



摘要
本文将详细介绍如何使用 Playwright 和 Visual Studio Code (VS Code) 进行自动化测试。Playwright 是一个强大的自动化测试工具,支持多种浏览器和语言,而 VS Code 是开发者广泛使用的代码编辑器。通过结合两者,可以高效地开发和管理自动化测试脚本。文章将涵盖环境搭建、基本用法、高级功能、常见问题解决以及最佳实践等内容,旨在帮助中国开发者,特别是 AI 应用开发者,快速上手并应用到实际项目中。
正文
第一章:环境搭建
1.1 安装 Node.js 和 npm
Playwright 是基于 Node.js 的工具,因此需要先安装 Node.js 和 npm。
# 下载并安装 Node.js
# 官方网站:https://nodejs.org/
1.2 安装 Playwright
在项目目录下运行以下命令安装 Playwright:
npm install @playwright/test
1.3 配置 VS Code
安装 Playwright 插件,以便在 VS Code 中更好地支持 Playwright。
# 在 VS Code 的扩展市场中搜索并安装 Playwright 插件
第二章:Playwright 基本用法
2.1 编写第一个测试脚本
以下是一个简单的 Playwright 测试脚本示例,使用 Python 编写:
# test_example.py
from playwright.sync_api import sync_playwright
def test_example():
"""
简单的Playwright测试示例
"""
with sync_playwright() as p:
# 启动浏览器
browser = p.chromium.launch()
# 创建新页面
page = browser.new_page()
# 访问网站
page.goto("https://example.com")
# 打印页面标题
print(page.title())
# 关闭浏览器
browser.close()
# 运行测试
if __name__ == "__main__":
test_example()
2.2 运行测试
在终端中运行以下命令:
python test_example.py
第三章:高级功能
3.1 测试多浏览器
Playwright 支持多种浏览器,包括 Chromium、Firefox 和 WebKit。以下是一个示例:
from playwright.sync_api import sync_playwright
def test_multi_browser():
"""
在多个浏览器中运行测试
"""
with sync_playwright() as p:
# 遍历所有支持的浏览器类型
for browser_type in [p.chromium, p.firefox, p.webkit]:
# 启动浏览器
browser = browser_type.launch()
# 创建新页面
page = browser.new_page()
# 访问网站
page.goto("https://example.com")
# 打印浏览器类型和页面标题
print(f"{browser_type.name} - {page.title()}")
# 关闭浏览器
browser.close()
# 运行测试
if __name__ == "__main__":
test_multi_browser()
3.2 使用 fixtures
Playwright 提供了 fixtures 功能,可以用于测试前的准备工作。以下是一个示例:
from playwright.sync_api import sync_playwright
def setup_browser():
"""
设置浏览器环境的fixture
"""
with sync_playwright() as p:
browser = p.chromium.launch()
page = browser.new_page()
page.goto("https://example.com")
return page
def test_with_fixture():
"""
使用fixture进行测试
"""
page = setup_browser()
print(page.title())
page.context.browser.close()
# 运行测试
if __name__ == "__main__":
test_with_fixture()
第四章:常见问题解决
4.1 解决 JSON 格式问题
在 PowerShell 中运行 Playwright 命令时,可能会遇到 JSON 格式错误。以下是解决方法:
# 使用单引号包裹 JSON 字符串
code --add-mcp '{"name":"playwright","command":"npx","args":["@playwright/mcp@latest"]}'
4.2 解决 VS Code 插件问题
确保安装了支持 Playwright 的插件,并检查插件版本是否为最新。
第五章:最佳实践
5.1 代码风格
遵循 PEP8 规范,确保代码风格一致。
5.2 错误处理
在测试脚本中添加错误处理机制,确保测试的稳定性。
from playwright.sync_api import sync_playwright
import logging
# 配置日志
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
def test_with_error_handling():
"""
包含错误处理的测试示例
"""
try:
with sync_playwright() as p:
browser = p.chromium.launch()
page = browser.new_page()
page.goto("https://example.com")
print(page.title())
except Exception as e:
logger.error(f"测试过程中发生错误: {e}")
raise
finally:
try:
browser.close()
logger.info("浏览器已关闭")
except Exception as e:
logger.error(f"关闭浏览器时发生错误: {e}")
# 运行测试
if __name__ == "__main__":
test_with_error_handling()
第六章:实践案例
6.1 AI 应用测试
以下是一个 AI 应用的测试案例,假设我们正在测试一个图像识别应用。
from playwright.sync_api import sync_playwright
import os
def test_ai_app():
"""
AI应用测试示例 - 图像识别应用
"""
with sync_playwright() as p:
# 启动浏览器(无头模式)
browser = p.chromium.launch(headless=False)
page = browser.new_page()
try:
# 访问AI应用网站
page.goto("https://ai-app.com")
# 点击上传按钮
page.click("#upload-button")
# 设置要上传的文件路径
image_path = "path/to/image.jpg"
# 检查文件是否存在
if os.path.exists(image_path):
# 上传文件
page.set_input_files("#file-input", image_path)
# 点击提交按钮
page.click("#submit-button")
# 获取结果
result = page.query_selector("#result").inner_text()
print(f"AI识别结果: {result}")
else:
print(f"文件 {image_path} 不存在")
except Exception as e:
print(f"测试过程中发生错误: {e}")
finally:
# 关闭浏览器
browser.close()
# 运行测试
if __name__ == "__main__":
test_ai_app()
6.2 数据抓取应用
以下是一个数据抓取的示例,这对于AI应用的数据收集非常有用:
from playwright.sync_api import sync_playwright
import json
import time
def scrape_data_for_ai_training():
"""
为AI训练抓取数据的示例
"""
with sync_playwright() as p:
# 启动浏览器
browser = p.chromium.launch()
page = browser.new_page()
try:
# 访问目标网站
page.goto("https://news.ycombinator.com/")
# 等待页面加载
page.wait_for_load_state("networkidle")
# 抓取新闻标题和链接
news_items = []
articles = page.query_selector_all(".storylink")
for article in articles[:10]: # 只抓取前10条
title = article.inner_text()
link = article.get_attribute("href")
news_items.append({
"title": title,
"link": link,
"timestamp": time.time()
})
# 保存数据到文件
with open("scraped_news.json", "w", encoding="utf-8") as f:
json.dump(news_items, f, ensure_ascii=False, indent=2)
print(f"成功抓取 {len(news_items)} 条新闻数据")
except Exception as e:
print(f"数据抓取过程中发生错误: {e}")
finally:
browser.close()
# 运行数据抓取
if __name__ == "__main__":
scrape_data_for_ai_training()
第七章:扩展阅读
7.1 官方文档
7.2 进阶教程
总结
本文详细介绍了如何使用 Playwright 和 VS Code 进行自动化测试。通过环境搭建、基本用法、高级功能、常见问题解决以及最佳实践等内容,开发者可以快速上手并应用到实际项目中。希望本文对广大开发者有所帮助。
参考资料
图表展示
架构图
流程图
思维导图
甘特图
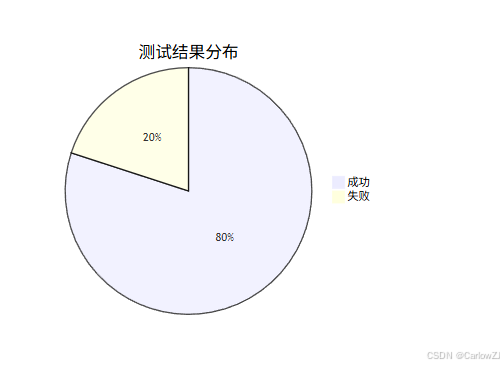
饼图
时序图
注意事项
- 确保 Node.js 和 npm 的版本兼容。
- 在 VS Code 中安装最新的 Playwright 插件。
- 测试脚本中添加错误处理机制,确保测试的稳定性。
常见问题
-
Q: 如何解决 JSON 格式问题?
- A: 使用单引号
'包裹 JSON 字符串。
- A: 使用单引号
-
Q: 如何解决 VS Code 插件问题?
- A: 确保插件版本为最新,并检查插件文档。
-
Q: 如何提高测试的稳定性?
- A: 添加适当的等待时间,使用错误处理机制,并确保网络连接稳定。
最佳实践建议
- 使用无头模式进行自动化测试:在生产环境中使用无头模式可以提高测试效率。
- 合理设置等待时间:使用
page.wait_for_*方法等待元素加载完成。 - 使用日志记录:添加日志记录以便于调试和问题追踪。
- 组织测试代码:将测试代码模块化,便于维护和重用。
- 定期更新依赖:保持 Playwright 和相关依赖的版本更新。
希望以上内容对你有帮助!




















 8686
8686

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











