



摘要
本文将详细介绍如何使用 Python 和 AI 技术构建一个智能测试用例生成与管理系统。我们将从基础概念入手,逐步深入到系统架构设计、核心功能实现、AI 模型集成、安全实践和部署方案。通过本文的学习,您将掌握构建企业级智能测试系统的完整技术栈和最佳实践。文章面向中国开发者,特别是 AI 应用开发者,内容涵盖系统架构图、业务流程图、思维导图、甘特图等多种可视化元素,以及完整的代码示例和部署指南。
正文
1. 引言
背景介绍
在现代软件开发过程中,测试是确保产品质量的关键环节。随着软件系统变得越来越复杂,传统的手工编写测试用例方式已经无法满足快速迭代的需求。自动化测试虽然在一定程度上提高了效率,但测试用例的设计和维护仍然是一个耗时耗力的过程。
近年来,人工智能技术的快速发展为测试领域带来了新的机遇。基于大语言模型的智能测试用例生成技术,能够根据需求文档、用户故事或功能描述自动生成高质量的测试用例,极大地提高了测试效率和覆盖率。
目标
本文旨在帮助开发者掌握使用 Python 和 AI 技术构建智能测试用例生成与管理系统的核心技术。通过本文的学习,您将能够:
- 理解智能测试系统的核心架构和工作原理
- 掌握 AI 模型在测试用例生成中的应用
- 实现需求解析、测试用例生成、优化和管理等核心功能
- 构建安全、可扩展的智能测试系统
- 部署和监控生产级智能测试系统
2. 基础概念
2.1 智能测试用例生成
智能测试用例生成是利用人工智能技术,特别是自然语言处理和机器学习算法,自动分析软件需求并生成相应测试用例的过程。其核心优势包括:
- 效率提升:大幅减少测试用例编写时间
- 覆盖面广:能够生成人工容易遗漏的边界条件测试
- 一致性好:避免人工编写时的主观差异
- 可维护性强:支持批量更新和优化
2.2 Python 在测试领域的应用
Python 作为测试领域的主流语言,具有以下优势:
- 丰富的测试框架:unittest、pytest、nose 等
- 强大的 AI 库支持:transformers、openai、google-generativeai 等
- 简洁的语法:易于学习和使用
- 活跃的社区:大量的第三方库和工具
2.3 测试用例生成原理
智能测试用例生成的核心工作流程包括:
- 需求理解:解析用户需求或功能描述
- 测试点识别:识别需要测试的功能点和边界条件
- 用例设计:根据测试点设计具体的测试步骤
- 数据生成:为测试用例生成合适的测试数据
- 优化调整:优化测试用例的可执行性和有效性
3. 系统架构设计
3.1 整体架构
3.2 核心组件说明
- API 网关:统一入口,处理请求路由、认证、限流等
- 应用实例:核心业务逻辑处理,可水平扩展
- Redis 缓存:缓存高频请求和中间结果,提升响应速度
- 数据库:存储用户信息、需求文档、测试用例等
- AI 模型服务:提供测试用例生成的核心 AI 能力
- 测试执行引擎:执行生成的测试用例并收集结果
- 监控系统:监控系统性能和健康状态
- 日志系统:记录系统运行日志,便于问题排查
4. 技术选型
4.1 核心技术栈
| 组件 | 技术 | 说明 |
|---|---|---|
| 后端框架 | FastAPI | 现代、快速的 Python Web 框架 |
| 异步支持 | asyncio | Python 原生异步编程库 |
| 数据库 | PostgreSQL | 强大的开源关系型数据库 |
| 缓存 | Redis | 高性能内存数据库 |
| AI 模型 | Google Generative AI | Google 的生成式 AI 模型 |
| 测试框架 | pytest | Python 测试框架 |
| 部署 | Docker + Docker Compose | 容器化部署方案 |
4.2 技术选型理由
- FastAPI:提供类型提示和自动文档生成,提升开发效率
- PostgreSQL:支持复杂查询和事务,适合存储结构化数据
- Redis:高性能缓存,适合存储中间结果和会话状态
- Google Generative AI:强大的生成能力,适合测试用例生成
- pytest:功能强大的测试框架,便于集成测试执行
- Docker:标准化部署,便于环境一致性和扩展
5. 数据库设计
5.1 数据库实体关系图
5.2 数据库表结构
-- 用户表
CREATE TABLE users (
id SERIAL PRIMARY KEY,
username VARCHAR(50) UNIQUE NOT NULL,
email VARCHAR(100) UNIQUE NOT NULL,
password_hash VARCHAR(255) NOT NULL,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
updated_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
-- 项目表
CREATE TABLE projects (
id SERIAL PRIMARY KEY,
user_id INTEGER REFERENCES users(id) NOT NULL,
name VARCHAR(100) NOT NULL,
description TEXT,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
updated_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
-- 需求表
CREATE TABLE requirements (
id SERIAL PRIMARY KEY,
project_id INTEGER REFERENCES projects(id) NOT NULL,
title VARCHAR(200) NOT NULL,
content TEXT NOT NULL,
source_type VARCHAR(50) DEFAULT 'manual', -- manual, file, image
file_path VARCHAR(500), -- 文件路径(如果是文件上传)
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
updated_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
-- 测试用例表
CREATE TABLE test_cases (
id SERIAL PRIMARY KEY,
requirement_id INTEGER REFERENCES requirements(id) NOT NULL,
title VARCHAR(200) NOT NULL,
description TEXT,
steps TEXT, -- 测试步骤,JSON 格式存储
expected_result TEXT,
priority VARCHAR(20) DEFAULT 'medium', -- low, medium, high, critical
status VARCHAR(20) DEFAULT 'draft', -- draft, approved, rejected, executed
ai_generated BOOLEAN DEFAULT TRUE,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
updated_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
-- 测试执行记录表
CREATE TABLE test_executions (
id SERIAL PRIMARY KEY,
test_case_id INTEGER REFERENCES test_cases(id) NOT NULL,
