



 本文详细介绍了Spring框架内核中的ReactorFlux组件,它如何支持反应式编程,以及在处理大量异步请求和事件驱动场景中的应用。作者通过实例展示了如何使用Flux进行数据流操作,如创建、过滤、映射等,以及与BlockingQueue的对比。
本文详细介绍了Spring框架内核中的ReactorFlux组件,它如何支持反应式编程,以及在处理大量异步请求和事件驱动场景中的应用。作者通过实例展示了如何使用Flux进行数据流操作,如创建、过滤、映射等,以及与BlockingQueue的对比。
Reactor Flux乃是Spring Framework内核架构中的一大重要组件,其主要功能在于实现反应式编程理念。在Reactor的世界观里,Flux担当着描述0至无限个任意元素组成序列的重任,不但如此,它还为同步及基于事件驱动的数据流提供全方位的支持与服务。Flux提供了多元化的操作及其相应的方法,其作用包括对数据流进行漫游、精炼、整合以及更多其他可能的操作,从而满足实现反应式编程特性的各种需求。
反应式编程,这是一种独特的编程范式,主要面向那些需要处理复杂多样的异步数据流和事件的场合。从根本上看,其设计思想都集中于揭示这样一个事实:即数据流的任何变化都会引发所有依附于此数据流的操作生效,进而演变为一种异常高效的事件驱动型程序编写方式。为助开发者更轻松地应对此类异步操作、事件处理以及数据流处理,反应式编程特别引入了诸如观察者模式、流动类型编程以及函数式编程等关键概念。
针对上述专业词汇的示好,我们不妨试着用通俗易懂的话语将其解释为:假如你在处理某个项目时遇到了涉及到异步操作且需用到队列的情境,那么请毫不犹豫地考虑使用Reactor Flux来完成这项任务。记得之前写过一篇文章:老板让我做一个缓存机制,我选择了Java自带的BlockingQueue。其实Reactor Flux与其颇具相似之处,然其技术性和高级性远胜于BlockingQueue。接下来便让我们共同探寻奇妙之旅吧!
例如说我现在有一个业务,每次有一个用户请求进来,我们后台要马上返回信息给前端,这个时候大家想到的是不是就是启动一个异步线程去执行这个任务,但是大家有没有想过,如果某一个时间有大量的大量的请求进来。那么我们系统也会创建对应的异步线程。那么这个时候就有一个问题,我们系统的压力会非常的大。如果我们系统没有顶住,我们系统就会崩溃。这是一个非常致命的问题。
当然我们可以弄一个队列。在请求中异步把信息丢入队列中,然后启动一个线程。一直while true去取这个队列里面的信息,就像我上面那篇文章所说的。但是这样其实并不是很优雅。而且并没有很多定制化的东西。没有很多有趣的API。那么就回到了我们这篇文章的主题:那就试试Reactor Flux吧
第一步,我们需要引入他的jar包。
<dependencies>
<dependency>
<groupId>io.projectreactor</groupId>
<artifactId>reactor-core</artifactId>
<version>3.3.10.RELEASE</version>
</dependency>
</dependencies>
如果你是springboot的项目的话,springboot已经默认集成过了,只需要我们把它导入进来就行。
