



目录
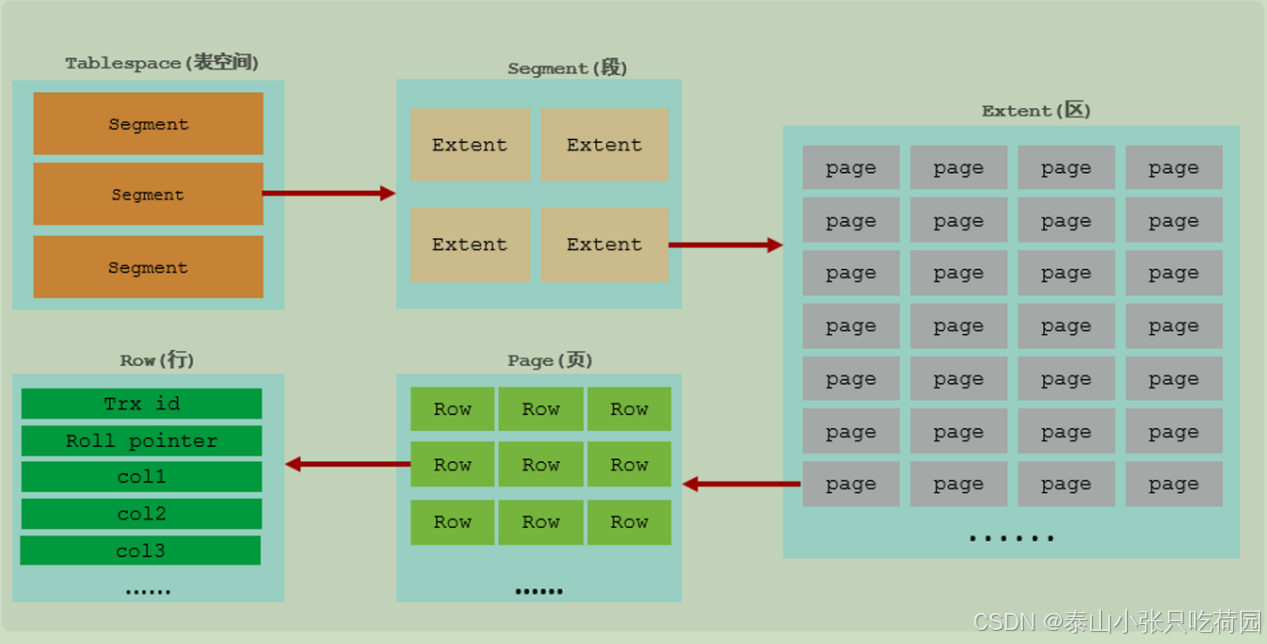
1.逻辑存储结构(表-段-区-页-行)
2.架构
2.1概述
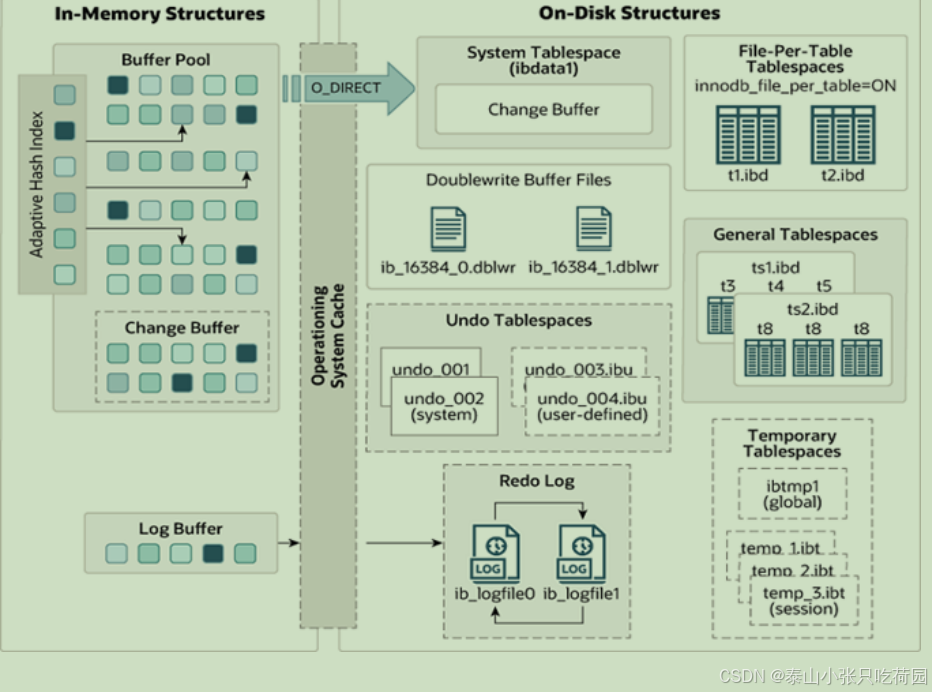
2.2内存结构

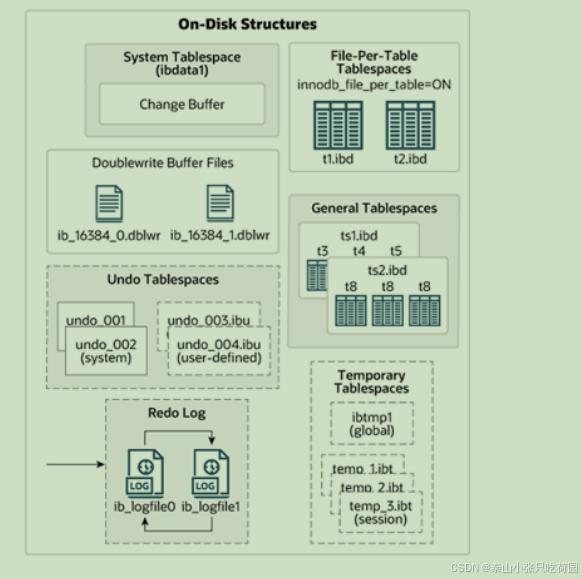
2.3磁盘结构
接下来,再来看看InnoDB体系结构的右边部分,也就是磁盘结构:
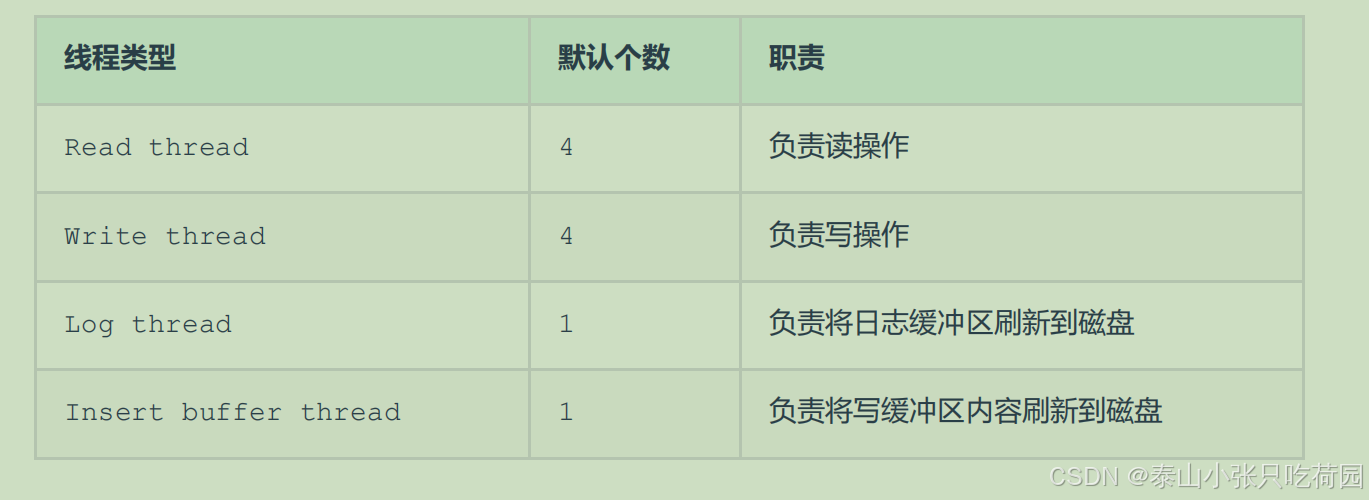
CREATE TABLESPACE ts_name ADD DATAFILE 'file_name' ENGINE = engine_name;CREATE TABLE xxx ... TABLESPACE ts_name;2.4 后台线程
show engine innodb status \G;3.事务原理
3.1事务基础(ACID)
在了解InnoDB引擎实现事务之前,先了解一下事务是什么。
3.2 redo log(保证事务的持久性)
重做日志,记录的是事务提交时数据页的物理修改,是用来实现事务的持久性。
