




本文 的 原文 地址
尼恩:LLM大模型学习圣经PDF的起源
在40岁老架构师 尼恩的读者交流群(50+)中,经常性的指导小伙伴们改造简历。
经过尼恩的改造之后,很多小伙伴拿到了一线互联网企业如得物、阿里、滴滴、极兔、有赞、希音、百度、网易、美团的面试机会,拿到了大厂机会。
然而,其中一个成功案例,是一个9年经验 网易的小伙伴,当时拿到了一个年薪近80W的大模型架构offer,逆涨50%,那是在去年2023年的 5月。
不到1年,小伙伴也在团队站稳了脚跟,成为了名副其实的大模型 应用 架构师。接下来,尼恩架构团队,通过 梳理一个《LLM大模型学习圣经》 帮助更多的人做LLM架构,拿到年薪100W, 这个内容体系包括下面的内容:
- 《Python学习圣经:从0到1精通Python,打好AI基础》
- 《LLM大模型学习圣经:从0到1吃透Transformer技术底座》
- 《LangChain学习圣经:从0到1精通LLM大模型应用开发的基础框架》
- 《LLM大模型学习圣经:从0到1精通RAG架构,基于LLM+RAG构建生产级企业知识库》
- 《SpringCloud + Python 混合微服务架构,打造AI分布式业务应用的技术底层》
- 《LLM大模型学习圣经:从0到1吃透大模型的顶级架构》
- 《LLM 智能体 学习圣经:从0到1吃透 LLM 智能体 的架构 与实操》
- 《LLM 智能体 学习圣经:从0到1吃透 LLM 智能体 的 中台 架构 与实操》
- 《Spring 集成 DeepSeek 的 3大方法,史上最全》
- 《基于Dify +Ollama+ Qwen2 完成本地 LLM 大模型应用实战》
- 《Spring AI 学习圣经 和配套视频 》
- 《Text2SQL圣经:从0到1精通Text2Sql(Chat2Sql)的原理,以及Text2Sql开源项目的使用》
- 《AI部署架构:A100、H100、A800、H800、H20的差异以及如何选型?开发、测试、生产环境如何进行部署架构?》
- 生产环境 K8S + Deepseek 实现大模型部署 和 容器调度(图解+史上最全)
以上学习圣经 的 配套视频, 2025年 5月份之前发布。
最近大火的 MCP 协议,看这篇文章就够了
本篇旨在回答以下三个问题:
(1)什么是 MCP?
(2)为什么需要 MCP?
(3)作为用户,我们如何使用/开发 MCP?
一 为什么需要 MCP?
我认为 MCP 的出现是 prompt engineering(提示工程)发展的产物。更结构化的上下文信息对模型的性能提升是显著的。我们在构造 prompt (提示词)时,希望能提供一些更具体的信息(比如本地文件,数据库,一些网络实时信息等)给模型,这样模型更容易理解真实场景中的问题。
想象一下没有 MCP 之前我们会怎么做?
我们可能会人工从数据库中筛选或者使用工具检索可能需要的信息,手动的粘贴到 prompt 中。随着我们要解决的问题越来越复杂,手工把信息引入到 prompt 中会变得越来越困难。
为了克服手工 prompt 的局限性,许多 LLM 平台(如 OpenAI、Google)引入了 function call (函数调用)功能。
这一机制允许模型在需要时调用预定义的函数来获取数据或执行操作,显著提升了自动化水平。
Agent 开发的过程和痛点:
AI 的发展链路大致是这样的: 从最初只能对话的 Chatbot,辅助人类决策的 Copilot,再到能自主感知和行动的 Agent,AI 在任务中的参与度不断提升。
