




在这个 AI 日新月异的时代,AIGC(AI生成内容)已迅速席卷全球,甚至掀起了一场技术革命。然而,当我们谈论这些炫酷的大模型时,你是否思考过它们背后的秘密?是什么让这些开源模型如此强大?它们是如何被训练出来的,又如何能够在我们本地运行?更重要的是,这场技术浪潮已经涌来,我们要如何在这股洪流中找到自己的方向,不被时代所抛下?所以作者决定出一系列的文章来和大家一起探索一下AIGC的世界,专栏就叫《重生之我要学AIGC》,欢迎大家订阅!!!谢谢大家。

在上一篇文章中:如果我们需要在本地运行大模型,我们应该怎么做?Ollama入门指南 我们认识了Ollama,知道了这是一款部署在本地的可以运行大模型的载体。
在之前我们也在SpringBoot项目中调用过阿里的通义灵码:国外的Spring出AI了?阿里:没关系,我会出手 但是,阿里的通义是阿里部署在云端的,我们只需要填写token调用他即可,很多同学说,不够深,我想要更深入一点,更深去了解AIGC本身,而之前我们说过的Ollama就是将大模型部署在本地的一个工具,而且Ollama也提供了RestApi的方式给我们调用,那么我们自然而然的就可以使用SpringBoot去集成Ollama实现全套部署一个自己的AIGC的应用。
Ollama有提供这样的RestApi
curl http://localhost:11434/api/chat -d '{
"model": "llama3.2",
"messages": [
{ "role": "user", "content": "why is the sky blue?" }
]
}'
但是就在作者想徒手造轮子,自己写一套SpringBoot的demo出来的时候(甚至SpringBootStarter),作者发现,Spring官方居然早就做了这件事!!!
所以,我们这次直接在巨人的肩膀上造车就行啦。
第一步,引入jar包依赖
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-ollama-spring-boot-starter</artifactId>
<version>1.0.0-M3</version>
</dependency>
因为这个jar包Spring只发布了在快照仓库,所以我们要配置maven仓库,那么完整的pom文件如下:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>3.3.4</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<groupId>com.masiyi</groupId>
<artifactId>spring-ai-ollama</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>spring-ai-ollama</name>
<description>spring-ai-ollama</description>
<url/>
<licenses>
<license/>
</licenses>
<developers>
<developer/>
</developers>
<scm>
<connection/>
<developerConnection/>
<tag/>
<url/>
</scm>
<properties>
<java.version>23</java.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-ollama-spring-boot-starter</artifactId>
<version>1.0.0-M3</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
<repositories>
<repository>
<id>spring-milestones</id>
<name>Spring Milestones</name>
<url>https://repo.spring.io/milestone</url>
<snapshots>
<enabled>false</enabled>
</snapshots>
</repository>
<repository>
<id>spring-snapshots</id>
<name>Spring Snapshots</name>
<url>https://repo.spring.io/snapshot</url>
<releases>
<enabled>false</enabled>
</releases>
</repository>
</repositories>
</project>
第二步,使用OllamaChatModel
大家翻一翻源码就知道,在我们引入的jar包中,Spring有写了一个 OllamaAutoConfiguration类,而我们再去看一下,里面定义了一个 OllamaChatModel类,而这个类就是Spring封装好的一些调用Ollama的api的一些方法的工具类。
所以我们直接在controller里面依赖他
@Autowired
private OllamaChatModel ollamaChatModel;
第三步,编写测试方法
@GetMapping("/ollama")
public Object ollamaCall(@RequestParam(value = "msg") String msg){
return ollamaChatModel.call(new Prompt(msg));
}
我们直接调用在一个controller类里面写一个最简单的方法调用他看一下
第四步,编写配置文件
我们在我们的properties配置文件中配置好我们要调用的模型:
spring.ai.ollama.chat.model=llama3.2
如果看过之前作者写的那篇Ollama文章的话就知道,这个参数的作用就是我们调用RestApi时候Body体Json内容里面指定的模型 "model": "llama3.2"
第五步,启动,测试
@RestController
@RequestMapping("/ai")
public class OllamaController {
@Autowired
private OllamaChatModel ollamaChatModel;
@GetMapping("/ollama")
public Object ollamaCall(@RequestParam(value = "msg") String msg){
return ollamaChatModel.call(new Prompt(msg));
}
}
我启动之后调用一下我们本地的接口试一下
可以看到,除了时间久了一点完全没有问题
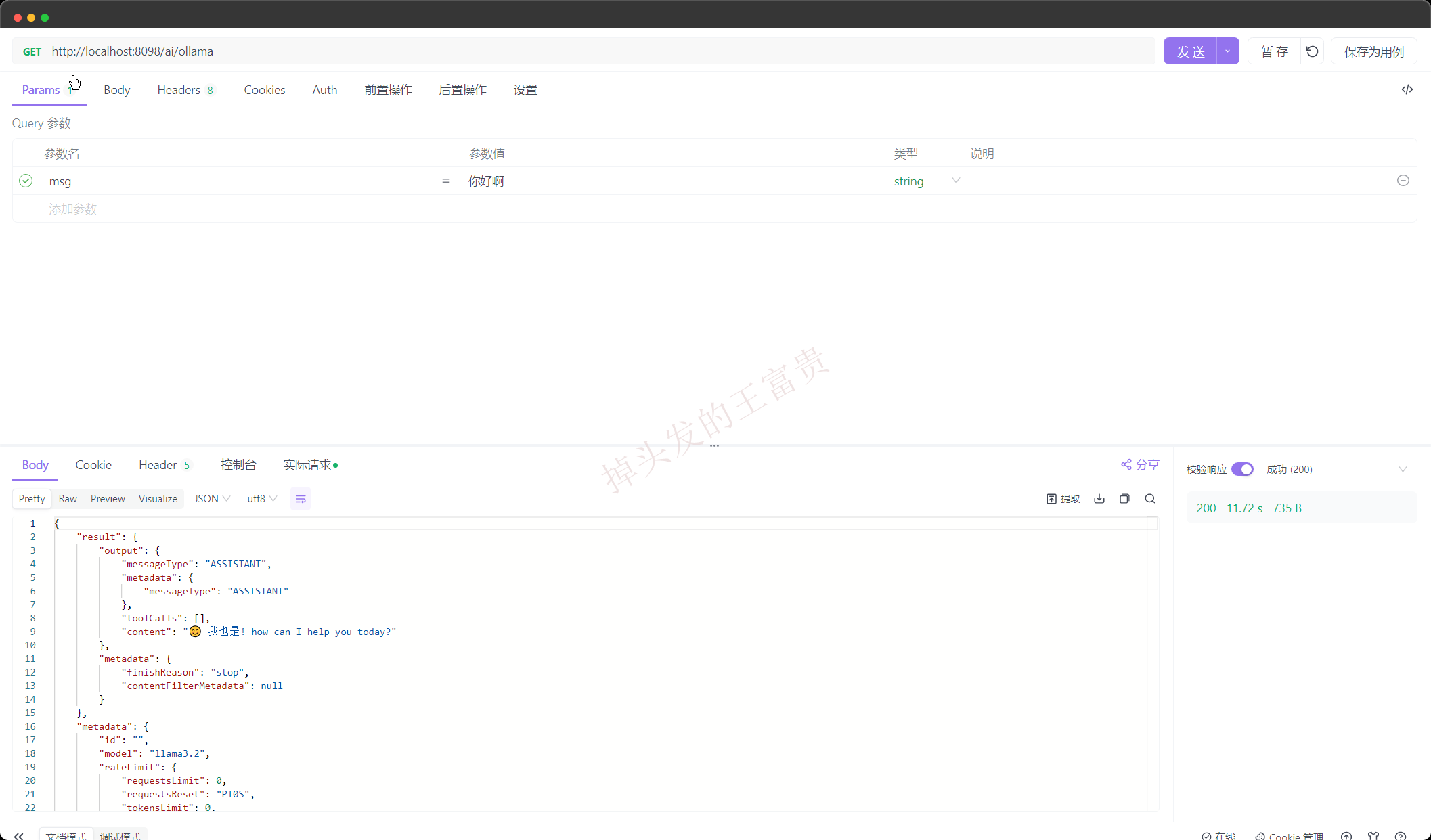
吐字功能
上面的是一个最基础的demo,那么我们之前说的,吐字是怎么来的呢?没看过之前作者写的吐字的那篇文章的可以移步去补习一下: 在ChatGPT中,吐字那么酷炫的效果到底是怎么实现的?