该日志文件由两部分组成:重做日志缓冲( redo log buffer)以及重做日志文件(redo log
file) ,前者是在内存中,后者在磁盘中。当事务提交之后会把所有修改信息都存到该日志文件中 , 用 于在刷新脏页到磁盘 ,发生错误时 , 进行数据恢复使用。
如果没有redolog,可能会存在什么问题的? 我们一起来分析一下。
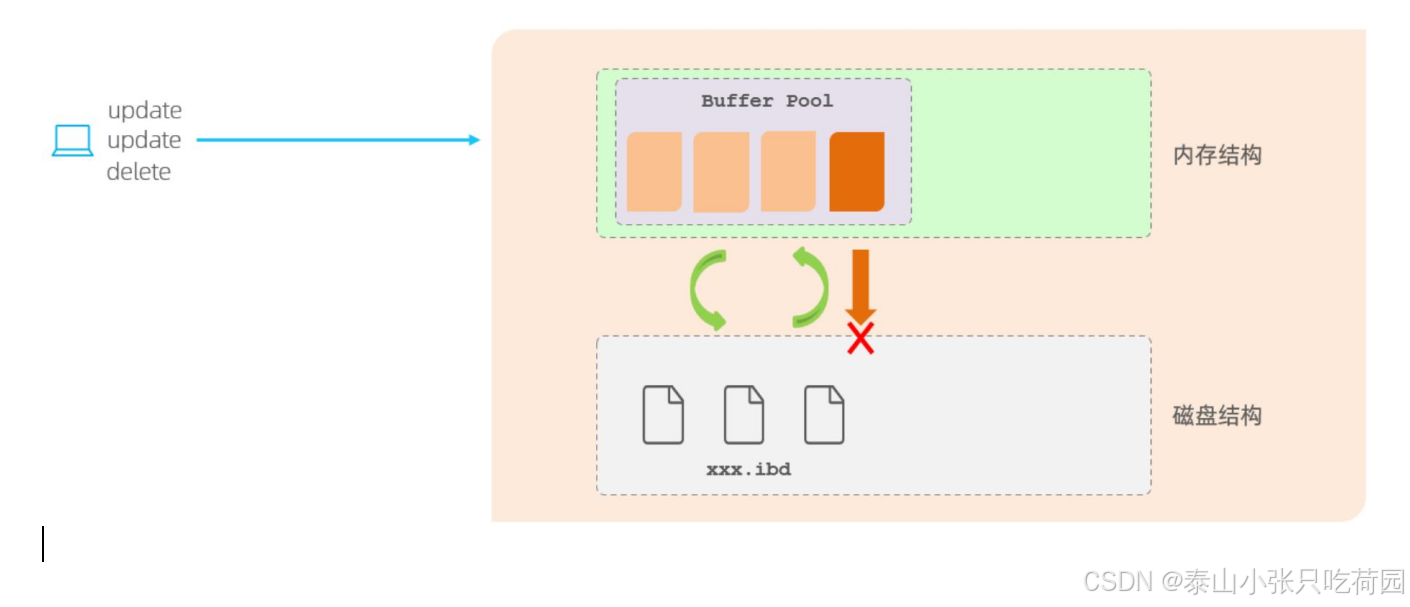
我们知道,在InnoDB引擎中的内存结构中,主要的内存区域就是缓冲池,在缓冲池中缓存了很多的数据页。 当我们在一个事务中,执行多个增删改的操作时, InnoDB引擎会先操作缓冲池中的数据,如果 缓冲区没有对应的数据,会通过后台线程将磁盘中的数据加载出来,存放在缓冲区中,然后将缓冲池中的数据修改,修改后的数据页我们称为脏页。而脏页则会在一定的时机,通过后台线程刷新到磁盘中,从而保证缓冲区与磁盘的数据一致。 而缓冲区的脏页数据并不是实时刷新的,而是一段时间之后 将缓冲区的数据刷新到磁盘中,假如刷新到磁盘的过程出错了,而
提示给用户事务提交成功,而数据却 没有持久化下来,这就出现问题了,没有保证事务的持久性。
上面的文字比较多,我们简单分析以下就是:
Buffer Pool中存放着数据页,我们的增删改操作会先在Buffer Pool中进行,增删改之后的数据页叫做脏页,脏页会在一定时机之后通过后台线程刷新到磁盘中,redo log是为了保证我们在进行脏页刷新发生错误时进行数据恢复,从而保证事务的持久性。
在InnoDB中提供了一份日志 redo log,接下来我们再来分析一 下,通过redolog如何解决这个问题。
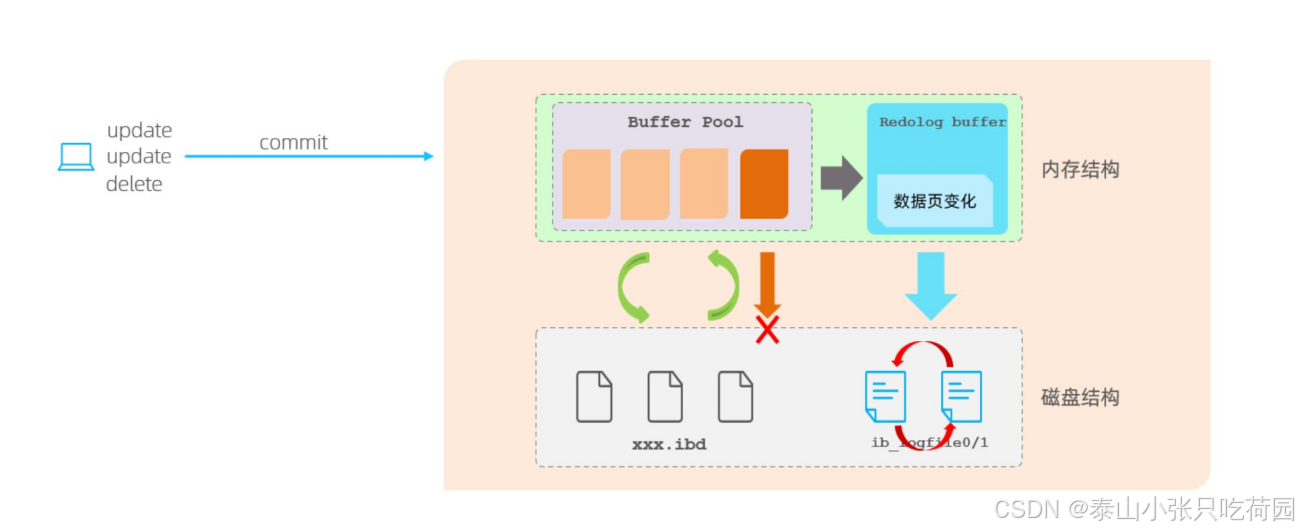
有了redolog之后,当对缓冲区的数据进行增删改之后,会首先将操作的数据页的变化,记录在redo log buffer中。在事务提交时,会将redo log buffer中的数据刷新到redo log磁盘文件中。
过一段时间之后,如果刷新缓冲区的脏页到磁盘时,发生错误,此时就可以借助于redo log进行数据恢复,这样就保证了事务的持久性。 而如果脏页成功刷新到磁盘或者涉及到的数据已经落盘,此时redolog就没有作用了,就可以删除了,所以存在的两个redolog文件是循环写的。
那为什么每一次提交事务,要刷新redo log 到磁盘中呢,而不是直接将buffer pool中的脏页刷新 到磁盘呢 ?