这要求 AI 拥有更丰富的任务上下文 (Context),并拥有执行 行动所需的工具 (Tool )。
Agent 让LLM 调用工具
一个 Agent 让LLM 调用工具,步骤如下:
(1)写好函数工具
开发者需要在本地写好函数工具,例如,如果想让LLM学会查询天气,我们需要在本地写好一个查询天气的函数
(2)写好函数的介绍(这个很关键)
LLM将会函数的介绍,理解函数的作用。函数介绍包括:函数的作用、参数的类型、参数的作用等。例如,DeepSeek的函数介绍格式如下:
tools = [{
"type": "function",
"function": {
"name": "get_weather",
"description": "Get weather of an location, the user shoud supply a location first",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "The city and state, e.g. San Francisco, CA",
}
},
"required": ["location"]
},
}
}, ]
这是一个天气查询的函数,参数为location,LLM将会通过这些介绍,学会如何调用函数。
(3)解析响应,并在本地执行函数
若DeepSeek认为当前应该调用函数,则会输出参数的填写方式,格式如下:
{
"message": {
"role": "assistant",
"content": "",
"tool_calls": [{
"index": 0,
"id": "call 0_c2fd458f-b1e3-43a0-b76a-c9138e609678",
"type": "function",
"function": {
"name": "get_weather",
"arguments": "{\"location\":\"Beijing\"}"
}
}]
}
}
我们可以通过解析message中是的tool_calls字段,将DeepSeek给出的参数填写在函数中,并在本地执行函数。
(4)LLM根据运行结果进行总结并回复
最后把函数执行的结果反馈给DeepSeek,DeepSeek再整理执行结果,给出回复。
Agent 开发 三大痛点
缺少标准化的上下文和工具集导致 Agent 开发有三大痛点:
1 开发耦合度高:
工具开发者需要深入了解 Agent 的内部实现细节,并在 Agent 层编写工具代码。这导致在工具的开发与调试困难。
2 工具复用性差:
因每个工具实现都耦合在 Agent 应用代码内,即使是通过 API 实现适配层在给到 LLM 的出入参上也有区别。
从编程语言角度来讲,没办法做到跨编程语言进行复用。
3 生态碎片化:
工具提供方能提供的只有 OpenAPI,由于缺乏标准使得不同 Agent 生态中的工具 Tool 互不兼容。
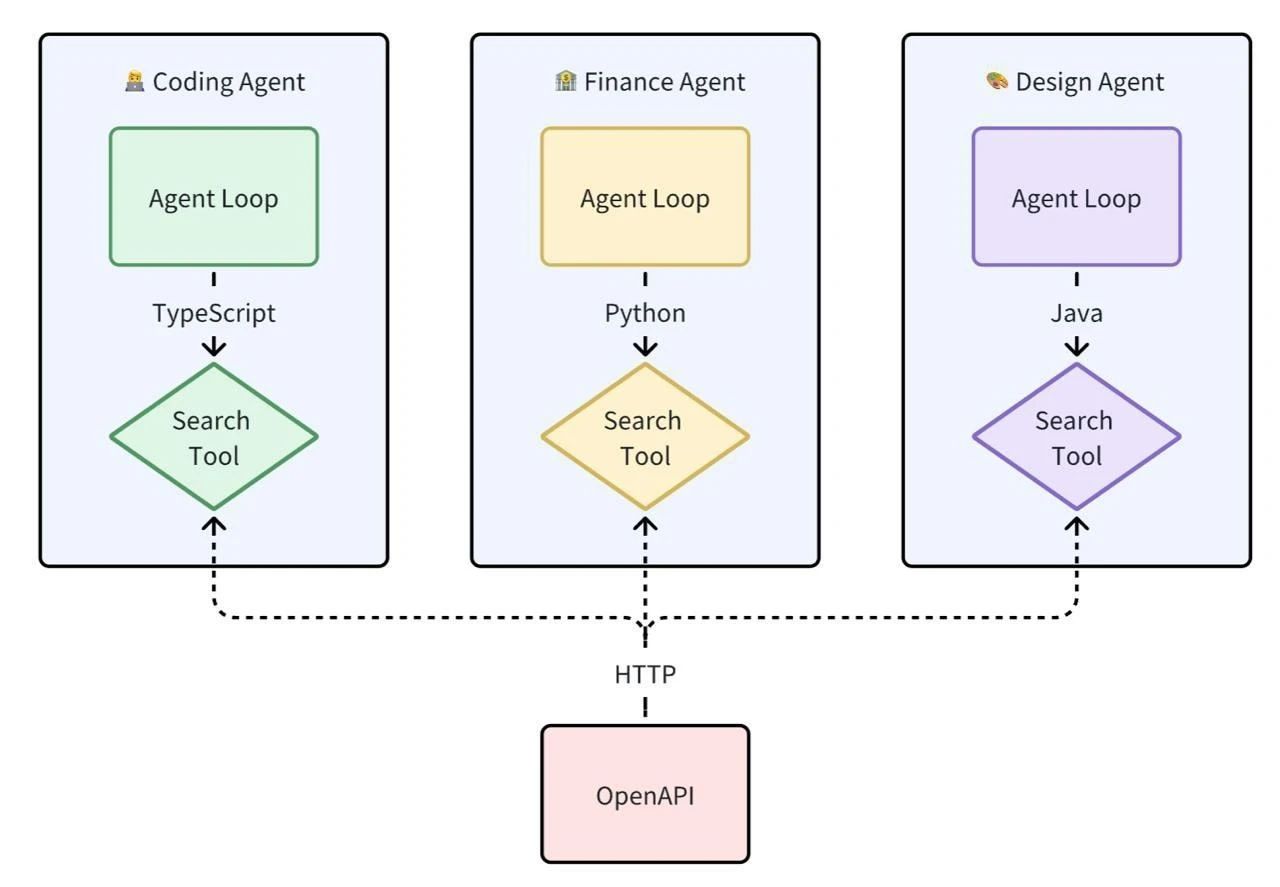
但是 function call 也有其局限性, function call 平台依赖性强,不同 LLM 平台的 function call API 实现差异较大。
例如,OpenAI 的函数调用方式与 Google 的不兼容,开发者在切换模型时需要重写代码,增加了适配成本。除此之外,还有安全性,交互性等问题。
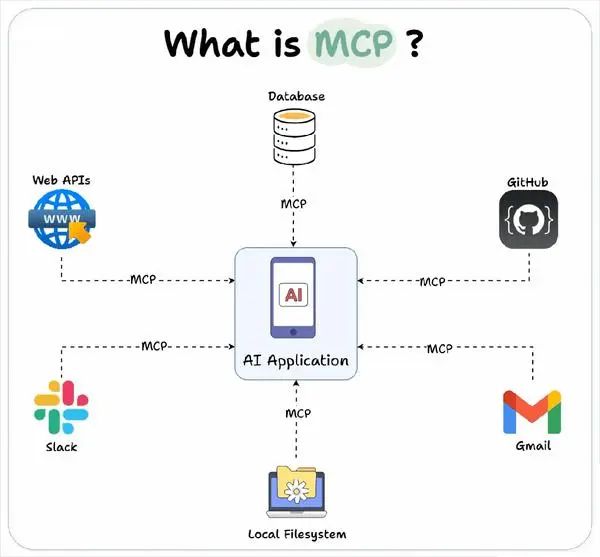
二、什么是 MCP?