第二步,新建一个FluxTestEntity 类
package com.masiyi.reactordemo;
/**
* @Author:掉头发的王富贵
* @Package:com.masiyi.reactordemo
* @Project:reactor-demo
* @name:FluxTestEntity
* @Date:2024/3/11 22:03
* 作用:
*/
public class FluxTestEntity {
private String name;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public FluxTestEntity(String name) {
this.name = name;
}
public FluxTestEntity() {
}
@Override
public String toString() {
return "FluxTestEntity{" +
"name='" + name + '\'' +
'}';
}
}
我们可以用这个类来模拟每次用户请求的body
第三步,创建一个FluxTestService类
package com.masiyi.reactordemo;
import org.springframework.stereotype.Service;
import reactor.core.publisher.Flux;
import reactor.core.publisher.FluxSink;
import java.time.Duration;
import java.util.Date;
/**
* @Author:掉头发的王富贵
* @Package:com.masiyi.reactordemo
* @Project:reactor-demo
* @name:FluxTestService
* @Date:2024/3/11 22:03
* 作用:
*/
@Service
public class FluxTestService {
private static volatile FluxSink<FluxTestEntity> logSink;
}
其中这里面我们加一个属性, FluxSink<FluxTestEntity> logSink
FluxSink是Reactor中的一个接口,用于向Flux数据流中发送元素、错误或完成信号。它允许我们在代码中手动控制数据流的生成,而不是被动地接收来自外部的数据。
第四步,模拟用户发送接口
package com.masiyi.reactordemo;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
@SpringBootTest
class ReactorDemoApplicationTests {
@Autowired
private FluxTestService fluxTestService;
@Test
void contextLoads() {
for (int i = 0; i < 10; i++) {
