




执行摘要
-
读取:观察到一致的聚合吞吐量 (Ops) 和读取延迟。
-
写入:观察到一致的写入延迟,直到集群达到大约。其容量的 90%。
-
在整个测试周期中,我们没有观察到 CPU、内存、HDD、NVMe、网络方面的任何瓶颈。我们也没有观察到 Ceph 守护进程的任何问题,这些问题表明集群在处理存储对象的数量方面存在困难。
-
该测试是在一个相对较小的集群上进行的。元数据溢出到较慢的设备和集群容量的大量使用的组合效应影响了整体性能。这可以通过适当调整 Bluestore 元数据设备的大小并在集群中保持足够的可用容量来缓解。
业绩总结
-
成功摄取超过 10 亿(准确地说是 1,014,912,090)个对象,通过 S3 对象接口分布在 10K 个桶中到 Ceph 集群中,操作或数据一致性挑战为零。这证明了 Ceph 集群的可扩展性和健壮性。
-
当集群中的对象数量接近 8.5 亿时,我们的存储容量就用完了。当集群填充率达到约 90% 时,我们需要为更多对象腾出空间,因此我们从之前的测试中删除了较大的对象并激活了平衡器模块。它们结合起来产生了额外的负载,我们认为这会降低客户端吞吐量并增加延迟。
-
不利的写入性能反映了 Bluestore 元数据从闪存溢出到慢速媒体。对于涉及存储数十亿个对象的用例,建议为 Bluestore 元数据 (block.db) 设置适当大小的 SSD,以避免 RocksDB 级别溢出到较慢的媒体。
-
使用bluestore_min_alloc_size = 64KB 会导致小型纠删码对象出现显着的空间放大。
-
减少bluestore_min_alloc_size 消除了空间放大问题,但是因为 18KB 不是 4KB 对齐的,所以导致对象创建率降低。
-
SSD的默认bluestore_min_alloc_size 将在 RHCS 4.1 中更改为 4KB,并且正在努力使 4KB 也适用于 HDD。
-
对于批量删除操作,发现 S3 对象删除 API 与 Ceph Rados API 相比要慢得多。因此,我们建议使用对象过期存储桶生命周期或 radosgw-admin 工具进行批量删除操作。
测试方法