因为在业务操作中,我们操作数据一般都是随机读写磁盘的,而不是顺序读写磁盘。 而redo log在 往磁盘文件中写入数据,由于是日志文件,所以都是顺序写的。顺序写的效率,要远大于随机写。 这 种先写日志的方式,称之为 WAL(Write-Ahead Logging)。
简单来说就是:
有了redo log(内存中的Redolog Buffer + 磁盘中的redo log file)之后,会先将脏页记录在redo log buffer中,在事务提交时,再将redo log buffer 中的数据刷新到redo log file中(内存到磁盘),当脏页刷新磁盘错误时就可以通过redo log进行数据恢复。
3.3 undo log(保证事务的原子性)
回滚日志,用于记录数据被修改前的信息 , 作用包含两个 : 提供回滚(保证事务的原子性) 和 MVCC(多版本并发控制) 。
undo log和redo log记录物理日志不一样,它是逻辑日志。可以认为当delete一条记录时, undo log中会记录一条对应的insert记录,反之亦然,当update一条记录时,它记录一条对应相反的update记录。当执行rollback时,就可以从undo log中的逻辑记录读取到相应的内容并进行回滚。
Undo log销毁: undo log在事务执行时产生,事务提交时,并不会立即删除undo log,因为这些 日志可能还用于MVCC。
Undo log存储: undo log采用段的方式进行管理和记录,存放在前面介绍的 rollback segment 回滚段中,内部包含1024个undo log segment。
3.4 MVCC(多版本并发控制)
在学习MVCC之前,我们需要先了解几个基本概念
3.4.1 基本概念
1)当前读
读取的数据是当前数据的最新版本,在读取的时候保证数据不被其他并发事务所修改。
对于我们日常的操作,如: select ... lock in share mode(共享锁), select ...for update、update、 insert、delete(排他锁)都是一种当前读。
2)快照读
简单的select (不加锁)就是快照读,快照读,读取的是记录数据的可见版本,不一定是最新数据,有可能是历史数据, 不加锁,是非阻塞读。
