




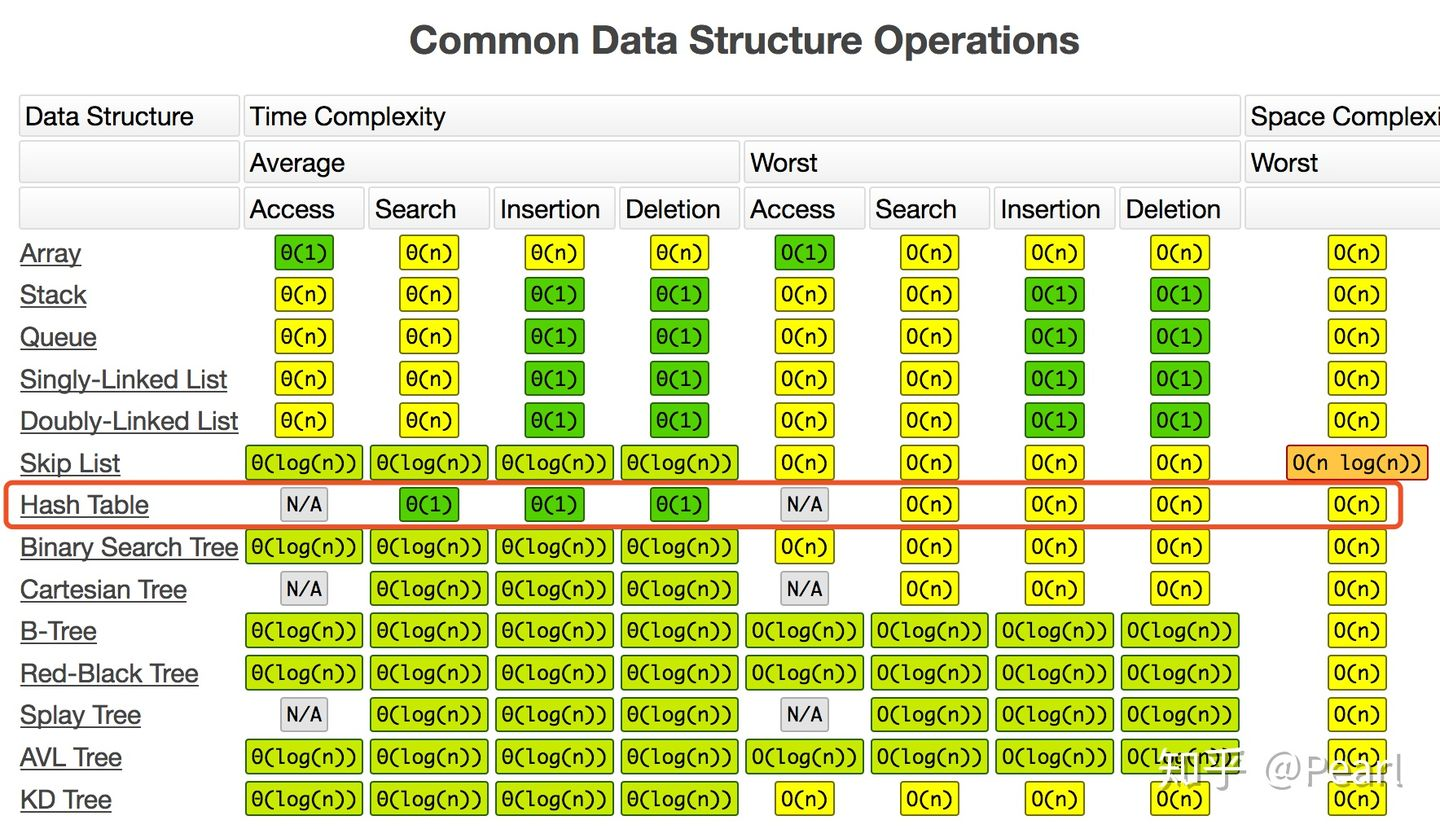
 本文深入探讨HashMap如何解决关联元素对应关系的问题,通过分析其内部结构(数组+链表+红黑树),阐述扩容机制及线程安全性问题,帮助读者理解HashMap的工作原理。
本文深入探讨HashMap如何解决关联元素对应关系的问题,通过分析其内部结构(数组+链表+红黑树),阐述扩容机制及线程安全性问题,帮助读者理解HashMap的工作原理。
map是一种常见的容器 ,此篇简单记载学习后的一些心得
第一个问题:map这种结构是用来解决什么样的问题?
看这样一个例子:假如我们希望将一些人名字的信息存储起来,首先我们想到使用数组存储这些元素
String [] names = new String [10]; names[0] = "张三"; names[1] = "李四"; //...
