 多租户之Quartz定时任务配置与原理
多租户之Quartz定时任务配置与原理





多租户定时任务篇
多租户要做到数据的隔离,涉及到数据库,redis, mongodb, es等等。而定时任务作为操作数据的一个入口,也需要考虑进来。
前言
因为历史系统遗留原因,本篇以quartz定时任务为例,讲述它的启动细节,以及多租户处理。
一、先让quartz跑起来
启动springboot项目,版本2.7.0. quartz版本是目前最新的稳定版本是2.3.0,但spring-boot-starter-quartz对应的版本是2.3.2
基于内存的是默认存储方式,虽然这种方式的性能更好,但是我们还是习惯于使用数据库存储,所以数据库依赖也一步位。
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.26</version>
</dependency>
配置一个任务:留意usingJobData,它内部使用了Map,也是实现多租户隔离的机制。
package com.example.qz.config;
import com.example.qz.job.FirstDemoJob;
import org.quartz.JobBuilder;
import org.quartz.JobDetail;
import org.quartz.SimpleScheduleBuilder;
import org.quartz.Trigger;
import org.quartz.TriggerBuilder;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
/**
* @author: jelex.xu
* @Date: 2025/1/9 09:38
* @desc:
**/
@Configuration
public class QuartzConfig {
@Bean
public JobDetail firstJobDetail(){
return JobBuilder.newJob(FirstDemoJob.class)
.withIdentity("firstJob")
.storeDurably()
.withDescription("firstJob测试")
.usingJobData("tenantId", "大庆")
.usingJobData("best美剧", "Prison Break")
.build();
}
@Bean
public Trigger firstJobTrigger(){
return TriggerBuilder.newTrigger()
.forJob(firstJobDetail())
.withIdentity("firstJobTrigger")
.withDescription("firstJobTrigger测试")
// .withSchedule(SimpleScheduleBuilder.simpleSchedule().withIntervalInSeconds(5).repeatForever())
.withSchedule(SimpleScheduleBuilder.repeatSecondlyForever(5))
.usingJobData("tenantId", "大庆~") // 会覆盖jobDetail中的tenantId
.usingJobData("lucyNo", 19)
.startNow()
.build();
}
}
package com.example.qz.job;
import com.alibaba.fastjson2.JSON;
import lombok.extern.slf4j.Slf4j;
import org.quartz.DisallowConcurrentExecution;
import org.quartz.JobExecutionContext;
import org.quartz.JobExecutionException;
import org.quartz.PersistJobDataAfterExecution;
import org.springframework.scheduling.quartz.QuartzJobBean;
/**
* @author: jelex.xu
* @Date: 2025/1/9 09:26
* @desc:
**/
//@PersistJobDataAfterExecution
//@DisallowConcurrentExecution // 根据jobKey 来判断是否并发执行
// @todo 待确认 如果是一个多个trigger绑定一个job, 能使用此注解吗?会限制多租户(都需要执行某个任务)的定时调用
@Slf4j
public class FirstDemoJob extends QuartzJobBean {
@Override
protected void executeInternal(JobExecutionContext context) throws JobExecutionException {
log.info("firstDemoJob execute, jobDataMap: {},,,, jobDetail:{},,,, trigger:{}",
JSON.toJSONString(context.getMergedJobDataMap()),
JSON.toJSONString(context.getJobDetail()), context.getTrigger());
}
}
如果使用基于内存的存储,那现在就可以启动项目了,然后控制台就会出现如下所示日志:
注意红框下一行的 RAMJobStore


此时有些疑问,为什么默认是10个线程,有哪些默认配置,能配置哪些内容?我们往下看。
根据控制台日志定位到:
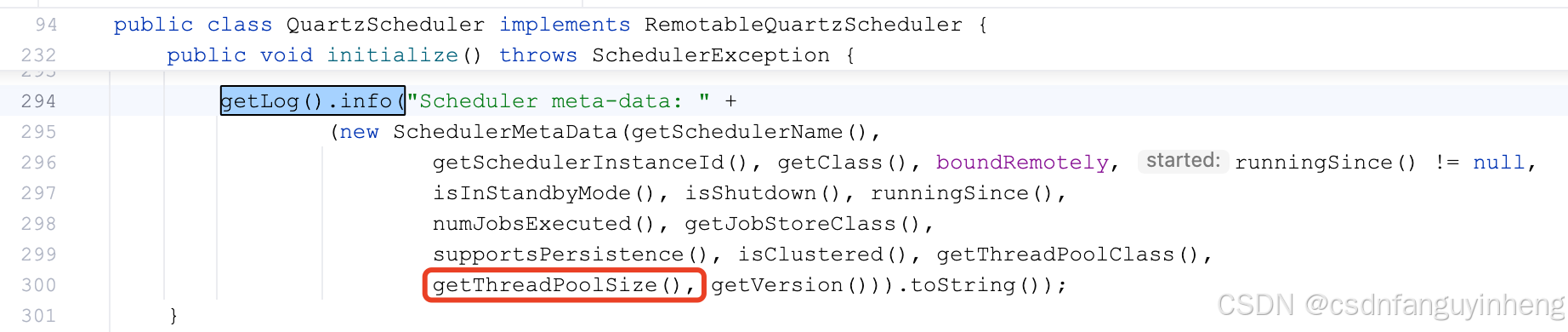
public int getThreadPoolSize() {
return resources.getThreadPool().getPoolSize();
}
是谁调用这个设置线程池方法呢?