• Read Committed:每次select,都生成一个快照读。
• Repeatable Read:开启事务后第一个select语句才是快照读的地方。
• Serializable:快照读会退化为当前读。
3). MVCC
全称 Multi-Version Concurrency Control,多版本并发控制。指维护一个数据的多个版本,使得读写操作没有冲突,快照读为MySQL实现MVCC提供了一个非阻塞读功能。 MVCC的具体实现,还需要依赖于数据库记录中的三个隐式字段、 undo log日志、 readView。
接下来,我们再来介绍一下InnoDB引擎的表中涉及到的隐藏字段 、undolog 以及 readview,从而来介绍一下MVCC的原理。
3.4.1 隐藏字段(事务id、回滚指针、隐藏主键)
| id | age | name |
| 1 | 1 | tom |
| 3 | 3 | cat |
当我们创建了上面的这张表,我们在查看表结构的时候,就可以显式的看到这三个字段。 实际上除了这三个字段以外, InnoDB还会自动的给我们添加三个隐藏字段及其含义分别是:
| 隐藏字段 | 含义 |
|---|---|
| DB_TRX_ID | 最近修改事务ID,记录插入这条记录或最后一次修改该记录的事务ID。 |
| DB ROLL PTR | 回滚指针,指向这条记录的上一个版本,用于配合undo log,指向上一个版 本。 |
| DB_ROW_ID | 隐藏主键,如果表结构没有指定主键,将会生成该隐藏字段。 |
而上述的前两个字段是肯定会添加的, 是否添加最后一个字段DB_ROW_ID,得看当前表有没有主键,如果有主键,则不会添加该隐藏字段。
3.4.2 undo log
3.4.2.1介绍
回滚日志,在insert、update、delete的时候产生的便于数据回滚的日志。当insert的时候,产生的undo log日志只在回滚时需要,在事务提交后,可被立即删除。
而update、delete的时候,产生的undo log日志不仅在回滚时需要,在快照读时也需要,不会立即被删除。
3.4.2.2 版本链
