




好的,请看这篇为你准备的 Pydub 技术博客文章。
Pydub 库初探:轻松玩转 Python 音频处理,告别“望声生畏”
经常处理音频的选手一定知道librosa这个著名的音频处理库,但是我们日常的一些工作中,这种库有点小题大作了,因为可能我们只是需要一些简单的淡入淡出,增加音量,音频格式转换等小操作。市面上的音频处理库似乎都有些“高冷”,librosa文档动辄万言,让人望而生畏。其实可以试试pydub,本文带你深入浅出地了解 Pydub 这个对开发者极为友好的 Python 音频处理库。我们将从它的核心概念讲起,逐步深入到常用的 API 和技术细节,目标是让你不仅“知其然”,更能“知其所以然”,在实际项目中游刃有余。
1. Pydub 是什么?为何选择它?
Pydub 是一个高级的 Python 音频处理库,它的核心设计理念就是——简单。它对底层的音频处理逻辑(通常依赖 FFmpeg 或 Libav)进行了优雅的封装,让你能够用非常 Pythonic 的方式来操作音频文件。
什么场景适合 Pydub?
- 快速原型开发:当你需要快速验证一个音频处理想法时,Pydub 的简洁性能让你几行代码就搞定。
- 批量音频处理:格式转换、音量调整、简单剪辑等任务,Pydub 脚本能帮你自动化。
- Web 应用后端:处理用户上传的音频文件,如格式化、片段截取等。
- 音频效果添加:如淡入淡出、反转、叠加等。
- 教学与学习:对于音频处理初学者,Pydub 是一个合适的入门工具。
Pydub 的核心在于其 AudioSegment 对象。你可以把它想象成一段“数字化的录音带”,几乎所有的操作都是围绕这个对象展开的。
Pydub 与其他库(如 Librosa, SoundFile)有何不同?
- Librosa 更侧重于音频分析、特征提取,常用于音乐信息检索和机器学习领域。它的功能更底层、更学术。
- SoundFile 基于
libsndfile库,提供了对多种音频格式的读写能力,但在高级编辑和效果处理方面不如 Pydub 直观。 - Pydub 的优势在于其易用性和对常见音频编辑操作的便捷封装。它不是要取代专业的数字音频工作站 (DAW) 或底层 DSP 库,而是提供一个“瑞士军刀”式的工具,让你快速完成 80% 的日常音频任务。
2. Pydub 核心概念:AudioSegment 对象
AudioSegment 是 Pydub 的灵魂。你可以将一个音频文件加载为一个 AudioSegment 实例,然后像操作 Python 对象一样对其进行各种处理。
核心特性:
- 不可变性 (Immutability):对
AudioSegment对象执行的任何操作(如调整音量、拼接)都会返回一个新的AudioSegment对象,原始对象保持不变。这有助于避免意外修改数据,让代码逻辑更清晰。 - FFmpeg/Libav 依赖:对于 WAV 和 RAW 格式的音频,Pydub 可以原生处理。但对于 MP3、AAC、FLAC 等绝大多数其他格式,Pydub 依赖 FFmpeg 或 Libav 进行解码和编码。所以,在使用 Pydub 前,请确保你的系统中正确安装了 FFmpeg 或 Libav,并将其添加到了系统路径中。
- 参数自动匹配:当合并或叠加多个
AudioSegment对象时,如果它们的声道数、帧率、采样宽度等参数不一致,Pydub 会自动将较低质量的音频转换为较高质量的音频参数,以避免音质损失。例如,单声道会自动转为立体声,采样率会提升。当然,如果你不希望这种行为,也可以手动进行参数调整。
3. Pydub 主要方法与 API 详解
下面我们将深入探讨 AudioSegment 的常用方法和属性,辅以代码示例和技术细节。
3.1 音频的加载与创建
AudioSegment.from_file(file, format=None, parameters...)
