



本文 的 原文 地址
原始的内容,请参考 本文 的 原文 地址
尼恩说在前面
年底,大厂的hc越来越多, 反而 机会越混越多。 以前的金九银十, 现在变成 黄金年底。
在45岁老架构师 尼恩的读者交流群(50+)中,最近有小伙伴拿到了一线互联网企业如阿里、滴滴、极兔、有赞、希音、百度、网易、美团的面试资格。
前两天一个 小伙伴面 阿里,遇到的一个基础面试题:
延迟双删有什么问题?大厂是如何优雅避开 延迟双删 的?
小伙伴只背过 延迟双删,并没有背过 延迟双删有什么问题, 更没有背过 大厂是如何优雅避开 延迟双删 的?
所以,只能 临阵磨枪 有一句没一句的说了几嘴, 结果 挂了。
回来后 ,小伙伴找尼恩复盘, 求助尼恩。
这里尼恩给大家做一下系统化、体系化的梳理,使得大家可以充分展示一下大家雄厚的 “技术肌肉”,让面试官爱到 “不能自已、口水直流”。也一并把这个题目以及参考答案,收入咱们的 《尼恩Java面试宝典PDF》V176版本,供后面的小伙伴参考,提升大家的 3高 架构、设计、开发水平。
最新《尼恩 架构笔记》《尼恩高并发三部曲》《尼恩Java面试宝典》的PDF,请关注本公众号【技术自由圈】获取,后台回复:领电子书
面试题:延迟双删有什么问题?大厂是如何优雅避开 延迟双删 的?
延迟双删(Delayed Double Delete)是一种用于缓解缓存与数据库不一致问题的常用策略,广泛应用于以 Redis 为缓存、MySQL 为持久化存储的系统架构中。
延迟双删的核心问题在于 需要“猜测时间” 。
延迟双删 依赖的“时间窗口” 精确控制,但在真实高并发场景中,请求耗时波动大、网络延迟不可控、读写竞争复杂, 都无法确保第二次删除 需要延迟多长。
这种基于“猜测时间”的机制本质上是脆弱且不可靠的。
1.1 什么是延迟双删?
延迟双删(Delayed Double Delete)设计初衷是解决“写操作期间读请求并发导致缓存污染”的典型问题。
首先看看延迟双删的起源。
在典型的缓存架构中,我们通常采用 Cache-Aside 模式:先更新数据库,再删除缓存。
理想情况下,后续请求会从数据库读取最新值并重建缓存。