有一张表原始数据为:
| id | age | name | DB_TRX_ID | DB_ROLL_PTR |
|---|---|---|---|---|
| 30 | 30 | A30 | 1 | null |
DB TRX ID : 代表最近修改事务ID,记录插入这条记录或最后一次修改该记录的事务ID,是自增的。
DB_ROLL_PTR : 由于这条数据是才插入的,没有被更新过,所以该字段值为null。
然后,有四个并发事务同时在访问这张表。
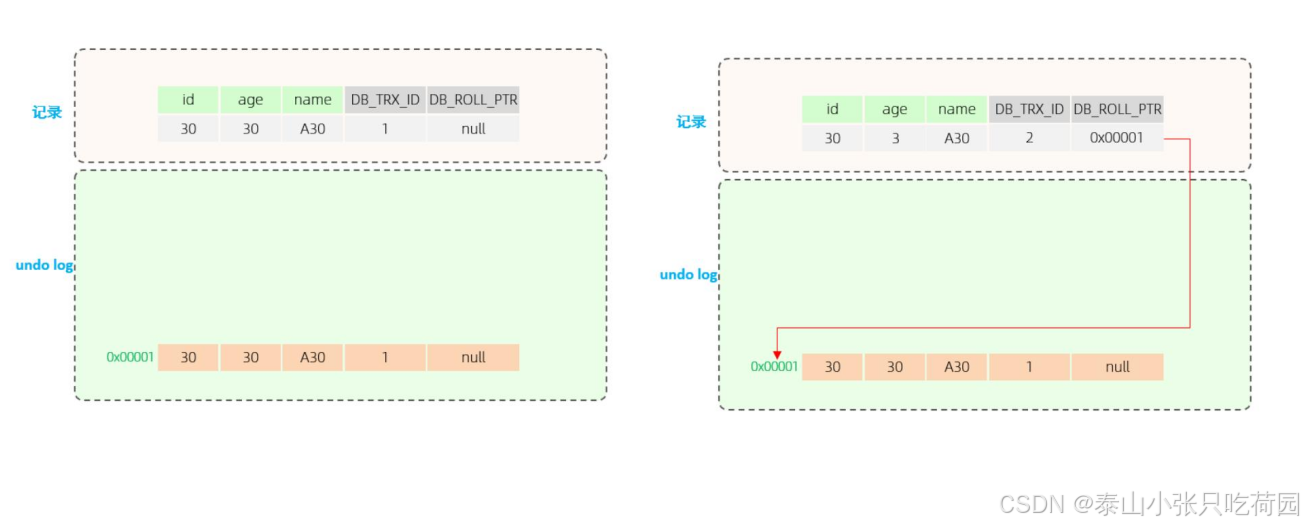
A. 第一步

当事务2执行第一条修改语句时,会记录undo log日志,记录数据变更之前的样子; 然后更新记录, 并且记录本次操作的事务ID,回滚指针,回滚指针用来指定如果发生回滚,回滚到哪一个版本。
B.第二步
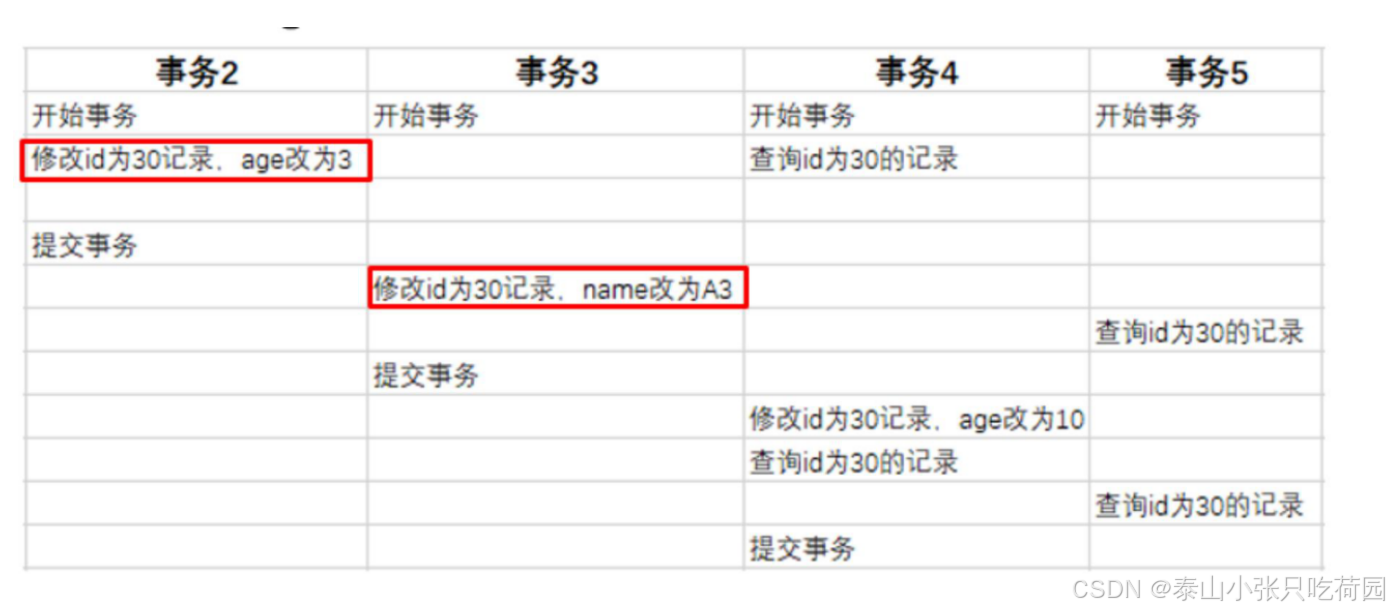
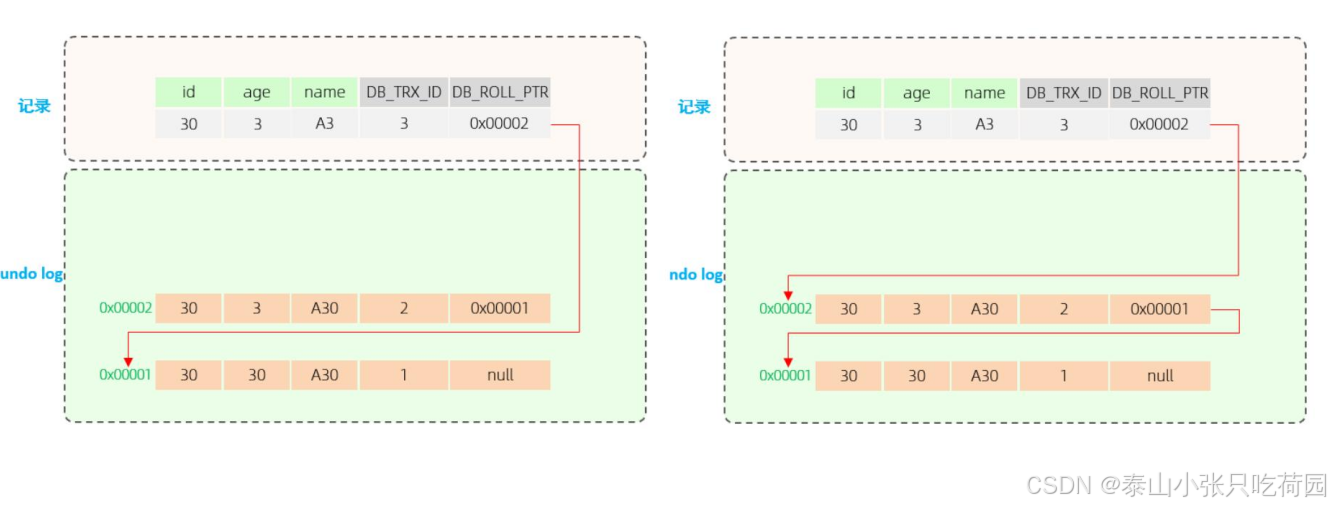
当事务3执行第一条修改语句时,也会记录undo log日志,记录数据变更之前的样子; 然后更新记 录,并且记录本次操作的事务ID,回滚指针,回滚指针用来指定如果发生回滚,回滚到哪一个版本。
C. 第三步
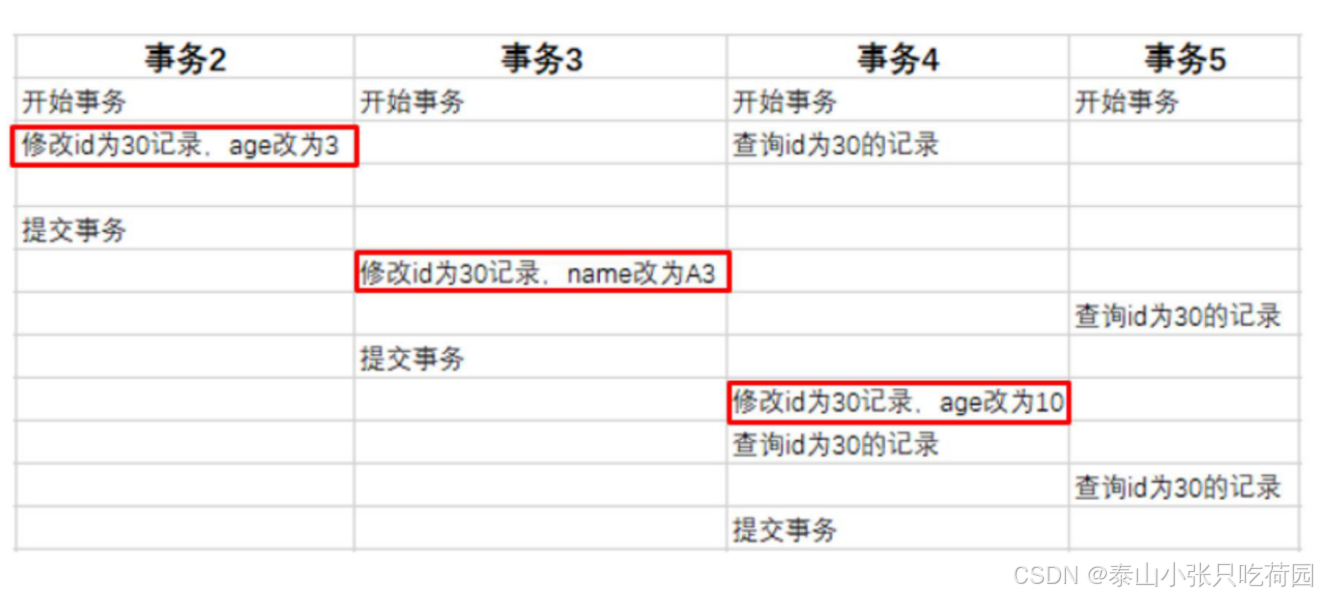
当事务4执行第一条修改语句时,也会记录undo log日志,记录数据变更之前的样子; 然后更新记 录,并且记录本次操作的事务ID,回滚指针,回滚指针用来指定如果发生回滚,回滚到哪一个版本。
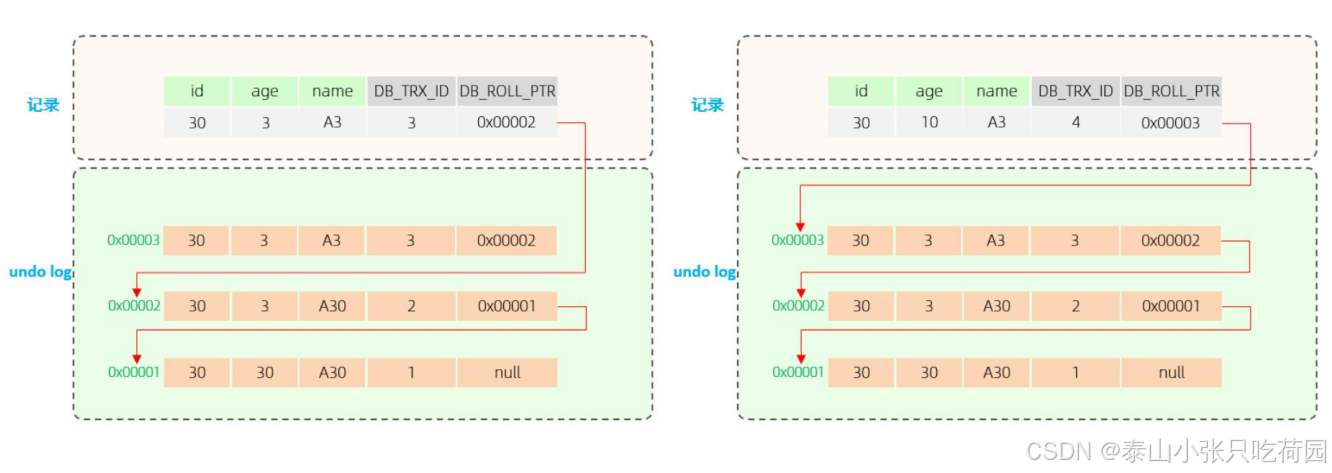
最终我们发现,不同事务或相同事务对同一条记录进行修改,会导致该记录的undolog生成一条
记录版本链表,链表的头部是最新的旧记录,链表尾部是最早的旧记录。
3.4.3 readview
ReadView(读视图)是快照读SQL(普通select语句)执行时MVCC提取数据的依据,记录并维护系统当前活跃的事务 (未提交的) id。
ReadView中包含了四个核心字段:
| 字段 | 含义 |
|---|---|
