



摘要
本篇博客面向中国AI开发者,系统讲解思源笔记的性能优化与大规模知识库管理实践。内容涵盖性能瓶颈分析、优化策略、数据库与索引管理、批量操作、API高效调用、实用案例、最佳实践与常见问题。通过丰富的Python代码、Mermaid图表和真实案例,帮助开发者高效管理海量知识库,提升系统响应速度与稳定性。
目录
- 性能瓶颈分析与优化原理
- 数据库与索引管理策略
- 批量操作与高效API调用
- 大规模知识库管理实践案例
- 性能监控与异常处理
- 最佳实践与注意事项
- 常见问题解答
- 总结与实践建议
- 参考资料与扩展阅读
1. 性能瓶颈分析与优化原理
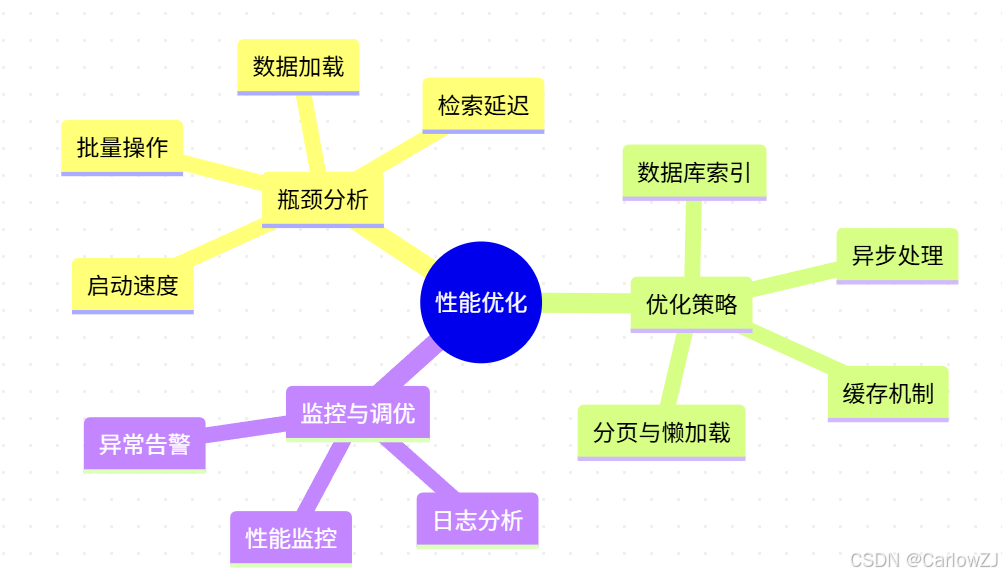
思维导图:性能瓶颈与优化方向
mindmap
root((性能优化))
瓶颈分析
启动速度
数据加载
检索延迟
批量操作
优化策略
数据库索引
缓存机制
异步处理
分页与懒加载
监控与调优
日志分析
性能监控
异常告警
说明:
- 识别瓶颈是优化的前提,常见问题包括启动慢、检索慢、批量操作卡顿等。
- 结合索引、缓存、异步等多种手段提升性能。
2. 数据库与索引管理策略
架构图:数据库与索引优化结构
优化建议:
- 定期重建索引,提升检索效率
- 合理设计表结构,避免冗余
- 利用全文索引支持大规模内容搜索
3. 批量操作与高效API调用
批量操作实践
- 批量插入/更新/删除块数据,减少单次请求负载
- 利用API循环与异步处理提升效率
Python代码示例:批量插入块数据
import requests
def batch_insert_blocks(parent_id, blocks, api_token):
url = "http://127.0.0.1:6806/api/block/insertBlock"
headers = {
"Authorization": f"Token {api_token}",
"Content-Type": "application/json"
}
for block in blocks:
data = {
"parentID": parent_id,
"dataType": block["type"],
"data": block["content"]
}
resp = requests.post(url, json=data, headers=headers)
print(resp.json())
# 示例用法
api_token = "你的API Token"
parent_id = "父块ID"
blocks = [
{"type": "NodeText", "content": "批量内容1"},
{"type": "NodeText", "content": "批量内容2"}
]
batch_insert_blocks(parent_id, blocks, api_token)
4. 大规模知识库管理实践案例
案例一:百万级块数据管理
- 分批导入与分段索引,避免单次操作过大
- 利用分页与懒加载提升前端响应速度
案例二:高并发检索优化
- 启用全文索引与缓存,减少数据库压力
- 异步API调用,提升并发处理能力
5. 性能监控与异常处理
流程图:性能监控与异常处理流程
建议:
- 启用系统日志与监控工具,及时发现性能问题
- 结合异常告警与自动重启机制,保障系统稳定
6. 最佳实践与注意事项
注意事项:
- 避免单次批量操作过大,建议分批处理
- 定期维护数据库与索引,防止膨胀
- 监控API调用频率,防止接口滥用
最佳实践:
- 结合缓存与异步机制提升响应速度
- 合理设计数据结构,便于扩展与维护
- 关注社区优化经验,持续迭代
7. 常见问题解答
- Q:知识库大了检索变慢怎么办?
A:优化索引结构,启用全文检索与缓存。 - Q:批量操作时系统卡顿?
A:分批处理,避免单次请求过大。 - Q:如何监控系统性能?
A:结合日志、监控工具与告警机制。
8. 总结与实践建议
- 思源笔记支持大规模知识库管理,性能优化空间大
- 推荐结合索引、缓存、异步等多种手段提升效率
- 实践中注重监控、分批处理与结构优化
- 积极参与社区,获取最新性能优化与大数据管理经验
9. 参考资料与扩展阅读
如需获取更多性能优化与大规模知识库管理内容,欢迎关注本专栏并留言交流!




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











