



 本文介绍了分布式调度的概念,包括定时任务的使用场景和分布式调度的双重含义。重点讲解了Elastic-Job框架,特别是Elastic-Job-Lite,如何在分布式环境下确保定时任务的唯一执行,并通过实例展示了如何配置和使用Elastic-Job-Lite实现任务的分片和分布式执行。
本文介绍了分布式调度的概念,包括定时任务的使用场景和分布式调度的双重含义。重点讲解了Elastic-Job框架,特别是Elastic-Job-Lite,如何在分布式环境下确保定时任务的唯一执行,并通过实例展示了如何配置和使用Elastic-Job-Lite实现任务的分片和分布式执行。
分布式调度可以被理解为在分布式环境下执行定时任务。那么要先理解一下“定时任务”。
定时任务的使用场景
何为定时任务?定时任务就是在某一时刻或者每隔一定时间去执行的任务。比如XX游戏在本赛季末的周日要统计用户上个赛季的积分等信息、XX相册要每个月清空一次回收箱、XX系统要每周生成销售报表、使用某宝购物,下单15分钟内不付款会自动取消订单等。
上述任务都是有规律的,因此我们可以编写脚本来设置定时做这些事,这就是调度。
分布式调度通俗简介
那么什么是分布式调度?字面意思上,分布式调度就是在分布式环境下执行定时任务,因此它可以有两层含义:
1. 同一个定时任务程序部署多份,在同一时刻只有一个会执行,即定时任务只执行一次
举个例子,当前我有个游戏系统,我写了个定时任务:每周周日0点更新一个版本,次日8点通知用户更新游戏。写完后我将其部署到分布式环境下的各个服务器,理想状态是到了每周一的8点,用户就会被提示更新游戏。

但是实际情况可能是:用户小明第一次打开游戏,服务器A接受处理他的请求,并告知他要更新游戏,小明照做,更新完后再次打开游戏,可能是服务器B接受处理第二次请求,小明被第二次告知需要更新游戏,这时小明可能就蒙圈了:我不是已经更新过一次了吗?即使这么想,小明还是又更新了一次,到第三次,服务器C接受处理他的请求…

设想极限情况,小明可能一整天都在更新游戏,这意味着我要失去一个用户。

导致以上情况发生的原因是我在每一台服务器上都部署了定时任务,所以每一台服务器都会执行一次定时任务。这不是我想要的,我的理想状态应该是不管往多少台服务器部署了定时任务,同一时刻只有一台服务器会去执行该任务,即该任务只执行一次,这就是分布式调度的含义之一:同一个定时任务程序部署多份,在同一时刻只有一个会执行,即定时任务只执行一次
2. 拆分定时任务,大任务拆分为若干个小任务
举个例子,我有一项定时任务需要在某一时刻去进行一百万次计算,那么如果这项任务能被拆分为若干个小任务,同一时刻由若干台服务器去执行,那么每台服务器需要处理的任务都比不拆分时由一台服务器处理的任务少,整体效率就上去了。这就是分布式调度的含义之二:把一个大的任务(作业)分为若干个小的任务(作业),同时执行


分布式调度框架Elastic-Job
以往在单体应用中,我们可能使用Quartz框架来实现定时任务的调度,但是在分布式环境下,Quartz很难实现我们想要的效果,于是这里要提一个专业的分布式框架:Elastic-Job,github:https://github.com/dangdangdotcom/elastic-job。
Elastic-Job简介
Elastic-Job是一款基于Quartz二次开发的开源分布式调度解决方案,由两个子项目Elastic-Job-Lite和Elastic-Job-Cloud组成,Elastic-Job-Lite是轻量级、无中心化的分布式调度方案,Elastic-Job-Cloud则是作用于云环境。本篇作为入门了解demo只以Elastic-Job-Lite做例子,具体内容可以上Elastic-Job-Lite官网看一波。
Elastic-Job-Lite应用
说回来,在分布式环境下,如果有一个定时任务被部署到多台服务器上,且要求这一定时任务只能执行一次,那么问题来了,其中一台服务器执行了任务,其他服务器怎么知道呢?

