



 本文深入解析Java集合框架,包括List、Set、Queue、Map的主要实现类如ArrayList、LinkedList、Vector、HashSet、TreeSet、HashMap、ConcurrentHashMap的底层数据结构、特性及应用场景,对比线程安全与效率的权衡。
本文深入解析Java集合框架,包括List、Set、Queue、Map的主要实现类如ArrayList、LinkedList、Vector、HashSet、TreeSet、HashMap、ConcurrentHashMap的底层数据结构、特性及应用场景,对比线程安全与效率的权衡。
Collection整体结构
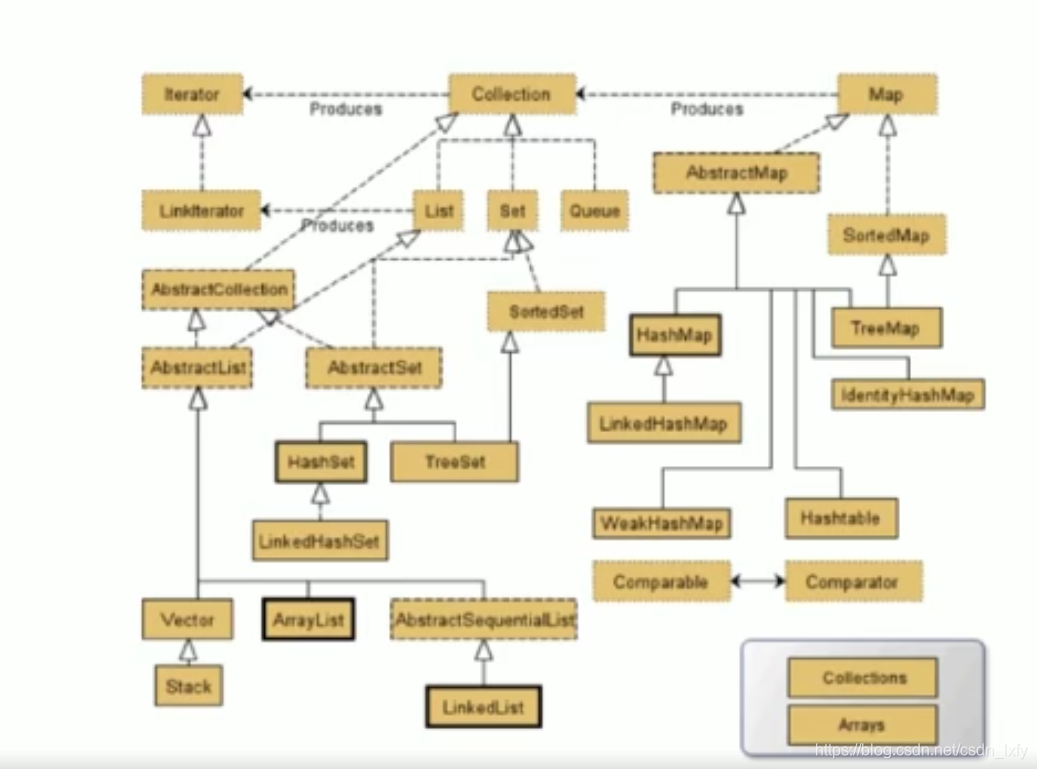
主要分为俩部分
- 继承自Collection的List、Set、Queue,常见的有ArrayList、LinkedList、Vector
- 继承自Map的各种Map,常见的有HashMap、HashTable、ConcurrentHashMap
#关于List与Set的区别

