



本文 的 原文 地址
尼恩说在前面:
在40岁老架构师 尼恩的读者交流群(50+)中,最近有小伙伴拿到了一线互联网企业如得物、阿里、滴滴、极兔、有赞、shein 希音、shopee、百度、网易的面试资格,遇到很多很重要的面试题:
MySQL的慢查询、如何监控、如何排查?
你知道如何排查慢sql嘛?
你知道如何对mysql进行优化嘛?
mysql慢查询如何定位分析?哪些情况会导致慢查询?
前几天 小伙伴面试 美团,遇到了这个问题。但是由于 没有回答好,导致面试挂了。
小伙伴面试完了之后,来求助尼恩。那么,遇到 这个问题,该如何才能回答得很漂亮,才能 让面试官刮目相看、口水直流。
所以,尼恩给大家做一下系统化、体系化的梳理,使得大家内力猛增,可以充分展示一下大家雄厚的 “技术肌肉”,让面试官爱到 “不能自已、口水直流”,然后实现”offer直提”。
当然,这道面试题,以及参考答案,也会收入咱们的 《尼恩Java面试宝典》V145版本PDF集群,供后面的小伙伴参考,提升大家的 3高 架构、设计、开发水平。
最新《尼恩 架构笔记》《尼恩高并发三部曲》《尼恩Java面试宝典》的PDF,请关注本公众号【技术自由圈】获取,后台回复:领电子书
尼恩提示:回答问题的时,首先 从一个 现场故事讲起。
现场事故:凌晨2点,报警群突然炸了
凌晨2点,报警群突然炸了——某核心业务库CPU飙到98%,交易系统响应延迟突破10秒。 我顶着黑眼圈打开AWR报告,发现一条"神秘SQL"正以每秒200次的频率疯狂吞噬着IO资源。
CPU已经飙升到了400%了,数据库服务器基本已经卡死。
我用三大神器(explain、OPTIMIZER_TRACE、PROFILE)一通分析,发现 这一个 SQL性能极差,Using temporary、Using filesort、Using join buffer、Block Nested Loop全出来了。
然后,花了我一天的时间,彻底把问题解决。
并且,把我的绝招整理成了下面的问题,也结合他们团队学习使用,给出了优化的目标建议:SQL中不要出现Using filesort、Block Nested Loop,尽量不要出现Using join buffer和Using temporary,把Using where尽量优化到Using Index级别。
慢查询日志
MySQL的慢查询日志是MySQL提供的一种日志记录。
MySQL的慢查询日志 ,主要 用来记录在MySQL中响应的时间超过 执行时长阈值的语句, 执行时长阈值 通过 一个 参数 long_query_time(默认是10秒)配置。
一个SQL的执行,只要 超过 这个 long_query_time 时长, 就会被判为慢查询, 会被记录到慢查询日志中。
慢查询日志的作用: 一般用于性能分析时开启,收集慢SQL, 然后通过explain进行全面分析。
尼恩提示:收集慢查询语句是十分耗性能的.
一般来说,生产是不会开启的,但是在测试环境是可以开启的,用户模拟分析的 执行计划,优化SQL语句
下面是一些关键参数设置:
- slow_query_log:控制慢查询日志的开关。设置成 1,日志就开启;设置成 0,日志就关闭。
- log-slow-queries(旧版本 5.6 以下使用)和slow-query-log-file(5.6 及以上版本使用):这两个参数用来指定慢查询日志的保存位置。如果不设置,系统会自动生成一个默认文件,名字是 “主机名 - slow.log”。
- long_query_time:慢查询阈值:它决定了什么样的查询算慢查询,只要 SQL 语句执行时间超过这里设置的时长,就会被记录到日志里。
- log_queries_not_using_indexes:这是个可选参数,打开后,没命中索引的查询语句也会被记录下来。
- log_output:用来选择日志保存方式。有 FILE(快) , TABLE(满) 两种方式保持日志。设置成FILE,日志就存到文件里,这是默认方式;设置成 TABLE,日志会存到数据库的mysql.slow_log表里。也可以同时用两种方式,写成FILE,TABLE。不过,存到数据库表比存到文件更费资源,如果既想开慢查询日志,又想数据库跑得快,建议优先把日志存到文件里。
慢查询相关参数设置与查看
slow_query_log 的 参数查看:
mysql> show VARIABLES like '%slow_query_log%';
+---------------------+-----------------------------------------------------------+
| Variable_name | Value |
+---------------------+-----------------------------------------------------------+
| slow_query_log | OFF |
| slow_query_log_file | d:\java\mysql-5.7.28-winx64\data\DEEP-2020AEBKQR-slow.log |
+---------------------+-----------------------------------------------------------+
2 rows in set, 1 warning (0.00 sec)
long_query_time 的 参数查看:
mysql> show VARIABLES like 'long_query_time%';
+-----------------+-----------+
| Variable_name | Value |
+-----------------+-----------+
| long_query_time | 10.000000 |
+-----------------+-----------+
1 row in set, 1 warning (0.00 sec)
设置启用慢查询日志:
SET GLOBAL slow_query_log = 'ON';
SET GLOBAL long_query_time = 1;
注意:修改全局参数后,当前连接会话仍使用旧值,需新建会话才会生效,需要重新登录
查看修改后参数:
mysql> show VARIABLES like '%slow_query_log%';
+---------------------+-----------------------------------------------------------+
| Variable_name | Value |
+---------------------+-----------------------------------------------------------+
| slow_query_log | ON |
| slow_query_log_file | d:\java\mysql-5.7.28-winx64\data\DEEP-2020AEBKQR-slow.log |
+---------------------+-----------------------------------------------------------+
2 rows in set, 1 warning (0.00 sec)
mysql> show VARIABLES like 'long_query_time%';
+-----------------+----------+
| Variable_name | Value |
+-----------------+----------+
| long_query_time | 1.000000 |
+-----------------+----------+
1 row in set, 1 warning (0.00 sec)
慢sql 模拟,并查看 慢查询日志
下面的代码, 模拟正常sql 1,执行时长=0.5s
mysql> select sleep(0.5);
+------------+
| sleep(0.5) |
+------------+
| 0 |
+------------+
1 row in set (0.50 sec)
模拟慢sql 2 ,执行时长=5s
mysql> select sleep(5);
+----------+
| sleep(5) |
+----------+
| 0 |
+----------+
1 row in set (5.00 sec)
查看慢sql数量
mysql> SHOW GLOBAL STATUS LIKE '%slow_queries%';
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| Slow_queries | 1 |
+---------------+-------+
1 row in set (0.00 sec)
DEEP-2020AEBKQR-slow.log 的 新的慢sql日志
Time Id Command Argument
// Time: 2025-05-11T10:33:05.581135Z
// User@Host: root[root] @ localhost [::1] Id: 10
// Query_time: 5.002170 Lock_time: 0.000000 Rows_sent: 1 Rows_examined: 0
SET timestamp=1746959585;
select sleep(5);
上面日志解读如下:
- User@Host:表示用户和慢查询的连接地址(root 用户,localhost地址,Id为 9)
- Query_time:表示 SQL 查询的耗时,单位为秒。Lock_time:表示获取锁的时间,单位为秒。Rows_sent:表示发送给客户端的行数。Rows_examined:表示服务器层检查的行数
- SET timestamp:表示慢 SQL 记录时的时间戳
- select sleep(5);:最后一行表示慢查询 SQL 语句
MySQLdumpslow 慢查询日志分析工具基本用法:
-- 比如,得到返回记录集最多的10个SQL
MySQLdumpslow -s r -t 10 /database/MySQL/MySQL06_slow.log
-- 得到访问次数最多的10个SQL
MySQLdumpslow -s c -t 10 /database/MySQL/MySQL06_slow.log
-- 得到按照时间排序的前10条里面含有左连接的查询语句
MySQLdumpslow -s t -t 10 -g “left join” /database/MySQL/MySQL06_slow.log
-- 另外建议在使用这些命令时结合 | 和more 使用 ,否则有可能出现刷屏的情况
MySQLdumpslow -s r -t 20 /MySQLdata/MySQL/MySQL06-slow.log | more
慢查询分析工具
慢查询分析一般分为三个步骤
1、 EXPLAIN
2、 OPTIMIZER_TRACE
3、 PROFILE
案例分析
下面对深度分页场景,产生的慢查询案例,进行分析,案例如下:
这是一个深度分页的案例, 7百万 数据 深度分页。具体 的案例如下:
mysql> select * from store.my_order order by id limit 100,1;
+-----+-------------+------------+----------+-------------+--------------+---------------------+
| id | customer_id | product_id | quantity | total_price | order_status | created_at |
+-----+-------------+------------+----------+-------------+--------------+---------------------+
| 101 | 630708 | 101 | 1 | 22 | 3 | 2023-08-25 17:24:50 |
+-----+-------------+------------+----------+-------------+--------------+---------------------+
1 row in set (0.00 sec)
mysql> select * from store.my_order order by id limit 7000000,1;
+---------+-------------+------------+----------+-------------+--------------+---------------------+
| id | customer_id | product_id | quantity | total_price | order_status | created_at |
+---------+-------------+------------+----------+-------------+--------------+---------------------+
| 7000001 | 765891 | 1 | 9 | 666 | 0 | 2023-08-25 17:25:43 |
+---------+-------------+------------+----------+-------------+--------------+---------------------+
1 row in set (1.88 sec)
这一个深度分页的案例的结果是1.88 sec, 比普通分页 性能差距 有 200倍之多。
那如何对这个慢查询场景进行分析呢?