execution_result VARCHAR(20), -- pass, fail, blocked, not_run
execution_log TEXT,
executed_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
execution_time FLOAT -- 执行时间(秒)
);
6. 核心代码实现
6.1 项目结构
ai-test-generator/
├── app/
│ ├── __init__.py
│ ├── main.py # 应用入口
│ ├── config.py # 配置管理
│ ├── models/ # 数据库模型
│ │ ├── __init__.py
│ │ ├── user.py
│ │ ├── project.py
│ │ ├── requirement.py
│ │ └── test_case.py
│ ├── schemas/ # 数据模型定义
│ │ ├── __init__.py
│ │ ├── user.py
│ │ ├── project.py
│ │ ├── requirement.py
│ │ └── test_case.py
│ ├── database.py # 数据库连接
│ ├── crud/ # 数据库操作
│ │ ├── __init__.py
│ │ ├── user.py
│ │ ├── project.py
│ │ ├── requirement.py
│ │ └── test_case.py
│ ├── api/ # API 路由
│ │ ├── __init__.py
│ │ ├── v1/
│ │ │ ├── __init__.py
│ │ │ ├── users.py
│ │ │ ├── projects.py
│ │ │ ├── requirements.py
│ │ │ └── test_cases.py
│ ├── core/ # 核心组件
│ │ ├── __init__.py
│ │ ├── security.py # 安全相关
│ │ ├── ai_client.py # AI 客户端
│ │ ├── cache.py # 缓存管理
│ │ └── test_executor.py # 测试执行器
│ └── utils/ # 工具函数
│ ├── __init__.py
│ ├── ocr.py # OCR 工具
│ └── helpers.py
├── tests/ # 测试代码
├── requirements.txt # 依赖列表
├── Dockerfile # Docker 配置
├── docker-compose.yml # Docker Compose 配置
├── .env.example # 环境变量示例
└── README.md # 项目说明
6.2 配置管理
创建 app/config.py 文件:
# app/config.py
import os
from typing import Optional
from pydantic_settings import BaseSettings
class Settings(BaseSettings):
# 应用配置
PROJECT_NAME: str = "AI 智能测试用例生成系统"
PROJECT_VERSION: str = "1.0.0"
DEBUG: bool = False
# 数据库配置
POSTGRES_USER: str = os.getenv("POSTGRES_USER", "postgres")
POSTGRES_PASSWORD: str = os.getenv("POSTGRES_PASSWORD", "password")
POSTGRES_SERVER: str = os.getenv("POSTGRES_SERVER", "localhost")
POSTGRES_PORT: str = os.getenv("POSTGRES_PORT", "5432")
POSTGRES_DB: str = os.getenv("POSTGRES_DB", "test_generator")
# 数据库连接字符串
DATABASE_URL: str = f"postgresql://{POSTGRES_USER}:{POSTGRES_PASSWORD}@{POSTGRES_SERVER}:{POSTGRES_PORT}/{POSTGRES_DB}"
# Redis 配置
REDIS_HOST: str = os.getenv("REDIS_HOST", "localhost")
REDIS_PORT: int = int(os.getenv("REDIS_PORT", "6379"))
REDIS_DB: int = int(os.getenv("REDIS_DB", "0"))
# AI 模型配置
GOOGLE_API_KEY: str = os.getenv("GOOGLE_API_KEY", "")
GOOGLE_MODEL: str = os.getenv("GOOGLE_MODEL", "gemini-pro")
# 安全配置
SECRET_KEY: str = os.getenv("SECRET_KEY", "your-secret-key-here")
ACCESS_TOKEN_EXPIRE_MINUTES: int = int(os.getenv("ACCESS_TOKEN_EXPIRE_MINUTES", "30"))
# OCR 配置
OCR_LANGUAGE: str = os.getenv("OCR_LANGUAGE", "chi_sim+eng")
# 应用配置
MAX_TEST_CASES_PER_REQUIREMENT: int = int(os.getenv("MAX_TEST_CASES_PER_REQUIREMENT", "50"))
CACHE_EXPIRE_TIME: int = int(os.getenv("CACHE_EXPIRE_TIME", "3600")) # 缓存过期时间(秒)
class Config:
env_file = ".env"
settings = Settings()
6.3 数据库连接
创建 app/database.py 文件:
# app/database.py
from sqlalchemy import create_engine
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy.orm import sessionmaker
from app.config import settings
import logging
# 配置日志
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
# 创建数据库引擎
engine = create_engine(
settings.DATABASE_URL,
pool_size=10, # 连接池大小
max_overflow=20, # 超出连接池后可创建的连接数
pool_pre_ping=True, # 连接前测试连接有效性
pool_recycle=3600, # 连接回收时间(秒)
echo=settings.DEBUG # 是否输出 SQL 语句
)
# 创建会话工厂
SessionLocal = sessionmaker(autocommit=False, autoflush=False, bind=engine)
# 创建基础类
Base = declarative_base()
def get_db():
"""
获取数据库会话
"""
db = SessionLocal()
try:
yield db
finally:
db.close()
def init_db():
"""
初始化数据库表
"""
logger.info("初始化数据库表...")