这是最常用的加载音频文件的方法。
file: 音频文件路径 (字符串) 或已打开的文件对象。format: (可选) 指定音频格式,如"mp3","wav","flac"。如果省略,Pydub 会尝试自动检测。对于raw格式,必须指定。sample_width,frame_rate,channels: 仅当format="raw"时需要。RAW 音频没有头部信息,因此需要手动提供这些参数。sample_width: 每个采样的字节数 (1: 8-bit, 2: 16-bit, 4: 32-bit)。channels: 声道数 (1: 单声道, 2: 立体声)。frame_rate: 帧率/采样率 (Hz),如 44100 (CD音质), 48000 (DVD音质)。
start_second,duration: (可选) 指定加载音频的起始秒数和持续时长(秒)。
from pydub import AudioSegment
# 加载 WAV 文件 (Pydub 原生支持,无需 FFmpeg)
sound_wav = AudioSegment.from_file("audio/sound.wav", format="wav")
# 加载 MP3 文件 (需要 FFmpeg)
sound_mp3 = AudioSegment.from_file("audio/sound.mp3") # 自动检测 format
# 加载 RAW 音频
# 假设是 16-bit, 44.1kHz, 立体声
# raw_audio_data = b'...' # 你的原始字节数据
# sound_raw = AudioSegment.from_file("audio/sound.raw", format="raw",
# sample_width=2, frame_rate=44100, channels=2)
# 从文件对象加载
with open("audio/another.ogg", "rb") as ogg_file:
sound_ogg = AudioSegment.from_file(ogg_file, format="ogg")
# 加载音频的前5秒
partial_sound = AudioSegment.from_file("audio/long_sound.mp3", duration=5.0)
# 从第2秒开始加载,加载3秒
partial_sound_offset = AudioSegment.from_file("audio/long_sound.mp3", start_second=2.0, duration=3.0)
Pydub 还提供了一些便捷的加载方法,如 AudioSegment.from_mp3(), AudioSegment.from_wav() 等,它们内部实际上还是调用的 from_file()。
AudioSegment(data=b'...', sample_width=2, frame_rate=44100, channels=2)
如果你拥有原始的音频字节数据 (raw audio data),可以使用 AudioSegment 的构造函数直接创建对象。参数与加载 raw 文件时类似。
# 假设有原始PCM数据
raw_data = b'\x00\x00\x01\x01\x02\x02...' # 示例数据
audio_segment = AudioSegment(
data=raw_data,
sample_width=2, # 16-bit
frame_rate=44100, # 44.1 kHz
channels=1 # Mono
)
AudioSegment.empty()
创建一个零长度的 AudioSegment。常用于循环中累积音频片段。
empty_segment = AudioSegment.empty()
print(f"空片段长度: {len(empty_segment)} ms") # 输出 0
sounds = [
AudioSegment.from_wav("audio/part1.wav"),
AudioSegment.from_wav("audio/part2.wav"),
]
playlist = AudioSegment.empty()
for sound in sounds:
playlist += sound
AudioSegment.silent(duration=1000, frame_rate=11025)
创建一个指定长度(毫秒)和帧率的静音 AudioSegment。可用作占位符、间隔或叠加其他声音的画布。
# 创建一个3秒的静音片段,使用 44.1kHz 帧率
silence_3s = AudioSegment.silent(duration=3000, frame_rate=44100)
3.2 音频的导出
audio_segment.export(out_f, format="mp3", bitrate="192k", tags=None, parameters=None, cover=None, ...)
