




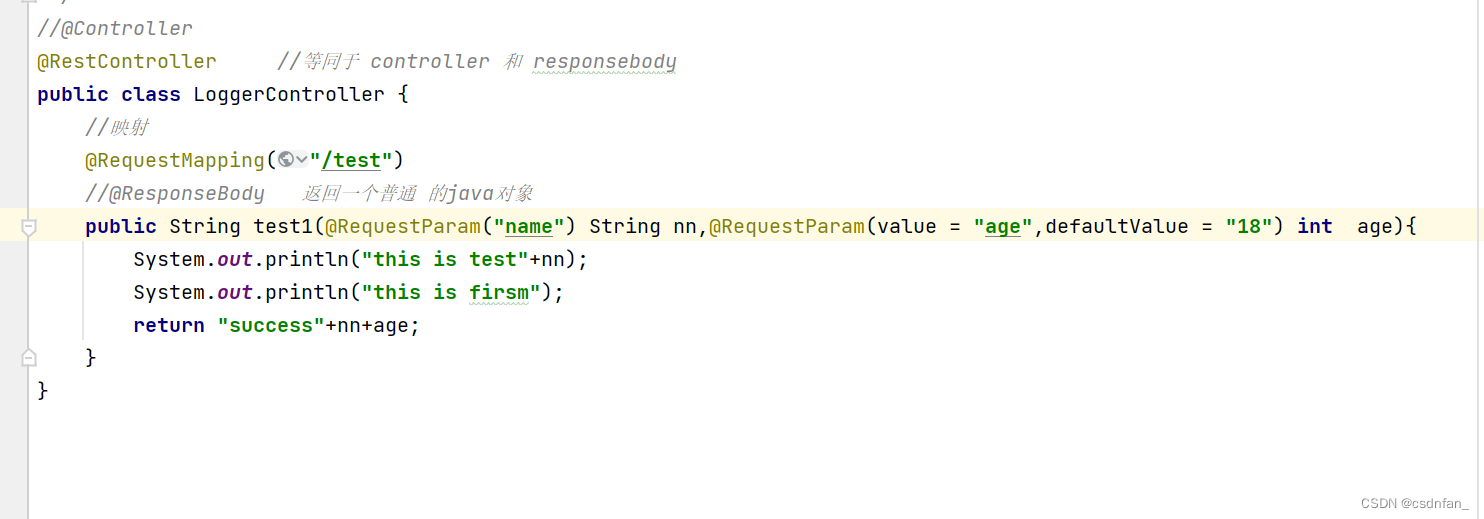
访问的时候

这是因为properties中配置的是 本地 的localhost
因为这里面请求地址是applog
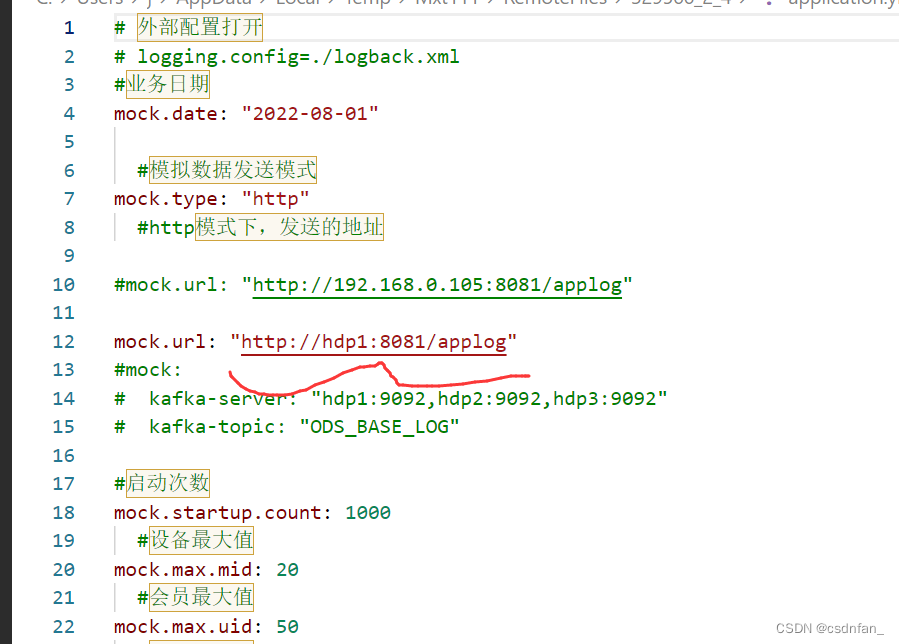
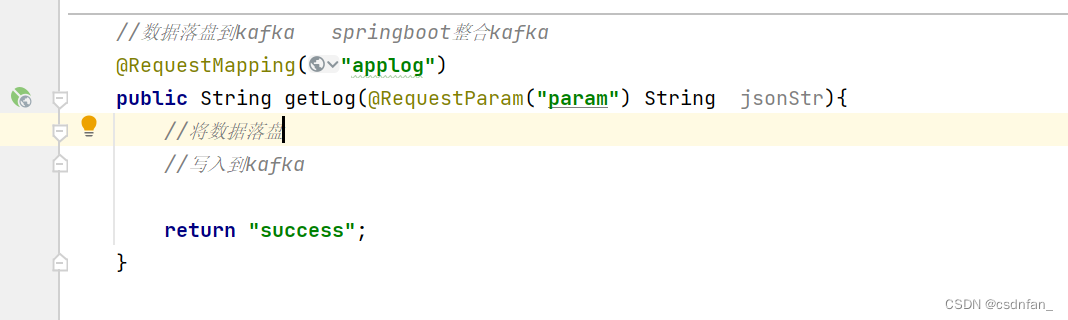
发送到kafka的properties
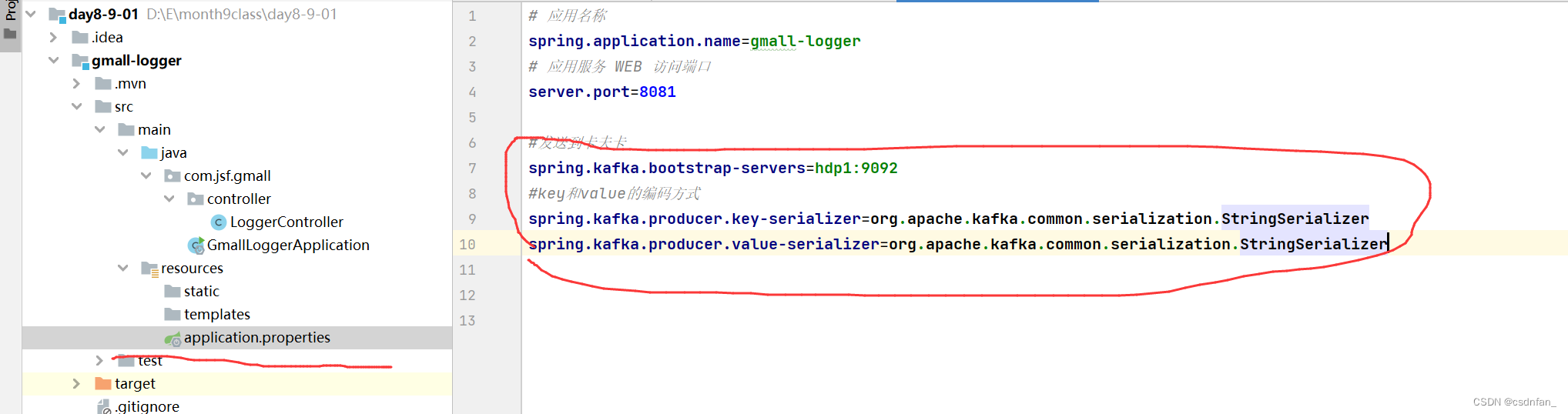
添加一个logback.xml
<?xml version="1.0" encoding="UTF-8"?>
<configuration>
<property name="LOG_HOME" value="d:/logs" />
<appender name="console" class="ch.qos.logback.core.ConsoleAppender">
<encoder>
<pattern>%msg%n</pattern>
</encoder>
</appender>
<appender name="rollingFile" class="ch.qos.logback.core.rolling.RollingFileAppender">
<file>${LOG_HOME}/app.log</file>
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<fileNamePattern>${LOG_HOME}/app.%d{yyyy-MM-dd}.log</fileNamePattern>
</rollingPolicy>
<encoder>
<pattern>%msg%n</pattern>a
</encoder>
</appender>
<!-- 将某一个包下日志单独打印日志 -->
<logger name="com.jsf.gmall.controller.LoggerController.java"
level="INFO" additivity="false">
<appender-ref ref="rollingFile" />
<appender-ref ref="console" />
</logger>
<root level="error" additivity="false">
<appender-ref ref="console" />
</root>
</configuration>
导入一个lombok下的

设置日志级别 (info ,和 warn 级别)


















 8307
8307


 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言








