



本文 的 原文 地址
原始的内容,请参考 本文 的 原文 地址
尼恩说在前面:
最近大厂机会多了, 在45岁老架构师 尼恩的读者交流群(50+)中,最近有小伙伴拿到了一线互联网企业如得物、阿里、滴滴、极兔、有赞、shein 希音、shopee、百度、网易的面试资格,遇到很多很重要的面试题:
京东场景题:100Wqps 亿级用户的社交关系如何设计?如何查看我的关注,关注我的?
京东场景题: 美国总统选举,要设计一个选票系统,要求 100w tps,1000w qps,选票不可篡改,不可重复,获取我的选票结果,获取最终投票结果。问:接口怎么设计,系统怎么设计
前几天 小伙伴面试 京东,遇到了上面 两个场景题 。
但是由于 没有回答好,导致面试挂了。
过两天吧,尼恩 会 再开一篇文章, 给大家介绍 第 二个场景题。
这篇文章,尼恩给大家介绍第一个场景题。
尼恩给大家做一下系统化、体系化的梳理,使得大家内力猛增,可以充分展示一下大家雄厚的 “技术肌肉”,让面试官爱到 “不能自已、口水直流”,然后实现”offer直提”。
当然,这道面试题,以及参考答案,也会收入咱们的 《尼恩Java面试宝典》V175版本PDF集群,供后面的小伙伴参考,提升大家的 3高 架构、设计、开发水平。
最新《尼恩 架构笔记》《尼恩高并发三部曲》《尼恩Java面试宝典》的PDF,请关注本公众号【技术自由圈】获取,后台回复:领电子书
一、亿级用户的社交关系 总的架构方案
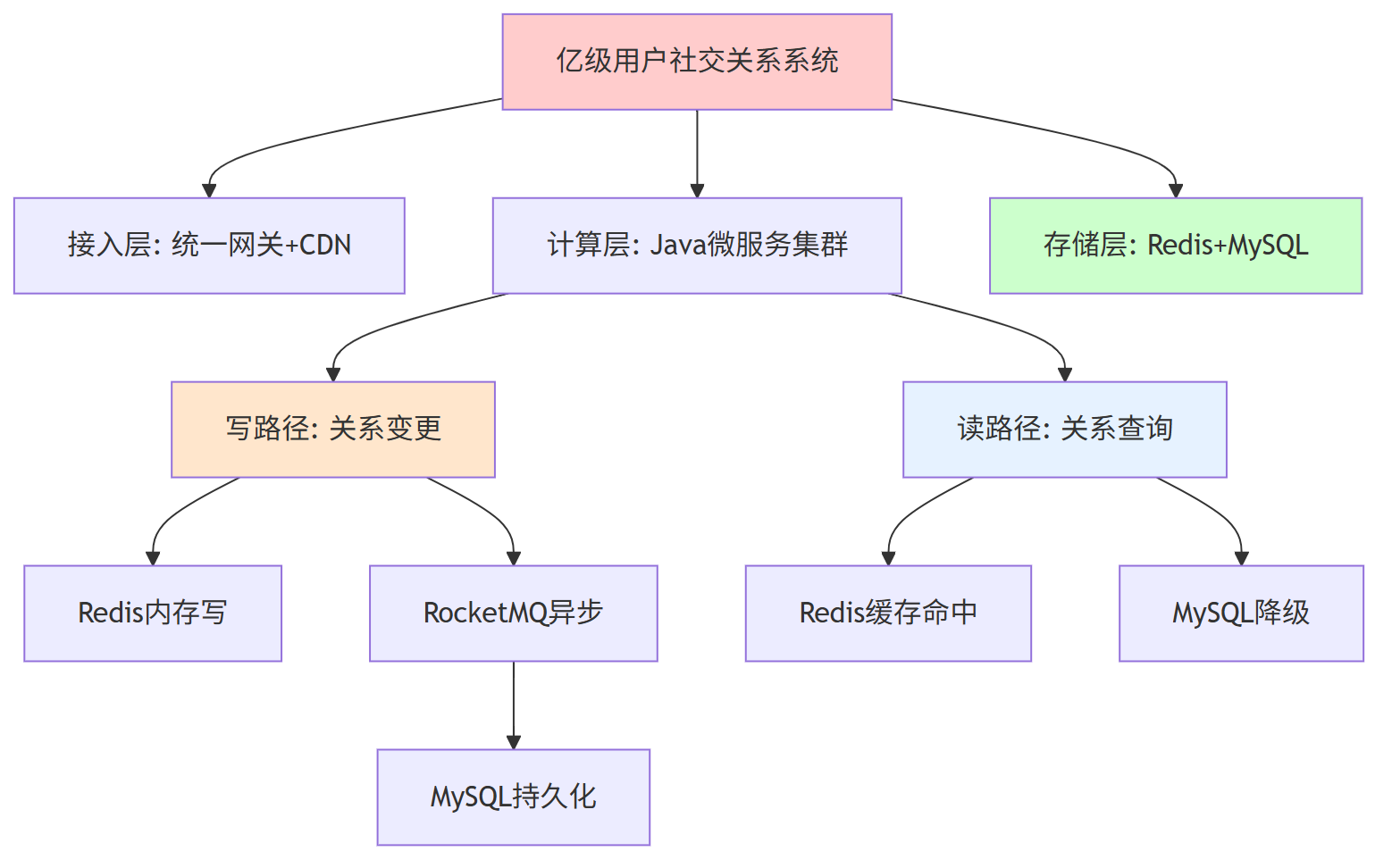
二、核心数据模型 设计
第一、关系语义
| 维度 | 枚举值 | 说明 |
|---|---|---|
| 方向 | 关注、粉丝、双向 | 用两笔记录冗余,避免JOIN |
| 状态 | 有效、已取消、拉黑 | 软删除,保留历史 |
| 时间 | create_time、update_time | 支持时序回溯 |
第二、MySQL表(水平16库×1024表)
CREATE TABLE user_relation_
PARTITION BY HASH(user_id) PARTITIONS 1024
(
user_id BIGINT COMMENT '用户A',
target_id BIGINT COMMENT '用户B',
relation_type TINYINT COMMENT '1A->B 2 B->A 3 双向',
state TINYINT COMMENT '0取消 1正常 2拉黑',
create_time DATETIME,
PRIMARY KEY (user_id, target_id),
KEY idx_target(target_id)
) ENGINE=InnoDB;
第三、Redis结构
| 场景 | Key | 类型 | TTL | 备注 |
|---|---|---|---|---|
| 我关注的人 | following:{userId} | Set | 永不过期 | 元素=targetId |
| 我的粉丝 | followers:{userId} | Set | 永不过期 | 元素=fanId |
| 关注数 | cnt:following:{userId} | String | 永不过期 | 缓存计数,异步同步 |
