



解放双手!达梦 GROUP BY 不再需要“复制黏贴”所有字段
背景信息
对于达梦数据库,可能大部分开发者使用的不多,通常一些企业会使用开源的Mysql 数据库。因此有的项目需要使用达梦数据库时,从Mysql 数据库切换到达梦数据库之后,在SQL语句操作上总有一些奇怪的地方。不知道大家有没有注意,在使用Mysql 的 GROUP BY 语句时,我们只需要对我们的目标字段添加 GROUP BY 分组,而达梦数据库则需要对所有非聚合字段添加 GROUP BY ,是不是很奇怪,并且也很不方便。当查询的字段很多时,遇到 GROUP BY 更是苦不堪言,需要将多有的字段复制黏贴在 GROUP BY 后面。
那么,有没有可以不用复制黏贴所有字段,就像Mysql 的 GROUP BY 那样,直接复制黏贴目标字段就可以呢?答案:有的。他就是 /+ GROUP_OPT_FLAG(1)/ 。
GROUP BY
下面我们来简单举个例子,来为大家展示一下Mysql 数据库和 达梦数据库 在用到 GROUP BY 时的不同之处。
Mysql 场景
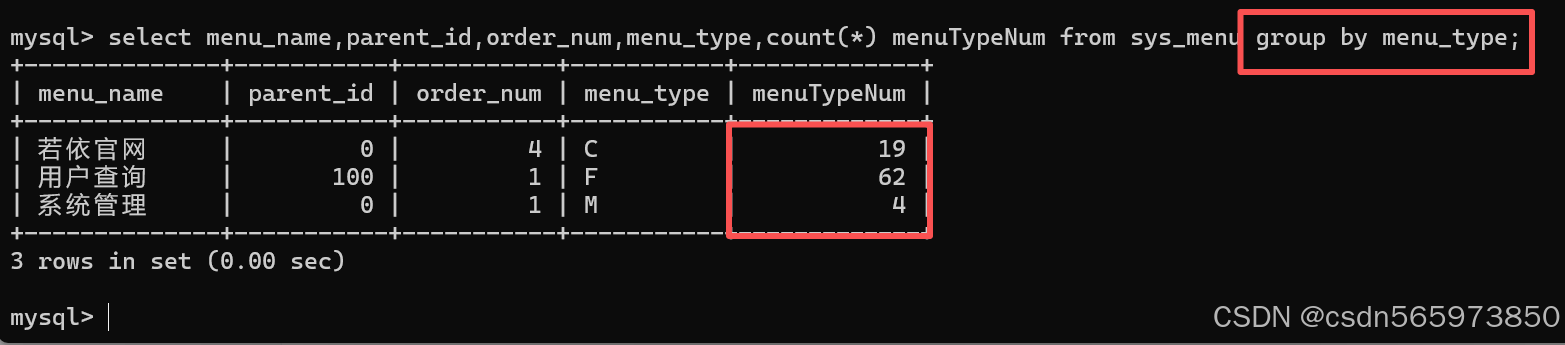
在Mysql 查询场景下,这里我们需要对我们的 菜单表 sys_menu 按照菜单类型 menu_type 分组统计每种菜单类型下的菜单数量,sql语句如下
select menu_name,parent_id,order_num,menu_type,count(*) menuTypeNum from sys_menu group by menu_type;
执行结果如下,我们可以看到不同的 menu_type 对应不同数量的菜单类型数据
达梦场景
下面我们再来看一下,当达梦数据库遇到需要用到 GROUP BY 统计数量或者使用聚合函数时,又是怎样的一种情况呢?同样的,我们来举例说明。
这里我们来统计付款表 t_sett_payment_apply 同一个付款机构下面付款的总额,如果是Mysql 的话,只需要 group by pay_org_id,但是如果是达梦数据库的话,我们就需要这样的sql 语句