接下来我们需要存储每个人的身份证号 怎么做?可以把人简单封装成对象放入数组
People zhangsan = new People("张三","11051xxxxxxxx");
People lisi = new People("李四","11051xxxxxxxx");
这时候我们需要查询 11051xxxxxxxx的身份证号是谁要做么做 ? 遍历数组取出每个人的身份证号进行比较才能得到结果。这个算法是非常低效的 ,运行时间最坏为O(n) ,那我们怎么解决这个问题 。我们需要的是一种能表示关联元素对应关系的数据结构 map就为我们解决了这个问题 接下来介绍 本篇的主角hashMap
让我们按照这样的思路去探寻 它能解决什么问题-》它是怎么实现的-》优缺点来看看下面的几个容器
hashMap:首先hashMap 就能解决我们上面的问题,为什么呢?
hashMap使用hashtable搜索在理想情况下执行时间为远远大于 Array
关于hashtable的算法不了解的朋友可以自行百度
hashMap 是怎么实现的呢 ? 让我们直接看源码
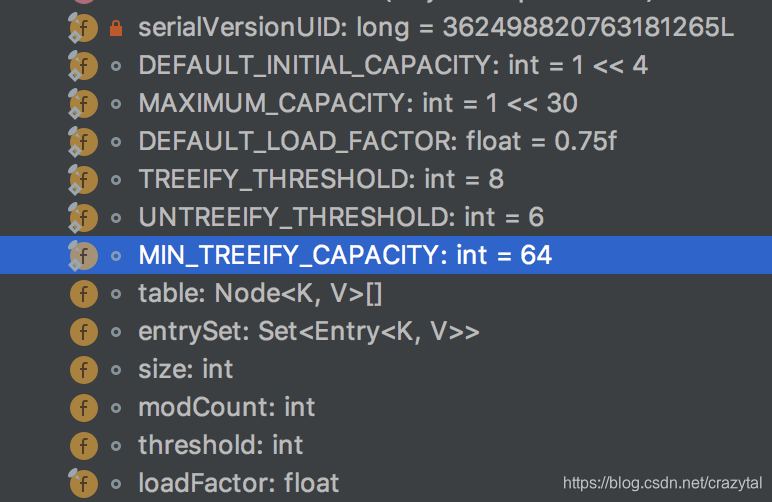
hashMap的所有属性都在这里能作为容器的只有 table 和 entrySet 两个属性是集合,那我们就看看到底是哪个容器
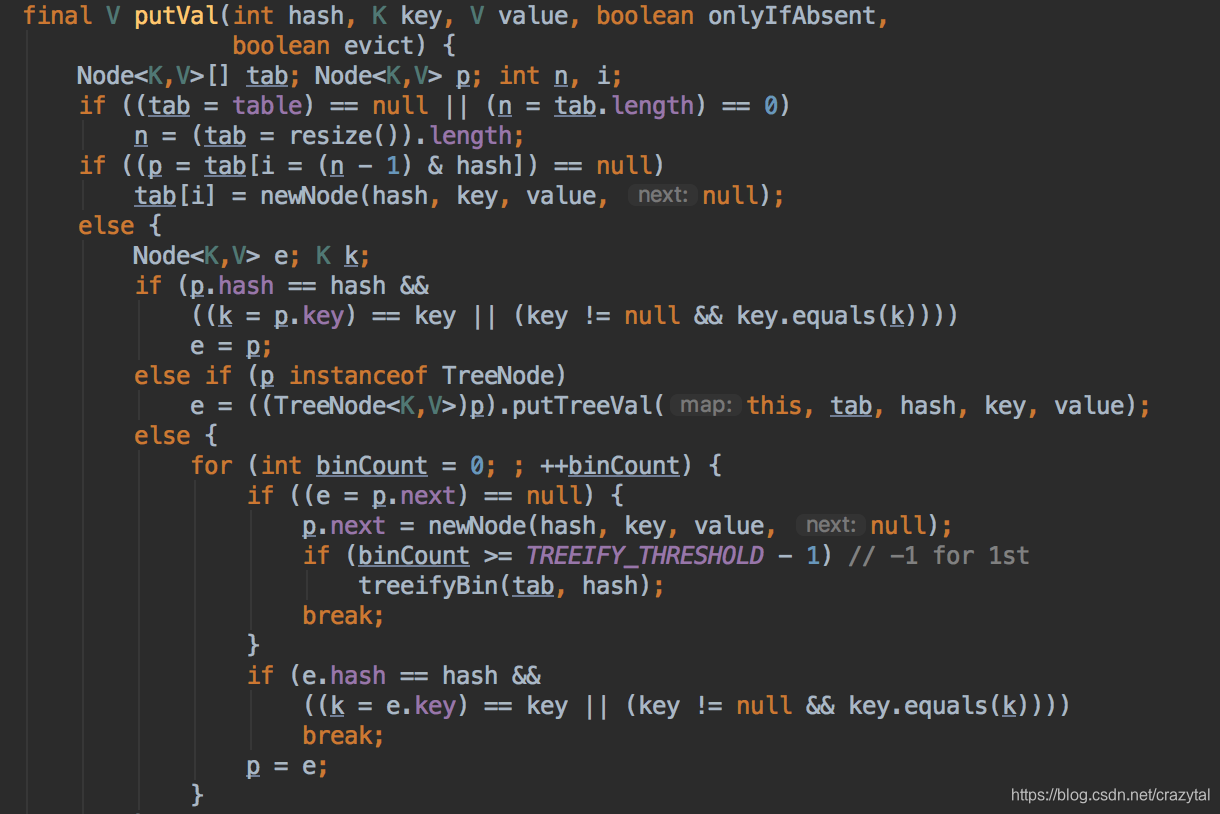
我们通过代码可以看到它是确实存放在我们的table 属性中了 说明table就是承载我们元素的容器 那么table是什么?
