



 本文介绍如何在正式环境中批量修改数据报表,并强调操作前备份的重要性。同时,讲解了跨库查询及使用CASE语句处理数据的方法。
本文介绍如何在正式环境中批量修改数据报表,并强调操作前备份的重要性。同时,讲解了跨库查询及使用CASE语句处理数据的方法。
大家好啊,又跟大家见面了,最近有个需求就是批量修改公司的数据报表,正式环境!!
而且要执行update!!
update it_xtgnyhcebg I set taskStatus = XXX
而且是没有加where条件的,相当于全表更新,这可马虎不得,我们在任何操作正式数据库之前一定一定要对数据库备份!!不要问我怎么知道的,因为我就因为有一次把测试环境的数据覆盖到正式环境去了,然后被公司扣钱了。。。

别到时候就后悔莫急,那是没有用的!


由于这个需求是需要在跨库操作的,所以我们在查询数据的时候需要带上库的名称,例如这样
SELECT
*
FROM
BPM00001.ACT_HI_PROCINST P
LEFT JOIN BPM00001.ACT_HI_VARINST V ON V.PROC_INST_ID_ = P.ID_
AND V.NAME_ = '__RESULE'
这样如果我们在任何一个库里面,只要在一个mysql服务里面都可以访问到这个数据
查出这个表之后
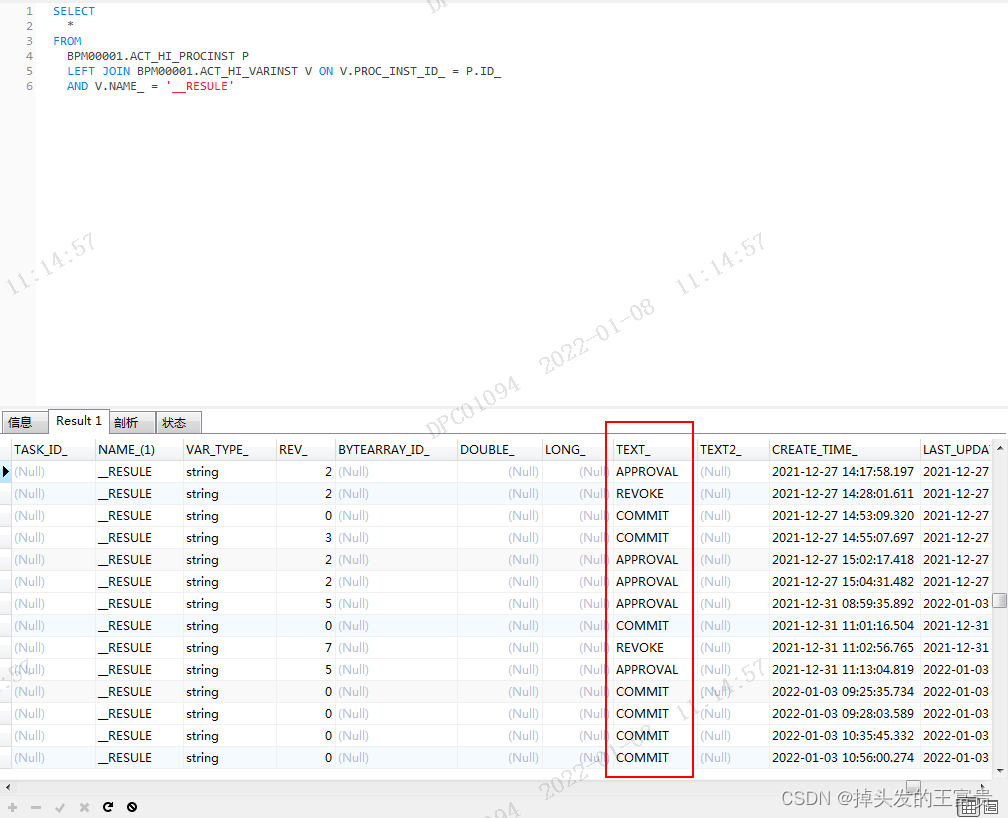
