




LLVM 有两个矢量化器(vectorizer):循环矢量化器(Loop Vectorizer),作用于循环,以及 SLP 矢量化器(SLP Vectorizer)。这两种矢量化器关注不同的优化机会并采用不同的技术。SLP 矢量化器会将代码中出现的多个标量合并为向量,而循环矢量化器则会扩展循环体中的指令,实现对多次连续迭代的共同处理。
Loop Vectorizer 和 SLP Vectorizer 默认都是开启的。
循环矢量化器(The Loop Vectorizer)¶
用法¶
循环矢量化器默认启用,但可以通过 clang 命令行选项关闭:
$ clang ... -fno-vectorize file.c
命令行选项¶
循环矢量化器基于 cost model(代价模型)来决定最优的矢量化因子和展开因子。不过,用户可以通过命令行强制指定这两者。clang 和 opt 都支持下述参数。
用户可以用命令行参数 -force-vector-width 控制矢量化 SIMD 宽度。
$ clang -mllvm -force-vector-width=8 ...
$ opt -loop-vectorize -force-vector-width=8 ...
用户可以用命令行参数 -force-vector-interleave 控制展开因子。
$ clang -mllvm -force-vector-interleave=2 ...
$ opt -loop-vectorize -force-vector-interleave=2 ...
Pragma 循环提示指令(loop hint directives)¶
#pragma clang loop 指令允许为随后的 for、while、do-while 或 C++11 范围 for 循环显式指定矢量化提示。可以启用或禁用矢量化和展开;还可以手动指定矢量宽度和展开计数。例如:
#pragma clang loop vectorize(enable) interleave(enable)
while(...) {
...
}
下面的示例通过指定矢量宽度和展开因子隐式启用矢量化和展开:
#pragma clang loop vectorize_width(2) interleave_count(2)
for(...) {
...
}
详细信息见 Clang 语言扩展。
诊断¶
并非所有循环都能被矢量化,包括复杂控制流、不可矢量化类型、不可矢量化调用等。循环矢量化器会产生优化备注(optimization remarks),可通过命令行选项查询,以定位和分析未被矢量化的循环。
启用优化备注的方法:
-Rpass=loop-vectorize标识成功矢量化的循环。-Rpass-missed=loop-vectorize标识矢量化失败的循环,并指明是否已请求矢量化。-Rpass-analysis=loop-vectorize标识导致矢量化失败的代码行。如果同时加上-fsave-optimization-record,还可以列出多种失败原因(未来可能改变)。
举例:
#pragma clang loop vectorize(enable)
for (int i = 0; i < Length; i++) {
switch(A[i]) {
case 0: A[i] = i*2; break;
case 1: A[i] = i; break;
default: A[i] = 0;
}
}