ArrayList源码分析总结
- 底层数数组实现,源码中定义属性 transient Object[] elementData;利用该数组存放数据
- 初始化数组大小是10,通过属性DEFAULT_CAPACITY = 10;
- ArrayList中的add与remove方法均为进行同步处理,故非线程安全的
- 正因为其线程不安全,故执行效率高
- 因为底层是数组,故而查询快,可以根据索引查询,且有序,增删慢,因为往头部增加一个元素会涉及后续所有元素的移动
- 因为数据需要的内存空间是连续的,所以ArrayList也是
- 每次动态扩容的时候调用grow()方法,扩展的执行方法是
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + (oldCapacity >> 1); //重点为该行,原数组大小右移一位则相当于/2,则每次扩容后的大小为之前的1.5倍
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);
}
Vector总结
- vector底层也为数组,源码中定义属性protected Object[] elementData;用于保存数据
- vector的初始化容量也为10,其通过在构造函数中调用this.(10),最终调用2个参数的构造函数完成初始化
- vector是线程安全的,因为其方法上均加入的Synchronized修饰
- 其他主要特性与ArrayList相同
- vector的扩容也调用的grow()方法,扩容逻辑如下
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + ((capacityIncrement > 0) ?
capacityIncrement : oldCapacity);//重点为此行,默认capacityIncrement=0,则默认情况下扩容的大小为之前的2倍
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
elementData = Arrays.copyOf(elementData, newCapacity);
}
LinkedList总结
- 底层数据结构是链表,有俩个属性Node first与Node last,用来表示首尾
- add(E)方法调用linkLast(E) 方法,默认加数据添加到链表尾部、
- LinkedList因为底层数据链表结构,查询较慢,增删较快
- LinkedList依旧是线程不安全的
- Node静态内部类的结构如下
private static class Node<E> {
E item;
Node<E> next; //指向下一个节点
Node<E> prev; //指向上一个节点
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
HashSet总结
- HashSet底层是HashMap
- 数据不可重复,但是无序的
- 其底层实现原理是将需要存储的元素以Key的形式存储在HashMap中
- 通过key.hashcode()与equals()保证key的唯一性
- 扩容方式与HashMap一致
TreeSet总结
- 底层是TreeMap,默认也为16
- TreeSet中的所有元素均要实现Comparator接口
- TreeMap底层实现是二叉树
- TreeSet实现集合有序主要依赖于Comparator接口,主要实现方式有俩种
- 自然排序,让对象所属的类去实现Compareable接口,重写compareTo方法
- 新建比较器类,实现Comparator接口,具体实现如下:
package com.bdcloud.Bean;
import com.bdcloud.compare.MyCompare;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import java.util.TreeSet;
@Data
@NoArgsConstructor
@AllArgsConstructor
public class MyCustomer {
private String name;
private int age;
public static void main(String[] args) {
MyCustomer o1 = new MyCustomer("lxf",10);
MyCustomer o2 = new MyCustomer("yqq",15);
MyCustomer o4 = new MyCustomer("yqq",15);
MyCustomer o3 = new MyCustomer("zyl",48);
//重新一个比较器
TreeSet<MyCustomer> treeSet = new TreeSet<>(new MyCompare());
treeSet.add(o1);
treeSet.add(o2);
treeSet.add(o3); treeSet.add(o4);
for (MyCustomer co:
treeSet) {
System.out.println(co.getName());
}
}
}
---------------------------------
package com.bdcloud.compare;
import com.bdcloud.Bean.MyCustomer;
import java.util.Comparator;
/***
** 比较类具体实现
***/
public class MyCompare implements Comparator<MyCustomer> {
@Override
public int compare(MyCustomer o1, MyCustomer o2) {
return o1.getName().compareTo(o2.getName());
}
}
HashMap总结
- HashMap底层实现是数组+链表+红黑树
- 链表树形化的阈值是8,通过属性static final int TREEIFY_THRESHOLD = 8;指定
- 链表反树形化的阀值是6,通过属性static final int UNTREEIFY_THRESHOLD = 6;指定
- HashMap的默认大小是16,通过static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16指定
- HashMap通过负载因子控制何时需要扩容,static final float DEFAULT_LOAD_FACTOR = 0.75f;其意义为当桶的容量超过75%时,则需要扩容
- HashMap的hash()函数,为减少hash碰撞,将key.hashcode()的值右移16位在与原hashcode()值进行异或
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
- HashMap的get方法通过(n - 1) & hash来获取Key值对应的桶的位置,然后判断第一key与查找的是否相同,若相同则返回,若不同则判断firt.next()节点是否为空,若不为空,通过instance of判断下一个节点是否已经树形话,若是已经树形化,则通过getTreeNode()方法获取,若为树形化,则遍历找个桶对应的链表,一一对照返回
- HastMap的put方法中调用putVal()方法,具体执行步骤如下:
- 第一步先判断table(存放Node的数组)是否为空,若为空则进行hashMap的初始化
- 第二步判断通过key hash计算的桶的位置的值是否为空,若为空,则直接新建一个Node存入该位置上
- 第三步判断通的位置上有值,且当前桶的key与put的key一致,则将该值进行覆盖
- 第四步判断该桶的第一个值是否instance of TreeNode,若是,则调用putTreeVal()方法
- 第五步遍历桶对应的链表,新建Node并插入,插入后判断是否达到树形化的阈值,若达到,则进行树形化
- 第六部判断当前的size是否大于16*0.75,若大于则进行扩容操作,resize()方法
- 最后若均为查找到则返回null
ConcurrentHashMap总结
- ConcurrentHashMap底层实现是数组+链表+红黑树
- ConcurrentHashMap是通过CAS+Synchronized实现线程安全的
- ConcurrentHashMap的默认大小也是16,负载因子0.75,扩容也是原来的size()<<1,扩容2倍
- ConcurrentHashMap的put方法,内部调用的putVal()方法
- 第一步遍历table数组,若是table数组为空,则执行数组初始化
- 第二步判断桶的位置上是否有值,若没值的话则使用casTabAt添加值,若失败,则重新添加
- 第三步判断一下fh是否是MOVE状态,若为该状态则调用helpTransfer帮助转换
- 第四步则出现hash碰撞后先锁住桶bucket,使用Synchronized包住
- 第五步,如果fh>0,则循环遍历链表. 插入该Node
- 第六步,如果f instance TreeBean,则按照树的方式插入
- 第七步,如果链表中的个数大于TREEIFY_THRESHOLDD,则进行树形化

















 947
947

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