| 粉丝数 | cnt:followers:{userId} | String | 永不过期 | 同上 |
三、并发写路径 设计(关注为例)
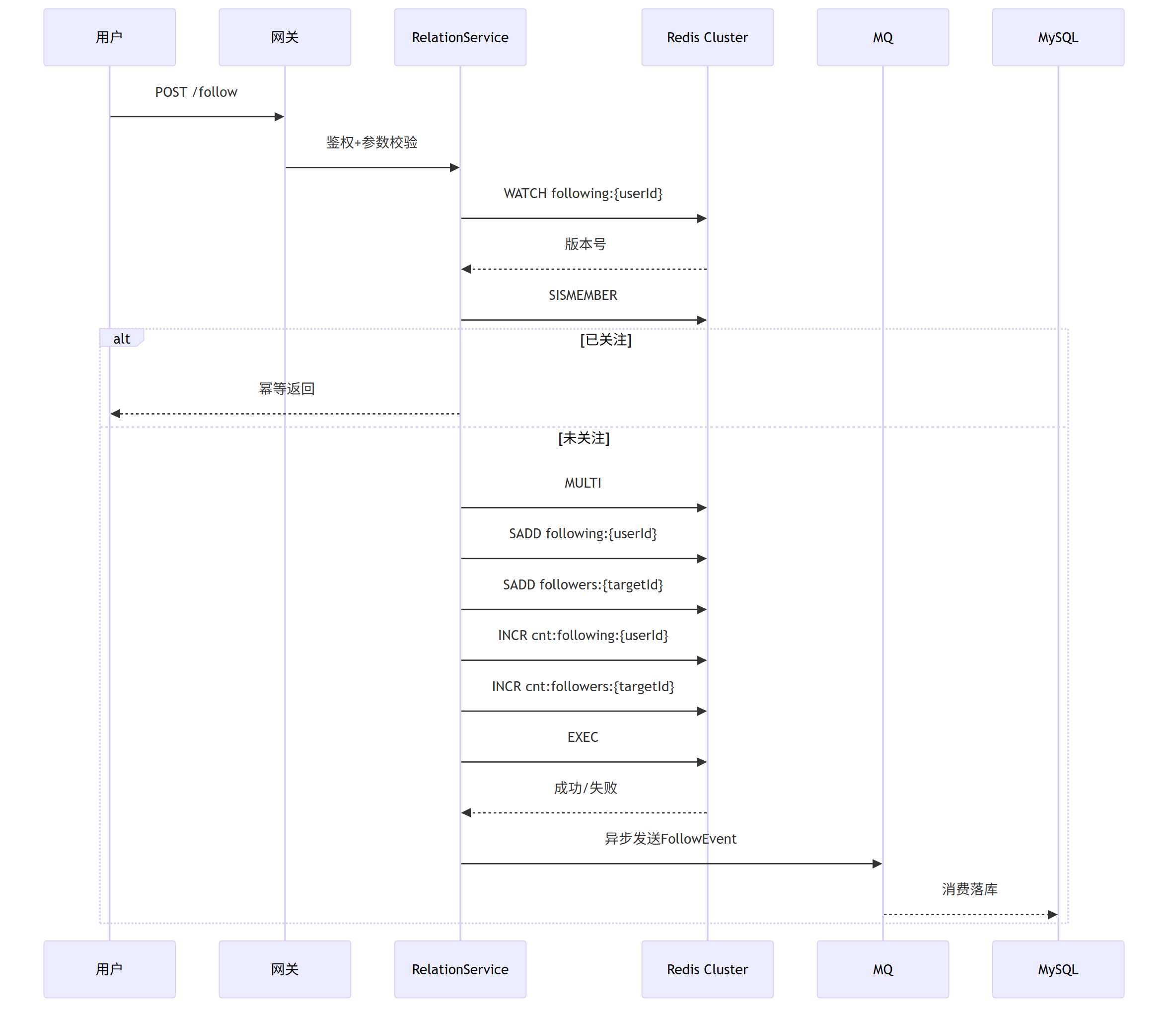
伪代码 如下
// 一、Redis Lua脚本:原子写
String lua =
"if redis.call('SISMEMBER', KEYS[1], ARGV[1]) == 1 then " +
" return 0 " +
"else " +
" redis.call('SADD', KEYS[1], ARGV[1]); " +
" redis.call('SADD', KEYS[2], ARGV[2]); " +
" redis.call('INCR', KEYS[3]); " +
" redis.call('INCR', KEYS[4]); " +
" return 1 " +
"end";
Long ok = redis.execute(lua,
Arrays.asList("following:"+userId,
"followers:"+targetId,
"cnt:following:"+userId,
"cnt:followers:"+targetId),
targetId.toString(), userId.toString());
if (ok == 1) {
rocketMQ.syncSend("follow-topic", new FollowEvent(userId, targetId, 1));
}
四、并发读路径
第一、缓存 穿透保护
// BloomFilter 预加载全部userId,100亿位≈1.2GB内存
if (!bloomFilter.mightContain(targetId)) {
return false; // 非法用户直接返回
}
第二、三级缓存
| 层级 | 位置 | 命中率 | 说明 |
|---|---|---|---|
| L1 | 本地Caffeine | 70% | 热点大V,5s过期 |
| L2 | Redis | 99% | Set/String,永久 |
| L3 | MySQL | 100% | 降级,binlog回填Redis |
五、容量与分片策略
第一、Redis
- 16分片集群,每片64GB,共1024GB
- 大V粉丝>1万时,拆分为
followers:{userId}:{shardId},shardId = targetId % 32
第二、MySQL
- 16库×1024表=16384张表
- 单表行数<5000万,索引深度≤3
- 冷热分离:6个月前数据迁移TiDB/ODPS
六、数据一致性保障
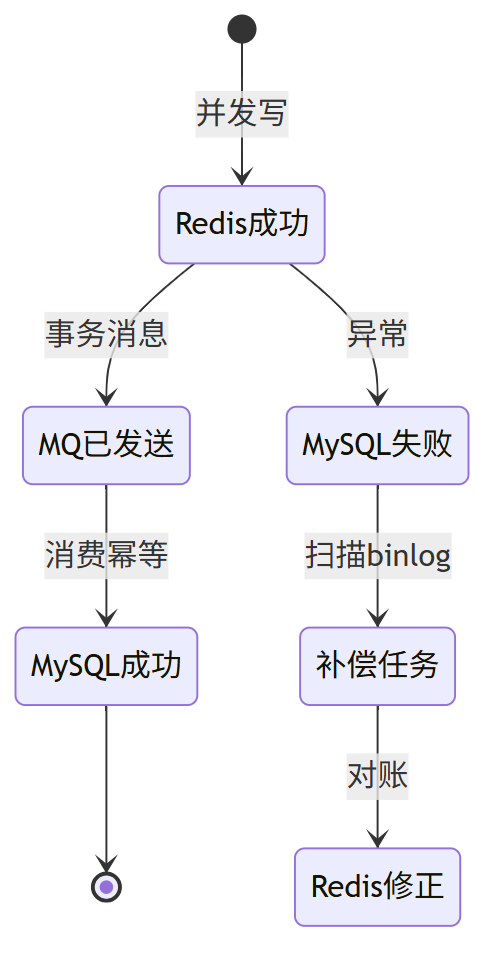
数据一致性保障 补偿任务 伪代码
@Scheduled(fixedDelay = 30_000)
public void reconcile() {
List<FollowEvent> list = canalClient.pullBinlog();
list.forEach(e -> {