Base.metadata.create_all(bind=engine)
logger.info("数据库表初始化完成")
6.4 AI 客户端
创建 app/core/ai_client.py 文件:
# app/core/ai_client.py
import google.generativeai as genai
from typing import List, Dict, Any, Optional
import json
import logging
from app.config import settings
# 配置日志
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
class AIClient:
"""
AI 客户端,用于生成测试用例
"""
def __init__(self):
"""
初始化 AI 客户端
"""
try:
# 配置 API 密钥
genai.configure(api_key=settings.GOOGLE_API_KEY)
# 配置模型
self.model = genai.GenerativeModel(settings.GOOGLE_MODEL)
logger.info(f"AI 客户端初始化成功,使用模型: {settings.GOOGLE_MODEL}")
except Exception as e:
logger.error(f"AI 客户端初始化失败: {e}")
raise
def generate_test_cases(
self,
requirement: str,
count: int = 5,
priority: str = "medium"
) -> List[Dict[str, Any]]:
"""
根据需求生成测试用例
Args:
requirement: 需求描述
count: 生成的测试用例数量
priority: 测试用例优先级
Returns:
List[Dict[str, Any]]: 生成的测试用例列表
"""
try:
# 构建提示词
prompt = f"""
请根据以下软件需求生成 {count} 个测试用例:
需求描述:
{requirement}
要求:
1. 每个测试用例应包含标题、描述、测试步骤和预期结果
2. 考虑正常流程、异常流程和边界条件
3. 测试用例优先级为 {priority}
4. 以 JSON 格式返回结果,结构如下:
[
{{
"title": "测试用例标题",
"description": "测试用例详细描述",
"steps": [
"步骤1",
"步骤2",
"步骤3"
],
"expected_result": "预期结果描述"
}}
]
"""
# 生成内容
response = self.model.generate_content(
prompt,
generation_config={
"temperature": 0.7,
"max_output_tokens": 2000,
}
)
if response.text:
# 解析 JSON 结果
try:
test_cases = json.loads(response.text)
logger.info(f"成功生成 {len(test_cases)} 个测试用例")
return test_cases
except json.JSONDecodeError:
# 如果 JSON 解析失败,尝试提取内容中的 JSON
import re
json_match = re.search(r'\[[\s\S]*\]', response.text)
if json_match:
test_cases = json.loads(json_match.group())
logger.info(f"成功提取并生成 {len(test_cases)} 个测试用例")
return test_cases
else:
logger.error("无法解析 AI 生成的测试用例")
raise Exception("AI 生成的测试用例格式不正确")
else:
logger.warning("AI 未生成有效内容")
return []
except Exception as e:
logger.error(f"生成测试用例过程中发生错误: {e}")
raise Exception(f"生成测试用例失败: {str(e)}")
def optimize_test_case(
self,
test_case: Dict[str, Any],
optimization_request: str = "优化测试用例的可执行性和清晰度"
) -> Dict[str, Any]:
"""
优化测试用例
Args:
test_case: 原始测试用例
optimization_request: 优化请求
Returns:
Dict[str, Any]: 优化后的测试用例
"""
try:
# 构建提示词
prompt = f"""
请优化以下测试用例:
原始测试用例:
{json.dumps(test_case, ensure_ascii=False, indent=2)}
优化请求:
{optimization_request}
要求:
1. 保持测试用例的核心功能不变
2. 提高测试步骤的清晰度和可执行性
3. 确保预期结果明确具体
4. 以 JSON 格式返回优化后的测试用例
"""
# 生成内容
response = self.model.generate_content(
prompt,
generation_config={
"temperature": 0.3, # 较低的温度以保持一致性
"max_output_tokens": 1000,
}
)
if response.text:
# 解析 JSON 结果
try:
optimized_test_case = json.loads(response.text)
logger.info("测试用例优化成功")
return optimized_test_case
except json.JSONDecodeError:
logger.error("优化后的测试用例格式不正确")
raise Exception("AI 优化的测试用例格式不正确")
else:
logger.warning("AI 未生成有效内容")
return test_case
except Exception as e:
logger.error(f"优化测试用例过程中发生错误: {e}")
raise Exception(f"优化测试用例失败: {str(e)}")
# 创建全局客户端实例
ai_client = AIClient()
6.5 OCR 工具
创建 app/utils/ocr.py 文件:
# app/utils/ocr.py
import pytesseract
from PIL import Image
import logging
from typing import Optional
from app.config import settings
# 配置日志
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
class OCRProcessor:
"""
OCR 处理器,用于从图片中提取文本
"""
def __init__(self):
"""
初始化 OCR 处理器
"""
self.language = settings.OCR_LANGUAGE
logger.info(f"OCR 处理器初始化成功,语言: {self.language}")
def extract_text_from_image(self, image_path: str) -> Optional[str]:
"""
从图片中提取文本
Args:
image_path: 图片路径
Returns:
Optional[str]: 提取的文本,如果失败返回 None
"""
try:
# 打开图片
image = Image.open(image_path)
# 使用 pytesseract 提取文本
text = pytesseract.image_to_string(
image,
lang=self.language
)
# 清理文本
cleaned_text = self._clean_text(text)
logger.info(f"成功从图片 {image_path} 中提取文本,长度: {len(cleaned_text)} 字符")
return cleaned_text
except Exception as e:
logger.error(f"从图片 {image_path} 提取文本时发生错误: {e}")
return None
def _clean_text(self, text: str) -> str:
"""
清理提取的文本
Args:
text: 原始文本
Returns:
str: 清理后的文本
"""
# 移除多余的空白字符
import re
cleaned = re.sub(r'\s+', ' ', text.strip())
return cleaned
# 创建全局 OCR 处理器实例
ocr_processor = OCRProcessor()
6.6 数据模型定义
创建 app/models/test_case.py 文件:
# app/models/test_case.py
from sqlalchemy import Column, Integer, String, Text, DateTime, ForeignKey, func, Boolean
from sqlalchemy.orm import relationship
import json
from app.database import Base
class User(Base):
"""
用户模型
"""
__tablename__ = "users"
id = Column(Integer, primary_key=True, index=True)
username = Column(String(50), unique=True, index=True, nullable=False)
email = Column(String(100), unique=True, index=True, nullable=False)
password_hash = Column(String(255), nullable=False)
created_at = Column(DateTime, default=func.now())
updated_at = Column(DateTime, default=func.now(), onupdate=func.now())
# 关联关系
projects = relationship("Project", back_populates="user")
class Project(Base):
"""
项目模型
"""