没错,你能想到的OllamaChatModel也想到了,我们根据我们之前学过的吐字加上 OllamaChatModel里面封装好的方法,我们就得到了这样的一个方法:
@PostMapping(value = "/ollama-stream", produces = "text/event-stream; charset=utf-8")
public Flux<ServerSentEvent> ollamaStream(@RequestParam(value = "msg") String msg){
return ollamaChatModel.stream(new Prompt(msg)).map(
message -> ServerSentEvent.builder().id("111").event("message").data(message.getResult().getOutput().getContent()).build()
);
}
我们调用它看看效果怎么样
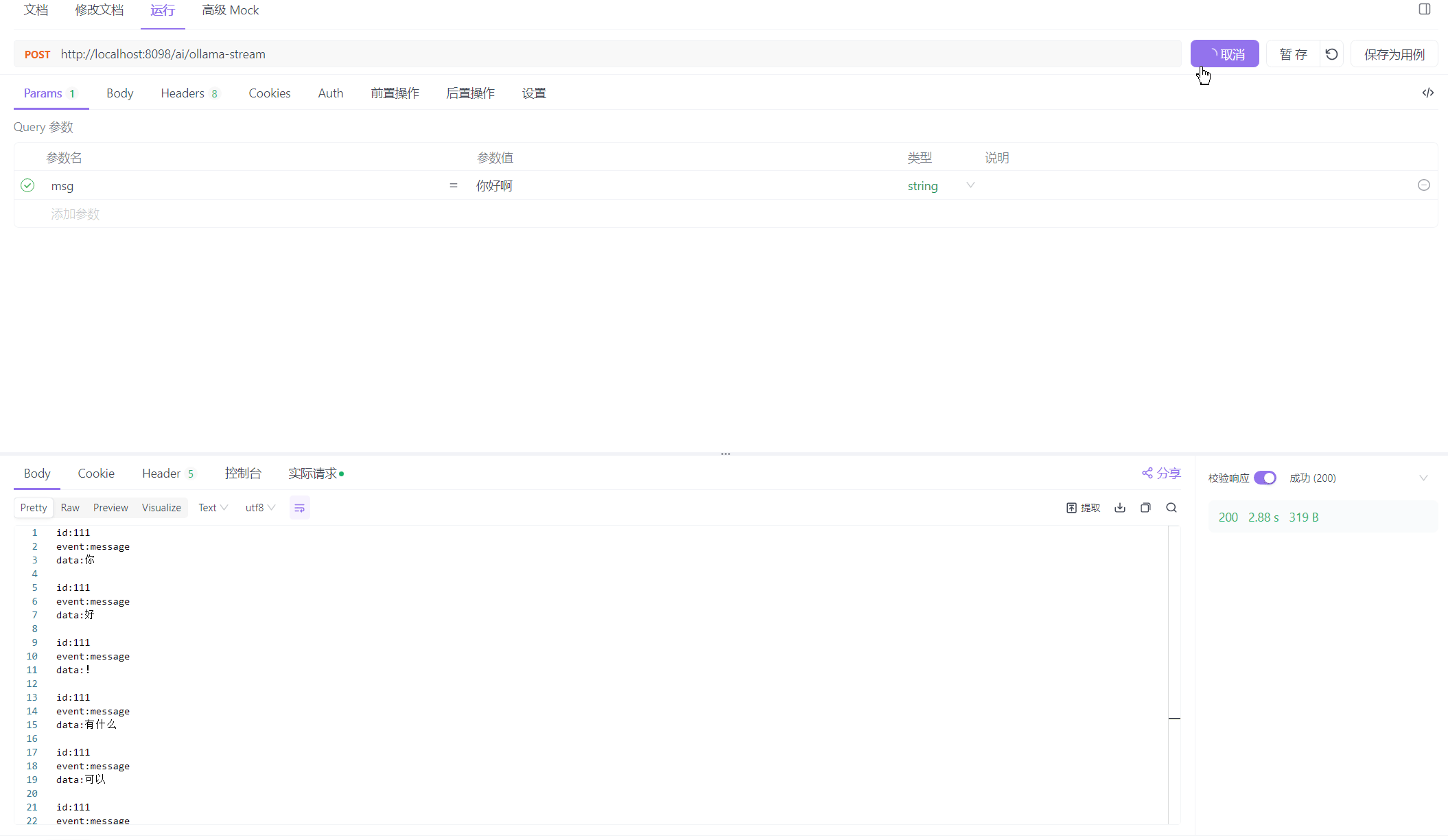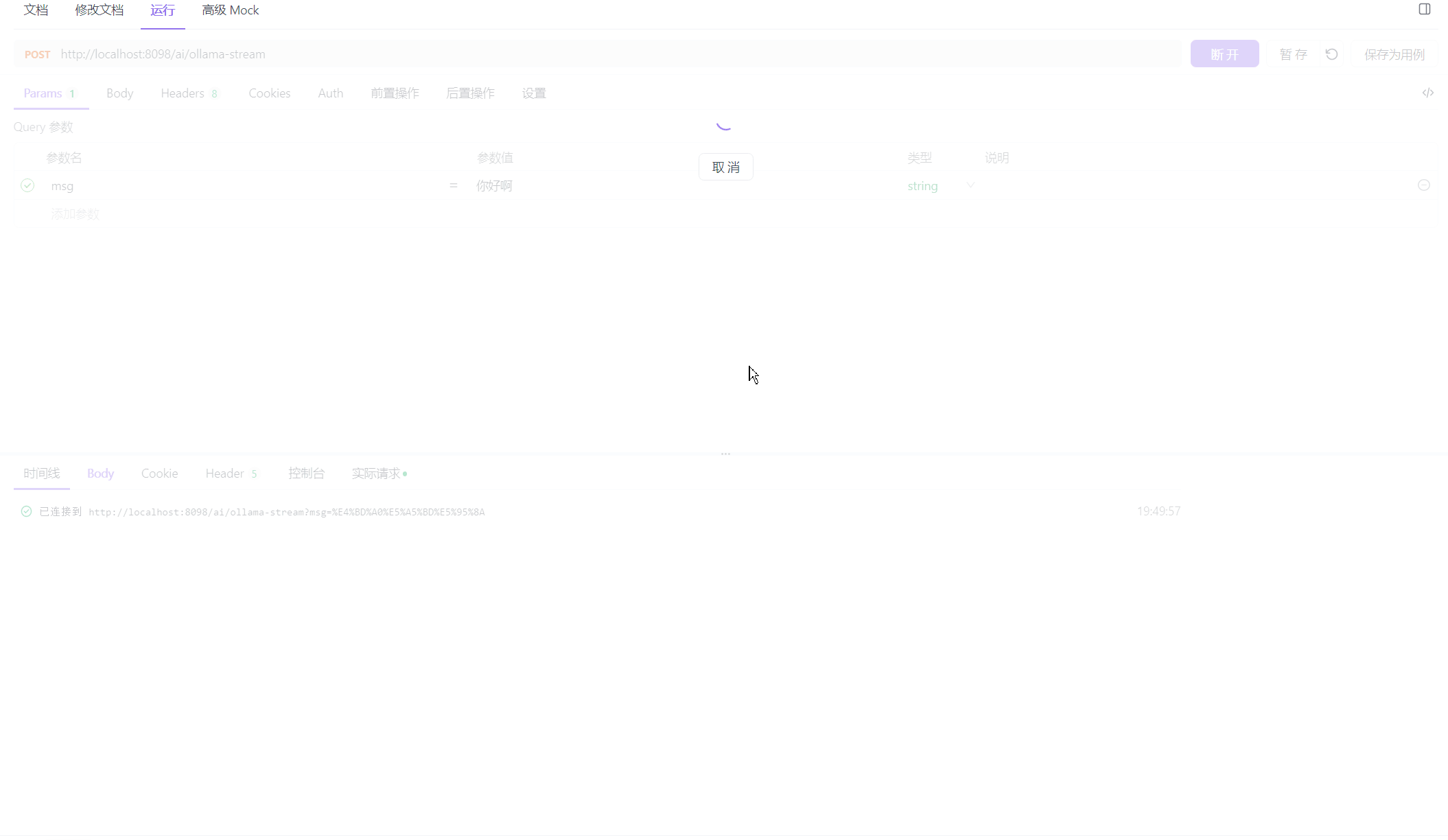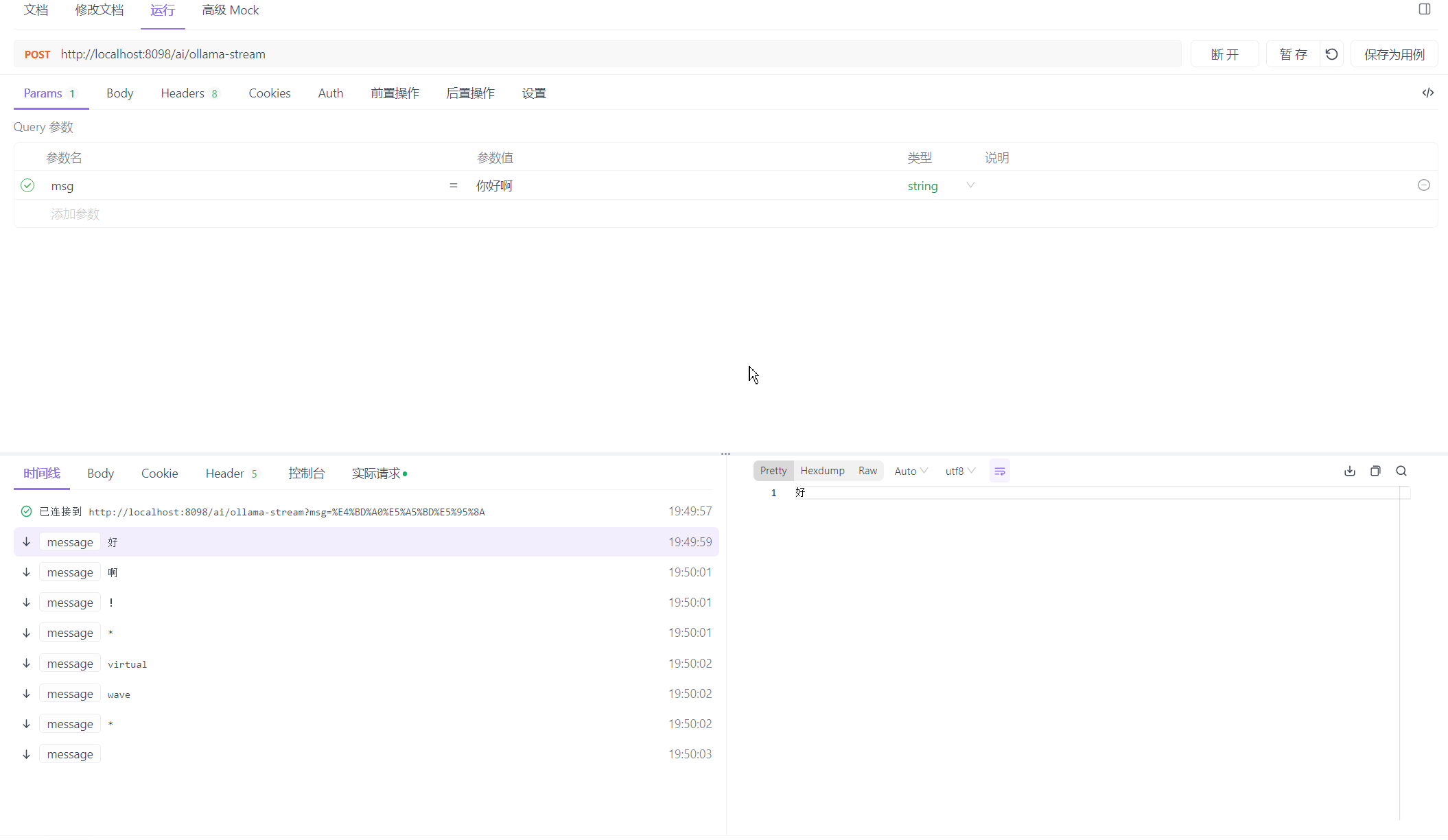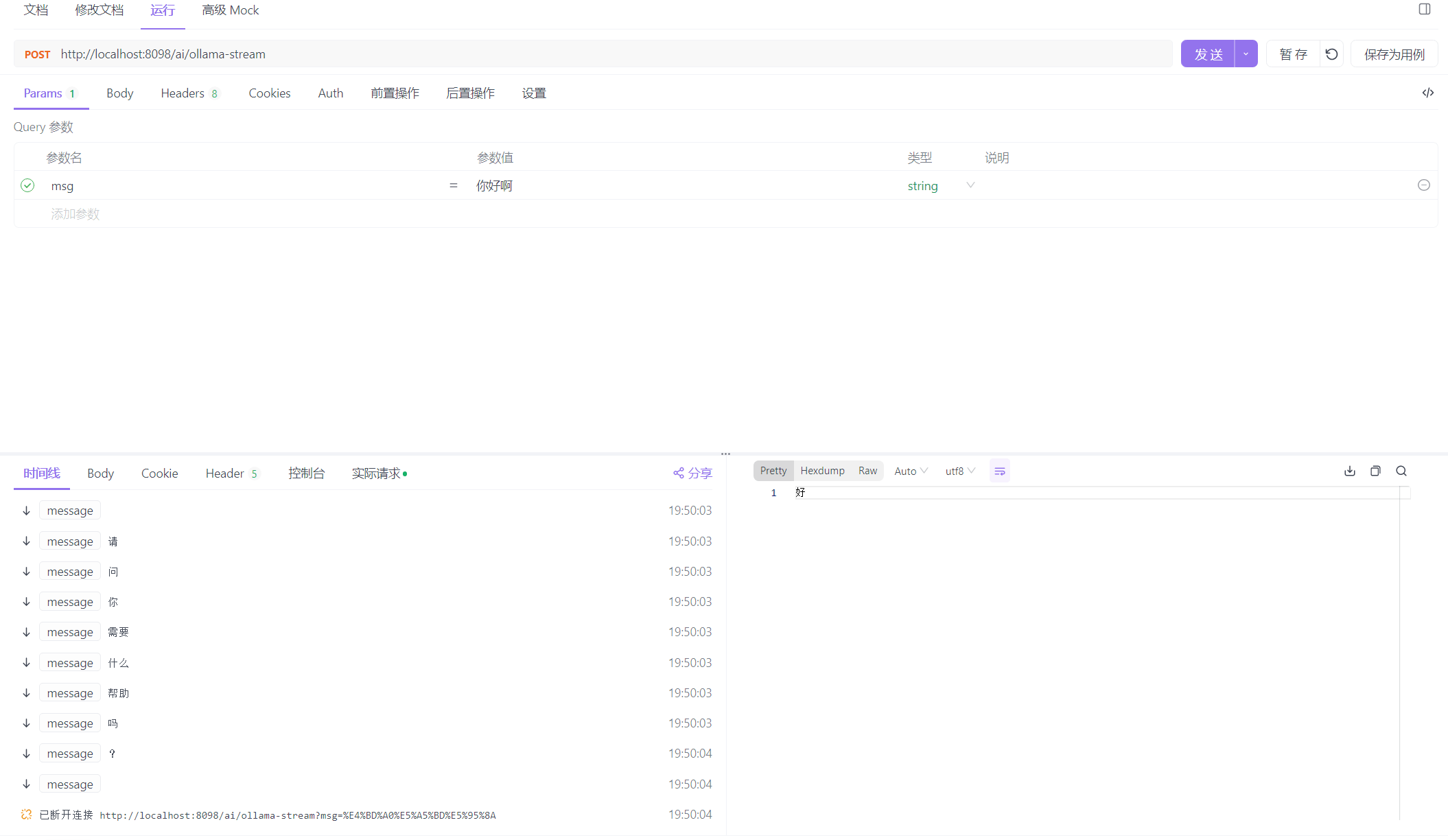
可以看到的是,完全符合我们吐字的要求!!!