Boolean inRedis = redis.sIsMember("following:"+e.getUserId(), e.getTargetId());
if (e.getState() == 1 && !inRedis) {
redis.sAdd("following:"+e.getUserId(), e.getTargetId());
} else if (e.getState() == 0 && inRedis) {
redis.sRem("following:"+e.getUserId(), e.getTargetId());
}
});
}
七: redis bigkey 风险点 和攻关
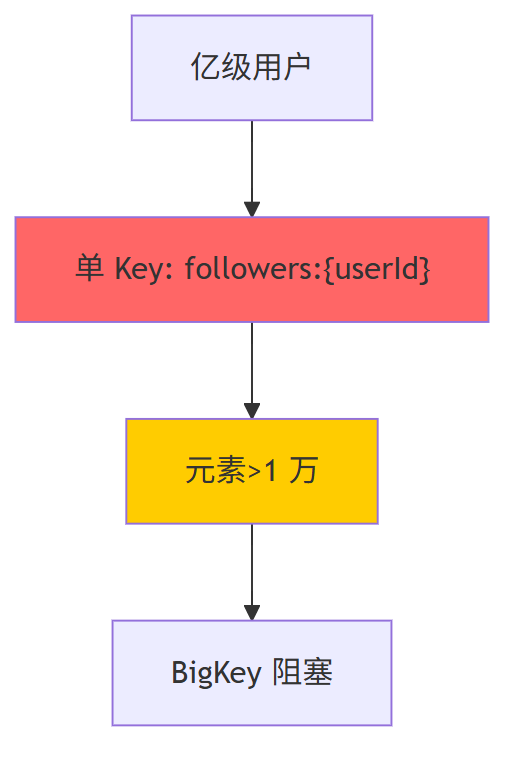
7.1、BigKey 识别体系
第一、实时巡检
// 每 10 min 抽样
if (redis.llen("followers:" + userId) > 10000) {
alertBigKey(userId);
}
第二、离线扫描
// 每日 Spark 任务
dataset.filter(r -> r.getLong("followers_count") > 1000_0000)
.foreach(r -> mailToOps(r.getString("user_id")));
7.2 、BigKey 攻关方案
第一、水平拆分(Hash 分桶)
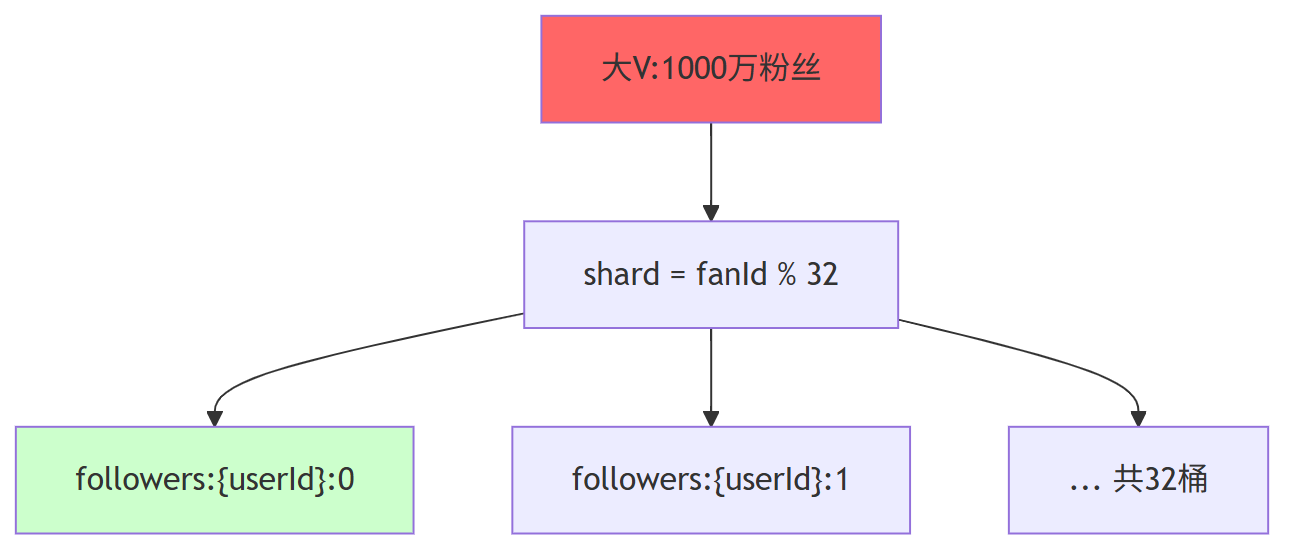
int shard = fanId & 31;
String key = "followers:" + userId + ":" + shard;
redis.sadd(key, fanId);
第二、读写路由
// 写
int shard = fanId % 32;
redis.sadd("followers:" + userId + ":" + shard, fanId);
// 读
Set<String> all = new HashSet<>();
for (int i = 0; i < 32; i++) {
all.addAll(redis.smembers("followers:" + userId + ":" + i));
}
return all;
第三、异步迁移
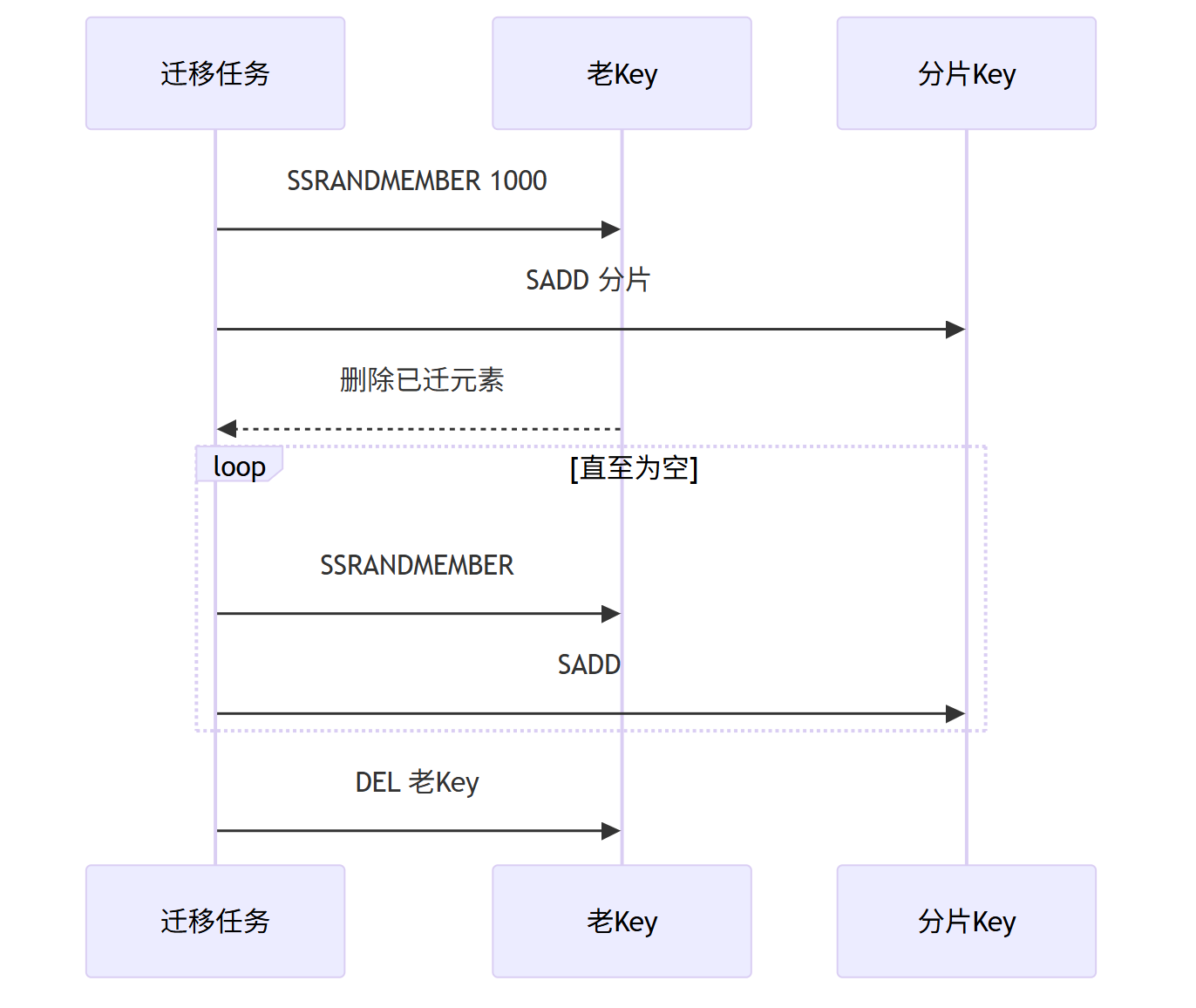
while (redis.scard("followers:" + userId) > 0) {
Set<String> batch = redis.spop("followers:" + userId, 1000);
for (String fan : batch) {
int shard = Long.parseLong(fan) % 32;
redis.sadd("followers:" + userId + ":" + shard, fan);
}
}
redis.del("followers:" + userId);
第四、热 Key 二次打散
// 一库32桶仍过热→再拆256微桶
int micro = (fanId % 8192) >> 5;
