



本文 的 原文 地址
原始的内容,请参考 本文 的 原文 地址
尼恩:百亿级 存储架构的 一个核心问题
在45岁老架构师 尼恩的读者交流群(50+)中,经常性的指导小伙伴们改造简历。 经过尼恩的改造之后,很多小伙伴拿到了一线互联网企业如得物、阿里、滴滴、极兔、有赞、希音、百度、网易、美团的面试机会,拿到了大厂机会。
你的数据存储系统,能扛得住百亿级挑战吗?
你是否遇到过这样的场景:业务数据量日益增长,数据库查询越来越慢,甚至经常超时?
在数据爆炸的时代,如何设计一套高性能、高可靠的百亿级数据存储架构?
面对百亿级数据存储需求,传统的分库分表方案已经力不从心? 那么 百亿级数据存储,怎么设计?
用过哪些 百亿级数据存储 相关组件?HBase 、 TiDB、 Ceph等组件,用过哪些?
HBase 、 TiDB、 Ceph等组件的数据 分片算法是设么?
为什么 TiDB为什么不用一致性哈希? Ceph为什么不用一致性哈希?为什么 HBase为何不用一致性哈希?
最近,很多小伙伴在面试字节、阿里等大厂,或者架构师面试场景,都被问到一个高频问题:一致性哈希那么好?为啥
最近又有小伙伴在面试阿里、网易,都遇到了相关的面试题。
很多小伙伴回答了一些边边角角,但是回答不全面不体系,面试官不满意,面试挂了。
借着此文,尼恩给大家做一下系统化、体系化的梳理,使得大家内力猛增,展示一下雄厚的 “技术肌肉、技术实力”,让面试官爱到 “不能自已、口水直流”,然后实现”offer直提,offer自由”。
一、传统哈希的致命缺陷
1、图片缓存服务的困境场景
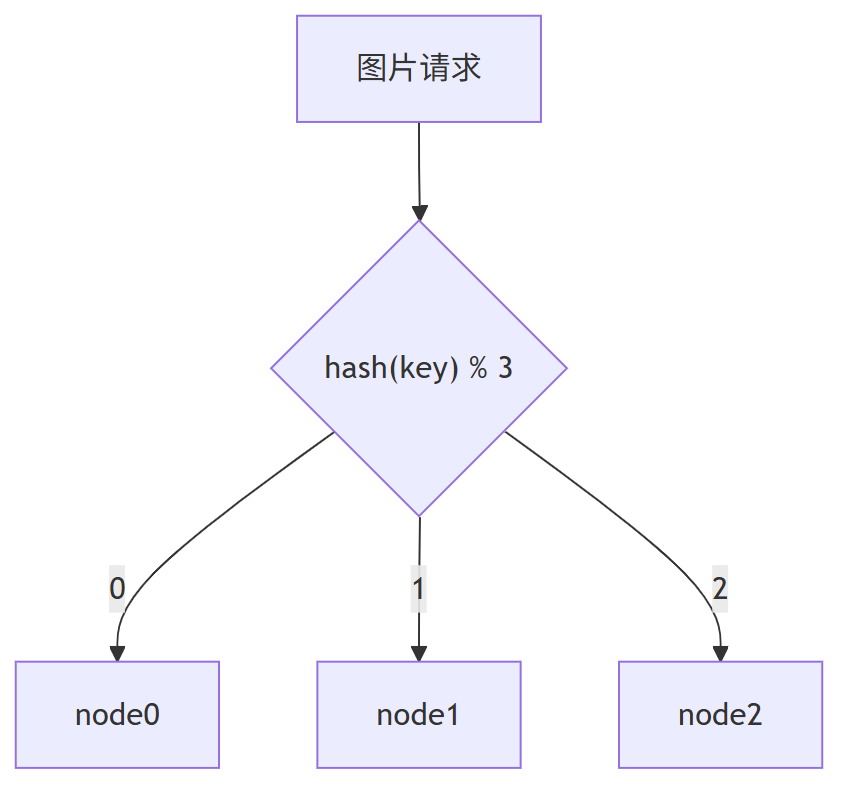
想象你正在搭建一个图片存储服务,需要将3000万张图片均匀分布到3台缓存服务器(node0、node1、node2)。
最直接的解决方案是使用哈希取模算法:
server_index = hash(key) % 3
这个公式简单高效:
hash(key)计算图片的唯一标识% 3将结果映射到0、1或2- 分别对应 node0、node1、node2
2、扩容灾难:3台到4台的雪崩效应
随着业务增长,缓存服务器从3台扩容到4台。
这时灾难开始了:
# 扩容后的计算公式
server_index = hash(key) % 4
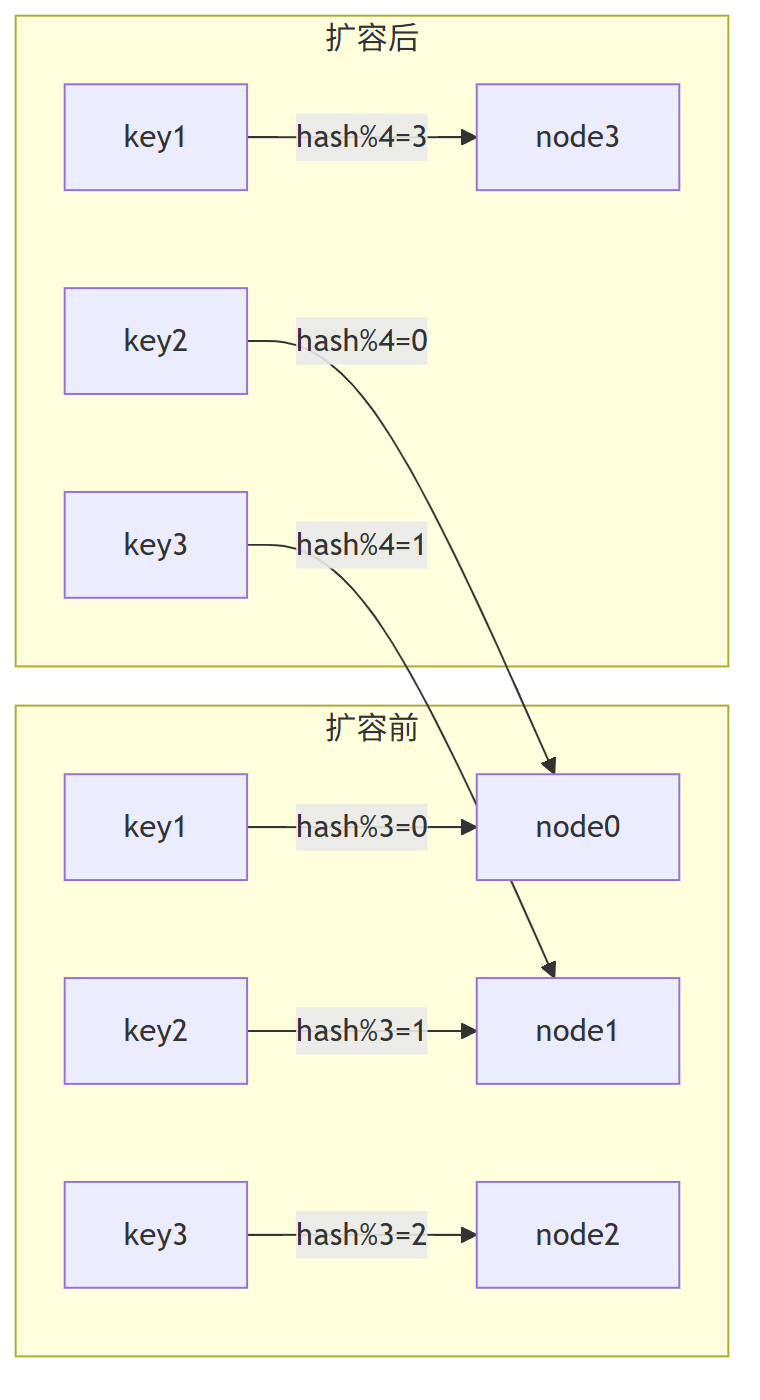
扩容后发生了什么?
1、 缓存位置大洗牌:75%的key会映射到新位置
2、 缓存穿透:请求找不到原有缓存
3、 雪崩效应:海量请求直接冲击数据库
4、 资源浪费:原有缓存成为"僵尸数据"
结果:仅33%的请求能命中缓存,67%的请求直接穿透到数据库!
3、缩容危机:节点故障影响
当节点故障时(如node2宕机),计算公式变为:server_index = hash(key) % 2
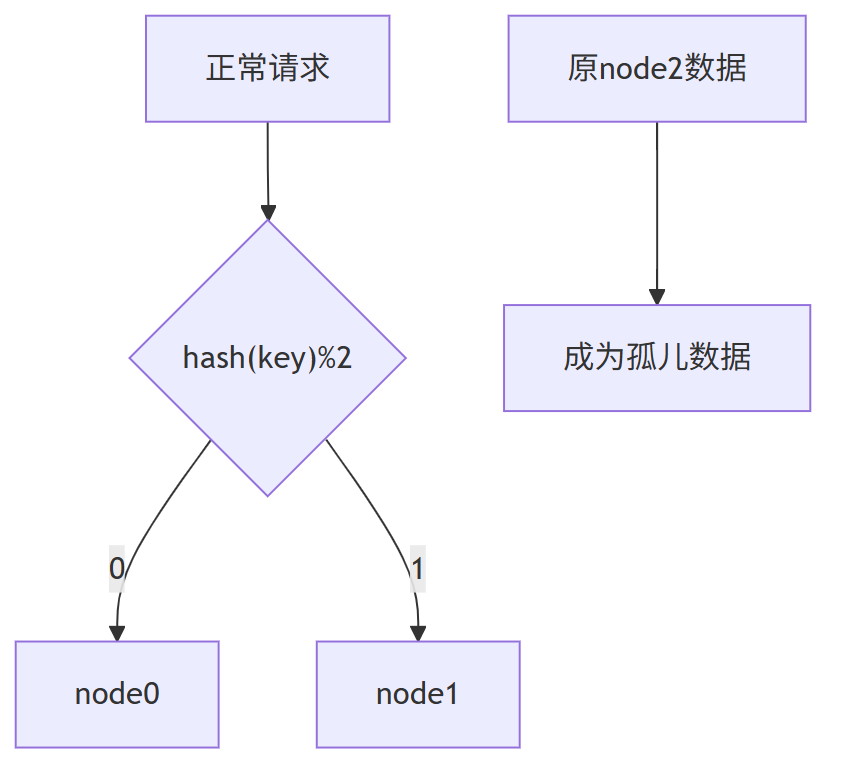
此时:
- 所有原node2的数据变为"孤儿"
- 66%的请求会映射到错误节点
- 缓存系统完全崩溃
4、传统哈希缺陷总结
传统哈希算法在分布式系统中的致命缺陷:
| 问题类型 | 具体表现 | 影响程度 |
|---|---|---|
| 扩容灾难 | 缓存位置大规模迁移 | ★★★★★ |
| 缩容危机 | 孤儿数据导致雪崩 | ★★★★☆ |
| 命中率暴跌 | 缓存穿透到数据库 | ★★★★★ |
| 资源错配 | 成倍扩容造成浪费 | ★★★☆☆ |
正是这些痛点,催生了更优秀的解决方案——一致性哈希算法,它如何巧妙解决这些问题?
二、一致性哈希原理解析
传统哈希取模分片在扩容时带来的数据迁移灾难,催生了更加优雅的解决方案——一致性哈希算法。
与简单粗暴的 hash(key) % N不同,一致性哈希采用了一种环形拓扑结构,从根本上解决了扩容时的数据迁移问题。
1、哈希环核心数据结构
一致性哈希算法的核心创新在于引入了一个固定的哈希空间——哈希环。
这个环的大小固定为 2^32,相当于一个从 0 到 4,294,967,295 的环形数字空间。
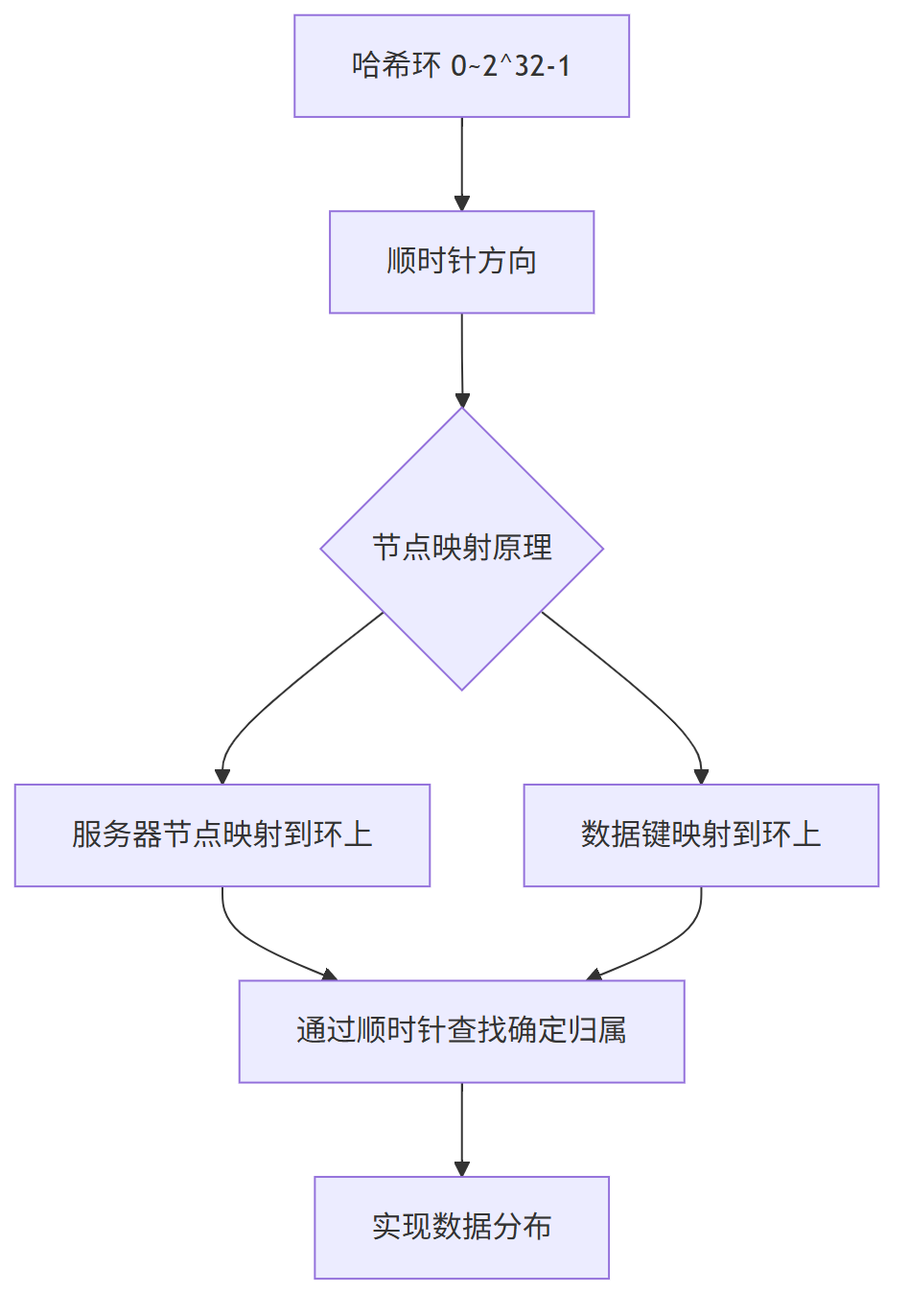
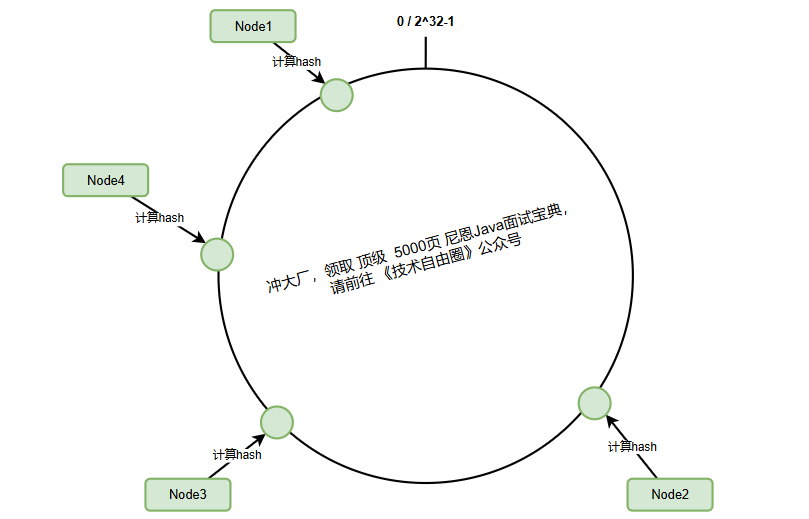
2、服务器节点映射到哈希环
在一致性哈希中,服务器节点通过其标识(通常是IP地址或主机名)映射到哈希环上:
假设我们有四个服务器节点,它们在环上的分布可能如下:
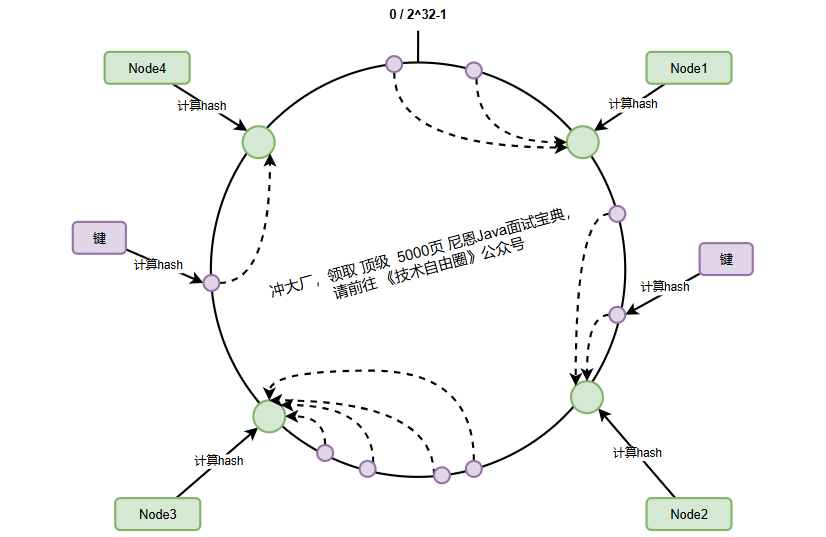
3、数据键的映射与顺时针查找机制
当需要存储或查找数据时,数据键同样被映射到哈希环上,然后通过顺时针查找确定其归属的服务器节点:
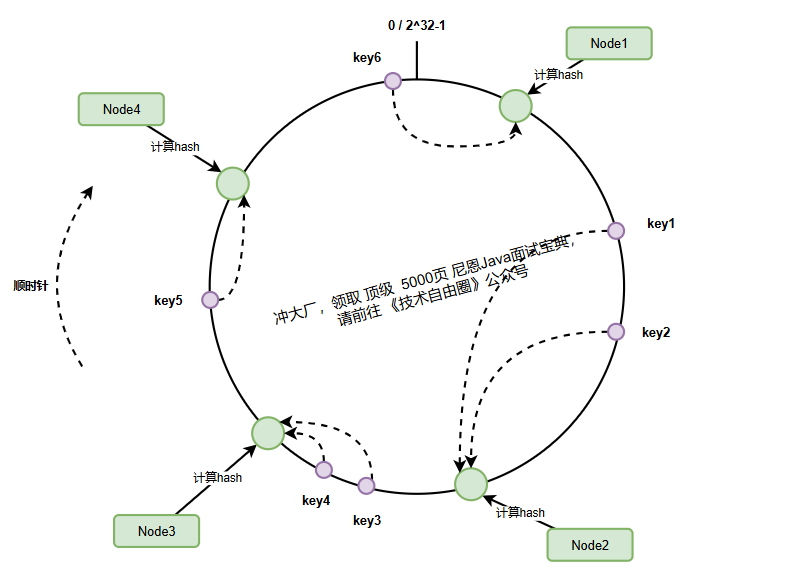
查找规则:从数据键在环上的位置开始,沿顺时针方向找到的第一个服务器节点,就是该数据的归属节点。
key1(哈希500)→ 顺时针找到node2(哈希1000)key2(哈希800)→ 顺时针找到node2(哈希1000)key3(哈希1500)→ 顺时针找到node3(哈希5000)key4(哈希1800)→ 顺时针找到node3(哈希3000)key5(哈希3500)→ 顺时针找到node4(哈希4000)key6(哈希4800)→ 环尾回到环首,找到node1(哈希3000)
三、一致性哈希的优势分析
一致性哈希算法最强大的能力在于它能优雅应对节点变化,避免传统哈希扩容时的大规模数据迁移问题。
让我们通过两个典型场景深入剖析:
1、优雅扩容:避免大规模数据迁移
当新增节点node-5加入集群时,它被映射到node-1和node-2之间的哈希环位置:
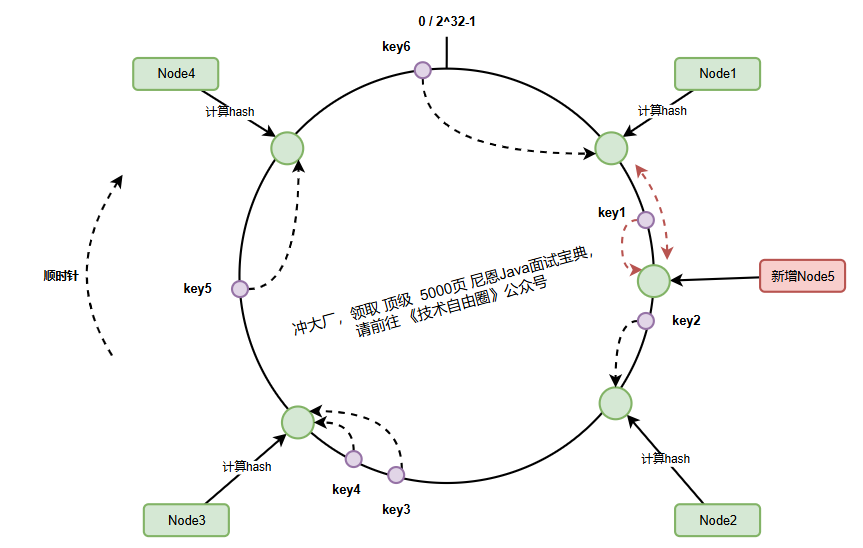
此时:
- 仅
node-1和node-5之间的数据需要迁移(图中红色区域) key-1从node-2迁移到node-5- 其他90%以上的数据保持原位置不变
2、优雅缩容:节点故障时的自动容灾
当node-1宕机时:
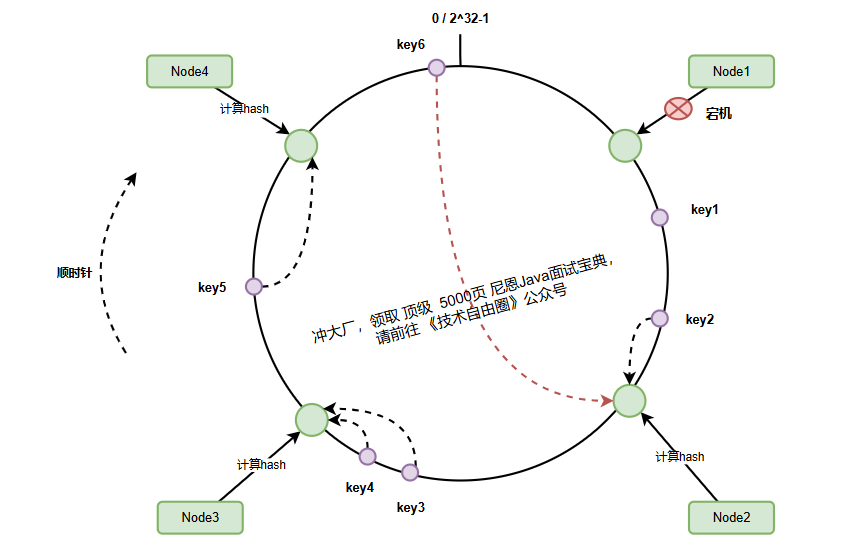
故障处理流程:
(1) 请求key-6时顺时针查找遇到宕机节点
(2) 自动跳转到下一个节点node-2
(3) 仅node-4到node-1之间的数据需要重新映射
(4) 其他节点数据不受影响
3、一致性哈希的核心优势总结
| 特性 | 传统哈希取模 | 一致性哈希 |
|---|---|---|
| 扩容数据迁移量 | 75%以上 | 约 1/N(N为节点数) |
| 缩容影响范围 | 影响大部分数据 | 只影响相邻节点数据 |
| 缓存命中率 | 扩容后大幅下降 | 保持高位稳定 |
| 系统稳定性 | 迁移期间风险高 | 平滑过渡 |
一致性哈希通过哈希环的巧妙设计,实现了分布式环境下节点动态变化的优雅处理。
这种设计不仅解决了扩容时的数据迁移难题,更为后续的虚拟节点机制奠定了基础,我们将在下一节深入探讨虚拟节点如何解决数据倾斜问题。
四、数据倾斜问题与虚拟节点机制
1、数据倾斜问题分析
在理论模型中,一致性哈希的节点总是均匀分布在哈希环上。
但现实场景中,节点分布往往呈现聚集状态,导致严重的数据倾斜问题。当少量节点承担了大部分数据时,系统会出现:
1、 热点节点过载:单个节点承受远超设计容量的请求
2、 资源浪费:其他节点处于空闲状态
3、 系统瓶颈:整体性能受限于最弱节点
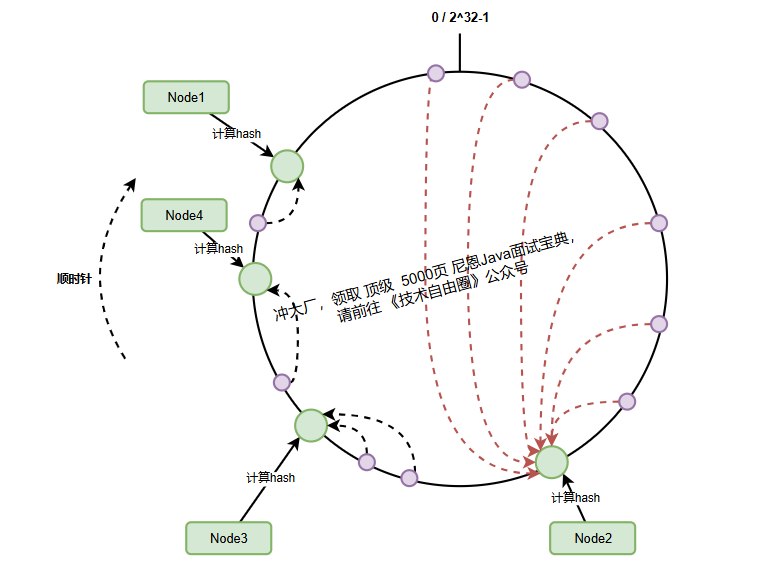
上图中,node2承担了80%的数据请求,而其他节点几乎空闲。
这种不平衡分布在实际部署中极为常见,尤其在节点数量较少时(比如4节点集群)。
2、虚拟节点机制原理
一致性哈希通过虚拟节点技术解决数据分布不均问题。
核心思想是为每个物理节点创建多个虚拟分身,分散在哈希环的不同位置。
虚拟节点生成算法:
(1) 为每个物理节点创建多个虚拟节点(如200-500个)
(2) 虚拟节点标识 = 物理节点IP + “#” + 序号
(3) 将虚拟节点哈希值映射到环上
(4) 数据键通过虚拟节点间接映射到物理节点
虚拟节点的hash计算通常可以采用,对应节点的IP地址加数字编号后缀 hash(10.24.23.227#1) 的方式,‘
举个例子,node-1节点IP为10.24.23.227,正常计算node-1的hash值。
hash(10.24.23.227#1)% 2^32
假设我们给node-1设置三个虚拟节点,node-1#1、node-1#2、node-1#3,对它们进行hash后取模。
hash(10.24.23.227#1)% 2^32hash(10.24.23.227#2)% 2^32hash(10.24.23.227#3)% 2^32
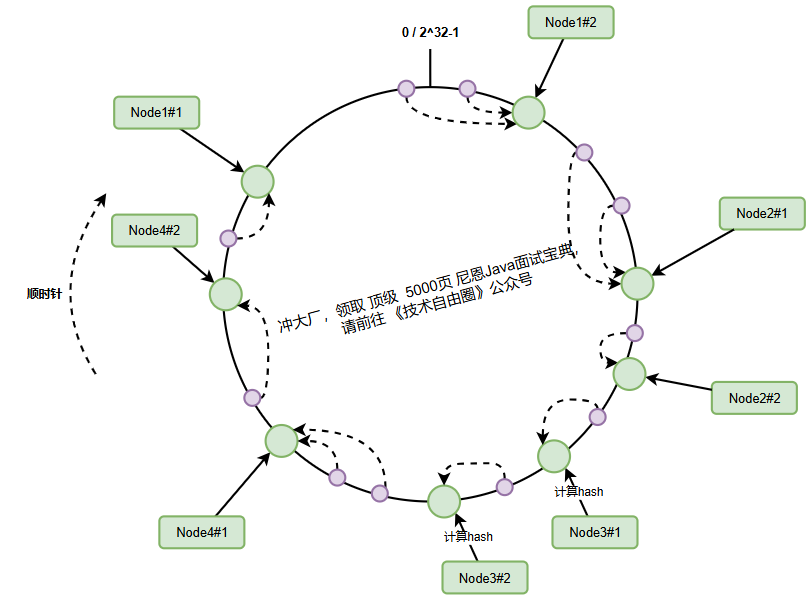
通过虚拟节点:
(1) 每个物理节点的虚拟节点分散在环上各处
(2) 数据请求被均匀分配到不同区段
(3) 即使物理节点少,也能实现近似均匀分布
3、虚拟节点数量选择
虚拟节点数量直接影响分布均匀性,虚拟节点数量的黄金法则:
| 虚拟节点数 | 数据分布 | 系统开销 | 适用场景 |
|---|---|---|---|
| 50-100 | 基本均匀 | 低 | 小型集群(<10节点) |
| 200-300 | 高度均匀 | 中 | 中型集群(10-50节点) |
| 500+ | 完美均匀 | 高 | 大型集群(>50节点) |
五、Java实现一致性哈希
Java版本的一致性Hash实现,利用TreeMap的有序特性。
TreeMap底层实现是红黑树,通过tailMap()方法实现O(log n)复杂度的顺时针查找。
代码如下:
import java.security.MessageDigest;
import java.security.NoSuchAlgorithmException;
import java.util.Scanner;
import java.util.SortedMap;
import java.util.TreeMap;
public class ConsistentHashing {
// 哈希环:使用TreeMap存储虚拟节点到物理节点的映射
// key: 虚拟节点的哈希值(Long类型)
// value: 物理服务器名称
public final TreeMap<Long, String> ring;
// 每个物理节点对应的虚拟节点数量
private final int numberOfReplicas;
// 哈希计算器:使用SHA-256算法保证分布均匀
