



1、Oracle 体系结构图
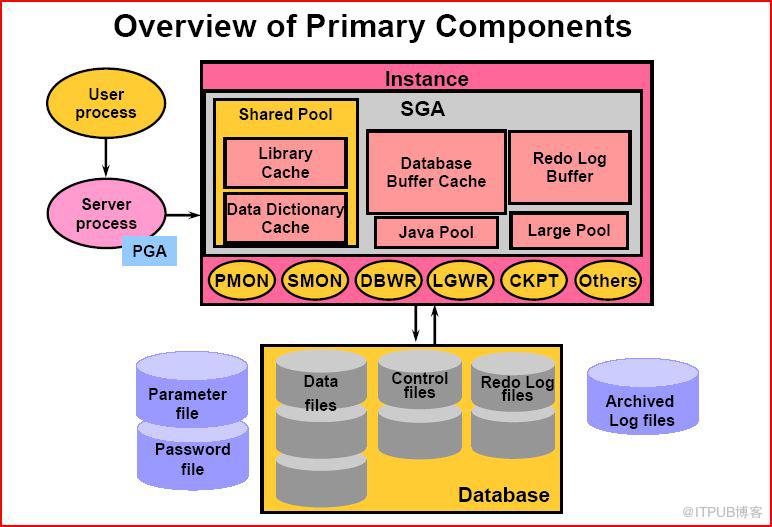
由有上图我们可以清楚的看到Oracle的各个组件的组成部分,下面对上图进行介绍及说明
2、Oracle 体系结构
1)oracle server :database + instance2)database:data file 、control file 、redolog file
3)instance: an instance access a database
4)oracle memory: sga + pga
5)instance : sga + backgroud process
6)sga:database buffer cache+ shared pool + redo log buffer +( large pool + java pool + stream pool)可选
3、SGA
3.1 SGA的6个基本组件1)database buffer cache:Oracle用了执行SQL的工作区域,存储从磁盘读入的数据块,为所有的用户共享。服务器进程将数据保存在保存在缓冲区中,用户进程提交sql语句,会话的服务器进程将扫描缓冲区的块,如果找到,则发生一次缓冲区缓存命中;不需要从磁盘读取,提高效率。数据缓冲区中被修改的数据块(脏块)由后台进程DBWR将其写入磁盘。数据缓冲区的大小对数据库的读取速度有直接的影响。
1.1)Database buffer cache中的chache
Buffer pool=(default pool)+(nodefault pool)
其中:
default pool(db_cache_size) //是标准块存放的内存空间大小,SGA自动管理时此参数不用设置。使用LRU算法清理空间
nodefault pool:
db_nk_cache_size //指定非标准块大小内存空间,比如2k、4k、16k、32k。
db_keep_cache_size //keep 存放经常访问的小表或索引等。
db_recycle_cache_size //与keep相反,存放偶尔做全表扫描的大表的数据。
SQL> create table scott.emp1 as select * from scott.emp;
Table created.
SQL> select segment_name,buffer_pool from dba_segments where segment_name='EMP1';
SEGMENT_NAME BUFFER_
------------------------- -------
EMP1 DEFAULT
SQL> alter table scott.emp1 storage(buffer_pool keep);
Table altered.
SQL> select segment_name,buffer_pool from dba_segments where segment_name='EMP1';
SEGMENT_NAME BUFFER_
------------------------- -------
EMP1 KEEP
如果要建立非标准块的表空间,先前要设定db buffer中的与之对应的db_nk_cache_size参数。
SQL> alter system set db_16k_cache_size=8m;
System altered.