String key = "followers:" + userId + ":" + shard + ":" + micro;
第五、效果验证
| 指标 | 优化前 | 优化后 |
|---|---|---|
| Key 体积 | 1 Key 1 万元素 | 32 Key 每 Key 310元素 |
| 单次阻塞 | 50 ms | <1 ms |
| 故障率 | 5% 超时 | 0.1% 超时 |
7.3、BigKey 攻关方案小结
通过「Hash 分桶 + 异步迁移 + 本地缓存」三级策略,彻底消除 BigKey 隐患,保障亿级场景下 Redis 延迟 <1 ms。
8、 100W QPS 亿级用户社交关系 高并发攻关方案
8.1、高并发 业务 压力识别
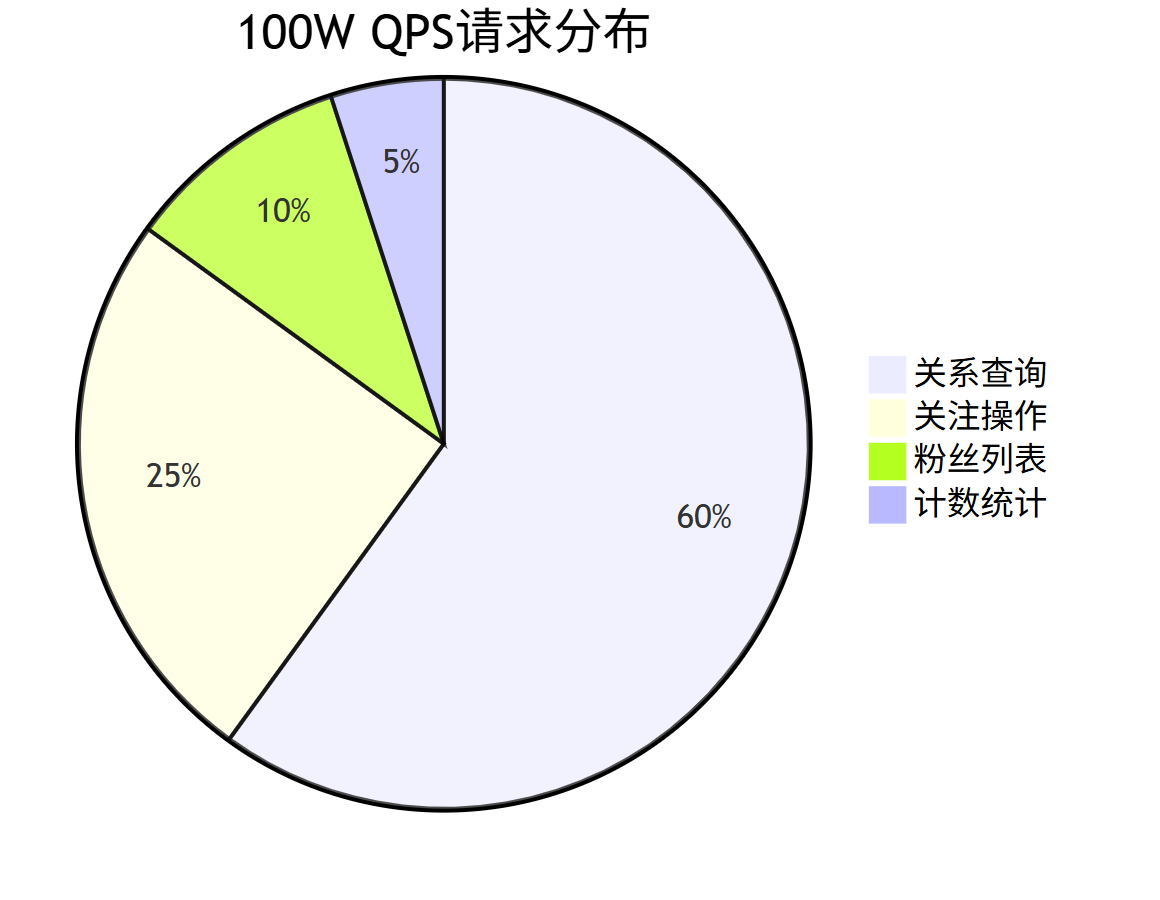
8.2、高并发 读写 压力识别
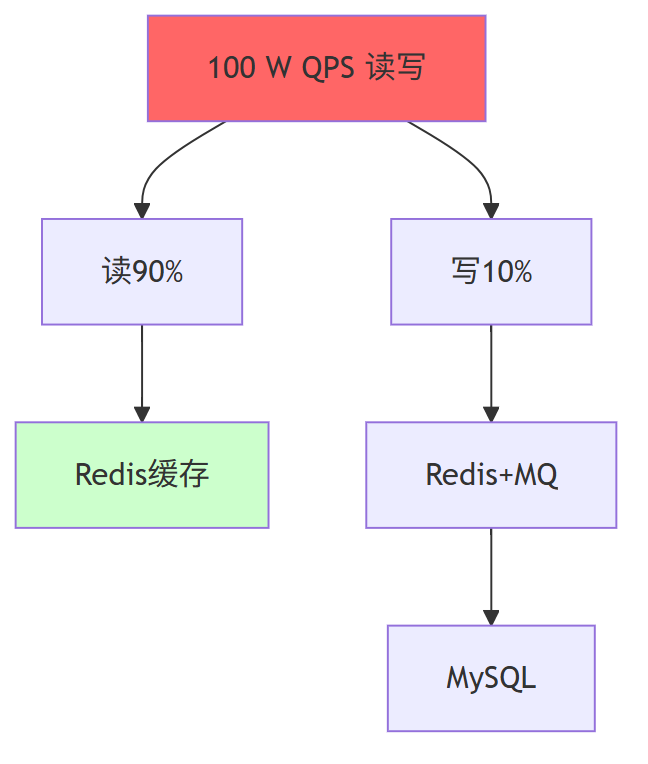
第一、读瓶颈
- 单 Redis 分片 6 W QPS → 需 16 分片才 96 W
- 热 Key 大 V 集中 → 单分片打满
第二、写瓶颈
- 单机 MySQL 1 W TPS → 需 100 分库才 100 W
- 锁冲突、页分裂 → 毛刺 100 ms
8.3、中间件 与 传输 瓶颈分析
- 网络IO:万兆网卡带宽极限
- 连接数:单机TCP连接数限制
- Redis单节点:8-10W QPS天花板
- MySQL写入:单机写入性能瓶颈
8.4、基础解决方案(支撑 50W QPS)
第一、读写分离架构优化
将读请求与写请求路由至不同存储节点,避免相互干扰:
- 写路径:Redis 主节点(处理关注 / 取消关注)→ MQ 异步同步 → MySQL 主库
- 读路径:本地缓存 → Redis 从节点 → MySQL 从库(降级场景)
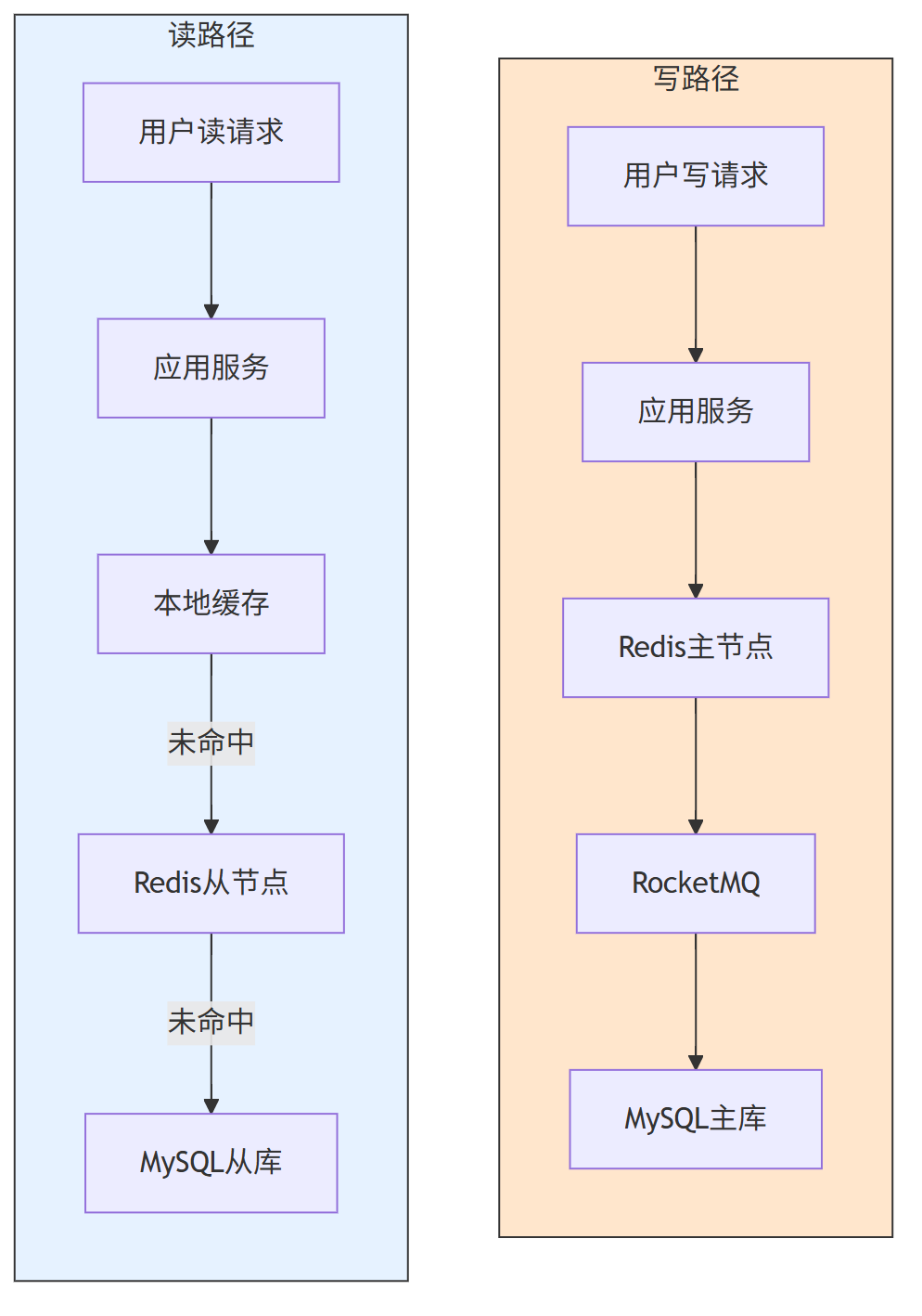
第二、Redis 集群扩容与分片优化
1、集群分片调整:将原 16 分片扩容至 32 分片,单分片 QPS 从 6.25W 降至 3.125W,降低单节点压力
2、热点分片隔离:将热点用户(如大 V)的 Redis 数据单独分配至 8 个专属分片,避免影响普通分片
3、读写分离配置:每个 Redis 主节点挂载 2 个从节点,读请求优先路由至从节点
// Redis分片路由:热点用户定向路由至专属分片
public RedisNode getRedisNode(Long userId) {
// 1. 检查是否为热点用户
List<Long> hotUsers = JSON.parseArray(redis.get("hot:users"), Long.class);
if (hotUsers.contains(userId)) {
// 2. 热点用户路由至专属分片(8个分片:0-7)
int shard = Math.abs(userId.hashCode() % 8);
return redisCluster.getNodeByShard(shard);
} else {
// 3. 普通用户路由至普通分片(24个分片:8-31)
int shard = 8 + Math.abs(userId.hashCode() % 24);
