



目录
(二)部分参数微调(Partial Fine-Tuning)
在当今人工智能领域,大语言模型(LLMs)已经成为了自然语言处理(NLP)的核心技术之一。这些模型通过学习大量的文本数据,能够生成高质量的文本内容,广泛应用于聊天机器人、文本生成、机器翻译、问答系统等领域。然而,预训练的语言模型虽然功能强大,但在特定任务上的表现往往需要进一步优化。这就是微调(Fine-Tuning)技术的用武之地。本文将深入探讨大语言模型的微调技术,包括其概念、方法、应用场景、代码示例以及注意事项,并通过架构图和流程图帮助读者更好地理解整个过程。
一、微调技术概述
微调是一种深度学习技术,用于对预训练模型进行进一步的训练,使其更好地适应特定的任务或数据集。预训练模型通常在大规模的通用数据上训练,能够学习到语言的基本结构和语义信息。然而,这些模型在特定领域的表现可能不够理想,因为它们没有针对特定任务进行优化。通过微调,我们可以在特定的任务数据上继续训练模型,使其学习到该任务的特定模式和特征,从而提高模型在该任务上的性能。
(一)微调的优势
-
提高任务相关性:微调可以使模型更好地适应特定任务的需求,例如在问答系统中更准确地回答问题。
-
提升性能:通过在特定数据上训练,模型能够学习到更符合任务需求的特征,从而提高准确率、召回率等指标。
-
节省资源:相比于从头开始训练一个模型,微调只需要在预训练模型的基础上进行少量的训练,大大节省了计算资源和时间。
(二)微调的挑战
-
数据需求:虽然微调不需要像预训练那样大量的数据,但仍然需要一定量的高质量标注数据。
-
过拟合风险:如果微调数据过少或过于集中,模型可能会过拟合到微调数据上,导致在新的数据上表现不佳。
-
超参数调整:微调过程中需要调整多个超参数,如学习率、训练轮数等,这需要一定的经验和实验。
二、微调的常见方法
(一)全参数微调(Full Fine-Tuning)
全参数微调是最直接的微调方法,它对预训练模型的所有参数进行更新。这种方法的优点是能够充分利用预训练模型的全部能力,但缺点是需要大量的计算资源和数据,否则容易过拟合。
1. 示例:全参数微调的代码示例
以下是一个基于Hugging Face Transformers库的全参数微调代码示例:
from transformers import AutoModelForSequenceClassification, AutoTokenizer, Trainer, TrainingArguments
from datasets import load_dataset
# 加载预训练模型和分词器
model_name = "bert-base-uncased"
model = AutoModelForSequenceClassification.from_pretrained(model_name, num_labels=2)
tokenizer = AutoTokenizer.from_pretrained(model_name)
# 加载数据集
dataset = load_dataset("glue", "mrpc")
# 数据预处理
def preprocess_function(examples):
return tokenizer(examples["sentence1"], examples["sentence2"], truncation=True)
encoded_dataset = dataset.map(preprocess_function, batched=True)
# 定义训练参数
training_args = TrainingArguments(
output_dir="./results",
evaluation_strategy="epoch",
learning_rate=2e-5,
per_device_train_batch_size=32,
per_device_eval_batch_size=64,
num_train_epochs=3,
weight_decay=0.01,
)
# 定义Trainer
trainer = Trainer(
model=model,
args=training_args,
train_dataset=encoded_dataset["train"],
eval_dataset=encoded_dataset["validation"],
)
# 开始训练
trainer.train()(二)部分参数微调(Partial Fine-Tuning)
部分参数微调是对预训练模型的一部分参数进行更新,通常只更新模型的最后几层或特定模块。这种方法可以在一定程度上减少计算资源的需求,同时避免过拟合。
1. 示例:部分参数微调的代码示例
以下是一个部分参数微调的代码示例:
from transformers import AutoModelForSequenceClassification, AutoTokenizer, Trainer, TrainingArguments
from datasets import load_dataset
# 加载预训练模型和分词器
model_name = "bert-base-uncased"
model = AutoModelForSequenceClassification.from_pretrained(model_name, num_labels=2)
tokenizer = AutoTokenizer.from_pretrained(model_name)
# 冻结部分参数
for param in model.bert.embeddings.parameters():
param.requires_grad = False
for param in model.bert.encoder.parameters():
param.requires_grad = False