SQL> create tablespace tbs_16k datafile '/u01/app/oracle/oradata/rman1/tbs16k01.dbf' size 10m blocksize 16k;
SQL> select TABLESPACE_NAME,block_size from dba_tablespaces;
TABLESPACE_NAME BLOCK_SIZE
------------------------------ ----------
SYSTEM 8192
SYSAUX 8192
UNDOTBS1 8192
TEMP 8192
USERS 8192
TBS_CATALOG 8192
TBS_TEST 8192
TBS_16K 16384
1.3)查看buffer cache命中率
SQL> select (1-(sum(decode(name, 'physical reads',value,0))/(sum(decode(name, 'db block gets',value,0))+
2 sum(decode (name,'consistent gets',value,0))))) * 100 "Hit Ratio" from v$sysstat;
Hit Ratio
----------
92.0081258
2) shared pool
共享池是对SQL、PL/SQL程序进行语法分析、编译、执行的内存区域。
共享池由库缓存(library cache),和数据字典缓存(data dictionary cache)以及结果缓存(result cache)等组成。
共享池的大小直接影响数据库的性能。
关于shared pool中的几个概念
library cache: sql和plsql的解析场所,存放着所有编译过的sql语句代码,以备所有用户共享。
data dictionary cache: 存放重要的数据字典信息,以备数据库使用
server result cache: 存放服务器端的SQL结果集及PL/SQL函数返回值
User Global Area (UGA) 与共享服务器模式有关
3)redo log buffer
日志条目(redo entries )记录了数据库的所有修改信息(包括DML和DDL), 为的是数据库恢复,日志条目首先产生于日志缓冲区。 日志缓冲区较小,它是以字节为单位的,它极其重要。
SQL> show parameter log_buffer
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
log_buffer integer 7057408
如果想让它是一个最小值,这样可以做:
SQL> alter system set log_buffer =1 scope=spfile; //修改动态参数文件,下次启动有效。
SQL> startup force
SQL> show parameter log_buffer;
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
log_buffer integer 2927616 //这就是最小值了
4)large pool(可选)
为了进行大的后台进程操作而分配的内存空间,与shared pool管理不同,主要用于共享服务器的session memory,RMAN备份恢复以及并行查询等。
5)java pool(可选)
为了java虚拟机及应用而分配的内存空间,包含所有session指定的JAVA代码和数据。
6) stream pool(可选)
为了stream process而分配的内存空间。stream技术是为了在不同数据库之间共享数据,因此,它只对使用了stream数据库特性的系统是重要的。
sga的granules(颗粒):组成oracle内存的最小单位
SGA_MAX_SIZE Granule Size
---------------------- ------------------------
<=1 GB 4 MB
1GB -- 8GB 16 MB
8GB --16GB 32 MB
16GB--32GB 64 MB
32GB--64GB 128 MB
64GB--128GB 256 MB
>128GB 512 MB
--查看SGA分配情况
NAME Size(M)
-------------------------------- ----------
Fixed SGA Size 2.14937592
Redo Buffers 6.765625
Buffer Cache Size 656
Shared Pool Size 224
Large Pool Size 32
Java Pool Size 16
Streams Pool Size 0
Shared IO Pool Size 0
Granule Size 16
Maximum SGA Size 1576.91797
Startup overhead in Shared Pool 81.7750549
Free SGA Memory Available 640
4、 Oracle的进程
三种process: 1)user process、 2)server process 、3)background process
user process:用户进程可以使连接Oracle服务器进程的任何客户端process,一般分为三种形式,1)sql*plus, 2)应用程序,3)web方式(EM)
客户端请求,sqlplus是客户端命令。
windows作为客户端:可以通过查看任务管理器看到sqlplus用户进程:
linux作为客户端时可以使用ps看到sqlplus关键字:
[oracle@rman1 rman1]$ ps -ef|grep sqlplus