第一步 EXPLAIN
最先登场的毫无疑问就是 EXPLAIN 语句了,这个查看 SQL 语句执行计划的命令,是最为基础的命令。
一般来说,95% 的慢查询问题只需要 EXPLAIN 就可以解决了
EXPLAIN 语句 的输出,主要观察 两个列:
- 在 Extra 列里面,避免出现
Use Temporary Table和Using file sort这类关键字, - 在 TYPE 列中也尽量避免 ALL 类型(全表扫描)出现。
EXPLAIN 的 主要 参数 (或者列)的说明,参考下图:

虽然EXPLAIN能分析出95%以上的慢查询,但是凑巧,咱们这个不能明确分析出来 根本差别。
mysql> explain select * from my_order order by id limit 100,1;
+----+-------------+----------+------------+-------+---------------+---------+---------+------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+----------+------------+-------+---------------+---------+---------+------+------+----------+-------+
| 1 | SIMPLE | my_order | NULL | index | NULL | PRIMARY | 4 | NULL | 101 | 100.00 | NULL |
+----+-------------+----------+------------+-------+---------------+---------+---------+------+------+----------+-------+
1 row in set, 1 warning (0.00 sec)
mysql> explain select * from my_order order by id limit 7000000,1;
+----+-------------+----------+------------+-------+---------------+---------+---------+------+---------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+----------+------------+-------+---------------+---------+---------+------+---------+----------+-------+
| 1 | SIMPLE | my_order | NULL | index | NULL | PRIMARY | 4 | NULL | 7000001 | 100.00 | NULL |
+----+-------------+----------+------------+-------+---------------+---------+---------+------+---------+----------+-------+
1 row in set, 1 warning (0.00 sec)
这两个结果差不多。
接下来, 用OPTIMIZER_TRACE。
第二步 OPTIMIZER_TRACE
有了EXPLAIN,为什么还用OPTIMIZER_TRACE呢?
EXPLAIN 分析 mysql怎么做,而OPTIMIZER_TRACE 分析 mysql为什么这么做。
EXPLAIN 适用于 快速定位执行计划异常,而 OPTIMIZER_TRACE 用于 深度 解析 sql 优化器 是什么决策逻辑,两者结合可形成完整的 SQL 调优闭环。
尼恩提示:这里提到了 sql 优化器,大家一定要理解 一条sql 执行过程是什么,了解 mysql内部有哪些组件,这些都是基础知识啦。
具体请参加下面的文章:
京东面试:一条sql 执行过程是什么?分析 SQL的解析和优化的原理?
Optimizer Trace 主要分析 优化器做出的各种决策(比如访问表的方式、各种开销计算、各种转换等),并将跟踪结果记录到INFORMATION_SCHEMA.OPTIMIZER_TRACE表中。
对性能要求苛刻的场景, EXPLAIN 和 OPTIMIZER_TRACE 如何结合使用呢?
- 建议优先使用EXPLAIN 筛选问题
- 再通过 OPTIMIZER_TRACE 精准定位根因
OPTIMIZER_TRACE基本用法
这里,用另一个 案例说明下如何使用OPTIMIZER_TRACE。
这个案例 的详情,请参考尼恩团队上一篇文章:京东面试:mysql深度分页 严重影响性能?根本原因是什么?如何优化?
尼恩团队上一篇文章 ,主要讲的 是深度分页原理和调优,其实也是一个慢sql查询。
首先, 用 EXPLAIN 筛查问题,以 上一篇文章的 深度分页的案例,
mysql> explain SELECT * FROM my_customer where name like 'c%' limit 1000000,1;
+----+-------------+-------------+------------+------+----------------------+------+---------+------+--------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------------+------------+------+----------------------+------+---------+------+--------+----------+-------------+
| 1 | SIMPLE | my_customer | NULL | ALL | my_customer_name_IDX | NULL | NULL | NULL | 995164 | 50.00 | Using where |
+----+-------------+-------------+------------+------+----------------------+------+---------+------+--------+----------+-------------+
上一篇文章的案例中, name字段虽然有普通索引,但是还是看到走的是全表扫描 type = ALL,为什么呢?
尼恩先说结论: 因为回表次数太多的原因,mysql优化器认为走索引的成本,还不如全表扫描, 所以就干脆优化为 全表扫描。
那如何使用OPTIMIZER_TRACE分析优化器如何做出的决策呢?
1、 开启/关闭,OPTIMIZER_TRACE
//开启
SET optimizer_trace="enabled=on";
//关闭
SET optimizer_trace="enabled=off";
2、 执行sql语句
SELECT * FROM my_customer where name like 'c%' limit 1000000,1;
3、 查看OPTIMIZER_TRACE结果
mysql> SELECT * FROM information_schema.OPTIMIZER_TRACE;
*************************** 1. row ***************************
QUERY: SELECT * FROM my_customer where name like 'c%' limit 1000000,1
TRACE: {
"steps": [
{
...省略部分内容
"rows_estimation": [
{
"table": "`my_customer`",
"range_analysis": {
"table_scan": {
"rows": 995164,
"cost": 203809
},
...省略部分内容
"analyzing_range_alternatives": {
"range_scan_alternatives": [
{
"index": "my_customer_name_IDX",
"ranges": [
"c\u0000\u0000\u0000\u0000\u0000\u0000\u0000\u0000\u0000\u0000\u0000\u0000\u0000\u0000\u0000\u0000\u0000\u0000\u0000\u0000\u0000\u0000\u0000\u0000\u0000\u0000\u0000\u0000\u0000\u0000\u0000\u0000\u0000\u0000\u0000\u0000\u0000\u0000\u0000\u0000\u0000\u0000\u0000\u0000\u0000\u0000\u0000\u0000\u0000\u0000\u0000\u0000\u0000\u0000\u0000\u0000\u0000\u0000\u0000\u0000\u0000\u0000\u0000\u0000\u0000\u0000\u0000\u0000\u0000\u0000\u0000\u0000\u0000\u0000\u0000\u0000\u0000\u0000\u0000\u0000\u0000\u0000\u0000\u0000\u0000\u0000\u0000\u0000\u0000\u0000\u0000\u0000\u0000\u0000\u0000\u0000\u0000\u0000\u0000 <= name <= c"
],
"index_dives_for_eq_ranges": true,
"rowid_ordered": false,
"using_mrr": false,
"index_only": false,
"rows": 497582,
"cost": 597099,
"chosen": false,
"cause": "cost"
}
],
...省略部分内容
"considered_execution_plans": [
{
"plan_prefix": [
],
"table": "`my_customer`",
"best_access_path": {
"considered_access_paths": [
{
"rows_to_scan": 995164,
"access_type": "scan",
"resulting_rows": 995164,
"cost": 203807,
"chosen": true
}
]
},
...省略部分内容
}
4、 结果分析
结果中,几个关键点解释MySQL为什么选择了全表扫描而不是索引扫描。
(1)、 rows_estimation 部分:
首先,在rows_estimation下的range_analysis里,有一个关于table_scan的评估,指出进行全表扫描需要读取995,164行数据,成本为(203,809)。
接着在potential_range_indexes中分析了可能使用的索引。
其中只有my_customer_name_IDX是可以用的,但, 即使使用这个索引,预估的行数是497,582(大约一半的数据),而其成本是 ( 597,099)。
尽管 索引扫描的行数( 497,582 ),少于全表扫描 (995,164 ),但是由于成本更高 ( 597,099) ,因此,索引扫描 未被选中。
(2)、 considered_execution_plans部分:
在这里,MySQL考虑了不同的执行计划,并最终选择了对my_customer表进行访问的最佳路径。
最佳访问路径显示,虽然它确实考虑了使用索引my_customer_name_IDX,但由于成本问题(cost: 597,099 vs cost: 203,807),最终还是选择了全表扫描(access_type: scan)。
综上所述,MySQL优化器决定进行全表扫描的主要原因是基于成本估算的结果。
尽管索引my_customer_name_IDX能够减少需要扫描的行数,但由于某些原因(推断因为回表原因),MySQL认为全表扫描是更有效的策略。
这通常发生在索引对于特定查询的选择性不足时,即使用索引并不能显著减少需要检查的数据量或计算的成本。
再来一个 OPTIMIZER_TRACE案例分析
继续使用这个工具分析上面的深度分页案例:
分别执行下面,
mysql> select * from my_order order by id limit 100,1;
mysql> select * from my_order order by id limit 7000000,1;
查看OPTIMIZER_TRACE结果,这一次,却看不到任何区别
mysql> SELECT * FROM information_schema.OPTIMIZER_TRACE;
所以,还需要第三步 PROFILE 性能分析
第三步 PROFILE
MySQL 的 PROFILE(性能分析)是一种用于分析 SQL 查询执行过程中资源消耗的工具。
它能够记录查询执行的各个阶段(如初始化、打开表、锁定、排序等)的耗时和资源使用情况(如 CPU、内存、I/O),帮助开发者定位性能瓶颈。
PROFILE 基本功能如下:
- 显示查询执行过程中每个阶段的时间消耗。
- 提供资源使用情况(如 CPU、内存、I/O)。
- 帮助识别查询的性能瓶颈(如全表扫描、临时表创建、排序等)。
1、 开启 PROFILING
默认情况下,profiling 是关闭的。
需要手动启用:
set session profiling = 1;
在实际的生产环境中,可能会需要加大profile的队列,保证想要查看的 PROFILE 结果还保存着,因此可以用如下操作来增加 PROFILE 的队列大小
set session profiling_history_size = 50;
2、 执行待分析的 SQL 查询
执行需要分析的 SQL 语句,例如:
select * from my_order order by id limit 100,1;
select * from store.my_order order by id limit 7000000,1;
3、 查看所有查询的概览
SHOW PROFILES; -- 显示所有已分析的查询
输出结果:
mysql> show profiles;
+----------+------------+----------------------------------------------------------+
| Query_ID | Duration | Query |
+----------+------------+----------------------------------------------------------+
| 1 | 0.00010200 | set session profiling_history_size = 50 |
| 2 | 0.00012500 | select * from my_order order by id limit 100,1 |
| 3 | 0.00145300 | select * from store.my_order order by id limit 100,1 |
| 4 | 2.86402600 | select * from store.my_order order by id limit 7000000,1 |
+----------+------------+----------------------------------------------------------+
4 rows in set, 1 warning (0.00 sec)
Query_ID:查询的唯一标识。Duration:查询总耗时(单位:秒)。
4、 查看具体查询的详细分析
通过 SHOW PROFILE 分析指定 Query_ID 的详细耗时和资源消耗:
SHOW PROFILE FOR QUERY 3; -- 查询 Query_ID=3 的详细信息
SHOW PROFILE FOR QUERY 4; -- 查询 Query_ID=4 的详细信息
输出结果:
mysql> show profile block io,cpu,memory,source for query 3;
+----------------------+----------+----------+------------+--------------+---------------+----------------------------+----------------------+-------------+