数据与工具本身是客观存在的,只不过我们希望将数据连接到模型的这个环节可以更智能更统一。
MCP(Model Context Protocol)是Anthropic(Claude的母公司)在2024年提出的一种协议标准,中文翻译过来的意思是"模型上下文协议"。
MCP的核心作用是让AI模型能够主动调用外部工具和服务,从而 大大 扩展AI的 能力边界。
MCP 起源于 2024 年 11 月 25 日 Anthropic 发布的文章:[Introducing the Model Context Protocol1]。
MCP (Model Context Protocol,模型上下文协议)定义了应用程序和 AI 模型之间交换上下文信息的方式。
MCP 使得开发者能够以一致的方式将各种数据源、工具和功能连接到 AI 模型(一个中间协议层),就像 USB-C 让不同设备能够通过相同的接口连接一样。
MCP 的目标是创建一个通用标准,使 AI 应用程序的开发和集成变得更加简单和统一。
所谓一图胜千言,我这里引用一些制作的非常精良的图片来帮助理解:
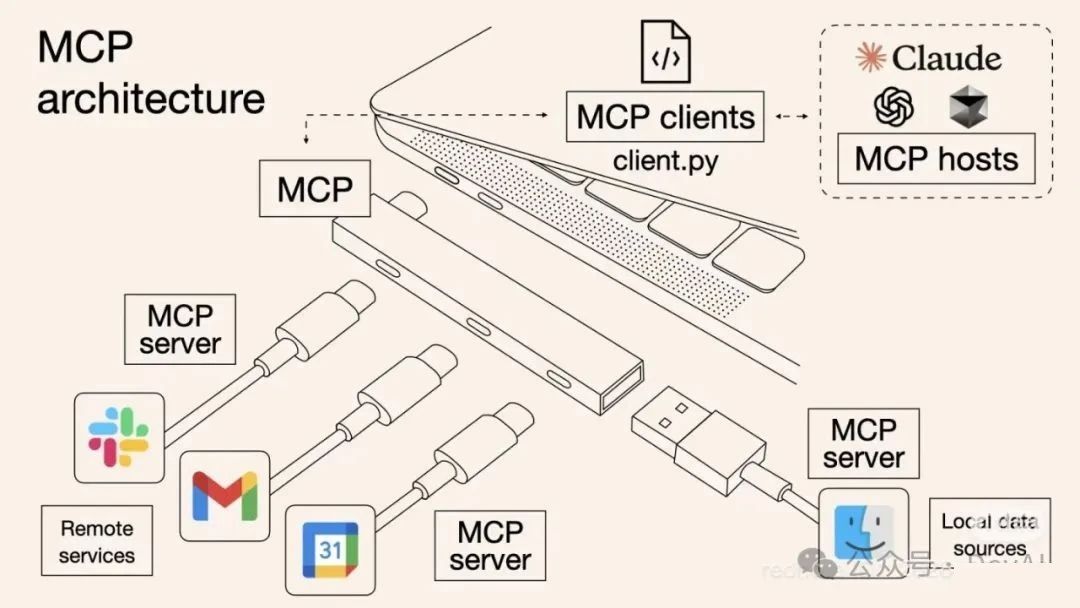
可以看出,MCP 就是以更标准的方式让 LLM Chat 使用不同工具,更简单的可视化如下图所示,这样你应该更容易理解“中间协议层”的概念了。
Anthropic 旨在实现 LLM Tool Call(LLM 工具调用)的标准。
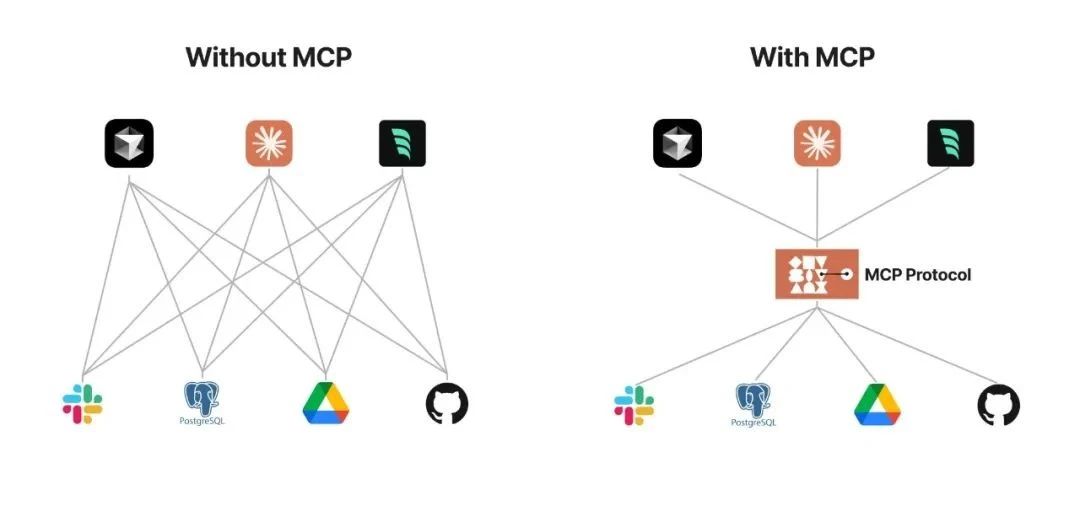
Anthropic 基于这样的痛点设计了 MCP,充当 AI 模型的"万能转接头",让 LLM 能轻松得获取数据或者调用工具。