上下文功能
大家要知道的是之所以gpt能够理解我们之前说过的话,核心之一的就是 上下文。那么作者之前也给大家演示了如何在RestApi中携带上下文:
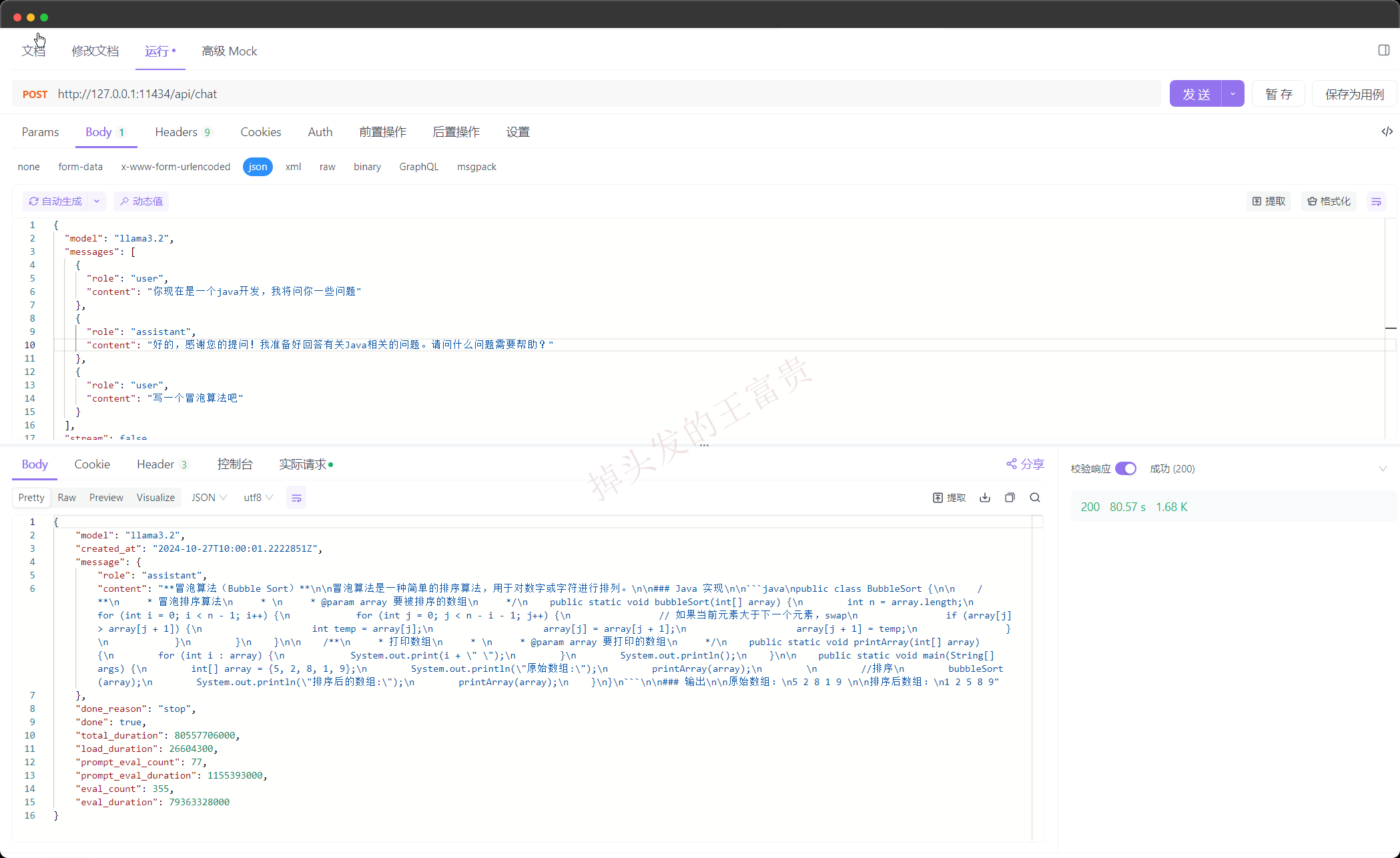
接口:
@PostMapping("/chat")
public String ollamaChat(@RequestBody List<AigcMessage> aigcMessages){
ArrayList<Message> messages = new ArrayList<>();
for (AigcMessage aigcMessage : aigcMessages) {
if ("user".equals(aigcMessage.role())) {
messages.add(new UserMessage(aigcMessage.content()));
} else if ("assistant".equals(aigcMessage.role())) {
messages.add(new AssistantMessage(aigcMessage.content()));
}
}
return ollamaChatModel.call(new Prompt(messages)).getResult().getOutput().getContent();
}
这地方我们用 AigcMessage类去包装前端发送的用户和gpt的角色和内容:
package com.masiyi.springaiollama.controller.dto;
public record AigcMessage(String role,
String content) {
}
这个时候我们的接口就可以这么传参了:通过assistant(gpt回答)和user的role去区分角色,然后传给大模型,这就是我们的上下文。
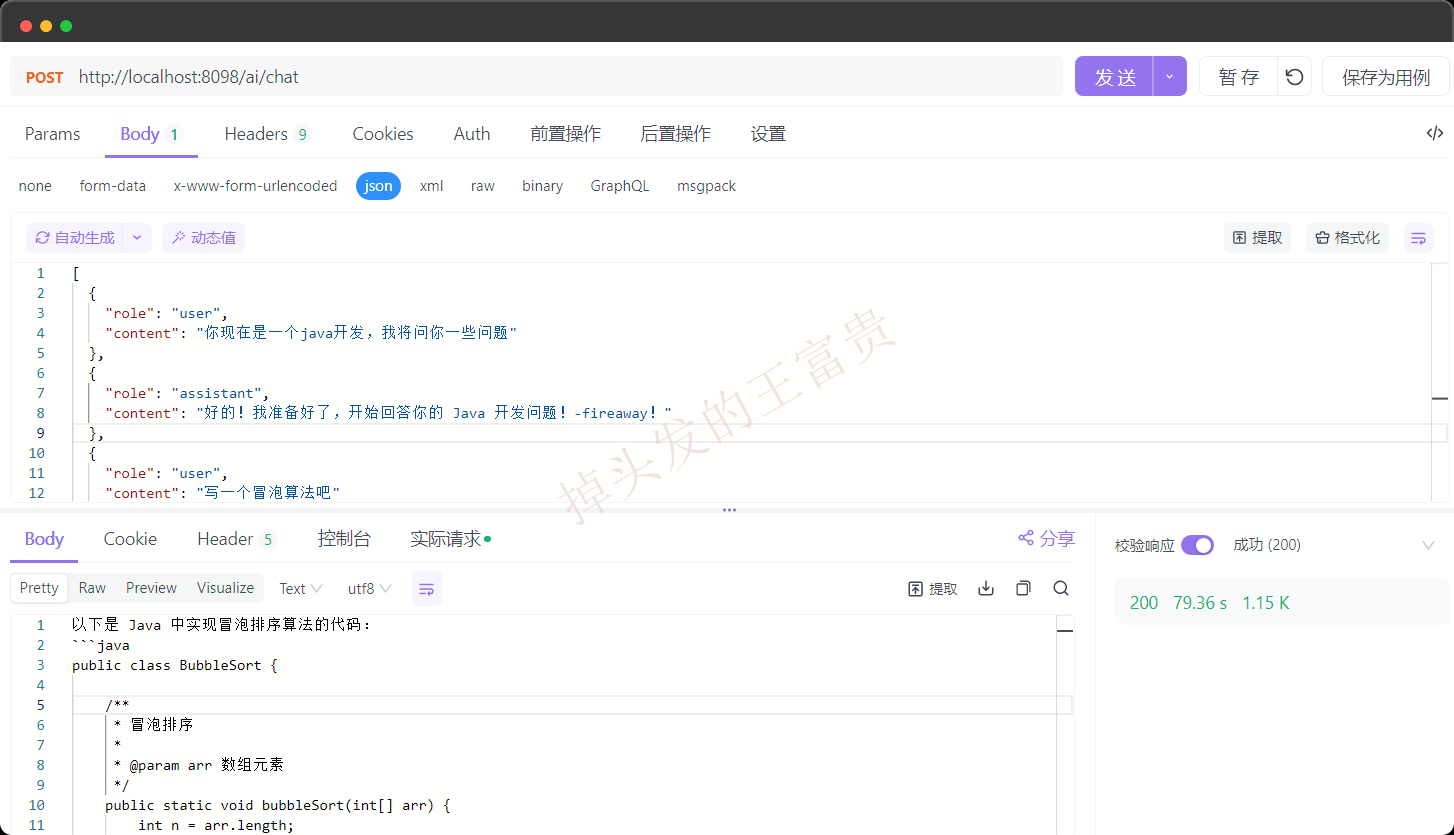
既然后端已经支持了,那么前端就需要每次把我们的回答和系统的回答再发送过来就行了。
上下文吐字
加上我们之前的吐字能力和上下文的能力,我们直接把他结合起来就成这样了:
@PostMapping(value = "/chat-stream", produces = "text/event-stream; charset=utf-8")