但在高并发+ 主从数据同步 场景下, Cache-Aside 模式 可能存在数据不一致问题:
(1) 线程A更新主库数据;
(2) 再删除缓存;
(3) 此时线程B发起查询,由于主从同步延迟,从库尚未收到更新;
(4) 查询返回旧数据,并被写回缓存(脏数据“复活”);
(5) 后续请求持续命中这个错误缓存,直到过期。
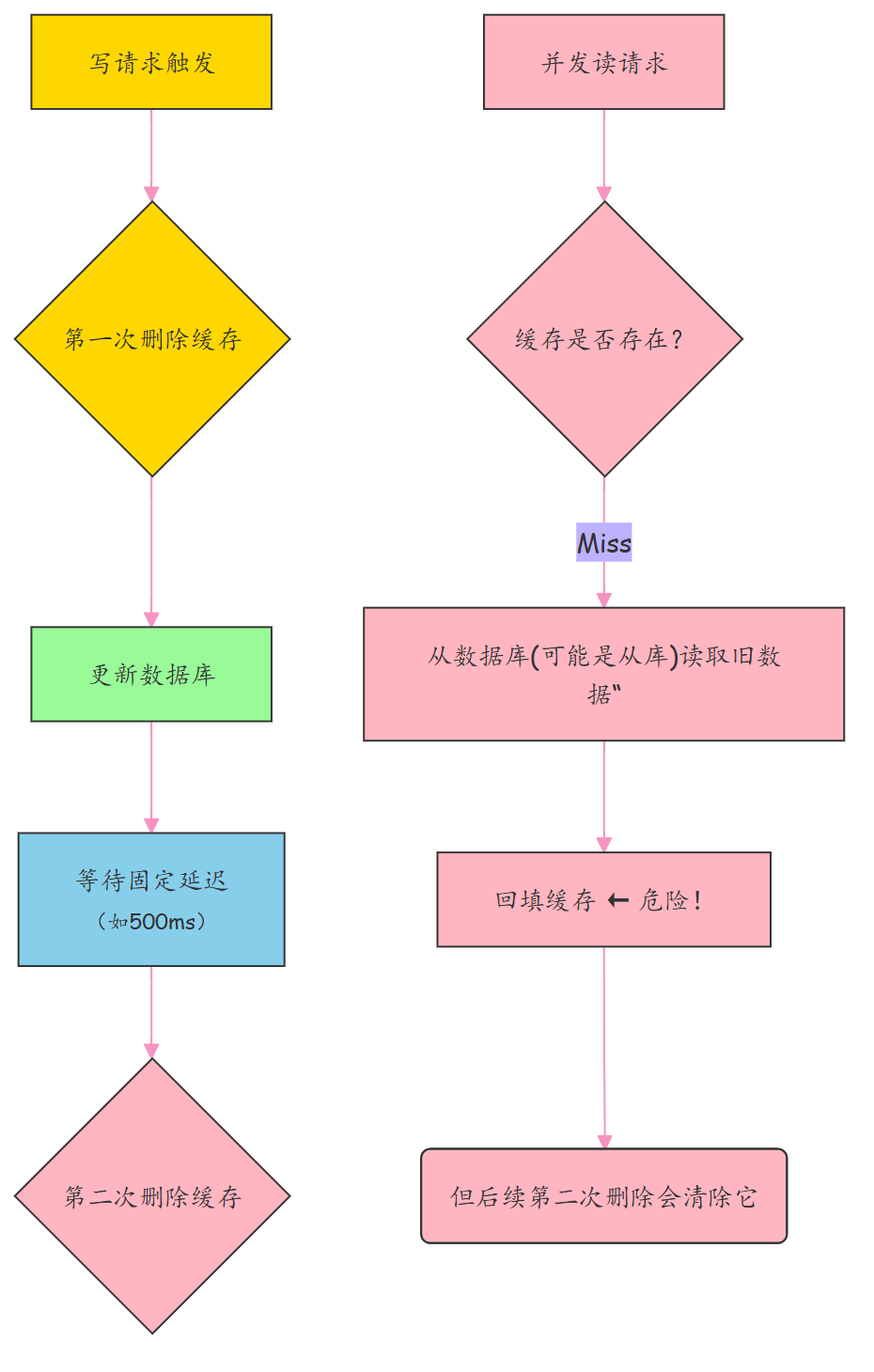
为应对这种情况,“延迟双删”应运而生。其执行流程如下:
**(1) 更新数据库**
↓
**(2) 删除缓存(第一次)**
↓
**(3) 等待固定时间(如500ms)**
↓
**(4) 再次删除缓存(第二次)**
延迟双删(Delayed Double Delete) 设计逻辑是:
- 给主从复制留出时间窗口,让从库完成同步;
- 第二次删除则清除可能已被污染的缓存,从而降低脏数据残留概率。
通过“先删缓存 → 更新数据库 → 延迟后再次删除缓存”的两阶段清除机制,在关键窗口期内切断旧数据回流路径,从而降低脏读概率,是一种简单但有效的最终一致性保障手段。
这就是 延迟双删(Delayed Double Delete)。
延迟双删(Delayed Double Delete) 的核心流程如下:
(1) 第一次删除:在更新数据库之前,主动删除缓存中的旧数据;
(2) 更新数据库:执行实际的数据修改操作;
(3) 延迟等待:等待一段预设时间(例如 500ms),确保在此期间可能发生的读请求已完成数据库查询并尝试回填缓存;
(4) 第二次删除:再次删除缓存,清除可能由读请求误写入的旧数据副本。
延迟双删 核心流程 图解
延迟双删 目的明确:
防止在数据库更新过程中, 并发 读请求因未命中缓存, 而从旧数据库状态加载数据 后,将旧数据错误地回填到缓存中, 导致 缓存脏数据问题。
典型并发场景示例:
- 线程A(写操作):删缓存 → 改DB → (延迟)→ 再删缓存
- 线程B(读操作):查缓存(miss)→ 查DB(旧值)→ 回填缓存(此时写线程还未提交)
→ 若无第二次删除,缓存将长期持有旧数据!