# 加载数据集
dataset = load_dataset("glue", "mrpc")
# 数据预处理
def preprocess_function(examples):
return tokenizer(examples["sentence1"], examples["sentence2"], truncation=True)
encoded_dataset = dataset.map(preprocess_function, batched=True)
# 定义训练参数
training_args = TrainingArguments(
output_dir="./results",
evaluation_strategy="epoch",
learning_rate=2e-5,
per_device_train_batch_size=32,
per_device_eval_batch_size=64,
num_train_epochs=3,
weight_decay=0.01,
)
# 定义Trainer
trainer = Trainer(
model=model,
args=training_args,
train_dataset=encoded_dataset["train"],
eval_dataset=encoded_dataset["validation"],
)
# 开始训练
trainer.train()(三)适配器微调(Adapter Fine-Tuning)
适配器微调是一种轻量级的微调方法,它在预训练模型的基础上添加一个小型的适配器模块,并只更新适配器模块的参数。这种方法的优点是计算资源需求小,且可以同时支持多个任务。
1. 示例:适配器微调的代码示例
以下是一个适配器微调的代码示例:
from transformers import AutoModelForSequenceClassification, AutoTokenizer, Trainer, TrainingArguments
from datasets import load_dataset
from transformers.adapters import AdapterConfig
# 加载预训练模型和分词器
model_name = "bert-base-uncased"
model = AutoModelForSequenceClassification.from_pretrained(model_name, num_labels=2)
tokenizer = AutoTokenizer.from_pretrained(model_name)
# 添加适配器
adapter_name = "mrpc_adapter"
model.add_adapter(AdapterConfig("pfeiffer", reduction_factor=16), adapter_name)
# 激活适配器
model.train_adapter(adapter_name)
# 加载数据集
dataset = load_dataset("glue", "mrpc")
# 数据预处理
def preprocess_function(examples):
return tokenizer(examples["sentence1"], examples["sentence2"], truncation=True)
encoded_dataset = dataset.map(preprocess_function, batched=True)
# 定义训练参数
training_args = TrainingArguments(
output_dir="./results",
evaluation_strategy="epoch",
learning_rate=2e-5,
per_device_train_batch_size=32,
per_device_eval_batch_size=64,
num_train_epochs=3,
weight_decay=0.01,
)
# 定义Trainer
trainer = Trainer(
model=model,
args=training_args,
train_dataset=encoded_dataset["train"],
eval_dataset=encoded_dataset["validation"],
)
# 开始训练
trainer.train()三、微调的应用场景
(一)文本分类
文本分类是自然语言处理中的一个经典任务,目标是将文本分配到预定义的类别中。通过微调,可以显著提高文本分类模型的性能。
1. 示例:文本分类的微调
假设我们有一个情感分析任务,需要判断文本是正面还是负面。我们可以使用微调技术来优化模型:
[
{
"text": "这部电影太棒了,我非常喜欢!",
"label": "positive"
},
{
"text": "这部电影真的很糟糕,不推荐。",
"label": "negative"
}
](二)问答系统
问答系统的目标是根据用户的问题生成准确的答案。通过微调,可以优化模型对特定领域问题的理解和回答能力。
1. 示例:问答系统的微调
假设我们正在开发一个医学问答系统,需要让模型更好地理解医学问题并生成准确的答案:
[
{
"question": "感冒应该如何治疗?",
"answer": "感冒通常可以通过多喝水、多休息来缓解。如果症状严重,可以服用感冒药。"
}
](三)机器翻译
机器翻译的目标是将一种语言的文本翻译成另一种语言。通过微调,可以优化模型对特定语言对的翻译能力。
1. 示例:机器翻译的微调
假设我们正在开发一个中英翻译模型,需要让模型更好地处理中英翻译任务:
[
{
"source": "这是一篇关于人工智能的文章。",
"target": "This is an article about artificial intelligence."
