得分就会越少。
MostRequestedPriority:空闲资源比例越低的 Node 得分越高。这个调度策略将会把你所有的工作负载(Pod)调度到尽量少的 Node 上。
RequestedToCapacityRatioPriority:为 Node 上每个资源占用比例设定得分值,给资源打分函数在打分时使用。
BalancedResourceAllocation:优选那些使得资源利用率更为均衡的节点。
NodePreferAvoidPodsPriority:这个策略将根据 Node 的注解信息中是否含有 scheduler.alpha.kubernetes.io/preferAvoidPods 来 计算其优先级。使用这个策略可以将两个不同 Pod 运行在不同的 Node 上。
NodeAffinityPriority:基于 Pod 属性中 PreferredDuringSchedulingIgnoredDuringExecution 来进行 Node 亲和性调度。你可以通过这篇文章 Pods 到 Nodes 的分派 来了解到更详细的内容。
TaintTolerationPriority:基于 Pod 中对每个 Node 上污点容忍程度进行优先级评估,这个策略能够调整待选 Node 的排名。
ImageLocalityPriority:Node 上已经拥有 Pod 需要的 容器镜像 的 Node 会有较高的优先级。
ServiceSpreadingPriority:这个调度策略的主要目的是确保将归属于同一个 Service 的 Pod 调度到不同的 Node 上。如果 Node 上 没有归属于同一个 Service 的 Pod,这个策略更倾向于将 Pod 调度到这类 Node 上。最终的目的:即使在一个 Node 宕机之后 Service 也具有很强容灾能力。
CalculateAntiAffinityPriorityMap:这个策略主要是用来实现pod反亲和。
EqualPriorityMap:将所有的 Node 设置成相同的权重为 1。

自定义调度器
除了 kubernetes 自带的调度器,考虑到实际环境中的各种复杂情况,kubernetes 的调度器采用插件化的形式实现,可以方便用户进行定制或者二次开发,我们可以自定义一个调度器并以插件形式和 kubernetes 进行集成。你也可以编写自己的调度器。通过 spec:schedulername 参数指定调度器的名字,可以为 pod 选择某个调度器进行调度。
kube-scheduler在启动的时候可以通过 --policy-config-file参数来指定调度策略文件,我们可以根据我们自己的需要来组装Predicates和Priority函数。选择不同的过滤函数和优先级函数、控制优先级函数的权重、调整过滤函数的顺序都会影响调度过程。
比如下面的 pod 选择 test-my-scheduler 进行调度,而不是默认的 default-scheduler:
apiVersion: v1
kind: Pod
metadata:
name: test-scheduler
labels:
name: testscheduler-example
spec:
schedulername: test-my-scheduler
containers:
- name: pod-with-second-annotation-container
image: gcr.io/google_containers/pause:2.0
调度器的编写请参考 kubernetes 默认调度器的实现,最核心的内容就是读取 apiserver 中 pod 的值,根据特定的算法找到合适的 node,然后把调度结果会写到 apiserver。
官方给出的范例:
#!/bin/bash
SERVER='localhost:8001'
while true;
do
for PODNAME in $(kubectl --server $SERVER get pods -o json | jq '.items[] | select(.spec.schedulerName == "my-scheduler") | select(.spec.nodeName == null) | .metadata.name' | tr -d '"')
;
do
NODES=($(kubectl --server $SERVER get nodes -o json | jq '.items[].metadata.name' | tr -d '"'))
NUMNODES=${#NODES[@]}
CHOSEN=${NODES[$[ $RANDOM % $NUMNODES ]]}
curl --header "Content-Type:application/json" --request POST --data '{"apiVersion":"v1", "kind": "Binding", "metadata": {"name": "'$PODNAME'"}, "target": {"apiVersion": "v1", "kind"
: "Node", "name": "'$CHOSEN'"}}' http://$SERVER/api/v1/namespaces/default/pods/$PODNAME/binding/
echo "Assigned $PODNAME to $CHOSEN"
done
sleep 1
done

【END】

更多精彩推荐
☞中国 AI 应用元年来了!
☞新基建东风下,开发者这样抓住工业互联网风口!
☞15 岁黑进系统,发挑衅邮件意外获 Offer,不惑之年捐出全部财产,Twitter CEO 太牛了!
☞避坑!使用 Kubernetes 最易犯的 10 个错误
☞必读!53个Python经典面试题详解
☞赠书 | 1月以来 Tether 增发47亿 USDT,美元都去哪儿了?
你点的每个“在看”,我都认真当成了喜欢


















 2679
2679

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











