



使用以下代码获取北京链家网首页(https://bj.lianjia.com/zufang/)HTML码,输出第一个房租信息相关代码,如下:
>>> import requests
>>> from bs4 import BeautifulSoup
>>> def getHTMLText(url):
headers={'User-Agent':'Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'}
r=requests.get(url,headers=headers)
r.encoding='utf-8'
bs=BeautifulSoup(r.text,'lxml')
print(bs.find_all('div',{'class':'content__list--item'})[0])
>>> url='https://bj.lianjia.com/zufang/'
>>> getHTMLText(url)
<div class="content__list--item" data-brand_code="200301001000" data-c_type="1" data-fb_expo_id="198615584158040065" data-house_code="BJ2289881416059854848" data-position="0" data-total="23045">
<a class="content__list--item--aside" href="/zufang/BJ2289881416059854848.html" target="_blank"><img alt="整租·北三环中路甲69号院 2室1厅 南/北" class="lazyload" data-src="https://image1.ljcdn.com/110000-inspection/2371aeae-566f-4e1e-897a-0afb03227b5b.jpg.250x182.jpg" src="https://s1.ljcdn.com/matrix_lianjia_pc/dist/pc/src/resource/default/250-182.png?_v=2019070216064119e"/>
<!-- 是否展示vr图片 -->
</a>
<div class="content__list--item--main">
<p class="content__list--item--title twoline">
<a href="/zufang/BJ2289881416059854848.html" target="_blank">
整租·北三环中路甲69号院 2室1厅 南/北 </a>
</p>
<p class="content__list--item--des">
<a href="/zufang/haidian" target="_blank">海淀</a>-<a href="/zufang/beitaipingzhuang" target="_blank">北太平庄</a>
<i>/</i>
59㎡
<i>/</i>南 北 <i>/</i>
2室1厅1卫 <span class="hide">
<i>/</i>
低楼层 (5层)
</span>
</p>
<p class="content__list--item--brand oneline">
链家 </p>
<p class="content__list--item--time oneline">3天前发布</p>
<p class="content__list--item--bottom oneline">
<i class="content__item__tag--is_subway_house">近地铁</i>
<i class="content__item__tag--decoration">精装</i>
<i class="content__item__tag--is_new">新上</i>
</p>
<span class="content__list--item-price"><em>6800</em> 元/月</span>
</div>
</div>
>>> r
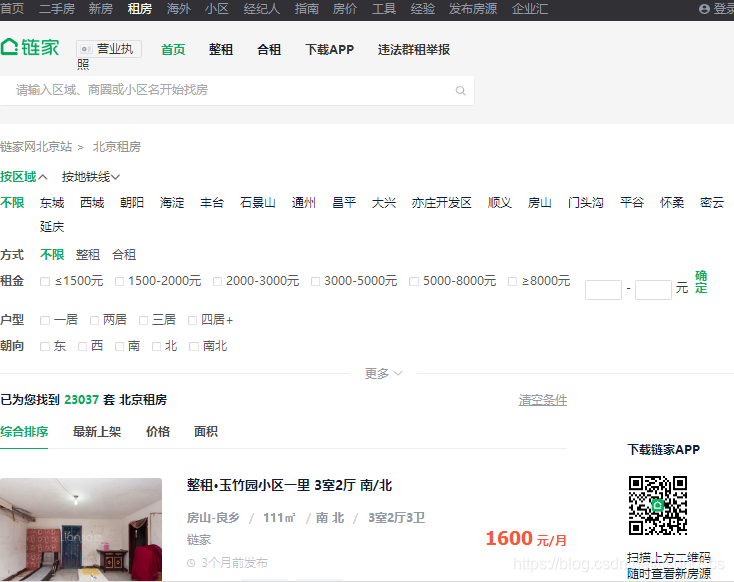
<Response [200]>然而,以上输出结果并不是第一个房租信息,也未在当前网页中出现,网页源代码也不包含以上返回信息,如下图:
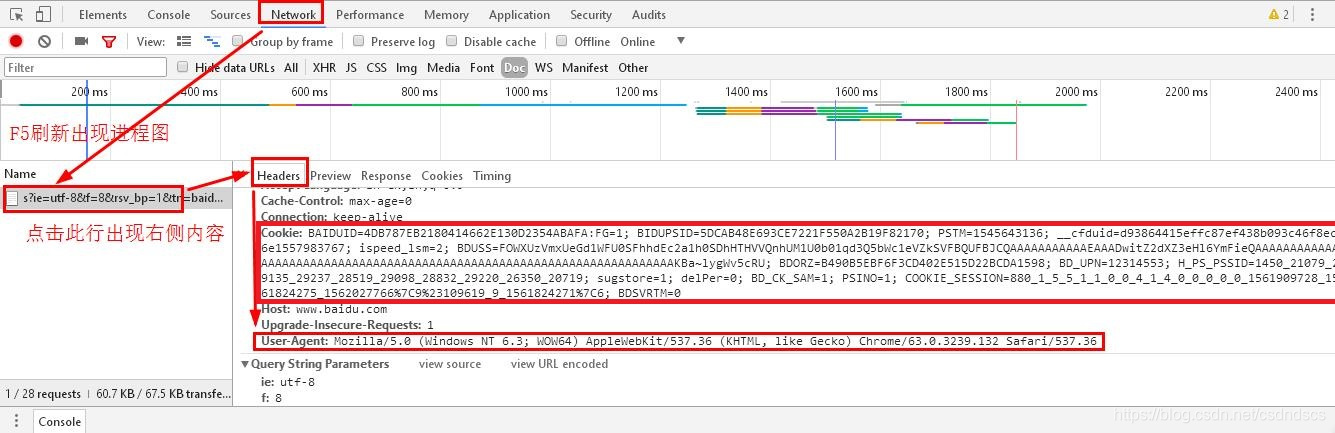
如果想得到与网页中信息一样的输出结果该怎么办呢?只需在header参数内加上cookies就行了,这样header字典内就有了两个元素。操作方法如下(参考爬虫时requests.get()响应状态码不是[200]怎么办?):
>>> import requests
>>> from bs4 import BeautifulSoup
>>> def getHTMLText(url):
headers={'User-Agent':'Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36',
'Cookie':'lianjia_uuid=9d3277d3-58e4-440e-bade-5069cb5203a4; UM_distinctid=16ba37f7160390-05f17711c11c3e-454c0b2b-100200-16ba37f716618b; _smt_uid=5d176c66.5119839a; sensorsdata2015jssdkcross=%7B%22distinct_id%22%3A%2216ba37f7a942a6-0671dfdde0398a-454c0b2b-1049088-16ba37f7a95409%22%2C%22%24device_id%22%3A%2216ba37f7a942a6-0671dfdde0398a-454c0b2b-1049088-16ba37f7a95409%22%2C%22props%22%3A%7B%22%24latest_traffic_source_type%22%3A%22%E7%9B%B4%E6%8E%A5%E6%B5%81%E9%87%8F%22%2C%22%24latest_referrer%22%3A%22%22%2C%22%24latest_referrer_host%22%3A%22%22%2C%22%24latest_search_keyword%22%3A%22%E6%9C%AA%E5%8F%96%E5%88%B0%E5%80%BC_%E7%9B%B4%E6%8E%A5%E6%89%93%E5%BC%80%22%7D%7D; _ga=GA1.2.1772719071.1561816174; Hm_lvt_9152f8221cb6243a53c83b956842be8a=1561822858; _jzqa=1.2532744094467475000.1561816167.1561822858.1561870561.3; CNZZDATA1253477573=987273979-1561811144-%7C1561865554; CNZZDATA1254525948=879163647-1561815364-%7C1561869382; CNZZDATA1255633284=1986996647-1561812900-%7C1561866923; CNZZDATA1255604082=891570058-1561813905-%7C1561866148; _qzja=1.1577983579.1561816168942.1561822857520.1561870561449.1561870561449.1561870847908.0.0.0.7.3; select_city=110000; lianjia_ssid=4e1fa281-1ebf-e1c1-ac56-32b3ec83f7ca; srcid=eyJ0Ijoie1wiZGF0YVwiOlwiMzQ2MDU5ZTQ0OWY4N2RiOTE4NjQ5YmQ0ZGRlMDAyZmFhODZmNjI1ZDQyNWU0OGQ3MjE3Yzk5NzFiYTY4ODM4ZThiZDNhZjliNGU4ODM4M2M3ODZhNDNiNjM1NzMzNjQ4ODY3MWVhMWFmNzFjMDVmMDY4NWMyMTM3MjIxYjBmYzhkYWE1MzIyNzFlOGMyOWFiYmQwZjBjYjcyNmIwOWEwYTNlMTY2MDI1NjkyOTBkNjQ1ZDkwNGM5ZDhkYTIyODU0ZmQzZjhjODhlNGQ1NGRkZTA0ZTBlZDFiNmIxOTE2YmU1NTIxNzhhMGQ3Yzk0ZjQ4NDBlZWI0YjlhYzFiYmJlZjJlNDQ5MDdlNzcxMzAwMmM1ODBlZDJkNmIwZmY0NDAwYmQxNjNjZDlhNmJkNDk3NGMzOTQxNTdkYjZlMjJkYjAxYjIzNjdmYzhiNzMxZDA1MGJlNjBmNzQxMTZjNDIzNFwiLFwia2V5X2lkXCI6XCIxXCIsXCJzaWduXCI6XCIzMGJlNDJiN1wifSIsInIiOiJodHRwczovL2JqLmxpYW5qaWEuY29tL3p1ZmFuZy9yY28zMS8iLCJvcyI6IndlYiIsInYiOiIwLjEifQ=='