命令行 -Rpass-missed=loop-vectorize 的输出如下:
no_switch.cpp:4:5: remark: loop not vectorized: vectorization is explicitly enabled [-Rpass-missed=loop-vectorize]
而 -Rpass-analysis=loop-vectorize 会指出 switch 语句不能矢量化。
no_switch.cpp:4:5: remark: loop not vectorized: loop contains a switch statement [-Rpass-analysis=loop-vectorize]
switch(A[i]) {
^
要输出行号和列号,可加上 -gline-tables-only -gcolumn-info 参数。参见 Clang 用户手册。
特性¶
LLVM 循环矢量化器有许多功能,方便矢量化复杂循环。
未知循环次数的循环
循环矢量化器支持未知循环次数的循环。如下例所示,start 和 end 点未知,矢量化器提供机制来矢量化非零起始点的循环。比如 ‘n’ 可能不是矢量宽度的整数倍,矢量化器会为剩余的迭代保留标量代码,这会稍微增加代码体积。
void bar(float *A, float* B, float K, int start, int end) {
for (int i = start; i < end; ++i)
A[i] *= B[i] + K;
}
指针的运行时检查
如下例,若 A 和 B 指向连续地址,则矢量化可能导致读写冲突。部分编程者会通过 restrict 关键字声明 A、B 相互独立,但如果未声明,矢量化器会自动生成运行时检查,如果 A、B 有重叠就执行标量版本:
void bar(float *A, float* B, float K, int n) {
for (int i = 0; i < n; ++i)
A[i] *= B[i] + K;
}
归约(reductions)
如例子所示,sum 在循环内每次迭代间有关联,正常情况下无法矢量化。但矢量化器可识别它为 reduction 变量,将其当作一个向量进行累加,最后执行归约操作得出结果。支持加、乘、异或、与、或等多种操作。
int foo(int *A, int n) {
unsigned sum = 0;
for (int i = 0; i < n; ++i)
sum += A[i] + 5;
return sum;
}
浮点型归约通过 -ffast-math 开启时支持。
自增变量(inductions)
如例子所示,循环变量 i 的每步值写入数组,可被矢量化。
void bar(float *A, int n) {
for (int i = 0; i < n; ++i)
A[i] = i;
}
If 语句转换
矢量化器可将 if 语句“扁平化”,合并为单条指令流。支持内层循环体中任意控制流,包括嵌套 if、else 乃至 goto。
int foo(int *A, int *B, int n) {
unsigned sum = 0;
for (int i = 0; i < n; ++i)
if (A[i] > B[i])
sum += A[i] + 5;
return sum;
}
指针型自增变量
如使用 C++ STL accumulate 的循环,变量为指针而非整数,自增指针同样可矢量化。这对大量基于迭代器的 C++ 程序尤为重要。
