



提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
前言
视图是一种虚拟存在的表,通过select语句查询一个表或多个表的数据进行拼接成一个新表暂时保存(只保存查询sql逻辑,不保存查询结果)。
一、视图是什么?
视图是一种虚拟存在的表,通过select语句查询一个表或多个表的数据进行拼接成一个新表暂时保存(只保存查询sql逻辑,不保存查询结果),简单来说就是将一张一张的二维关系表组合成一张表,只是存储了数据的集合,视图中数据时根据基表的更新而更新,便于后续查询。
二、视图的作用
1). 简单
视图不仅可以简化用户对数据的理解,也可以简化他们的操作。那些被经常使用的查询可以被定义为视图,从而使得用户不必为以后的操作每次指定全部的条件。
2). 安全
数据库可以授权,但不能授权到数据库特定行和特定的列上。通过视图用户只能查询和修改他们所能见到的数据。
create view stu_v_count as select count(*) from student;
insert into stu_v_count values(10);
3). 数据独立
视图可帮助用户屏蔽真实表结构变化带来的影响。
三、视图的使用
1.视图的语法
1)创建视图
CREATE [OR REPLACE] VIEW 视图名称[(列名列表)] AS SELECT语句 [ WITH [CASCADED | LOCAL ] CHECK OPTION ]2)查询视图
查看创建视图语句:SHOW CREATE VIEW 视图名称;
查看视图数据:SELECT * FROM 视图名称 ...... ;3)修改视图
方式一:CREATE [OR REPLACE] VIEW 视图名称[(列名列表)] AS SELECT语句 [ WITH][ CASCADED | LOCAL ] CHECK OPTION ]
方式二:ALTER VIEW 视图名称[(列名列表)] AS SELECT语句 [ WITH [ CASCADED |LOCAL ] CHECK OPTION ]4)删除视图
DROP VIEW [IF EXISTS] 视图名称 [,视图名称] ...2.视图的检查选项
在我们对视图进行插入的时候,会发现有时候能够插入,有时候插入不了,而是直接插入到基表当中,例如我们创建了以下视图:
create or replace view emp_v_1 as select id ,name from emp where id < 20 ;此时向该视图插入一个id为17和一条id为21的数据,如下:
insert into emp_v_1 values (18,'张三');
insert into emp_v_1 values (21,'李四');此时数据库中的视图如下:
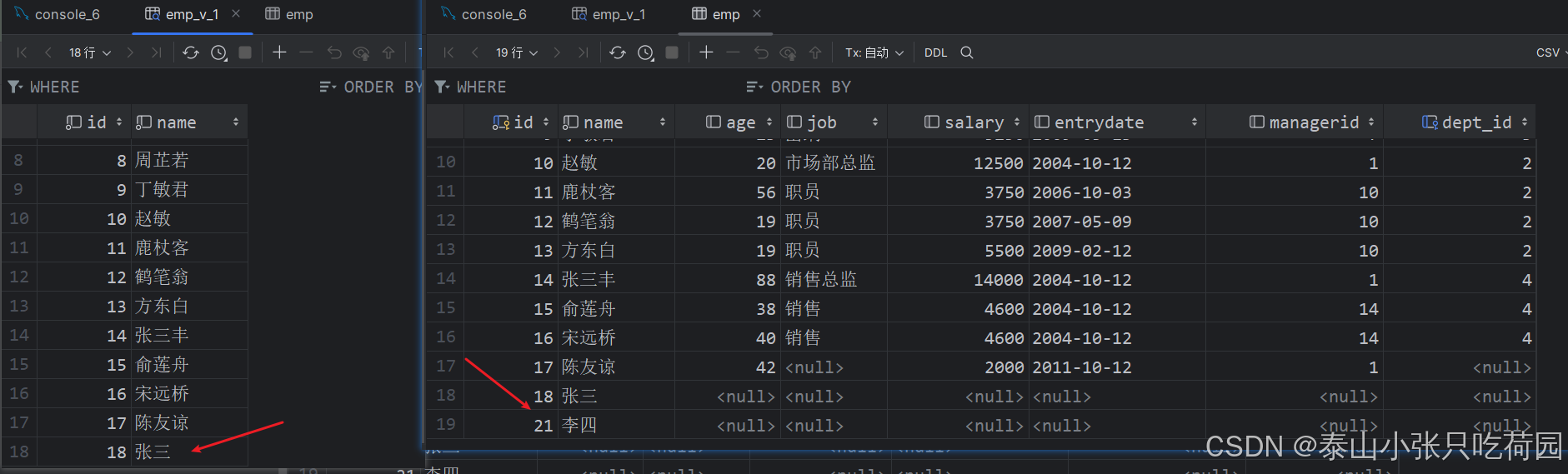
可以看到张三能够在视图中显示,而李四不能在视图中显示,那是因为李四的id为21不符合视图的规则(id<20),因此我们在创建带where条件的视图时可以在后面加上with cascaded check option,如下:
create or replace view emp_v_1
as select id ,name from emp
where id < 20
with cascaded check option ;
此时在执行那两条SQL,就只有张三的SQL能够插入到基表中,李四的SQL插不进去了。
CASCADED(级联)
比如,v2视图是基于v1视图的,如果在v2视图创建的时候指定了检查选项为 cascaded,但是v1视图创建时未指定检查选项。 则在执行检查时,不仅会检查v2,还会级联检查v2的关联视图v1。

LOCAL(本地)
比如,v2视图是基于v1视图的,如果在v2视图创建的时候指定了检查选项为 local ,但是v1视图创建时未指定检查选项。 则在执行检查时,知会检查v2,不会检查v2的关联视图v1。

3.视图的更新
要使视图可更新,视图中的行与基础表中的行之间必须存在一对一的关系。如果视图包含以下任何一项,则该视图不可更新:
A. 聚合函数或窗口函数(SUM()、 MIN()、 MAX()、 COUNT()等)
B. DISTINCT
C. GROUP BY
D. HAVING
E. UNION 或者 UNION ALL

















 1776
1776

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