将 AudioSegment 对象写入文件或文件对象。
out_f: 输出文件路径 (字符串) 或可写的文件对象。format: 输出格式,默认为"mp3"。"wav"和"raw"原生支持,其他格式需要 FFmpeg。bitrate: (可选) 压缩格式的比特率,如"128k","192k","320k"。具体可用值取决于 FFmpeg 和所选编解码器。codec: (可选) 指定编码器,如 OGG 格式常用"libvorbis"。tags: (可选) 一个字典,用于设置媒体信息标签 (如专辑、艺术家),主要对 MP3 等格式有效。parameters: (可选) 一个列表,传递给 FFmpeg 的额外命令行参数。例如["-ac", "1"]强制单声道输出。id3v2_version: (可选) 设置 ID3v2 版本,如"3"(对 Windows Explorer 兼容性更好)。cover: (可选) 专辑封面图片路径 (jpg, png, bmp, tiff)。目前主要用于 MP3。
sound = AudioSegment.from_file("audio/my_song.wav")
# 简单导出为 MP3
sound.export("output/my_song_exported.mp3", format="mp3")
# 复杂导出,带比特率和标签
sound.export("output/my_song_tagged.mp3",
format="mp3",
bitrate="256k",
tags={"artist": "My Band", "album": "My Album", "title": "My Song"},
cover="images/album_cover.jpg")
# 导出到文件对象
with open("output/my_song_output.ogg", "wb") as f:
sound.export(f, format="ogg", codec="libvorbis")
3.3 AudioSegment 核心属性
这些属性提供了音频段的基本信息。
len(audio_segment)或audio_segment.duration_seconds:len(audio_segment): 返回音频时长,单位是毫秒。audio_segment.duration_seconds: 返回音频时长,单位是秒 (内部调用len())。
audio_segment.channels: 声道数 (1: 单声道, 2: 立体声)。audio_segment.frame_rate: 帧率/采样率 (Hz)。例如 44100。audio_segment.sample_width: 采样宽度,即每个采样的字节数 (1: 8-bit, 2: 16-bit, 4: 32-bit)。CD 音质是 16-bit,所以sample_width为 2。audio_segment.frame_width: 每帧的字节数。等于channels * sample_width。例如 CD 音质 (立体声, 16-bit):2 * 2 = 4字节/帧。audio_segment.dBFS: 音频的平均响度,单位是 dBFS (相对于最大可能响度的分贝数)。一个最大幅度的方波大约是 0 dBFS,一个最大幅度的正弦波大约是 -3 dBFS。audio_segment.rms: 音频的均方根振幅,响度的一种度量。dBFS是基于rms计算的对数度量,更符合人耳感知。audio_segment.max: 音频段中所有采样的最大振幅值。audio_segment.max_dBFS: 音频段中采样的峰值响度 (dBFS)。常用于标准化(Normalization)。audio_segment.raw_data: 返回音频段的原始字节数据 (bytes类型)。当你需要与其他音频库或底层 API 交互时非常有用。
sound = AudioSegment.from_file("audio/stereo_sound.wav")
print(f"时长 (ms): {len(sound)}")
print(f"时长 (s): {sound.duration_seconds}")
print(f"声道数: {sound.channels}")
print(f"帧率: {sound.frame_rate} Hz")
print(f"采样宽度: {sound.sample_width} bytes")
print(f"帧宽度: {sound.frame_width} bytes")
print(f"平均响度 (dBFS): {sound.dBFS:.2f} dBFS")
print(f"峰值响度 (dBFS): {sound.max_dBFS:.2f} dBFS")
# print(f"原始数据前10字节: {sound.raw_data[:10]}")
3.4 基本音频操作
由于 AudioSegment 的不可变性,以下所有操作都会返回一个新的 AudioSegment 对象。
-
拼接 (Concatenation):
sound1 + sound2或sound1.append(sound2, crossfade=100)- 将
sound2附加到sound1的末尾。 - 默认使用 100 毫秒的交叉淡入淡出 (crossfade) 来避免拼接处的爆音。
crossfade参数可以指定交叉淡化的时长 (毫秒)。设为0则不使用交叉淡化。
intro = AudioSegment.from_file("audio/intro.mp3") main_part = AudioSegment.from_file("audio/main.mp3") # 使用 + 运算符拼接 (默认100ms交叉淡化) full_song = intro + main_part # 使用 append 方法,并指定500ms交叉淡化 full_song_long_crossfade = intro.append(main_part, crossfade=500) # 无交叉淡化 full_song_no_crossfade = intro.append(main_part, crossfade=0) - 将
-
重复 (Repetition):
sound * N- 将
sound重复N次。
clap = AudioSegment.from_file("audio/clap.wav") three_claps = clap * 3 - 将
