



 本文介绍了Hive的架构组成,包括用户接口、元数据存储、HQL查询处理流程及数据存储方式。详细阐述了Hive如何利用HDFS和MapReduce进行大数据处理。
本文介绍了Hive的架构组成,包括用户接口、元数据存储、HQL查询处理流程及数据存储方式。详细阐述了Hive如何利用HDFS和MapReduce进行大数据处理。
1、Hive架构与基本组成
Hive的体系结构可以分为以下几部分:
(1)用户接口主要有三个:CLI,Client 和
WUI。其中最常用的是CLI。Client是Hive的客户端,用户连接至Hive
Server。在启动 Client模式的时候,需要指出Hive Server所在节点,并且在该节点启动Hive Server。
WUI是通过浏览器访问Hive。
(2)Hive将元数据存储在数据库中,如mysql、derby。hive 的元数据结构描述信息库,可选用不同的关系型数据库来存储,通过配置文件修改、查看数据库配置信息。(
hive-site.xml 统一元数据管理
)Hive中的元数据包括表的名字,表的列和分区及其属性,表的属性(是否为外部表等),表的数据所在目录等。
hive-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://localhost:3306/ruozedata_basic02?createDatabaseIfNotExist=true</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>root</value>
</property>
</configuration>

(3)解释器、编译器、优化器完成HQL查询语句从词法分析、语法分析、编译、优化以及查询计划的生成。生成的查询计划存储在HDFS中,并在随后有MapReduce调用执行。
(4)Hive的数据存储在HDFS中,大部分的查询、计算由MapReduce完成(包含*的查询,比如select * from tbl不会生成MapRedcue任务)。
Hive将元数据存储在RDBMS中
2.知识体系
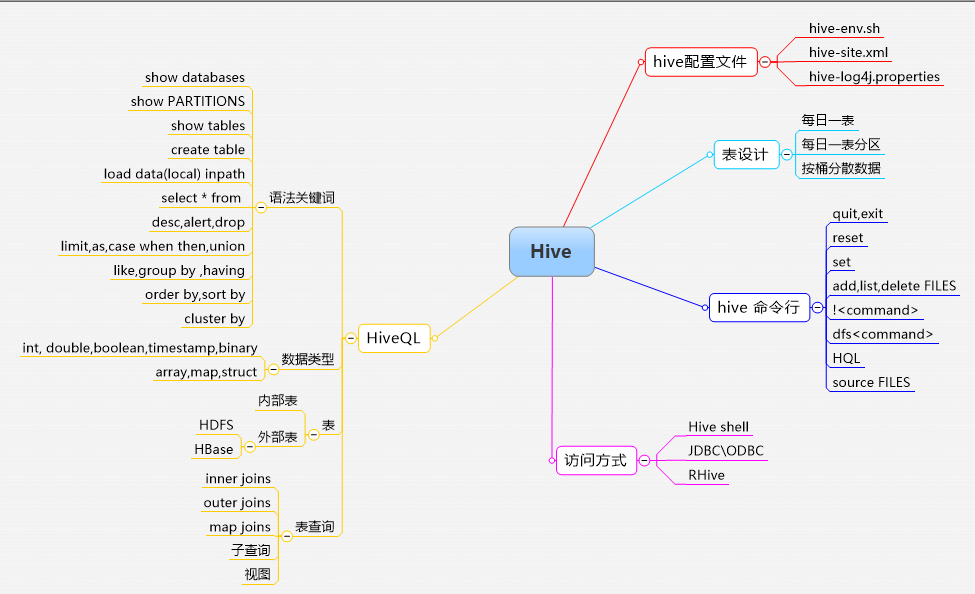
来自 “ ITPUB博客 ” ,链接:http://blog.itpub.net/31496956/viewspace-2199602/,如需转载,请注明出处,否则将追究法律责任。
转载于:http://blog.itpub.net/31496956/viewspace-2199602/


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