| Status | Duration | CPU_user | CPU_system | Block_ops_in | Block_ops_out | Source_function | Source_file | Source_line |
+----------------------+----------+----------+------------+--------------+---------------+----------------------------+----------------------+-------------+
| starting | 0.000054 | 0.000000 | 0.000000 | NULL | NULL | NULL | NULL | NULL |
| checking permissions | 0.000003 | 0.000000 | 0.000000 | NULL | NULL | check_access | sql_authorization.cc | 809 |
| Opening tables | 0.001221 | 0.000000 | 0.000000 | NULL | NULL | open_tables | sql_base.cc | 5753 |
| init | 0.000012 | 0.000000 | 0.000000 | NULL | NULL | handle_query | sql_select.cc | 128 |
| System lock | 0.000013 | 0.000000 | 0.000000 | NULL | NULL | mysql_lock_tables | lock.cc | 330 |
| optimizing | 0.000003 | 0.000000 | 0.000000 | NULL | NULL | JOIN::optimize | sql_optimizer.cc | 158 |
| statistics | 0.000008 | 0.000000 | 0.000000 | NULL | NULL | JOIN::optimize | sql_optimizer.cc | 374 |
| preparing | 0.000007 | 0.000000 | 0.000000 | NULL | NULL | JOIN::optimize | sql_optimizer.cc | 482 |
| Sorting result | 0.000005 | 0.000000 | 0.000000 | NULL | NULL | JOIN::make_tmp_tables_info | sql_select.cc | 3849 |
| executing | 0.000001 | 0.000000 | 0.000000 | NULL | NULL | JOIN::exec | sql_executor.cc | 126 |
| Sending data | 0.000061 | 0.000000 | 0.000000 | NULL | NULL | JOIN::exec | sql_executor.cc | 202 |
| end | 0.000002 | 0.000000 | 0.000000 | NULL | NULL | handle_query | sql_select.cc | 206 |
| query end | 0.000005 | 0.000000 | 0.000000 | NULL | NULL | mysql_execute_command | sql_parse.cc | 4956 |
| closing tables | 0.000003 | 0.000000 | 0.000000 | NULL | NULL | mysql_execute_command | sql_parse.cc | 5009 |
| freeing items | 0.000051 | 0.000000 | 0.000000 | NULL | NULL | mysql_parse | sql_parse.cc | 5622 |
| cleaning up | 0.000007 | 0.000000 | 0.000000 | NULL | NULL | dispatch_command | sql_parse.cc | 1931 |
+----------------------+----------+----------+------------+--------------+---------------+----------------------------+----------------------+-------------+
16 rows in set, 1 warning (0.00 sec)
mysql> show profile block io,cpu,memory,source for query 4;
+----------------------+----------+----------+------------+--------------+---------------+----------------------------+----------------------+-------------+
| Status | Duration | CPU_user | CPU_system | Block_ops_in | Block_ops_out | Source_function | Source_file | Source_line |
+----------------------+----------+----------+------------+--------------+---------------+----------------------------+----------------------+-------------+
| starting | 0.000169 | 0.000000 | 0.000000 | NULL | NULL | NULL | NULL | NULL |
| checking permissions | 0.000003 | 0.000000 | 0.000000 | NULL | NULL | check_access | sql_authorization.cc | 809 |
| Opening tables | 0.000009 | 0.000000 | 0.000000 | NULL | NULL | open_tables | sql_base.cc | 5753 |
| init | 0.000011 | 0.000000 | 0.000000 | NULL | NULL | handle_query | sql_select.cc | 128 |
| System lock | 0.000004 | 0.000000 | 0.000000 | NULL | NULL | mysql_lock_tables | lock.cc | 330 |
| optimizing | 0.000003 | 0.000000 | 0.000000 | NULL | NULL | JOIN::optimize | sql_optimizer.cc | 158 |
| statistics | 0.000021 | 0.000000 | 0.000000 | NULL | NULL | JOIN::optimize | sql_optimizer.cc | 374 |
| preparing | 0.000006 | 0.000000 | 0.000000 | NULL | NULL | JOIN::optimize | sql_optimizer.cc | 482 |
| Sorting result | 0.000001 | 0.000000 | 0.000000 | NULL | NULL | JOIN::make_tmp_tables_info | sql_select.cc | 3849 |
| executing | 0.000001 | 0.000000 | 0.000000 | NULL | NULL | JOIN::exec | sql_executor.cc | 126 |
| Sending data | 2.863684 | 1.437500 | 0.171875 | NULL | NULL | JOIN::exec | sql_executor.cc | 202 |
| end | 0.000007 | 0.000000 | 0.000000 | NULL | NULL | handle_query | sql_select.cc | 206 |
| query end | 0.000006 | 0.000000 | 0.000000 | NULL | NULL | mysql_execute_command | sql_parse.cc | 4956 |
| closing tables | 0.000006 | 0.000000 | 0.000000 | NULL | NULL | mysql_execute_command | sql_parse.cc | 5009 |
| freeing items | 0.000091 | 0.000000 | 0.000000 | NULL | NULL | mysql_parse | sql_parse.cc | 5622 |
| cleaning up | 0.000007 | 0.000000 | 0.000000 | NULL | NULL | dispatch_command | sql_parse.cc | 1931 |
+----------------------+----------+----------+------------+--------------+---------------+----------------------------+----------------------+-------------+
16 rows in set, 1 warning (0.00 sec)
关键阶段:
Creating tmp table:创建临时表(可能是性能瓶颈)。Sorting result:排序耗时。Sending data:数据传输时间。
通过对比两个查询的性能分析结果,可以发现以下关键区别:
1、 查询总耗时差异显著
-
查询 3的总耗时极短(约 0.00146 秒),各阶段耗时分布较为均匀。
-
查询 4的总耗时长达 2.8639 秒,其中绝大部分时间(2.863684 秒)集中在
Sending data状态。
2、 Sending data 状态的巨大差异
-
查询 3的
Sending data仅耗时 0.000061 秒,CPU 资源消耗为零。 -
查询 4的
Sending data耗时占比超过 99.9%,且消耗了 1.4375 秒 的用户 CPU 时间和 0.171875 秒 的系统 CPU 时间。这表明查询 4 在数据传输或结果处理阶段存在严重性能瓶颈。
3、Opening tables 阶段的差异
-
查询 3在此阶段耗时 0.001221 秒,可能涉及表结构加载或缓存未命中。
-
查询 4仅耗时 0.000009 秒,推测表已被缓存或查询复杂度较低。
4、 统计信息收集阶段(statistics)
- 查询 4的
statistics阶段耗时 0.000021 秒,略高于查询 3 的 0.000008 秒,可能表明查询 4 涉及更多表或索引统计信息的收集。
5、可能的原因与优化建议
查询 4 的瓶颈分析:Sending data阶段长时间运行
Sending data阶段长时间运行 通常意味着:
-
结果集过大:查询返回大量数据,导致网络传输或客户端处理缓慢。
-
缺少索引:全表扫描或排序操作消耗大量 CPU 资源。
-
临时表或文件排序:查询执行过程中生成了大型临时表。
-
建议优化查询条件、添加适当索引、分页处理结果集或限制返回行数。
通过对比可知,查询 4 的性能问题主要集中在数据处理和传输阶段,需重点优化查询逻辑或数据库结构。
5、 关闭 PROFILING
分析完成后,关闭性能分析以避免不必要的资源占用:
SET profiling = 0;
6、 分析结果
案例分析结果:虽然都只输出一行结果,但是在 Sending data 阶段花费的时间差别很大,其实就是花在扫描 700 万行数据上去了
通过 SHOW PROFILE 的输出,可以识别以下常见问题:
| 阶段 | 问题描述 |
|---|---|
Creating tmp table | 查询需要创建临时表(可能是排序或分组操作导致)。 |
Copying to tmp table | 临时表过大,需从内存复制到磁盘(性能严重下降)。 |
Filesort | 未使用索引导致排序操作(需优化索引或调整查询)。 |
Full scan on NULL key | 未使用索引进行全表扫描(需添加合适索引)。 |
Sending data | 数据量过大或网络延迟(需优化查询字段或分页)。 |
11 种常见 慢查询 场景分析 + 原因分析
场景一:SQL 没加索引
很多时候,的慢查询,都是因为没有加索引。
如果没有加索引的话,会导致全表扫描的。
因此,应考虑在 where 的条件列,建立索引,尽量避免全表扫描。
下面是一反例:address 没有索引,全表扫描
mysql> explain select * from my_customer where address='技术自由圈';
+----+-------------+-------------+------------+------+---------------+------+---------+------+--------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------------+------------+------+---------------+------+---------+------+--------+----------+-------------+
| 1 | SIMPLE | my_customer | NULL | ALL | NULL | NULL | NULL | NULL | 995164 | 10.00 | Using where |
+----+-------------+-------------+------------+------+---------------+------+---------+------+--------+----------+-------------+
1 row in set, 1 warning (0.00 sec)
上面反例中: type= ALL ,表示 全表扫描
下面是一正例:name字段有索引,索引扫描
mysql> explain select * from my_customer where name='技术自由圈';
+----+-------------+-------------+------------+------+----------------------+----------------------+---------+-------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------------+------------+------+----------------------+----------------------+---------+-------+------+----------+-------+
| 1 | SIMPLE | my_customer | NULL | ref | my_customer_name_IDX | my_customer_name_IDX | 402 | const | 1 | 100.00 | NULL |
+----+-------------+-------------+------------+------+----------------------+----------------------+---------+-------+------+----------+-------+
1 row in set, 1 warning (0.00 sec)
上面正例中: type= ref,key = my_customer_name_IDX , 表示 索引扫描
场景二:SQL 索引不生效
有时候明明加了索引了,但是索引却不生效。在哪些场景,索引会不生效呢?