源码分析:
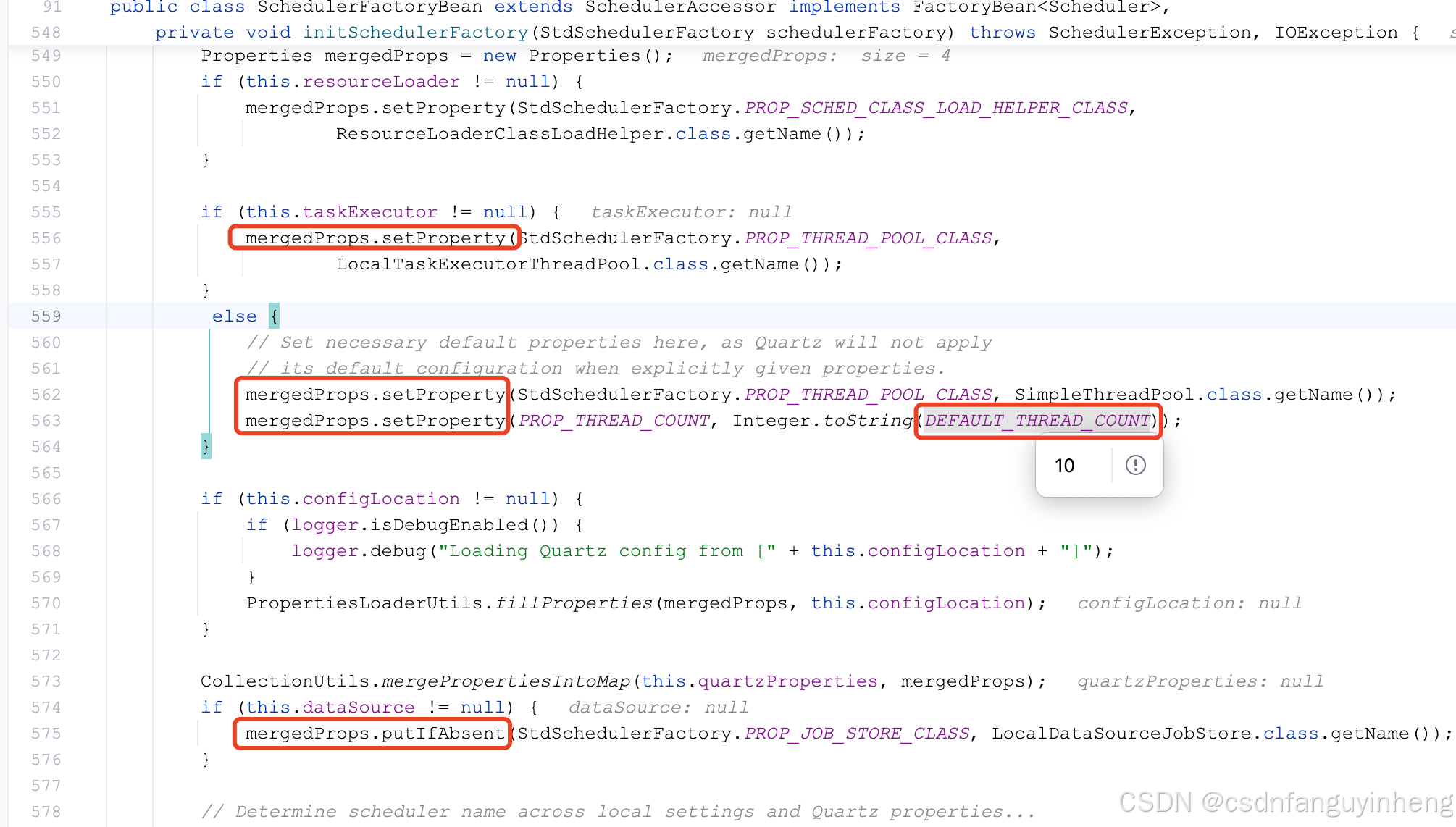
可以看到除了线程数量外,还有几个默认属性。往下,注意这里要跳到StdSchedulerFactory类中了:
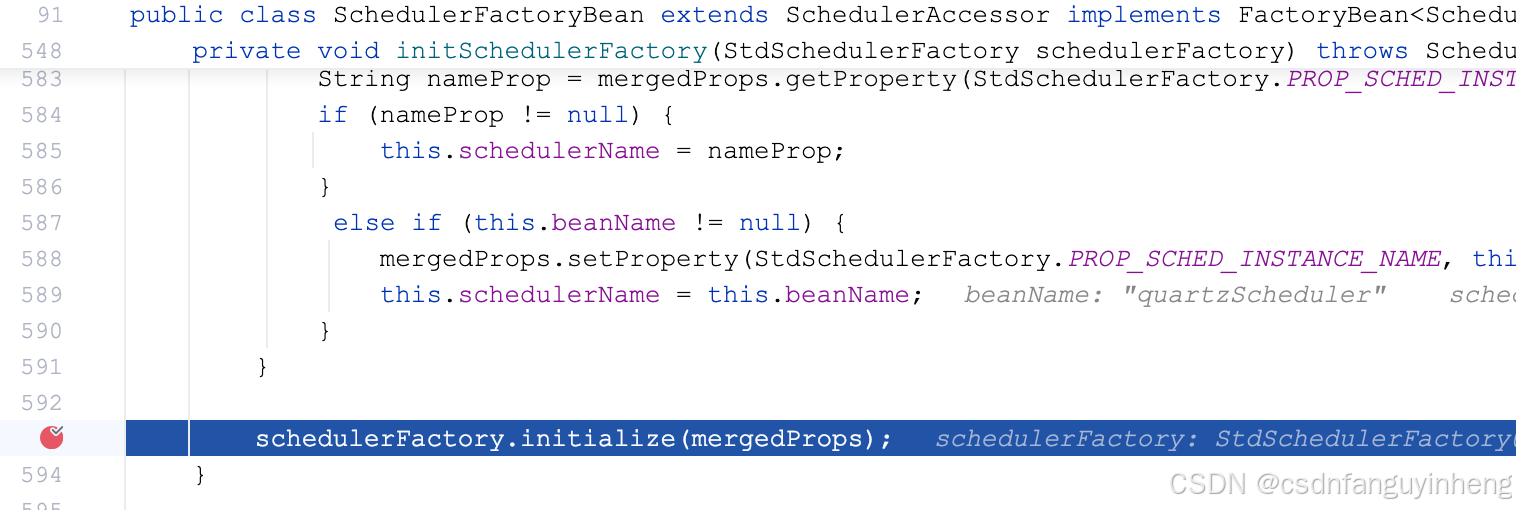

到此,StdSchedulerFactory类中的cfg属性有值了,有如下这些默认值:

接着往下,具体到线程部分:

org.quartz.impl.StdSchedulerFactory#setBeanProps通过反射把属性值设置到这个对象中:
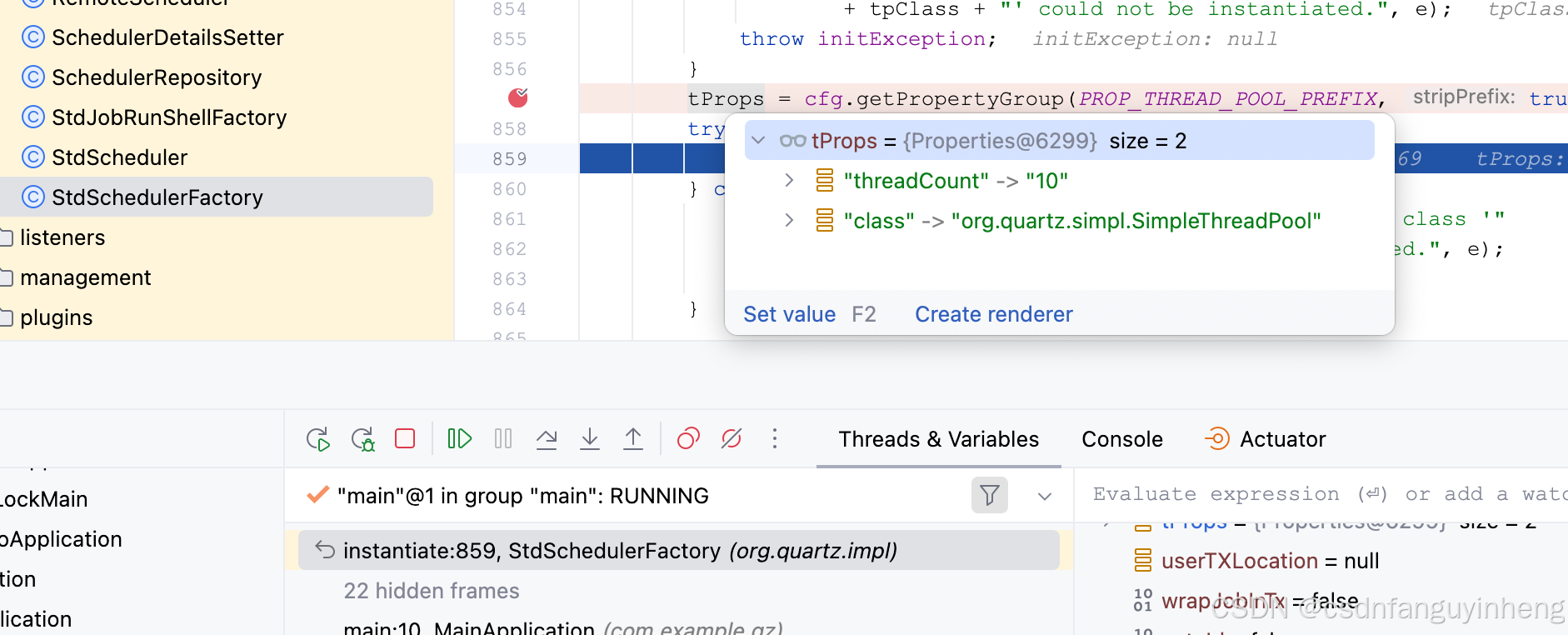