public Flux<ServerSentEvent> ollamaStream(@RequestBody List<AigcMessage> aigcMessages) {
ArrayList<Message> messages = new ArrayList<>();
for (AigcMessage aigcMessage : aigcMessages) {
if ("user".equals(aigcMessage.role())) {
messages.add(new UserMessage(aigcMessage.content()));
} else if ("assistant".equals(aigcMessage.role())) {
messages.add(new AssistantMessage(aigcMessage.content()));
}
}
return ollamaChatModel.stream(new Prompt(messages)).map(
message -> {
String content = message.getResult().getOutput().getContent()
.replace("\n", "\\n") // 保留换行符
.replace(" ", " "); // 保留空格
return ServerSentEvent.builder()
.id("222")
.event("message")
.data(content)
.build();
}
);
}
我们来看一下效果:
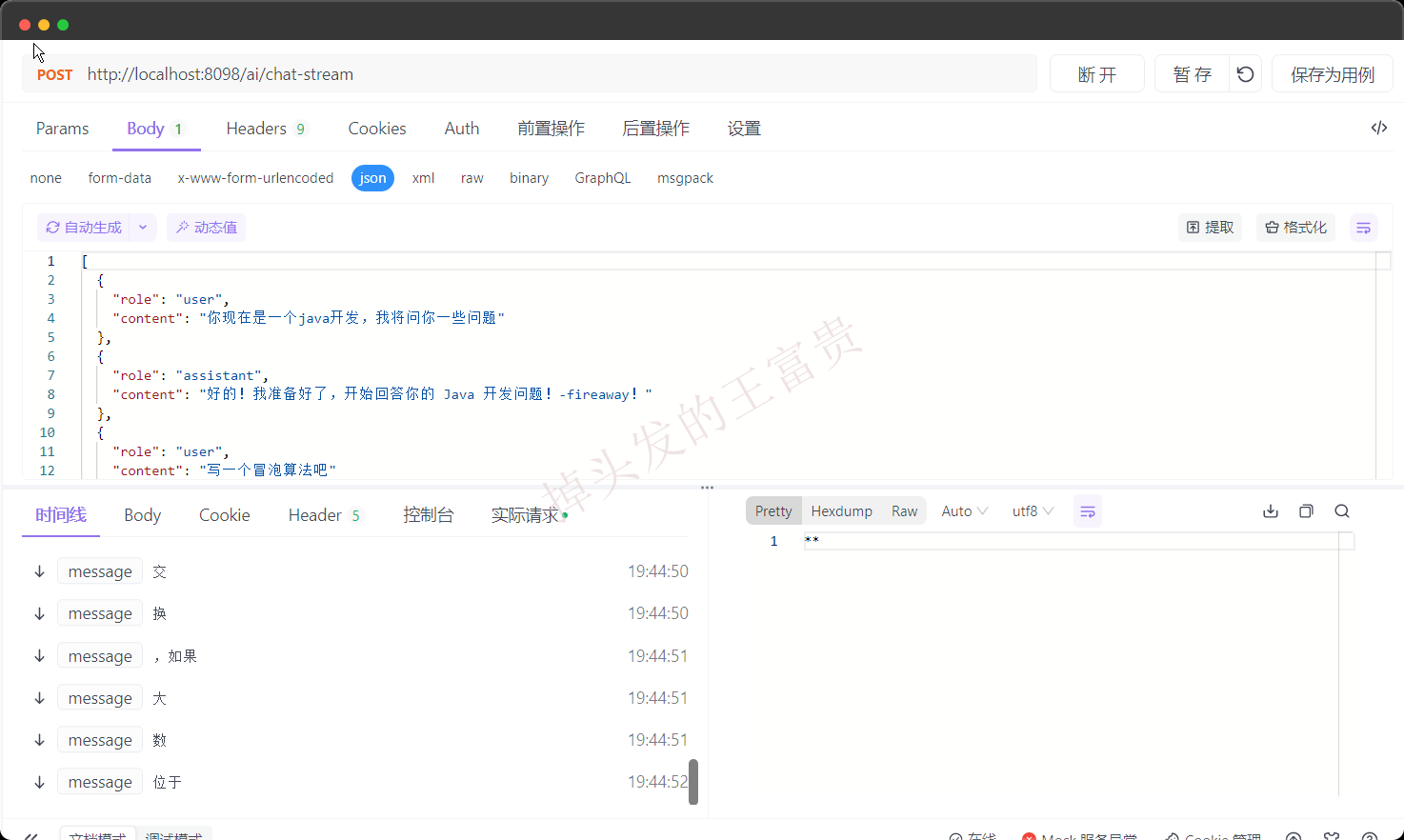
写个前端
写个前端来更直观得看到效果
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Chat Interface with Streaming & Context</title>
<style>
body {
font-family: Arial, sans-serif;
max-width: 600px;
margin: auto;
padding: 10px;
}
#chatBox {
border: 1px solid #ccc;
padding: 10px;
height: 400px;
overflow-y: scroll;
margin-bottom: 10px;
}
.message {
padding: 5px;
border-radius: 5px;
