



摘要
在当今信息爆炸的时代,智能推荐系统已成为帮助用户快速找到所需内容的重要工具。从电商平台的商品推荐到流媒体平台的影视推荐,再到社交媒体的信息推送,推荐系统无处不在。本文将深入探讨智能推荐系统的概念、原理、架构设计、开发实践以及应用场景。通过详细的代码示例、架构图、流程图和数据流图,帮助读者全面理解智能推荐系统的实现过程,并提供开发过程中需要注意的关键问题。最后,我们将总结智能推荐系统的发展趋势和未来展望。
一、智能推荐系统的概念
(一)定义与背景
智能推荐系统是一种利用人工智能技术,根据用户的历史行为和偏好,为用户提供个性化推荐内容的系统。它通过分析用户的行为数据(如浏览历史、购买记录、评分等),预测用户可能感兴趣的内容,从而提高用户体验和平台的运营效率。推荐系统的发展背景包括以下几个方面:
-
海量信息的挑战:互联网上的信息量呈指数级增长,用户难以在海量信息中快速找到所需内容。
-
个性化需求的提升:用户对个性化服务的需求越来越高,希望获得符合自己兴趣和偏好的内容。
-
人工智能技术的推动:机器学习、深度学习等技术的发展为推荐系统提供了强大的算法支持。
(二)推荐系统的类型
-
基于内容的推荐(Content-Based Filtering):根据用户过去喜欢的内容特征,推荐相似的内容。
-
协同过滤推荐(Collaborative Filtering):通过分析用户之间的相似性或物品之间的相似性,为用户推荐其他用户喜欢的内容。
-
混合推荐(Hybrid Filtering):结合多种推荐技术,提高推荐的准确性和多样性。
二、智能推荐系统的架构设计
(一)架构图
以下是智能推荐系统的架构图,展示了系统的各个组成部分及其关系:
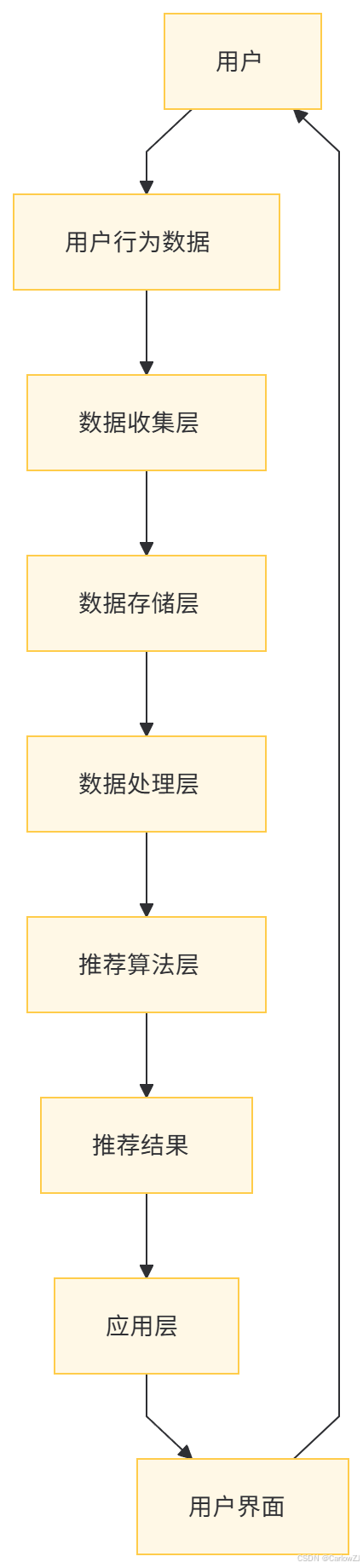
(二)各层的功能
-
数据收集层:负责收集用户的浏览行为、购买行为、评分等数据。
-
数据存储层:将收集到的数据存储在数据库或数据仓库中。
-
数据处理层:对数据进行清洗、预处理和特征提取。
-
推荐算法层:应用机器学习或深度学习算法生成推荐结果。
-
应用层:将推荐结果展示给用户,提供交互界面。
三、开发实践与代码示例
(一)数据收集与预处理
以下是一个使用Python进行数据收集和预处理的代码示例:
import pandas as pd
# 加载数据
data = pd.read_csv('user_behavior.csv')
# 数据清洗
data.dropna(inplace=True) # 删除缺失值
data = data[data['rating'] > 0] # 筛选有效评分
# 特征提取
data['timestamp'] = pd.to_datetime(data['timestamp'])
data['hour'] = data['timestamp'].dt.hour
print(data.head())(二)协同过滤推荐算法
以下是一个基于协同过滤的推荐算法示例:
from sklearn.metrics.pairwise import cosine_similarity
import numpy as np
# 用户-物品评分矩阵
ratings = pd.pivot_table(data, index='user_id', columns='item_id', values='rating')
# 计算用户之间的相似度
user_similarity = cosine_similarity(ratings.fillna(0))
# 为用户生成推荐
def recommend_items(user_id, ratings, user_similarity, num_recommendations=5):
user_index = ratings.index.get_loc(user_id)
user_ratings = ratings.iloc[user_index]
similar_users = np.argsort(user_similarity[user_index])[-2:][::-1]
recommendations = []
for similar_user in similar_users:
similar_user_ratings = ratings.iloc[similar_user]
recommended_items = similar_user_ratings[similar_user_ratings > 0].index