当然,延迟双删不能完全保证强一致性,它属于最终一致性范畴。
但在多数业务可接受的范围内显著提升了数据可靠性,尤其适用于对实时性要求不高、但对数据准确性较敏感的场景,如商品库存、用户资料等。
二、问题分析:延迟双删的四大缺陷
尽管延迟双删被广泛用于缓解缓存与数据库的一致性问题,但在实际应用中仍暴露出诸多难以忽视的缺陷。
其本质是在“时间”上做妥协,试图用等待来换一致性,但这种做法在复杂多变的生产环境中往往力不从心。
核心痛点:
延迟双删的核心痛点在于——它依赖不可控的时间窗口来保证数据一致,而这个窗口既无法精准设定,又极易被系统动态因素打破,导致一致性失效和资源浪费。本质上,它是用“时间”对抗“不确定性”,注定无法稳定可靠。
2.1. 固定的延迟时间难以精确控制
延迟多久才够?100ms?500ms?没有标准答案。
实际所需时间受主从复制延迟、网络抖动、系统负载等多重动态因素影响,波动大。
固定延迟是一种“拍脑袋”决策:
- 设短了,从库还没同步完,旧数据可能被重新写入缓存;
- 设长了,缓存长期不生效,性能受损,用户体验下降。
更严重的是,不同业务、不同表、不同集群的延迟差异巨大,统一配置难以适配。
延迟时间难以精确控制 的根本原因:用静态策略应对动态环境,注定顾此失彼。
2.2. 无法彻底保证最终一致性
- 即使设置了延迟,也无法杜绝脏数据风险。
- 在第二次删除执行前,若有读请求访问缓存(未命中),会从数据库加载数据并回填缓存。
- 如果此时读的是尚未同步最新数据的从库,就会把旧值重新写入缓存,形成“伪刷新”。
- 后续请求将持续读到脏数据,直到下一次删除或过期,一致性彻底崩溃。
典型场景:高主从延迟 + 高频读 = 脏数据雪崩。
2.3. 第二次删除失败,缓存将永久残留旧数据
- 第二次删除需通过定时任务、延迟队列或异步线程实现,引入额外组件。
- 若服务宕机或任务丢失,第二次删除失败,缓存将永久残留旧数据。
- 必须配套设计补偿机制(如定期扫描、监控告警),进一步抬高开发与运维成本。
- 故障排查困难:日志分散在多个线程/服务中,难以追踪“谁删了缓存”“为什么没删”。
代价高昂:为一个临时方案投入大量稳定性建设。
2.4. 一次更新删除2次 写操作多了一倍,高并发场景会导致击穿
- 一个缓存更新删除2次, 写操作多了一倍。 频繁写操作场景, 缓存会被频繁删除,引发大量缓存未命中。
- 每次未命中都可能触发回源查询,数据库压力骤增,易引发缓存击穿或雪崩。
- “删除 → 读取重建 → 再次删除”的循环模式造成大量重复IO和计算浪费。
- 在热点数据场景下尤为明显,性能损耗显著。
恶性循环:越写越删,越删越查,系统雪上加霜。
三、方案设计:大厂如何优雅规避延迟双删?