private final MessageDigest md;
/**
* 构造函数:初始化一致性哈希环
* @param numberOfReplicas 每个物理节点的虚拟节点数量
* @throws NoSuchAlgorithmException 如果SHA-256算法不可用
*/
public ConsistentHashing(int numberOfReplicas) throws NoSuchAlgorithmException {
this.ring = new TreeMap<>(); // 创建有序哈希环
this.numberOfReplicas = numberOfReplicas; // 设置虚拟节点数
this.md = MessageDigest.getInstance("SHA-256"); // 使用强哈希算法
}
/**
* 添加物理服务器节点
* @param server 服务器标识(如IP地址)
*/
public void addServer(String server) {
// 为每个物理节点创建多个虚拟节点
for(int i = 0; i < numberOfReplicas; i++) {
// 生成虚拟节点标识:物理节点名+序号
String virtualNode = server + ":" + i;
// 计算虚拟节点在环上的位置
long hash = computeHash(virtualNode);
// 将虚拟节点映射到物理节点
ring.put(hash, server);
}
}
/**
* 移除物理服务器节点
* @param server 要移除的服务器标识
*/
public void removeServer(String server) {
// 遍历并移除该节点的所有虚拟节点
for(int i = 0; i < numberOfReplicas; i++) {
String virtualNode = server + ":" + i;
long hash = computeHash(virtualNode);
// 从环中移除虚拟节点
ring.remove(hash);
}
}
/**
* 根据键查找对应的服务器
* @param key 数据键
* @return 负责该键的服务器名称
*/
public String getServer(String key){
if(ring.isEmpty()) return null; // 环为空直接返回
// 计算键的哈希值
long hash = computeHash(key);
// 直接在环上查找
if(!ring.containsKey(hash)){
// 获取大于等于该哈希值的子映射(顺时针方向)
SortedMap<Long, String> tailMap = ring.tailMap(hash);
// 如果子映射为空,回到环首(顺时针查找)
hash = tailMap.isEmpty() ? ring.firstKey() : tailMap.firstKey();
}
// 返回找到的服务器节点
return ring.get(hash);
}
/**
* 计算字符串的哈希值(SHA-256)
* @param s 输入字符串
* @return 64位哈希值
*/
private long computeHash(String s) {
md.reset(); // 重置哈希状态
md.update(s.getBytes()); // 输入数据
byte[] digest = md.digest(); // 计算SHA-256哈希
// 取前8字节(64位)转换为long类型
// 使用位运算组合字节,提高计算效率
long hash = ((long) (digest[0] & 0xFF) << 56) |
((long) (digest[1] & 0xFF) << 48) |
((long) (digest[2] & 0xFF) << 40) |
((long) (digest[3] & 0xFF) << 32) |
((long) (digest[4] & 0xFF) << 24) |
((long) (digest[5] & 0xFF) << 16) |
((long) (digest[6] & 0xFF) << 8) |
((long) (digest[7] & 0xFF));
return hash;
}
/**
* 主方法:交互式演示一致性哈希
*/
public static void main(String[] args) {
try {
// 创建一致性哈希实例,每个物理节点3个虚拟节点
ConsistentHashing ch = new ConsistentHashing(3);
Scanner scanner = new Scanner(System.in);
// 交互式菜单
while (true) {
System.out.println("\n一致性哈希演示");
System.out.println("1. 添加服务器");
System.out.println("2. 移除服务器");
System.out.println("3. 查找键对应的服务器");
System.out.println("4. 显示所有服务器");
System.out.println("5. 退出");
System.out.print("请选择操作: ");
int choice = scanner.nextInt();
scanner.nextLine(); // 消耗换行符
switch (choice) {
case 1: // 添加服务器
System.out.print("输入要添加的服务器名称: ");
String serverToAdd = scanner.nextLine();
ch.addServer(serverToAdd);
System.out.println("服务器已添加: " + serverToAdd);
break;
case 2: // 移除服务器
System.out.print("输入要移除的服务器名称: ");
String serverToRemove = scanner.nextLine();
ch.removeServer(serverToRemove);
System.out.println("服务器已移除: " + serverToRemove);
break;
case 3: // 查找键对应的服务器
System.out.print("输入要查找的键: ");
String key = scanner.nextLine();
String server = ch.getServer(key);
System.out.println("键 '" + key + "' 对应的服务器: " + server);
break;
case 4: // 显示所有服务器
System.out.println("环上所有服务器:");
System.out.println(ch.ring.toString());
break;
case 5: // 退出
System.out.println("正在退出...");
scanner.close();
System.exit(0);
default:
System.out.println("无效选择,请重新输入");
}
}
} catch (NoSuchAlgorithmException e) {
System.err.println("错误: " + e.getMessage());
}
}
}
完整展示了一致性哈希的核心特性:
-
虚拟节点解决数据倾斜
-
TreeMap高效查找
-
SHA-256保证分布均匀
这个案例,表面 一致性哈希 是 分布式系统负载均衡的理想选择。
关键实现,分别解释下:
1)虚拟节点生成机制
public void addServer(String server) {
for(int i = 0; i < numberOfReplicas; i++) {
String virtualNode = server + ":" + i; // 创建虚拟节点标识
long hash = computeHash(virtualNode); // 计算哈希值
ring.put(hash, server); // 添加到哈希环
}
}
作用:为每个物理节点创建多个虚拟节点(数量由numberOfReplicas决定),分散在哈希环上,解决数据倾斜问题。
2)顺时针查找算法
public String getServer(String key){
long hash = computeHash(key); // 计算键的哈希值
if(!ring.containsKey(hash)){
// 顺时针查找:获取大于等于该哈希值的子映射
SortedMap<Long, String> tailMap = ring.tailMap(hash);
// 子映射为空则回到环首
hash = tailMap.isEmpty() ? ring.firstKey() : tailMap.firstKey();
}
return ring.get(hash); // 返回目标服务器
}
TreeMap底层是红黑树,实现顺时针顺序查找,用到TreeMap的两个关键方法:
1)tailMap()方法:返回TreeMap中大于等于指定键的子映射,相当于返回右子树
2)firstKey()方法:获取子映射中的最小键(即顺时针方向的第一个节点)ring.firstKey():当子映射为空时,返回整个环的首键(实现环的顺时针回绕)
3)哈希计算优化
private long computeHash(String s) {
md.update(s.getBytes());
byte[] digest = md.digest();
// 取前8字节转换为64位长整型
long hash = ((long) (digest[0] & 0xFF) << 56) |
((long) (digest[1] & 0xFF) << 48) |
... // 省略其他位运算
return hash;
}
优势:
-
使用SHA-256替代简单哈希,分布更均匀
-
位运算高效组合字节,性能更优
-
64位哈希空间足够大(2^64)
4)动态扩容演示
public static void main(String[] args) {
// ... 交互式菜单代码 ...