margin-bottom: 5px;
white-space: pre-wrap; /* 保留换行 */
}
.user {
background-color: #e0f7fa;
text-align: right;
}
.assistant {
background-color: #e8f5e9;
}
#userInput {
width: 100%;
padding: 10px;
font-size: 16px;
}
</style>
</head>
<body>
<h1>Chat Interface with Streaming & Context</h1>
<div id="chatBox"></div>
<input type="text" id="userInput" placeholder="Type a message..." onkeydown="if(event.key === 'Enter') sendMessage()">
<script>
let conversationHistory = [];
function displayMessage(role, content) {
const chatBox = document.getElementById('chatBox');
const messageDiv = document.createElement('div');
messageDiv.className = `message ${role}`;
const formattedContent = content.replace(/\\n/g, '<br>'); // 解析 \n 为 <br>
messageDiv.innerHTML = formattedContent; // 使用 innerHTML 显示换行格式内容
chatBox.appendChild(messageDiv);
chatBox.scrollTop = chatBox.scrollHeight;
return messageDiv;
}
function sendMessage() {
const userInput = document.getElementById('userInput');
const messageContent = userInput.value.trim();
if (!messageContent) return;
displayMessage('user', messageContent);
userInput.value = '';
conversationHistory.push({ role: 'user', content: messageContent });
startSSE(conversationHistory);
}
function startSSE(messages) {
const url = 'http://localhost:8098/ai/chat-stream';
fetch(url, {
method: 'POST',
headers: {
'Content-Type': 'application/json',
'Accept': 'text/event-stream'
},
body: JSON.stringify(messages)
}).then(response => {
if (!response.ok) {
throw new Error('Network response was not ok');
}
const reader = response.body.getReader();
const decoder = new TextDecoder();
let buffer = '';
let assistantMessageDiv = displayMessage('assistant', ''); // 空元素用于后续更新
let accumulatedData = '';
return new ReadableStream({
start(controller) {
function read() {
reader.read().then(({ done, value }) => {
if (done) {
controller.close();
conversationHistory.push({ role: 'assistant', content: accumulatedData });
return;
}
buffer += decoder.decode(value, { stream: true });
const eventBlocks = buffer.split("\n\n");
buffer = eventBlocks.pop();
eventBlocks.forEach(eventBlock => {
const lines = eventBlock.split("\n");