我们需要根据这里的内容显示出不同的东西
就例如说是“APPROVAL”我就显示“已通过”
这就类似与java中的Switch,其实sql也能实现这样的效果
如下:
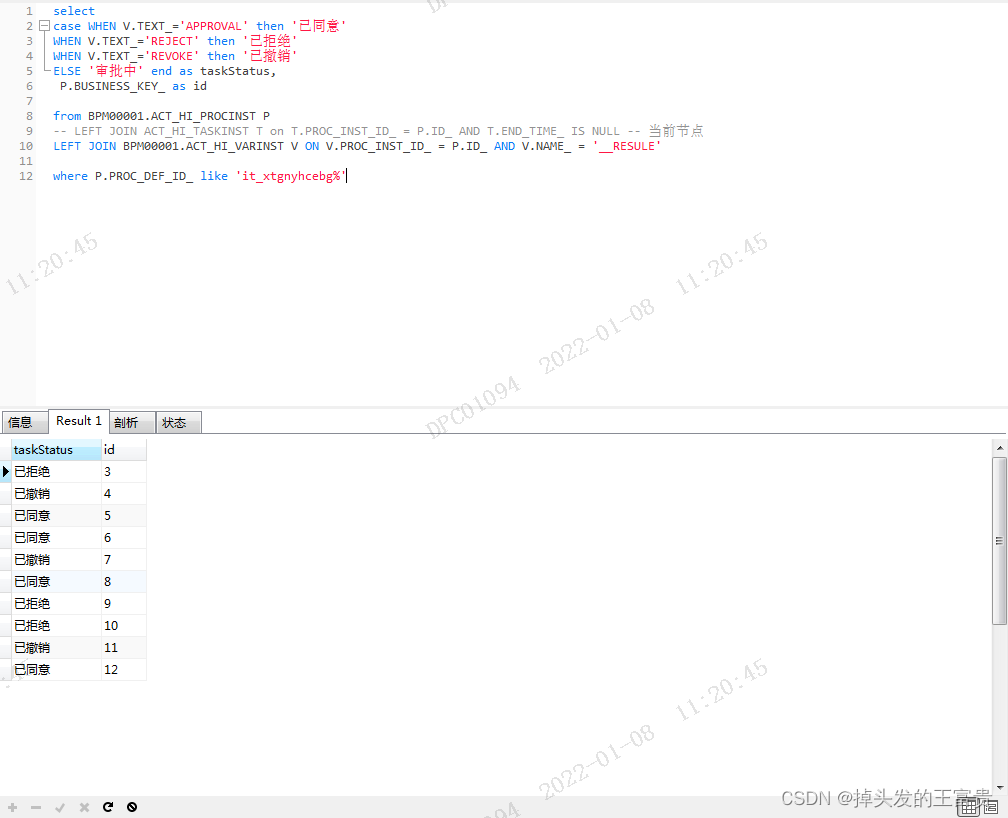
这就是sql的case语句的使用
有了这些数据之后我们就可以更新数据表了,回到我们之前讨论过的,这是及其危险的操作
我们先把要set的值给拿出来
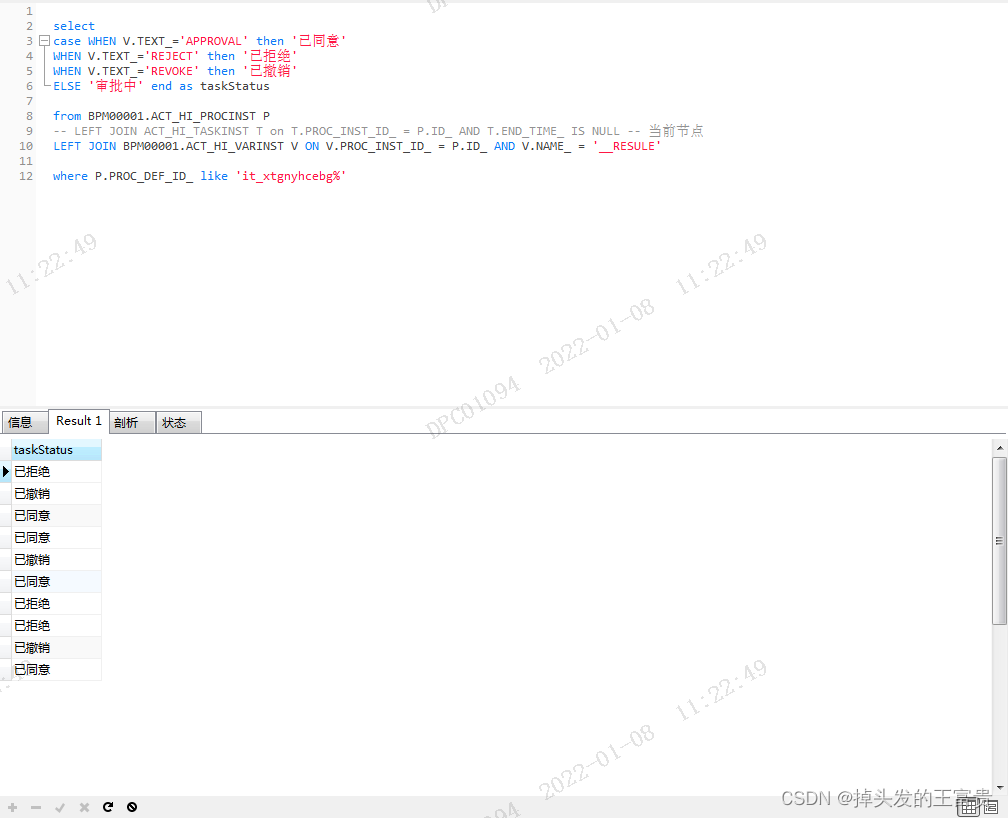
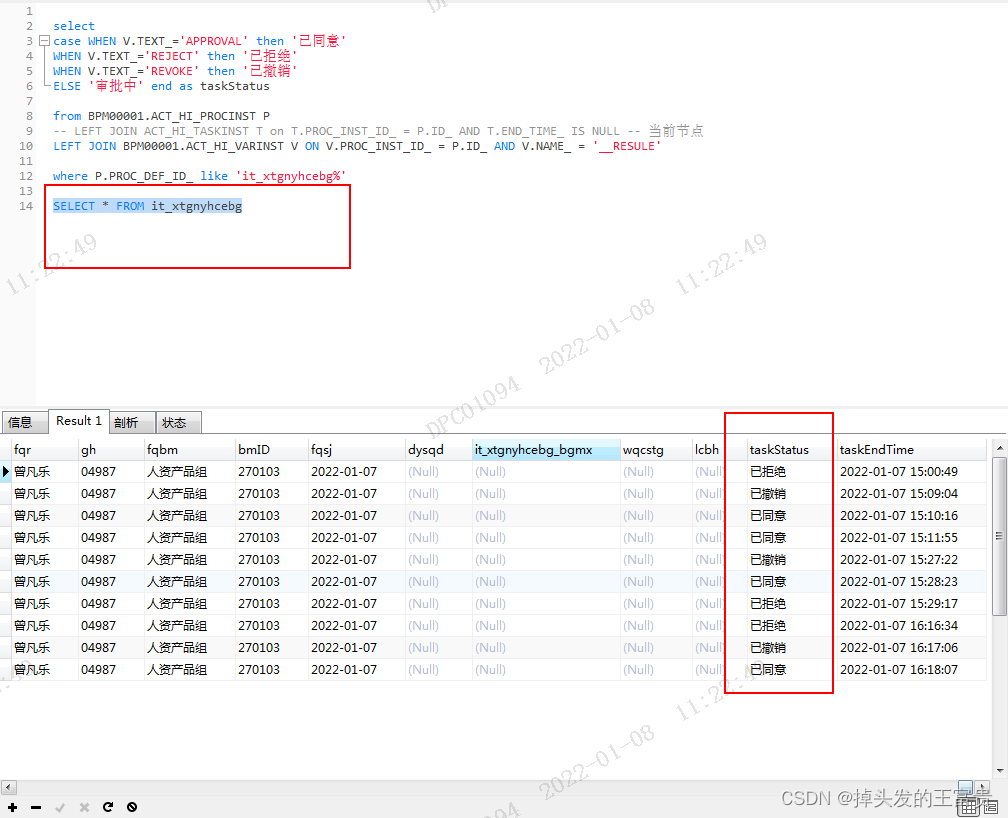
但是我们怎么知道这个里面的主键呢?
