




 本文深入解析正则表达式的概念与应用,涵盖模糊匹配、量词、位置匹配及常见正则模式,辅以实例说明。
本文深入解析正则表达式的概念与应用,涵盖模糊匹配、量词、位置匹配及常见正则模式,辅以实例说明。
一.正则表达式是匹配模式,要么匹配字符,要么匹配位置。
什么是位置?
如何匹配字符?如何匹配位置?
位置的特性?
模糊匹配: 而模糊匹配,有两个方向上的“模糊”:横向模糊和纵向模糊。
横向模糊指: 一个正则可匹配的字符串的长度不是固定的,可以是多种情况。
**实现的方式:**使用量词,譬如{m,n},表示连续出现最少m次,最多n次。
比如正则/ab{2,5}c/表示匹配这样一个字符串:第一个字符是"a",接下来是2到5个字符"b",最后是字符"c"。
其可视化形式:
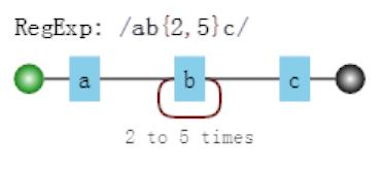
测试如下
var regex = /ab{2,5}/g;
var string = "abc abbc abbbc abbbbc abbbbbc abbbbbbc";
console.log(string.match(regex));//=>['abbc','abbbc','abbbbc','abbbbbc']
案例中用的正则是/ab{2,5}c/g,其中g是正则的一个修饰符。表示全局匹配,即在目标字符串中按顺序找到满足匹配模式的所有子串,强调的是“所有”,而不只是“第一个”,g是单词global的首字母。
纵向模糊匹配
纵向模糊指的是,一个正则匹配的字符串,具体到某一位字符时,它可以不是某个确定的字符,可以有多种可能。其实现的方式是使用字符组。譬如[abc]表示该字符是可以字符’a’,‘b’,'c’中的任何一个。比如/a{123}b/可以匹配如下三种字符串:“a1b”,“a2b”,“a3b”。
其可视化如下:
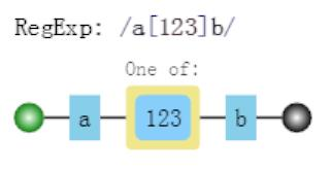
var regex=/a[123]b/g;
var string="a0b a1b a2b a3b a4b";
console.log(string.match(regex));//=>["a1b","a2b","a3b"]
字符组
需要强调的是,虽然交字符组(字符类),但只是其中一个字符。例如[abc],表示匹配一个字符,它可以"a",“b”,“c"之一。
范围表示法
如果字符组里的字符特别多的话,怎么办?可以使用范围表示法。比如[123456abcdefGHIJKLM],可以写成[1-6a-fG-M]。用连接字符 - 来省略和简写。
因为连接字符有特殊用途,那么要匹配"a”,"-",“z"这三者任意一个字符,该怎么做呢?不能写成[a-z],因为其表示小写字符中的任何一个。可以写成如下方式:[-az]或[az-]或[a-z]。即要么放在开头,要么放在结尾,要么转义。总之不会让引擎认为是范围表示法就行了。
排除字符组
纵向模糊匹配,还有一种情形就是,某位字符可以是任何东西,但就是不能是"a”,“b”,“c”。此时就是排除字符组(反义字符组)的概念。例如[abc],表示是一个除"a",“b”,"c"之外的任意一个字符。字符组的第一位放(脱字符),表示求反的概念。
常见的简写形式
| 字符组 | 具体含义 |
|---|---|
| \d | 表示[0-9],表示是一位数字。记忆方式:其英文是digit(数字) |
| \D | 表示[^0-9],表示除数字外的任意符 |
| \w | 表示[0-9a-zA-Z],表示数字,大小写字母和下划线记忆方式:w是word的简写,也称单词字符 |
| \W | 表示[^0-9a-zA-Z],非单词字符 |
| \s | 记忆方式:s是soace的首字母,空白符的单词是white space |
| \S | [^\t\v\n\r\f,非空白符] |
如果要匹配任意字符怎么办?可以使用[\d\D],[\w\W],[\s\S]和[^]中的任何一个。
量词
量词也称重复,掌握{m,n}的准确含义后,只需要记住一些简写形式。
| 量词 | 具体含义 |
|---|---|
| {m,} | 表现至少出现m次 |
| {m} | 等价于{m,m},表示出现m次 |
| ? | 等价于{0,1},表示出现或不出现,记忆方式:问号的意思表示有吗? |
| + | 等价于{1,},表示出现至少一次 |
| * | 等价于{0,},表示出现任意次,有可能不出现 |
贪婪匹配与惰性匹配
贪婪匹配就是要把所有满足的匹配出来,而惰性匹配,就是尽可能的少匹配。
通过在量词后面加一个问号就能实现惰性匹配,因此说有惰性匹配情形如下:
| 惰性量词 | 贪婪量词 |
|---|---|