| m_ids | 当前活跃的事务ID集合 |
| min_trx_id | 最小活跃事务ID |
| max_trx_id | 预分配事务ID,当前最大事务ID+1(因为事务 ID是自增的) |
| creator_trx_id | ReadView创建者的事务ID |
而在readview中就规定了版本链数据的访问规则:
trx_id 代表当前undolog版本链对应事务ID。
如果trx_id == creator_trx_id(trx_id为当前事务自己)或已提交(trx_id<max_trx_id且不在m_ids中就),就可以访问该版本数据。
不同的隔离级别,生成ReadView的时机不同:
READ COMMITTED :在事务中每一次执行快照读时生成ReadView。
REPEATABLE READ:仅在事务中第一次执行快照读时生成ReadView,后续复用该ReadView。
3.4.3.1 RC隔离级别
C隔离级别下,在事务中每一次执行快照读时生成ReadView。
我们就来分析事务5中,两次快照读读取数据,是如何获取数据的?
在事务5中,查询了两次id为30的记录,由于隔离级别为Read Committed,所以每一次进行快照读 都会生成一个ReadView,那么两次生成的ReadView如下。
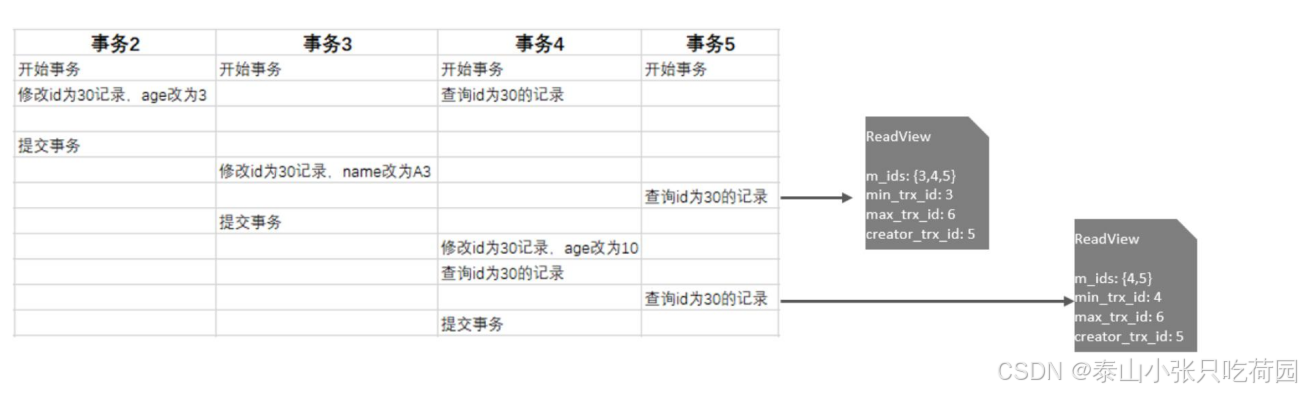
那么这两次快照读在获取数据时,就需要根据所生成的ReadView以及ReadView的版本链访问规则, 到undolog版本链中匹配数据,最终决定此次快照读返回的数据。
以下是这条记录的版本链:
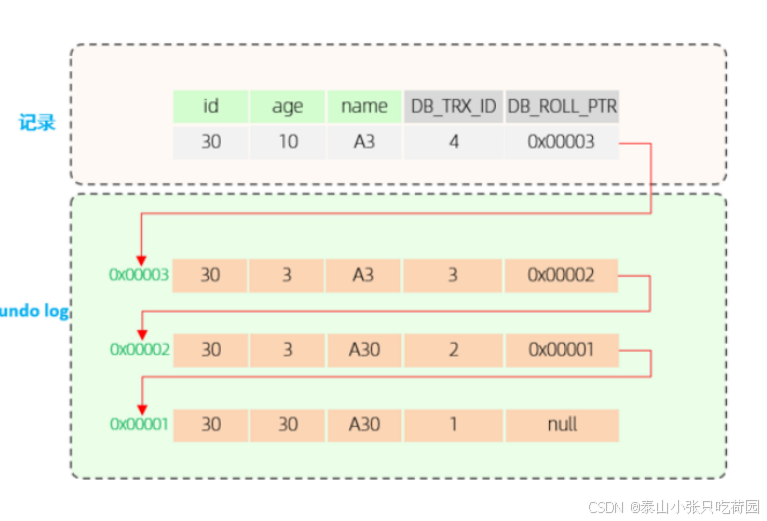
在执行“查询id为30的记录”这条SQL语句时,会从undo log 的版本链,从上到下挨个进行匹配
先匹配下面这一条记录,我们可知道trx_id=4
而4不等于5(creator_trx_id)且4在m_ids中,所以这条记录不是我们该查的记录,继续往下匹配:

此时的trx_id为3,同理这条记录也不是我们该查的记录,继续往下匹配:

此时的trx_id为2,不在m_ids集合中,说明该记录已经提交上去了,这才是我们该查到的记录!