你如果直接这么加,肯定是不行的
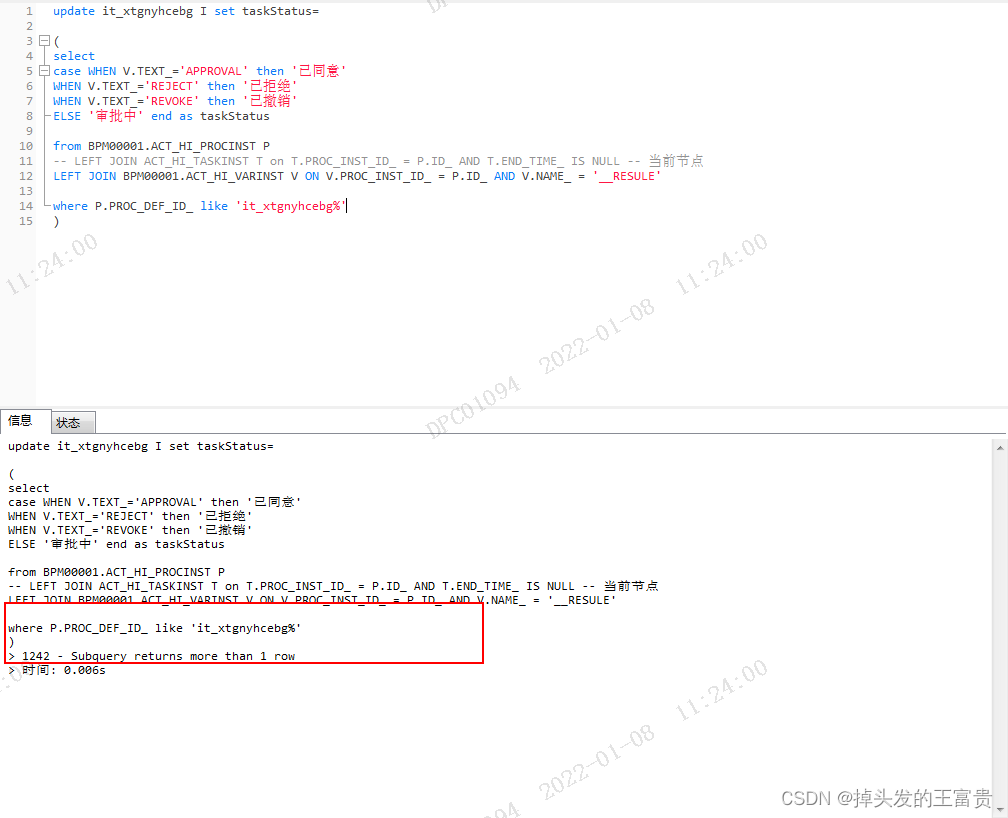
所以我们需要在sql后面加入这样的一条语句
注意,这个语句一定要写在set语句的里面,这样sql就能依据里面判断的条件进行一一赋值
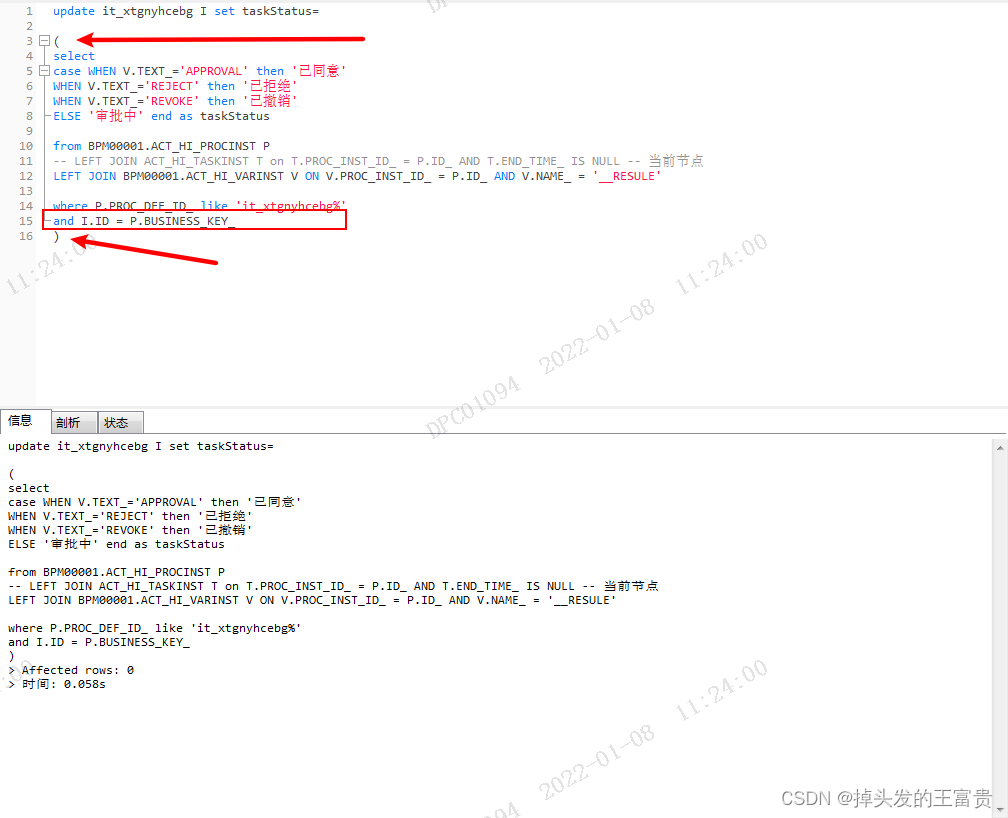
最后,将这个sql语句执行到生产库中
拓展:
作为查询语句的key绝对不能重复,否则会失败(找bug找了半天的人的善意提醒)
例如上面的语句中P.BUSINESS_KEY_必须要保证是唯一的!!

成功执行!!!
怎么样,这些sql的小妙招你学会了吗?



















 3103
3103

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