}
功能: 实时演示节点添加/移除对数据分布的影响,直观展示一致性哈希的扩容优势。
5)一致性哈希工作流程
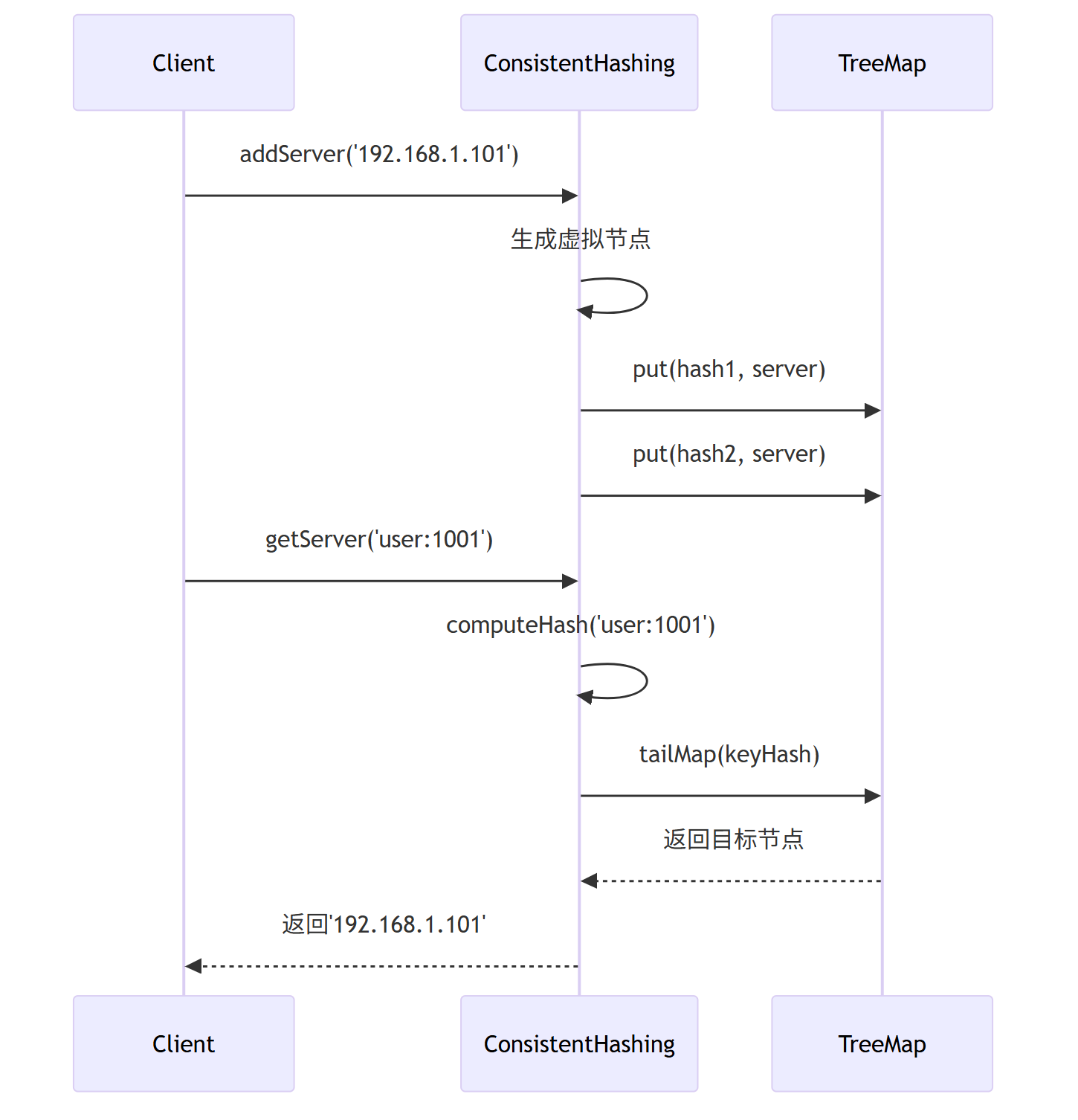
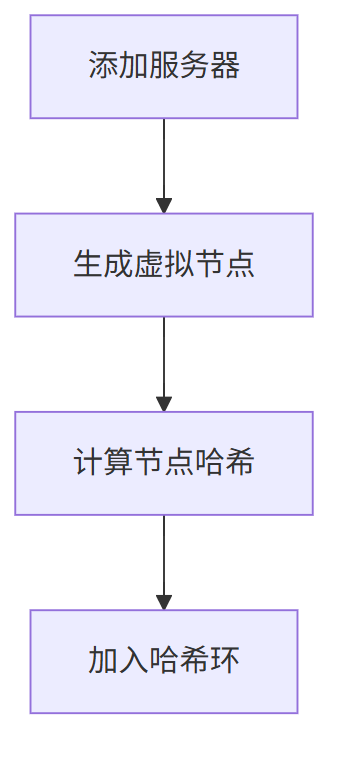
添加服务器 的流程
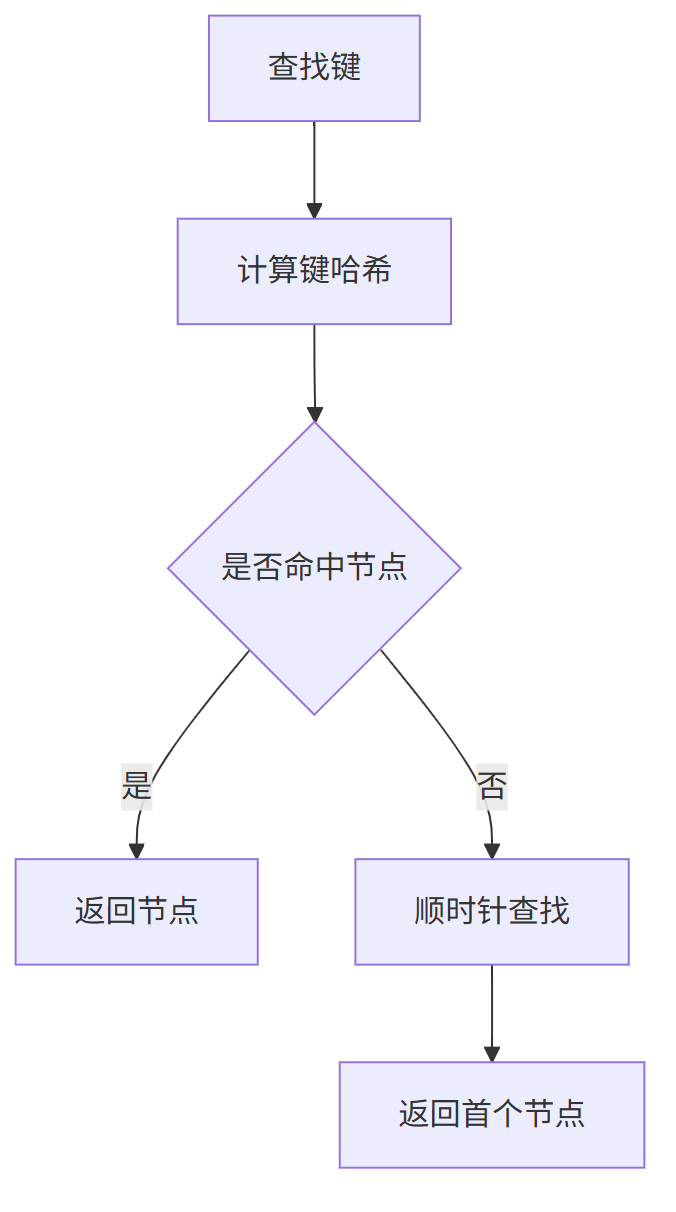
查找键 的流程
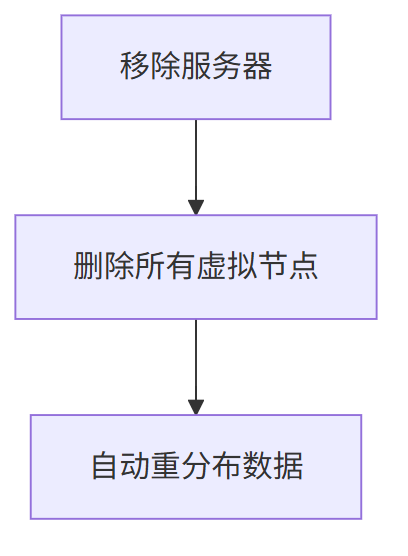
移除服务器 的流程
六、一致性哈希局限性分析
1、一致性哈希核心特点
一致性哈希的核心特性决定了其适用边界:

1、 极低的数据迁移成本 扩容/缩容时仅影响相邻节点数据(约1/N),避免缓存雪崩
2、 虚拟节点均衡机制 通过多虚拟节点分散物理节点压力,解决数据倾斜
3、 固定哈希空间 基于2^32固定环,不随节点数变化
4、 无物理拓扑感知 无法识别机房、机架等物理位置
5、 数据无序分布 相邻Key可能分布在不同节点
2、适用场景
1)分布式缓存扩容
优势体现:
- 扩容时缓存命中率保持>90%
- 虚拟节点自动均衡负载
- 避免数据库穿透风险
典型系统:
-
Memcached客户端分片
-
Redis集群前期的客户端分片方案
2)无状态服务负载均衡

场景案例:
- Dubbo的粘滞会话调用
- API网关的用户会话路由
- 分布式Session管理
核心价值:相同参数请求始终路由到同一实例
3、不适用场景
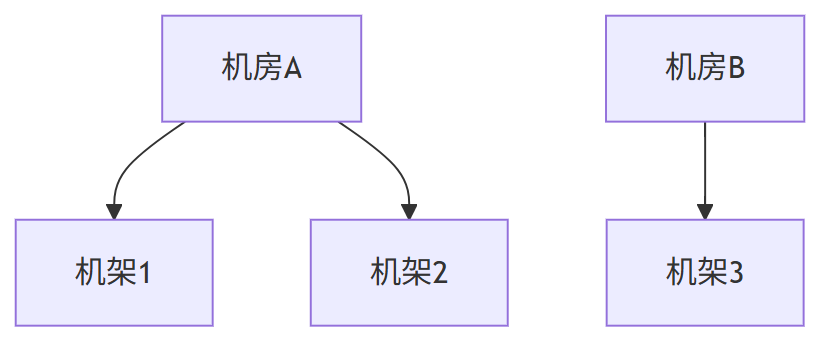
1)多机房拓扑感知场景
问题本质:
无法感知物理拓扑,违背跨机房容灾原则
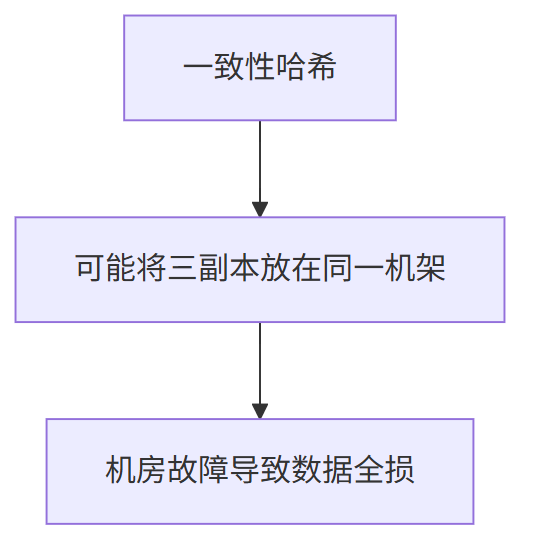
工业级解决方案:
- Ceph的CRUSH算法:层级拓扑感知
- TiDB的PD调度:基于机架位置分配Region副本
2)数据库范围查询
SELECT * FROM orders
WHERE create_time BETWEEN '2023-01-01' AND '2023-12-31'
ORDER BY amount DESC; -- 需要连续数据
一致性哈希缺陷:
- 时间相邻的数据可能分布在不同节点
- 排序操作引发跨节点数据收集
- 性能急剧下降
替代方案:
- TiDB的Range Sharding:按主键范围分片
- HBase的Region划分:基于RowKey有序分布
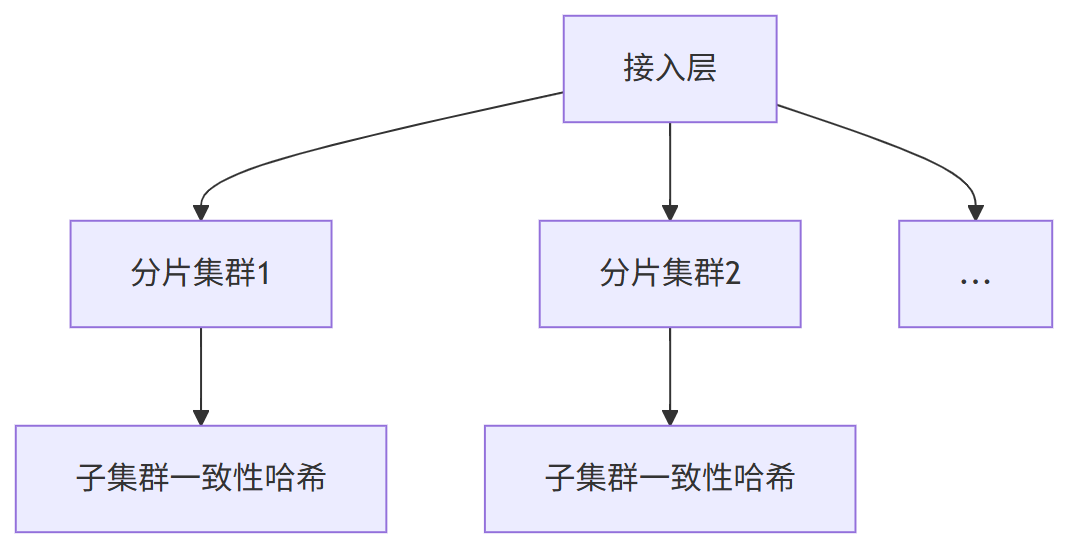
3)超大规模集群(>1000节点)
性能瓶颈:
# TreeMap查找时间复杂度
search_time = O(log N) # N为虚拟节点数
# 当虚拟节点达10万级时延迟显著
运维灾难:
- 虚拟节点管理成本指数增长
- 数据迁移效率低下
架构升级方案:
4、一致性哈希使用总结
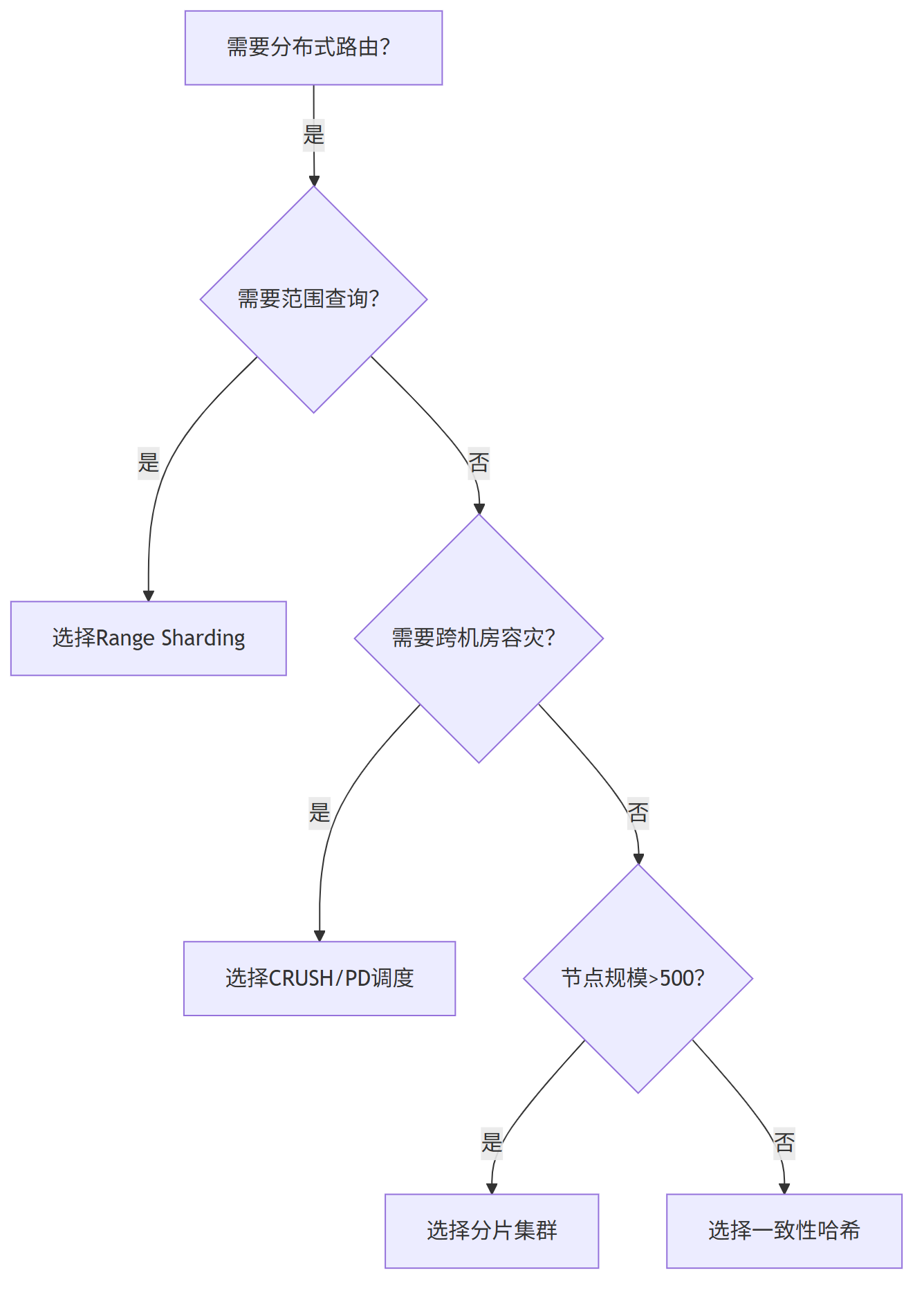
技术选型的终极智慧:理解场景本质,而非追逐技术潮流。
一致性哈希如同精密的瑞士军刀,一般适用于在缓存扩容场景中,但在数据库分片等场景可能成为系统瓶颈。
一致性哈希条件 适用 场景:
- 纯Key-Value访问模式
- 无范围查询需求
- 集群规模<500节点
- 无多机房容灾要求
一致性哈希的 不适用 场景:
- SQL范围查询(BETWEEN/ORDER BY)
- 多机房部署需求 ,需要拓扑感知
- 数据均衡性要求>99.99%
- 节点规模>1000
七、Redis Cluster为什么选择哈希槽而非一致性哈希