FluxTestEntity fluxTestEntity = new FluxTestEntity();
fluxTestEntity.setName("掉头发的王富贵");
fluxTestService.saveEntity(fluxTestEntity);
}
}
}
这个里面我们的作用是利用for循环,实现循环十次去保存我们的用户请求。我们的saveEntity方法长这样:
public void saveEntity(FluxTestEntity entity) {
if (logSink == null) {
initImportSink();
}
//添加到队列中
logSink.next(entity);
}
首先检查logSink是否已经初始化。如果logSink尚未初始化(即为null),则调用initImportSink()方法来初始化logSink,以确保数据流的正确创建和使用。这种写法可以避免在每次调用saveEntity()方法时都进行初始化操作,提高了代码的效率和性能。通过延迟初始化logSink,只有在需要发送元素时才会进行初始化,避免了不必要的资源消耗。
另外,这种写法也符合懒加载(Lazy Loading)的思想,即在需要时才进行初始化,而不是提前初始化可能不会被使用的资源。
第五步,创建Flux流
private synchronized void initImportSink() {
if (logSink == null) {
Flux.<FluxTestEntity>create(fluxSink -> logSink = fluxSink)
//列队最大5, 超时时间10秒
.bufferTimeout(5, Duration.ofSeconds(10))
//订阅
.subscribe(entiys -> {
System.out.println(entiys);
});
}
}
即上面的initImportSink方法
这段代码定义了一个initImportSink()方法,用于初始化logSink,确保在需要时创建一个Flux数据流。让我们逐步解释这段代码的功能:
- Flux.create(fluxSink -> logSink = fluxSink):使用Flux.create()方法创建一个Flux数据流,并将其赋值给logSink,以便后续操作。
- bufferTimeout(5, Duration.ofSeconds(10)):设置数据流的缓冲区大小为5,超时时间为10秒。这意味着当数据流中的元素数量达到5个或者等待时间超过10秒时,会触发数据流的处理。
- subscribe(entities -> { System.out.println(entities); });:订阅数据流,并定义处理数据流中元素的逻辑。在这里,当数据流中有元素到达时,会打印这些元素。
例如上面的效果就是这的:
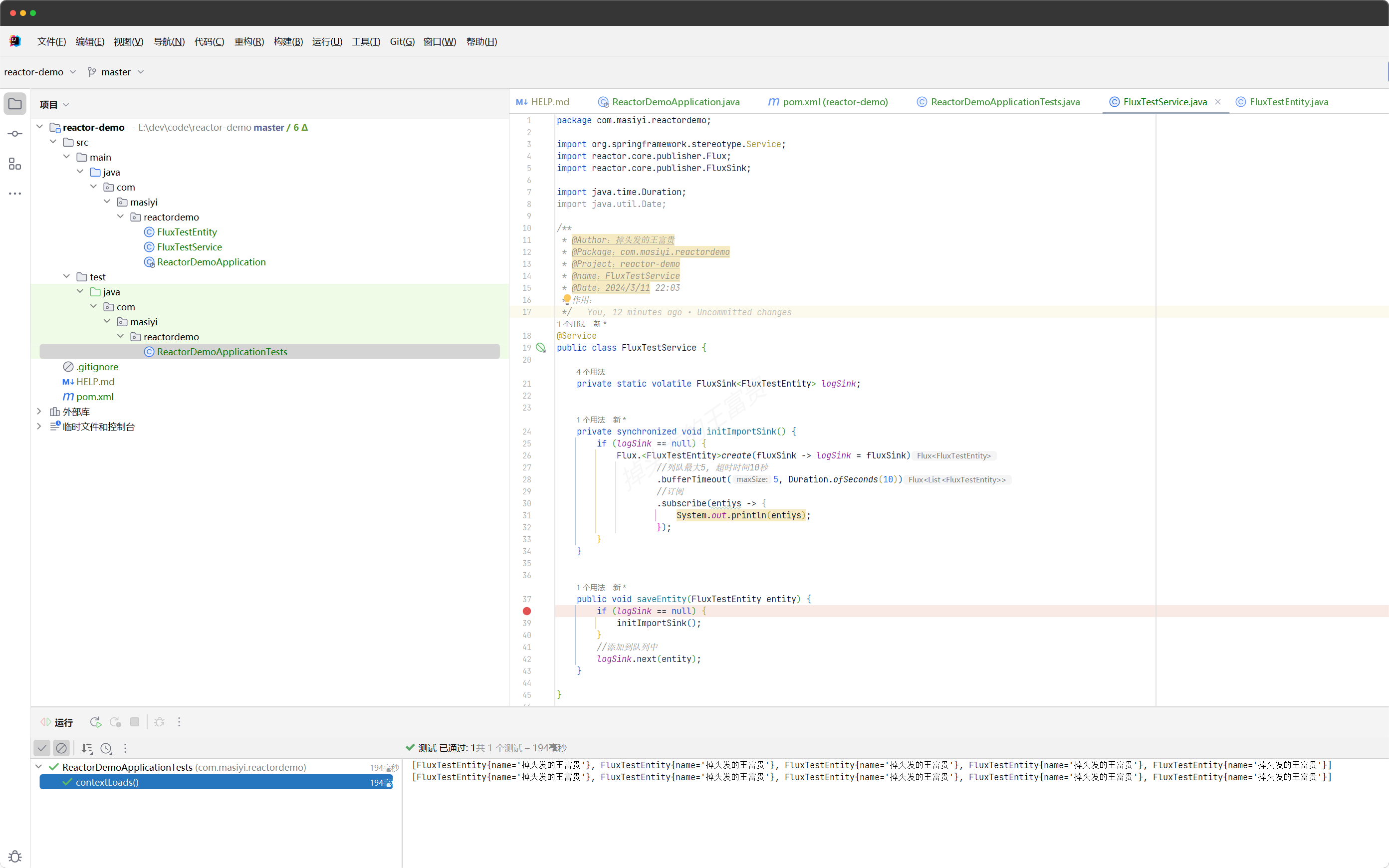
可以看到当我们的流中到达五条数据的时候,就会触发我们的打印,即subscribe方法里面的方法体,值得注意的是,这里可以用lambda表达式进行一个传值。lambda表达式传值的是一个list,它并不是一个单体的实体类。