于是自然而然就涉及到服务器之间的通信,Elastic-Job框架已经做好了这方面的准备,它依赖ZooKeeper来实现服务器的通信需求(关于Zookeeper的详细内容不在本篇重点范围内,可上Zookeeper官网了解)。

任务需求
我们当前有一个业务需求:有一张数据表test_user,当中存储学生信息。

这些信息的使用频率很低甚至常年不使用,我们需要将这些不常用的数据做一个备份,方便这张数据表在后续使用上能简便一些。具体操作是将记录的state字段从on修改为off,并将记录复制到另一张表test_user_bak中。

在单体应用中我们可以使用一条语句实现这个需求,但是在分布式环境下就没那么简单了,现在我们就要编写一个定时任务,并且假设定时任务执行时机已到,手动执行它。
引入依赖
要使用Elastic-Job框架,就先引入其依赖支持
<!-- https://mvnrepository.com/artifact/com.dangdang/elastic-job-lite-core -->
<dependency>
<groupId>com.dangdang</groupId>
<artifactId>elastic-job-lite-core</artifactId>
<version>2.1.5</version>
</dependency>
编写数据库交互工具类
与数据库的交互不是本篇重点,所以这个不详述,只提供代码。JdbcUtil工具类提供两个DML操作接口
- 更新:
executeUpdate(String sql,Object...obj) - 查询:
executeQuery(String sql,Object...obj)
public class JdbcUtil {
//url
private static String url = "jdbc:mysql://localhost:3306/test?characterEncoding=utf8&useSSL=false";
//user
private static String user = "root";
//password
private static String password = "123456";
//驱动程序类
private static String driver = "com.mysql.jdbc.Driver";
static {
try {
Class.forName(driver);
} catch (ClassNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