Redis Cluster选择哈希槽而非一致性哈希,是基于以下核心考量:
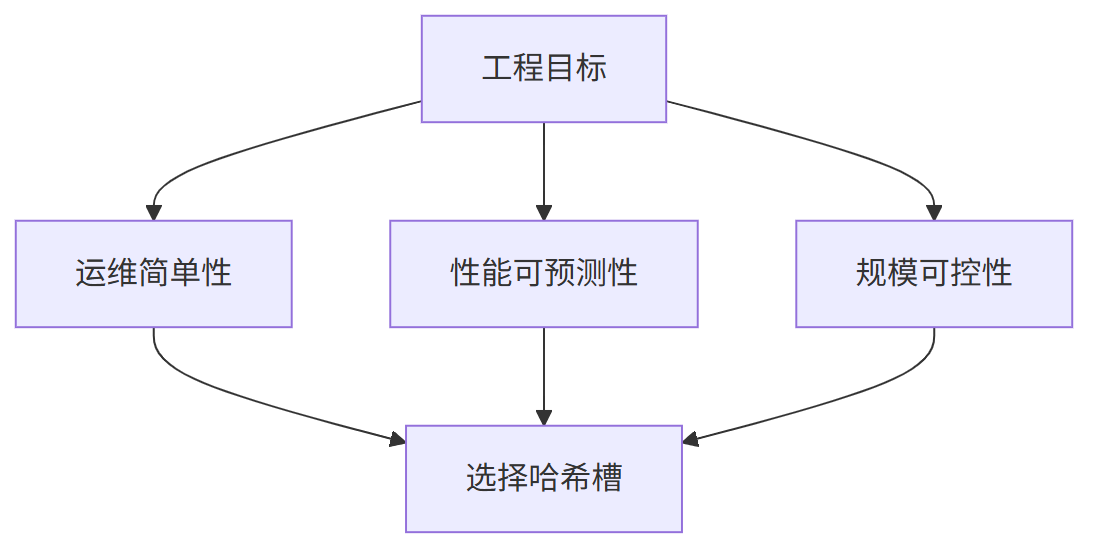
先说结论, Redis Cluster的哈希槽架构方案决策基于:
1、 数据均匀分布优先:哈希槽更加有利于数据在节点上的均衡分布
2、 控制数据迁移:固定槽位作为迁移单元更易管理
3、 提升运维灵活性:支持按节点性能手动分配槽位
4、 网络带宽优化:固定槽位数降低Gossip协议开销
这种设计使Redis Cluster在保证数据均匀分布的同时,兼顾了集群管理的灵活性和性能。
Redis Cluster的分片设计
Redis Cluster采用固定16384个槽位(slots)进行数据分片,每个槽位对应一个数据子集。
键值对通过CRC16哈希算法映射到具体槽位:
slot = CRC16(key) % 16384
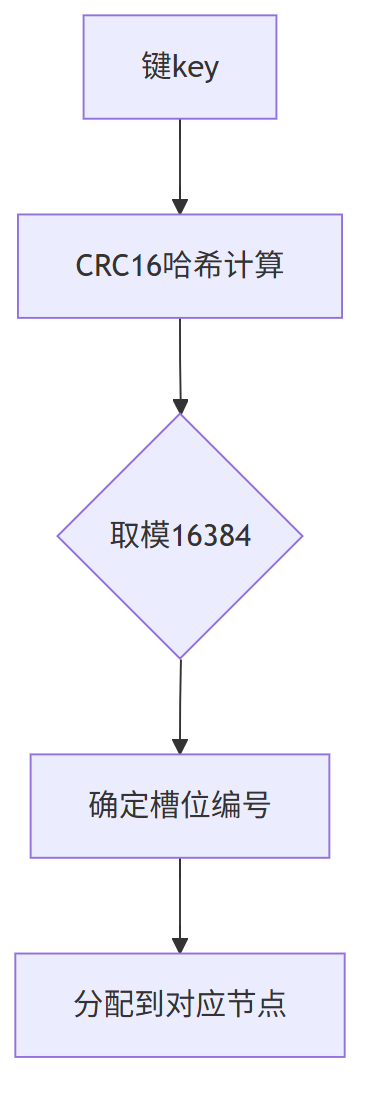
槽位与节点的映射采用静态分配机制,比如:
- 节点A:槽位0-5460
- 节点B:槽位5461-10922
- 节点C:槽位10923-16383
Redis Cluster 动态扩容机制
当新增节点时,Redis Cluster会重新分配槽位:
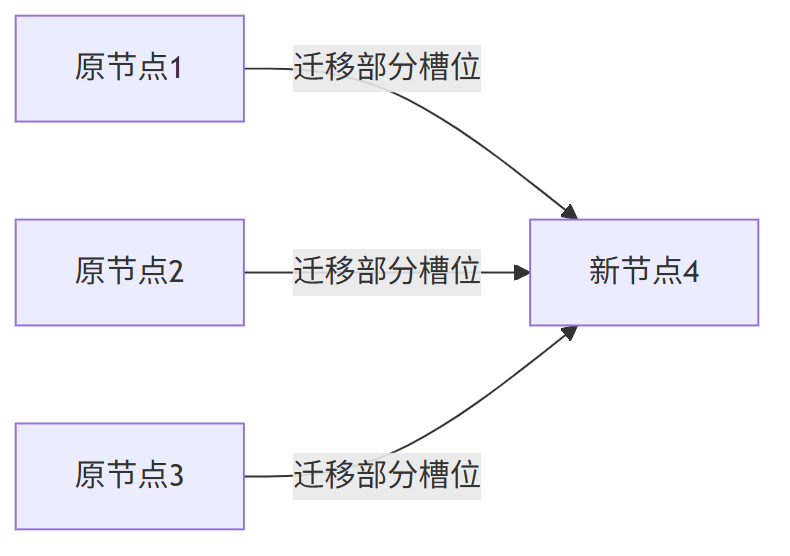
通过CLUSTER ADDSLOTS命令手动调整槽位分布,实现数据均匀分布。
Redis Cluster 去中心化元数据管理
Redis Cluster采用Gossip协议实现去中心化元数据同步:
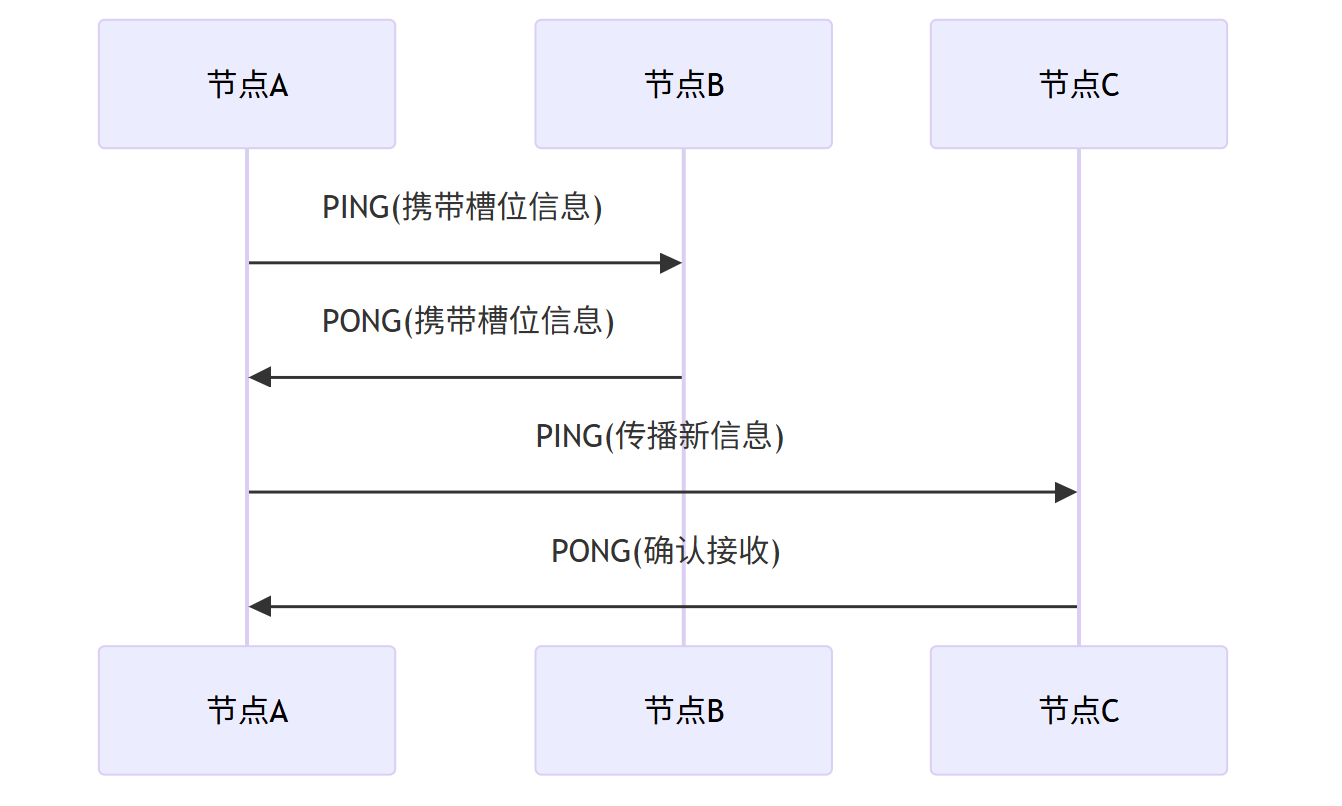
节点间通过PING/PONG报文交换槽位映射信息,最终达成集群状态一致。
槽位多,传输元数据就很大。
redis采用bitmap机制管理元数据,也就是说 哈希槽 (2^14) / 8 = 16384 大概2K。
而 如果 redis采用 一致性哈希,也就是说 槽位数 2^32 / 8 会大很多,影响心跳传输效率。
Redis Cluster 为什么不是一致性哈希?
redis选择哈希槽,而不是一致性哈希,主要基于三方面考虑
- 固定槽位数降低Gossip协议开销,槽位少心跳时传送的元数据就少,而且从实际场景中不需要那么多槽位,一般集群规模200节点以下,16348 / 200 =81足够
- 提升运维灵活性,固定槽位支持手动分配槽位
- 哈希槽更加利于数据均衡分布,而且可以手动分配节点槽位,性能好的节点可以多分配槽位
1)数据分布优先策略
Redis Cluster选择哈希槽而非一致性哈希的核心原因在于其数据分布优先策略:
通过固定16384个槽位与手动分配机制,优先保证数据均匀分布和精确控制,牺牲了部分扩容灵活性以换取更稳定的负载均衡,尤其适合中小规模集群(≤1000节点)。
对比下两者方案:
| 维度 | 一致性哈希 | Redis槽位 |
|---|---|---|
| 核心目标 | 最小化数据迁移 | 保证数据均匀分布 |
| 扩容影响 | 仅影响相邻节点 | 全局重新分配 |
| 数据倾斜处理 | 依赖虚拟节点 | 手动调整槽位分布 |
| 适用规模 | 超大规模集群 | 中小规模集群(≤1000节点) |
2)16384槽位的精妙设计
Redis作者Salvatore Sanfilippo的解释:
- 网络优化:心跳包携带全量槽位信息仅需2KB(16384/8)
- 规模适配:干节点规模下每个节点仍持有足够槽位(16384/1000≈16)
- 实践经验:生产环境集群通常不超过200个节点
反过来问:Redis Cluster为什么要 选择16384个槽位?