至此读取默认配置值,并初始化流程打通了。那么有哪些属性可以设置呢?
二、原理
线程部分可查看类org.quartz.simpl.SimpleThreadPool:
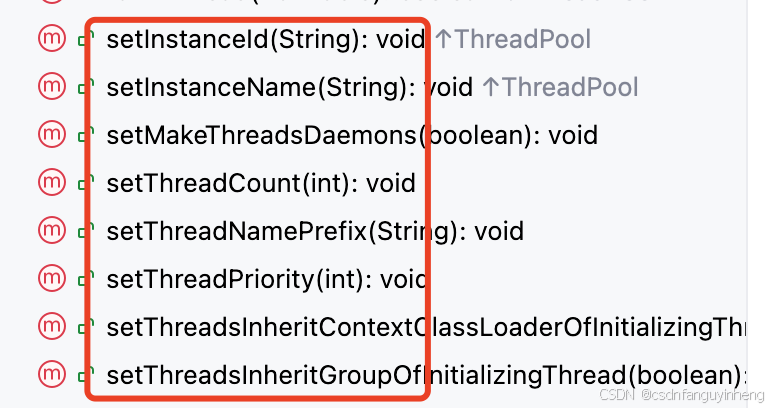
其它大部分属性可以在org.quartz.impl.StdSchedulerFactory中查看:
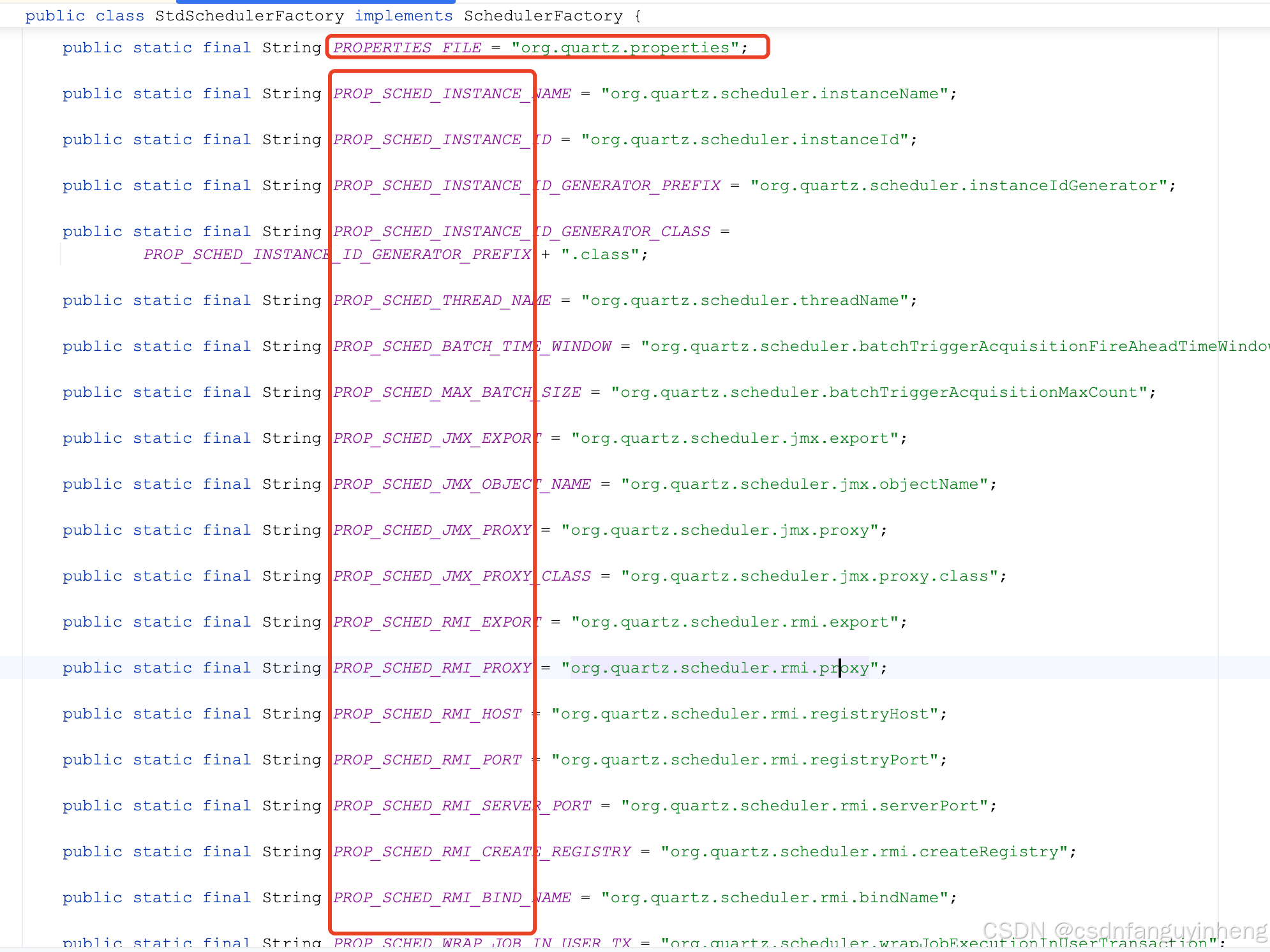
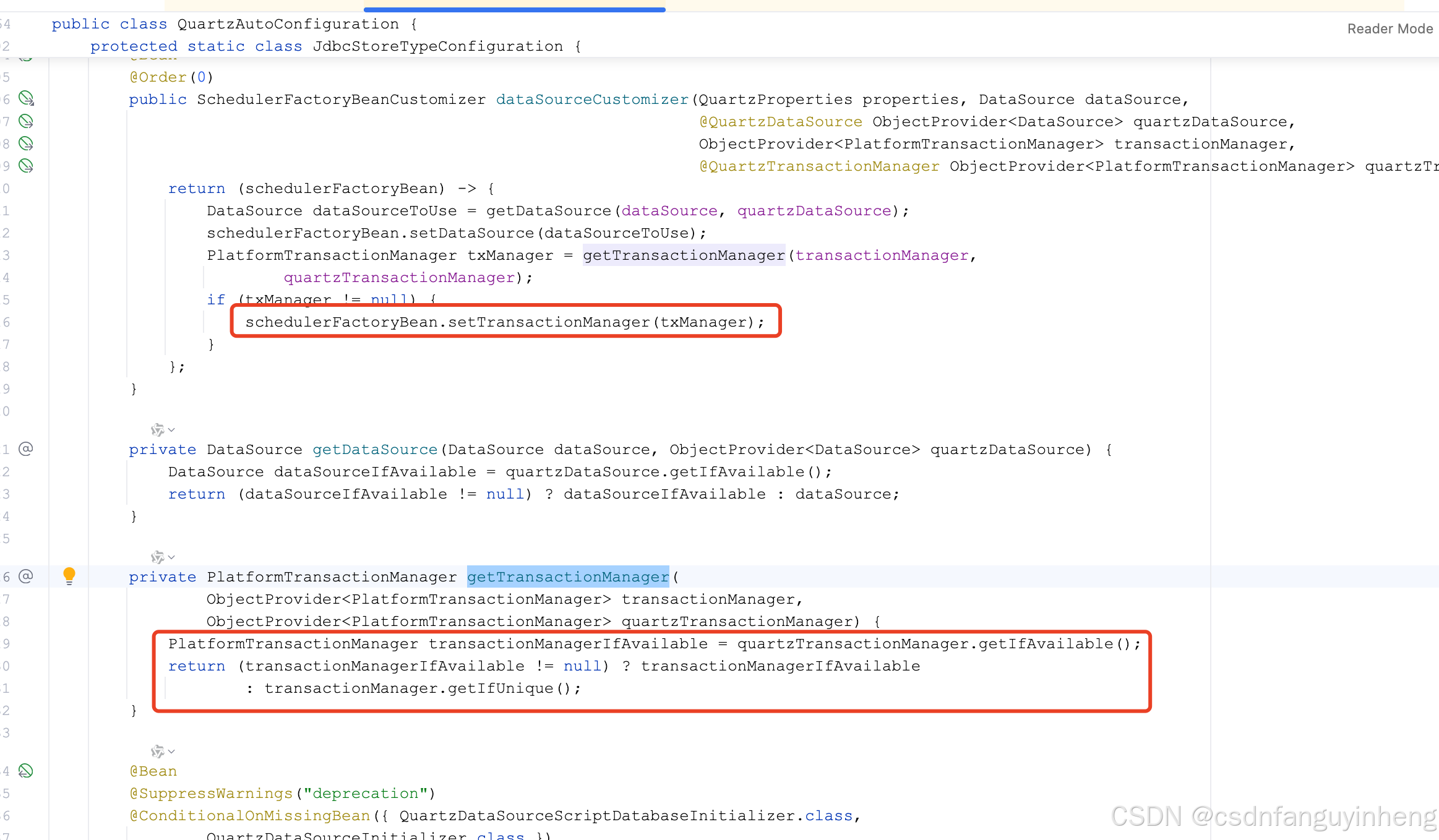
还有数据库层面的配置,在下面说清楚,这里先说完原理:自动装配:
org.springframework.boot.autoconfigure.quartz.QuartzAutoConfiguration
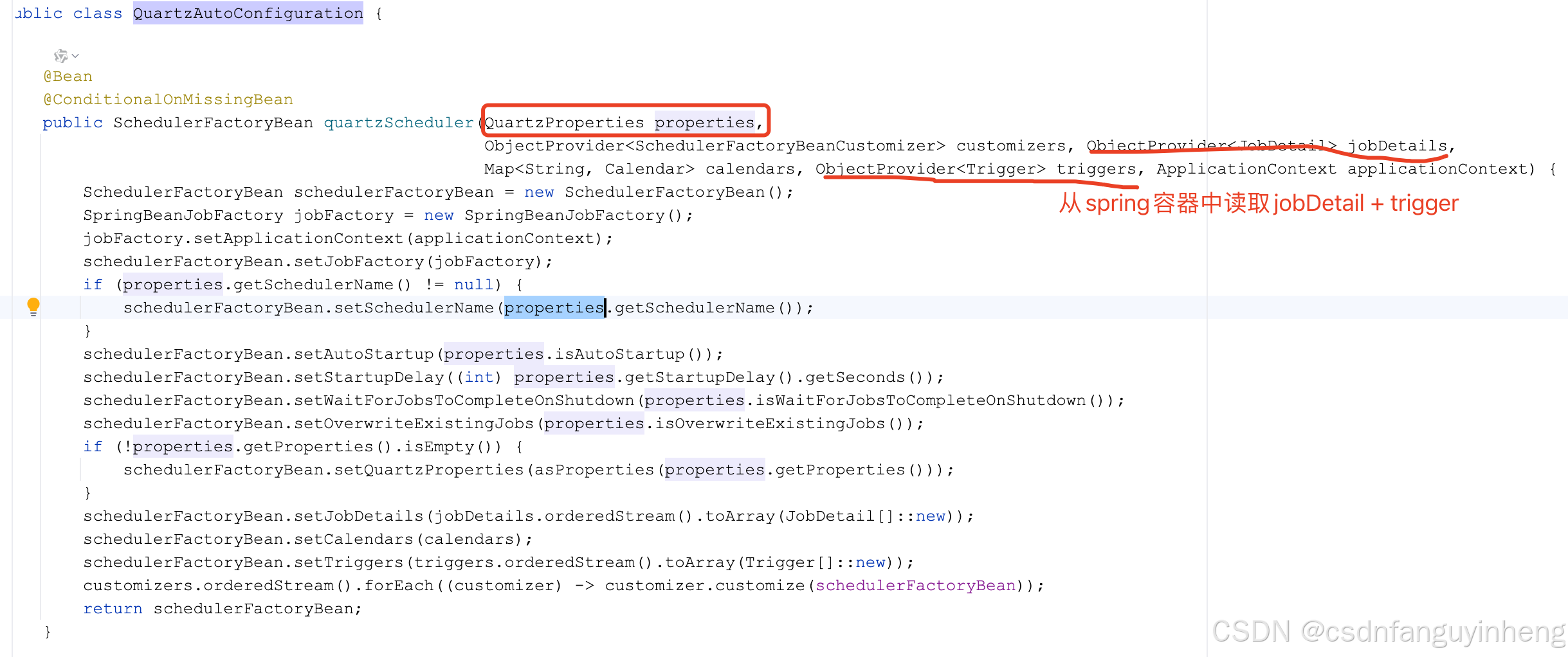
所以QuartzProperties关键:

额外的quartz配置项在这里接收:

那上面说完了quartz线程方面的配置,接下来就说quartz数据库相关的配置.
三、使用mysql存储
3.1 铺垫
因为使用层面上比较简单,网上教程一大堆,就那么几个参数,这里我只想把原理铺垫开。
这里还是自动装配:
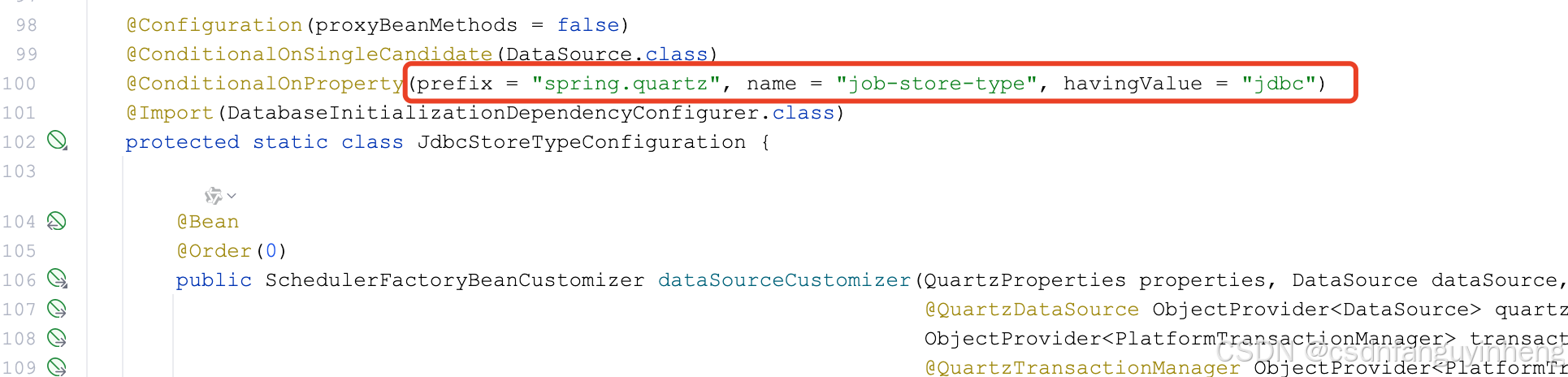