通过源代码我们可知就是数组+链表构成 (1.8之后加入了红黑树)
put 方法中:

将获取的index存入数组中,数组中则存放一个链表。
get 方法中:
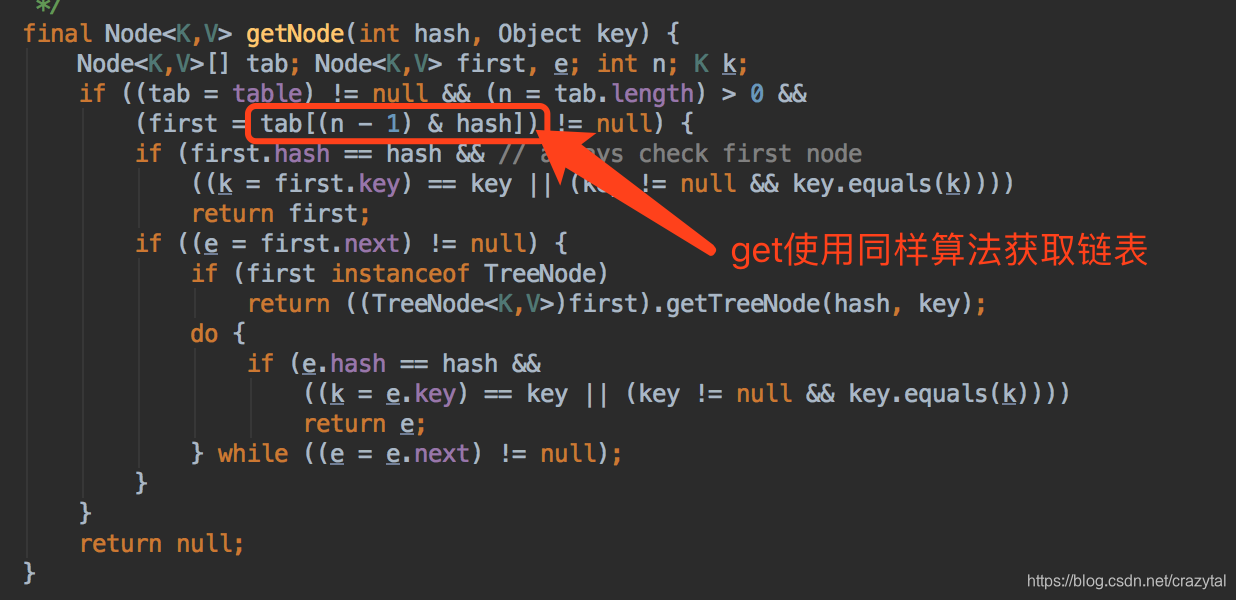
map的存储模型如下:
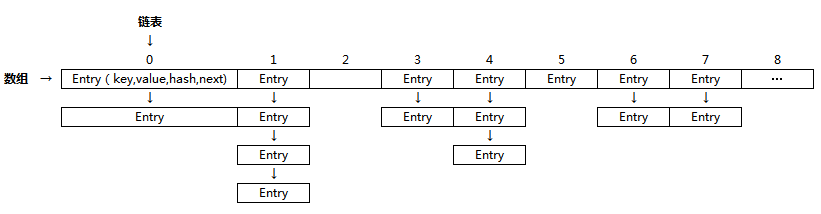
从模型中我们可以看出每条链表的长度将是制约查询速度的主要问题,当我们通过key计算出index后需要遍历每个链表节点的数据得到结果。 假如数据量比较大的情况可能会出现链表都比较长的问题,这个问题hashMap 是怎么解决的呢 扩容
假如1000条数据我们的hashMap的数组长度为10时 我们期望的每个链表长度则为100 当我们扩展到200时 