__tablename__ = "projects"
id = Column(Integer, primary_key=True, index=True)
user_id = Column(Integer, ForeignKey("users.id"), nullable=False)
name = Column(String(100), nullable=False)
description = Column(Text)
created_at = Column(DateTime, default=func.now())
updated_at = Column(DateTime, default=func.now(), onupdate=func.now())
# 关联关系
user = relationship("User", back_populates="projects")
requirements = relationship("Requirement", back_populates="project")
class Requirement(Base):
"""
需求模型
"""
__tablename__ = "requirements"
id = Column(Integer, primary_key=True, index=True)
project_id = Column(Integer, ForeignKey("projects.id"), nullable=False)
title = Column(String(200), nullable=False)
content = Column(Text, nullable=False)
source_type = Column(String(50), default="manual") # manual, file, image
file_path = Column(String(500)) # 文件路径(如果是文件上传)
created_at = Column(DateTime, default=func.now())
updated_at = Column(DateTime, default=func.now(), onupdate=func.now())
# 关联关系
project = relationship("Project", back_populates="requirements")
test_cases = relationship("TestCase", back_populates="requirement")
class TestCase(Base):
"""
测试用例模型
"""
__tablename__ = "test_cases"
id = Column(Integer, primary_key=True, index=True)
requirement_id = Column(Integer, ForeignKey("requirements.id"), nullable=False)
title = Column(String(200), nullable=False)
description = Column(Text)
# 测试步骤,以 JSON 字符串形式存储
_steps = Column("steps", Text)
expected_result = Column(Text)
priority = Column(String(20), default="medium") # low, medium, high, critical
status = Column(String(20), default="draft") # draft, approved, rejected, executed
ai_generated = Column(Boolean, default=True)
created_at = Column(DateTime, default=func.now())
updated_at = Column(DateTime, default=func.now(), onupdate=func.now())
# 关联关系
requirement = relationship("Requirement", back_populates="test_cases")
executions = relationship("TestExecution", back_populates="test_case")
@property
def steps(self):
"""
获取测试步骤(JSON 解析)
"""
if self._steps:
try:
return json.loads(self._steps)
except json.JSONDecodeError:
return []
return []
@steps.setter
def steps(self, value):
"""
设置测试步骤(JSON 序列化)
"""
self._steps = json.dumps(value, ensure_ascii=False) if value else None
class TestExecution(Base):
"""
测试执行记录模型
"""
__tablename__ = "test_executions"
id = Column(Integer, primary_key=True, index=True)
test_case_id = Column(Integer, ForeignKey("test_cases.id"), nullable=False)
execution_result = Column(String(20)) # pass, fail, blocked, not_run
execution_log = Column(Text)
executed_at = Column(DateTime, default=func.now())
execution_time = Column(Integer) # 执行时间(秒)
# 关联关系
test_case = relationship("TestCase", back_populates="executions")
6.7 API 路由实现
创建 app/api/v1/test_cases.py 文件:
# app/api/v1/test_cases.py
from fastapi import APIRouter, Depends, HTTPException, status, UploadFile, File
from sqlalchemy.orm import Session
from typing import List, Optional
import logging
import os
import uuid
from app.database import get_db
from app.models.test_case import TestCase, Requirement
from app.schemas.test_case import (
TestCaseCreate,
TestCaseResponse,
TestCaseGenerateRequest,
TestCaseGenerateResponse,
TestCaseOptimizeRequest
)
from app.core.ai_client import ai_client
from app.utils.ocr import ocr_processor
from app.config import settings
# 配置日志
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
router = APIRouter(prefix="/test-cases", tags=["测试用例"])
@router.post("/generate", response_model=TestCaseGenerateResponse)
async def generate_test_cases(
request: TestCaseGenerateRequest,
db: Session = Depends(get_db)
):
"""
根据需求生成测试用例
"""
try:
# 检查需求是否存在
requirement = db.query(Requirement).filter(
Requirement.id == request.requirement_id
).first()
if not requirement:
raise HTTPException(
status_code=status.HTTP_404_NOT_FOUND,
detail="需求不存在"
)
# 使用 AI 生成测试用例
ai_test_cases = ai_client.generate_test_cases(
requirement=requirement.content,
count=request.count,
priority=request.priority
)
# 保存生成的测试用例到数据库
saved_test_cases = []
for ai_test_case in ai_test_cases:
db_test_case = TestCase(
requirement_id=request.requirement_id,
title=ai_test_case["title"],
description=ai_test_case.get("description", ""),
steps=ai_test_case.get("steps", []),
expected_result=ai_test_case.get("expected_result", ""),
priority=request.priority,
ai_generated=True
)
db.add(db_test_case)
db.commit()
db.refresh(db_test_case)
saved_test_cases.append(db_test_case)
logger.info(f"成功生成 {len(saved_test_cases)} 个测试用例")
return TestCaseGenerateResponse(
requirement_id=request.requirement_id,
test_cases=saved_test_cases,
count=len(saved_test_cases)
)
except HTTPException:
raise
except Exception as e:
logger.error(f"生成测试用例过程中发生错误: {e}")
db.rollback()
raise HTTPException(
status_code=status.HTTP_500_INTERNAL_SERVER_ERROR,
detail="生成测试用例失败"
)