主要有以下 SQL 索引不生效 十大经典场景:
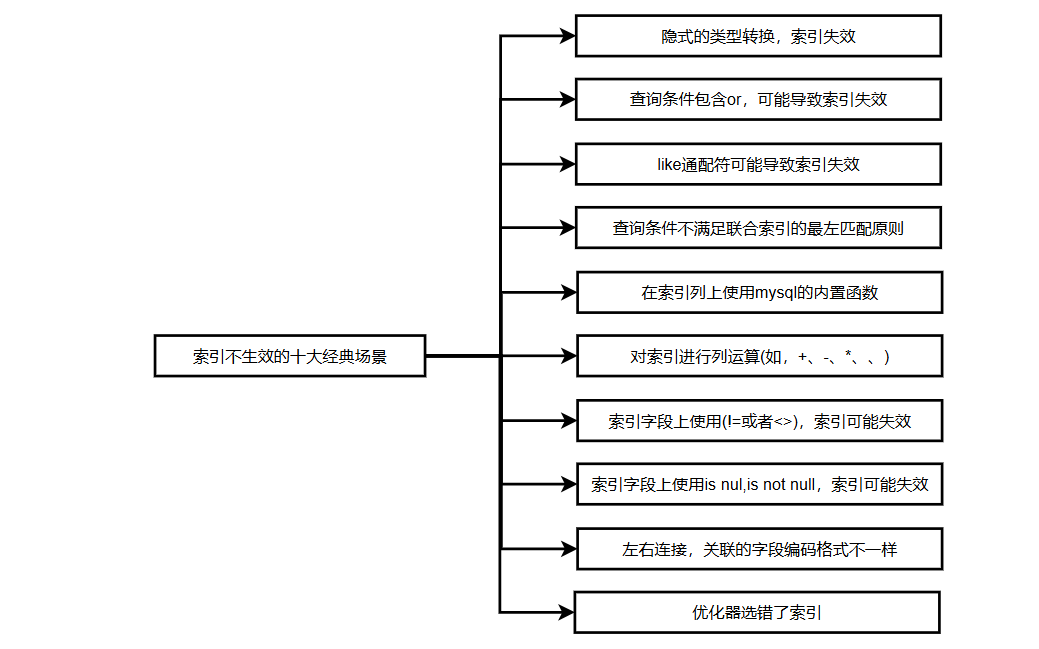
索引失效详细分析参考:美团面试:mysql 索引失效?怎么解决? (重点知识,建议收藏,读10遍+)
不生效1:隐式的类型转换,索引失效
name 字段为字串类型,是 B + 树的普通索引,如果查询条件传了一个数字过去,会导致索引失效。
如下:
mysql> explain select * from my_customer where name = 123;
+----+-------------+-------------+------------+------+----------------------+------+---------+------+--------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------------+------------+------+----------------------+------+---------+------+--------+----------+-------------+
| 1 | SIMPLE | my_customer | NULL | ALL | my_customer_name_IDX | NULL | NULL | NULL | 995164 | 10.00 | Using where |
+----+-------------+-------------+------------+------+----------------------+------+---------+------+--------+----------+-------------+
1 row in set, 3 warnings (0.00 sec)
如果给数字加上’', 也就是说,传的是一个字符串呢,当然是走索引,如下:
mysql> explain select * from my_customer where name = '123';
+----+-------------+-------------+------------+------+----------------------+----------------------+---------+-------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------------+------------+------+----------------------+----------------------+---------+-------+------+----------+-------+
| 1 | SIMPLE | my_customer | NULL | ref | my_customer_name_IDX | my_customer_name_IDX | 402 | const | 1 | 100.00 | NULL |
+----+-------------+-------------+------------+------+----------------------+----------------------+---------+-------+------+----------+-------+
1 row in set, 1 warning (0.00 sec)
为什么第一条语句未加单引号就不走索引了呢?
这是因为不加单引号时,是字符串跟数字的比较,它们类型不匹配,MySQL 会做隐式的类型转换,把它们转换为浮点数再做比较。隐式的类型转换,索引会失效。
不生效2:查询条件包含 or,可能导致索引失效
还是用这个表结构,其中 name 加了索引,但是 address 没有加索引的。
使用了 or,以下 SQL 是不走索引的,如下:
mysql> explain select * from my_customer where name = '123' or address='abc';
+----+-------------+-------------+------------+------+----------------------+------+---------+------+--------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------------+------------+------+----------------------+------+---------+------+--------+----------+-------------+
| 1 | SIMPLE | my_customer | NULL | ALL | my_customer_name_IDX | NULL | NULL | NULL | 995164 | 19.00 | Using where |
+----+-------------+-------------+------------+------+----------------------+------+---------+------+--------+----------+-------------+
1 row in set, 1 warning (0.00 sec)
对于 or 没有索引的 address 这种情况,假设它走了 name 的索引,但是走到 address 查询条件时,它还得全表扫描,也就是需要三步过程:全表扫描 + 索引扫描 + 合并。
如果它一开始就走全表扫描,直接一遍扫描就完事。
Mysql 优化器出于效率与成本考虑,遇到 or 条件,让索引失效,看起来也合情合理嘛。
注意:如果 所有的or 条件 列都加了索引,索引可能会走,也可能不走,大家可以自己试一试哈。
但是平时大家使用的时候,还是要注意一下这个 or,学会用 explain 分析。遇到不走索引的时候,考虑拆开两条 SQL。
不生效3:不符合前缀匹配原则
并不是用了 like 通配符,索引一定会失效,而是 like 查询是以 % 开头,才会导致索引失效。
like 查询以 % 开头,索引失效
mysql> explain select * from my_customer where name like '%123';
+----+-------------+-------------+------------+------+---------------+------+---------+------+--------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------------+------------+------+---------------+------+---------+------+--------+----------+-------------+
| 1 | SIMPLE | my_customer | NULL | ALL | NULL | NULL | NULL | NULL | 995164 | 11.11 | Using where |
+----+-------------+-------------+------------+------+---------------+------+---------+------+--------+----------+-------------+
1 row in set, 1 warning (0.00 sec)
把 % 放后面,发现索引还是正常走的,如下:
mysql> explain select * from my_customer where name like '123%';
+----+-------------+-------------+------------+-------+----------------------+----------------------+---------+------+------+----------+-----------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------------+------------+-------+----------------------+----------------------+---------+------+------+----------+-----------------------+
| 1 | SIMPLE | my_customer | NULL | range | my_customer_name_IDX | my_customer_name_IDX | 402 | NULL | 1 | 100.00 | Using index condition |
+----+-------------+-------------+------------+-------+----------------------+----------------------+---------+------+------+----------+-----------------------+
1 row in set, 1 warning (0.00 sec)
既然 like 查询以 % 开头,会导致索引失效。如何优化呢?
- 使用覆盖索引
- 把 % 放后面
前缀原则详细分析参考:
美团面试:mysql 索引失效?怎么解决? (重点知识,建议收藏,读10遍+)
不生效4:查询条件不满足联合索引的最左匹配原则
最左匹配原则详细分析参考:
美团面试:mysql 索引失效?怎么解决? (重点知识,建议收藏,读10遍+)
假设存在联合索引(a,b,c),注意顺序
MySQl 建立联合索引时,会遵循最左前缀匹配的原则,即最左优先。如果你建立一个(a,b,c)的联合索引,相当于建立了 (a)、(a,b)、(a,b,c) 三个索引。
有一个联合索引 (a,b,c),执行这个 SQL,查询条件是 b=‘b’ and c = ‘c’,索引是无效:
因为没有a字段,破坏了最左匹配原则
mysql> EXPLAIN SELECT * FROM my_customer2 WHERE b='b' AND c='c';
+----+-------------+--------------+------------+------+---------------+------+---------+------+--------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+--------------+------------+------+---------------+------+---------+------+--------+----------+-------------+
| 1 | SIMPLE | my_customer2 | NULL | ALL | NULL | NULL | NULL | NULL | 993114 | 1.00 | Using where |
+----+-------------+--------------+------------+------+---------------+------+---------+------+--------+----------+-------------+
1 row in set, 1 warning (0.00 sec)
在联合索引中,查询条件满足最左匹配原则时,索引才正常生效。
mysql> EXPLAIN SELECT a,b,c FROM my_customer2 WHERE a='a' and b='b' AND c='c';
+----+-------------+--------------+------------+------+---------------------+---------------------+---------+-------------------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+--------------+------------+------+---------------------+---------------------+---------+-------------------+------+----------+-------------+
| 1 | SIMPLE | my_customer2 | NULL | ref | my_customer_abc_IDX | my_customer_abc_IDX | 1206 | const,const,const | 1 | 100.00 | Using index |
+----+-------------+--------------+------------+------+---------------------+---------------------+---------+-------------------+------+----------+-------------+
1 row in set, 1 warning (0.00 sec)
不生效5:在索引列上使用 mysql 的内置函数
虽然 name 加了索引,但是因为使用了 mysql 的内置函数 索引失效
mysql> EXPLAIN SELECT a,b,c FROM my_customer2 WHERE substring(name, 3)='abc';
+----+-------------+--------------+------------+------+---------------+------+---------+------+--------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+--------------+------------+------+---------------+------+---------+------+--------+----------+-------------+
| 1 | SIMPLE | my_customer2 | NULL | ALL | NULL | NULL | NULL | NULL | 993114 | 100.00 | Using where |
+----+-------------+--------------+------------+------+---------------+------+---------+------+--------+----------+-------------+
1 row in set, 1 warning (0.00 sec)
一般这种情况怎么优化呢?可以从代码上进行优化,优化后语句如下:
-- 改写为以第三个字符为起点的固定前缀查询
SELECT a, b, c
FROM my_customer2
WHERE name LIKE '__abc%'; -- 前两字符任意,第三字符起为 'abc'
不生效6:对索引进行列运算(如,+、-、*、/), 索引不生效
虽然 age 加了索引,但是因为它进行运算,索引直接迷路了。。。:
mysql> EXPLAIN SELECT * from my_customer where age=10;