| {m,n} | {m,n} |
| {m,}? | {m,} |
| ?? | ? |
| +? | + |
| *? | * |
什么是位置?
位置(锚)是相邻字符之间的位置。比如,下面中箭头所指的地方:
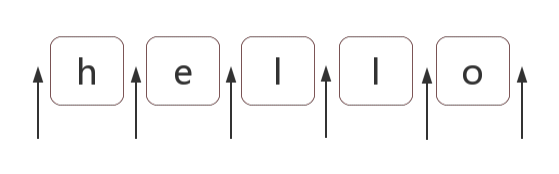
如何匹配位置?
在ES5中,共有6个位置(锚):^,$,\b,\B,(?=p),(?!p)
在ES6中,共有2个位置(锚):(?<=p),(?<!p)
例:var regExp = /(?<=a)(?<!a)/g相应解释为:以a开头,不以a开头
\b是单词边界,具体就是\w与\W之间的位置,也包括\w与^之间的位置,\w与%之间的位置。
比如考查文件名"[JS]Lesso_01.mp4"中的\b,如下
var result="[JS]Lesso_01.mp4.replace(/\b/g,'#')";
console.log(result);//=>"[#JS#]#Lesso_01#.#mp4#"
\B就是非单词边界,例如在字符串中所有位置中,扣掉\b,剩下的都是\B.j具体来说就是\w与\w、\W与\W、^与\W、\W与$之间的位置。
比如上面的例子,把所有\B替换成“#”如下
var result="[JS]Lesso_01.mp4.replace(/\b/g,'#')";
console.log(result);//=>"#[J#S]#L#e#s#s#o#_#0#1.m#p#4#"
(?=p),其中p是一个子模式,即p前面的位置,或者说,该位置后面的字符要匹配p
比如(?=l),表示"l"字符前面的位置,例如
var result="hello".replace(/(?=l)/g,'#');
console.log(result);//=>"he#l#lo"
//而(?!p)就是(?=p)的反面意思,比如:
var result="hello".replace(/(?!l)/g,'#');
console.log(result);//=>"#h#ell#o#"
二者的学名分别是positive lookahead【正向先行断言】和negative lookahead【负向先行断言】ES之后的版本,会支持positive lookbehind(?<=p)和negative lookbehined(?<!p)。
比如(?=p),一般都理解成:要求接下来的字符与p匹配,但不能包括p匹配的那些字符。(?=p)就与^一样好理解,就是p前面的那个位置。
总结:
正则表达式的修饰符:
| 修饰符 | 简介 |
|---|---|
| i | 忽略大小写 |
| g | 全局匹配 |
| m | 多行匹配 |
正则表达式的API:
conmpile:编译正则表达式
exec:检索字符串中的值,返回找到值,并确定位置
test:检索字符串中指定的值,返回true和false
常见的正则表达式:
| 常见的正则 | 作用 |
|---|---|
| Email地址 | ^\w+([-+.])\w*@\w+([-.]\w+)*\.\w+([-.]\w+)*$ |
| 域名 | [a-zA-Z0-9][-a-zA-Z0-9]{0,62}(/.[a-zA-Z0-9][a-zA-Z0-9{0,62}])+/.? |
| internetURL | [a-zA-Z]+://[^\s]*或^http://([\w-]+\.)+[\w-]+(/[\w-./?%&=]*)?$ |
| 18位省份证号码 | ^((\d{18}|([0-9x]{18})|([0-9x]){18}))$ |
| 账号是否合法(字母开头,允许开头,允许5-16字节,允许字母数字下划线) | ^[a-zA-Z][a-zA-Z0-9_]{4,15}$ |
| 密码(以字母开头,长度在6-18之间,只能包含字母,数字和下划线) | ^[a-zA-Z]\w{5,17}$ |
| 日期格式 | ^\d{4}-\d{1,2}-\d{1,2} |
| 中文字符 | [\u4e00-\u9fa5] |
| 空白行(可以用来删除空白行) | \n\s*\r |
| 收尾空白字符(可以用来删除行首行尾的空白符(空格,制表符,换页符等)) | ^\s*|\s*$或(^\s*)|(\s*$) |
| qq号 | [1-9] [0-9]{4,} |
| 中国邮政编码 | [1-9\d{5}(?!\d)] |
| IP地址 | \d+\.\d+\.\d+\.\d+ |

















 2720
2720

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