return redisCluster.getNodeByShard(shard);
}
}
第三、批量请求优化
将高频小请求合并为批量请求,减少网络 IO 次数:
- 批量查询:支持一次查询多个用户的关注状态(如 “检查是否关注 [1001,1002,1003]”)
- 批量写入:MQ 消费端批量处理关注事件,每 100 条请求合并为 1 次 MySQL 写入
// 批量检查关注状态(支撑单次请求查20个用户)
public List<Boolean> batchCheckFollow(Long userId, List<Long> targetIds) {
// 1. 构造Redis批量请求
List<Object> results = redis.pipelined(p -> {
targetIds.forEach(targetId -> {
p.sIsMember("following:" + userId, targetId.toString());
});
}).get();
// 2. 转换结果
return results.stream()
.map(res -> res != null && (Boolean) res)
.collect(Collectors.toList());
}
// MQ消费端批量写入MySQL
@RabbitListener(queues = "follow-event-queue")
public void batchProcessFollowEvent(List<FollowEvent> events) {
// 1. 按用户ID分组(避免跨库事务)
Map<Long, List<FollowEvent>> eventGroup = events.stream()
.collect(Collectors.groupingBy(FollowEvent::getUserId));
// 2. 批量插入各分组数据
eventGroup.forEach((userId, groupEvents) -> {
List<FollowDO> followDOS = groupEvents.stream()
.map(event -> new FollowDO(
event.getUserId(),
event.getTargetId(),
event.getRelationType()
)).collect(Collectors.toList());
// 3. 批量插入(一次插入100条)
if (followDOS.size() >= 100) {
userRelationMapper.batchInsert(followDOS);
followDOS.clear();
}
});
}
8.4、进阶解决方案(支撑 100W QPS)
第一、多级缓存架构升级
在基础 “本地缓存 + Redis” 两级缓存基础上,新增 “ 分布式本地缓存”,提升读请求命中率至 99.5%:
| 缓存层级 | 技术选型 | 缓存内容 | 过期时间 | 命中率目标 |
|---|---|---|---|---|
| L1 | Caffeine(一致性hash本地缓存) | 热点用户关注状态、列表 | 30 秒 | 40% |