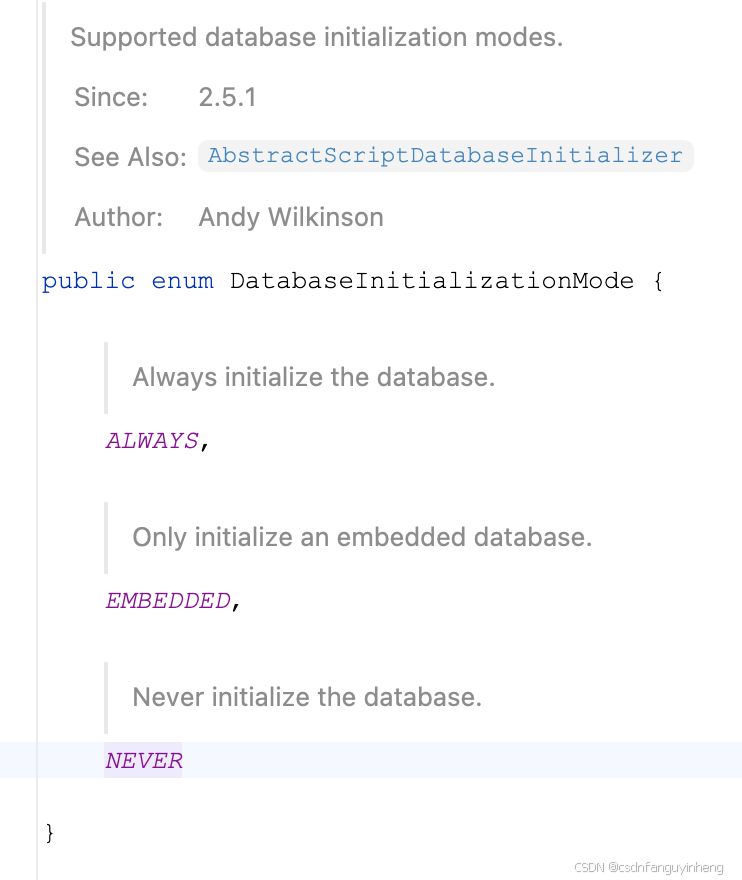
默认初始化sql脚本位置:

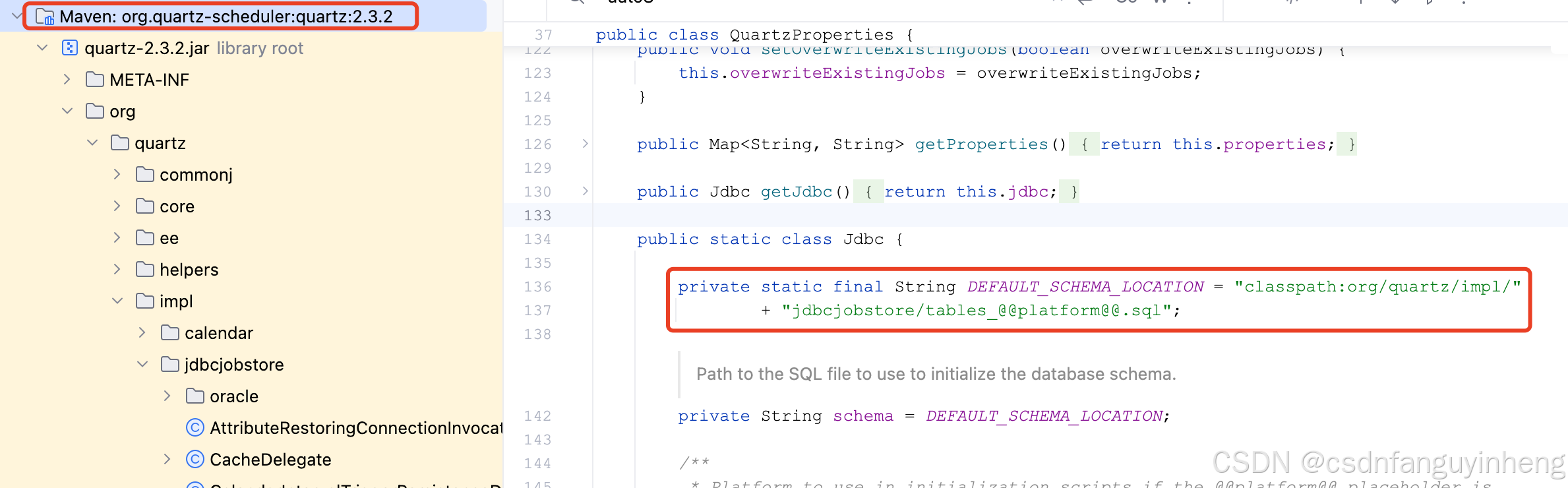
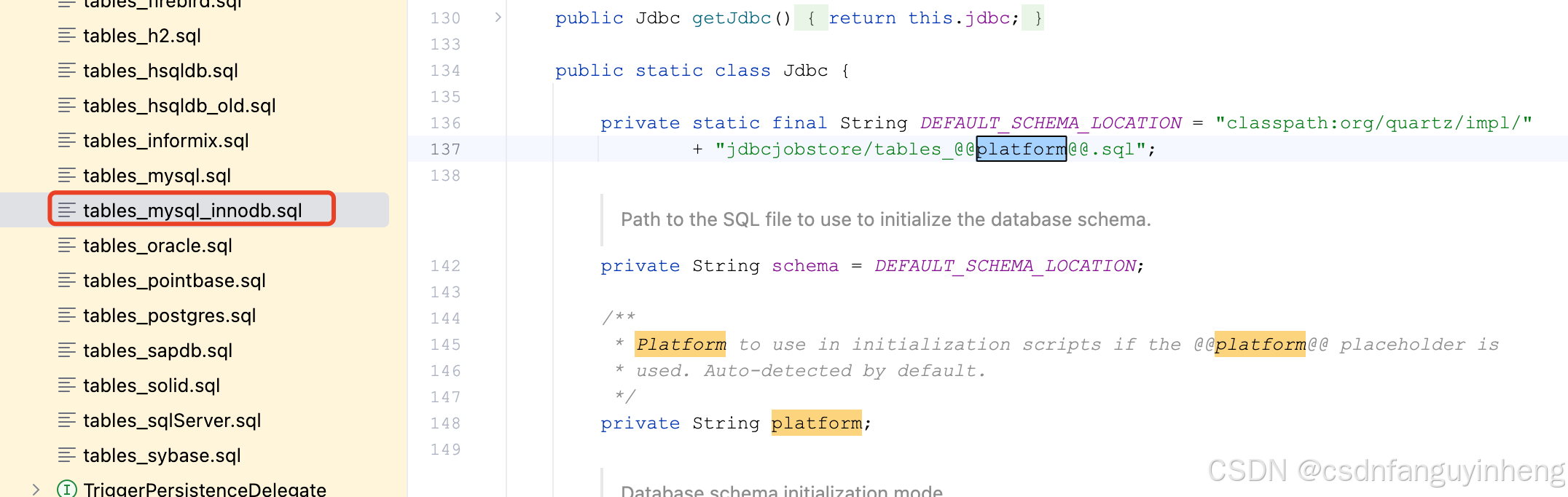
不出意外,我们使用的会是tables_mysql_innodb.sql
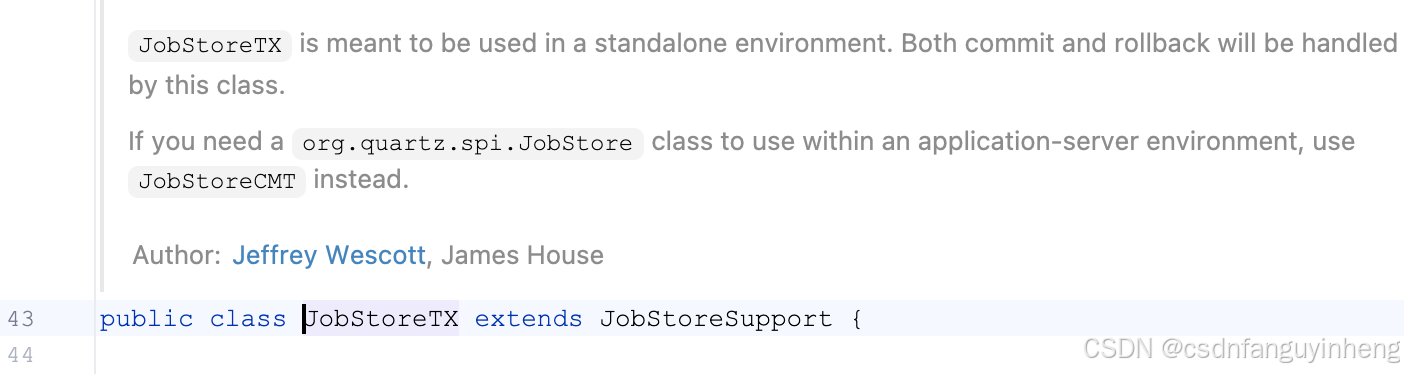
数据库层面可配置的属性:注意,要看它们的set方法,而不是属性名称