@router.post("/{test_case_id}/optimize", response_model=TestCaseResponse)
async def optimize_test_case(
test_case_id: int,
request: TestCaseOptimizeRequest,
db: Session = Depends(get_db)
):
"""
优化测试用例
"""
try:
# 检查测试用例是否存在
db_test_case = db.query(TestCase).filter(
TestCase.id == test_case_id
).first()
if not db_test_case:
raise HTTPException(
status_code=status.HTTP_404_NOT_FOUND,
detail="测试用例不存在"
)
# 构造测试用例数据
test_case_data = {
"title": db_test_case.title,
"description": db_test_case.description,
"steps": db_test_case.steps,
"expected_result": db_test_case.expected_result
}
# 使用 AI 优化测试用例
optimized_test_case = ai_client.optimize_test_case(
test_case=test_case_data,
optimization_request=request.optimization_request
)
# 更新数据库中的测试用例
db_test_case.title = optimized_test_case["title"]
db_test_case.description = optimized_test_case.get("description", "")
db_test_case.steps = optimized_test_case.get("steps", [])
db_test_case.expected_result = optimized_test_case.get("expected_result", "")
db_test_case.status = "approved" # 优化后自动批准
db.commit()
db.refresh(db_test_case)
logger.info(f"测试用例 {test_case_id} 优化成功")
return db_test_case
except HTTPException:
raise
except Exception as e:
logger.error(f"优化测试用例过程中发生错误: {e}")
db.rollback()
raise HTTPException(
status_code=status.HTTP_500_INTERNAL_SERVER_ERROR,
detail="优化测试用例失败"
)
@router.get("/{test_case_id}", response_model=TestCaseResponse)
async def get_test_case(
test_case_id: int,
db: Session = Depends(get_db)
):
"""
获取测试用例详情
"""
try:
db_test_case = db.query(TestCase).filter(
TestCase.id == test_case_id
).first()
if not db_test_case:
raise HTTPException(
status_code=status.HTTP_404_NOT_FOUND,
detail="测试用例不存在"
)
logger.info(f"获取测试用例 {test_case_id} 成功")
return db_test_case
except HTTPException:
raise
except Exception as e:
logger.error(f"获取测试用例过程中发生错误: {e}")
raise HTTPException(
status_code=status.HTTP_500_INTERNAL_SERVER_ERROR,
detail="获取测试用例失败"
)
@router.get("/", response_model=List[TestCaseResponse])
async def list_test_cases(
requirement_id: Optional[int] = None,
priority: Optional[str] = None,
status: Optional[str] = None,
skip: int = 0,
limit: int = 100,
db: Session = Depends(get_db)
):
"""
获取测试用例列表
"""
try:
query = db.query(TestCase)
# 添加过滤条件
if requirement_id:
query = query.filter(TestCase.requirement_id == requirement_id)
if priority:
query = query.filter(TestCase.priority == priority)
if status:
query = query.filter(TestCase.status == status)
# 执行查询
test_cases = query.offset(skip).limit(limit).all()
logger.info(f"获取测试用例列表成功,数量: {len(test_cases)}")
return test_cases
except Exception as e:
logger.error(f"获取测试用例列表过程中发生错误: {e}")
raise HTTPException(
status_code=status.HTTP_500_INTERNAL_SERVER_ERROR,
detail="获取测试用例列表失败"
)
@router.put("/{test_case_id}", response_model=TestCaseResponse)
async def update_test_case(
test_case_id: int,
test_case_update: TestCaseCreate,
db: Session = Depends(get_db)
):
"""
更新测试用例
"""
try:
# 检查测试用例是否存在
db_test_case = db.query(TestCase).filter(
TestCase.id == test_case_id
).first()
if not db_test_case:
raise HTTPException(
status_code=status.HTTP_404_NOT_FOUND,
detail="测试用例不存在"
)
# 更新测试用例
for field, value in test_case_update.dict(exclude_unset=True).items():
setattr(db_test_case, field, value)
db.commit()
db.refresh(db_test_case)
logger.info(f"更新测试用例 {test_case_id} 成功")
return db_test_case
except HTTPException:
raise
except Exception as e:
logger.error(f"更新测试用例过程中发生错误: {e}")
db.rollback()
raise HTTPException(
status_code=status.HTTP_500_INTERNAL_SERVER_ERROR,
detail="更新测试用例失败"
)
@router.delete("/{test_case_id}", response_model=dict)
async def delete_test_case(
test_case_id: int,
db: Session = Depends(get_db)
):
"""
删除测试用例
"""
try:
# 检查测试用例是否存在
db_test_case = db.query(TestCase).filter(
TestCase.id == test_case_id
).first()
if not db_test_case:
raise HTTPException(
status_code=status.HTTP_404_NOT_FOUND,
detail="测试用例不存在"
)
# 删除测试用例
db.delete(db_test_case)
db.commit()
logger.info(f"删除测试用例 {test_case_id} 成功")
return {"message": "测试用例删除成功", "test_case_id": test_case_id}
except HTTPException:
raise
except Exception as e:
logger.error(f"删除测试用例过程中发生错误: {e}")
db.rollback()
raise HTTPException(
status_code=status.HTTP_500_INTERNAL_SERVER_ERROR,
detail="删除测试用例失败"
)
6.8 应用主文件
创建 app/main.py 文件:
# app/main.py
from fastapi import FastAPI, Depends
from fastapi.middleware.cors import CORSMiddleware
from contextlib import asynccontextmanager
import logging
from app.config import settings
from app.database import init_db
from app.api.v1 import test_cases, requirements, projects, users
from app.core.ai_client import ai_client
# 配置日志
logging.basicConfig(
level=logging.INFO,
format='%(asctime)s - %(name)s - %(levelname)s - %(message)s'
)
logger = logging.getLogger(__name__)
@asynccontextmanager
async def lifespan(app: FastAPI):
"""
应用生命周期管理
"""
logger.info("应用启动中...")
