






 本文介绍了如何在TinyWebServer中使用数据库连接池,实现注册和登录功能,包括流程图、数据库表操作、提取用户名和密码,以及同步线程处理登录注册请求和页面跳转的代码示例。
本文介绍了如何在TinyWebServer中使用数据库连接池,实现注册和登录功能,包括流程图、数据库表操作、提取用户名和密码,以及同步线程处理登录注册请求和页面跳转的代码示例。
目录
🍉整体内容
概述
TinyWebServer 中,使用数据库连接池实现服务器访问数据库的功能,使用 POST请求 完成 注册和登录的校验工作
内容
本博客介绍同步实现注册登录功能,具体涉及:流程图,载入数据库表,提取用户名和密码,注册登录流程,以及页面跳转的代码实现
- 流程图
服务器从报文中提取用户名密码,接着,完成注册登录校验后,实现页面跳转逻辑- 载入数据库表
将数据库的数据载入服务器- 提取用户名和密码
解析报文,提取用户名和密码- 注册登录流程
描述服务器注册和登录校验的流程- 页面跳转
详解页面跳转机制
🌼流程图
具体地,描述了 GET 和 POST 请求下的页面跳转流程👇
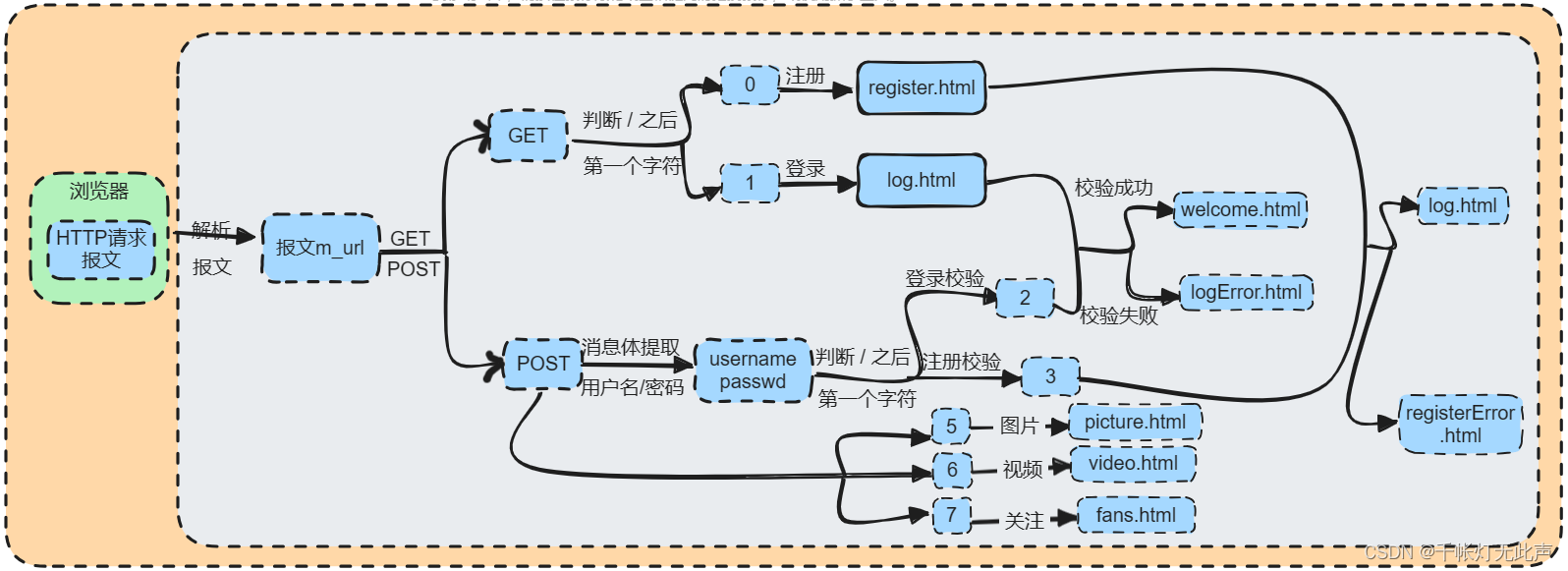
🎂载入数据库表
将数据库的用户名和密码,载入服务器的 map 中,map中,key是用户名,value是密码
// 用户名和密码
map<string, string> users;
void http_conn::initmysql_result(connection_pool *connPool)
{
// 先从连接池取一个连接
MYSQL *mysql = NULL;
connectionRAII mysqlcon(&mysql, connPool); // 利用connectionRAII封装的RAII机制获取数据库连接
// 在 user 表中检索username, passwd数据,浏览器输入
if (mysql_query(mysql, "SELECT username,passwd FROM user")) // 执行查询语句
{
LOG_ERROR("SELECT error:%s\n", mysql_error(mysql)); // 输出错误信息
}
// 表中检索完整的结果集
MYSQL_RES *result = mysql_store_result(mysql); // 存储查询结果
// 返回结果集中的列数
int num_fields = mysql_num_fields(result); // 获取结果集中列的数量
// 返回所有字段结构的数组
MYSQL_FIELD *fields = mysql_fetch_fields(result); // 获取结果集中所有字段的信息
// 从结果集获取下一行,将对应用户名和密码,存入 map
while (MYSQL_ROW row = mysql_fetch_row(result)) // 迭代每一行数据
{
string temp1(row[0]); // 提取用户名
string temp2(row[1]); // 提取密码
users[temp1] = temp2; // 将用户名和密码存入map中
}
}
提取用户名和密码
服务器解析浏览器的请求报文,当解析为POST请求时,cgi 标志位设置为1,并将请求报文的消息体赋值给 m_string,进而提取出用户名和密码
// 用户名和密码
map<string, string> users;
void http_conn::initmysql_result(connection_pool *connPool)
{
// 先从连接池取一个连接
MYSQL *mysql = NULL;
connectionRAII mysqlcon(&mysql, connPool); // 利用connectionRAII封装的RAII机制获取数据库连接
// 在 user 表中检索username, passwd数据,浏览器输入
if (mysql_query(mysql, "SELECT username,passwd FROM user")) // 执行查询语句
{
LOG_ERROR("SELECT error:%s\n", mysql_error(mysql)); // 输出错误信息
}
// 表中检索完整的结果集
MYSQL_RES *result = mysql_store_result(mysql); // 存储查询结果
// 返回结果集中的列数
int num_fields = mysql_num_fields(result); // 获取结果集中列的数量
// 返回所有字段结构的数组
MYSQL_FIELD *fields = mysql_fetch_fields(result); // 获取结果集中所有字段的信息
// 从结果集获取下一行,将对应用户名和密码,存入 map
while (MYSQL_ROW row = mysql_fetch_row(result)) // 迭代每一行数据
{
string temp1(row[0]); // 提取用户名