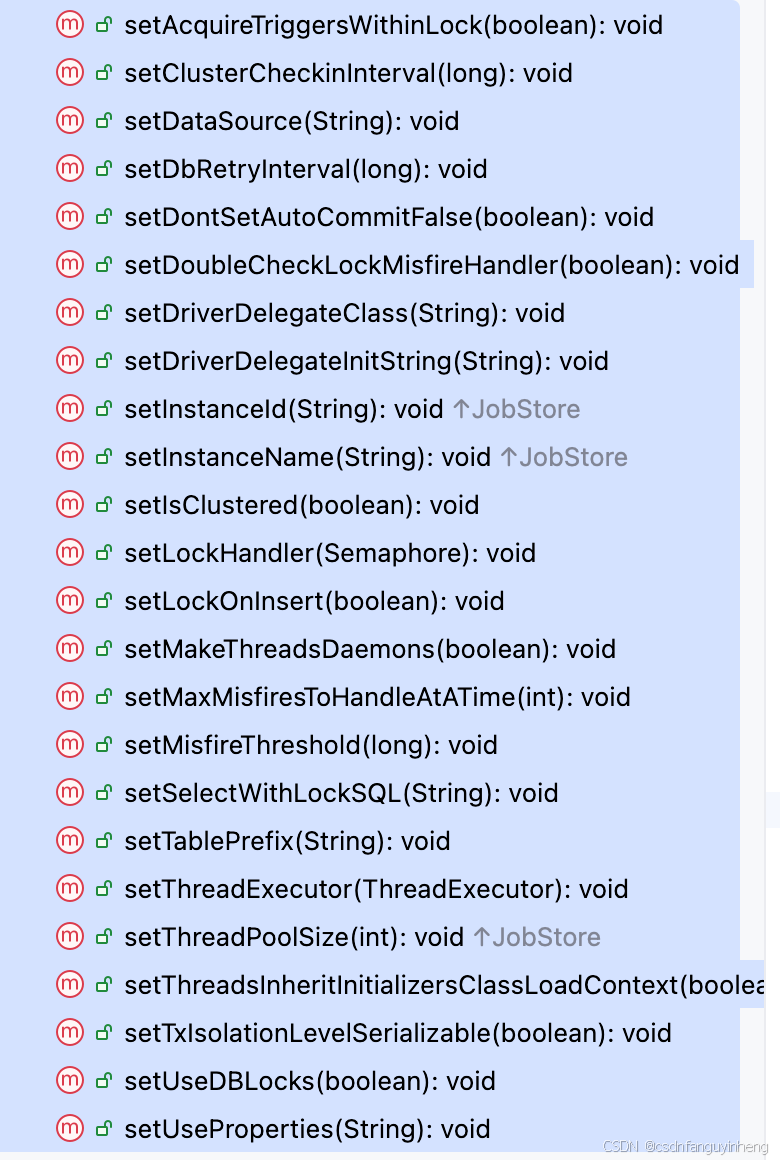
其它大多数类都继承于StdJDBCDelegate类
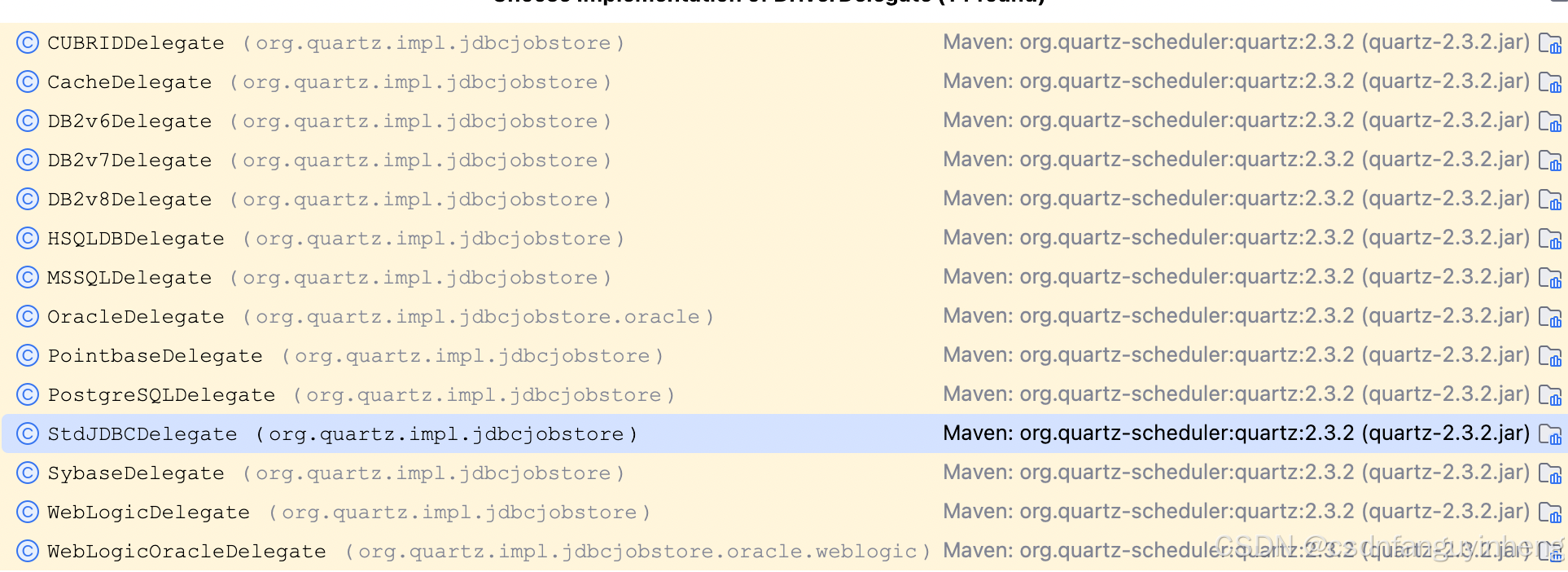
这里涉及到定时任务数据源配置:配置项可查看PoolingConnectionProvider类:
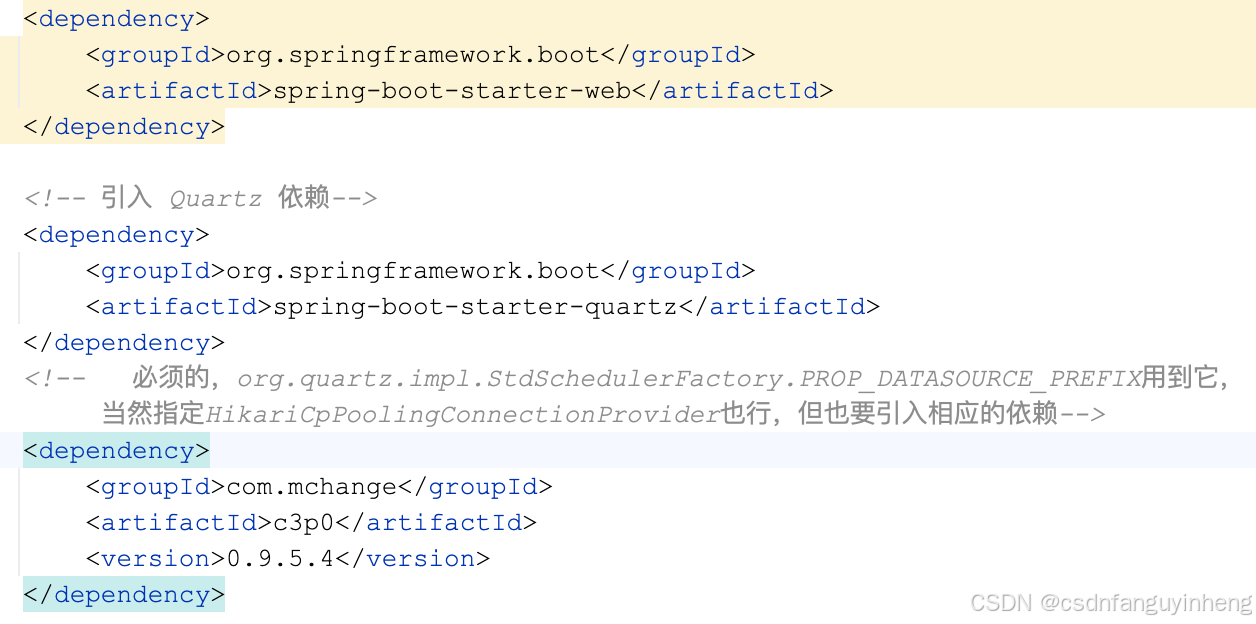
要加入c3p0依赖,否则报错:
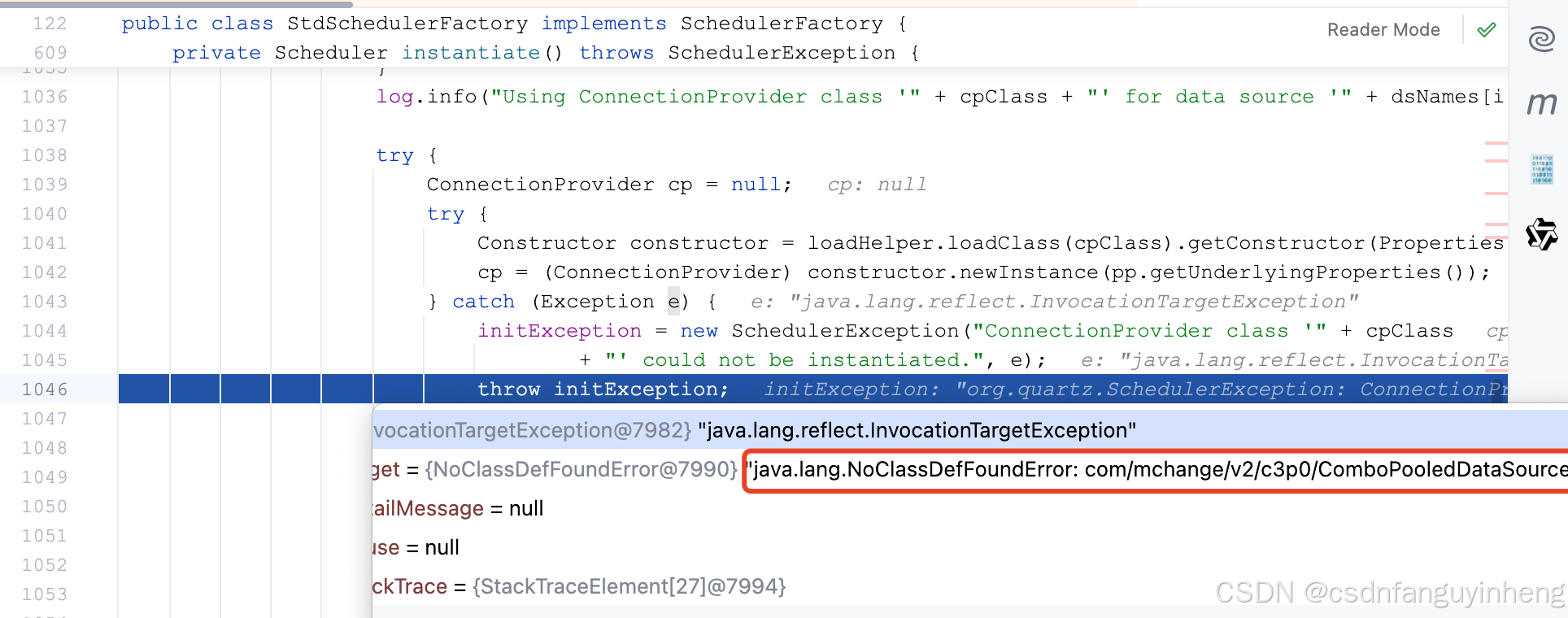
但是也可以通过配置connectionProvider.class 解决,但是也要加入相应类的依赖
pom.xml依赖如下:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-quartz</artifactId>
</dependency>
<!-- 必须的,org.quartz.impl.StdSchedulerFactory.PROP_DATASOURCE_PREFIX用到它,
当然指定HikariCpPoolingConnectionProvider也行,但也要引入相应的依赖-->
<dependency>
<groupId>com.mchange</groupId>
<artifactId>c3p0</artifactId>
<version>0.9.5.4</version>
</dependency>
3.2 最终配置如下
spring:
quartz:
# scheduler-name: quartzScheduler # 默认值
job-store-type: jdbc
overwrite-existing-jobs: true
# jdbc:
# initialize-schema: always
properties:
org.quartz.scheduler.instanceName: MyQuartz # 集群的名称要一致
org.quartz.scheduler.instanceId: AUTO
org.quartz.jobStore.class: org.quartz.impl.jdbcjobstore.JobStoreTX # 定时和业务分开,用这个