}
](四)文本生成
文本生成的目标是根据给定的提示生成连贯、有意义的文本。通过微调,可以优化模型的生成能力,使其更符合特定的风格或主题。
1. 示例:文本生成的微调
假设我们正在开发一个创意写作助手,需要让模型生成有趣的科幻故事:
[
{
"prompt": "在一个遥远的星球上,有一个会说话的猫……",
"output": "这个猫名叫米洛,它拥有神奇的力量……"
}
]四、微调的注意事项
(一)数据质量
数据质量是影响微调效果的关键因素。在微调过程中,需要确保数据的准确性和多样性,避免数据偏差和噪声。
(二)过拟合
过拟合是微调过程中常见的问题,尤其是在数据量较少的情况下。可以通过以下方法减少过拟合的风险:
-
数据增强:通过生成新的数据样本来扩充数据集。
-
正则化:使用Dropout、L2正则化等技术。
-
早停法:在验证集上监控性能,提前停止训练。
(三)超参数调整
微调过程中需要调整多个超参数,如学习率、训练轮数、批量大小等。这些超参数的选择对模型性能有重要影响。可以通过网格搜索或贝叶斯优化等方法来选择最优的超参数。
(四)计算资源
微调需要一定的计算资源,尤其是全参数微调。如果资源有限,可以考虑使用部分参数微调或适配器微调。
五、架构图与流程图
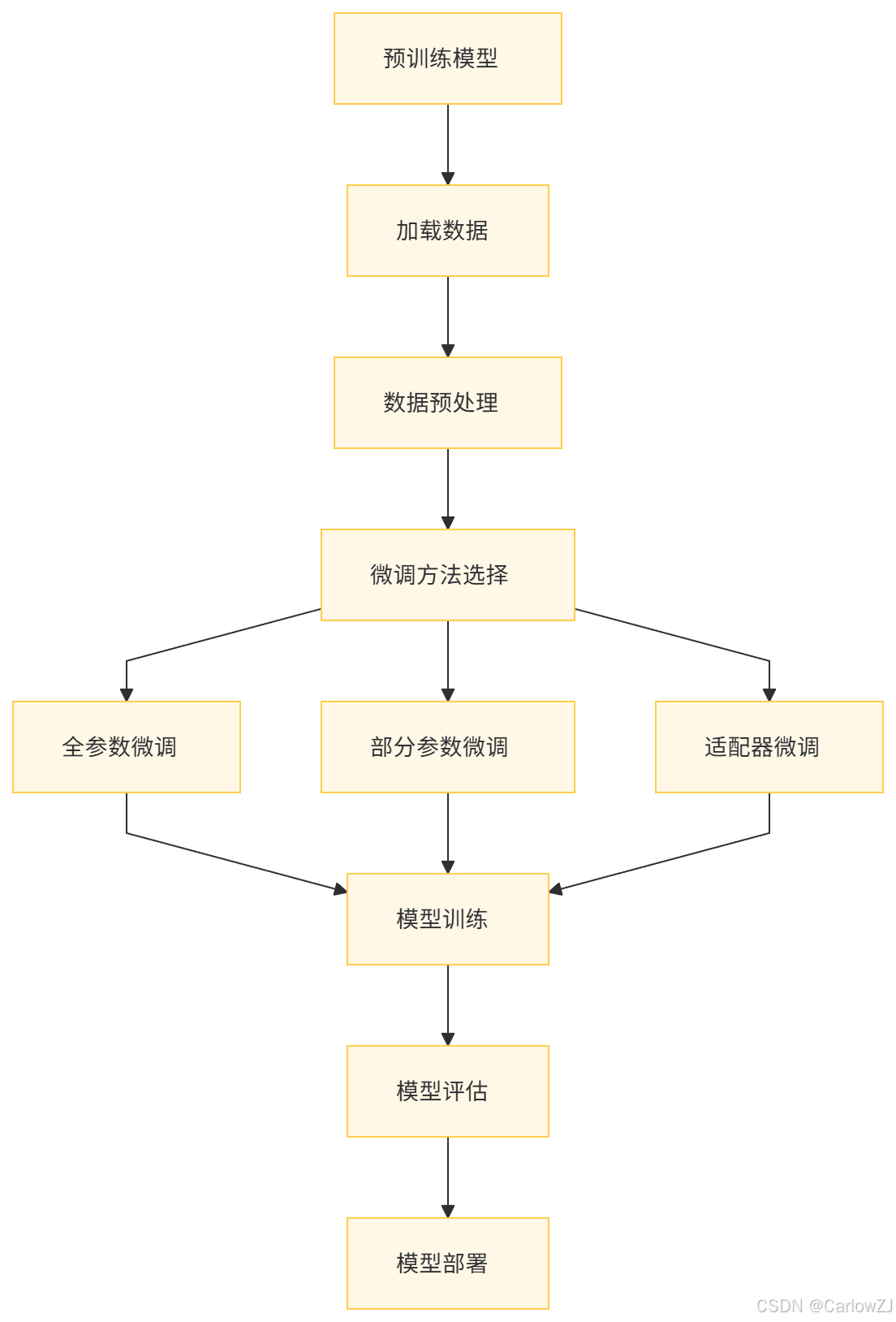
(一)架构图
以下是一个大语言模型微调的整体架构图:
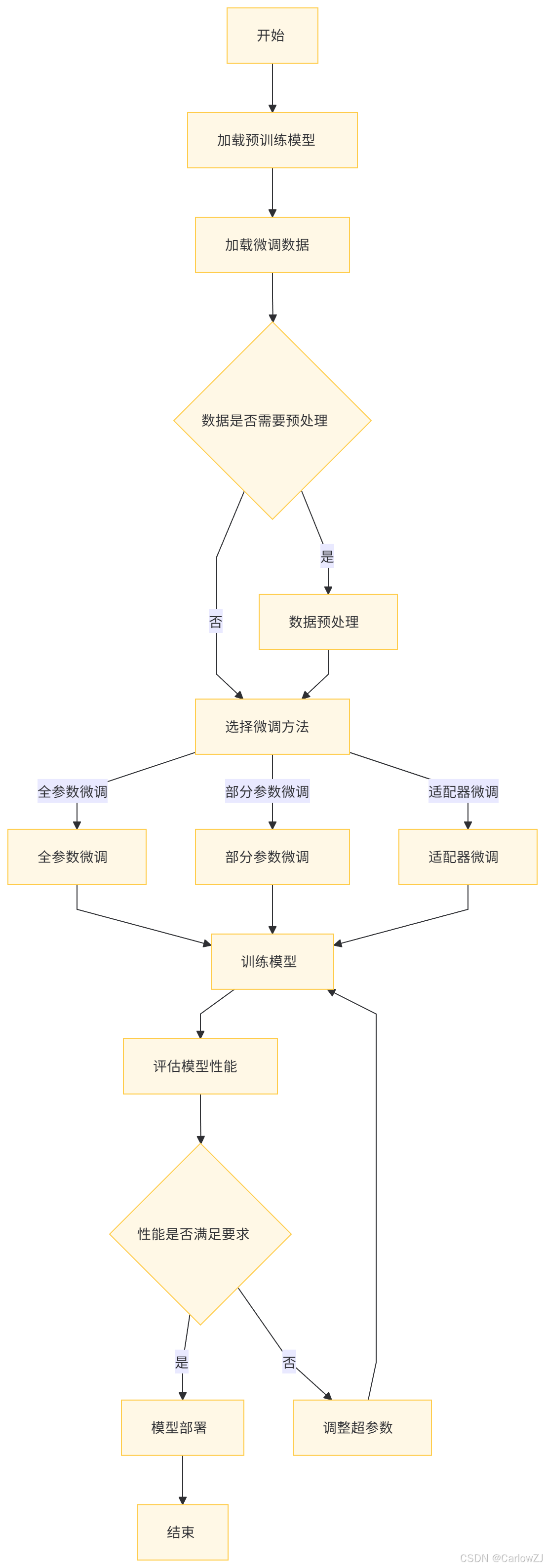
(二)流程图
以下是一个大语言模型微调的详细流程图:
六、总结
大语言模型的微调技术是自然语言处理领域的重要技术之一,通过微调可以显著提高模型在特定任务上的性能。本文详细介绍了微调的概念、方法、应用场景、代码示例以及注意事项,并通过架构图和流程图帮助读者更好地理解整个过程。希望本文对您有所帮助!如果您有任何问题或建议,欢迎在评论区留言。





















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