public static Connection getConnection() {
try {
return DriverManager.getConnection(url, user, password);
} catch (SQLException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
return null;
}
public static void close(ResultSet rs, PreparedStatement ps, Connection con) {
if (rs != null) {
try {
rs.close();
} catch (SQLException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} finally {
if (ps != null) {
try {
ps.close();
} catch (SQLException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} finally {
if (con != null) {
try {
con.close();
} catch (SQLException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
}
}
}
}
/***
* DML操作(增删改)
* 1.获取连接数据库对象
* 2.预处理
* 3.执行更新操作
* @param sql
* @param obj
*/
//调用者只需传入一个sql语句,和一个Object数组。该数组存储的是SQL语句中的占位符
public static void executeUpdate(String sql,Object...obj) {
Connection con = getConnection();//调用getConnection()方法连接数据库
PreparedStatement ps = null;
try {
ps = con.prepareStatement(sql);//预处理
for (int i = 0; i < obj.length; i++) {//预处理声明占位符
ps.setObject(i + 1, obj[i]);
}
ps.executeUpdate();//执行更新操作
} catch (SQLException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} finally {
close(null, ps, con);//调用close()方法关闭资源
}
}
/***
* DQL查询
* Result获取数据集
*
* @param sql
* @param obj
* @return
*/
public static List<Map<String,Object>> executeQuery(String sql, Object...obj) {
Connection con = getConnection();
ResultSet rs = null;
PreparedStatement ps = null;
try {
ps = con.prepareStatement(sql);
for (int i = 0; i < obj.length; i++) {
ps.setObject(i + 1, obj[i]);
}
rs = ps.executeQuery();
//new 一个空的list集合用来存放查询结果
List<Map<String, Object>> list = new ArrayList<>();
//获取结果集的列数
int count = rs.getMetaData().getColumnCount();
//对结果集遍历每一条数据是一个Map集合,列是k,值是v
while (rs.next()) {
//一个空的map集合,用来存放每一行数据
Map<String, Object> map = new HashMap<String, Object>();
for (int i = 0; i < count; i++) {
Object ob = rs.getObject(i + 1);//获取值
String key = rs.getMetaData().getColumnName(i + 1);//获取k即列名
map.put(key, ob);
}
list.add(map);
}
return list;
} catch (SQLException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} finally {
close(rs, ps, con);
}
return null;
}
}
编写定时任务
定时任务思路:
- 从
test_user表查询一条state字段为on的记录 - 修改记录的
state字段为off - 复制修改后的记录到
test_user_bak表
编写定时任务类ScheduledTask,定时任务类需要实现com.dangdang.ddframe.job.api.simple.SimpleJob接口并实现它的execute方法。