# org.quartz.jobStore.class: org.springframework.scheduling.quartz.LocalDataSourceJobStore
org.quartz.jobStore.dataSource: qz # 数据源名称要有,否则报错
org.quartz.jobStore.driverDelegateClass: org.quartz.impl.jdbcjobstore.StdJDBCDelegate
# org.quartz.jobStore.tablePrefix: QRTZ_ # 默认值
org.quartz.jobStore.isClustered: true # 集群,默认是false, 如果有多个实例运行,那就设置为true
org.quartz.jobStore.clusterCheckinInterval: 20000 # 集群检查时间间隔,默认75000ms
# org.quartz.dataSource.my_quartz.connectionProvider.class: org.quartz.utils.HikariCpPoolingConnectionProvider # 数据源连接池,不指定时默认使用c3p0,org.quartz.utils.C3p0PoolingConnectionProvider
org.quartz.dataSource.qz.driver: com.mysql.cj.jdbc.Driver
org.quartz.dataSource.qz.URL: jdbc:mysql://127.0.0.1:3306/my_quartz?useUnicode=true&characterEncoding=utf-8&useSSL=false&serverTimezone=Asia/Shanghai
org.quartz.dataSource.qz.user: root
org.quartz.dataSource.qz.password: jelexRoot!
# org.quartz.threadPool.class: org.quartz.simpl.SimpleThreadPool # 线程池,这也是默认值
# org.quartz.threadPool.threadCount: 10 # 线程池大小,默认10
# org.quartz.threadPool.threadPriority: 5 # 线程优先级,默认5
3.3 运行测试