则每条链表的长度期望就是5,这种扩容方案是1.7之前的主要解决方案,1.8则使用红黑树来彻底解决这个问题。
让我们来看看hashMap是如何进行扩容的 这里面用于判断的threshold的值为数组长度的0.75 初始值为12
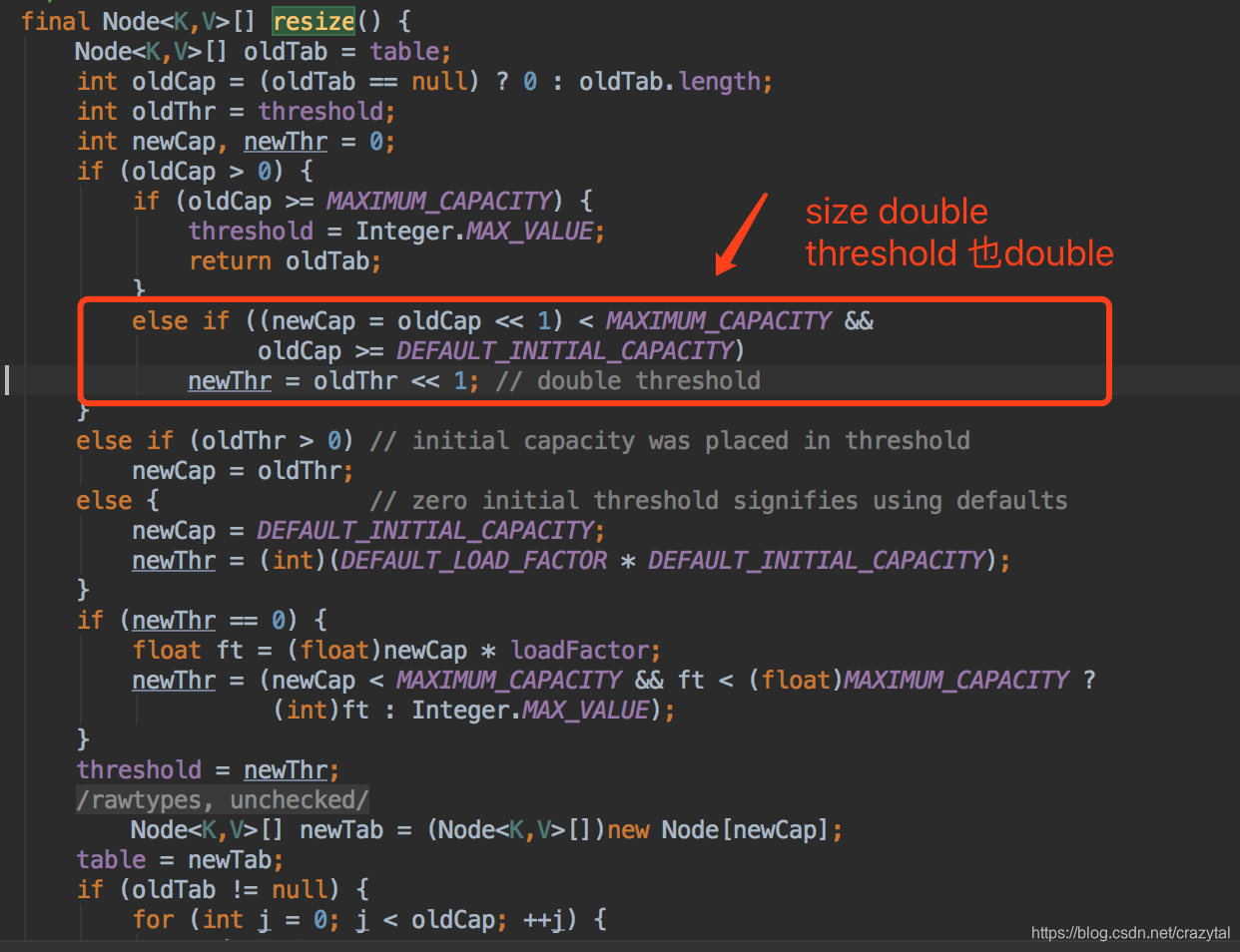
扩容也会带来很大的问题。扩容后会将之前的全部元素重新计算存入扩容后的hashMap会耗费大量资源
最后简单说说我们的hashMap的缺点:线程不安全
总结就到这里欢迎大家指正问题 !! 与君共勉

















 600
600

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