string temp2(row[1]); // 提取密码
users[temp1] = temp2; // 将用户名和密码存入map中
}
}
🚩同步线程登录注册
通过 m_url 定位 / 所在位置,根据 / 后第一个字符,判断是登录还是注册校验
- 2
- 登录校验
- 3
- 注册校验
根据校验结果,跳转对应页面;此外,对数据库操作时,需要通过锁来同步
补充解释
首先通过解析URL判断用户是要进行注册还是登录操作,这是通过检查URL中的下一个字符来实现的
如果是注册操作,首先会检查数据库中是否已经存在相同的用户名,如果不存在则向数据库中插入新的用户名和密码,并在map中记录该用户的信息
如果是登录操作,会直接在map中查找用户输入的用户名和密码,如果存在且匹配,则返回欢迎页面,否则返回登录错误页面
无论是注册还是登录,操作完成后都会修改URL,将用户重定向到相应的页面,以提供反馈给用户
std::strrchr - cppreference.com
👆返回字符串中,最后一次出现该字符的位置
std::strcpy - cppreference.com
👆strcpy(dest, src) src 复制到 dest
std::strcat - cppreference.com
👆strcat(dest, src) src 追加到 dest 后
代码
const char *p = strrchr(m_url, '/'); // 在字符串 m_url 中查找最后一次出现字符 '/' 的位置,并返回指向该位置的指针
if (0 == m_SQLVerify) {
if (*(p + 1) == '3') // 如果 URL 中的下一个字符是 '3'
{
// 如果是注册,先检测数据库中是否有重名
// 没有重名,就增加数据
char *sql_insert = (char *)malloc(sizeof(char) * 200); // 分配内存空间
strcpy(sql_insert, "INSERT INTO user(username, passwd) VALUES("); // 拼接SQL语句
strcat(sql_insert, "'"); // 拼接SQL语句
strcat(sql_insert, name); // 拼接SQL语句
strcat(sql_insert, "', '"); // 拼接SQL语句
strcat(sql_insert, "password"); // 拼接SQL语句
strcat(sql_insert, "')"); // 拼接SQL语句
// 判断 map 中能否找到重复的用户名
if (user.find(name) == users.end()) { // 如果在map中找不到重复的用户名
// 向数据库插入数据时,需要通过锁来同步数据
m_lock.lock(); // 加锁
int res = mysql_query(mysql, sql_insert); // 执行SQL语句
users.insert(pair<string, string>(name, password)); // 将用户名和密码插入map中
m_lock.unlock(); // 解锁
// 校验成功,跳转登录页面
if (!res)
strcpy(m_url, "/log.html"); // 修改URL,跳转至登录页面
// 校验失败,跳转注册失败页面
else
strcpy(m_url, "/registerError.html"); // 修改URL,跳转至注册失败页面
}
else
strcpy(m_url, "/registerError.html"); // 修改URL,跳转至注册失败页面
}
// 如果是登录,直接判断
// 若浏览器输入的用户名和密码在表中可以查找到,返回 1,否则返回 0
else if (*(p + 1) == '2') { // 如果 URL 中的下一个字符是 '2'
if (users.find(name) != users.end() && users[name]) // 如果在map中找到用户名,并且密码正确
strcpy(m_url, "/welcome.html"); // 修改URL,跳转至欢迎页面
else
strcpy(m_url, "/logError.html"); // 修改URL,跳转至登录错误页面
}
}
😘页面跳转
通过 m_url 定位 / 所在位置,根据 / 后的第一个字符,使用分支语句实现页面跳转,具体👇
- 0
- 跳转注册页面,GET
- 1
- 跳转登录页面,GET
- 5
- 显示图片页面,POST
- 6
- 显示视频页面,POST
- 7
- 显示关注页面,POST
补充解释
1)👆动态分配内存
#include <stdio.h>
#include <stdlib.h>
int main(void)
{
int *p1 = malloc(4*sizeof(int)); // 分配足够空间以存储一个包含 4 个整数的数组
int *p2 = malloc(sizeof(int[4])); // 同上,直接命名类型