| L2 | Redis 从节点 | 普通用户关系数据 | 永久 | 29.5% |
| L3 | MySQL 从库 | 降级场景数据 | - | 0.5% |
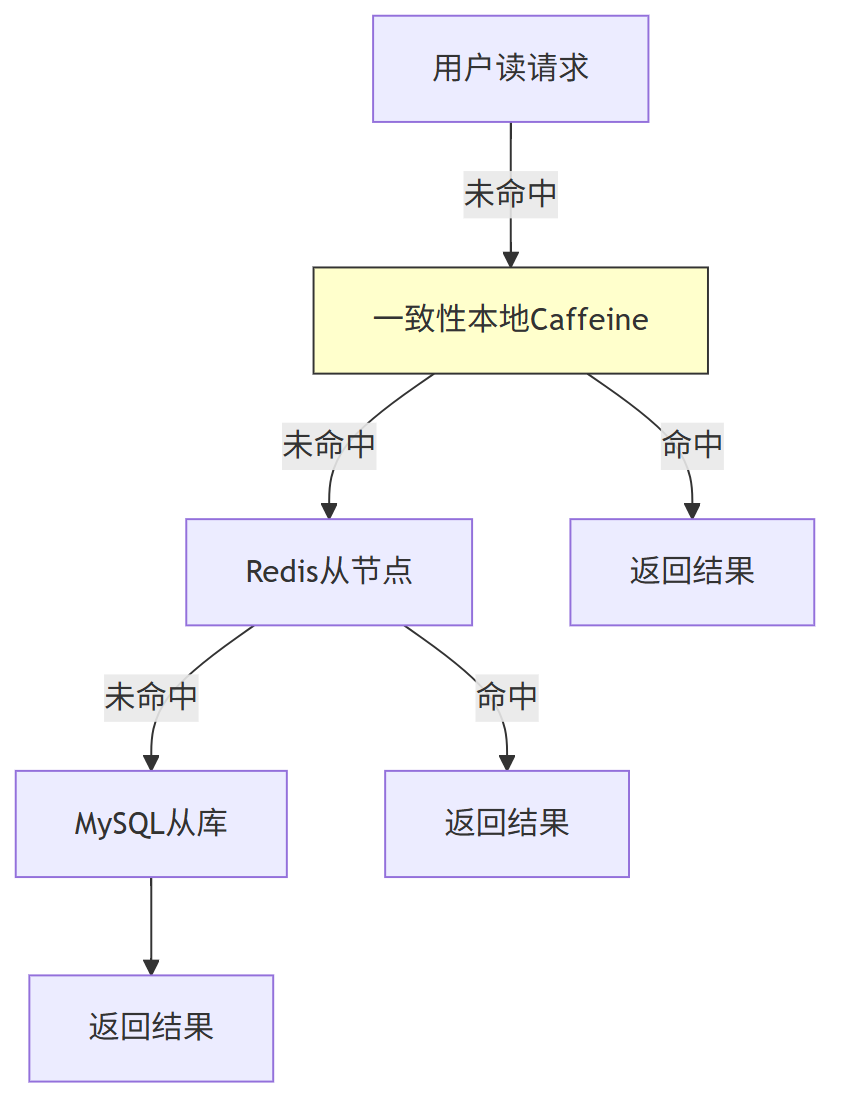
// 多级缓存查询:获取用户粉丝数
public Long getFansCount(Long userId) {
String cacheKey = "cnt:followers:" + userId;
// 1. 查本地Caffeine缓存
Long localVal = caffeineCache.getIfPresent(cacheKey);
if (localVal != null) return localVal;
// 2. 查Redis缓存
String redisVal = redis.get(cacheKey);
if (redisVal != null) {
Long val = Long.parseLong(redisVal);
// 回写本地缓存
caffeineCache.put(cacheKey, val, 30, TimeUnit.SECONDS);
// 热点用户回写CDN
if (hotUsers.contains(userId)) {
cdnClient.set(cacheKey, val.toString(), 300, TimeUnit.SECONDS);
}
return val;
}
// 3. 查MySQL并回填缓存
Long dbVal = userRelationMapper.countFans(userId);
redis.set(cacheKey, dbVal.toString());
caffeineCache.put(cacheKey, dbVal, 30, TimeUnit.SECONDS);
if (hotUsers.contains(userId)) {
cdnClient.set(cacheKey, dbVal.toString(), 300, TimeUnit.SECONDS);
}
return dbVal;
}
分布式 Caffeine :通过 一致性 Hash , 把「本地内存」当成「分布式环形空间」来用 ,提升本地缓存命中了
分布式 Caffeine 环形定位图
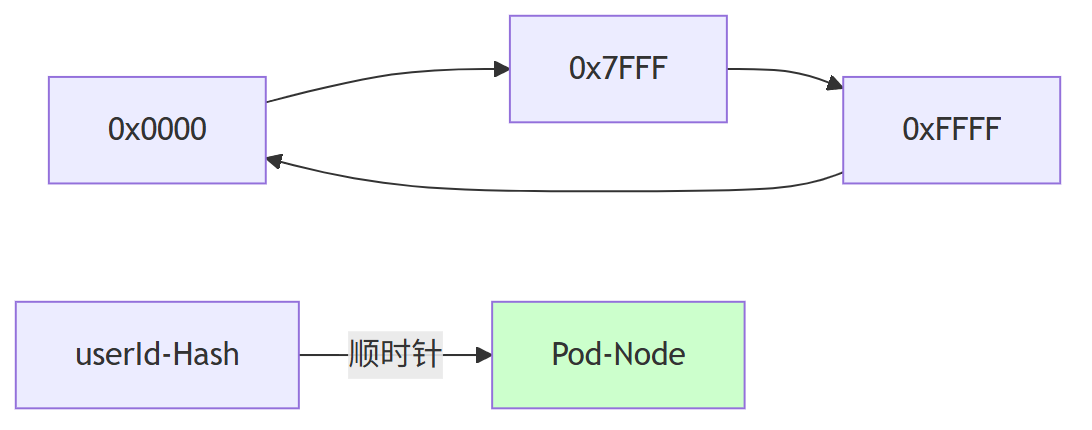
(1) 把 64 位 Hash 空间首尾相接成环。
(2) 每台 Pod 启动时根据「IP+端口」生成 200 个虚拟节点,均匀散落在环上。
(3) 任意 userId 的 Hash 值顺时针遇到的第一个虚拟节点,即为「缓存负责节点」。
第二、写请求削峰与异步化
通过 “前置缓存 + MQ 削峰 + 批量写入” 降低写请求对存储的瞬时压力:
1、前置缓存:写请求先更新 Redis,确保读请求能立即获取最新状态
2、MQ 削峰:将写请求发送至 RocketMQ,按用户 ID 分区,避免消息乱序
3、批量消费:消费端按 “100 条 / 批” 或 “100ms / 批” 触发批量写入 MySQL,降低数据库写 TPS