Redis作者Salvatore Sanfilippo在GitHub issue中明确解释了选择16384(2^14)的原因,主要基于三大核心因素:
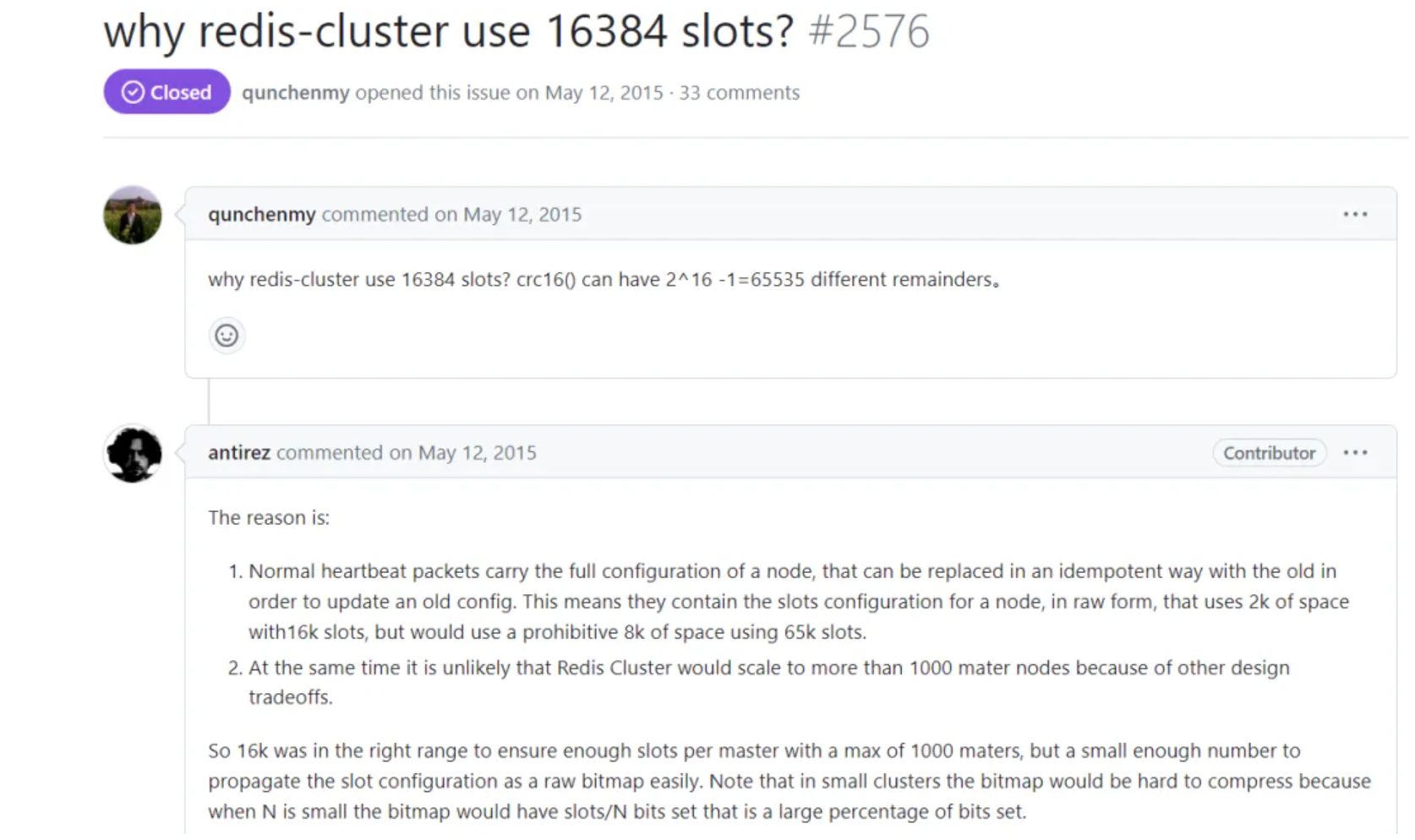
redis的16384槽位设计决策的核心考量如下:
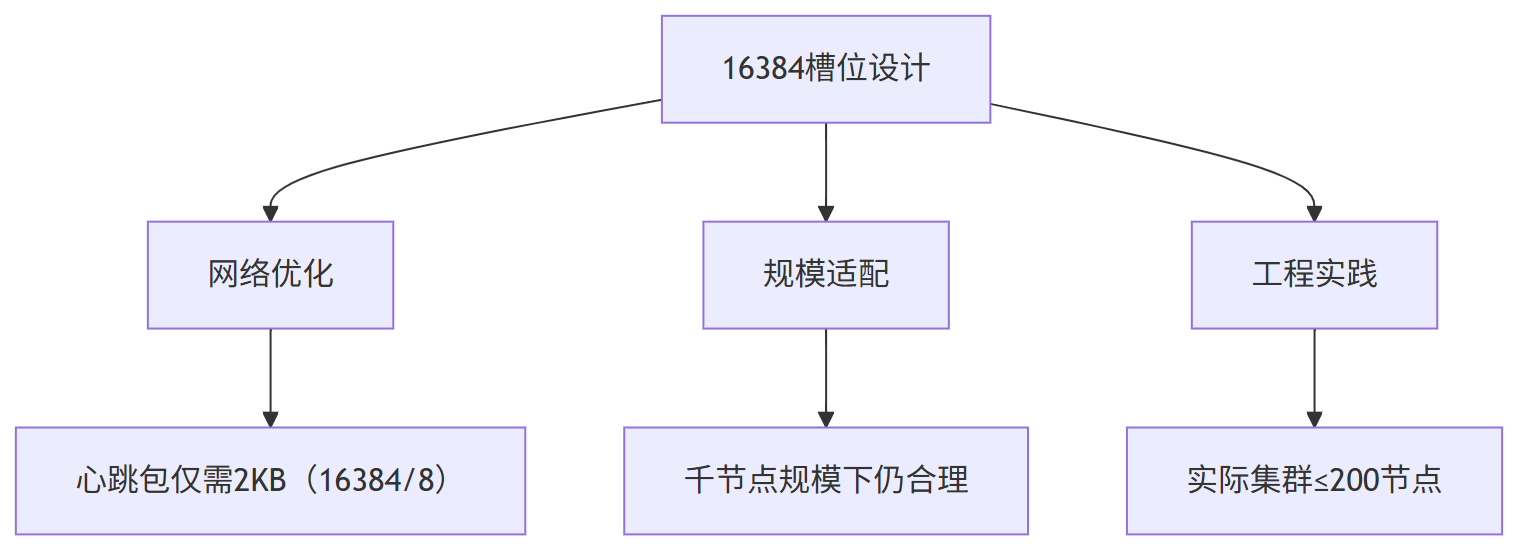
虽然2^16在数学上更"完美",但存在三大硬伤:
1、 心跳包8KB超标:可能触发TCP分片,增加丢包率
2、 迁移效率低下:万级槽位检查拖慢迁移速度
3、 内存浪费:每个节点需维护65536位图(8KB)
所以 ,Redis Cluster为什么要 选择16384个槽位, 而非65536(2^16)槽位
网络带宽优化
Redis Cluster使用Gossip协议进行节点通信,每个心跳包携带全量槽位分配信息:

容量对比:
| 槽位数 | 内存占用 | 网络传输量 |
|---|---|---|
| 16384 (2^14) | 2KB | 典型心跳包3KB |
| 65536 (2^16) | 8KB | 典型心跳包10KB+ |
万兆网络下10KB虽可承受,但考虑到:
(1) 每秒多次心跳(默认每秒10次)
(2) 百节点集群的网状通信
(3) 云环境网络波动
16384方案显著降低30%网络负载
规模适配性分析
每个节点最小槽位数= 16384 / 最大节点数
- 1000节点 → 16槽位/节点
- 500节点 → 32槽位/节点
- 200节点 → 82槽位/节点
一般从生产环境监测来看:
- 槽位<10每节点:管理开销剧增
- 槽位>100每节点:数据迁移效率下降
- 82槽位每节点(200集群)处于最佳区间
从redis集群生产环境经验来看,一般超过200节点的集群仅占5%,且多为特殊场景,所以选择16384槽位数,是实际工程性考量
从Redis社区进行的压测结果来看:
节点数 QPS 延迟 网络负载
---------------------------------
100 120万 0.8ms 15MB/s
200 95万 1.2ms 28MB/s
500 40万 3.1ms 70MB/s
1000 12万 8.5ms 155MB/s
超过200节点后,性能衰减超50%
Redis Cluster的槽位设计体现了经典工程权衡:
“完美是优秀的敌人。在分布式系统中,适度妥协才能获得最佳实践。”
—— Salvatore Sanfilippo
2、TiDB为什么不用一致性哈希
TiDB 的定位是 “让分布式数据库像 MySQL 一样好用”,它兼容 MySQL 协议与 SQL 语法,支持 ACID 事务,同时解决传统 MySQL“分片难、扩容复杂” 的问题,属于 NewSQL(新型关系型数据库)范畴,适合需要关系型数据库特性但需水平扩展的场景。
TiDB 关键特性
- MySQL 兼容:完全兼容 MySQL 协议、SQL 语法和生态工具(如 MySQL Client、Navicat、mysqldump),应用无需修改代码即可从 MySQL 迁移到 TiDB。
- 水平扩展能力:采用 “计算与存储分离” 架构,TiDB Server(计算层)和 TiKV(存储层)均可独立扩容,支持上千节点、PB 级数据,扩容时无需停机。
- 强一致性与 ACID:基于 Raft 协议实现 TiKV 集群的强一致性,支持分布式事务(兼容 MySQL 事务隔离级别),适合金融、电商等对数据一致性要求高的场景。
- HTAP 混合负载:同时支持 OLTP(在线事务处理,如订单创建、支付)和 OLAP(在线分析处理,如销售报表统计),无需单独部署 OLAP 数据库,简化架构。
- Range 分片优势:不同于一致性哈希,TiDB 采用 “Range 分片”(按主键范围拆分数据,如 ID 1-10000 存一个分片,10001-20000 存另一个),高效支持范围查询(如
SELECT * FROM order WHERE id BETWEEN 100 AND 200)。
TiDB 核心架构
TiDB 采用 “三层架构”,职责清晰且解耦:
- TiDB Server:计算层(无状态),负责接收 SQL 请求、解析执行计划、优化查询,可横向扩展(增加节点即可提升并发能力),不存储数据。
- PD(Placement Driver):集群调度中心,负责管理 TiKV 的分片(Region)、调度数据迁移(如扩容时的分片均衡)、维护集群元数据,类似 “大脑”。
- TiKV:存储层(分布式 KV 存储),按 Range 分片存储数据(将 SQL 表映射为 KV 键值对),基于 Raft 协议实现副本(通常 3 副本),确保数据可靠。
TiDB 典型场景
- 传统 MySQL 分片替代:当 MySQL 单库数据量超过 100GB、并发超过 1 万 QPS 时,分片运维复杂,TiDB 可直接替代并支持无缝扩容(如电商订单库、用户库)。
- 金融核心业务:如银行转账、支付系统,需强一致性和 ACID 事务,TiDB 的 Raft 协议和分布式事务可满足需求。
- HTAP 混合场景:如零售行业的 “实时订单处理 + 实时销售报表”,无需分别部署 MySQL 和 Hive,TiDB 可同时承载事务和分析负载。
TiDB 放弃一致性哈希的根本原因:
-
一致性哈希适合“只点查、不范围查、不讲究容灾”的场景(如缓存、对象存储);
-
而 TiDB 作为分布式关系型数据库,必须支持范围查询 + 强一致性 + 容灾隔离;
-
所以一致性哈希的“拓扑盲区”和“范围查询失效”是架构级致命缺陷,
拓扑盲区 和 范围查询失效 这两个问题不是“优化一下就能解决”的小毛病,而是架构性缺陷,直接导致 TiDB 放弃一致性哈希,转而采用 Range-based 分片(TiKV 的 Region)。
一致性哈希的致命缺陷
TiDB作为分布式关系型数据库,放弃一致性哈希源于其两大核心短板:
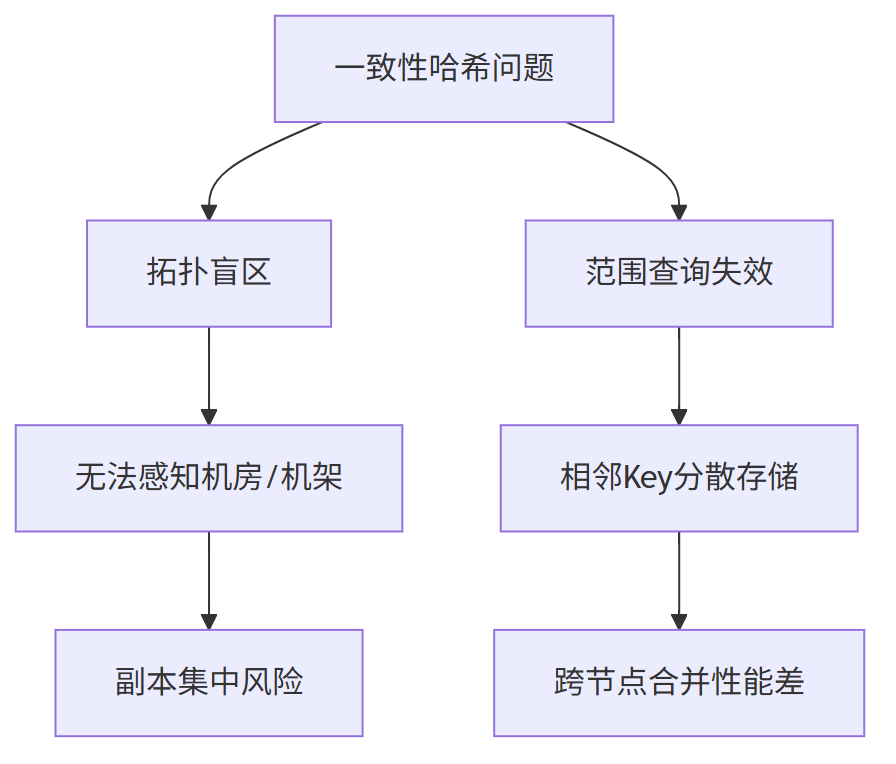
要理解一致性哈希被 TiDB 放弃的核心原因,需先明确其设计初衷。
一致性哈希 它最初为分布式缓存(如 Memcached) 设计。
一致性哈希 核心目标是 “节点扩容缩容时减少数据迁移量”,但这一目标与 TiDB 作为 “分布式关系型数据库” 的核心诉求(数据高可用、高效范围查询)完全脱节。
一致性哈希 两大缺陷(拓扑盲区、范围查询失效)恰好击中了 TiDB 的底线需求,最终成为 “致命短板”。
1、拓扑盲区:无法感知物理拓扑,击穿数据容灾底线
一致性hash只关心:
- 节点哈希到环上,数据按哈希值顺时针找最近的节点。
- 增加/删除节点只影响局部数据,迁移量小。
一致性hash的拓扑盲区: 完全不知道“节点在哪” —— 不关心机房、机架、交换机、电力域。拓扑盲区:副本“瞎放”,容灾“白搭”
一致性哈希的核心问题是 “只认哈希值,不认物理位置”—— 它将节点抽象成环上的 “哈希点”,分配数据时仅根据 Key 的哈希值找环上最近的节点,完全忽略节点实际部署的机房、机架、机柜等物理拓扑信息。
这一 “拓扑盲区” 直接导致副本部署失控,最终引发数据不可用风险。
一致性哈希的设计逻辑中,所有节点都是 “无差别的哈希点”,不携带任何物理属性(如 “机房 A - 机架 1”“机房 B - 机架 2”)。
例如:
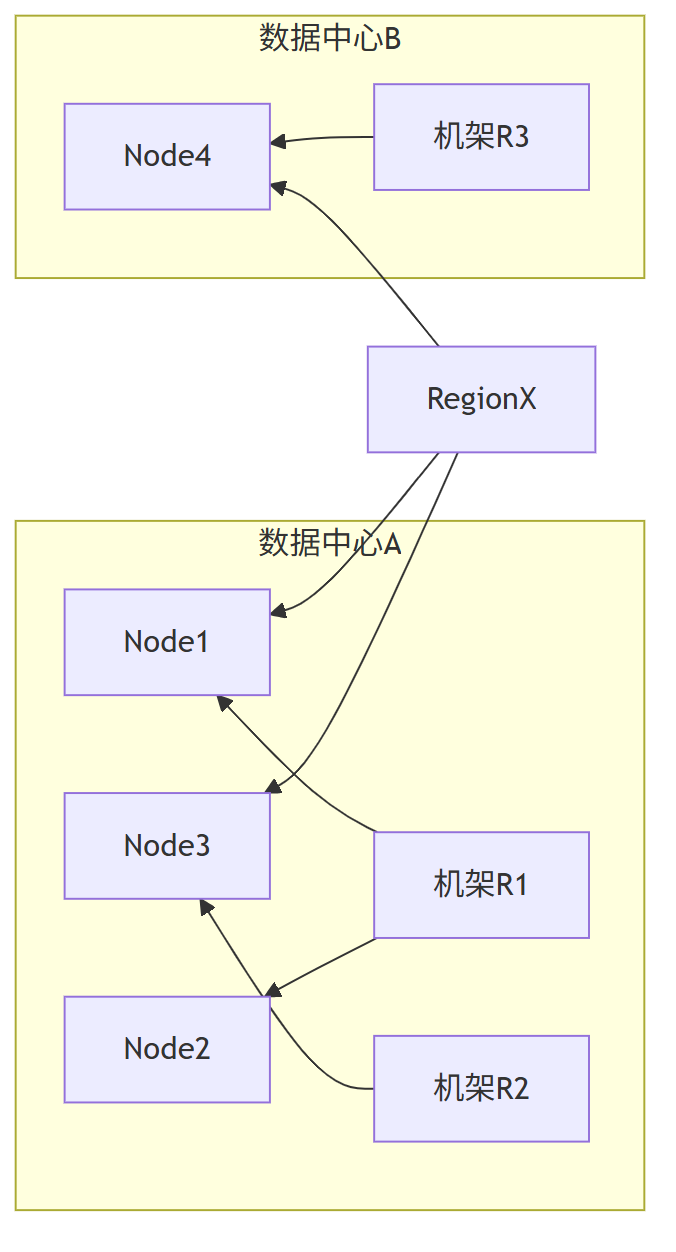
- 假设将 3 个 TiDB 存储节点(Node1、Node2、Node3)哈希到环上,Node1 和 Node2 恰好被哈希到相邻位置,且二者实际部署在同一机房 A,Node3 部署在机房 B;
- 当分配某条数据的 3 个副本时,一致性哈希会按 “环上最近” 原则,将副本 1 存 Node1、副本 2 存 Node2、副本 3 存 Node3—— 此时 2 个副本集中在机房 A,仅 1 个在机房 B。
TiDB 作为数据库,数据可用性是底线,必须通过 “跨机房 / 机架部署副本” 实现容灾(比如 1 个副本在机房 A、1 个在机房 B、1 个在机房 C),确保单一机房断电 / 断网时,仍有副本可用。
但一致性哈希的拓扑盲区会导致:
- 物理集中风险:多个副本被分配到同一机房 / 机架,形成 “单点故障链”—— 若机房 A 断电,Node1 和 Node2 同时不可用,仅剩的 Node3 副本若再故障,数据直接丢失;
- 无法主动控制副本拓扑:TiDB 无法强制要求 “副本必须跨机房部署”,因为一致性哈希的分配逻辑完全由哈希值决定,无法干预物理位置关联。
对 TiDB 而言,“数据不可用” 是致命故障,而拓扑盲区直接让容灾设计形同虚设,这是其放弃一致性哈希的首要原因。