select pay_org_id,pay_org_code,pay_org_name,SUM(pay_amount) from t_sett_payment_apply group by pay_org_id,pay_org_code,pay_org_name;
也就是需要将当前需要展示的所有非聚合的字段都作为 GROUP BY 的分组字段复制粘贴再 GROUP BY 后面。执行后的效果就像这样
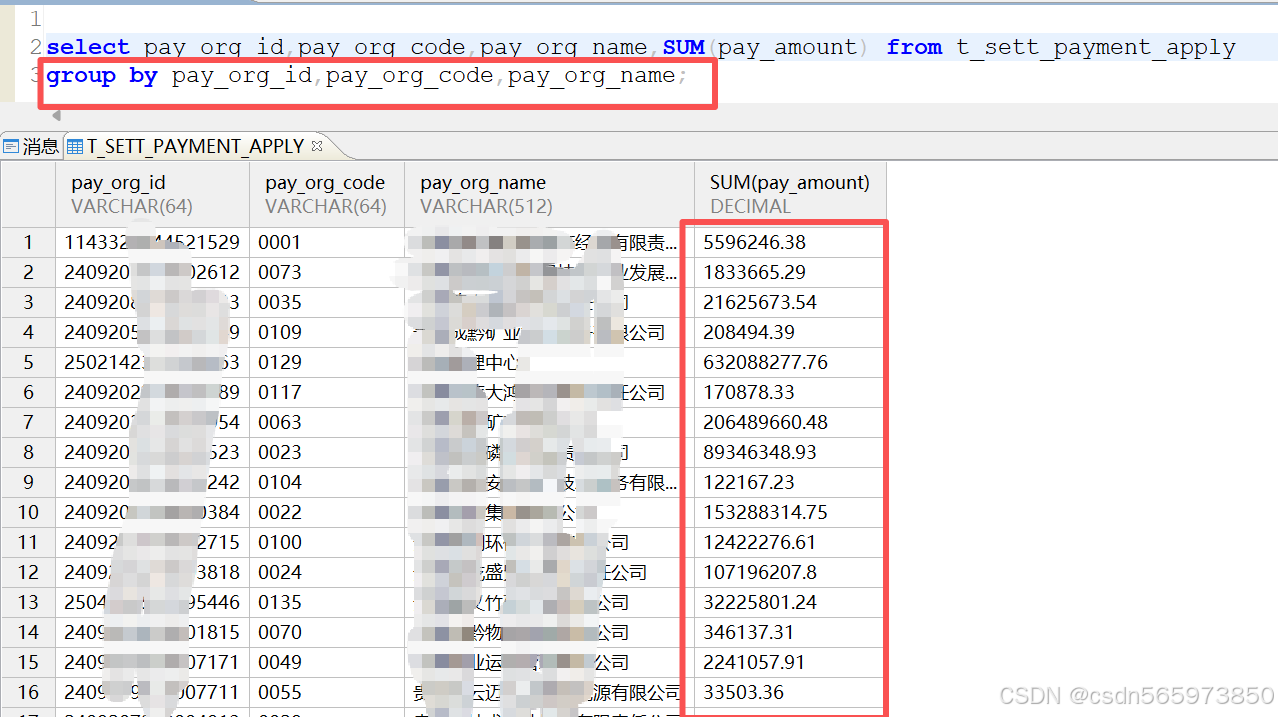
对于达梦数据库来说,这种情况很常见。那么对于这种情况,字段少的时候还能接受,需要展示的非聚合字段多呢,是不是就很烦了。
这种情况在达梦数据库设计的时候也有所考量,就是下面的达梦SQL 调优介绍。
达梦SQL调优
DM 查询优化器采用基于代价的方法。在估计代价时,主要以统计信息或者数据分布为依据。通常情况下,估计的代价都是准确的。但在一些估算代价的依据极度缺乏的情况下,例如:缺少统计信息、或统计信息陈旧、或抽样数据不能很好地反映数据分布时,优化器选择的执行计划不是最优的,甚至可能是很差的执行计划。
然而 DBA 对于数据分布是很清楚的,并且知道 SQL 语句按照哪种方法执行会最快。在面临上述优化器选择的执行计划不是最优的情况下,DBA 可以主动进行人工干预,指示优化器按照指定的方法去选择 SQL 的执行计划。
这种人工干预优化器的方法称为 HINT。优化器可根据 DBA 的 HINT 提示来生成指定的执行计划。如果优化器无法根据给定的 HINT 生成相应的执行计划,那么将忽略该 HINT。
HINT 的常见格式如下所示:
SELECT /*+ HINT1 [HINT2]*/ 列名 FROM 表名 WHERE_CLAUSE ;
UPDATE 表名 /*+ HINT1 [HINT2]*/ SET 列名 =变量 WHERE_CLAUSE ;
DELETE FROM 表名 /*+ HINT1 [HINT2]*/ WHERE_CLAUSE ;
我们要介绍的 /+ GROUP_OPT_FLAG(1)/ 就是 HINT 中的一种。