为了将 10 亿个对象摄取到 Ceph 集群中,我们使用了 COSBench 并执行了数百轮测试,其中每一轮包括
-
创建 14 个新存储桶。
-
每个桶摄取(也称为写入)100,000 个 64KB 负载大小的对象。
-
在 300 秒内尽可能多地阅读书面对象。
结果
Ceph 被设计成一个内在可扩展的系统。我们在这个项目中进行的十亿对象摄取测试强调了 Ceph 可扩展性的一个非常重要的维度。在本节中,我们将分享我们在将 10 亿个对象摄取到 Ceph 集群时捕获的发现。
读取性能
图 1 表示以聚合吞吐量 (ops) 指标衡量的读取性能。图 2 显示了平均读取延迟,以毫秒为单位(蓝线)。这两个图表都显示了 Ceph 集群强大且一致的读取性能,同时测试套件摄取了超过 10 亿个对象。在整个测试期间,读取吞吐量保持在 15K Ops - 10K Ops 的范围内。这种性能变化可能与高存储容量消耗(~90%)以及后台发生的旧大对象删除和重新平衡操作有关。
图 1:对象计数与聚合读取吞吐量操作
图 2 比较了我们摄取对象时读取和写入测试的平均延迟(以毫秒为单位)(从客户端测量)。鉴于此测试的规模,读取和写入延迟都保持非常一致,直到我们用完存储容量和大量 Bluestore 元数据溢出到慢速设备。
测试的前半部分显示,与读取相比,写入延迟保持较低。这可能是 Bluestore 效应。我们过去进行的性能测试显示了类似的行为,其中发现 Bluestore 写入延迟略低于 Bluestore 读取延迟,这可能是因为 Bluestore 不依赖 Linux 页面缓存来进行预读和操作系统级缓存。
在测试的后半部分,与写入相比,读取延迟保持较低,这可能与 Bluestore 元数据从闪存溢出到慢速硬盘驱动器有关(在下一节中解释)。
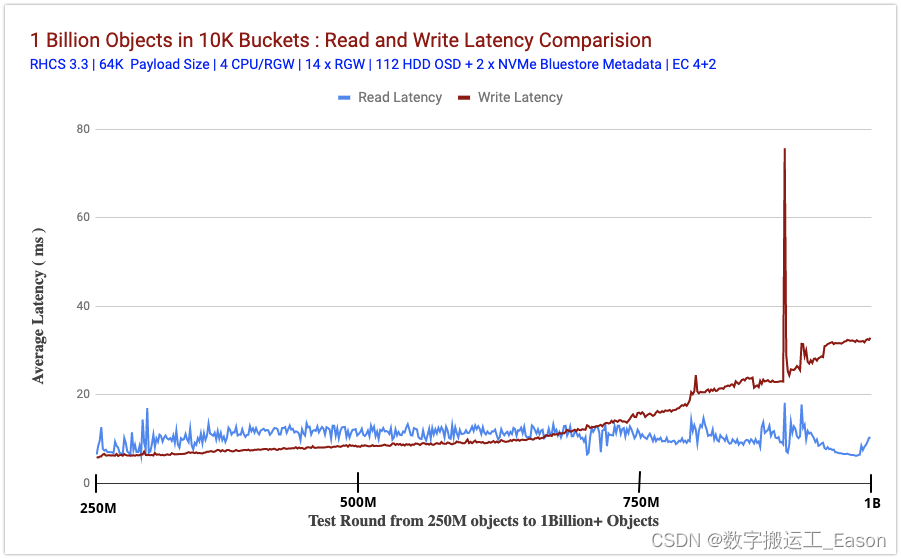
图 2:读写延迟比较
写入性能
图 3 表示通过其 S3 接口将 10 亿个 64K 对象摄取(写入操作)到我们的 Ceph 集群。测试从大约 2.9 亿个对象开始,这些对象已经存储在 Ceph 集群中。