# 启动时执行的代码
init_db() # 初始化数据库
yield
# 关闭时执行的代码
logger.info("应用已关闭")
# 创建 FastAPI 应用
app = FastAPI(
title=settings.PROJECT_NAME,
version=settings.PROJECT_VERSION,
debug=settings.DEBUG,
lifespan=lifespan
)
# 配置 CORS
app.add_middleware(
CORSMiddleware,
allow_origins=["*"], # 在生产环境中应该指定具体的域名
allow_credentials=True,
allow_methods=["*"],
allow_headers=["*"],
)
# 包含路由
app.include_router(users.router)
app.include_router(projects.router)
app.include_router(requirements.router)
app.include_router(test_cases.router)
@app.get("/")
async def root():
"""
根路径
"""
return {
"message": "欢迎使用 AI 智能测试用例生成系统 API",
"version": settings.PROJECT_VERSION,
"docs": "/docs",
"redoc": "/redoc"
}
@app.get("/health")
async def health_check():
"""
健康检查
"""
return {
"status": "healthy",
"version": settings.PROJECT_VERSION,
"ai_model": settings.GOOGLE_MODEL
}
if __name__ == "__main__":
import uvicorn
uvicorn.run(
"app.main:app",
host="0.0.0.0",
port=8000,
reload=settings.DEBUG
)
7. 业务流程设计
7.1 核心业务流程
7.2 错误处理流程
8. 知识体系梳理
8.1 技术栈思维导图
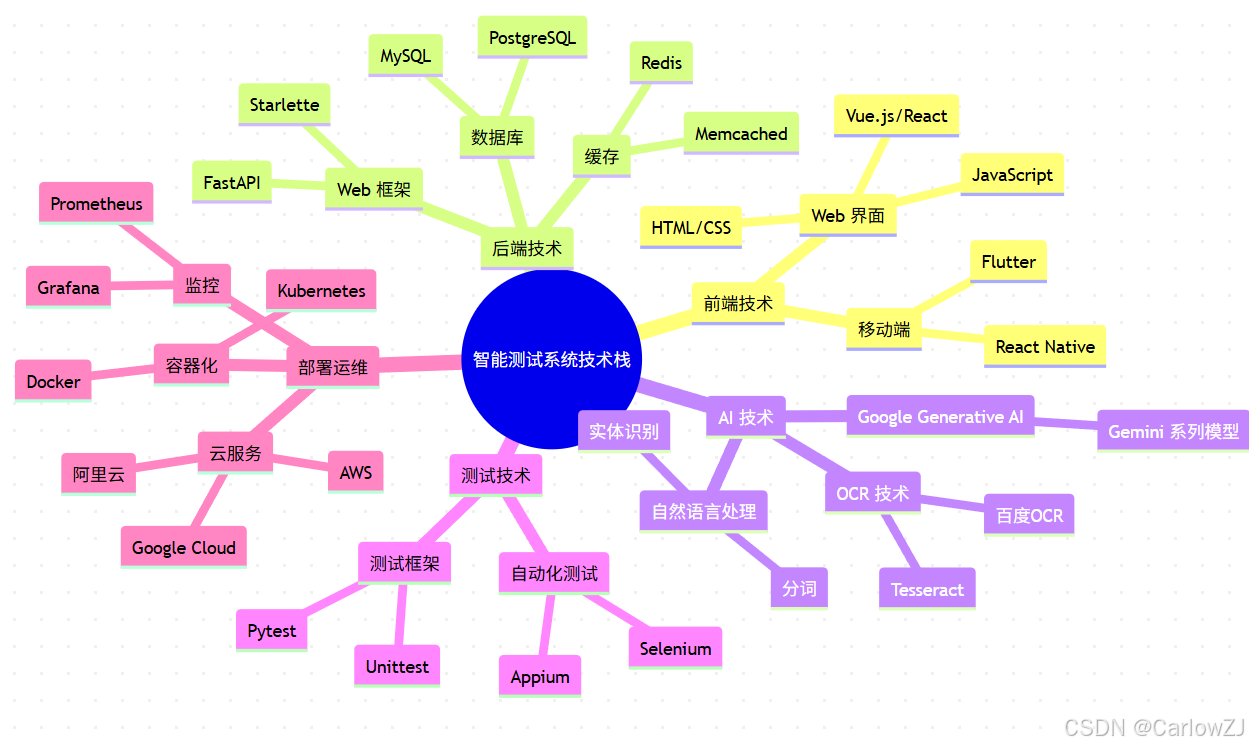
mindmap
root((智能测试系统技术栈))
前端技术
Web 界面
HTML/CSS
JavaScript
Vue.js/React
移动端
Flutter
React Native
后端技术
Web 框架
FastAPI
Starlette
数据库
PostgreSQL
MySQL
缓存
Redis
Memcached
AI 技术
Google Generative AI
Gemini 系列模型
OCR 技术
Tesseract
百度OCR
自然语言处理
分词
实体识别
测试技术
自动化测试
Selenium
Appium
测试框架
Pytest
Unittest
部署运维
容器化
Docker
Kubernetes
云服务
Google Cloud
AWS
阿里云
监控
Prometheus
Grafana
9. 实践案例
9.1 场景一:电商平台购物车功能测试
电商平台的购物车功能是核心业务之一,需要全面的测试覆盖。
需求描述:
购物车功能:
1. 用户可以将商品添加到购物车
2. 用户可以修改购物车中商品的数量
3. 用户可以删除购物车中的商品
4. 用户可以查看购物车中商品的总价
5. 购物车应支持多种商品类型
实现要点:
- 生成覆盖正常流程和异常流程的测试用例
- 考虑边界条件(如最大数量、最小数量等)
- 验证价格计算的准确性
- 测试并发操作的处理
# 示例:电商平台购物车测试用例生成
def generate_shopping_cart_test_cases():
"""
生成购物车功能测试用例
"""
requirement = """
购物车功能:
1. 用户可以将商品添加到购物车
2. 用户可以修改购物车中商品的数量
3. 用户可以删除购物车中的商品
4. 用户可以查看购物车中商品的总价
5. 购物车应支持多种商品类型
"""
# 使用 AI 生成测试用例
test_cases = ai_client.generate_test_cases(
requirement=requirement,
count=10,
priority="high"
)
# 示例输出
for i, test_case in enumerate(test_cases[:3], 1):
print(f"测试用例 {i}:")
print(f" 标题: {test_case['title']}")
print(f" 描述: {test_case.get('description', 'N/A')}")
print(f" 步骤: {test_case.get('steps', [])}")
print(f" 预期结果: {test_case.get('expected_result', 'N/A')}")
print()
# 运行示例
if __name__ == "__main__":
generate_shopping_cart_test_cases()
9.2 场景二:银行转账功能测试
银行转账功能对安全性和准确性要求极高,需要特别关注安全测试。
功能特点:
- 身份验证:确保转账操作的安全性
- 金额验证:检查转账金额的合法性
- 余额检查:验证账户余额是否充足
- 交易记录:确保交易记录的准确性
- 异常处理:处理网络异常、系统故障等情况
安全要点:
- 严格的身份验证机制
- 敏感信息的加密传输和存储
- 防止重复转账的机制
- 交易日志的完整性和可追溯性
9.3 场景三:社交媒体发布功能测试
社交媒体发布功能需要考虑内容审核、性能和用户体验。
核心功能:
- 文本发布:支持文本内容的发布
- 图片/视频上传:支持多媒体内容的发布
- 内容审核:过滤不当内容
- 隐私设置:控制内容的可见性
- 性能优化:确保发布过程的流畅性
测试要点:
- 内容格式和大小限制
- 审核机制的有效性
- 隐私设置的正确性
- 高并发情况下的性能表现
10. 安全与最佳实践
10.1 API 密钥管理
# app/core/security.py
import os
import secrets
import hashlib
from functools import wraps
from fastapi import HTTPException, status, Depends
from fastapi.security import APIKeyHeader
from app.config import settings
import logging
# 配置日志
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
# API 密钥头部
api_key_header = APIKeyHeader(name="X-API-Key", auto_error=False)
def verify_api_key(api_key: str = Depends(api_key_header)):
"""
验证 API 密钥
"""
if not api_key:
raise HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="缺少 API 密钥"
)
if api_key != settings.API_KEY:
raise HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="无效的 API 密钥"
)
return api_key
def mask_sensitive_data(data: str) -> str:
"""
掩盖敏感数据
"""
if isinstance(data, str) and len(data) > 10:
return data[:5] + '*' * (len(data) - 10) + data[-5:]
return data
def generate_secure_token(length: int = 32) -> str:
"""
生成安全的随机令牌
Args:
length: 令牌长度
Returns:
str: 生成的令牌
"""
return secrets.token_urlsafe(length)
def hash_password(password: str) -> str:
"""
哈希密码
Args:
password: 原始密码
Returns:
str: 哈希后的密码
"""
return hashlib.sha256(password.encode()).hexdigest()
10.2 输入验证和过滤
import re
from fastapi import HTTPException, status
import logging
# 配置日志
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
def validate_test_case_input(test_case_data: dict) -> bool:
"""
验证测试用例输入数据
"""
# 检查必需字段
required_fields = ['title', 'steps', 'expected_result']
for field in required_fields:
if field not in test_case_data or not test_case_data[field]:
logger.warning(f"缺少必需字段: {field}")
return False
# 检查标题长度
if len(test_case_data['title']) > 200:
logger.warning("测试用例标题过长")
return False
# 检查步骤数量
if len(test_case_data['steps']) > 50:
logger.warning("测试步骤过多")
return False
# 检查恶意内容
malicious_patterns = [
r'<script.*?>.*?</script>', # XSS 攻击
r'(DROP|DELETE|UPDATE|INSERT)\s+', # SQL 注入
]
all_text = f"{test_case_data['title']} {test_case_data.get('description', '')}"
all_text += ' '.join(test_case_data['steps'])
all_text += f" {test_case_data.get('expected_result', '')}"
for pattern in malicious_patterns:
if re.search(pattern, all_text, re.IGNORECASE):
logger.warning("检测到恶意内容")
return False
return True
def sanitize_input(user_input: str) -> str:
"""
清理用户输入
"""
if not isinstance(user_input, str):
return ""
# 移除多余的空白字符
cleaned = re.sub(r'\s+', ' ', user_input.strip())
# 转义特殊字符(简单示例)
cleaned = cleaned.replace('<', '<').replace('>', '>')
return cleaned
def rate_limit_check(client_ip: str, max_requests: int = 100, window_seconds: int = 3600) -> bool:
"""
速率限制检查
Args:
client_ip: 客户端 IP
max_requests: 窗口期内最大请求数
window_seconds: 时间窗口(秒)
Returns:
bool: 是否允许请求
"""
try:
# 使用 Redis 实现速率限制
from app.core.cache import cache_manager
key = f"rate_limit:{client_ip}"
current_count = cache_manager.get(key) or 0
if current_count >= max_requests:
logger.warning(f"速率限制触发,IP: {client_ip}")
return False
# 增加计数器
if current_count == 0:
cache_manager.set(key, 1, expire=window_seconds)
else:
cache_manager.increment(key)
return True
except Exception as e:
logger.error(f"速率限制检查失败: {e}")
# 出错时允许请求,避免影响正常用户
return True
10.3 性能优化建议
- 缓存策略:
from functools import lru_cache
import asyncio
# 使用 LRU 缓存高频函数
@lru_cache(maxsize=128)
def preprocess_requirement(requirement: str) -> str:
"""
预处理需求文本
"""
# 移除多余空格,标准化格式等
return requirement.strip().lower()
# 异步处理多个请求
async def batch_generate_test_cases(requirements: List[str]):
"""
批量生成测试用例
"""
tasks = [
generate_single_test_case(req)
for req in requirements
]
results = await asyncio.gather(*tasks)
return results
- 数据库优化:
# 添加数据库索引
from sqlalchemy import Index
# 为常用查询字段添加索引
Index('idx_test_cases_requirement_id', TestCase.requirement_id)
Index('idx_test_cases_priority', TestCase.priority)
Index('idx_test_cases_status', TestCase.status)
Index('idx_requirements_project_id', Requirement.project_id)
11. 部署与监控
11.1 Docker 部署
创建 Dockerfile:
FROM python:3.11-slim
WORKDIR /app
# 安装系统依赖
RUN apt-get update && apt-get install -y \
gcc \
postgresql-client \
tesseract-ocr \
tesseract-ocr-chi-sim \
&& rm -rf /var/lib/apt/lists/*
# 复制依赖文件
COPY requirements.txt .
# 安装 Python 依赖
RUN pip install --no-cache-dir -r requirements.txt
# 复制应用代码
COPY . .