一句话解释就是 MCP 提供给 LLM 所需的上下文:Resources 资源、Prompts 提示词、Tools 工具。
更具体的说 MCP 的优势在于:
**(1)生态:**MCP 提供很多现成的插件,你的 AI 可以直接使用。
**(2)统一性:**不限制于特定的 AI 模型,任何支持 MCP 的模型都可以灵活切换。
**(3)数据安全:**你的敏感数据留在自己的电脑上,不必全部上传(因为我们可以自行设计接口确定传输哪些数据)。
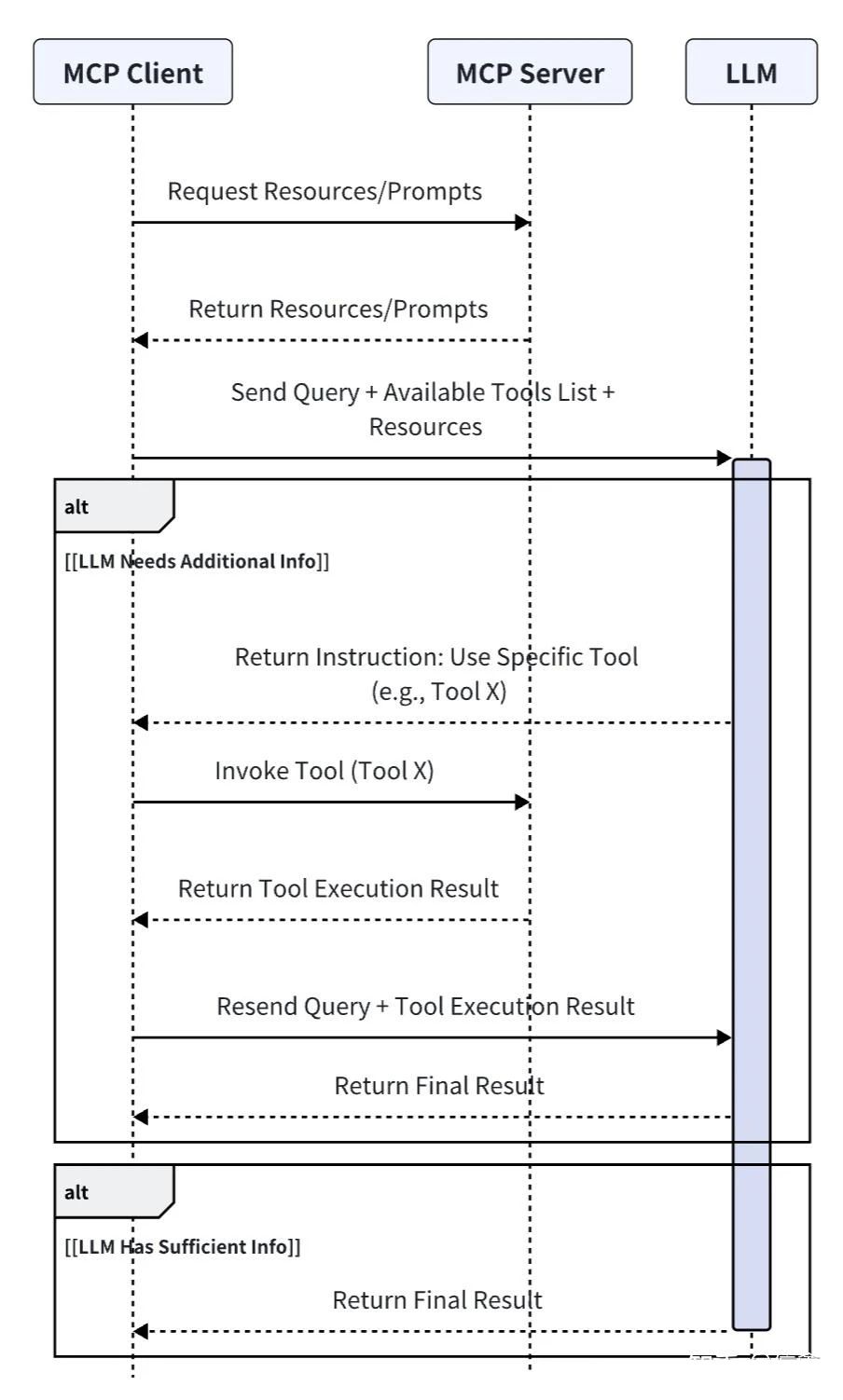
MCP 和 Function Call 区别?
| MCP | Function Call | |
|---|---|---|
| 定义 | 模型和其它设备集成的标准接口,包含:工具 Tools、资源 Resources、提示词 Prompts | 将模型连接到外部数据和系统,平铺式的罗列 Tools 工具。和 MCP Tool 不同的在于:MCP Tool 的函数约定了输入输出的协议规范。 |
| 协议 | JSON-RPC,支持双向通信(但目前使用不多)、可发现性、更新通知能力。 | JSON-Schema,静态函数调用。 |
| 调用方式 | Stdio / SSE / 同进程调用(见下文) | 同进程调用 / 编程语言对应的函数 |
| 适用场景 | 更适合动态、复杂的交互场景 | 单一特定工具、静态函数执行调用 |
| 系统集成难度 | 高 | 简单 |
| 工程化程度 | 高 | 低 |
从前后端分离看 MCP
早期 Web 开发在 JSP、PHP 盛行时,前端交互页面都是耦合在后端逻辑里的,造成开发复杂度高、代码维护困难、前后端协作不便,难以适应现代 Web 应用对用户体验和性能的更高要求。