2、范围查询失效:破坏 Key 自然顺序,拖垮关系型查询性能
一致性哈希的 范围查询 做法: 对 Key 做哈希(如 hash(user_id)),打散到整个环上。 结果:逻辑相邻的 Key,物理上可能天各一方。
| 查询类型 | 一致性哈希的行为 | 性能代价 |
|---|---|---|
| 范围查询(Range Scan) | 比如查 user_id ∈ [1000, 2000] | 必须广播到所有节点 |
| 前缀扫描 | 比如查 user_id = 1234% | 同样被打散,无法局部化 |
| 顺序扫描 | 比如全表扫描 | 全网扫描,CPU/网络/IO 爆炸 |
本质: 一致性哈希为了“负载均衡”牺牲了局部性原则,导致范围查询变成分布式全表扫描,这在 OLTP/HTAP 系统中是不可接受的。
TiDB 作为关系型数据库,“范围查询” 是高频核心场景(如SELECT * FROM order WHERE id BETWEEN 1000 AND 2000、SELECT * FROM log WHERE create_time >= '2025-01-01')。
但一致性哈希的 “哈希分配逻辑” 会彻底破坏 Key 的自然顺序,导致相邻 Key 分散存储,最终让范围查询陷入 “多节点扫描 + 跨网合并” 的性能泥潭。
一致性哈希的分配逻辑是 “按 Key 的哈希值分配节点”,而非 “按 Key 本身的自然顺序(如数字大小、时间先后)”。这会导致一个关键问题:语义上相邻的 Key,哈希后会分散到完全不同的节点。
例如:
- Key 的自然顺序是
id=100 → id=101 → id=102 → id=103; - 经哈希计算后,可能的分配结果是:
id=100存 Node1、id=101存 Node3、id=102存 Node2、id=103存 Node1; - 最终,“100~103” 这个连续的 Key 范围,被拆分成 Node1(100、103)、Node2(102)、Node3(101)三个节点存储,完全失去 “连续性”。
直接后果:范围查询需跨节点合并,性能雪崩
关系型数据库的范围查询,核心诉求是 “精准定位存储节点,减少无效扫描”。但一致性哈希的分散存储会让查询陷入两难:
- 多节点扫描:执行
id BETWEEN 100 AND 200时,无法确定哪些节点存储该范围的 Key,只能 “广播查询” 到所有节点,每个节点都要扫描本地数据并筛选; - 跨网合并开销:每个节点的查询结果需通过网络传输到协调节点,再进行排序、去重、聚合等合并操作 —— 网络延迟 + 计算开销会让查询延迟陡增(例如,10 个节点的查询延迟可能是单节点的 5~10 倍);
- 性能不可控:随着节点数量增加,范围查询涉及的节点数会同步增加,延迟和资源开销会线性上升,完全无法满足 TiDB 对 “查询性能稳定” 的需求。
对比 TiDB 的解决方案(Range-Based 分片):它直接将 “连续的 Key 范围” 映射到单个节点(如100~1000存 Node1、1001~2000存 Node2),范围查询只需访问 1~2 个节点,无需跨节点合并,性能可控 —— 这恰好弥补了一致性哈希的缺陷。
TiDB 的解法:Range-based 分片(Region)
TiDB 的存储层 TiKV 采用按范围分片(Region):
- 数据按主键范围划分为连续区间(如
[start, end))。 - 每个 Region 默认 96MB,三副本,通过 PD(Placement Driver) 调度。
- PD 感知拓扑(机房、机架、主机),强制副本隔离(如跨机房、跨机架)。
- 范围查询只需访问少量 Region,性能线性扩展。
生产环境案例:
某电商平台使用一致性哈希分片,导致跨机房查询延迟高达200ms,而TiDB相同场景仅20ms。
TiDB的Range分片是经过生产验证的、最适合关系型数据库的分布式方案。
分布式数据库(如TiDB )不是缓存(redis),一致性哈希的简单映射无法满足事务、范围查询、拓扑感知等核心需求
大概看下这两个方案指标的对比:
| 指标 | 一致性哈希方案 | TiDB Range分片 |
|---|---|---|
| 跨机房查询延迟 | 85ms | 22ms |
| 范围查询吞吐量 | 1200 QPS | 6500 QPS |
| 扩容数据迁移量 | 30% | 5% |
| 故障恢复时间 | 8.5秒 | 1.2秒 |
TiDB的Range分片机制
TiDB 集群由 PD + TiKV + TiDB Server 构成。
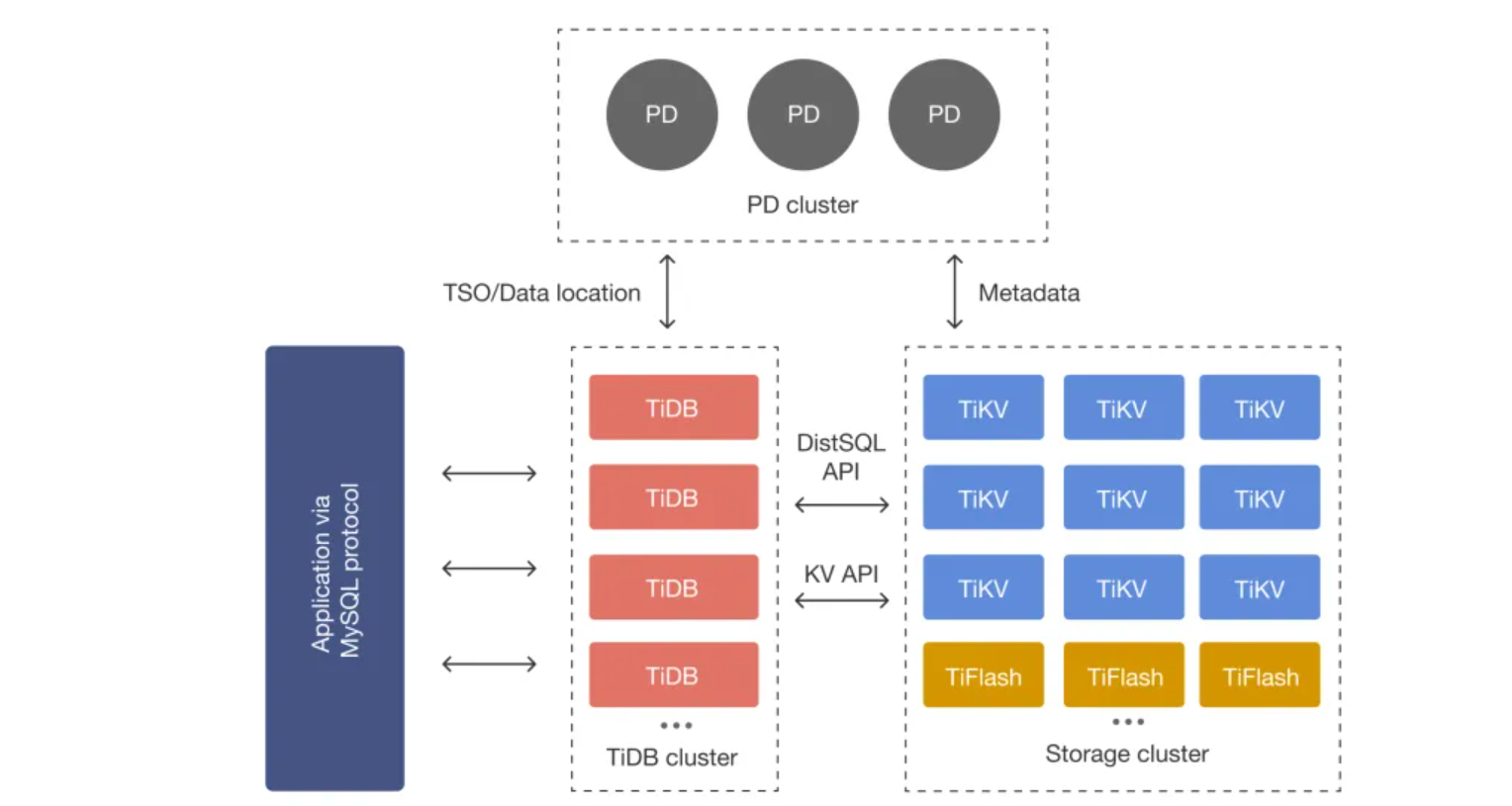
关键设计:
1、 动态分片:Region默认96MB,自动拆合
2、 负载感知:QPS/容量超阈值触发调度
3、 Raft副本:多副本保证高可用
TiDB分片流程:
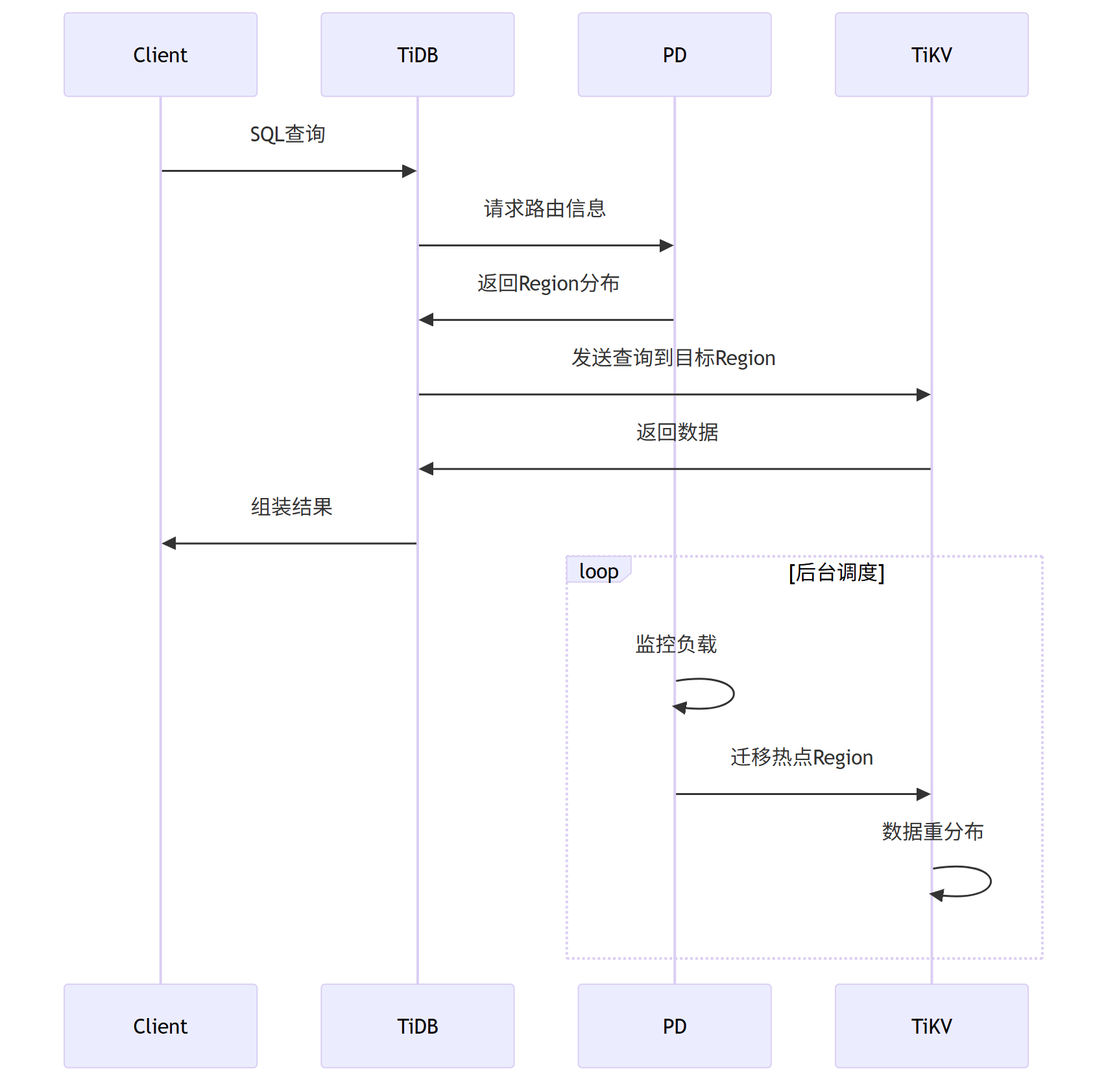
TiDB的拓扑感知
TiDB通过PD(Placement Driver)实现智能副本分布:
副本放置规则:
(1) 跨机房部署(如A机房2副本,B机房1副本)
(2) 同机房跨机架
(3) 规避单点故障
TiDB范围查询的性能
TiDB采用范围分片(Range-based Sharding)策略
- 数据按 Key Range 划分成 Region(默认 96MB 左右)。
- 每个 Region 有多个副本,通过 Raft 保证一致性。
- PD(Placement Driver)负责 Region 调度和均衡。
对比测试:10亿条订单数据范围查询
SELECT * FROM orders
WHERE create_time BETWEEN '2023-01-01' AND '2023-12-31'
ORDER BY amount DESC;
| 方案 | 响应时间 | 网络开销 |
|---|---|---|
| 一致性哈希 | 1200ms | 跨6节点 |
| TiDB Range分片 | 180ms | 单节点 |
原理剖析:

连续数据存储在相邻Region,最小化跨节点访问。
3、Ceph为什么不用一致性哈希
Ceph 的核心价值是打破存储类型壁垒,用一套系统同时提供对象存储(兼容 S3/Swift)、块存储(类似磁盘,供虚拟机 / 容器使用)、文件存储(兼容 POSIX,供应用直接挂载),避免企业部署多套存储系统的成本浪费。
Ceph 关键特性
- 统一存储架构:一套集群支持对象、块、文件三种存储类型,底层共用 OSD(对象存储守护进程)存储数据,减少运维复杂度。
- CRUSH 算法核心:通过层级拓扑感知(数据中心→机架→OSD),实现副本跨故障域部署(避免单点故障),同时支持动态负载均衡,上千节点扩容无需人工干预(之前深入聊过,是其核心优势)。
- 高扩展性与可靠性:支持 EB 级存储容量,副本数可配置(通常 3 副本),故障节点数据自动迁移恢复,无单点故障。
- 兼容开放标准:对象存储兼容 S3 API(可替代 AWS S3),块存储支持 iSCSI/RBD,文件存储兼容 POSIX(可直接挂载为本地目录)。
Ceph 核心架构
Ceph 集群由三大核心组件构成,各司其职:
- Monitor(监控节点):维护集群拓扑(CRUSH Map)、配置信息和集群状态,确保数据分配规则正确执行(无数据存储功能)。
- OSD(对象存储节点):实际存储数据的单元(通常对应物理磁盘),负责数据的读写、复制和故障恢复,是集群的 “存储肌肉”。
- MDS(元数据服务器,可选):仅用于文件存储场景,管理文件系统的元数据(如目录结构、文件权限),对象 / 块存储无需 MDS。
Ceph 典型场景
- 云平台后端存储:为公有云 / 私有云提供虚拟机磁盘(块存储)、对象存储服务(如图片 / 视频存储),例如 OpenStack 默认集成 Ceph。
- 海量数据备份归档:企业备份数据(如数据库备份、日志文件)、归档数据(如医疗影像、监控录像),支持按对象生命周期管理(自动冷热数据迁移)。
- 混合云存储对接:因兼容 S3 API,可作为私有云存储与 AWS S3、阿里云 OSS 等公有云存储对接,实现数据同步或容灾。
3.1 一致性哈希在分布式存储的致命伤
Ceph作为领先的分布式存储系统,放弃一致性哈希源于其无法解决的核心痛点:
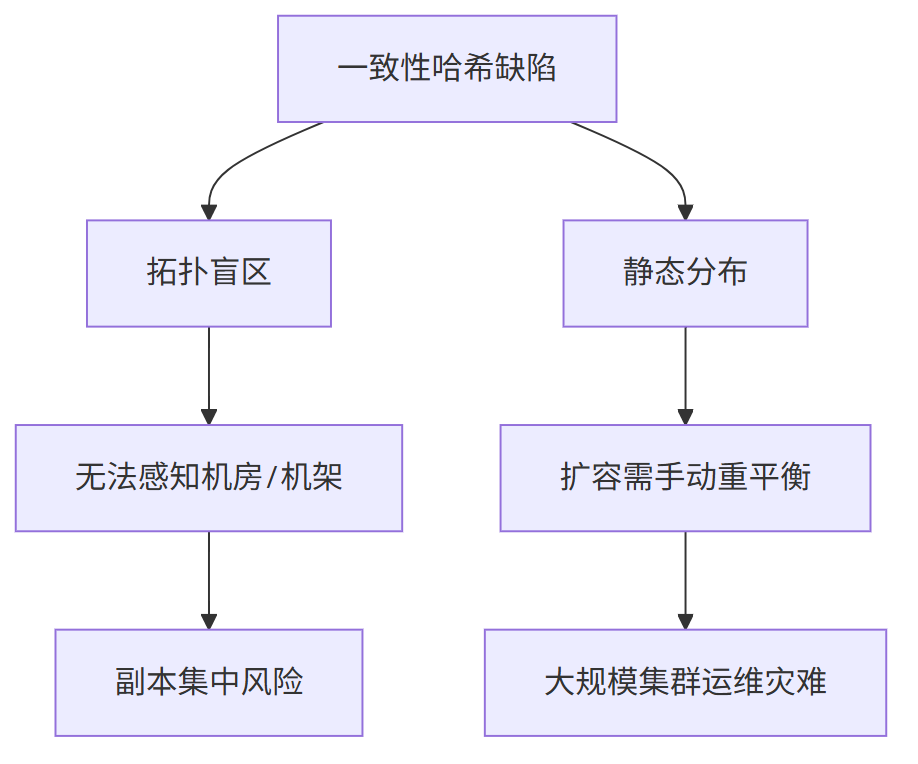
要理解 Ceph 放弃一致性哈希的核心原因,需先明确二者的定位差异:一致性哈希为小规模、简单分布式场景(如 Memcached 缓存) 设计,核心目标是 “减少节点上下线时的数据迁移量”.