核心痛点:
缓存与数据库的一致性难以保障,根本问题在于“写后删除缓存”这一操作的异步性和不可靠性。当更新数据库后立即(或延迟)删除缓存时,若中间存在并发读写、网络延迟或服务宕机,极易导致旧数据被重新加载进缓存,造成“脏读”。更严重的是,这种问题难以复现和监控,往往在高并发场景下突然爆发。
核心方案:
放弃依赖“时间窗口”的延迟双删策略,转而通过 事件驱动 + 版本控制 的方式实现解耦与安全更新。即:用数据库变更日志主动触发缓存清理,并借助版本机制防止旧数据覆盖新缓存,最终在系统层面达成最终一致性。
方案1 :弱一致方案 Cache-Aside + Binlog 异步更新(阿里/美团实践)
弱一致 Binlog 异步更新核心思想
Cache-Aside + Binlog 异步更新 , 不再由业务代码直接操作缓存,而是通过监听数据库的变更日志(Binlog),异步感知数据变化并触发缓存删除。
这种方式将缓存维护逻辑从主流程中剥离,避免了因程序异常或网络抖动导致的缓存不一致问题。
弱一致Binlog 异步更新架构流程
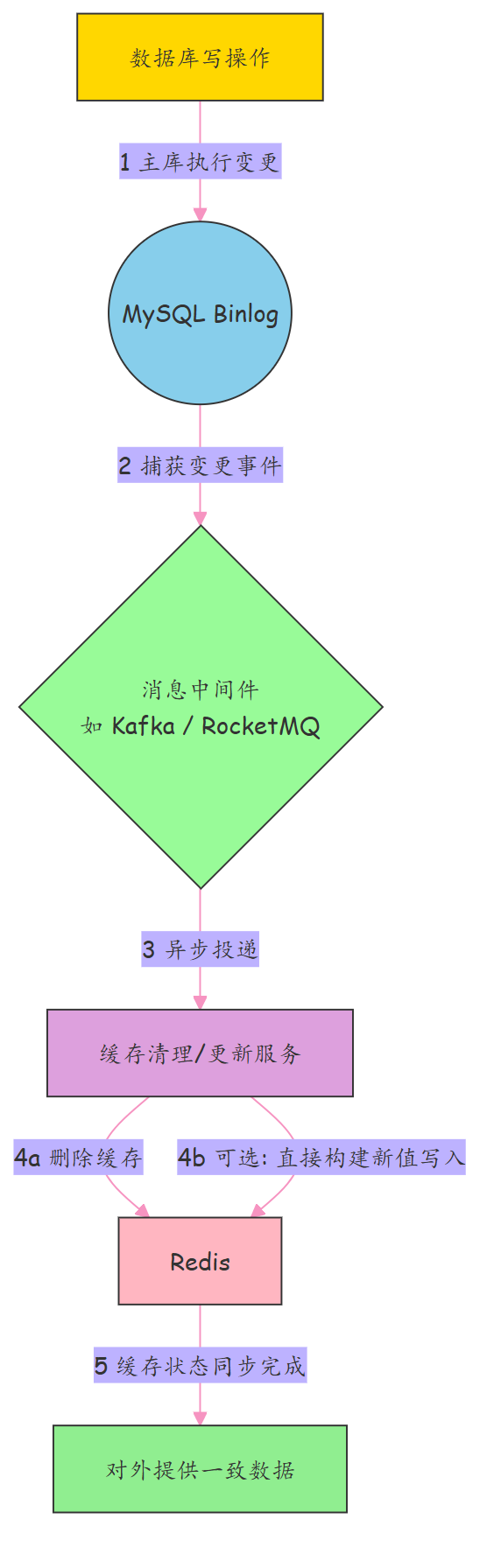
Binlog 异步更新 流程说明
1、所有数据变更通过主库执行,并生成 binlog;
2、通过 中间件(如 Canal)捕获 Binlog 、监听 binlog,发送至消息队列;
3、 独立的消费者服务消费消息,执行对应的 消费 操作,异步删除 对应缓存项(或预加载新值);
4、保证“只要有写,就有缓存清理”,不依赖时间猜测;
5、实现最终一致性,且无固定延迟、无脏数据风险。
Binlog 异步更新 优势
- 可靠性高:利用 MQ 的持久化与重试机制,确保删除指令最终可达。
- 解耦清晰:业务无需关心缓存逻辑,专注核心流程。
- 可追溯性强:所有缓存变更均有日志记录,便于排查问题。
Binlog 异步更新 方案对比
-
延迟双删的根本问题是以固定的“时间等待”对抗动态的“系统延迟”,导致一致性不可控、资源浪费、维护困难。
-
Binlog 异步更新, 属于事件驱动缓存更新机制,让每一次数据变更都主动触发缓存清理,实现精准、可靠、低侵入的最终一致性。