这些数据是由之前的测试运行创建的,我们选择不删除它并从此时开始填充集群,直到我们达到超过 10 亿个对象。我们执行了 600 多个独特的测试,并用 10 亿个对象填充了集群。在课程中,我们测量了对象总数、写入和读取吞吐量 (Ops)、读取和写入平均延迟 (ms)等 指标。
在大约 5 亿个对象时,集群达到其可用容量的 50%,我们观察到聚合写入吞吐量性能呈下降趋势。经过数百次测试后,聚合写入吞吐量继续下降,而集群使用容量达到了惊人的 90%。
从这一点来看,为了实现我们的目标,即摄取 10 亿个对象,我们需要更多的可用容量,因此我们删除/重新平衡了大于 64KB 的旧对象。
通常,我们知道存储系统的性能随着整体消耗的增长而逐渐下降。我们在 Ceph 上观察到类似的行为,在使用容量的大约 90% 时,聚合吞吐量与我们最初的情况相比有所下降。因此,我们相信如果我们添加更多存储节点以保持较低的利用率,性能可能不会像我们观察到的那样受到影响。
另一个有趣的观察可能是导致聚合性能下降的一个潜在原因,即 Bluestore 元数据频繁从 NVMe 溢出到 HDD。我们摄取了大约 10 亿个新对象,这些对象生成了大量的 Bluestore 元数据。根据设计,Bluestore 元数据存储在 RocksDB 中,建议将此分区放在闪存介质上,在我们的示例中,我们为每个共享的 OSD 使用 80GB NVMe 分区在 Bluestore RocksDB 和 WAL 之间。
RocksDB 内部采用层次式压缩,将 RocksDB 中的文件组织成多个层次。例如Level-0(L0)、Level-1(L1)等。Level-0 比较特殊,内存中的写入缓冲区(memtables)被刷新到文件中,它包含最新的数据。较高级别包含较旧的数据。
当 L0 文件达到特定阈值(可使用level0_file_num_compaction_trigger 配置)时,它们将合并到 L1 中。所有非 0 级别都有一个目标大小。RocksDB 的压缩目标是将每个级别的数据大小限制在目标以下。目标大小计算为级别基本大小 x 10 作为下一个级别乘数。因此,L0 目标大小为 (250MB)、L1 (250MB)、L2(2,500MB)、L3(25,000MB) 等等。
