




背景:
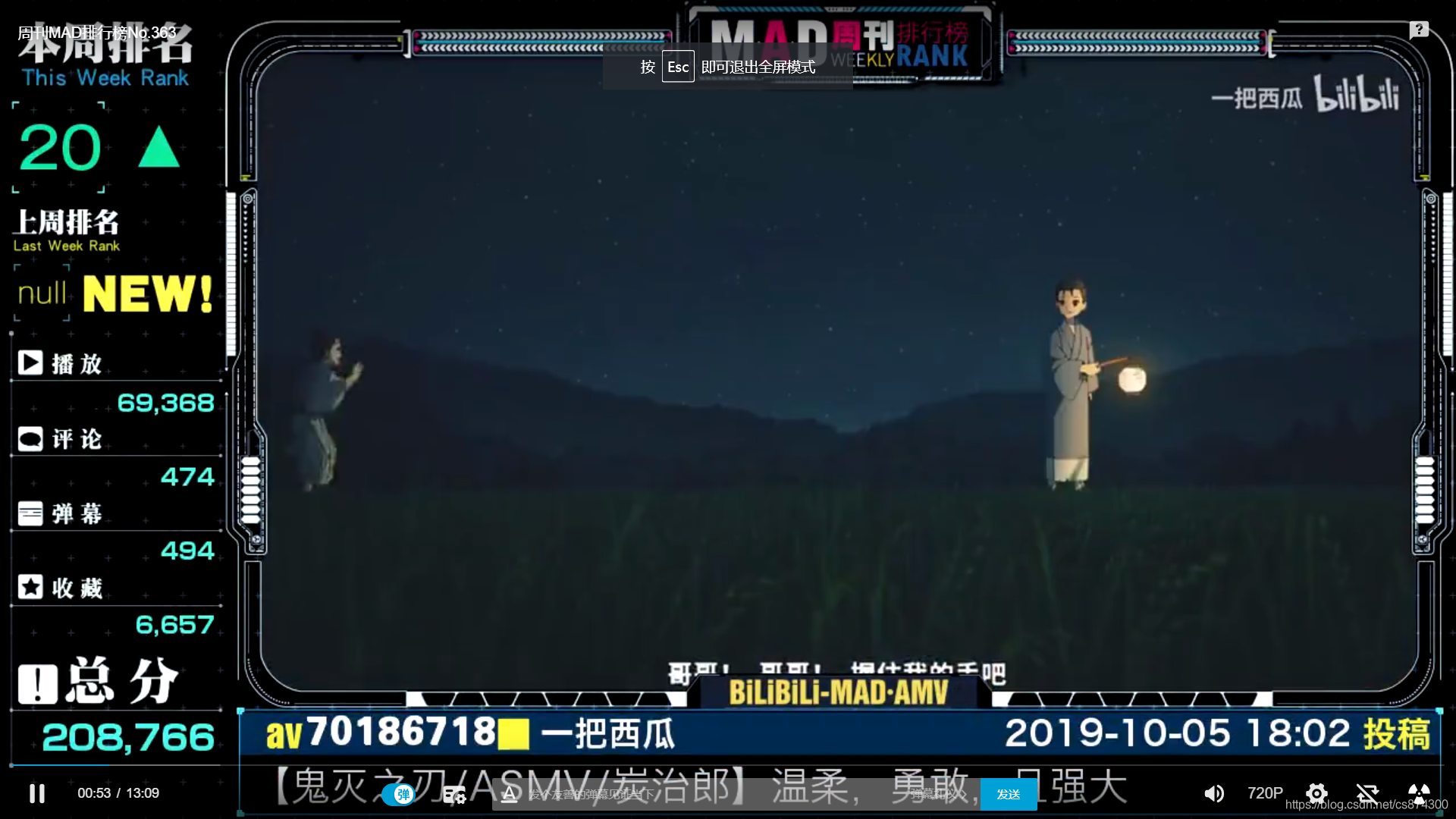
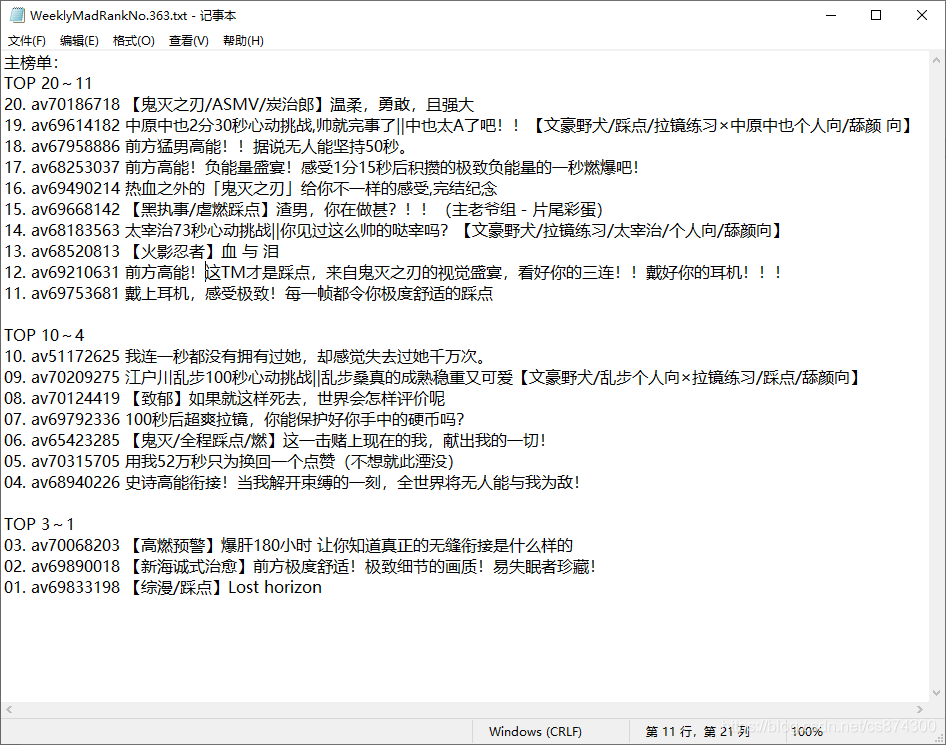
身为一个MAD爱好者会经常在B站上看MAD周刊,MAD周刊将近一周的MAD依据热度做成一个排行,我会把前20的av号标题以评论的形式放在下面。前两天觉得可以自己做个自动化脚本,只要输入MAD周刊的av号就能直接给出评论的内容,通过对视频图片进行OCR识别,获得上榜的av号,然后再得到其标题,最后以txt的形式保存。
Python 3.7
以下
1.通过MAD周刊的av获得其标题
通过av号获得B站视频的方法
import re
import requests
headers={
'Content-Type':'application/x-www-form-urlencoded'
}
def getVideoNameByAv(av):
rs = requests.get('https://m.bilibili.com/video/av{}.html'.format(av),headers=header).text
rTitle = r'"title": "(.*?)"'
title = re.findall(rTitle, rs)
return title
其中返回的rs中在下面做个json数组里面包含了视频的标题(截取了部分)
<script type="application/ld+json">
{
"@context": "https://zhanzhang.baidu.com/contexts/cambrian.jsonld",
"title": "【火影忍者】血 与 泪",
"images": “”
}import re 使用正则表达式获取title的内容
具体可参考
https://blog.youkuaiyun.com/weixin_42785547/article/details/86604762
2.依据Mad周刊标题创建文件夹用于保存下载的视频
import os
if madWeeklyTitle:
path = os.path.dirname(os.path.dirname(os.path.realpath(__file__))) + '\\'
path += 'WeeklyMadRank' + madWeeklyTitle[-6:]
if not os.path.exists(path):
os.mkdir(path)# 获取该py文件的绝对路径
os.path.realpath(__file__)
# 获取上一级路径
os.path.dirname()