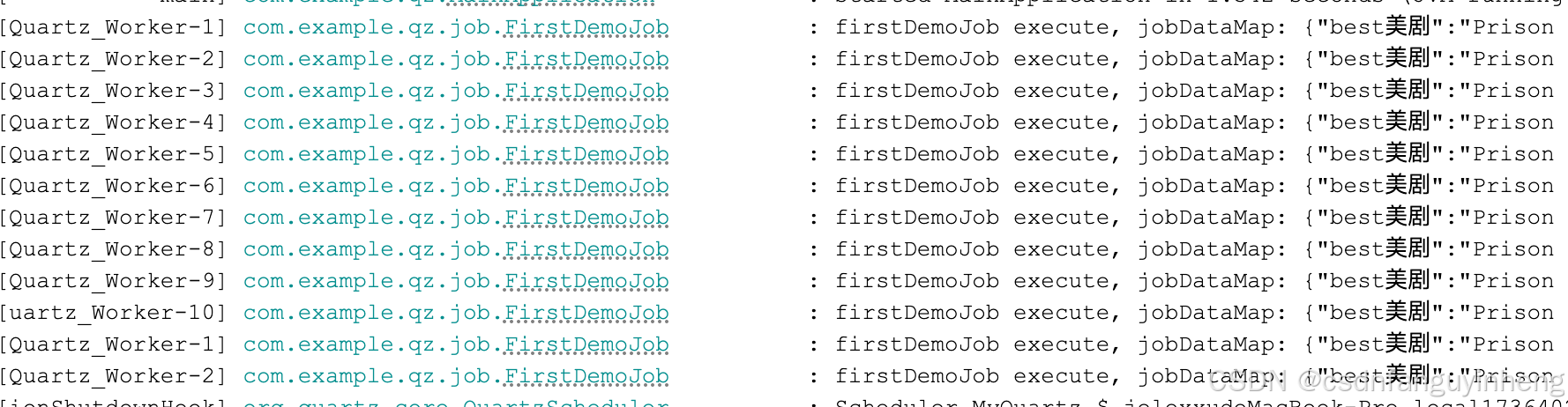
至此,quartz环境算是ok了,可以看到触发调度执行时,可以从jobDataMap中拿到租户上下文信息,进行业务调用了。。。
总结
例如:以上就是本篇内容。但还有不少完善的地方:
1.还差启动一个业务系统,对接起来,即把租户信息透传到业务系统。但是我们已经拿到从trigger/job中传递的租户信息。
2.如果是分布式的话,又涉及到feign调用的多租户链路传递了,可以通过feign的拦截器配置,在请求头中添加租户信息。
3.应该提供一个增删改查的页面,用于管理定时任务。
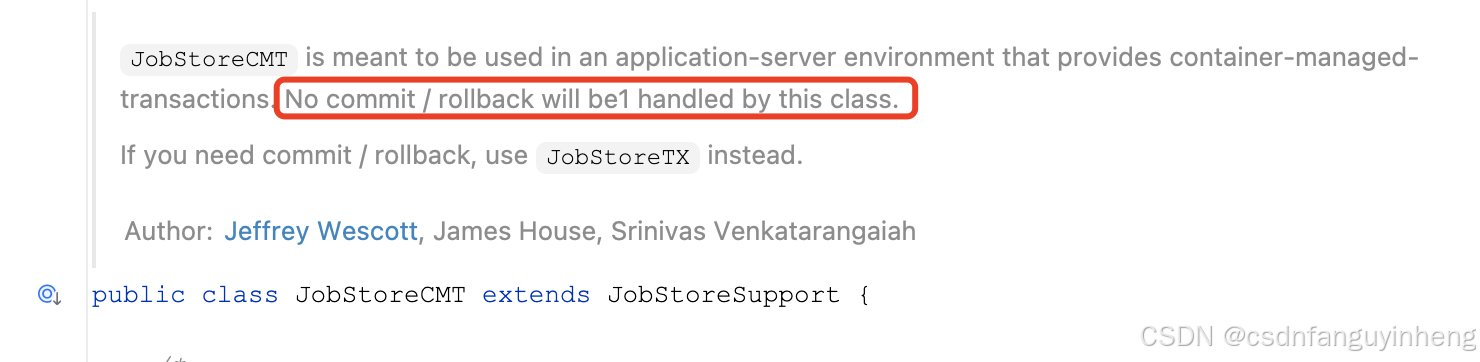
另外,本篇并没有详细介绍配置中的org.quartz.impl.jdbcjobstore.JobStoreTX类,这里贴出官方说明吧:
JobStoreTX is meant to be used in a standalone environment.
Both commit and rollback will be handled by this class.
If you need a org.quartz.spi.JobStore class
to use within an application-server environment, use JobStoreCMT instead.
我的理解是:如果定时任务是独立的springboot项目,那么就使用JobStoreTX,如果定时任务和业务系统是一起的,那么就使用JobStoreCMT, 我们yaml配置中注释掉的LocalDataSourceJobStore正是JobStoreCMT的子类。
前者可配置独立的事务管理器,后者不处理事务的提交/回滚,它依赖于业务系统本身的事务。

















 1740
1740

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