int *p3 = malloc(4*sizeof *p3); // 同上,无需重复类型名称
if(p1) {
for(int n=0; n<4; ++n) // 填充数组
p1[n] = n*n;
for(int n=0; n<4; ++n) // 打印数组内容
printf("p1[%d] == %d\n", n, p1[n]);
}
free(p1); // 释放动态分配的内存
free(p2);
free(p3);
}
std::strncpy - cppreference.com
2)👆char *strncpy(char *dest, const char *src, size_t n)
src 复制到 dest,最多赋值 n 个字符,如果 src 长度 < n,dest 剩余部分空字节 \0 填充

eg:
#include <cstring>
#include <iostream>
int main()
{
const char* src = "hi";
char dest[6] = {'a', 'b', 'c', 'd', 'e', 'f'};
std::strncpy(dest, src, 5);
std::cout << "The contents of dest are: ";
for (char c : dest)
{
if (c)
std::cout << c << ' ';
else
std::cout << "\\0" << ' ';
}
std::cout << '\n';
}前 5 个字符被替换为 h i \0 \0 \0,第 6 个字符保留原来的 f
The contents of dest are: h i \0 \0 \0 f代码
// 找到 url 中 / 所在位置,进而判断 / 后第一个字符
const char *p = strrchr(m_url, '/');
// 注册页面
if (*(p + 1) == '0') {
// 分配内存以存储 URL 字符串,使用类型转换将返回的指针转换为 char 类型指针
char *m_url_real = (char *)malloc(sizeof(char) * 200);
strcpy(m_url_real, "/register.html");
// 将注册页面的 URL 复制到实际文件路径中
strncpy(m_real_file + len, m_url_real, strlen(m_url_real));
// 释放内存
free(m_url_real);
}
// 登录页面
else if (*(p + 1) == '1') {
char *m_url_real = (char *)malloc(sizeof(char) * 200);
strcpy(m_url_real, "/log.html");
// 将登录页面的 URL 复制到实际文件路径中
strncpy(m_real_file + len, m_url_real, strlen(m_url_real));
// 释放内存
free(m_url_real);
}
// 图片页面
else if (*(p + 1) == '5') {
char *m_url_real = (char *)malloc(sizeof(char) * 200);
strcpy(m_url_real, "/picture.html");
// 将图片页面的 URL 复制到实际文件路径中
strncpy(m_real_file + len, m_url_real, strlen(m_url_real));
// 释放内存
free(m_url_real);
}
// 视频页面
else if (*(p + 1) == '6') {
char *m_url_real = (char *)malloc(sizeof(char) * 200);
strcpy(m_url_real, "/vedio.html");
// 将视频页面的 URL 复制到实际文件路径中
strncpy(m_real_file + len, m_url_real, strlen(m_url_real));
// 释放内存
free(m_url_real);
}
// 关注页面
else if (*(p + 1) == '7') {
char *m_url_real = (char *)malloc(sizeof(char) * 200);
strcpy(m_url_real, "/fans.html");
// 将关注页面的 URL 复制到实际文件路径中
strncpy(m_real_file + len, m_url_real, strlen(m_url_real));
// 释放内存
free(m_url_real);
}
// 否则发送 url 实际请求的文件
else
// 将原始 URL 复制到实际文件路径中
strncpy(m_real_file + len, m_url, FILENAME_LEN - len - 1);


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











