



 本文探讨了一种基于深度学习的端到端视频编解码技术,通过分层插值和融合不同网络结构实现视频压缩,效果接近H264但逊于H265,提出未来改进和应用的方向。
本文探讨了一种基于深度学习的端到端视频编解码技术,通过分层插值和融合不同网络结构实现视频压缩,效果接近H264但逊于H265,提出未来改进和应用的方向。
通过阅读文献以及复现,有以下几点总结或感受:
一、作者提供的源码。地址:https://github.com/chaoyuaw/pytorch-vcii。在复现过程中发现,这份源码中存在一些小的bug,不过修改起来并不困难。
二、这是一篇基于深度学习的端到端的深度视频编解码文献。目前这类文献并不多,文章中也有提到说这是第一篇端到端的视频编解码文章。而且视频编解码框架明显区别于传统的H系列的框架。
三、论文思想:
0、论文的模型结构很简单。
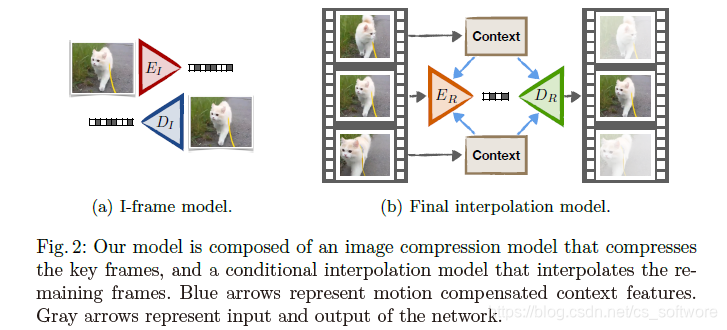
1、遵循一个简单的想法:通过重复图片插值对视频进行压缩。传统的H系列的视频压缩算法,视频帧分为I B P帧,这篇文献将视频帧分为I帧和R帧。I帧,也就是关键帧,可以选用任何的图片压缩技术,并不在本文的讨论范围内。文章就是设计了R帧的插值方法:通过分层插值编解码R帧。

论文中分层插值的做法(可以参考作者4.2节的描述):(1)每12帧作为一个GOP,第一帧作为关键帧;(2)相邻两个GOP的关键帧首先完成第一次插值;(3)然后第一层插值获取的帧再分别和左右关键帧完成第二层插值;(4)第二层插值获取的帧再分别与左右的关键帧或第一层插值获取的帧完成第三层插值。
举例:比如帧号为1 、2、3................12、13的帧,第一次首先用第1和13帧插值获取第7帧,第二次插值,用第1和第7帧插值获取第4帧,用第7和第13帧插值获取第10帧,第三次插值,1和4帧插值获取第2和3帧,4和7帧插值获取5和6帧,7和10帧插值获取8和9帧,10和13帧插值获取11和12帧。
完成分层插值,需要训练三个插值模型,作者源码只有第三次插值模型的训练,其余两次插值模型,稍微做一些代码修改就可以训练。
2、网络结构。
整体流程需要四个网络结构:encoder(编码)、Binarizer(量化)、decoder、Entropy coding(熵编码)。编码和解码网络就是Conv-LSTM网络;量化网络就是一个1*1的卷积与一些非线性操作,本文将特征量化成-1和1两个值;熵编码的核心在于对二进制数的概率估计,本文采用Pixel-CNN进行概率估计。
本文在编码和解码网络中,还融合了U-net网络提取的时空上下文信息。
总的来说,本文并没有提出新的深度网络结构,只是组合不同的网络用于视频编解码。
3、context frame
就是待插值帧的前一帧与后一帧,比如上面例子中的第一层插值中,第7帧的context frame就是第1和13帧。
4、送进去网络中的数据是什么?
以编码器为例:
送到编码器中的数据是两个context frame和编码帧组成的9通道图像。那么直接用这个9通道图对待编码帧进行编码不就可以了么,U-net网络以及运动估计图有什么用呢?
作者是这样做的:待压缩帧的前一帧(context fame)和后一帧(context fame)首先用U-net进行特征提取,然后在利用运动信息对context frame的U-net特征进行warp操作(其实就是pytorch的grid_sample操作),然后将warp操作后的特征与编码器网络(Conv-LSTM网络)的中间特征进行通道融合,然后进行后续的编码工作。本文有三个插值模型,所以这里也对应有三种特种融合方式。
四、怎么做数据?
作者目前还没有能提供生成数据的代码。那么我们自己该如何自己做数据呢?
首先,我们理解作者提供的样例图片的格式,一个GOP是12帧,所以我们需要把视频分解成包含12帧的视频片段。
每张图为什么有四张运动估计图呢?因为每一帧待插值图片的context frame有两帧图片,而且运动估计有x、y方向,所以每帧图片包含四个运动估计图。
运动估计算法选什么?根据作者的描述,可以选取任何运动估计算法。
另外需要注意,在做样本时,要理清楚哪些帧是用作第一个插值模型的,哪些帧是用作第二插值模型的,哪些帧是用作第三个插值模型的就可以了。
五、论文效果

作者的实验表明,效果与H264相当,要差于H265。工业界用的x265算法无论从编解码效率还是编解码效果上看,都要远远好于H265。而且,这篇文献用的网络包含RNN,不利于网络进行芯片化。这篇文献只是提供了思路,离真正落地应用还有相当长的路要走。

















 660
660

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