AJAX、Node.js、RESTful API 推动前后端分离,对应 MCP 也正在实现 AI 开发的“工具分层”:
- 前后端分离:
前端专注界面,后端专注 API 接口;
- MCP 分层:
让工具开发者和 Agent 开发者各司其职,工具质量和功能的迭代不需要 Agent 开发者感知。
这种分层让 AI Agent 开发者能像搭积木一样组合工具,快速构建复杂 AI 应用。
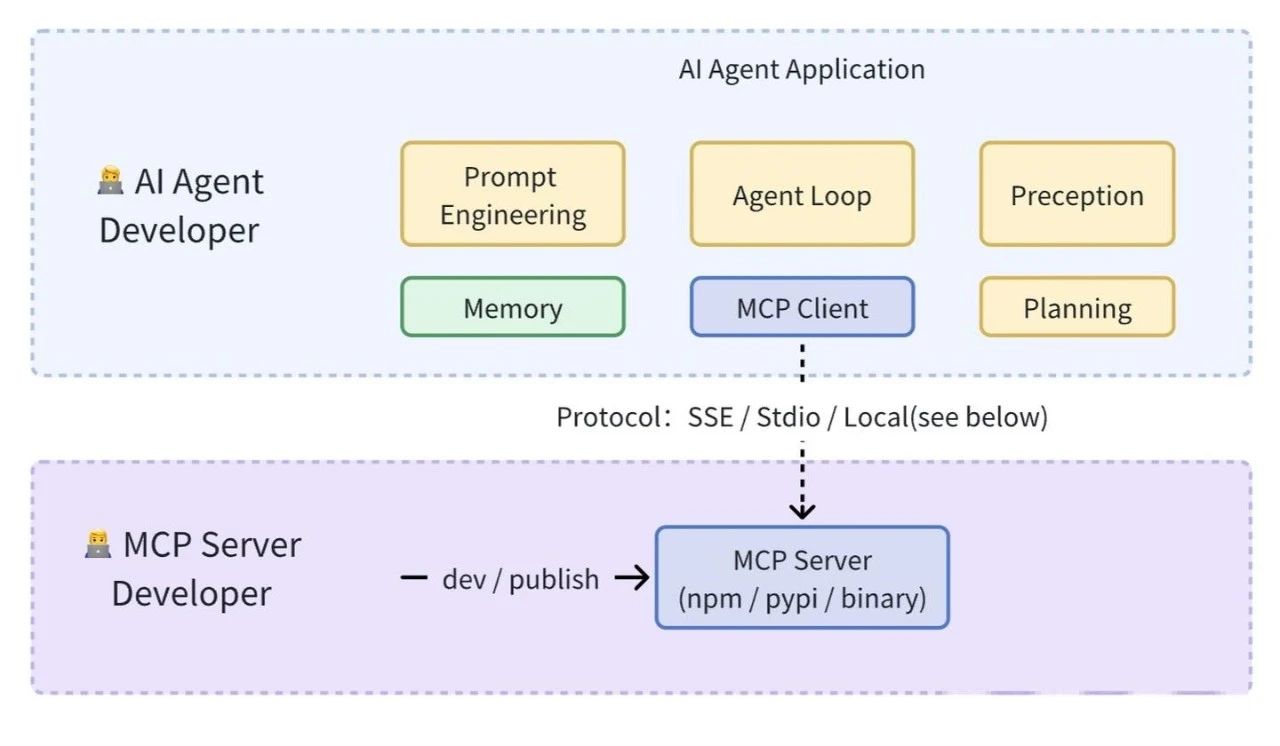
三、 用户如何使用 MCP?
对于用户来说,我们并不关心 MCP 是如何实现的,通常我们只考虑如何更简单地用上这一特性。
具体的使用方式参考官方文档:For Claude Desktop Users。
这里不再赘述,配置成功后可以在 Claude 中测试:Can you write a poem and save it to my desktop? Claude 会请求你的权限后在本地新建一个文件。
并且官方也提供了非常多现成的 MCP Servers,你只需要选择你希望接入的工具,然后接入即可。
比如官方介绍的 filesystem 工具,它允许 Claude 读取和写入文件,就像在本地文件系统中一样。
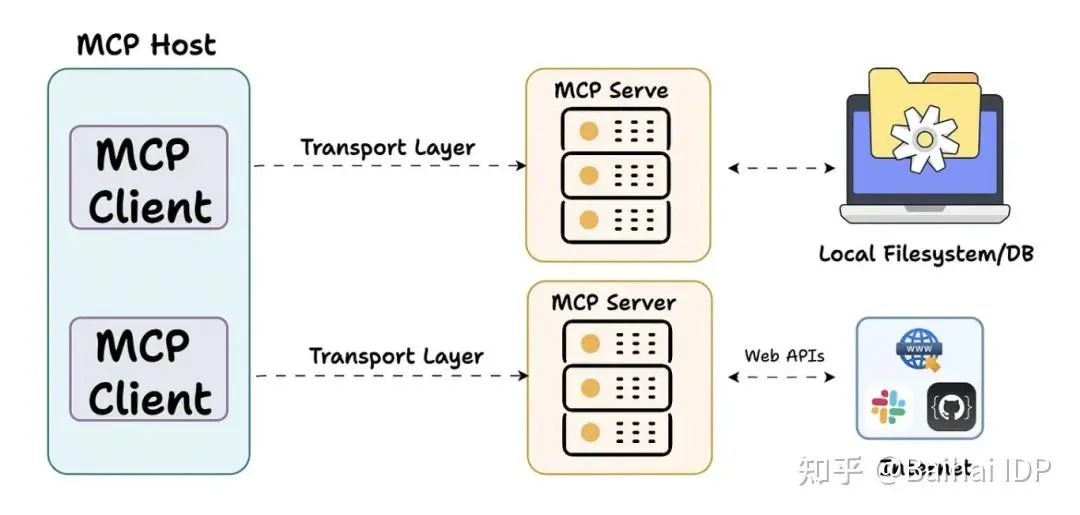
4. MCP 架构解构
这里首先引用官方给出的架构图。

MCP 由三个核心组件构成:Host(主机)、Client(客户端) 和 Server(服务器)。
让我们通过一个实际场景来理解这些组件如何协同工作: 假设你正在使用 Claude Desktop (Host) 询问:“我桌面上有哪些文档?”