弱一致 Binlog 异步更新 适用场景
适用于高并发读(读多写少)、允许短暂不一致的业务场景,例如商品详情页、用户资料展示等。
阿里巴巴、美团内部广泛使用 Binlog 异步更新,支撑大规模数据同步与缓存更新,实现 高并发 缓存 弱一致。
方案2:分布式锁 + 版本号控制( 强一致性场景)
设计背景
对于账户余额、金融交易流水等强一致性要求的场景,不能接受任何中间状态被外部读取。
此时需牺牲部分性能换取绝对正确性。
核心思想
通过 分布式锁 + 数据版本号 控制访问时序,确保“写未完成前,读不会看到旧值”。
通过在数据中引入版本字段(如 version 或 update_time),读取时校验版本,防止低版本数据污染高版本缓存。
写入流程
- 更新数据库,同时递增 version 字段;
- 立即删除缓存(无需延迟);
- 下次读请求触发缓存重建时,携带最新版本信息回填。
读取流程
-
先查缓存,
-
如果没有,查 DB 获取当前 version,再比对缓存中的 version;
-
若 DB version >缓存 version, 才允许写缓存 ,说明 当前数据版本 >= 缓存中标记的版本, 缓存版本过期;
-
返回 结果。
def get_data(key):
data = redis.get(key)
if not data:
# 缓存未命中,查数据库
fresh_data = db.query()
# 只有当前数据版本 >= 缓存中标记的版本,才允许写回
if fresh_data.version >= get_cached_version(key):
redis.set(key, fresh_data, version=fresh_data.version)
return fresh_data
return data
串行化+版本号控制 实现要点
(1) 更新数据时,在 DB 中增加 version 字段(或使用 timestamp);
(2) 写操作加锁(如 Redis 分布式锁),保证同一 key 的读写串行;
(3) 写流程:先更新 DB(含 version+1),再删除缓存;