# 命名的字符串截取,从倒数第六位往后,即No.xxx madWeeklyTitle[-6:]
字符串的截取
https://www.cnblogs.com/xunbu7/p/8074417.html
3.依据av号下载flv视频
https://blog.youkuaiyun.com/Enderman_xiaohei/article/details/100598003
其中我尝试了一下mp4下载,有时候可以有时候会失败。而且即使是下载的清晰度也明显不对,有空再做仔细的分析。
4.将视频用Opencv处理
包括以下三个部分
按一定帧数截取画面
https://blog.youkuaiyun.com/qq_37902216/article/details/84988676
黑白化
https://blog.youkuaiyun.com/u013480370/article/details/38345453
裁剪
https://blog.youkuaiyun.com/zbj18314469395/article/details/98056164
图片裁剪的两种方式
最后以这样的形式保存
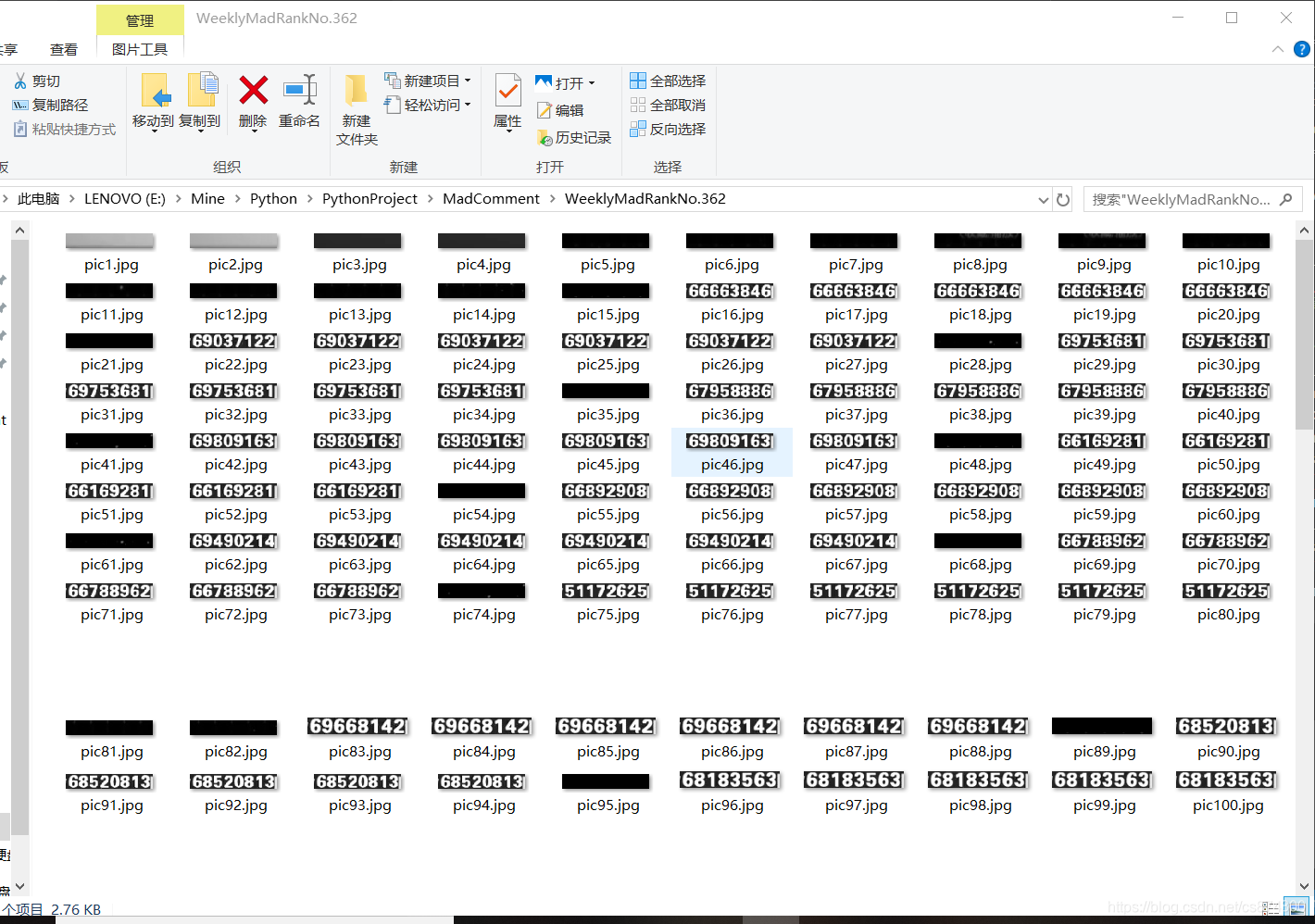
提取图片简书上有更详细的办法,最后我还是采用了上面的简单的形式
https://www.jianshu.com/p/e3c04d4fb5f3
关键代码
timeF = 100 # 视频帧计数间隔频率
while c < 21000: # 循环读取视频帧
rval, frame = vc.read()
frame = cv.cvtColor(frame, cv.COLOR_BGR2GRAY)
# 存储为图像
if c % timeF == 0:
pic = pic + 1
# 每隔 timeF 帧进行存储操作
cv.imwrite(path + '\\' + 'pic' + str(pic) + '.jpg', frame[418:438,176:294])
c = c + 1
cv.waitKey(1)将裁剪与帧保存整合了一下
其中遇到了一些问题
OpenCV导入的问题
Python使用opencv 在VsCode上报错的问题
解决vscode报错: Module 'cv2' has no ‘XXX’ member
是VsCode检测的问题,可以直接忽略,能够正常运行。或者添加包的时候改为
from cv2 import cv2 as cv
就OK了

还有imwrite写入却没有文件的问题
是因为cv.imwrite(path,frame)path路径不能包含中文
(我排查了一晚上最后居然是因为这个又好气又好笑)