int baz(int *A, int n) {
return std::accumulate(A, A + n, 0);
}
逆序迭代器
矢量化器能处理倒序的循环。
void foo(int *A, int n) {
for (int i = n; i > 0; --i)
A[i] += 1;
}
Scatter / Gather
矢量化器可矢量化包含 scatter/gather 操作的循环(即访问模式非简单递增)。
void foo(int *A, int *B, int n) {
for (intptr_t i = 0; i < n; ++i)
A[i] += B[i * 4];
}
许多场景下 cost model 会判断这样做不划算,只有通过 -mllvm -force-vector-width=# 强制开启时才会矢量化。
混合类型矢量化
矢量化器支持含多种类型变量的循环,cost model 会评估类型转换代价再决定是否矢量化。
void foo(int *A, char *B, int n) {
for (int i = 0; i < n; ++i)
A[i] += 4 * B[i];
}
全局结构别名分析
对全局结构体成员的访问同样可矢量化,由别名分析确保不会冲突,也可对指针成员做运行时检查。
许多变种得到支持,但对于依赖未定义行为的(如其他编译器实现方式),仍未矢量化。
struct { int A[100], K, B[100]; } Foo;
void foo() {
for (int i = 0; i < 100; ++i)
Foo.A[i] = Foo.B[i] + 100;
}
函数调用的矢量化
矢量化器能矢量化部分内建数学函数,如下表所列:
pow
exp
exp2
sin
cos
sqrt
log
log2
log10
fabs
floor
ceil
fma
trunc
nearbyint
fmuladd
但注意,如果对应的 math 库函数可能访问全局状态(如 errno),优化器或许无法矢量化这些函数。可通过 -fno-math-errno 优化 math 库调用。
矢量化器还会识别目标平台特殊指令,例如在 Intel x86 支持 SSE4.1 roundps 时,循环调用 floor 会被矢量化:
void foo(float *f) {
for (int i = 0; i != 1024; ++i)
f[i] = floorf(f[i]);
}
很多 math 函数只有在用指定 veclib 时才被矢量化。可用 clang 的 -fveclib 标志指定加速库,如 accelerate,libmvec,massv,svml,sleef,darwin_libsystem_m,armpl,amdlibm:
$ clang ... -fno-math-errno -fveclib=libmvec file.c
矢量化中的部分循环展开
现代处理器有多执行单元,只有并行度高的程序才能充分利用硬件。循环矢量化器会进行部分展开(unrolling),以增加指令级并行度。
如例,累加数组到 sum,仅用单寄存器端口执行。展开后可同时用多端口,加快累加速度。
int foo(int *A, int n) {
unsigned sum = 0;
for (int i = 0; i < n; ++i)
sum += A[i];
return sum;
}
矢量化器会用 cost model 判断是否值得展开,依据寄存器压力及代码体积。
