



 本文详细介绍了K-Means聚类算法的工作原理,包括簇分类和聚类中心移动的过程,探讨了优化目标和随机初始化策略,以及如何选择合适的K值,并提供了避开局部最优解的方法。
本文详细介绍了K-Means聚类算法的工作原理,包括簇分类和聚类中心移动的过程,探讨了优化目标和随机初始化策略,以及如何选择合适的K值,并提供了避开局部最优解的方法。
1.K-Means要完成的事情
1.1簇分类
遍历所有数据,判断其与聚类中心点的距离,将与划分到与其最近的点的一类
1.2移动聚类中心
将K个聚类中心点移动到其所在点的均值处

若出现某一个聚类中心点没有点,要么重新初始化所有的据类中心点,要么删除该点,根据实际情况选择
2.优化目标

3.如何随机初始化?如何避开局部最优?
保证K<m,然后从训练样本中随机挑选K个样本作为聚类中心点。(k在2-10之间时,多次随机初始化可以得到局部最优,大于10后,多次随机初始化的效果不太好)

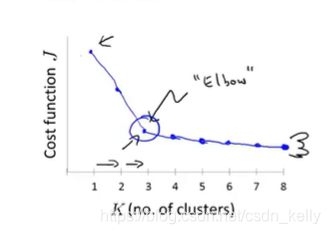
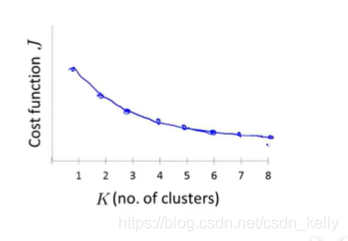
4.如何选择K的值?
观察可视化的图、聚类算法的输出等,但是K的值并不唯一
肘部法则:从k=1开始依次递增,画出k与代价函数J的折线图,找到曲线类似肘子的位置即为合理的分类数量,理想情况下如左图,但实际会出现右图的情况,这时这个方法就不适用了。最好的方法就是根据实际需要来确定。

















 530
530

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