public class ScheduledTask implements SimpleJob {
@Override
public void execute(ShardingContext shardingContext) {
//1. 从`test_user`表查询一条`state`字段为`on`的记录
String querySql = "select * from test_user where state = 'on' limit 1";
List<Map<String, Object>> list = JdbcUtil.executeQuery(querySql);
if (null == list || list.size() == 0) {
System.out.println("任务处理完毕");
return;
}
//2. 修改记录的`state`字段为`off`
Map<String, Object> objectMap = list.get(0);
//为了可以直观地观察数据,获取部分数据输出到控制台
Integer id = (Integer) objectMap.get("id");
String name = (String) objectMap.get("user_name");
String education = (String) objectMap.get("education");
System.out.println("===>>>id:" + id + "\tuser_name:" + name + "\teducation:" + education);
//更新字段
String updateSql = "update test_user set state = 'off' where id = ?";
JdbcUtil.executeUpdate(updateSql, id);
//3. 复制修改后的记录到`test_user_bak`表
String insertSql = "insert into test_user_bak select * from test_user where id = ?";
JdbcUtil.executeUpdate(insertSql, id);
}
}
编写分布式调度中心
定时任务写好了,得有人去调它。这里就编写一个调度中心类ElasticJobMain模拟运行时机已到去执行定时任务,本调度中心的执行逻辑是每1秒执行1次任务。配置Zookeeper的内容依然不是本篇中心,不赘述。
public class ElasticJobMain {
public static void main(String[] args) {