(1)Host:Claude Desktop 作为 Host,负责接收你的提问并与 Claude 模型交互。
(2)Client:当 Claude 模型决定需要访问你的文件系统时,Host 中内置的 MCP Client 会被激活。这个 Client 负责与适当的 MCP Server 建立连接。
(3)Server:在这个例子中,文件系统 MCP Server 会被调用。它负责执行实际的文件扫描操作,访问你的桌面目录,并返回找到的文档列表。
整个流程是这样的:你的问题 → Claude Desktop(Host) → Claude 模型 → 需要文件信息 → MCP Client 连接 → 文件系统 MCP Server → 执行操作 → 返回结果 → Claude 生成回答 → 显示在 Claude Desktop 上。
这种架构设计使得 Claude 可以在不同场景下灵活调用各种工具和数据源,而开发者只需专注于开发对应的 MCP Server,无需关心 Host 和 Client 的实现细节。
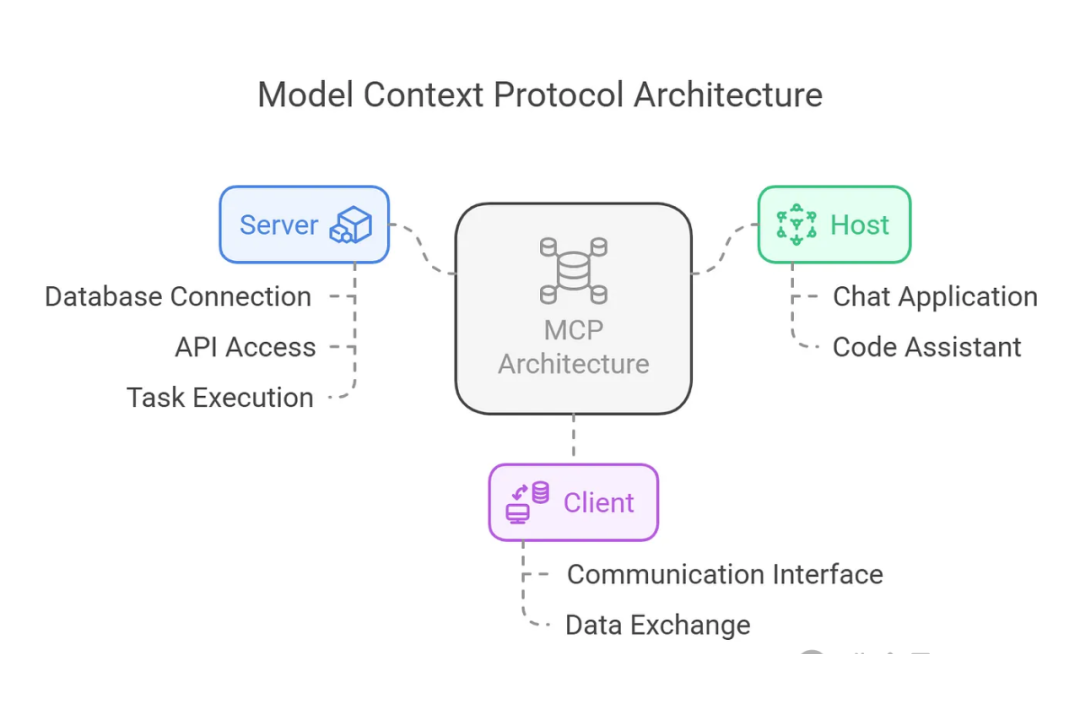
更加细致的 整体架构图,如下:
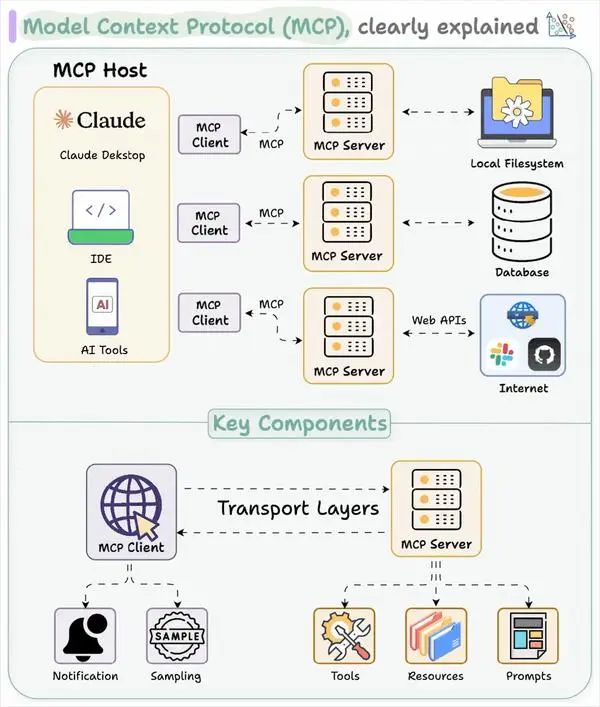
直观地说,MCP 就像 AI 应用的 USB-C 接口。
正如 USB-C 为设备连接各种配件提供了标准化方案,MCP 也将 AI 应用连接到不同数据源和工具的方式标准化了。
MCP 的核心遵循客户端-服务器(client-server)架构,Host 应用程序可以连接到多个 Server。
它包含三个主要组件:
- Host
- Client
- Server
Host 代表任何提供 AI 交互环境、访问外部工具和数据源,Host 是一个 还负责 运行 MCP Client 的 AI 应用(如 Claude 桌面版 、 Cursor )。
MCP Client 在 Host 内运行,实现与 MCP Servers 的通信。