需要注意的是:如果 HINT 的语法没有写对或指定的值不正确,DM 并不会报错,而是直接忽略 HINT 继续执行。
[-4080]: 不是 group by 表达式
对于刚开始使用达梦数据库的开发者来说,相信大家在使用达梦数据库 GROUP BY 的时候,经常会看到这样的错误提示,就像这样:我想要对表的 币种字段 CURRENCY_CODE 分组计算不同币种下的金额,sql语句以及执行效果就像这样
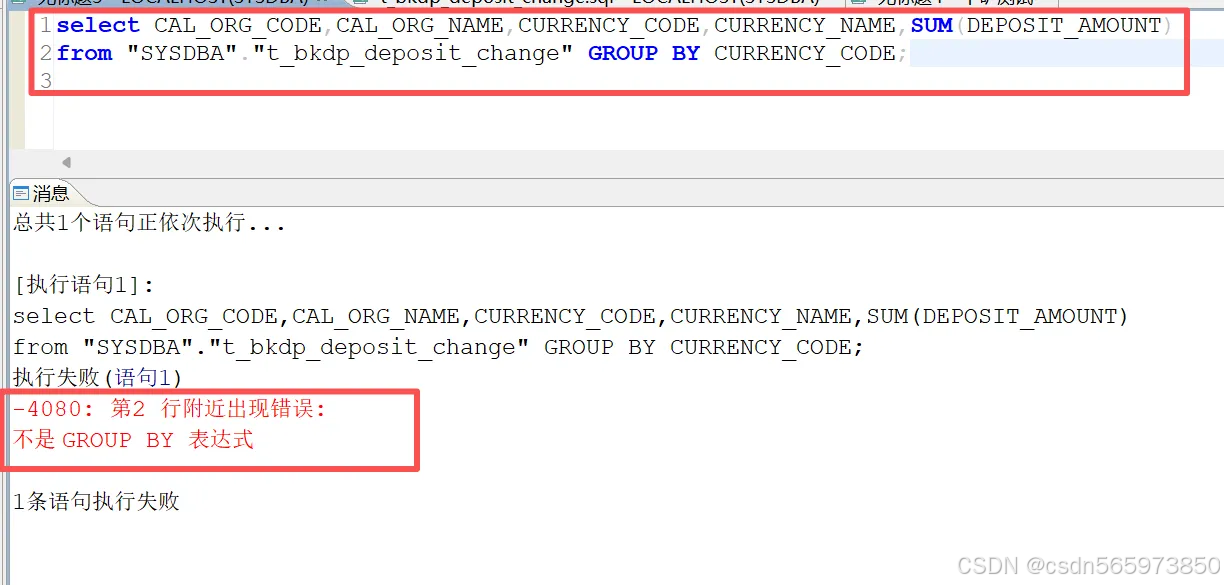
为什么会这样,就是因为达梦数据库语法的特殊之处,对于 GROUP BY 语句,需要将非聚合的字段都放在 GROUP BY 后面,就像这样
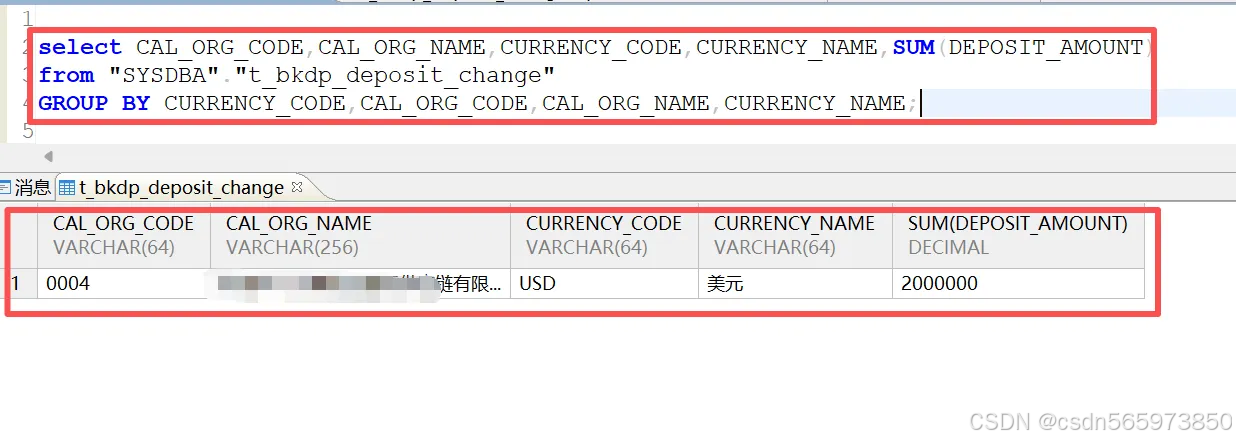
那么不想把所有查询的字段都复制粘贴到 GROUP BY 语句后面,就可以用到我们今天的 /+ GROUP_OPT_FLAG(1)/。
这里需要注意的是:
-
GROUP BY 和 ORDER BY 一起使用时,ORDER BY 要在 GROUP BY 的后面。
-
GROUP BY 后面必须有 ORDER BY 的字段。
-
在 select 需要查询的语句中选中的字段,必须出现在 GROUP BY 子句中。
/+ GROUP_OPT_FLAG(1)/
为了可以满足我们的需求,官方提出了几种方法:

最常用的就是像我们这样的,比如针对我们上面按照机构统计付款金额的语法sql 如下
select /*+ GROUP_OPT_FLAG(1)*/pay_org_id,pay_org_code,pay_org_name,SUM(pay_amount) from t_sett_payment_apply
group by pay_org_id;
执行后的效果如图,就和我们在 Mysql 中使用ORDER BY 的感觉一样了
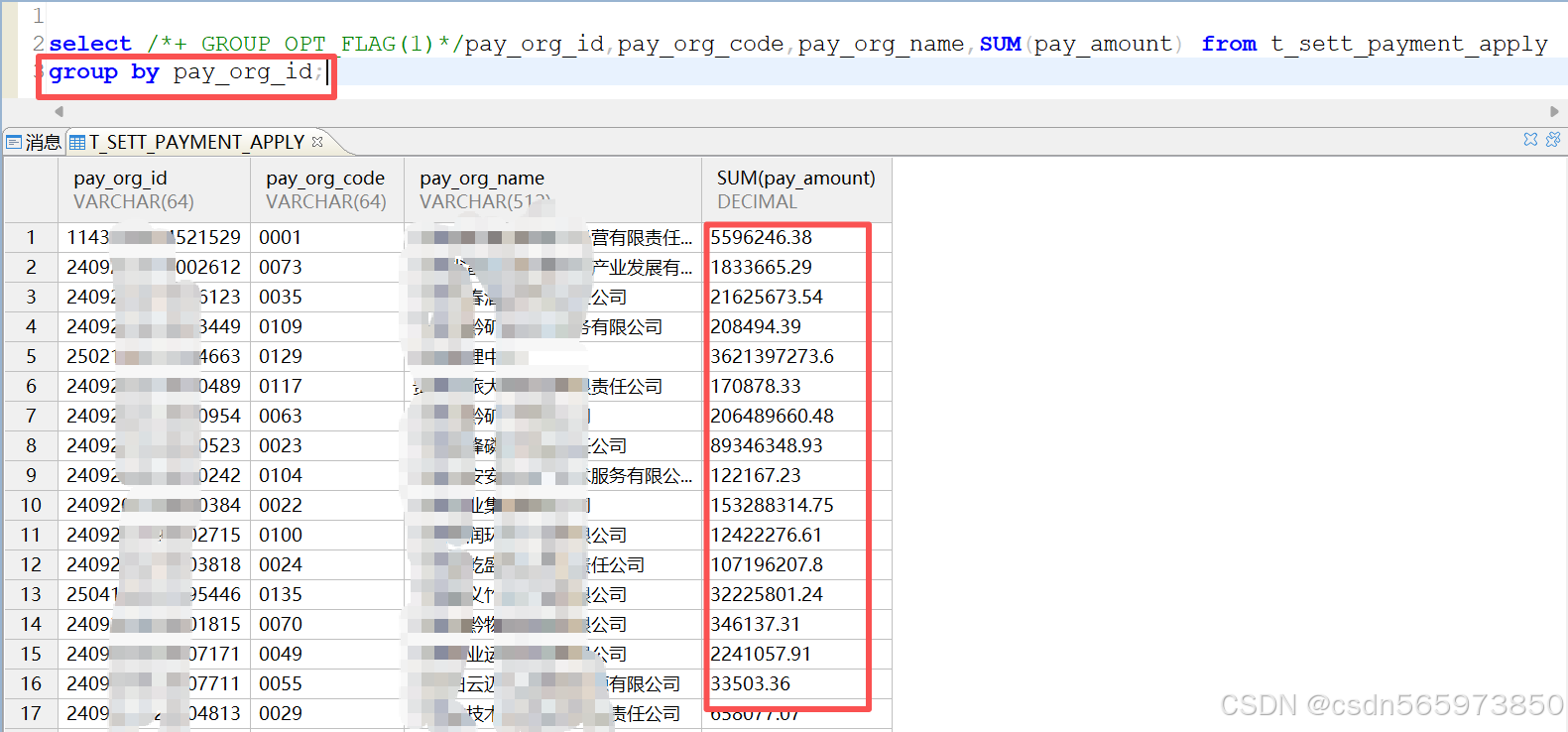
通过在select 语句中添加 /+ GROUP_OPT_FLAG(1)/ 来避免重复列出所有字段。