+----+-------------+-------------+------------+------+-----------------------+-----------------------+---------+-------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------------+------------+------+-----------------------+-----------------------+---------+-------+------+----------+-------+
| 1 | SIMPLE | my_customer | NULL | ref | my_customer_phone_IDX | my_customer_phone_IDX | 5 | const | 1 | 100.00 | NULL |
+----+-------------+-------------+------------+------+-----------------------+-----------------------+---------+-------+------+----------+-------+
1 row in set, 1 warning (0.00 sec)
mysql> EXPLAIN SELECT * from my_customer where age-1=10;
+----+-------------+-------------+------------+------+---------------+------+---------+------+--------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------------+------------+------+---------------+------+---------+------+--------+----------+-------------+
| 1 | SIMPLE | my_customer | NULL | ALL | NULL | NULL | NULL | NULL | 995164 | 100.00 | Using where |
+----+-------------+-------------+------------+------+---------------+------+---------+------+--------+----------+-------------+
1 row in set, 1 warning (0.00 sec)
所以不可以对索引列进行运算,可以在代码处理好,再传参进去。
不生效7:索引字段上使用(!= 或者 < >),索引可能失效
表结构:
虽然 age 加了索引,但是使用了!= 或者 < >,not in 这些时,索引如同虚设。如下:
mysql> EXPLAIN SELECT * from my_customer where age=10;
+----+-------------+-------------+------------+------+-----------------------+-----------------------+---------+-------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------------+------------+------+-----------------------+-----------------------+---------+-------+------+----------+-------+
| 1 | SIMPLE | my_customer | NULL | ref | my_customer_phone_IDX | my_customer_phone_IDX | 5 | const | 1 | 100.00 | NULL |
+----+-------------+-------------+------------+------+-----------------------+-----------------------+---------+-------+------+----------+-------+
1 row in set, 1 warning (0.00 sec)
mysql> EXPLAIN SELECT * from my_customer where age!=10;
+----+-------------+-------------+------------+------+-----------------------+------+---------+------+--------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------------+------------+------+-----------------------+------+---------+------+--------+----------+-------------+
| 1 | SIMPLE | my_customer | NULL | ALL | my_customer_phone_IDX | NULL | NULL | NULL | 995164 | 50.00 | Using where |
+----+-------------+-------------+------------+------+-----------------------+------+---------+------+--------+----------+-------------+
1 row in set, 1 warning (0.00 sec)
其实这个也是跟 mySQL优化器有关,如果优化器觉得即使走了索引,还是需要扫描很多很多行的哈,它觉得不划算,不如直接不走索引。
平时用!= 或者 < >,not in 的时候,要注意,最好从逻辑上避免
不生效8:索引字段上使用 is null, is not null,索引可能失效
单个 name 字段加上索引,并查询 name 为非空的语句,其实会走索引的,如下:
mysql> EXPLAIN SELECT * from my_customer where name is not null;
+----+-------------+-------------+------------+------+----------------------+------+---------+------+--------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------------+------------+------+----------------------+------+---------+------+--------+----------+-------------+
| 1 | SIMPLE | my_customer | NULL | ALL | my_customer_name_IDX | NULL | NULL | NULL | 995164 | 90.00 | Using where |
+----+-------------+-------------+------------+------+----------------------+------+---------+------+--------+----------+-------------+
1 row in set, 1 warning (0.00 sec)
很多时候,也是因为数据量问题,导致了 MySQL 优化器放弃走索引。
同时,平时用 explain 分析 SQL 的时候,如果 type=range, 要注意一下哈,因为这个可能因为数据量问题,可能导致索引无效。
不生效9:左右连接,关联的字段编码格式不一样
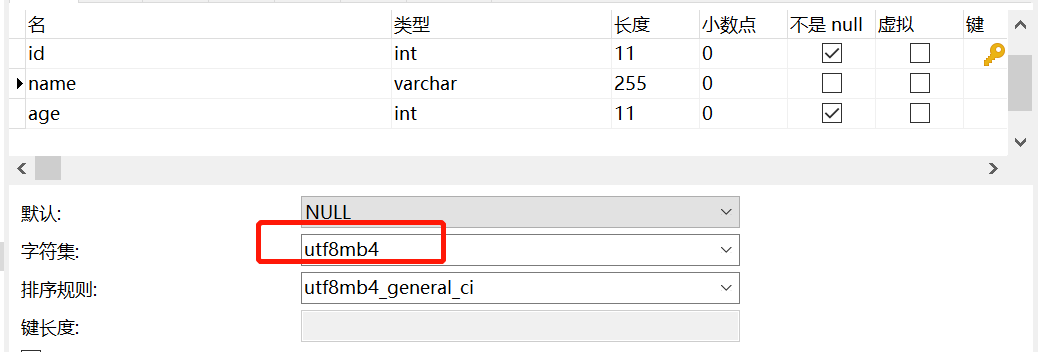
新建两个表,一个 user,一个 user_job
CREATE TABLE USER (
id INT(11) NOT NULL AUTO_INCREMENT,
NAME VARCHAR(255) CHARACTER SET utf8mb4 DEFAULT NULL,
age INT(11) NOT NULL,
PRIMARY KEY (id),
KEY idx_name (NAME) USING BTREE
) ENGINE = INNODB AUTO_INCREMENT = 2 DEFAULT CHARSET = utf8mb4;
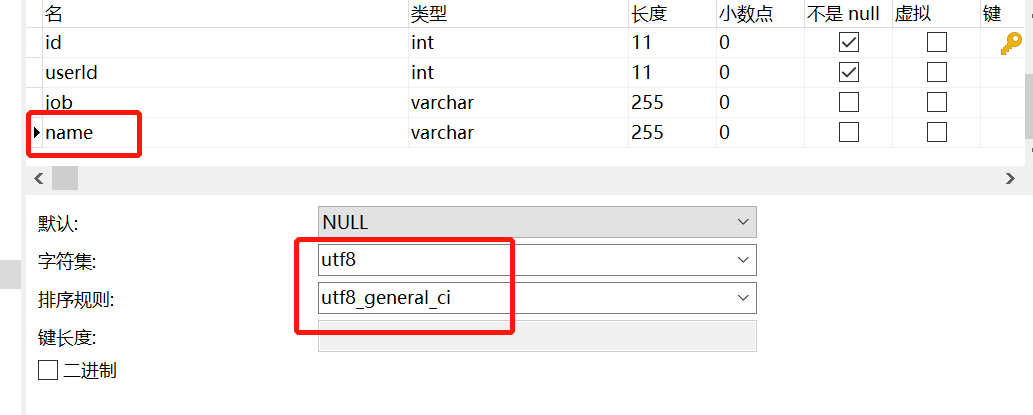
CREATE TABLE user_job (
id INT(11) NOT NULL,
userId INT(11) NOT NULL,
job VARCHAR(255) DEFAULT NULL,
NAME VARCHAR(255) DEFAULT NULL,
PRIMARY KEY (id),
KEY idx_name (NAME) USING BTREE
) ENGINE = INNODB DEFAULT CHARSET = utf8;
user 表的 name 字段编码是 utf8mb4,而 user_job 表的 name 字段编码为 utf8。
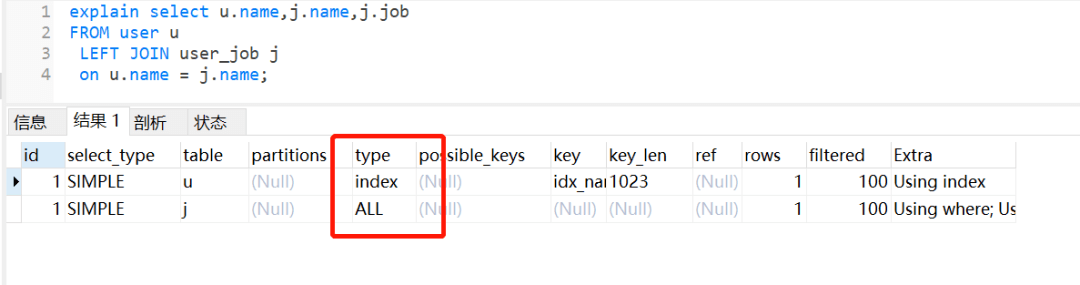
执行左外连接查询,user_job 表还是走全表扫描,如下:
如果把它们的 name 字段改为编码一致,相同的 SQL,还是会走索引。
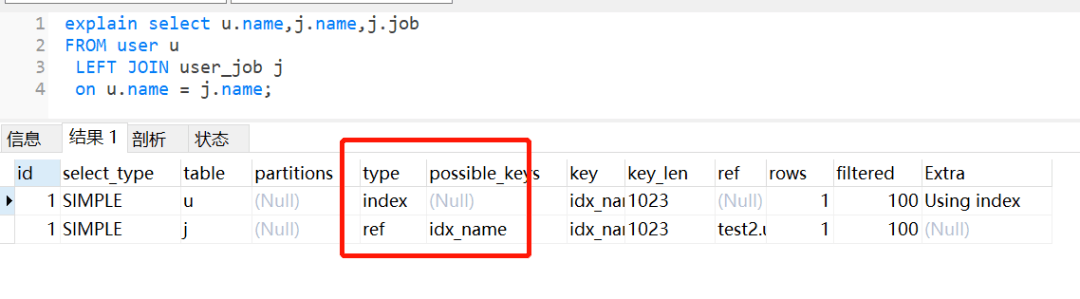
所以大家在做表关联时,注意一下关联字段的编码问题。
不生效10:优化器选错了索引
MySQL 中一张表是可以支持多个索引的。
写 SQL 语句的时候,如果 没有主动指定使用哪个索引的话,用哪个索引是由 MySQL 来确定的。
日常开发中,不断地删除历史数据和新增数据的场景,有可能会导致 MySQL 选错索引。
那么有哪些解决方案呢?
- 使用 force index 强行选择某个索引
- 修改 SQl,引导它使用期望的索引
- 优化业务逻辑
- 优化索引,新建一个更合适的索引,或者删除误用的索引。
场景三:limit 深分页问题
limit 深分页为什么会导致 SQL 变慢呢? 具体请参考 上一篇文章
京东面试:mysql深度分页 严重影响性能?根本原因是什么?如何优化?
分析下面的场景,存在name字段索引
mysql> EXPLAIN SELECT * FROM my_customer WHERE NAME LIKE 'c%' LIMIT 1000000, 10;
+----+-------------+-------------+------------+------+----------------------+------+---------+------+--------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------------+------------+------+----------------------+------+---------+------+--------+----------+-------------+
| 1 | SIMPLE | my_customer | NULL | ALL | my_customer_name_IDX | NULL | NULL | NULL | 995164 | 50.00 | Using where |
+----+-------------+-------------+------------+------+----------------------+------+---------+------+--------+----------+-------------+
1 row in set, 1 warning (0.00 sec)
mysql> EXPLAIN SELECT name FROM my_customer WHERE NAME LIKE 'c%' LIMIT 1000000, 10;
+----+-------------+-------------+------------+-------+----------------------+----------------------+---------+------+--------+----------+--------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------------+------------+-------+----------------------+----------------------+---------+------+--------+----------+--------------------------+
| 1 | SIMPLE | my_customer | NULL | range | my_customer_name_IDX | my_customer_name_IDX | 402 | NULL | 497582 | 100.00 | Using where; Using index |
+----+-------------+-------------+------------+-------+----------------------+----------------------+---------+------+--------+----------+--------------------------+
1 row in set, 1 warning (0.00 sec)
第一个 SQL( SELECT* limit ) 的执行流程:
1、 通过普通二级索引树 name,过滤 name 条件,找到满足条件的主键 id。
2、 通过主键id,回到 id主键索引树,找到满足记录的行,然后取出需要展示的列(回表过程)
3、 扫描满足条件的 10001 行,然后扔掉前 100000 行,返回。

4、 优化器认为多次回表 比 全表扫描 成本还高,故此采用全表扫描 (type=ALL)
第二个 SQL ( SELECT name limit ) 的执行流程:
1、 通过普通二级索引树 name,过滤 name 条件,找到满足条件的主键 id。
2、 因为只返回name索引列,所以使用了覆盖索引,不需要回表查询。
3、 因为没有回表,所以使用 索引范围查询 ,而不是 全表扫描 ,性能高
总结一下 limit 深分页,导致 SQL 变慢原因有两个:
- limit 语句会先扫描 offset+n 行,然后再丢弃掉前 offset 行,返回后 n 行数据。也就是说 limit 100000,10,就会扫描 100010 行,而 limit 0,10,只扫描 10 行。
- limit 100000,10 扫描更多的行数,也意味着回表更多的次数。
- 回表次数太多,优化器判断成本就会退回到全表扫描
那怎么优化呢?