5.根据识别图片返回av号(数字)
刚开始采用了tesserocr,效果不是很好后来采用了百度的ocr,准确性也不是100%,不过比tesserocr整一张图片都识别不了好一些。
tesserocr也训练了自己的样本,不过效果也不好。(其实单张图片能够识别的都还行,就是会出现一整张图片都无法识别的情况,遂放弃)
https://blog.youkuaiyun.com/u012555556/article/details/80666809
Tesseract-OCR 图片数字识别的样本训练
https://blog.youkuaiyun.com/qq_39720249/article/details/89965593
安装库 tesserocr
后来用了百度的API
https://blog.youkuaiyun.com/qq_40484582/article/details/82054009
利用百度API做图像识别(py3)
我用的是OCR的接口https://ai.baidu.com/docs#/OCR-API-GeneralBasic/top
后来出现 Max retries exceeded with url 错误
因为好像是请求连接过多的原因,因为我有210张图片,一张一个request,在循环里。
通过下面的方法关闭多余连接
https://blog.youkuaiyun.com/hyfound/article/details/82184027
然后将返回的‘word’下的‘value’ append到List里
返回的本来应该是av号,可是还有文字,错误av号等元素,所以还要对其处理
import difflib
rankList = []
a = []
for i in madNumList[::-1]:
if not re.match(r'^\d{7,9}$', i):
madNumList.remove(i)
li = list(set(madNumList))
li.sort(key=madNumList.index)
length = len(li)
for i in range(0, length-1):
j = i + 1
if difflib.SequenceMatcher(None, li[i], li[j]).ratio() >= 0.875:
if madNumList.count(li[i]) > madNumList.count(li[j]):
a.append(li[j])
else:
a.append(li[i])
rankList = [x for x in li if x not in a]
以以下返回结果为例