(4) 读流程:先查 DB 获取当前 version,再比对缓存中的 version;
- 若 DB version >缓存 version, 当前数据版本 >= 缓存中标记的版本,才允许写回;;
- 返回 结果。
串行化+版本号控制 示例流程
**(1) [写] 加锁 → 更新 DB (value=new, version=5) → 删除缓存 → 释放锁**
**(2) [读] 查询 DB 得 version=5 → 而查缓存得 version=4 → 重新构建缓存**
优势
- 实现近似“强一致性”语义;
- 防覆盖保护:防止主从延迟期间读到旧数据后写入缓存;即使缓存删除失败或滞后,也能阻止旧数据回填。
- 支持智能缓存刷新策略(如仅当版本不一致时才穿透)。
缺点
- ️ 锁带来性能开销,不适合高频读写的大批量 key;
- ️ 需改造表结构和 DAO 层逻辑,侵入性强;
- ️ 锁竞争可能导致超时或雪崩,需谨慎设计降级策略。
适用场景:金融交易流水、 账户余额 等关键数据。
方案3:Write Through + 缓存代理层
思路:
把缓存当成唯一入口,写操作统一由代理处理
与其让每个服务自己管理“先删缓存还是先改库”,不如封装一层统一的数据访问层,对外暴露缓存接口,内部自动完成数据库同步。
- 所有写请求都发往缓存代理层;
- 代理层执行 Write Through 策略:先写数据库,成功后再更新/删除缓存;
- 或直接使用支持持久化的 Redis 增强版存储(如 Tendis、Pika),兼具高性能与数据安全;
- 对业务方透明,无需关心底层一致性细节。
实现方式:
- 自研统一 DAL(Data Access Layer)中间件;
- 使用兼容 Redis 协议但内置回源写能力的存储系统;
- 结合连接池、熔断降级、监控告警,构建高可用数据网关。
大厂业务场景:
字节跳动部分核心业务采用“缓存即入口”架构,所有读写经由统一代理,极大降低了数据一致性出错的概率。
方案4:逻辑删除 + 异步补偿清理
核心思想:用 “标记失效” 替代 “立即删除 redis key”,或者说,用 “逻辑删除” 替代 “物理删除”。