recommendations.extend(recommended_items)
return recommendations[:num_recommendations]
# 示例:为用户1生成推荐
recommendations = recommend_items(1, ratings, user_similarity)
print(recommendations)(三)深度学习推荐算法
以下是一个使用TensorFlow实现的深度学习推荐算法示例:
import tensorflow as tf
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Input, Embedding, Flatten, Dense, Dot
# 用户和物品嵌入
user_input = Input(shape=[1], name='user_id')
item_input = Input(shape=[1], name='item_id')
user_embedding = Embedding(input_dim=num_users, output_dim=50, input_length=1)(user_input)
item_embedding = Embedding(input_dim=num_items, output_dim=50, input_length=1)(item_input)
user_embedding = Flatten()(user_embedding)
item_embedding = Flatten()(item_embedding)
# 点积运算
dot_product = Dot(axes=-1)([user_embedding, item_embedding])
# 输出层
output = Dense(1, activation='sigmoid')(dot_product)
# 构建模型
model = Model(inputs=[user_input, item_input], outputs=output)
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
# 训练模型
model.fit([data['user_id'], data['item_id']], data['rating'], epochs=10, batch_size=64)四、应用场景
(一)电商平台
通过推荐系统为用户推荐商品,提高用户的购买转化率和平台的销售额。
(二)流媒体平台
根据用户的观看历史和偏好,推荐影视作品,提升用户体验和平台的用户粘性。
(三)社交媒体
根据用户的兴趣和社交关系,推荐文章、视频、朋友等内容,增强用户参与度。
(四)新闻平台
根据用户的阅读历史,推荐新闻文章,帮助用户快速获取感兴趣的信息。
五、注意事项
(一)数据隐私与安全
-
数据加密:确保用户数据在传输和存储过程中的加密。
-
隐私政策:明确告知用户数据的使用范围和目的,遵守相关法律法规。
(二)推荐系统的多样性与公平性
-
避免信息茧房:推荐系统应避免过度集中于用户已知的内容,增加推荐的多样性。
-
公平性:确保推荐系统对不同用户群体的公平性,避免算法偏见。
(三)性能优化
-
实时性:推荐系统需要快速响应用户请求,提升用户体验。
-
可扩展性:随着用户和数据量的增加,推荐系统需要具备良好的可扩展性。
(四)用户反馈机制
-
反馈收集:通过用户评分、点击率等数据收集用户对推荐结果的反馈。
-
算法优化:根据用户反馈调整推荐算法,提高推荐的准确性和满意度。
六、数据流图
以下是智能推荐系统的数据流图,展示了数据在系统中的流动过程:
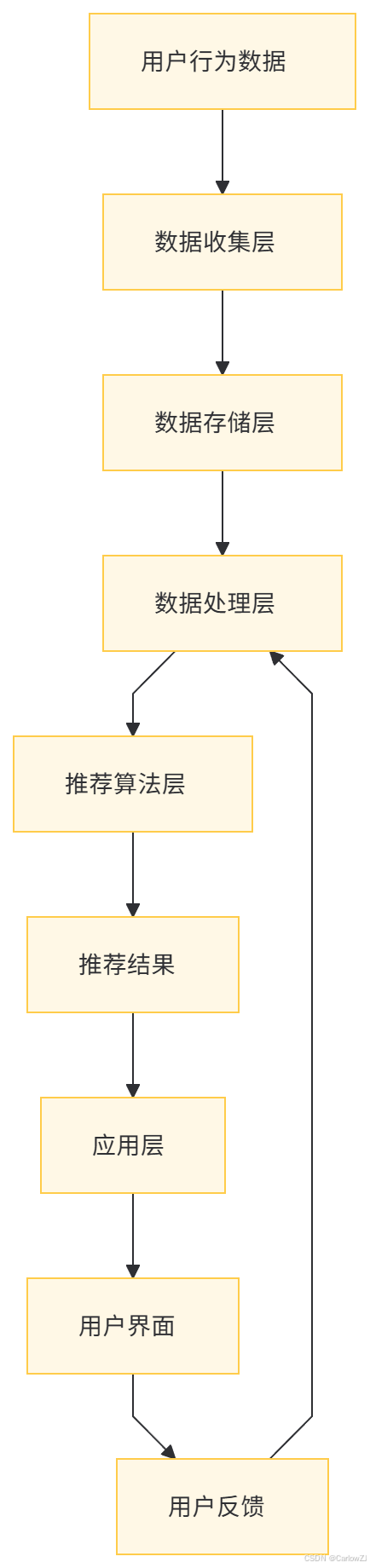
七、总结
智能推荐系统在当今数字化时代扮演着至关重要的角色。通过合理的设计和实现,推荐系统能够为用户提供个性化的内容推荐,提升用户体验和平台的运营效率。本文通过详细的架构设计、开发实践和应用场景分析,帮助读者全面理解智能推荐系统的开发过程。未来,随着人工智能技术的不断发展,推荐系统将更加智能化、个性化和多样化,为用户带来更好的体验。





















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