['70186718', '70186718', '70186713', '69614182', '69614182', '69614182', '69614182', '000秒,戴上耳', '刃/最後呼吸】']
re.match(r'^\d{7,9}$', i)将List中不是数字的,数字过长的元素排除 i表示其中的元素
^\d{7,9}$ 在7位到9位的元素,具体可见
https://blog.youkuaiyun.com/Chenftli/article/details/88414321
常用正则表达式
经过正则表达式处理后变成
['70186718', '70186718', '70186713', '69614182', '69614182', '69614182', '69614182',]
如何处理被错误识别的元素呢
我的思路是先将重复元素去除成为一个li ,然后遍历这个列表,后一个元素与前一个元素比较相似度,因为8位数,一般只会出错一个,相似度为1/8的时候我们可以认为其中是被识别错误的了,然后比较两个元素在原列表中的count,count低的存入列表a,然后将列表li中含有a列表元素的元素remove,
li = list(set(madNumList))
li.sort(key=madNumList.index)
https://www.cnblogs.com/tianyiliang/p/7845932.html
list去重
[x for x in li if x not in a]http://www.imooc.com/wenda/detail/566970
从另一个列表中删除所有出现在列表中的元素
difflib.SequenceMatcher(None, li[i], li[j]).ratio()Python去除列表list重复或相似元素的方法
最后可得20个av号的List
6.根据av号获得title再写入txt文件
with open(txtpath, "w", encoding='utf-8') as f:
要写utf-8,不然有人在标题里加入了❤就会报下面的错误
UnicodeEncodeError: 'gbk' codec can't encode character 'xxx' in position xxxx:
https://blog.youkuaiyun.com/qq_39208536/article/details/81253531
GBK问题

















 1630
1630

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