参考 京东面试:mysql深度分页 严重影响性能?根本原因是什么?如何优化?
场景四:单表数据量太大
单表数据量太大 为什么会导致 SQL 变慢呢? 具体请参考 上一篇文章
美团一面:InndoDB 单表最多 2000W,为什么?小伙伴竟然面挂
一个表的数据量达到好几千万或者上亿时,加索引的效果没那么明显啦。
性能之所以会变差,是因为维护索引的 B+ 树结构层级变得更高了,查询一条数据时,需要经历的磁盘 IO 变多,因此查询性能变慢。
一棵 B + 树可以存多少数据量
一个三层 B + 树大概可以存放多少数据量呢?
看一张图
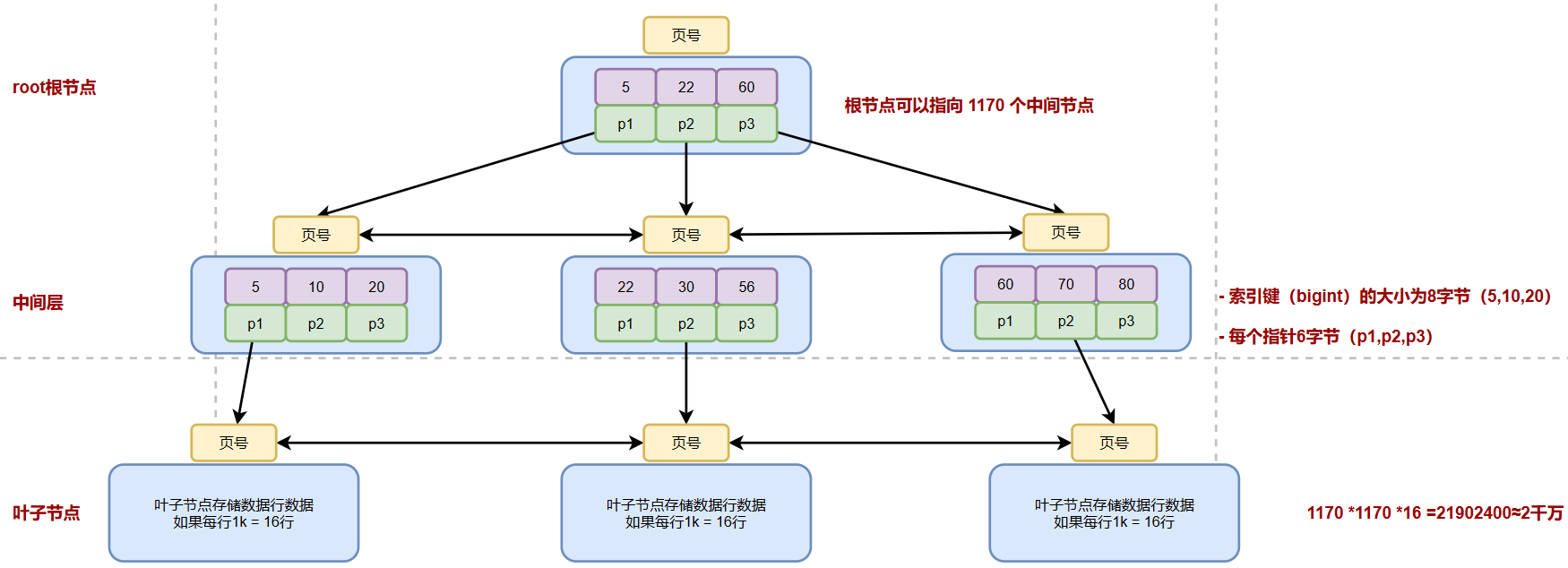
- 如果一行记录的数据大小为 1k,那么单个叶子节点可以存的记录数 =16k/1k =16
- 非叶子节点内存放多少指针呢?假设主键 ID 为 bigint 类型,长度为 8 字节,而指针大小在 InnoDB 源码中设置为 6 字节,所以就是 8+6=14 字节,16k/14B =16*1024B/14B = 1170
因此,2层 B + 树,能存放 1170 * 16=18720 条这样的数据记录。
同理一棵高度为 3 的 B + 树,能存放 1170 *1170 *16 =21902400,也就是说,可以存放两千万左右的记录,如果一行记录1K,可以存放一千万左右记录。
如果 B + 树想存储更多的数据,那树结构层级就会更高,查询一条数据时,需要经历的磁盘 IO 变多,因此查询性能变慢。
如何解决单表数据量太大,查询变慢的问题
一般超过千万级别,或者超过 500万,可以考虑分库分表了。
场景五:order by 文件排序
order by 文件排序 为什么会导致 SQL 变慢呢? 具体请参考 尼恩团队的专题文章
order by 原理和调优参考:滴滴一面:order by 调优10倍,思路是啥?
下面的例子,name字段有索引,adddress字段没有索引,address排序走文件排序,结果如下:
mysql> explain select address from my_customer order by address;
+----+-------------+-------------+------------+------+---------------+------+---------+------+--------+----------+----------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------------+------------+------+---------------+------+---------+------+--------+----------+----------------+
| 1 | SIMPLE | my_customer | NULL | ALL | NULL | NULL | NULL | NULL | 995164 | 100.00 | Using filesort |
+----+-------------+-------------+------------+------+---------------+------+---------+------+--------+----------+----------------+
1 row in set, 1 warning (0.00 sec)
mysql> explain select name from my_customer order by name;
+----+-------------+-------------+------------+-------+---------------+----------------------+---------+------+--------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------------+------------+-------+---------------+----------------------+---------+------+--------+----------+-------------+
| 1 | SIMPLE | my_customer | NULL | index | NULL | my_customer_name_IDX | 402 | NULL | 995164 | 100.00 | Using index |
+----+-------------+-------------+------------+-------+---------------+----------------------+---------+------+--------+----------+-------------+
1 row in set, 1 warning (0.00 sec)
order by 不走索引,走文件排序,就可能导致慢查询,也就是执行计划中出现Extra:Using filesort
文件排序有两种方式,如下图:
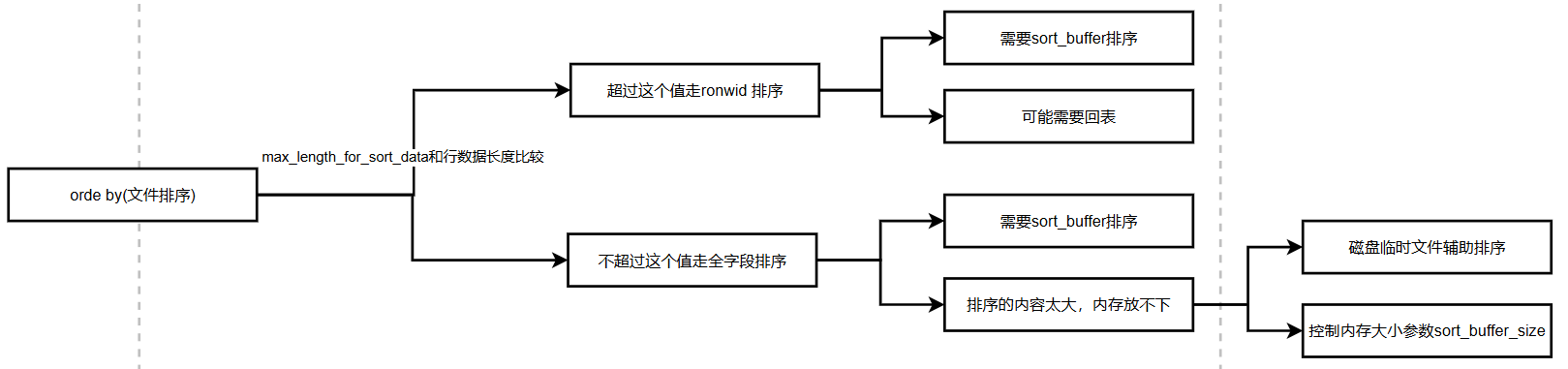
ORDER BY 优化策略:
1、 索引优化
- 创建复合索引:对
ORDER BY字段和WHERE条件字段组合建索引(如(user_id, create_time)),避免文件排序(filesort) - 覆盖索引:确保查询字段全被索引覆盖(如
SELECT id, name FROM users ORDER BY age使用(age, id, name)索引),减少回表开销 - 强制索引:通过
FORCE INDEX指定索引(如SELECT ... FORCE INDEX (idx_time)),避免优化器误选低效索引。
2、 减少数据量
- 结合
WHERE过滤:缩小排序范围(如WHERE user_id = 1)。 - 使用
LIMIT:仅返回必要结果(如LIMIT 10),尤其适用于分页场景。
3、 分页优化
- 主键分页:用上一页最后一条记录的主键值作为起点(如
WHERE id > 1000 ORDER BY id LIMIT 10),避免OFFSET带来的性能损耗。 - 子查询分页:先定位 ID 范围再关联数据(如嵌套
SELECT id子查询)。
4、 配置调优
- 增大内存参数:调整
sort_buffer_size和read_rnd_buffer_size,提升内存排序效率。 - 避免磁盘排序:确保排序操作在内存中完成,减少临时表 I/O。
5、 其他优化
- 避免函数/表达式:如
ORDER BY UPPER(name)会失效索引。 - 分区表:对时间序列数据按分区裁剪,减少排序数据量。
关键原则:通过索引加速排序、减少数据扫描量、合理分页及配置调优。
场景六:group by 使用临时表
group by 使用临时表 为什么会导致 SQL 变慢呢? 具体请参考 尼恩团队的专题文章
group by 原理和调优参考:京东太狠:100W数据去重,用distinct还是group by,说说理由?