什么时候物理删除呢? 异步补偿清理 redis key。
逻辑删除通过 “标记 + 异步重建” 机制,从根源上避免缓存失效期间的脏数据暴露:
-
写操作时不直接删除缓存,而是给缓存数据打上 “失效标记”(如添加 is_deleted=true 字段、前缀标识或版本号);
-
读请求优先查询缓存,若检测到 “失效标记”,则直接穿透到数据库读取最新数据,同时异步重建缓存;
-
后台启动低优先级异步任务,批量清理带有 “失效标记” 的缓存数据,释放存储空间,避免无效数据堆积。
逻辑删除 + 异步补偿清理 核心流程:
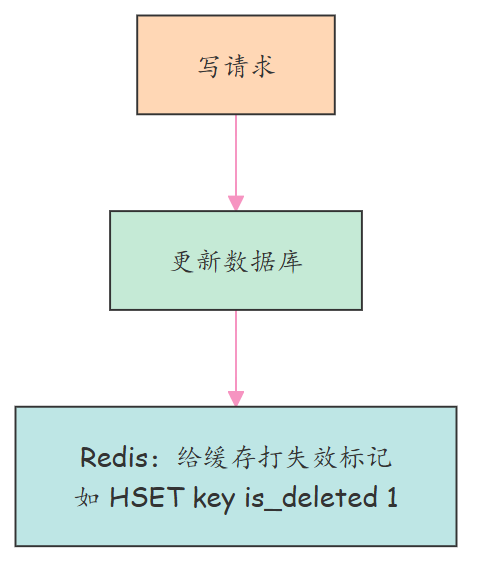
写操作:更新数据库 → 给对应缓存打上 “失效标记”(非删除,操作原子性强);
读操作:查询缓存 → 若有 “失效标记” → 直接查 DB 最新数据 → 重建缓存(覆盖旧标记数据);
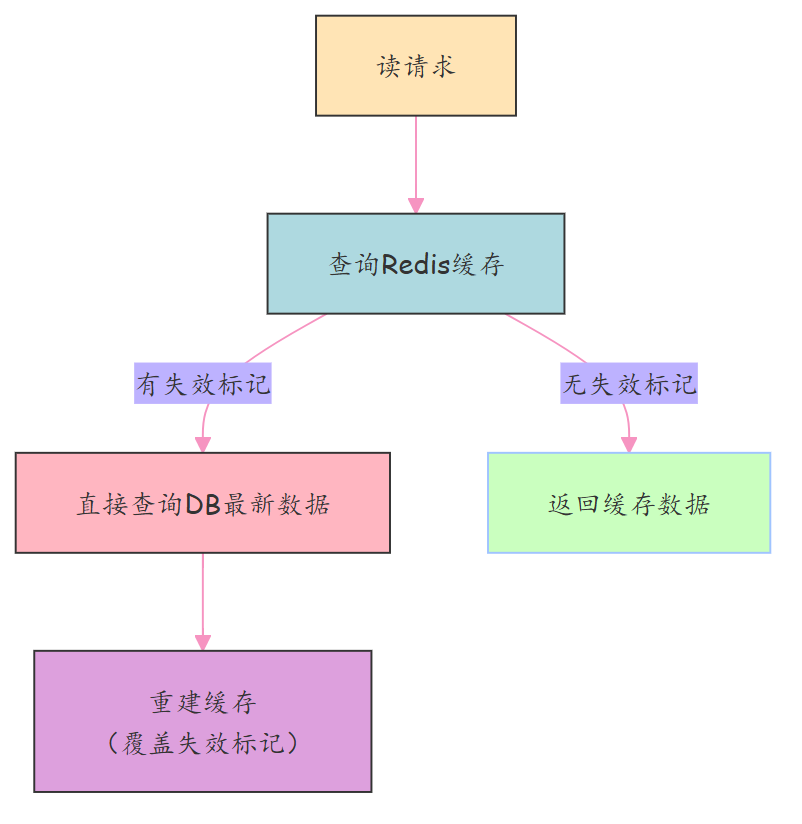
异步清理:定时任务 / 消息驱动,扫描并删除带有 “失效标记” 的缓存项,降低存储冗余。
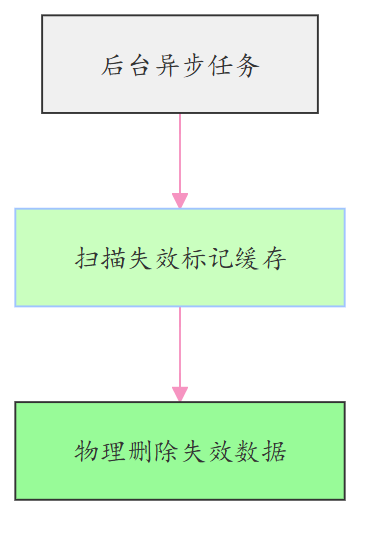
清理时机:
异步清理可选择低峰期执行(如凌晨 2-4 点),或结合缓存访问频率(长期未被访问的失效数据优先清理);
逻辑删除 + 异步补偿清理 的优势:
- **无并发脏读风险:**标记失效后,读请求不会使用旧数据,直接回源,彻底规避 “删除→回填” 的恶性循环;
- **操作轻量高效:**标记操作是原子性的 Redis 指令(如 HSET key is_deleted 1),比删除更高效,且不会引发缓存穿透;
- **适配高并发写:**无需等待延迟时间,写操作快速完成,适合高频更新场景(如用户状态、实时统计数据)。
- **容错性强:**即使异步清理任务失败,“失效标记” 仍能保证读请求正确性,仅需承担少量存储成本;
大厂业务场景:
适配高并发写 场景。
美团、滴滴等大厂在高频更新场景(如订单状态流转、骑手位置更新)中广泛应用此策略,既保证了一致性,又兼顾了高并发场景下的性能与稳定性。