所有级别的目标大小的总和就是您需要的 RocksDB 存储总量。按照 Bluestore 配置的建议,RocksDB 存储应该使用闪存介质。如果我们没有为 RocksDB 提供足够的闪存容量来存储其关卡,RocksDB 会将关卡数据溢出到硬盘等慢速设备上。毕竟,数据必须存储在某个地方。
RocksDB 元数据从闪存设备溢出到 HDD 会大大降低性能。如图表 4 所示,当我们将对象提取到系统中时,溢出的元数据达到每个 OSD 超过 80+GB。
所以我们的假设是,Bluestore 元数据从闪存媒体到慢速媒体的这种频繁溢出是我们案例中聚合性能下降的原因。
因此,如果您知道您的用例将涉及在 Ceph 集群上存储数十亿个对象,则可以通过为每个 Ceph OSD 为 BlueStore (RocksDB) 元数据使用大型闪存分区来减轻性能影响,这样它可以存储最多到闪存上 RocksDB 的 L4 文件。
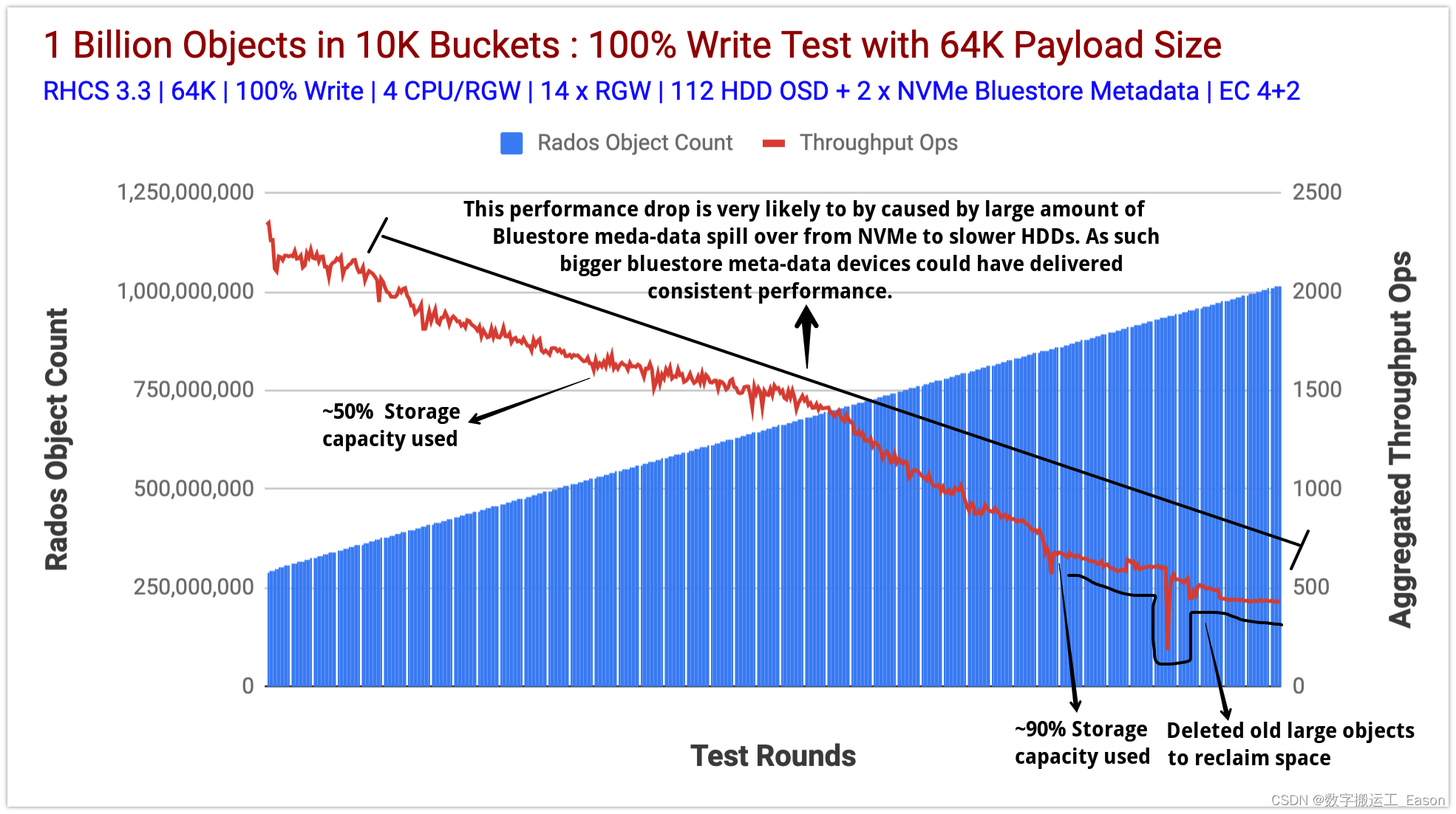
图 3:对象计数与聚合写入吞吐量操作
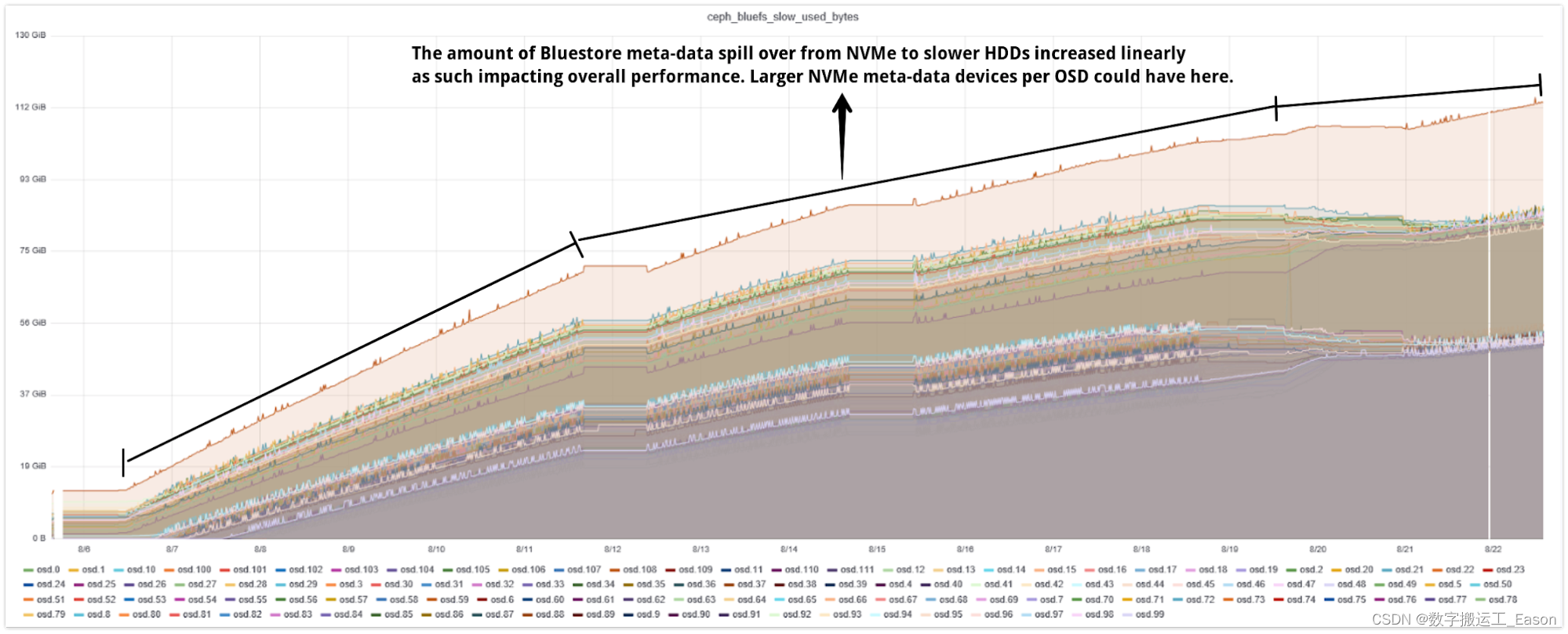
图 4:Bluestore 元数据溢出到慢速 (HDD) 设备
调查结果
在本节中,我们想介绍我们的一些发现。
大规模删除对象
当我们的集群中的存储容量用完时,我们别无选择,只能删除存储在桶中的旧大对象,而我们有数百万个这样的对象。我们最初是从 S3 API 的 DELETE 方法开始的,但我们很快意识到它不适用于存储桶删除,因为必须先删除存储桶中的所有对象,然后才能删除存储桶本身。
我们遇到的另一个 S3 API 限制是每个 API 请求只能删除 1K 个对象。我们有数百个桶,每个桶有 100K 个对象,因此我们使用 S3 API DELETE 方法删除数百万个对象是不切实际的。
幸运的是,使用 radosgw-admin CLI 工具公开的本机 RADOS 网关 API 支持删除加载了对象的存储桶。通过使用本机 RADOS 网关 API,我们花了几秒钟就摆脱了数百万个对象。因此,对于以任何规模删除对象,Ceph 的原生 API 可以派上用场。