日常开发中,group by使用得比较频繁。
group by 一般用于分组统计,它表达的逻辑就是根据一定的规则,进行分组。
group by使用不当,很容易就会产生慢SQL 问题。因为它既用到临时表,又默认用到排序。
有时候还可能用到磁盘临时表。
- 如果执行过程中,会发现内存临时表大小到达了上限(控制这个上限的参数就是
tmp_table_size),会把内存临时表转成磁盘临时表。- 如果数据量很大,很可能这个查询需要的磁盘临时表,就会占用大量的磁盘空间。
基本的优化方案:group by 后面的字段加索引
下面的案例,应为address没有索引,即使用了临时表,有使用了文件排序
mysql> explain select address,count(*) as num from my_customer group by address;
+----+-------------+-------------+------------+------+---------------+------+---------+------+--------+----------+---------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------------+------------+------+---------------+------+---------+------+--------+----------+---------------------------------+
| 1 | SIMPLE | my_customer | NULL | ALL | NULL | NULL | NULL | NULL | 995164 | 100.00 | Using temporary; Using filesort |
+----+-------------+-------------+------------+------+---------------+------+---------+------+--------+----------+---------------------------------+
1 row in set, 1 warning (0.00 sec)
mysql> explain select name,count(*) as num from my_customer group by name;
+----+-------------+-------------+------------+-------+----------------------+----------------------+---------+------+--------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------------+------------+-------+----------------------+----------------------+---------+------+--------+----------+-------------+
| 1 | SIMPLE | my_customer | NULL | index | my_customer_name_IDX | my_customer_name_IDX | 402 | NULL | 995164 | 100.00 | Using index |
+----+-------------+-------------+------------+-------+----------------------+----------------------+---------+------+--------+----------+-------------+
1 row in set, 1 warning (0.00 sec)
场景七:delete + in 子查询不走索引!
之前见到过一个生产慢 SQL 问题,当 delete 遇到 in 子查询时,即使有索引,也是不走索引的。
而对应的 select + in 子查询,却可以走索引。

在 MySQL 中,SHOW WARNINGS 语句用于查看最近执行的 SQL 语句产生的警告信息(含查询优化信息)。这些警告信息通常包括语法问题、数据类型转换问题、约束违反、查询优化信息等。
当你执行一条查询后,如果有警告产生,MySQL 会记录这些警告。
通过 SHOW WARNINGS,你可以查看这些警告的详细信息,包括警告的级别(注意、警告或错误)、错误代码以及警告消息。
假设你在执行一条查询后,运行了 SHOW WARNINGS,它可能会返回类似以下的结果:
mysql> SHOW WARNINGS;
+-------+------+------------------------------------------+
| Level | Code | Message |
+-------+------+------------------------------------------+
| Note | 1003 | /* SELECT, QUERY */ SELECT 1 /* end */ |
| Warning | 1292 | Truncated incorrect DOUBLE value: 'abc' |
+-------+------+------------------------------------------+
在这个例子中:
- Level:显示警告的级别,可以是
Note(注意)、Warning(警告)或Error(错误)。 - Code:MySQL 的错误代码。
- Message:警告或错误的描述信息。
为什么 SHOW WARNINGS 能显示优化信息
1、查询优化过程:
当执行一个查询时,MySQL 的查询优化器会分析查询的结构,并尝试将其转换为更高效的执行计划。
对于 SELECT ... IN 子查询,优化器会检查是否可以将其转换为 JOIN 操作。JOIN 通常比子查询更高效,因为它可以利用索引和更优的查询执行计划。
2、优化器的通知:
- 在优化过程中,优化器会生成一些内部通知或日志,记录它对查询所做的优化操作。
- 这些通知通常以警告(
Warning)的形式记录下来,并可以通过SHOW WARNINGS查看。
3、信息性通知:
- 错误代码
1003是一种信息性通知,表示查询优化器对查询进行了优化或重写。 - 这些通知通常不会影响查询的执行结果,但可以帮助开发者了解优化器的行为。
使用 SHOW WARNINGS 能显示优化信息:
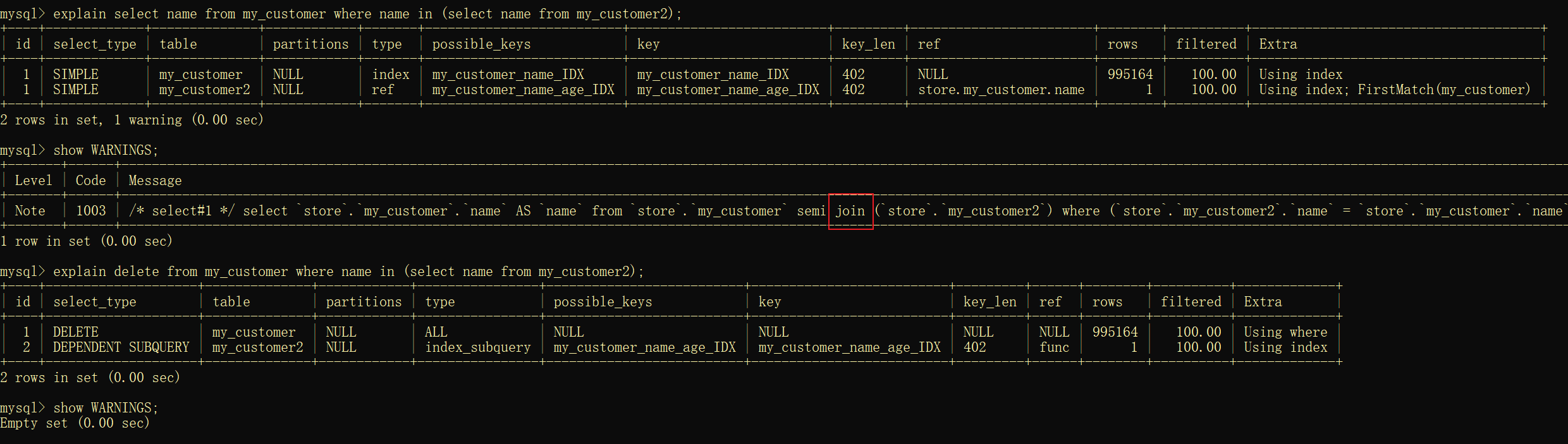
可以发现,实际执行的时候,MySQL 对 select in 子查询做了优化,把子查询改成 join 的方式,所以可以走索引。
但是很遗憾,对于 delete in 子查询,MySQL 却没有对它做这个优化。
优化方案:使用join方式,join方式可以走索引
场景8: join 或者子查询过多
MySQL 中,join 的执行算法主要有两种:Index Nested-Loop Join 和 Block Nested-Loop Join。
-
Index Nested-Loop Join:
这种 join 算法类似于程序里的嵌套查询。
如果被驱动表(也就是 join 右边的表)上有索引,MySQL 会利用这个索引来快速定位匹配的数据,这样查询效率会比较高。
-
Block Nested-Loop Join:
如果被驱动表上没有可用的索引,MySQL 会采用这种算法。
它先把驱动表(join 左边的表)的数据读入到一个叫 join_buffer 的内存区域,然后逐行扫描被驱动表,把每一行数据与 join_buffer 中的数据进行比较,符合条件的就加入结果集。
过多表连接的问题主要体现在两个方面:
-
一方面,会让 SQL 语句变得非常复杂,维护起来困难;
-
另一方面,如果被驱动表有索引,并且用小表作为驱动表,查询效率还可以。
但如果被驱动表没有索引,就只能依赖 join_buffer 来进行匹配。如果数据量不大或者 join_buffer 设置得足够大,查询速度也不会太慢。
然而,当 join 的数据量很大时,MySQL 会在硬盘上创建临时表来进行关联匹配,这就会严重影响查询效率,因为磁盘 IO 的速度本来就慢,再加上关联操作,会让查询变得更慢。
一般来说,如果业务确实需要进行表连接,2~3 个表的关联是可以接受的,但前提是关联字段要添加索引。
如果需要关联更多的表,建议在代码层面进行拆分:先查询一张表的数据,然后以关联字段作为条件去查询关联表,将结果存入 map 中,最后在业务层进行数据的拼装。这样可以避免复杂的多表连接,提高系统的性能和可维护性。
场景9:in 元素过多
知道,在 SQL 查询中,如果使用了 IN 关键字,即使 IN 后面的字段有索引,也要特别注意:传入的值不能太多。一般来说,IN 后面的元素个数建议不要超过 500 个。
如果超过了这个数量,最好进行分组处理,每次最多传 500 个,避免一次性查询过多数据。
反例说明:比如下面这条 SQL:
SELECT user_id, name FROM user WHERE user_id IN (1, 2, 3, ..., 1000000);
如果不对 IN 中的元素数量做任何限制,这条语句可能会一次性查出非常多的数据,导致数据库压力剧增,甚至引起接口超时、系统卡顿等问题。
更危险的情况是,有时候使用的是子查询来填充 IN 的条件,根本不知道到底会返回多少条数据。