四、思想提炼: 如何从 “架构维度” 解决延迟双删?
延迟双删 在架构层面的不足:
-
延迟双删看似解决了缓存与数据库的一致性问题,实则依赖“固定延迟时间差”来掩盖并发竞争,本质上是一种不确定性的权宜之计。
-
延迟双删 无法保证 在高并发、主从延迟或服务异常时极易出现脏数据,属于典型的“用技巧修补”而非系统性解决。
接下来,就进行一下架构 的升级:
-
架构 升级一:用 “精准驱动” 替代 “固定延迟”。
-
架构 升级二:场景分层,按 “不同一致性等级” 适配不同的 架构方案。
核心架构思想一:精准施策:用 “精准驱动” 替代 “固定延迟”。
-
延迟双删的本质是被动妥协, 关键是: 将缓存更新的固定延迟 , 从 “时间猜测”,转化为 基于数据变更 驱动 的确定性精准时间 。
-
通过 Binlog 捕获、MQ 投递、异步消费,让每一次数据变更,都能精准驱动缓存清理,既避免了固定延迟的顾此失彼,又通过中间件的重试机制保证可靠性,这是解耦复杂系统、提升一致性的核心范式。
核心架构思维二:场景分层,按 “一致性等级” 去匹配 “不同的控制力度”。
世界上没有万能架构,只有适配场景的最优解:
- 高并发读场景+ 弱一致场景用 “Binlog + 异步清理” 实现低侵入、高吞吐;
- 高频写场景用 “逻辑标记 + 异步补偿” 平衡性能与正确性。
- 强一致场景用 “分布式锁 + 版本号” 刚性控制读写时序;
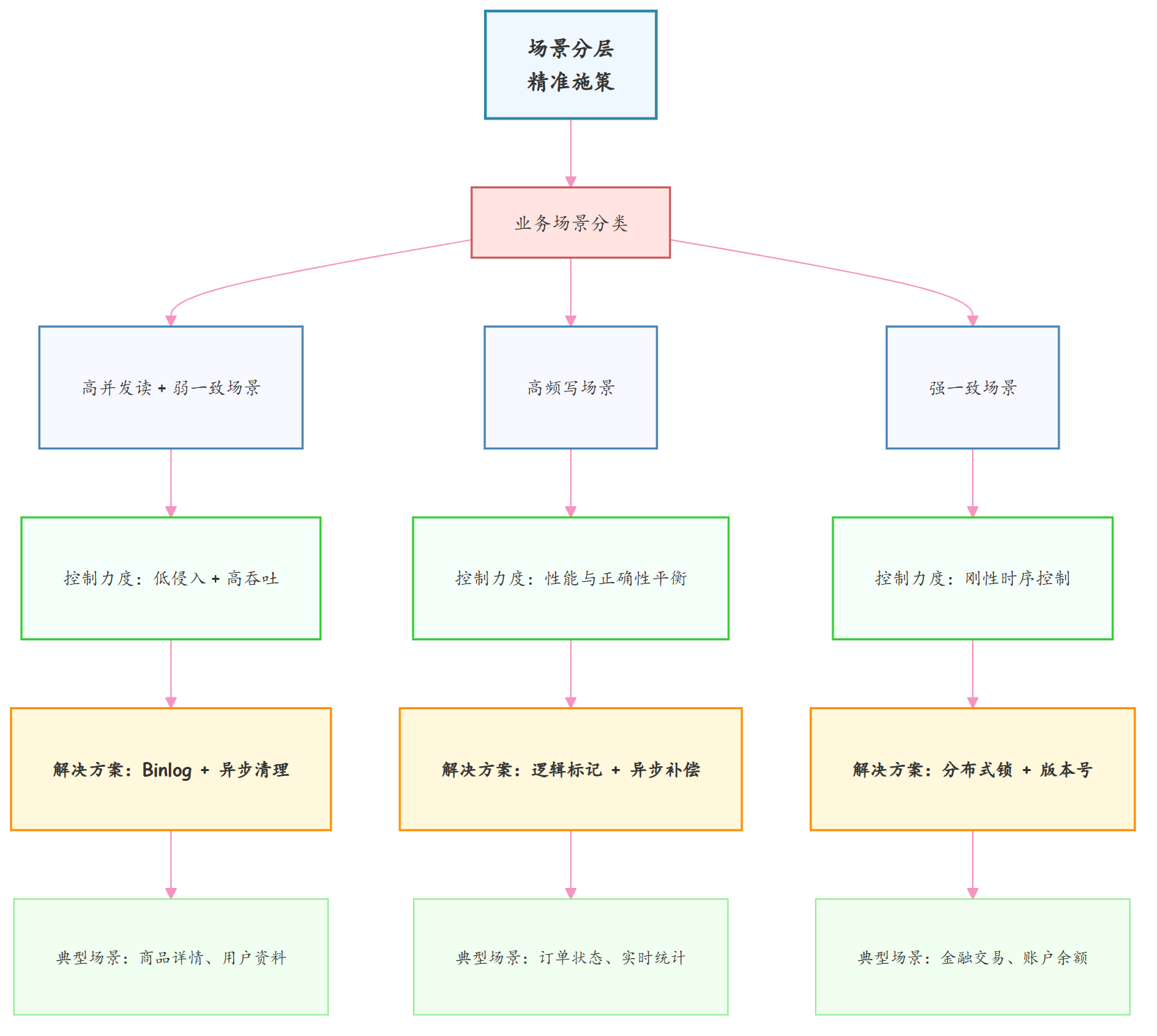
这种 “场景分层 + 精准施策” 的思维,拒绝一刀切的方案,而是在一致性要求、性能损耗、开发成本间找到最优平衡点,这正是架构设计的精髓所在。
五、 延迟双删 如何规避 ? 45岁老架构师 来一次 暴击路线总结
… 略5000字+
…由于平台篇幅限制, 剩下的内容(5000字+),请参参见原文地址

















 912
912

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