MCP Server 对外开放特定能力,并提供对数据源的访问权限,包括:
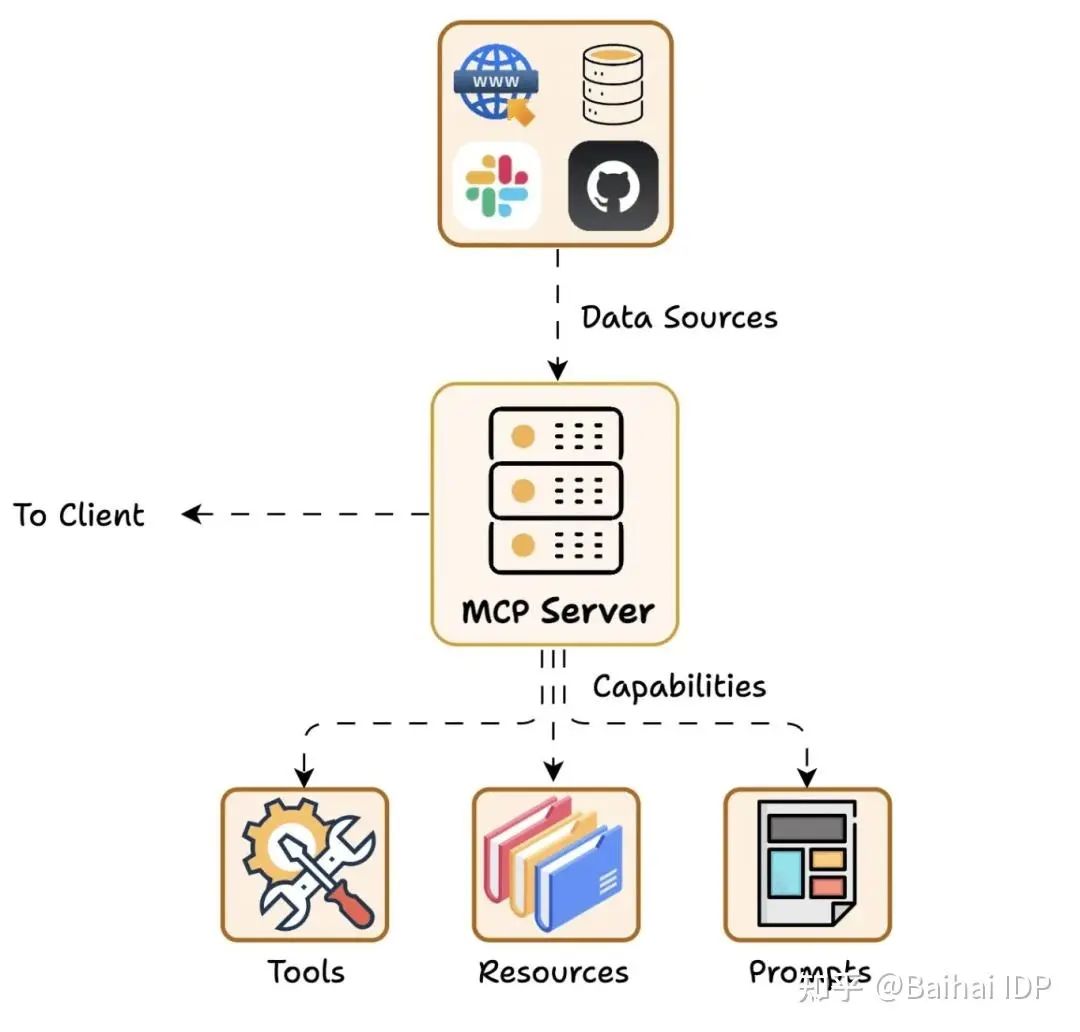
MCP Server 包括:
- Tools:使大语言模型能够通过你的 Server 执行操作。
- Resources:将 Server 上的数据和内容开放给大语言模型。
- Prompts:创建可复用的提示词模板和工作流程。
要构建属于你自己的 MCP 系统,理解客户端-服务器通信机制是必不可少的。
动态服务发现与适配机制
MCP Server 和 MCP Client 之间,是 一种 动态服务发现与适配机制,也叫做 能力交换 Capability Exchange 机制
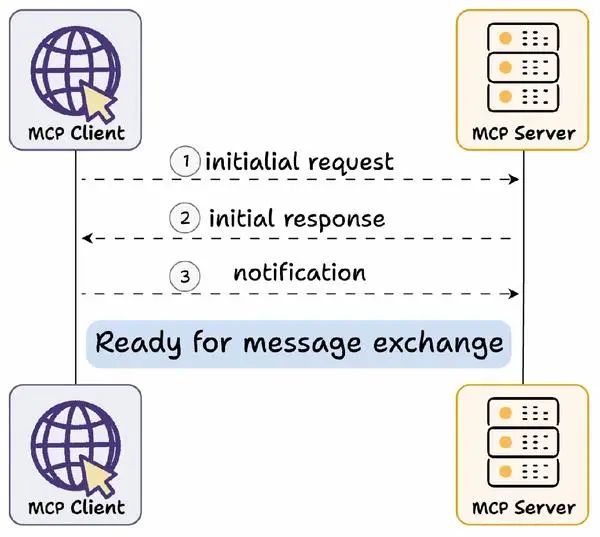
首先进行 Capability Exchange(译者注:Capability Exchange(能力交换)是一种动态服务发现与适配机制,是MCP连接建立的必经步骤,类似于“握手协议”。)
Capability Exchange 流程如下:
(1) 客户端发送初始请求,获取服务器能力信息
(2) 服务器返回其能力信息详情
(3) 例如当天气 API 服务器被调用时,它可以返回可用的“tools”、“prompts templates”及其他资源供客户端使用
交换完成后,客户端确认连接成功,然后继续交换消息。
Capability Exchange 流程 具体如何实现呢? MCP协议官方提供了两种主要通信方式:stdio(标准输入输出)和 SSE (Server-Sent Events,服务器发送事件)。
客户端与服务器的通信流程
MCP协议官方提供了两种主要通信方式:stdio(标准输入输出)和 SSE (Server-Sent Events,服务器发送事件)。
这两种方式均采用全双工通信模式,通过独立的读写通道实现服务器消息的实时接收和发送。
什么是SSE Transport?