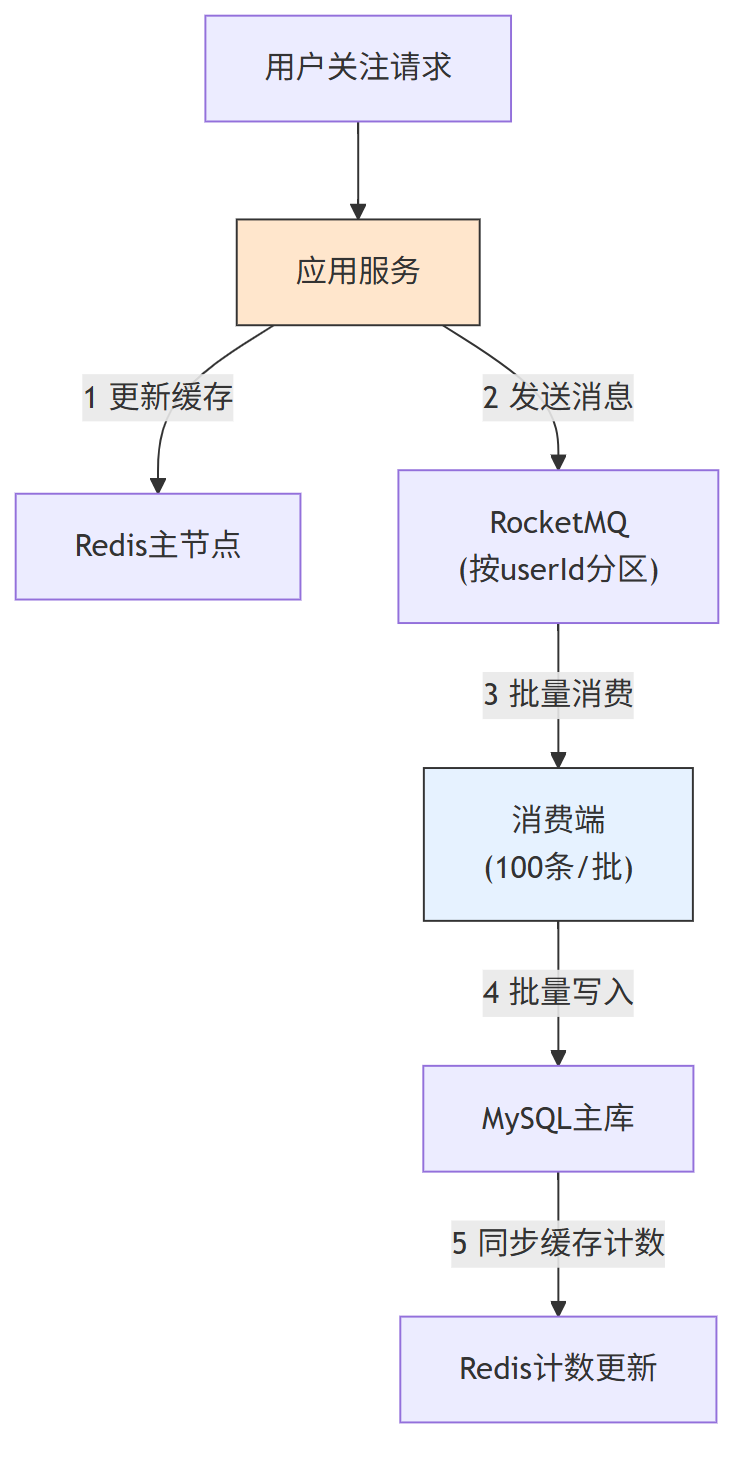
// 异步关注接口:先更缓存再发MQ
public boolean asyncFollow(Long userId, Long targetId) {
// 1. Lua脚本原子更新Redis(避免并发问题)
String lua = "if redis.call('SISMEMBER', KEYS[1], ARGV[1]) == 1 then " +
" return 0 " + // 已关注,返回失败
"else " +
" redis.call('SADD', KEYS[1], ARGV[1]); " + // 关注列表
" redis.call('SADD', KEYS[2], ARGV[2]); " + // 粉丝列表
" redis.call('INCR', KEYS[3]); " + // 关注数
" redis.call('INCR', KEYS[4]); " + // 粉丝数
" return 1 " + // 成功,返回1
"end";
Long result = redis.execute(lua,
Arrays.asList("following:"+userId, "followers:"+targetId,
"cnt:following:"+userId, "cnt:followers:"+targetId),
targetId.toString(), userId.toString()
);
if (result == 1) {
// 2. 发送MQ消息(按userId分区,确保顺序)
FollowEvent event = new FollowEvent(userId, targetId, 1);
rocketMQ.send("follow-topic",
MessageSelector.byTag("userId:" + (userId % 100)),
event);
return true;
}
return false;
}
第三、热点用户特殊处理
针对热点用户(如大 V)的高访问量,采用 “数据预加载 + 本地缓存全量存储 + 独立集群” 策略:
1、数据预加载:每天凌晨 3 点,将前 1000 名热点用户的关注 / 粉丝列表全量加载至分布式本地缓存(如 Redis Cluster 本地缓存)
2、本地全量存储:应用服务本地缓存热点用户的完整关注列表(仅前 10 万条,超量部分走分页)
3、独立集群:热点用户的 Redis 数据部署在独立集群,避免占用普通集群资源
// 热点用户数据预加载
@Scheduled(cron = "0 0 3 * * ?")
public void preloadHotUserData() {
// 1. 获取前1000名热点用户
List<Long> hotUsers = JSON.parseArray(redis.get("hot:users:top1000"), Long.class);
// 2. 批量预加载关注列表至分布式本地缓存
for (Long userId : hotUsers) {
// 2.1 从Redis获取完整关注列表(前10万条)