# 创建非 root 用户
RUN adduser --disabled-password --gecos '' appuser && \
chown -R appuser:appuser /app
USER appuser
# 暴露端口
EXPOSE 8000
# 启动应用
CMD ["uvicorn", "app.main:app", "--host", "0.0.0.0", "--port", "8000"]
创建 docker-compose.yml:
version: '3.8'
services:
db:
image: postgres:15
environment:
POSTGRES_USER: ${POSTGRES_USER:-postgres}
POSTGRES_PASSWORD: ${POSTGRES_PASSWORD:-password}
POSTGRES_DB: ${POSTGRES_DB:-test_generator}
volumes:
- postgres_data:/var/lib/postgresql/data
ports:
- "5432:5432"
healthcheck:
test: ["CMD-SHELL", "pg_isready -U postgres"]
interval: 10s
timeout: 5s
retries: 5
redis:
image: redis:7-alpine
ports:
- "6379:6379"
volumes:
- redis_data:/data
healthcheck:
test: ["CMD", "redis-cli", "ping"]
interval: 10s
timeout: 3s
retries: 3
app:
build: .
ports:
- "8000:8000"
environment:
- POSTGRES_USER=${POSTGRES_USER:-postgres}
- POSTGRES_PASSWORD=${POSTGRES_PASSWORD:-password}
- POSTGRES_SERVER=db
- POSTGRES_PORT=5432
- POSTGRES_DB=${POSTGRES_DB:-test_generator}
- REDIS_HOST=redis
- REDIS_PORT=6379
- GOOGLE_API_KEY=${GOOGLE_API_KEY}
- GOOGLE_MODEL=${GOOGLE_MODEL:-gemini-pro}
depends_on:
db:
condition: service_healthy
redis:
condition: service_healthy
volumes:
- ./logs:/app/logs
- ./uploads:/app/uploads
volumes:
postgres_data:
redis_data:
11.2 项目实施计划
12. 数据分析与可视化
12.1 系统使用情况统计

12.2 用户满意度调查

13. 常见问题解答
13.1 如何提高 AI 生成测试用例的质量?
- 优化提示词:设计更精确的提示词模板
- 提供示例:给出高质量的测试用例示例
- 分步生成:将复杂需求分解为多个简单部分分别生成
- 人工审核:结合专家经验进行审核和优化
# 示例:优化提示词
def generate_better_prompt(requirement: str, examples: List[dict]) -> str:
"""
生成更好的提示词
"""
example_str = "\n".join([
f"示例 {i+1}:\n{json.dumps(ex, ensure_ascii=False, indent=2)}"
for i, ex in enumerate(examples)
])
prompt = f"""
请根据以下软件需求生成高质量的测试用例:
需求描述:
{requirement}
参考示例:
{example_str}
要求:
1. 每个测试用例应包含标题、描述、测试步骤和预期结果
2. 考虑正常流程、异常流程和边界条件
3. 确保测试步骤清晰、可执行
4. 以 JSON 格式返回结果
"""
return prompt
13.2 如何处理 AI 模型的调用限制?
- 使用缓存机制:缓存相似需求的测试用例
- 批量处理:合并多个请求减少调用次数
- 重试机制:实现指数退避重试策略
- 队列处理:使用消息队列处理高并发请求
import asyncio
import time
from typing import Callable, Any
async def retry_with_backoff(
func: Callable,
*args,
max_retries: int = 3,
base_delay: float = 1.0,
**kwargs
) -> Any:
"""
带指数退避的重试机制
"""
for attempt in range(max_retries + 1):
try:
return await func(*args, **kwargs)
except Exception as e:
if attempt == max_retries:
raise e
delay = base_delay * (2 ** attempt)
logger.warning(f"请求失败,{delay}秒后重试 (尝试 {attempt + 1}/{max_retries + 1})")
await asyncio.sleep(delay)
13.3 如何确保生成的测试用例可执行?
- 标准化格式:定义统一的测试用例格式
- 步骤细化:将复杂步骤分解为简单操作
- 环境说明:明确测试环境和前置条件
- 数据准备:提供测试数据的生成方法
13.4 如何保护用户数据安全?
- 数据加密:对敏感数据进行加密存储
- 访问控制:实现严格的权限控制机制
- 日志脱敏:对日志中的敏感信息进行脱敏处理
- 定期清理:定期清理过期的用户数据
14. 扩展阅读
15. 总结
本文详细介绍了如何使用 Python 和 AI 技术构建一个智能测试用例生成与管理系统。我们从系统需求分析入手,逐步深入到架构设计、数据库建模、代码实现、安全实践和部署方案,并提供了丰富的实践案例和最佳实践建议。
关键要点回顾:
- 技术选型:选择了 FastAPI + PostgreSQL + Redis + Google Generative AI 的技术组合,兼顾了性能、可扩展性和开发效率
- 系统架构:设计了清晰的分层架构,便于维护和扩展
- AI 集成:实现了与 Google Generative AI 的深度集成,支持智能测试用例生成和优化
- 安全实践:实现了 API 密钥管理、输入验证、数据加密等安全机制
- 部署方案:给出了 Docker 容器化部署方案,便于快速部署和扩展
通过本文的学习,您应该能够:
- 理解智能测试系统的工作原理
- 掌握 AI 在测试用例生成中的应用
- 构建功能完整的企业级测试系统
- 实施安全和性能优化措施
- 部署和监控测试系统应用
在实际项目中,建议根据具体需求进行调整和优化,例如:
- 集成更多的 AI 模型以提高生成质量
- 实现更复杂的测试执行和结果分析功能
- 添加团队协作和版本管理功能
- 集成 CI/CD 流程实现自动化测试
- 实现更智能的测试用例推荐和优化
希望本文能够帮助您快速掌握如何利用现代技术和 AI 能力构建智能测试系统,提升软件测试的效率和质量。
16. 参考资料
- Google Generative AI 官方文档. https://cloud.google.com/vertex-ai/docs/generative-ai
- FastAPI 官方文档. https://fastapi.tiangolo.com/
- PostgreSQL 官方文档. https://www.postgresql.org/docs/
- Redis 官方文档. https://redis.io/documentation/
- Pytesseract 官方文档. https://github.com/tesseract-ocr/tesseract
- 软件测试艺术. 机械工业出版社, 2012
- 智能测试技术发展与应用. https://developer.aliyun.com/article/1593037
- AI 在软件测试中的应用实践. https://m.sohu.com/a/882743335_121701517/?pvid=000115_3w_a



















 3813
3813

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