}
r=requests.get(url,headers=headers)
r.encoding='utf-8'
bs=BeautifulSoup(r.text,'lxml')
print(bs.find_all('div',{'class':'content__list--item'})[0])
>>> url='https://bj.lianjia.com/zufang/'
>>> getHTMLText(url)
<div class="content__list--item" data-brand_code="200301001000" data-c_type="1" data-fb_expo_id="198621183625195521" data-house_code="BJ2163169874879455232" data-position="0" data-total="23044">
<a class="content__list--item--aside" href="/zufang/BJ2163169874879455232.html" target="_blank"><img alt="整租·玉竹园小区一里 3室2厅 南/北" class="lazyload" data-src="https://image1.ljcdn.com/110000-inspection/9fafb124-4c19-45a0-a84f-46cfcb99c8f2.jpg.250x182.jpg" src="https://s1.ljcdn.com/matrix_lianjia_pc/dist/pc/src/resource/default/250-182.png?_v=2019070216064119e"/>
<!-- 是否展示vr图片 -->
</a>
<div class="content__list--item--main">
<p class="content__list--item--title twoline">
<a href="/zufang/BJ2163169874879455232.html" target="_blank">
整租·玉竹园小区一里 3室2厅 南/北 </a>
</p>
<p class="content__list--item--des">
<a href="/zufang/fangshan" target="_blank">房山</a>-<a href="/zufang/liangxiang" target="_blank">良乡</a>
<i>/</i>
111㎡
<i>/</i>南 北 <i>/</i>
3室2厅3卫 <span class="hide">
<i>/</i>
地下室 (6层)
</span>
</p>
<p class="content__list--item--brand oneline">
链家 </p>
<p class="content__list--item--time oneline">3个月前发布</p>
<p class="content__list--item--bottom oneline">
<i class="content__item__tag--is_subway_house">近地铁</i>
<i class="content__item__tag--central_heating">集中供暖</i>
<i class="content__item__tag--is_key">随时看房</i>
</p>
<span class="content__list--item-price"><em>1600</em> 元/月</span>
</div>
</div>这样输出结果就与网页中一致了。
headers中加上其他的元素也可,只是这两个是必要的。

















 8430
8430

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