Set<String> follows = redis.zRange("following:" + userId, 0, 99999);
List<Long> followList = follows.stream()
.map(Long::valueOf)
.collect(Collectors.toList());
// 2.2 存储至分布式本地缓存(过期时间24小时)
distributedLocalCache.put("preload:following:" + userId,
followList,
86400,
TimeUnit.SECONDS);
// 2.3 同理预加载粉丝列表
Set<String> fans = redis.zRange("followers:" + userId, 0, 99999);
List<Long> fanList = fans.stream()
.map(Long::valueOf)
.collect(Collectors.toList());
distributedLocalCache.put("preload:fans:" + userId,
fanList,
86400,
TimeUnit.SECONDS);
}
}
// 热点用户关注列表查询:优先查预加载缓存
public List<Long> getHotUserFollows(Long userId, int page, int size) {
// 1. 检查是否为热点用户
List<Long> topHotUsers = JSON.parseArray(redis.get("hot:users:top1000"), Long.class);
if (!topHotUsers.contains(userId)) {
return getNormalUserFollows(userId, page, size); // 普通用户流程
}
// 2. 查预加载缓存
List<Long> preloadList = distributedLocalCache.get("preload:following:" + userId);
if (preloadList != null) {
// 3. 分页截取(避免全量返回)
int start = (page - 1) * size;
int end = Math.min(start + size, preloadList.size());
return preloadList.subList(start, end);
}
// 4. 缓存未命中,走正常流程并回写
List<Long> result = getNormalUserFollows(userId, page, size);
distributedLocalCache.put("preload:following:" + userId,
result,
3600,
TimeUnit.SECONDS);
return result;
}
九: 如何查看我的关注,关注我的
…由于平台篇幅限制, 剩下的内容(5000字+),请参参见原文地址


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