GROUP_OPT_FLAG Hint 详解
基本语法如下
SELECT /*+ GROUP_OPT_FLAG(1) */ * FROM table_name GROUP BY column;
-- 或者
SELECT /*+ GROUP_OPT_FLAG(1) */ column1, COUNT(*)
FROM table_name
GROUP BY column1;
参数含义:
GROUP_OPT_FLAG 接受不同的参数值,每个值代表不同的分组优化策略:
- GROUP_OPT_FLAG(0): 使用哈希分组(HASH GROUP)算法
- GROUP_OPT_FLAG(1): 使用排序分组(SORT GROUP)算法
- GROUP_OPT_FLAG(2): 让优化器自动选择最优的分组算法
不同分组算法的适用场景
不同分组算法适用于不同的场景,例如下面的语句
-- 1. 数据量较小且需要有序结果时,使用排序分组
SELECT /*+ GROUP_OPT_FLAG(1) */
product_category,
SUM(sales) as total_sales
FROM sales_data
GROUP BY product_category
ORDER BY product_category; -- 排序分组后结果自然有序
-- 2. 数据量较大时,使用哈希分组可能更高效
SELECT /*+ GROUP_OPT_FLAG(0) */
customer_id,
COUNT(*) as order_count
FROM orders
GROUP BY customer_id;
-- 3. 让优化器自动选择
SELECT /*+ GROUP_OPT_FLAG(2) */
year, month,
SUM(revenue) as monthly_revenue
FROM financial_data
GROUP BY year, month;
实际应用建议
在实际应用中,我们也可以针对不同的应用情况来具体使用 Hint 例如下面的语句