由于我们刚刚是一瞬间就进入了他并没有到达十秒,即他并没有到达超时时间,所以我们说如果到达了超时时间的话会怎么样?
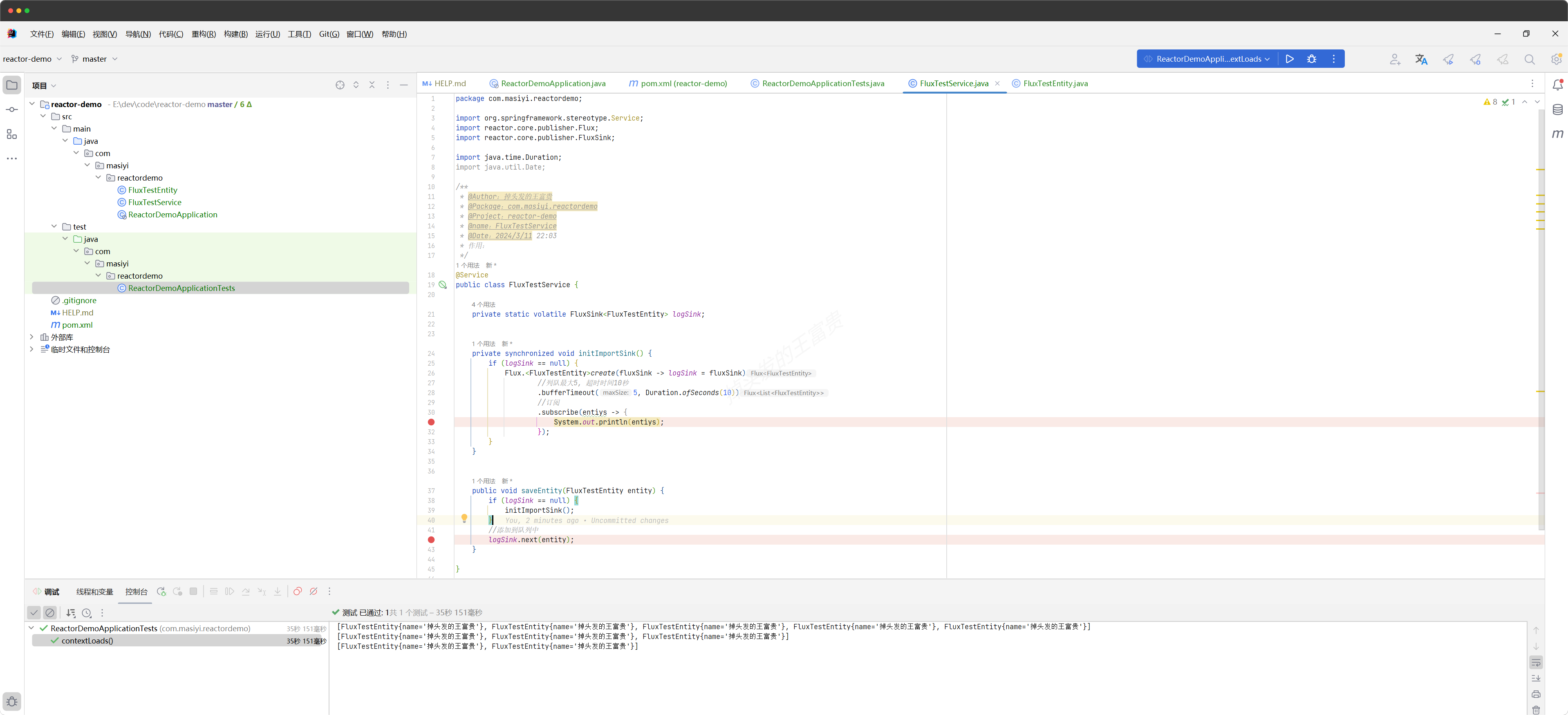
这里我们以debug的形式运行,让它卡住,这里就让它卡十秒钟以上。这个时候我们就会发现它并不单单把十条数据分割为两个数组。我们可以看到它的效果就是超过十秒,它就会自动触发订阅方法里面的消息体。然后进行一个输出。
这里我们可以看到他到达了超时时间之后会马上进行输出,并且如果下一步有数据插入它就会进入到下一个时间段去进行一个存储。也就是说上面有两个条件,他就会触发订阅方法里面的方法体,第一个是队列长度到达了五,第二个是超过了十秒。
其他的方法
private synchronized void initImportSink() {
if (logSink == null) {
Flux.<FluxTestEntity>create(fluxSink -> logSink = fluxSink)
.bufferTimeout(5, Duration.ofSeconds(10))
.filter(entity -> entity.getId() % 2 == 0) // 过滤偶数id的实体
.map(entity -> entity.getName().toUpperCase()) // 将实体名称转换为大写
.subscribe(entities -> {
System.out.println("Received batch of entities:");
entities.forEach(System.out::println);
});
}
}
当然Flux还有其他的方法,例如上面的还添加了filter和map操作符来进一步处理数据流。filter用于过滤偶数id的实体,map用于将实体名称转换为大写。
其他的方法类似:
- concatMap(Function):类似于flatMap,但保持元素的顺序。
- mergeWith(Publisher):将当前数据流与另一个数据流合并为一个新的数据流。
- zipWith(Publisher, BiFunction):将当前数据流与另一个数据流按照给定的函数进行组合。
- distinct():去除数据流中的重复元素。
- reduce(BiFunction):对数据流中的元素进行累积操作。
- skip(long):跳过数据流中的前n个元素。
- take(long):仅取数据流中的前n个元素。
- doOnNext(Consumer):在每个元素被处理前执行操作。
- doOnError(Consumer):在发生错误时执行操作。
- doOnComplete(Runnable):在数据流完成时执行操作。
- …
其实他是有点像java8里面的stream流的。Reactor Flux是一个强大的工具,用于处理异步数据流和事件,实现响应式编程的特性。通过灵活运用Flux的方法和操作符,可以处理各种数据流场景,例如我们公司就是用这个处理大量的异步队列的场景。




















 851
851

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