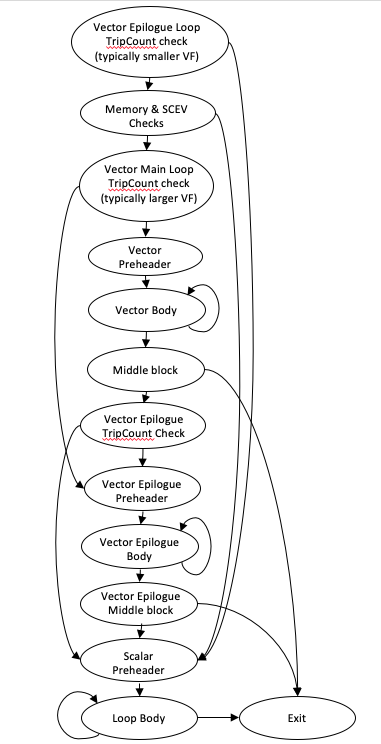
结尾(Epilogue)矢量化
当循环次数未知或不能整除矢量宽度/展开因子时,剩余迭代(epilogue)需用标量代码执行。若矢量化/展开因子较大,小循环可能大部分时间都跑在 epilogue。为此,内层矢量化器加了 epilogue 矢量化特性,使小循环也能尽量运行到 vector 代码路径上。如下图所示(CFG 结构),巧妙避免了重复的指针检查,对小 trip count 路径进行了优化。
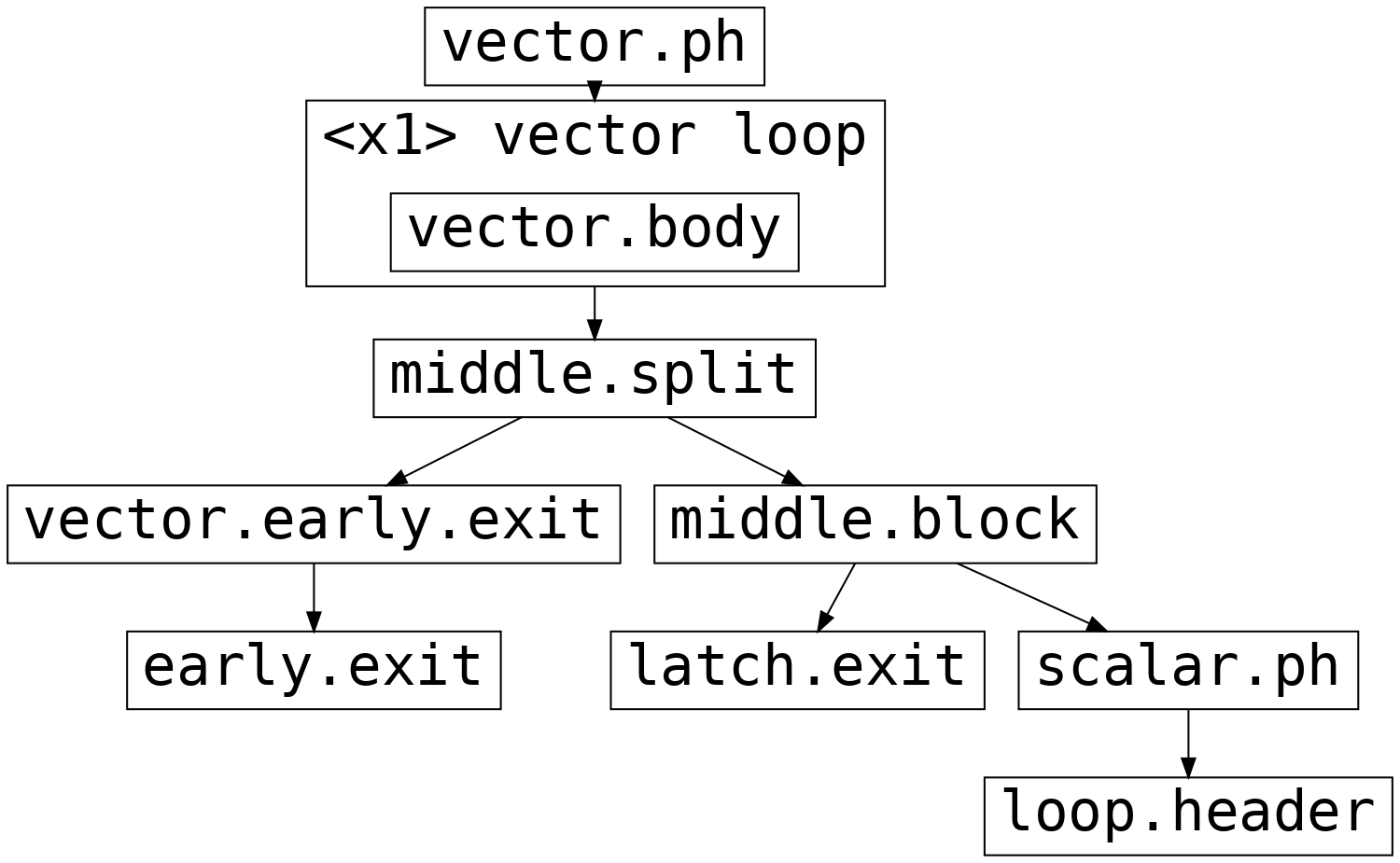
提前退出矢量化
若有单一提前退出(early exit),相关 block 以谓词方式处理,vector loop 总能从 latch 退出。如已提前退出,则 vector 循环的 successor block(如 middle.split)将跳到 early exit block(如 vector.early.exit),负责递补计算所有需要提前返回的变量;否则继续选择正常退出或剩余标量循环路径。
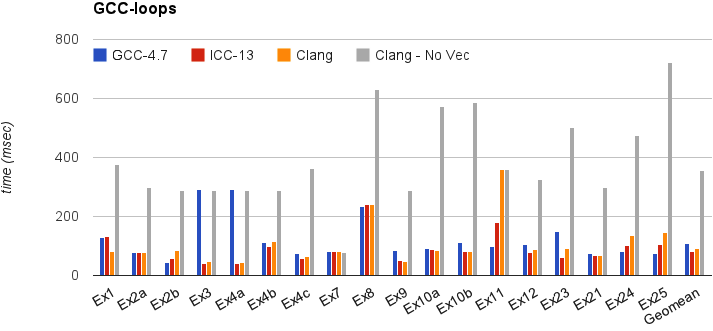
性能
本节展示 Clang 在简单测试中的执行时间:gcc-loops。这是从 GCC 自动矢量化 页面 收录的循环。
下图比较了 GCC-4.7、ICC-13 及 Clang-SVN(包含/不包含循环矢量化)在 -O3 及 corei7-avx 下的执行时间(单位毫秒,越低越好,最后一栏为所有 kernel 的几何平均)。
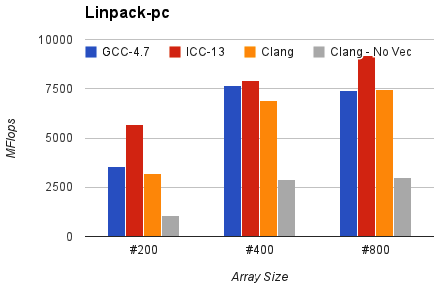
Linpack-pc 同样配置下的测试,结果为 Mflops(越高越好):
持续开发方向
矢量化计划(Vectorization Plan)
用于建模 LLVM 循环矢量化器流程和基础设施升级。
SLP 矢量化器(The SLP Vectorizer)¶
细节¶
SLP(superword-level parallelism)矢量化的目标是将类似、独立的指令合并为一条向量指令。内存访问、算术、比较、PHI 节点等都能用此方法矢量化。
例如下例,(a1, b1) 和 (a2, b2) 参与了类似运算,SLP 矢量化器可将它们合并成向量计算:
void foo(int a1, int a2, int b1, int b2, int *A) {
A[0] = a1*(a1 + b1);
A[1] = a2*(a2 + b2);
A[2] = a1*(a1 + b1);
A[3] = a2*(a2 + b2);
}
SLP 矢量化器自底向上(bottom-up)跨 basic block 搜索可合并的标量。
用法¶
SLP 矢量化器默认启用,也可通过 clang 命令行关闭:
$ clang -fno-slp-vectorize file.c
Sandbox 矢量化器(The Sandbox Vectorizer)¶
Sandbox Vectorizer 是一个实验性的框架,用于在 Sandbox IR 之上构建模块化的矢量化流水线,侧重于测试和开发便捷性。
原文地址:https://llvm.org/docs/Vectorizers.html



















 1830
1830

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