-- 场景1:分组后需要排序的情况,使用排序分组更高效
SELECT /*+ GROUP_OPT_FLAG(1) */
region,
SUM(sales) as regional_sales
FROM sales
GROUP BY region
ORDER BY region;
-- 场景2:大数据量且分组键分布均匀,使用哈希分组
SELECT /*+ GROUP_OPT_FLAG(0) */
user_id,
COUNT(DISTINCT product_id) as unique_products
FROM user_behavior
GROUP BY user_id;
-- 场景3:复杂的多表连接分组
SELECT /*+ GROUP_OPT_FLAG(1) */
d.department_name,
j.job_title,
COUNT(e.employee_id) as employee_count
FROM employees e
JOIN departments d ON e.department_id = d.department_id
JOIN jobs j ON e.job_id = j.job_id
GROUP BY d.department_name, j.job_title;
最后总结
在达梦数据库中使用 /+ GROUP_OPT_FLAG(1)/ Hint 可以有效解决 GROUP BY 语法严格性的问题,让达梦数据库能够像 MySQL 一样只对目标字段进行分组,而不需要将所有非聚合字段都列在 GROUP BY 子句中。这个 Hint 通过强制使用排序分组算法,绕过了达梦数据库默认的严格语法检查,既避免了繁琐的字段复制粘贴,又能在分组后需要排序的场景中提升性能。虽然这原本是用于优化分组算法选择的调优手段,但在实际应用中成为了解决 GROUP BY 语法兼容性问题的有效变通方案,特别适合从 MySQL 迁移到达梦数据库或需要简化复杂分组查询的场景。


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