let eventData = { data: '' };
lines.forEach(line => {
if (line.startsWith("data:")) {
eventData.data += line.substring(5);
}
});
if (eventData.data) {
accumulatedData += eventData.data.replace(/\\n/g, '\n');
assistantMessageDiv.innerHTML = accumulatedData;
document.getElementById('chatBox').scrollTop = document.getElementById('chatBox').scrollHeight;
}
});
read();
});
}
read();
}
});
}).catch(error => {
console.error('Fetch error:', error);
displayMessage('assistant', 'Error: Unable to fetch response');
});
}
</script>
</body>
</html>
我们直接来看一下效果!!
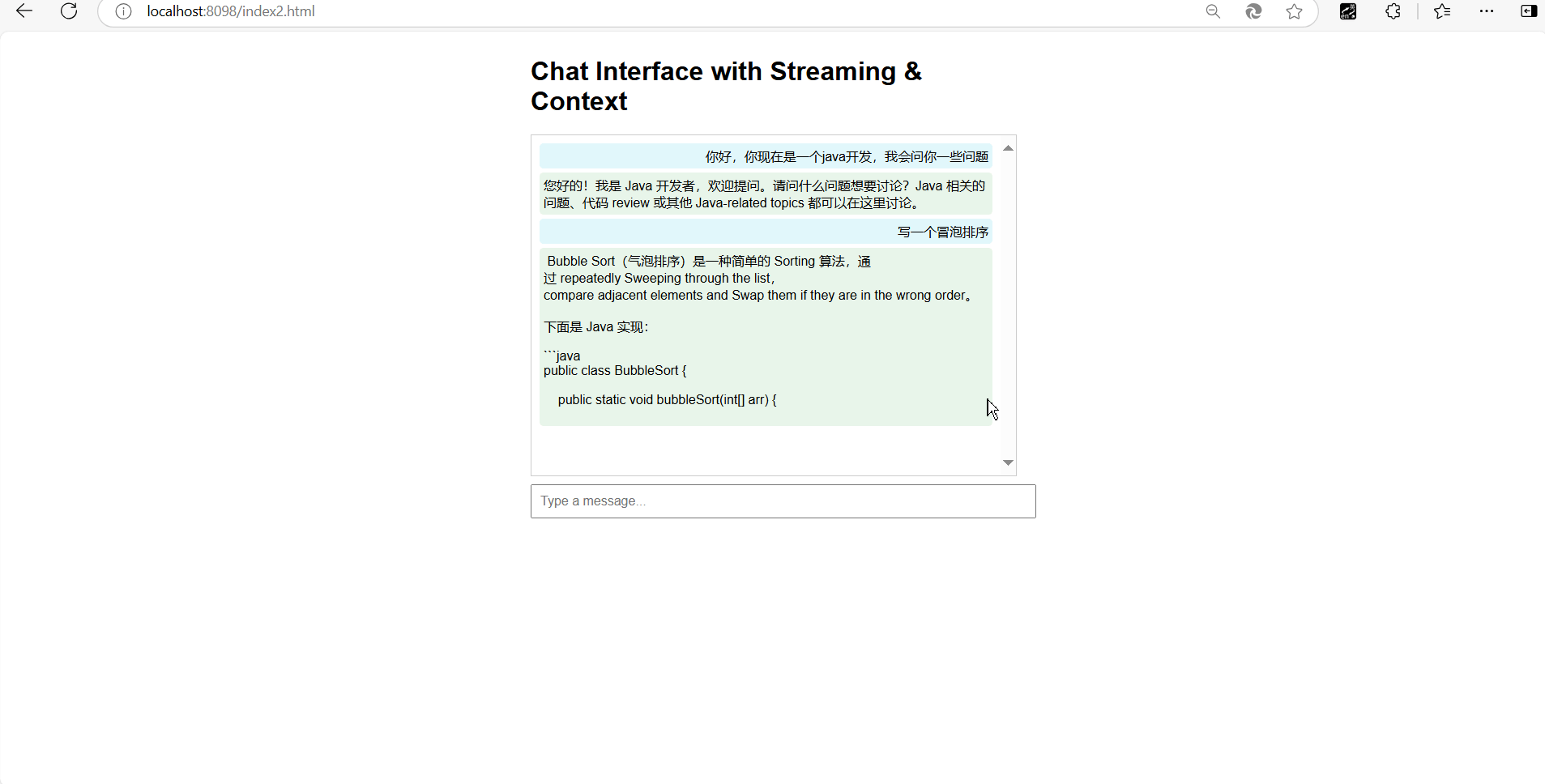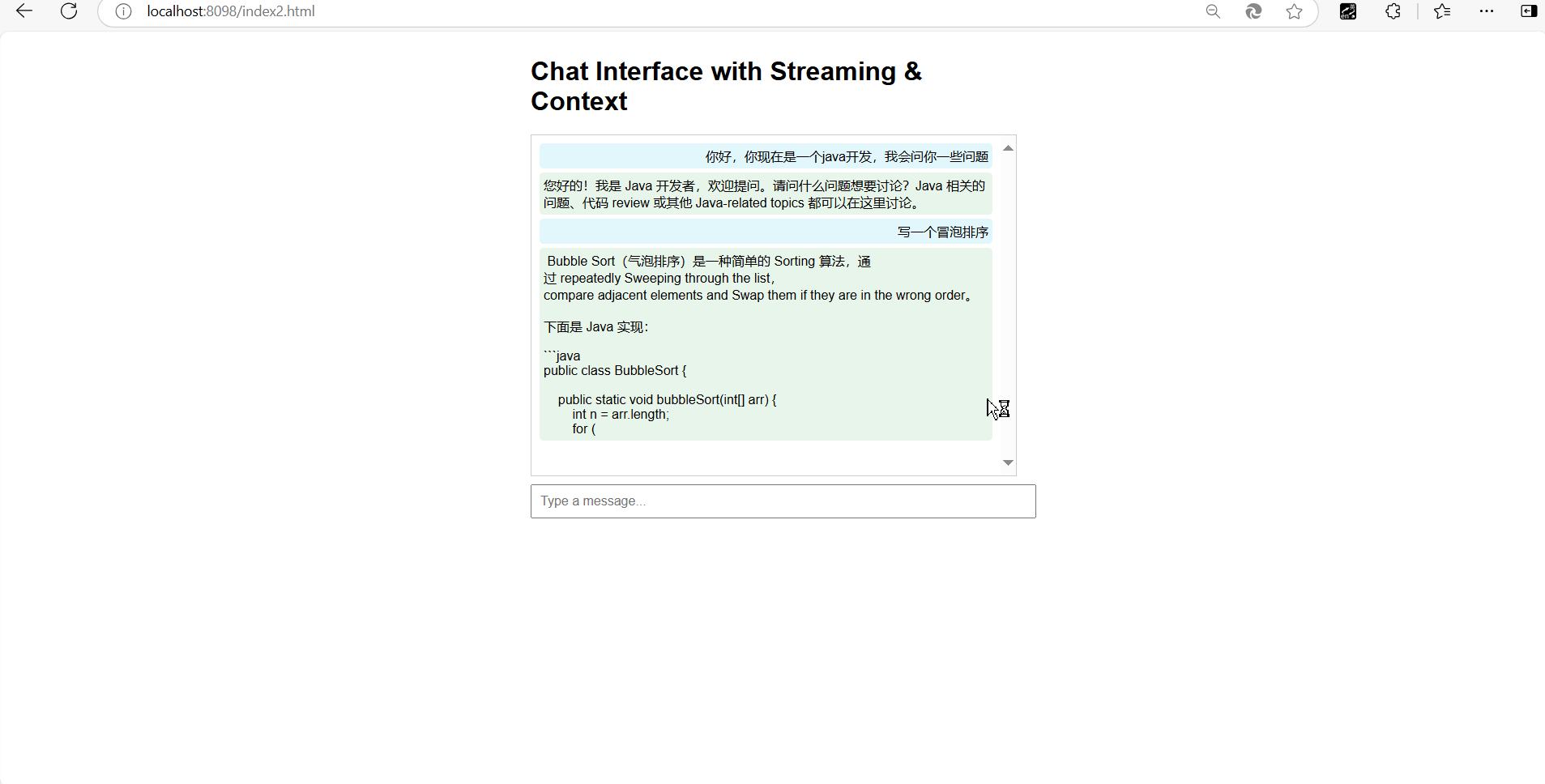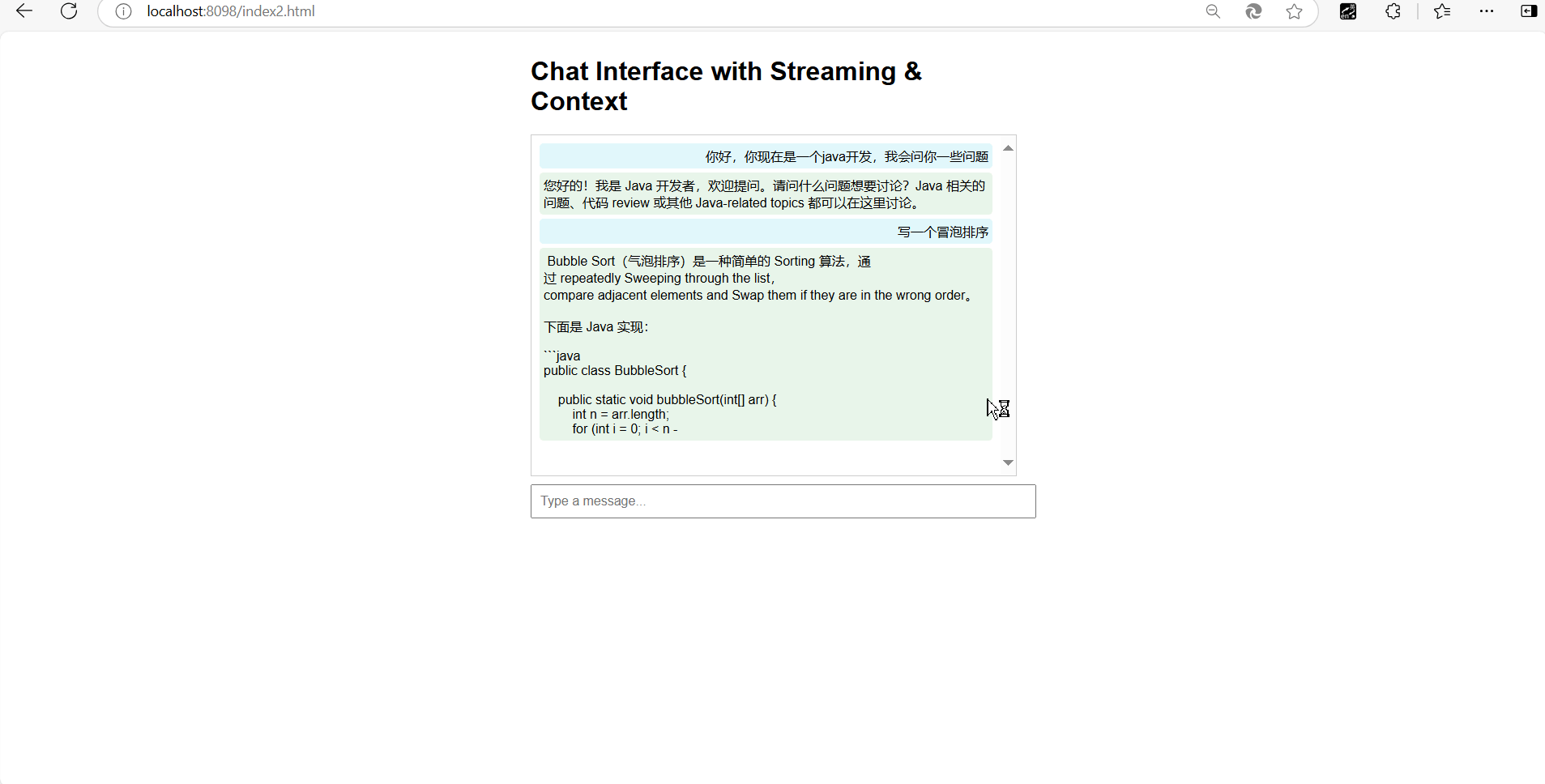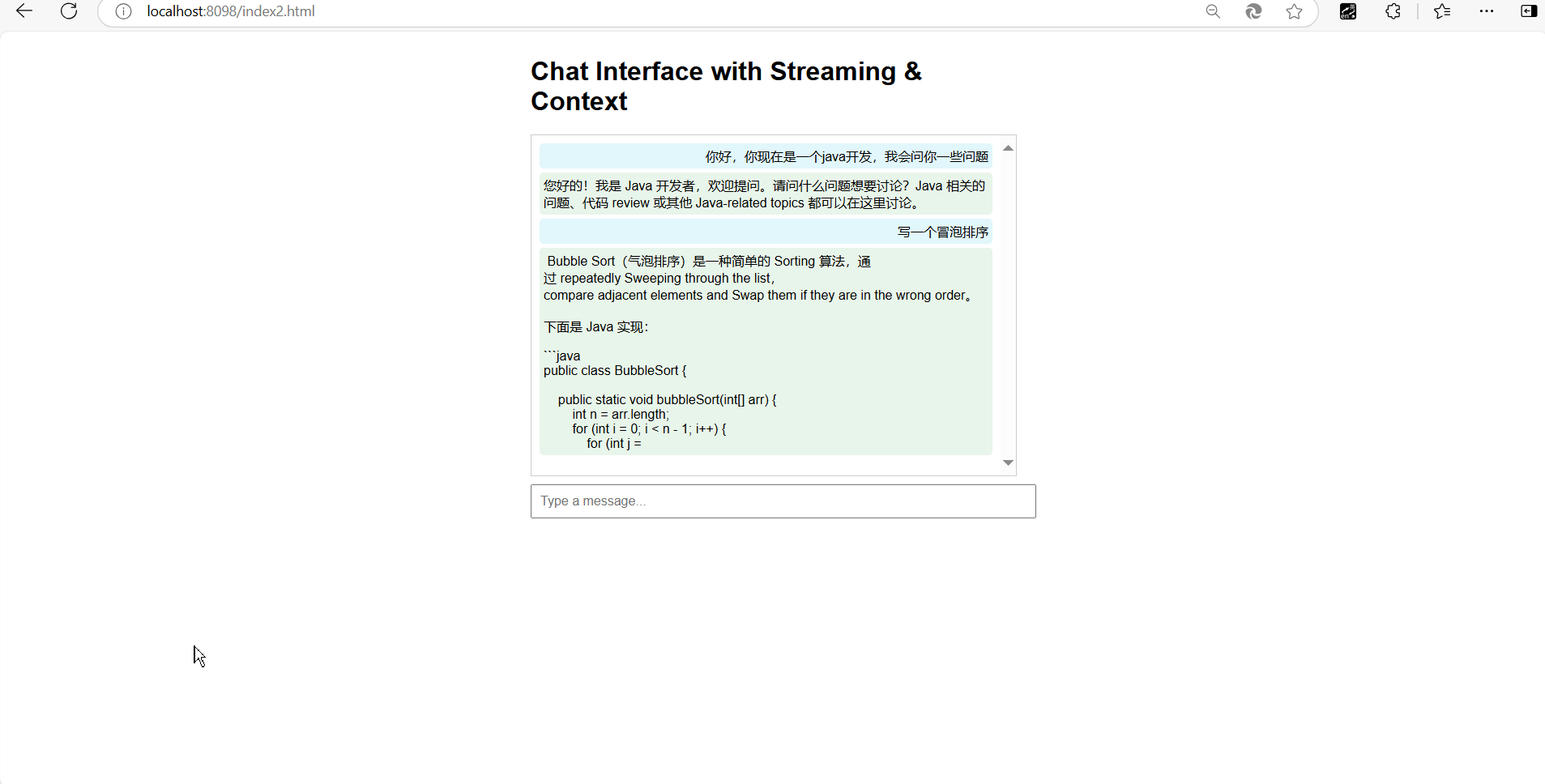
简直完美!!!
我们可以看到我们的接口是没问题的
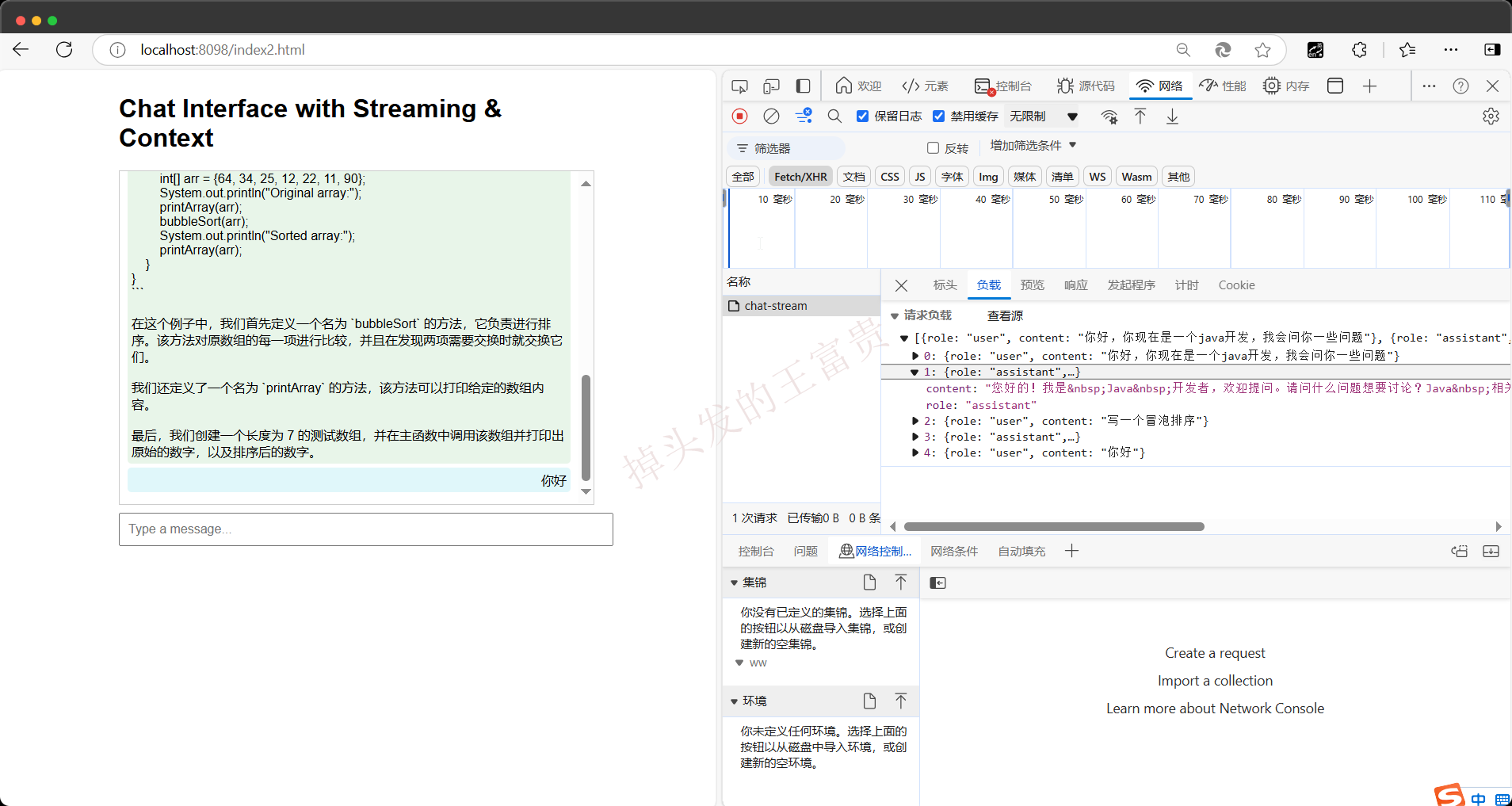
至此,我们的SpringBoot集成Ollama,成功把本地模型通过java后端暴露出来了,意味着我们只要有机器,就可以对外暴露我们的接口,而且可以无限次调用!!!那么还有一些更进阶的操作,欢迎关注博主和这篇专栏,让我们一起探索AIGC的世界吧!!
那么这篇博客对应的项目地址博主也开源了,欢迎大家去玩玩
https://gitee.com/wangfugui-ma/spring-boot-ollama.git




















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











