



目录

随着人工智能技术的飞速发展,本地部署大语言模型的需求日益增加。DeepSeek 作为一款开源且性能强大的大语言模型,提供了灵活的本地部署方案,让用户能够在本地环境中高效运行模型,同时保护数据隐私。本文将详细介绍在 Windows 系统上部署 DeepSeek 的全过程,包括环境准备、安装工具、下载模型以及运行模型等步骤。希望这篇教程能够帮助你快速、顺利地完成部署。
一、环境准备
(一)硬件需求
-
CPU:建议使用多核心处理器,特别是对于需要处理大量文本生成任务的情况。
-
内存:至少16GB RAM;根据模型大小和预期负载,可能需要更多内存(如32GB或更高)。
-
GPU(可选但推荐):NVIDIA GPU 配备至少8GB显存,用于加速模型推理过程。推荐使用具有16GB或以上显存的专业级GPU。
-
存储:SSD硬盘以加快数据读取速度;考虑到模型文件较大,建议准备充足的存储空间。
(二)软件依赖
-
操作系统:Windows 10或更高版本。
-
Python:建议 Python 3.8 或更高版本,确保兼容最新的库和工具包。
-
Docker:如果使用 Open Web UI,需要安装 Docker。
二、安装 Ollama
Ollama 是一个开源工具,用于在本地轻松运行和部署大型语言模型。它支持多种模型架构,并提供与 OpenAI 兼容的 API 接口,适合软件开发者和包括小微企业在内的企业快速搭建本地私有化 AI 服务。以下是安装 Ollama 的步骤:
-
访问 Ollama 官网:前往 Ollama 官网,下载适用于 Windows 的安装包,点击“Download”按钮。
-
Github地址:https://github.com/ollama/ollama
-
下载安装包:根据你的操作系统选择对应的安装包。下载完成后,直接双击安装文件并按照提示完成安装。
-
验证安装:安装完成后,在终端输入以下命令,检查 Ollama 版本:
bash复制
ollama --version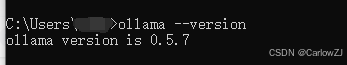
-
如果输出版本号(例如
ollama version is 0.5.6),则说明安装成功。或者找到下面图标点击 -

使用Ollama
1. 模型操作命令
ollama serve:启动 Ollama 服务,是后续操作的基础。ollama create:从模型文件创建模型,适用于自定义模型或本地已有模型文件的情况。ollama show:显示模型信息,可查看模型架构、参数等详细信息,辅助模型分析。ollama run:运行模型,如ollama run qwen2,若本地无该模型会自动下载并运行,可用于快速测试模型。ollama pull:从注册表中拉取模型,如ollama pull llama3,方便获取官方或其他来源的模型。ollama push:将模型推送到注册表,便于共享模型。ollama list:列出本地已有的模型,方便管理和选择。ollama cp:复制模型,可用于备份或创建模型副本。ollama rm:删除模型,释放存储空间。ollama help:获取任何命令的帮助信息,方便用户快速查询命令用法。
Ollama 的主要特点包括:
- 轻量化部署:支持在本地设备上运行模型,无需依赖云端服务。
- 多模型支持:兼容多种开源模型,如 LLaMA、DeepSeek 等。
- 高效管理:提供命令行工具,方便用户下载、加载和切换模型。
- 跨平台支持:支持 Windows、macOS 和 Linux 系统。
三、下载并部署 DeepSeek 模型
Ollama 支持多种 DeepSeek 模型版本,用户可以根据硬件配置选择合适的模型。
DeepSeek是由深度求索(DeepSeek)公司开发的高性能 AI 推理模型,专注于数学、代码和自然语言推理任务。其核心优势包括:
- 强化学习驱动:通过强化学习技术显著提升推理能力,仅需少量标注数据即可高效训练。
- 长链推理(CoT):支持多步骤逻辑推理,能够逐步分解复杂问题并解决。
- 模型蒸馏:支持将推理能力迁移到更小型的模型中,适合资源有限的场景。
- 开源生态:遵循 MIT 开源协议,允许用户自由使用、修改和商用。
以下是部署步骤:
(一)选择模型版本
-
入门级:1.5B 版本,适合初步测试。
-
中端:7B 或 8B 版本,适合大多数消费级 GPU。
-
高性能:14B、32B 或 70B 版本,适合高端 GPU。
(二)启动 Ollama 服务
在终端运行以下命令启动 Ollama 服务:
bash复制
ollama serve可以通过访问 http://localhost:11434 进行查看是否启动成功。
(三)下载模型
服务启动后,输入以下命令下载并运行 DeepSeek 模型。例如,下载 7B 版本的命令为:
bash复制
ollama pull deepseek-r1:7b如果需要下载其他版本,可以参考以下命令:
bash复制
ollama pull deepseek-r1:8b
ollama pull deepseek-r1:14b
ollama pull deepseek-r1:32b(四)查看已下载的模型列表
下载完成后,可以使用以下命令查看已下载的模型列表:
bash复制
ollama list
(五)运行模型
可以通过以下命令运行模型:
bash复制
ollama run deepseek-r1:7b这将启动 DeepSeek 7B 模型,并进入交互式命令行界面,可以直接与模型对话。
测试功能
-
- 在交互模式下,可以测试 DeepSeek-R1 的多种功能,例如:
- 智能客服:输入客户常见问题,如“win10的复制快捷键?”。
- 内容创作:输入“以元宵佳节为题写一篇500字的文章”。
- 编程辅助:输入“用Java写贪心算法”。
- 教育辅助:输入“说一下水在化学中的元素组成”。
- 在交互模式下,可以测试 DeepSeek-R1 的多种功能,例如:

四、使用 Open WebUI 增强交互体验
只要是支持Ollama的webUI都可以,如Dify,AnythingLLM都可以。我这里用比较简单,而且也是与Ollama结合比较紧密的open-webui为例:
GitHub地址:https://github.com/open-webui/open-webui
如果有Python3环境直接Pip安装即可
安装
pip install open-webui
启动服务
open-webui serve
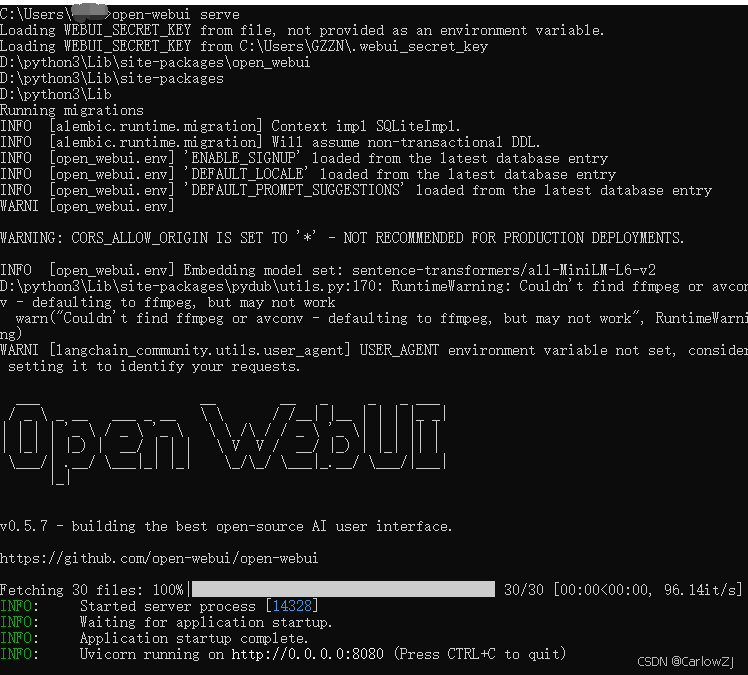
启动后,在浏览器中访问 http://localhost:8080/ 即可进入 Open WebUI 界面。
选择模型并测试
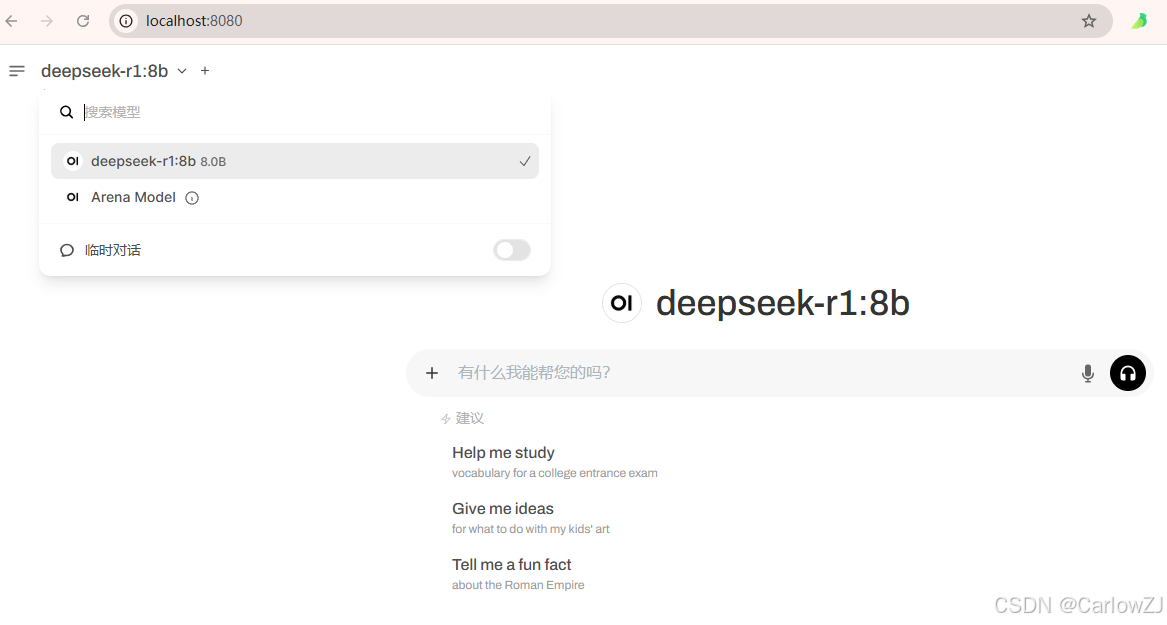
在 Open WebUI 界面中,选择已下载的 DeepSeek-R1 模型,即可开始对话测试。
五、通过 Cherry Studio 调用模型
Cherry Studio 是一款开源的多模型桌面客户端,可以直接调用主流的大模型,包括本地模型。以下是通过 Cherry Studio 调用 DeepSeek 模型的步骤:
-
下载 Cherry Studio:进入 Cherry Studio 官网 的下载界面,点击“立即下载”,或者从网盘链接下载。
-
安装 Cherry Studio:安装步骤简单,直接点击“下一步”即可。
-
配置模型服务:安装完成后,点击左下角的“设置”,在模型服务里选择“Ollama”,点亮右上角的“启用”,API 密钥会自动填写,然后点击“管理”。