比如这样:
SELECT * FROM user WHERE user_id IN (SELECT author_id FROM article WHERE type = 1);
这种写法看起来没问题,但如果子查询返回了几万个甚至几十万个 author_id,主查询就会变得非常慢,很容易把数据库拖垮。
正确做法:可以对 IN 查询做拆分,比如每批最多查 500 个 ID:
SELECT user_id, name FROM user WHERE user_id IN (1, 2, 3, ..., 500);
如果你是在程序里动态传参,还可以加一个参数校验逻辑,防止一次传入太多 ID:
if (userIds.size() > 500) {
throw new Exception("单次查询的用户ID不能超过500个");
}
或者在代码中自动分批次处理,比如每次取 500 个 ID 查询一次,循环执行直到全部完成。
小结一下:
- 即使字段有索引,
IN后面也不能放太多值; - 建议控制在 500 个以内,超出就分批;
- 子查询嵌套在
IN中时更要小心,可能返回大量数据; - 程序中要对传参做校验或自动分页处理,避免接口超时或数据库性能下降。
场景10:拿不到锁,导致慢sql
当一条简单的SQL查询长时间无响应,通常是发生了数据库表级锁或行级锁冲突。
这种场景类似于:多人合租只有一个卫生间的场景——若室友A比你先进入卫生间,你必须等待其使用完毕才能进入。
此时可通过以下方式诊断:
1、 执行 SHOW PROCESSLIST 查看当前连接状态,若发现大量"Waiting for table metadata lock"或"Lock wait"提示,说明存在锁竞争;
2、 结合information_schema.innodb_trx表分析具体阻塞事务。
核心逻辑:数据库锁机制与合租卫生间的“互斥访问”原理高度相似,需通过排查锁定源头事务或优化事务隔离级别(如降低为READ COMMITTED)减少等待。
场景11:数据库在刷脏页
脏页的定义
在数据库运行过程中,当内存里的数据页和磁盘上对应的数据页内容不一样时,把这个内存页叫做“脏页”。
而当内存中的数据被写入磁盘后,内存和磁盘上的数据页内容就达成了一致,此时这个内存页就被称作“干净页”。
通常来说,只有执行更新类的SQL语句才有可能产生脏页。
下面回顾一下,一条更新语句在MySQL中究竟是如何执行的。
更新语句的执行流程
现在来看看这条更新SQL:update t set c=c+1 where id=666;
它的执行步骤如下:
1、 获取数据行:
执行器首先会向存储引擎请求获取id=666的这一行数据。
要是这行数据所在的数据页已经在内存当中,存储引擎会直接把它返回给执行器;
要是不在内存里,存储引擎就会先从磁盘把该数据页读入内存,然后再返回给执行器。
2、 执行数据更新:
执行器拿到存储引擎返回的行数据之后,会对这一行中c的值进行加1操作,得到一行新的数据。
随后,执行器会调用存储引擎的接口,将这行新数据写入。
3、 记录重做日志:
存储引擎会把这行新数据更新到内存里,同时将这个更新操作记录到redo log(重做日志)当中。
需要注意的是,此时redo log处于prepare(准备)状态。
4、 写入二进制日志:
执行器会生成与这个操作相对应的binlog(二进制日志),并把binlog写入磁盘。
5、 完成事务提交:
执行器调用存储引擎的提交事务接口,存储引擎会把之前写入的redo log状态从prepare改为commit(提交),至此,整个更新操作完成。
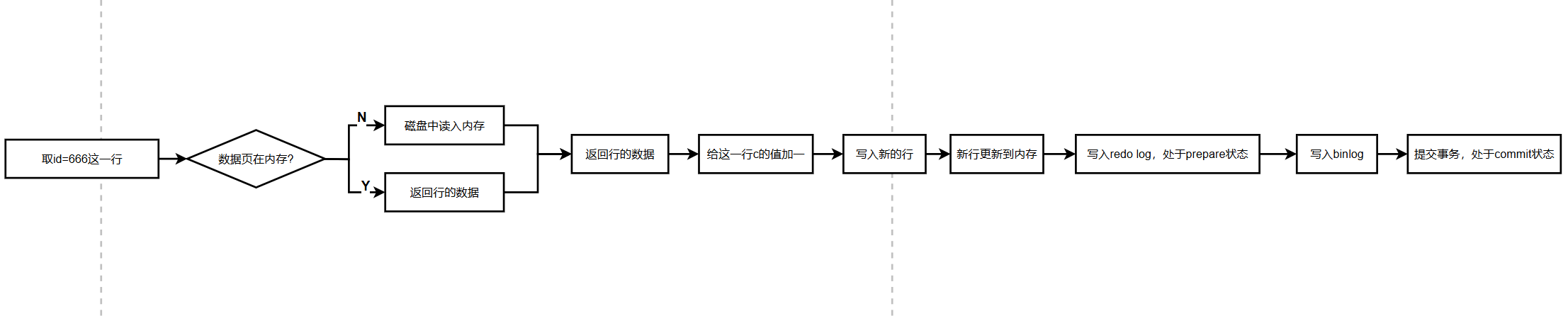
InnoDB存储引擎在处理更新语句时,实际上只进行了一次磁盘操作,就是写redo log。
平时感觉更新SQL执行得很快,原因就在于它只是更新了内存以及写入了redo log,真正把redo log里的数据同步到磁盘这个操作,是等到系统空闲的时候才会去做的。
可能有些小伙伴会感到疑惑,redo log不是存储在磁盘上吗?
那为什么写redo log的速度并不慢呢?
这是因为写redo log采用的是顺序写磁盘的方式。在磁盘操作中,顺序写能够减少寻道等待时间,所以它的速度要比随机写快得多。
脏页的产生原因
更新SQL在执行时,只是对内存和redo log进行写入操作,而将redo log里的数据同步到磁盘这个过程是在系统空闲时才进行的。
在数据同步之前,内存数据页和磁盘数据页的内容是不一致的,这就导致了脏页的出现。
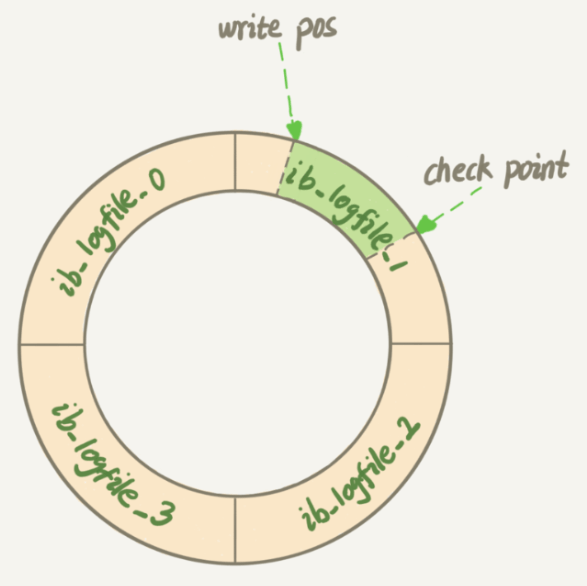
脏页刷新的时机
InnoDB存储引擎的redo log大小是固定的,并且采用的是环形写入的方式。
那么,究竟在哪些情况下会触发脏页的刷新(flush)呢?
主要有以下几种场景:
1、 redo log写满时:
当redo log被写满了,就必须要刷新脏页了。这种情况要尽量避免,因为一旦出现这种情况,整个系统就无法再接受新的更新操作了,所有的更新请求都将被阻塞。
2、 内存不足时:
当系统需要新的内存页,而内存空间又不够的时候,就需要淘汰一些数据页,这时就可能会触发脏页刷新。InnoDB使用缓冲池(buffer pool)来管理内存,当要读入的数据页不在内存中时,就需要从缓冲池中申请一个数据页。此时,只能把最久不使用的数据页从内存中淘汰掉。如果要淘汰的数据页是干净页,那么可以直接释放出来复用;但如果是脏页,就必须先把脏页刷到磁盘,使其变成干净页之后才能复用。
3、 系统空闲时:
MySQL会在认为系统处于空闲状态的时候,主动刷新一些脏页。
4、 MySQL正常关闭时:
当MySQL正常关闭时,会把内存中的所有脏页都刷新到磁盘上。
脏页刷新导致SQL变慢的原因
1、 redo log写满引发的阻塞:
当redo log写满需要刷新脏页时,会导致系统所有的更新操作都被阻塞,此时写性能会降为0,SQL执行速度自然就变得很慢。这种情况一般要想办法杜绝。
2、 查询淘汰脏页过多:
如果一个查询操作需要淘汰的脏页数量太多,也会使得查询的响应时间明显变长。
脏页刷新导致SQL变慢的优化方法
1、优化磁盘 I/O 性能
-
升级硬件 :使用高速磁盘,如固态硬盘(SSD)代替传统的机械硬盘。SSD 的读写速度比机械硬盘快得多,可以有效减少脏页刷新的等待时间。
-
优化磁盘配置 :采用磁盘阵列技术(如 RAID),通过条带化可以提高读写速度,通过镜像或多副本可以提高数据的可靠性。同时,合理分配磁盘空间,避免磁盘碎片过多,定期进行磁盘碎片整理。
-
调整文件系统和磁盘参数 :根据数据库系统的推荐,设置合适的文件系统参数(如文件系统块大小)和磁盘 I/O 调度算法(如使用 deadline 或 noop 调度算法代替默认的 cfq 算法),以提高磁盘 I/O 的效率。
2、调整缓冲池大小和配置
-
合理设置缓冲池大小 :根据服务器的内存大小和数据库的工作负载来设置缓冲池的大小。一般来说,缓冲池大小可以设置为服务器物理内存的 60% - 80% 左右。对于以 InnoDB 作为存储引擎的 MySQL 数据库,可以通过
innodb_buffer_pool_size参数来设置缓冲池大小。 -
启用缓冲池实例 :在多核服务器上,启用多个缓冲池实例可以减少缓冲池操作的锁竞争。通过设置
innodb_buffer_pool_instances参数来指定缓冲池实例的数量,实例数量一般可以设置为与 CPU 核心数相近。
3、 优化事务日志相关设置
-
调整事务日志文件大小和数量 :根据数据库的写入负载,适当增大事务日志文件的大小(如 MySQL InnoDB 的
innodb_log_file_size参数),减少日志文件切换的频率,同时可以增加事务日志文件的数量(如innodb_log_files_in_group参数)。 -
优化事务日志的写入策略 :一些数据库系统允许调整事务日志的写入方式,例如设置日志写入的刷盘策略(如 MySQL 的
innodb_flush_log_at_trx_commit参数)。将其设置为 1 时,每个事务提交都会将日志写入并刷盘,虽然保证了数据的完整性,但会增加 I/O 开销;设置为 2 时,日志写入文件但不立即刷盘,在系统故障时可能会丢失最多 1 秒的事务;设置为 0 时,日志不立即写入和刷盘,性能最好,但数据安全性最低。可以根据实际的数据安全需求和性能要求来选择合适的设置。
4、 调整脏页刷新策略和参数
-
调整脏页刷新频率相关参数 :例如在 MySQL 中,可以通过
innodb_max_dirty_pages_pct参数来设置缓冲池中允许的脏页比例。当脏页比例达到这个值时,数据库会开始刷新脏页。合理设置这个参数可以避免脏页过多积累,同时不会过于频繁地刷新脏页。一般来说,将其设置为 70% - 80% 左右比较合适。默认值为75%,在内存较大且I/O能力较强的存储下,可以适当调大该值,减少脏页的频繁刷新。 -
优化脏页刷新的速度控制参数 :一些数据库系统允许控制脏页刷新的速度,如
innodb_io_capacity和innodb_io_capacity_max参数。innodb_io_capacity表示磁盘的 I/O 吞吐量,用于控制脏页刷新等 I/O 操作的速度。innodb_io_capacity_max表示脏页刷新的最大 I/O 操作数量,当磁盘 I/O 压力较大时,可以适当调整这两个参数来平衡脏页刷新速度和 SQL 操作的性能。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