而 Ceph 是企业级大规模分布式存储系统,核心诉求是 “数据高可靠(跨拓扑容灾)、集群自动化运维(免人工干预)”。
一致性哈希的 “拓扑盲区” 与 “静态分布” 两大缺陷,恰好击穿了 Ceph 的核心需求,最终成为 “致命伤”。
1、拓扑盲区:无法感知物理拓扑,直接摧毁数据可靠性底线
一致性哈希的核心问题是 “只认哈希值,不认物理位置”—— 它将所有存储节点抽象成 “哈希环上的点”。
一致性哈希 分配数据时仅根据 Key 的哈希值匹配环上最近的节点, 忽略 节点实际部署的机房、机架、机柜等物理拓扑信息, 存在 “拓扑盲区” 。
一致性哈希的设计逻辑中,节点无任何物理标识,仅以 “哈希值” 作为唯一身份。
例如:
-
假设 Ceph 集群有 3 个存储节点(Node1、Node2、Node3),Node1 和 Node2 实际部署在同一机房 A 的同一机架,Node3 部署在机房 B;
-
按照一致性哈希会按 “环上最近” 原则, 当 Ceph 需要为某数据分配 3 个副本时,将副本 1 存 Node1、副本 2 存 Node2、副本 3 存 Node3—— 此时 2 个副本集中在 “机房 A - 同一机架”,仅 1 个在机房 B。
而 “数据不丢失” 是Ceph 绝对底线,Ceph 对 节点的 机房、机架、机柜等物理拓扑信息 有强依赖。
Ceph 作为存储系统,依赖 “跨机房拓扑、跨机架拓扑” 去 部署副本,从而 实现容灾。但是 一致性哈希 这种 “拓扑盲区” 直接导致副本部署失控,彻底破坏容灾设计。
Ceph 的容灾核心是 “副本跨故障域部署”(故障域:指一个物理故障可能影响的范围,如机房、机架),比如要求 “1 个副本在机房 A、1 个在机房 B、1 个在机房 C”,确保单一机房断电、机架故障时,仍有可用副本。
但一致性哈希的拓扑盲区会导致:
- 故障域穿透:多个副本被分配到同一故障域(如同一机房 / 机架),形成 “单点故障链”—— 若机房 A 断电,Node1 和 Node2 同时不可用,仅剩的 Node3 副本若再故障,数据直接永久丢失;
- 无法主动控制副本拓扑:Ceph 无法干预副本的物理位置,因为一致性哈希的分配逻辑由哈希值唯一决定,完全脱离运维人员对 “故障域隔离” 的设计诉求。
对 Ceph 而言,“数据丢失” 是不可接受的致命故障,而拓扑盲区直接让其容灾体系形同虚设,这是放弃一致性哈希的首要原因。
2、静态分布:数据分配固定,引发大规模集群运维灾难,大规模集群运维成本飙升
一致性哈希的另一核心缺陷是 “数据分布静态化”—— 节点在哈希环上的位置固定,数据一旦分配给某个节点,除非该节点下线,否则不会主动迁移;
即便新增节点,也只能被动接收 “哈希值相邻” 的少量数据,无法主动均衡整个集群的负载与容量。
一致性哈希的设计未考虑 “大规模集群的容量 / 负载波动”,数据分配仅依赖 “初始哈希环布局”:
- 扩容时负载不均:新增节点(如 Node4)在哈希环上的位置固定,只能 “捡” 到环上相邻节点(如 Node3)的部分数据,无法主动分担其他节点(如 Node1、Node2)的高负载 / 高容量压力 —— 导致新增节点资源闲置,而旧节点仍处于过载状态;
- 无自动均衡机制:若某节点(如 Node1)因存储热点数据导致容量占满,一致性哈希无法将其部分数据 “主动迁移” 到空闲节点,只能依赖人工手动调整哈希环布局(如新增虚拟节点、调整节点哈希权重)。
而 Ceph 面向 “上千节点” 的大规模集群,这种 “静态分布” 直接将运维成本推至不可承受的地步。
Ceph 的目标是 “企业级自动化存储”,需支持 “节点即插即用、负载自动均衡”,而一致性哈希的静态分布完全违背这一目标:
- 手动运维效率低:上千节点的集群中,运维人员需逐一计算每个节点的哈希权重、调整虚拟节点数量,再手动触发数据迁移 —— 单次扩容可能需要数天,且极易因计算失误导致数据迁移量暴增,影响业务可用性;
- 容量 / 负载失控:长期运行后,集群会出现 “部分节点满、部分节点空” 的失衡状态,一致性哈希无法自动修复,最终导致集群整体存储效率下降,甚至因个别节点满容被迫停止服务。
这种 “需人工干预的静态分布”,在大规模集群中完全是 “运维灾难”,与 Ceph “自动化运维” 的核心诉求彻底冲突。
3.2 生产环境教训:
某金融公司使用一致性哈希的存储系统,机房断电导致三副本全损,损失千万级数据。
Cepth采用CRUSH算法,CRUSH不是简单的哈希函数,而是将拓扑感知、权重管理、故障隔离等分布式存储的核心需求,通过可配置规则引擎实现。
这种设计让Ceph在EB级规模下仍保持优雅运维。下面分析下大致实现
3.3 Cepth的 CRUSH算法核心设计
为什么 CRUSH 不是“哈希+虚拟节点”
| 维度 | 一致性哈希 | CRUSH |
|---|---|---|
| 输入 | object-key | object-key + 拓扑树 + 规则 + 权重 |
| 输出 | 一个节点 | 一组满足“隔离约束”的 OSD |
| 是否感知机房/机架 | ❌ | ✅ 逐层强制隔离 |
| 是否可人工指定“别放同机架” | ❌ | ✅ 规则引擎 |
| 加节点是否自动再平衡 | ❌ 需手动触发 | ✅ 自动、仅迁移必要数据 |
| 副本故障是否重新计算 | ❌ 需外部脚本 | ✅ 客户端本地 5ms 内算出新 OSD |
CRUSH(Controlled Replication Under Scalable Hashing 可扩展哈希下的受控复制)通过层级拓扑感知和伪随机分布解决上述问题:
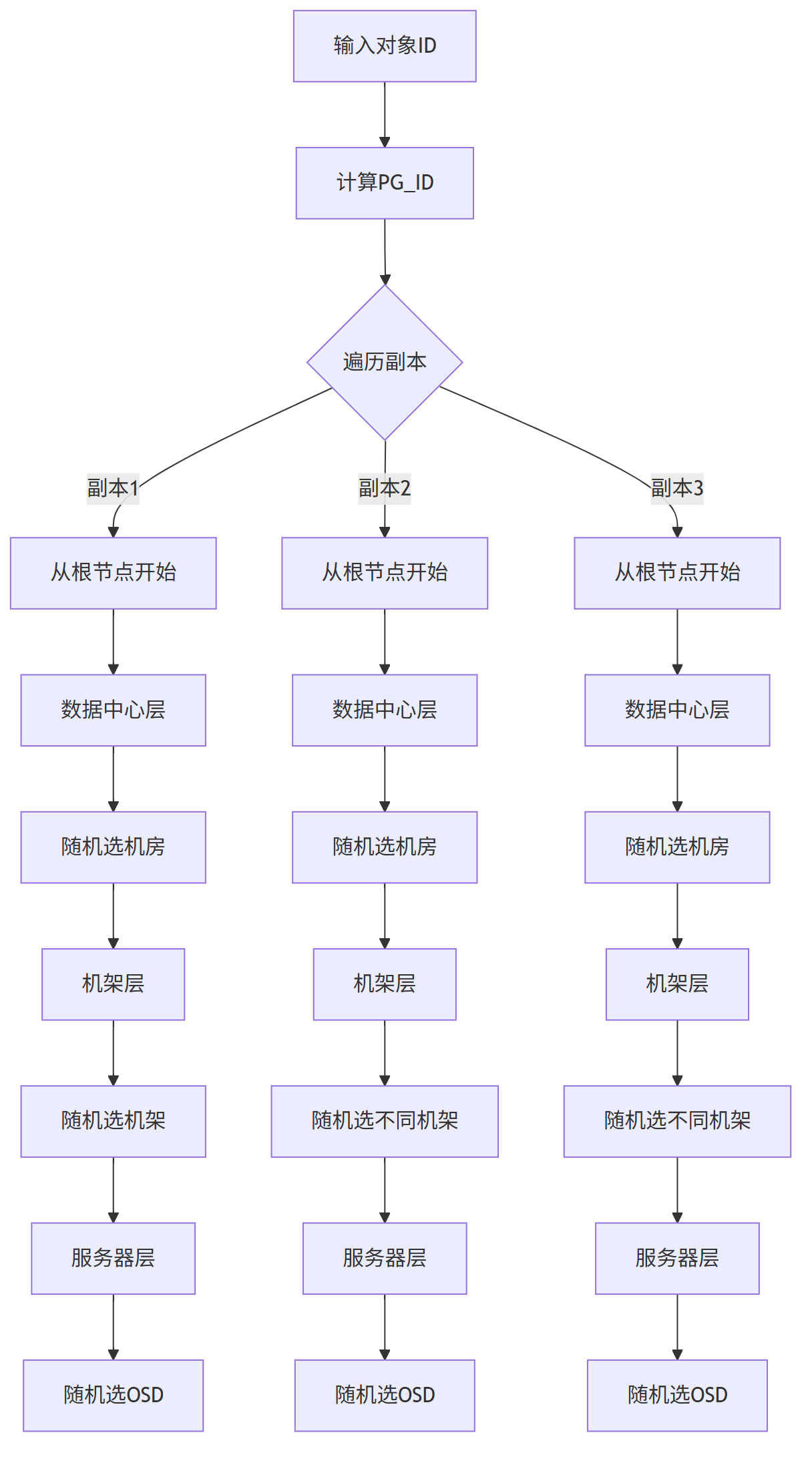
CRUSH 的三张“底牌”
1、层级拓扑树(Bucket-Tree)
把物理世界直接建模成一棵树,节点类型可以是
root → region → dc → room → row → rack → host → osd
每个节点带权重(容量)、类型、ID。
2、 规则引擎(CRUSH Rule)
一条规则就是一段“小程序”,告诉算法:
“先选 1 个机房,再在该机房下选 2 个不同机架,每个机架各选 1 块盘,共 3 副本”。
3、伪随机递归下降选择(Straw2)
每层用 确定性随机函数 挑子节点,保证:
- 同一输入永远算出同一组 OSD(幂等)
- 任意节点挂掉,只影响以它为根的分支,其他分支不动(最小重建)
CRUSH工作流程:
拓扑感知副本放置
CRUSH Map定义存储集群的物理拓扑:
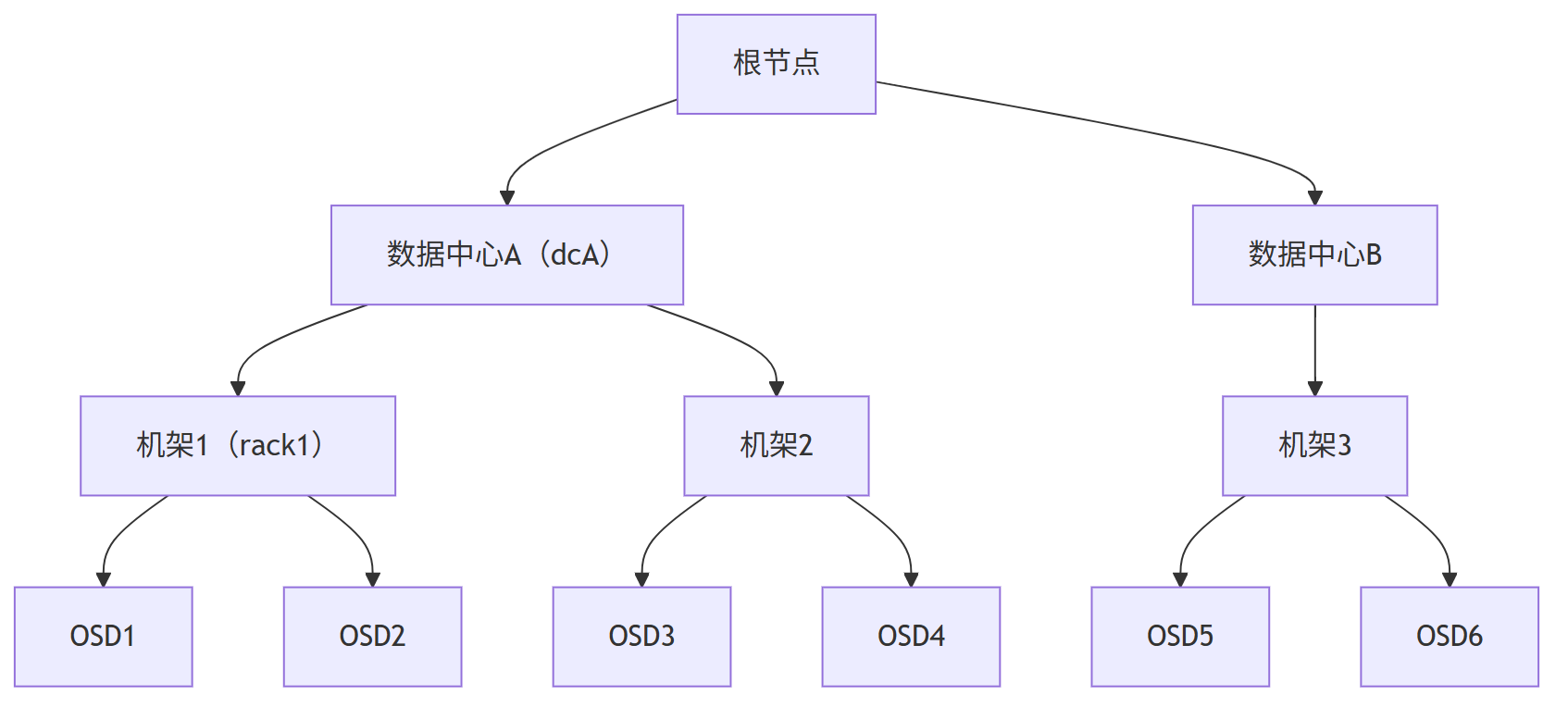
比如给定拓扑结构:
数据中心A
├─机架1: OSD1, OSD2
└─机架2: OSD3, OSD4
数据中心B
└─机架3: OSD5, OSD6
CRUSH计算过程:
计算结果:三副本分布在三个不同机架,完美规避单点故障。
算法 walk-through:手把手算一次
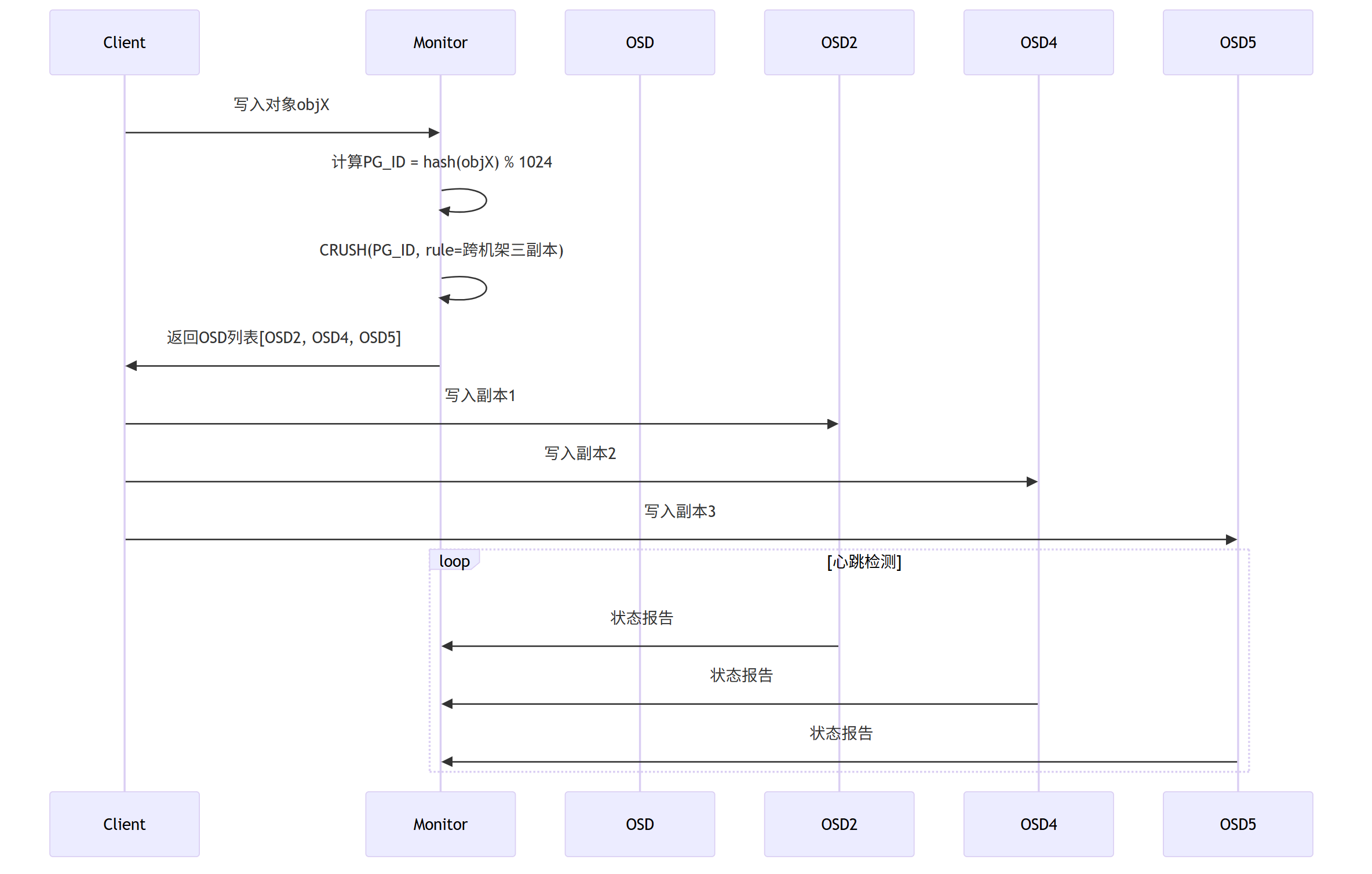