MCP(Model Context Protocol) 是一个开放协议,旨在标准化应用程序与大型语言模型(LLM)之间的上下文交互。它定义了客户端与服务器如何通过传输层交换消息。
MCP 支持两种标准传输机制:
- **stdio:**通过标准输入输出流进行本地通信。
- **SSE(Server-Sent Events):**通过 HTTP 协议实现服务器到客户端的实时单向数据推送,结合 HTTP POST 用于客户端到服务器的消息发送。
SSE Transport 是 MCP 中基于 HTTP 的传输方式,利用 SSE 技术实现服务器到客户端的流式消息推送,同时通过 HTTP POST 请求处理客户端到服务器的双向通信。
这种机制特别适合需要实时更新或远程通信的场景。
SSE Transport 的工作原理
SSE(Server-Sent Events)是一种基于 HTTP 协议的服务器推送技术,允许服务器向客户端发送实时更新。
MCP 的 SSE Transport 结合了 SSE 和 HTTP POST,形成了以下工作流程:
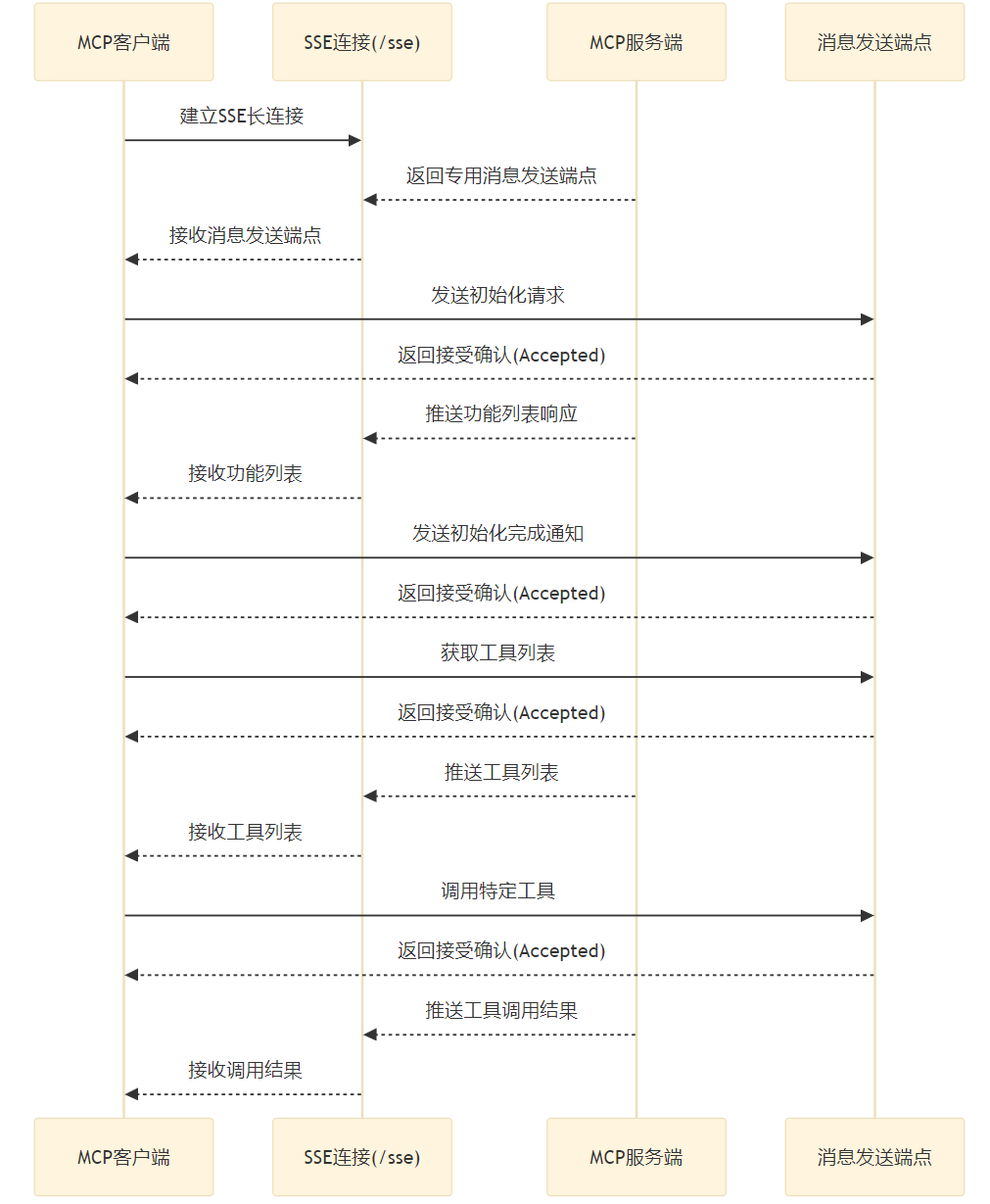
SSE Transport 交互流程
1.建立连接:
- 客户端通过 HTTP GET 请求访问服务器的 SSE 端点(例如 /sse)。
- 服务器响应一个 text/event-stream 类型的内容,保持连接打开。
- 服务器发送一个初始的 endpoint 事件,包含一个唯一的 URI(例如 /messages?session_id=xxx),客户端后续通过这个 URI 发送消息。
2.服务器到客户端的消息推送:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1044
1044

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