oracle 9353 9322 0 07:32 pts/3 00:00:00 rlwrap sqlplus / as sysdba
oracle 9354 9353 0 07:32 pts/4 00:00:00 sqlplus as sysdba
server process:用来处理连接到实例的用户进程提交的请求,user process不能直接访问Oracle,必须通过相应的server process访问实例,进而访问数据库。
可以在oracle查看V$process视图,它包括了当前所有的oracle进程,即后台进程和服务器进程。
SQL> select pid,program,background from v$process;
background字段为1是background process,其余都是server process
background process:实现为多用户提供服务且保证系统性能,在一个多进程Oracle系统中,粗壮你多个被称为后台进程的Oracle进程。
基本的后台进程
smon(System Monitor):系统监控进程
在实例崩溃之后,Oracle会自动恢复实例。另一个作用是释放不再使用的临时段。
pmon(process monitor):进程监控进程
1、当user process失败时,清理出现故障的进程。 释放所有当前挂起的锁定。释放服务器端使用的资源
2、监控空闲会话是否到达阀值
3、动态注册监听
dbwn: 数据写入进程
将脏缓冲区从数据库缓冲区缓存写入数据文件中,释放data buffer空间
以下几种情况dbwn执行写操作
1、没有可用的缓冲区
2、脏缓冲区过多(阀值)
3、超过3秒
4、遇到检查点
SQL> select kvittag,kvitval,kvitdsc from x$kvit where kvittag in('kcbldq','kcbfsp');
KVITTAG KVITVAL KVITDSC
---------- ------- ----------------------------------------------------------------------
kcbldq 25 large dirty queue if kcbclw reaches this
kcbfsp 40 Max percentage of LRU list foreground can scan for free
kcbldq的kvitval=25 表示DRITY_list队列中dirty_buffer达到25%阀值时,DBWN被触发
kcbfsp的kvitval=40 表示LRU_list中free block低于40%时,DBWR被触发
LGWR
lgwr:写日志条目,从redo log buffer到redo logfile (必须在dbwr写脏块之前写入日志)
负责将日志缓冲区中的日志条目写入日志文件。 有多个日志文件,该进程以循环的方式将数据写入文件。
以下4个状况发生时, lgwr都会写
1)commit, 2)三分之一满,3)先于dbwr写(先记后写,先记日志后写脏块,保证未提交数据都能回滚),4)3秒(由DBWR的3秒传导而来)
ckpt:生成检查点, 通知或督促dbwr写脏块
完全检查点:保证数据一致性。增量检查点:不断更新控制文件中的检查点位置,当发生实例崩溃时,可以尽量缩短实例恢复的时间。
arcn:归档模式下,发生日志切换时,把当前日志组中的内容写入归档日志,作为备份历史日志。
确定哪些进程正在运行,以及每个进程的数量
SQL> select program from v$session order by program;
SQL> select program from v$process order by program;
5、pga
pga(program global area)提供服务进程存储数据及控制信息的内存区域。服务进程启动时由Oracle创建的非共享的内存去。只有服务进程才能访问属于自己的PGA,
特点:属于oracle内存结构,存放用户游标、变量、控制、数据排序、存放hash值。与SGA不同,PGA是独立的,非共享。
特点:属于oracle内存结构,存放用户游标、变量、控制、数据排序、存放hash值。与SGA不同,PGA是独立的,非共享。
6、用户与Oracle服务器的连接方式
6.1 专用连接模式(dedicated server process)
对于客户端的每个user process,服务器端都会出现一个server process,会话与专用服务器之间存在一对一的映射。对专用连接来说,用户在客户端启动了一个应用程序,例如sql*plus,就是在客户端启动一个用户进程;与oracle服务器端连接成功后,会在服务器端生成一个服务器进程,该服务器进程作为用户进程的代理进程,代替客户端执行各种命令并把结果返回给客户端。用户进程一旦中止,与之对应的服务器进程立刻中止。
专用连接的PGA的管理方式是私有的。Oracle缺省采用专用连接模式。
6.2 共享连接模式(shared server process)
多个user process共享一个server process。它通过调度进程(dispatcher)与共享服务器连接,共享服务器实际上就是一种连接池机制(connectionpooling),连接池可以重用已有的超时连接,服务于其它活动会话。来自 “ ITPUB博客 ” ,链接:http://blog.itpub.net/28282660/viewspace-1411523/,如需转载,请注明出处,否则将追究法律责任。
转载于:http://blog.itpub.net/28282660/viewspace-1411523/

















 1723
1723

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