修改 bluestore_min_alloc_size_hdd参数
此测试是在具有 4+2 配置的纠删码池上完成的。因此,根据设计,每个 64K 的有效负载必须分成 4 个块,每个块 16KB。Bluestore 使用的 bluestore_min_alloc_size_hdd 参数表示为存储在 Ceph Bluestore objectstore 中的对象创建的 blob 的最小大小,其默认值为 64KB。因此在我们的例子中,每个 16KB EC 块将分配 64KB 空间,这将导致 48KB 未使用空间的开销,无法进一步利用。
因此,在我们的 10 亿对象摄取测试之后,我们决定将bluestore_min_alloc_size_hdd 降低到 18KB 并重新测试。如图表 5 所示,在将 bluestore_min_alloc_size_hdd 参数从 64KB(默认值)降低到 18KB 后,对象创建率显着降低。因此,对于大于 bluestore_min_alloc_size_hdd 的对象,默认值似乎是最佳的,如果您打算减少 bluestore_min_alloc_size_hdd 参数,较小的对象还需要更多调查。请注意,bluestore_min_alloc_size_hdd 不能设置为低于 bdev_block_size(默认 4096 - 4kB)。
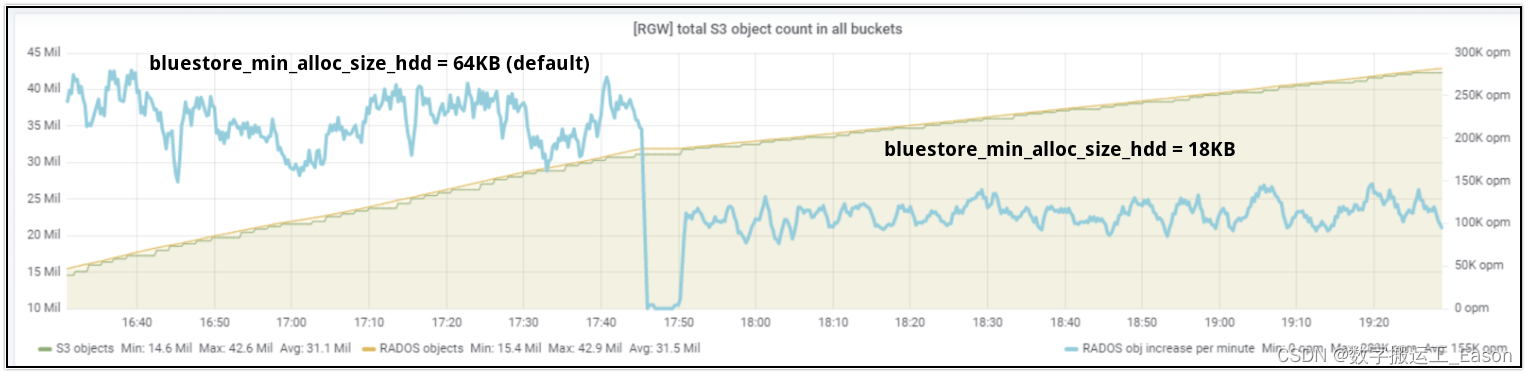
图表 5:每分钟的对象摄取率
总结和下一个
在这篇文章中,我们通过将十亿多个对象摄取到集群中,展示了 Ceph 集群的稳健性和可扩展性。我们了解了与处于最大容量的集群相关的各种性能特征,以及 bluestore 元数据溢出到慢速设备如何降低性能,以及您在设计 Ceph 集群以进行扩展时可以选择的缓解措施。
请珍惜劳动成果,支持原创,欢迎点赞或者关注收藏,你每一次的点赞和收藏都是作者的动力,内容如有问题请私信随时联系作者,谢谢!




















 1266
1266

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