-
选择模型:返回到首页,点击页面上方显示的模型名称,选择本地部署的 DeepSeek-R1:1.5B。
-
开始对话:配置完成后,就可以与 AI 正常对话了。
六、常见问题及解决方法
(一)权限问题
请确保所有操作均在管理员权限下进行,避免因权限不足导致安装失败。
(二)文件路径
解压及移动文件时,请选择不含特殊字符的目录,防止路径错误。
(三)文件完整性
下载前请核实安装包版本及完整性,如遇错误请重新下载。
(四)初始化配置
首次运行软件时,请耐心等待初始化过程完成,确保配置正确。
七、总结
通过以上步骤,你可以在 Windows 系统上成功部署 DeepSeek 模型,并通过 Cherry Studio 调用模型进行对话。本地部署 DeepSeek 模型具有响应及时、免费、个性化程度高的优势,但对硬件配置有一定要求。如果你有合适的设备,不妨尝试本地部署,体验强大的 AI 功能。
希望这篇教程对你有所帮助。如果在部署过程中遇到任何问题,欢迎在评论区留言,我们将持续更新解决方案并提供技术支持。
参考文献: DeepSeek本地部署教程一键安装包-windows电脑deepseek本地运行 DeepSeek本地部署保姆级教程,0基础有手就会! DeepSeek本地部署详细指南



















 3248
3248

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