B. 再来看第二次快照读具体的读取过程 :

那么在第二条“查询id为30的记录”这条语句又会查到那一条记录呢?这留给读者自行研究,有疑惑欢迎在评论区提出。
3.4.3.2 RR隔离
RR隔离级别下,仅在事务中第一次执行快照读时生成ReadView,后续复用该ReadView。 而RR 是可重复读,在一个事务中,执行两次相同的select语句,查询到的结果是一样的。 那MySQL是如何做到可重复读的呢? 我们简单分析一下就知道了
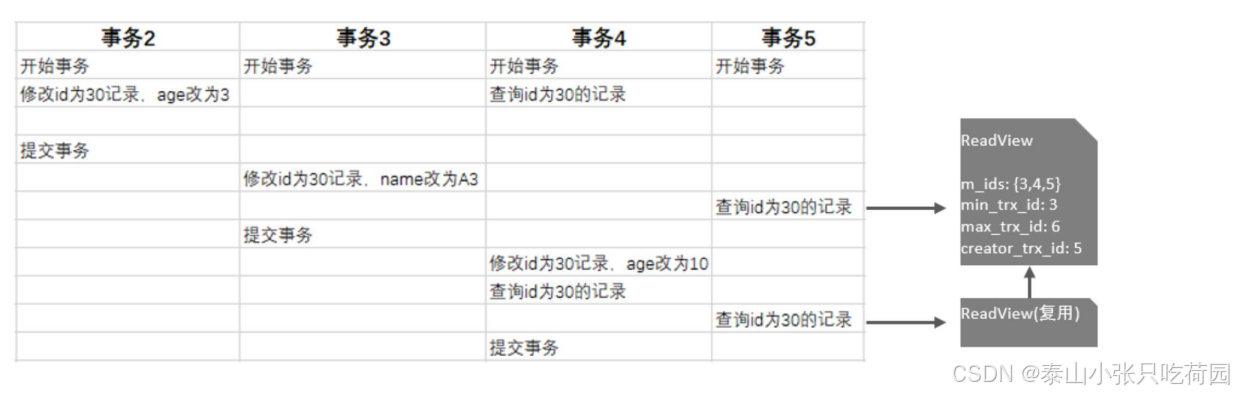
查到的数据匹配规则与RC隔离一样,不再赘述。
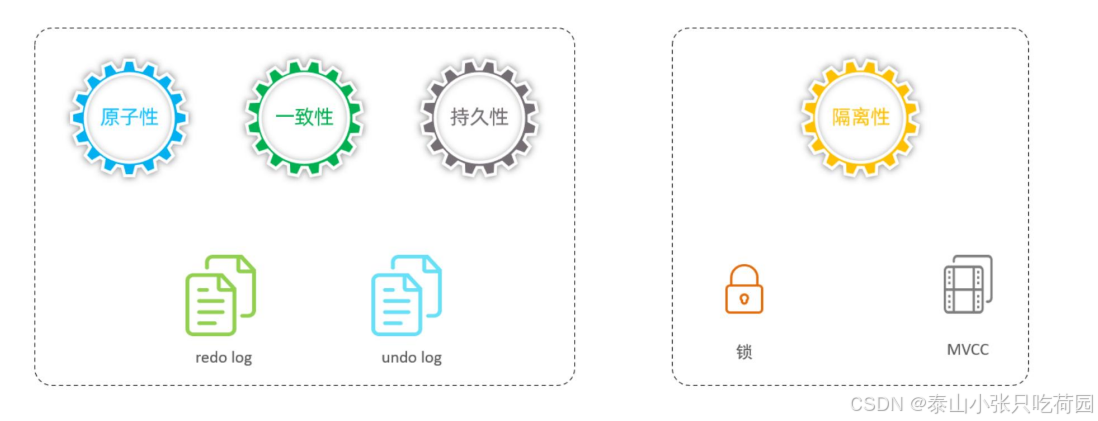
3.5 事务原理小结
MySQL数据库中实现事务主要是实现事务的四大特性
原子性-undo log
持久性-redo log
一致性-undo log+redo log
隔离性-锁+MVCC
关于MySQL数据库中的锁机制,可以参考以下文章:
MySQL数据库中的锁机制(全局锁、表级锁、行级锁)-优快云博客
至此InnoDB存储引擎的学习到此结束,感谢您的阅读,制作不易,点个收藏谢谢。

















 776
776

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