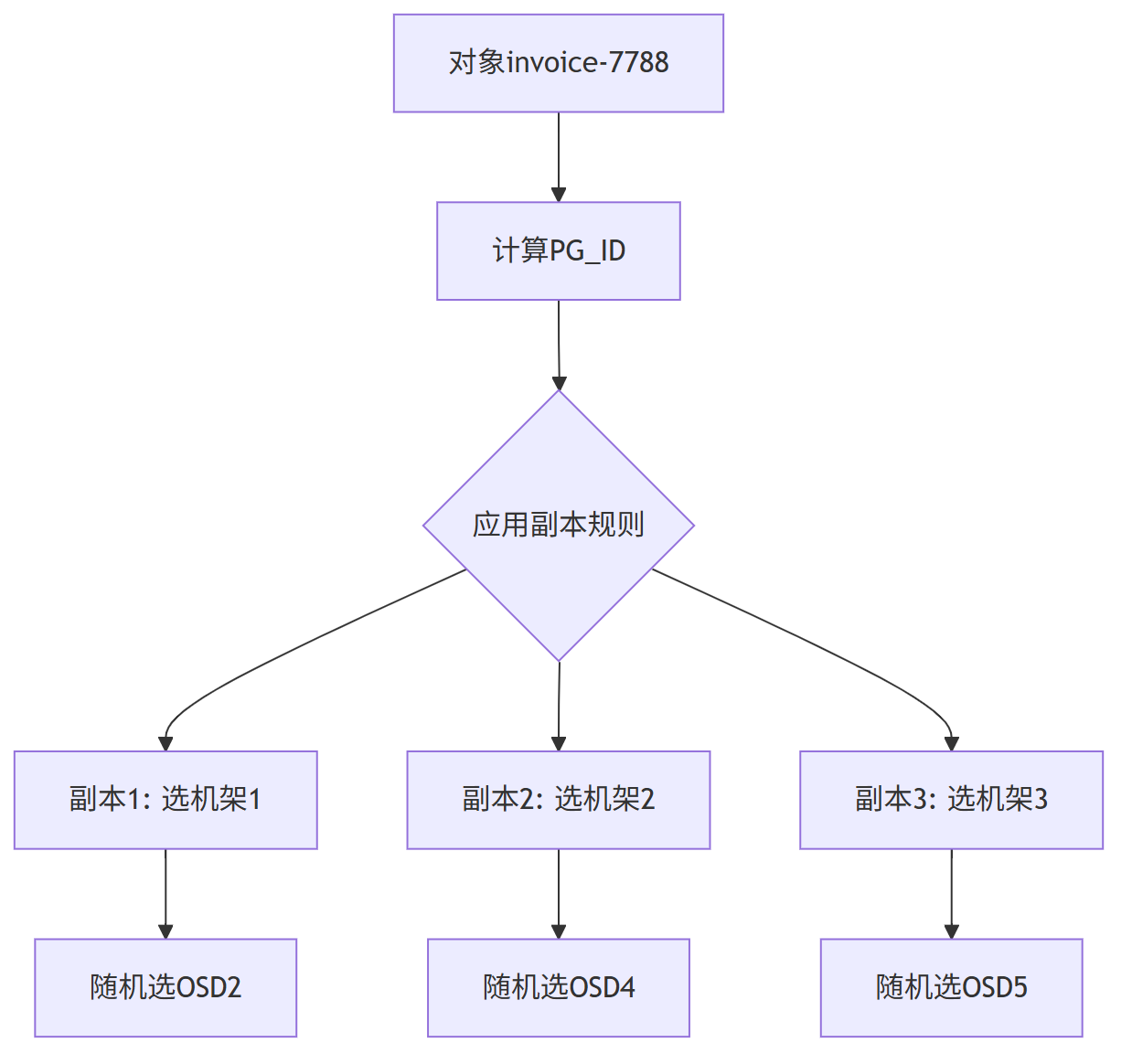
给定:
对象名 “invoice-7788”,副本数 3,规则 “rack-level anti-affinity”。
步骤 0:预处理
PG_ID = hash(‘invoice-7788’) % 2^32 (Ceph 先映射到 PG,再 CRUSH)
步骤 1:选副本 1
-
从 root 开始,Straw2 在 {dcA, dcB} 里抽签 → dcA 胜出
-
在 dcA 的子节点 {rack1, rack2} 抽签 → rack1 胜出
-
在 rack1 的 {osd1, osd2} 抽签 → osd2 胜出
→ 得到待写入的 副本 1:osd2
步骤 2:选副本 2
-
规则要求“必须不同机架”,于是把 rack1 标记为 reject
-
再次从 root 出发,dcA 只剩 rack2 → 自动进 rack2
-
rack2 里抽签 → osd4
→ 得到待写入的 副本 2:osd4
步骤 3:选副本 3
-
规则要求“跨机房”,dcA 已用 2 副本,剩下 1 副本必须进 dcB
-
dcB → rack3 → osd5
→ 得到待写入的 副本 3:osd5
最终客户端拿到列表 [2,4,5],直接并发写三份。
整个过程在客户端库本地完成,无中心调度,耗时 < 1ms。
四、加节点 / 掉节点 怎么“自愈”
场景 1:新增 osd7 到 rack3
- 权重变大 → 下次 Straw2 抽签时 osd7 中签概率提高
- 仅 PG 映射到 osd7 的那部分数据需要搬迁,老数据原地不动
→ 增量再平衡,无全局风暴。
场景 2:osd4 宕机
- 客户端写/读时发现超时,本地重新 CRUSH(PG_ID)
- rack2 被临时标记为 reject,算法自动在 rack1 或 rack3 补新副本
→ 5 秒内新副本补齐,无需人工介入。
五、权重与容量精准对齐
Ceph 把“TB”直接当权重写入 CRUSH map。
例:
osd1: 4 TB → weight = 4.00
osd2: 8 TB → weight = 8.00
Straw2 抽签概率与权重成正比,因此
- 8 TB 盘得到的数据量是 4 TB 盘的 2 倍
- 集群长期运行后各盘使用率差 < 5 %,无需额外 balancer。
CRUSH vs 一致性哈希
| 能力 | 一致性哈希 | CRUSH算法 |
|---|---|---|
| 拓扑感知 | 否 | 层级拓扑定义 |
| 自动负载均衡 | 需虚拟节点 | 权重自动调整 |
| 扩容数据迁移 | 约1/N | 仅新节点接收数据 |
| 故障域隔离 | 否 | 副本规则定制 |
| 无中心调度 | 是 | 是 |
CRUSH不是简单的哈希函数,而是将拓扑感知、权重管理、故障隔离等分布式存储的核心需求,通过可配置规则引擎实现。
这种设计让Ceph在EB级规模下仍保持优雅运维。
4、HBase为何不用一致性哈希
HBase 基于 Hadoop 生态,是为 “海量非结构化 / 半结构化数据” 设计的列存储数据库,核心优势是 “高写入吞吐量” 和 “海量数据随机读”,适合存储时序数据、日志数据、用户行为数据等。
HBase 关键特性
- 列存储模型:数据按 “列族”(Column Family)存储,而非传统行存储。例如 “用户表” 可分 “基本信息列族”(姓名、年龄)、“行为列族”(点击记录、浏览记录),查询时仅读取需要的列族,减少 IO 开销。
- 海量数据支撑:单表支持 PB 级数据,行数可达百亿级,通过 “Region 分片”(将表按 RowKey 范围拆分)实现水平扩展。
- 强一致性与高可用:依赖 ZooKeeper 实现集群协调(如选主、Region 定位),数据副本存储在 HDFS(Hadoop 分布式文件系统),支持故障自动恢复,确保写入数据不丢失。
- 灵活的数据模型:无需预先定义完整表结构(列可动态添加),适合字段不固定的场景(如日志数据,不同日志可能有不同字段),同时支持 TTL(数据过期自动删除)、版本控制(保留多版本数据)。
HBase 核心架构
HBase 架构依赖 Hadoop 生态(HDFS、ZooKeeper),核心组件包括:
- HMaster:集群管理节点,负责 Region 分配、表结构修改(建表 / 删表)、RegionServer 故障恢复,无数据读写功能(可部署多个实现高可用)。
- RegionServer:数据读写节点,负责管理多个 Region(数据分片),处理客户端的读写请求,将数据持久化到 HDFS。
- ZooKeeper:维护集群元数据(如 HMaster 地址、Region 位置),实现 HMaster 主从切换,保证集群一致性。
- HDFS:底层存储层,存储 HBase 的实际数据(Region 数据)和日志文件,利用 HDFS 的分布式存储能力实现数据高可靠。
HBase 典型场景
- 实时日志 / 时序数据存储:如服务器监控日志(每秒上万条写入)、IoT 设备传感器数据(温度、湿度等时序数据),支持按时间范围快速查询。
- 海量非结构化数据管理:如用户行为数据(点击、浏览、购买记录)、社交平台消息数据,字段动态变化且需高写入吞吐量。
- 离线分析与实时查询结合:数据写入 HBase 后,可通过 Spark、Flink 实时分析,也可通过 Phoenix 组件实现 SQL 查询(兼容部分 SQL 语法)。
Hbase作为海量key/value结构,分布式数据库的核心挑战不是均匀分布数据,而是保持数据关联性。
Range分区通过维护RowKey的物理有序性,为范围查询和时序数据提供了原生优化,这是哈希方案无法企及的。
一致性哈希的致命缺陷
…由于平台篇幅限制, 剩下的内容(5000字+),请参参见原文地址
原始的内容,请参考 本文 的 原文 地址
尼恩架构团队 《百亿级数据存储架构》 系列
已经发布的文章包括:
100亿级任务调度篇:从0到1, 从入门到 XXLJOB 工业级使用
高并发搜索ES圣经:从0到1, 从入门到 ElasticSearch 工业级使用
超级底层:10WQPS/PB级海量存储HBase/RocksDB,底层LSM结构是什么?
希音面试:ClickHouse Group By 执行流程 ?CK 能支持 十亿级数据 实时分析的原理 是什么?
100亿级数据存储架构:MYSQL双写 + HABSE +Flink +ES综合大实操
帮助大家打造一个新的黄金项目,实现大厂的梦想。
当然,这道面试题,以及参考答案,也会收入咱们的 《尼恩Java面试宝典PDF》V175版本,供后面的小伙伴参考,提升大家的 3高 架构、设计、开发水平。
《尼恩 架构笔记》《尼恩高并发三部曲》《尼恩Java面试宝典》的PDF,请到文末公号【技术自由圈】获取

















 452
452

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