// 配置分布式协调服务(注册中心)Zookeeper
ZookeeperConfiguration zkConfiguration = new ZookeeperConfiguration("localhost:2181", "sch_Task");
CoordinatorRegistryCenter registryCenter = new ZookeeperRegistryCenter(zkConfiguration);
registryCenter.init();
// 配置任务(时间事件、定时任务业务逻辑、调度器)
JobCoreConfiguration jobCoreConfiguration = JobCoreConfiguration
.newBuilder("archive-job", "*/1 * * * * ?", 1) //参数“*/1 * * * * ?”表示每秒执行一次任务,参数“1”表示任务分片数为1
.build();
SimpleJobConfiguration simpleJobConfiguration = new SimpleJobConfiguration(
jobCoreConfiguration,
ArchivieJob.class.getName());
JobScheduler jobScheduler = new JobScheduler(
registryCenter,
LiteJobConfiguration.newBuilder(simpleJobConfiguration).overwrite(true).build());
jobScheduler.init();
}
}
效果与优化
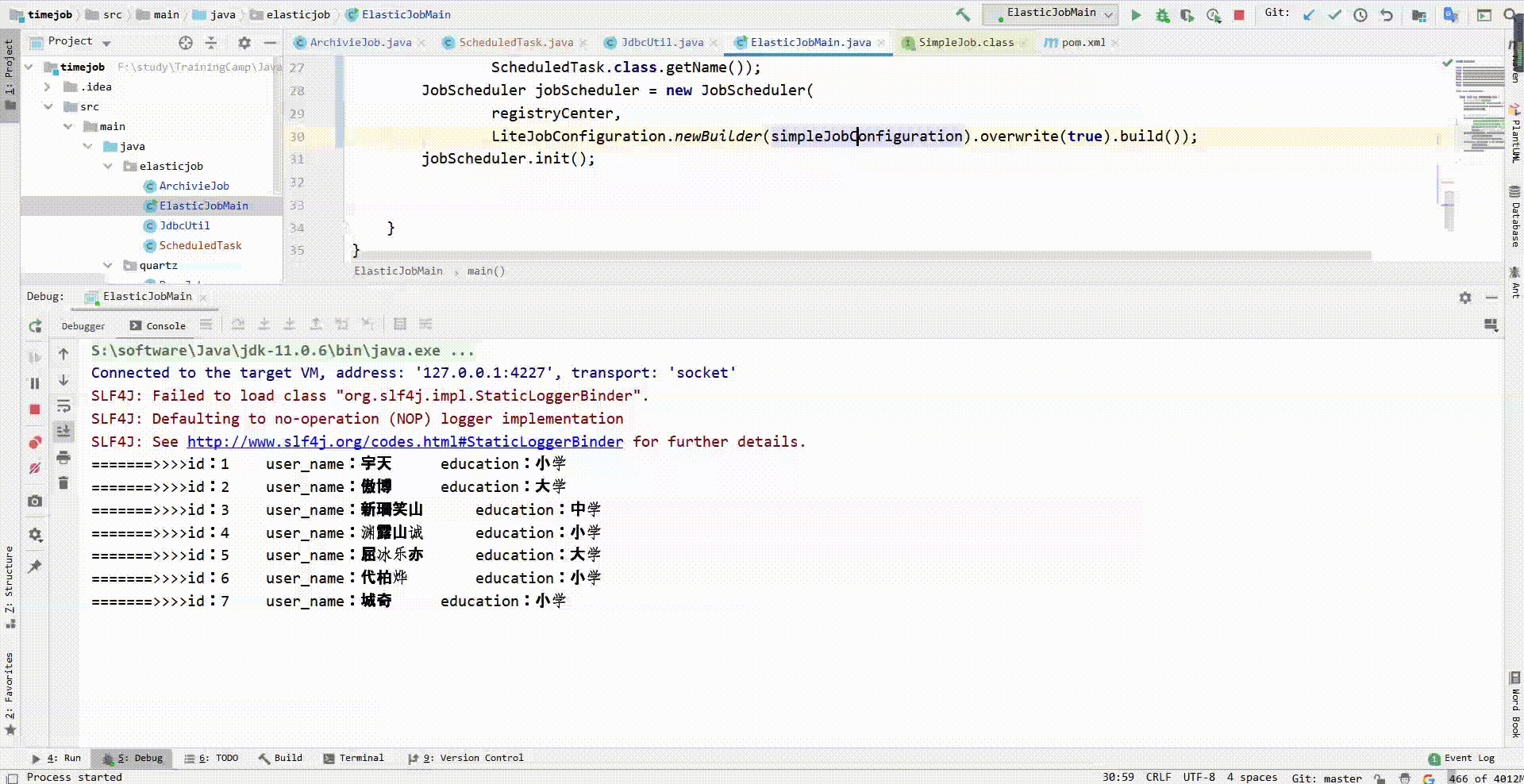
只执行一次main方法,模拟只启动一台服务器。每秒执行一次任务,一次任务处理一条数据。
现在我新增多台服务器(即再运行多次main方法):
可以看到原本在执行任务的服务器停止了任务执行,另一台服务器接手了任务,且从第一台服务器没处理过的数据开始处理,也就是说,实现了同一个定时任务部署在多台服务器上,任务在同一时刻只执行一次的效果。
现在我手动关闭一台服务器来模拟宕机
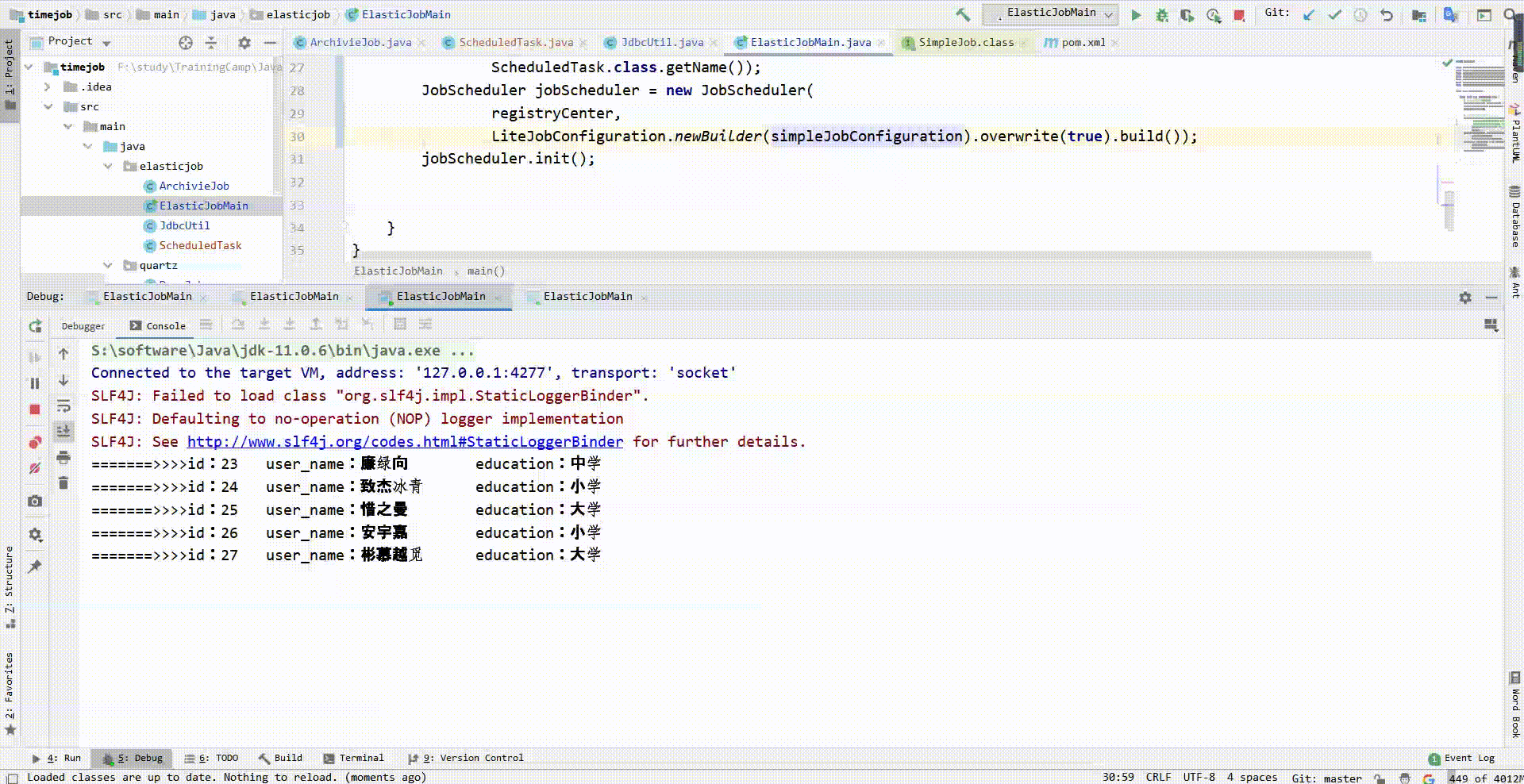
可以看到其他服务器再次接手未完成的任务继续处理。
现在我要修改调度逻辑:将每秒的要执行的1个大任务分为3个子任务。每个小任务都有所标识,这里我打算使用education字段作为标识,于是使用shardingItemParameters方法添加分片标识,以0为小学、1为中学、2为大学:
JobCoreConfiguration jobCoreConfiguration = JobCoreConfiguration
.newBuilder("archive-job", "*/1 * * * * ?", 3) //,参数“1”修改为“3”
.shardingItemParameters("0=小学,1=中学,2=大学")
.build();
定时任务代码也要根据分片逻辑进行修改:
//1. 从`test_user`表查询一条`state`字段为`on`的记录
//为了观察直观,输出到控制台查看
int shardingItem = shardingContext.getShardingItem();
System.out.println("====>>>>当前分片:" + shardingItem + "\t");
//从execute方法参数shardingContext中获取分片标识"0=小学,1=中学,2=大学"
String shardingParameter = shardingContext.getShardingParameter();
//筛选条件添加按每个小人物的分片标识查询
String querySql = "select * from test_user where state = 'on' and education='"+ shardingParameter +"' limit 1";
List<Map<String, Object>> list = JdbcUtil.executeQuery(querySql);
if (null == list || list.size() == 0) {
System.out.println("任务处理完毕");
return;
}
再次执行可见一台服务器在每秒执行一次任务,每个任务都包含3个小任务:
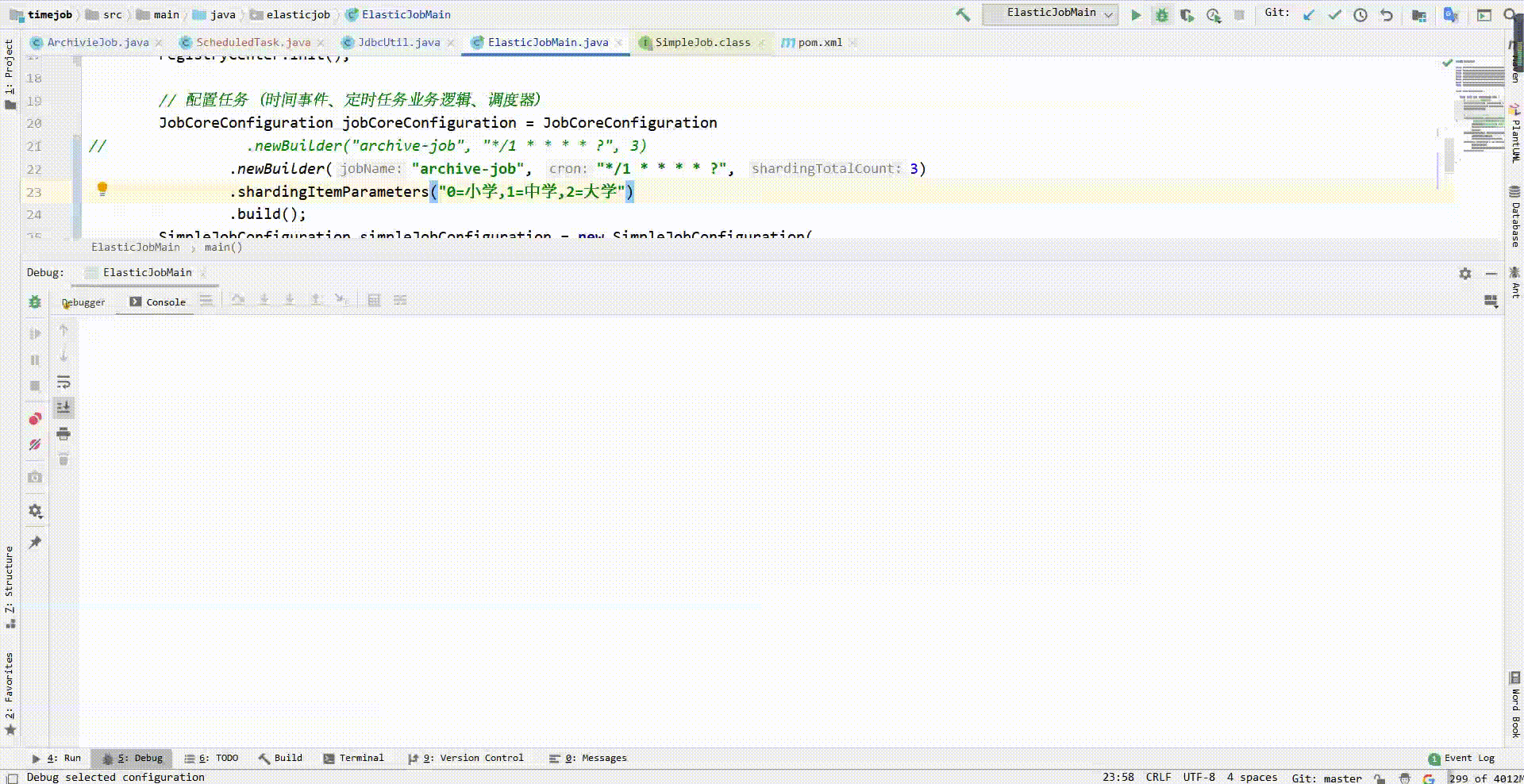
一台服务器每秒处理3个小任务压力可能比较大,因此我再启动一台服务器,处理效果如图:

可以看到,新增的服务器分担了一部分任务,第一台服务器开始只处理分片标识为1的任务,当同时启动三台服务器时,任务就会均分:
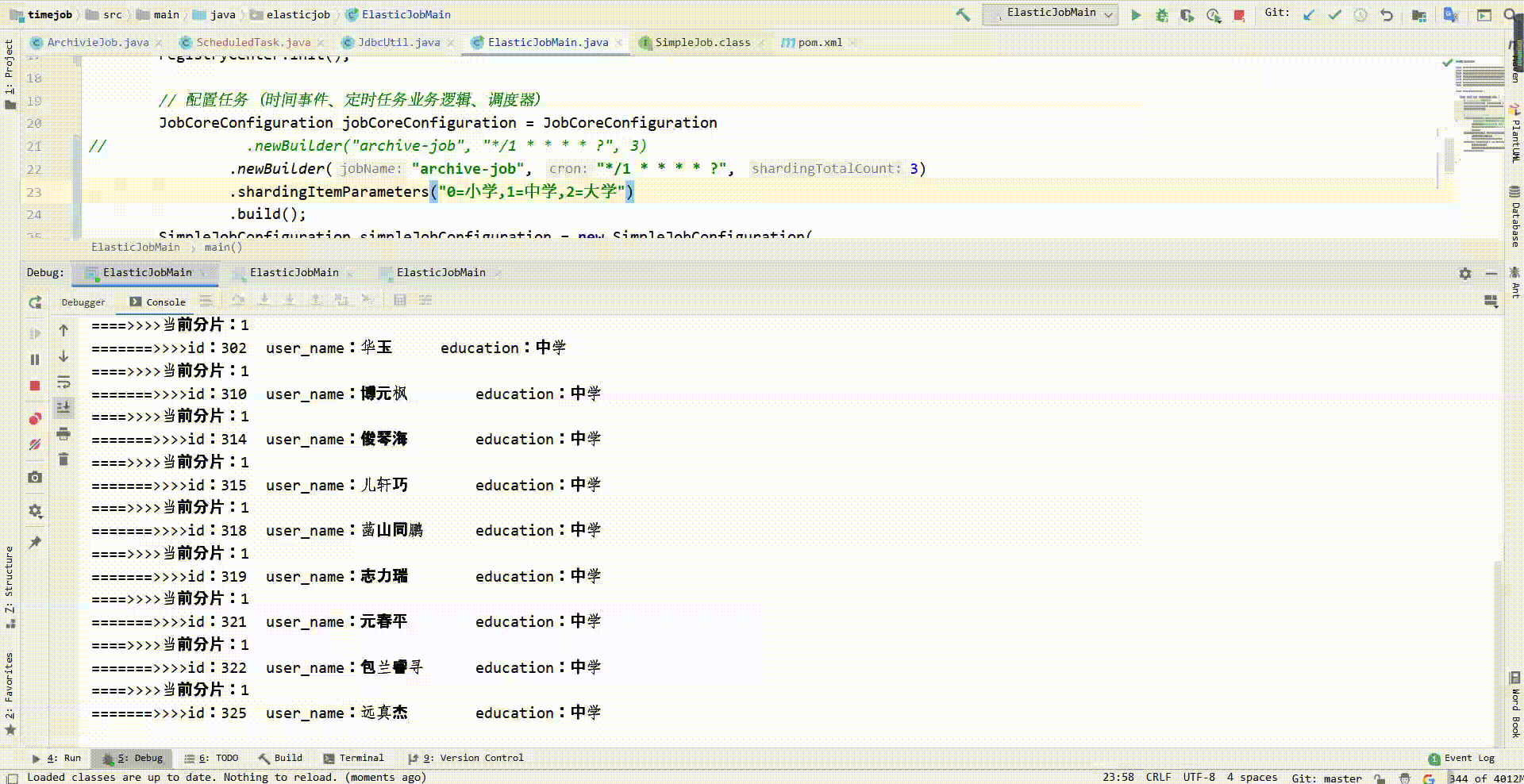
至此已实现了分布式调度的两种目标:
- 同一个定时任务程序部署多份,在同一时刻只有一个会执行,即同一个定时任务只执行一次;
- 拆分定时任务,大任务拆分为若干个小任务,分配到多台服务器上协同处理。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