-
切片 (Slicing):
sound[start_ms:end_ms]- 获取音频的一部分,单位是毫秒。支持标准的 Python 切片语法。
long_audio = AudioSegment.from_file("audio/long_speech.mp3") # 获取前5秒 first_5_seconds = long_audio[:5000] # 获取最后3秒 last_3_seconds = long_audio[-3000:] # 获取第10秒到第15秒 (索引从10000ms到15000ms) middle_segment = long_audio[10000:15000] # 每隔10秒取一个片段 (这里仅演示语法,实际应用需注意片段长度) # slices = long_audio[::10000] -
音量调整 (Gain Adjustment):
sound + X或sound - X或sound.apply_gain(X)X是分贝 (dB) 值。正值增加音量,负值减小音量。+3dB大约是音量翻倍,-3dB大约是音量减半。
voice = AudioSegment.from_file("audio/voice_recording.wav") # 增加 6 dB louder_voice = voice + 6 # 或者 # louder_voice = voice.apply_gain(6) # 减小 3.5 dB quieter_voice = voice - 3.5 # 或者 # quieter_voice = voice.apply_gain(-3.5) -
叠加/混音 (Overlay):
sound1.overlay(sound2, position=0, loop=False, times=1, gain_during_overlay=0)- 将
sound2叠加到sound1上,它们将同时播放。 - 结果音频的长度通常与
sound1相同。如果sound2更长,超出部分会被截断。 position:sound2开始叠加的时间点 (毫秒),相对于sound1的开头。loop: (布尔值) 如果True,sound2将在sound1的持续时间内循环播放。times: (整数)sound2将重复播放的次数。即使重复次数很多,最终长度仍受限于sound1。gain_during_overlay: (dB) 在叠加sound2期间,sound1的音量变化。例如,设为-6可以在播放背景音乐时让人声更清晰。
background_music = AudioSegment.from_file("audio/background.mp3") narration = AudioSegment.from_file("audio/narration.wav") # 将旁白叠加到背景音乐开头 mixed_simple = background_music.overlay(narration) # 旁白在背景音乐播放5秒后开始 mixed_delayed = background_music.overlay(narration, position=5000) # 叠加时,背景音乐降低音量 8dB mixed_ducking = background_music.overlay(narration, position=2000, gain_during_overlay=-8) # 假设背景音乐30秒,一个5秒的音效循环播放 short_effect = AudioSegment.silent(duration=5000) + 3 # 创建一个带内容的短音效 # effect_loop = background_music.overlay(short_effect, loop=True) effect_multiple_times = background_music.overlay(short_effect, times=4, position=1000) - 将
3.5 格式与属性转换
set_sample_width(width): 改变采样宽度。增加通常不损失质量,减少则会。set_frame_rate(rate): 改变帧率。增加通常不损失质量,减少则会。set_channels(num_channels): 改变声道数。单声道转立体声通常听不出变化,立体声转单声道可能因左右声道混合而损失信息(如果左右声道不同)。
sound_16bit_44k_stereo = AudioSegment.from_file("audio/standard.wav")
# 转为 8-bit (质量下降)
sound_8bit = sound_16bit_44k_stereo.set_sample_width(1)
# 转为 22.05 kHz (高频信息可能丢失)
sound_22k = sound_16bit_44k_stereo.set_frame_rate(22050)
# 转为单声道
sound_mono = sound_16bit_44k_stereo.set_channels(1)
3.6 声道操作
split_to_mono(): 将立体声AudioSegment分割为两个单声道AudioSegment对象(左声道和右声道),返回一个列表[left_channel, right_channel]。AudioSegment.from_mono_audiosegments(left_segment, right_segment, ...): 从两个或多个单声道AudioSegment创建一个多声道(通常是立体声)AudioSegment。所有输入的单声道片段长度必须完全一致。apply_gain_stereo(left_db, right_db): 分别调整立体声左右声道的音量。如果原音频是单声道,会自动转为立体声再处理。pan(pan_amount): 声像摇摆。pan_amount从 -1.0 (完全左) 到 +1.0 (完全右)。0.0 表示居中。摇摄时会调整另一声道的音量以保持感知响度大致不变。例如,摇到最左时,左声道音量 +3dB,右声道静音。
stereo_sound = AudioSegment.from_file("audio/stereo_mix.wav")
if stereo_sound.channels == 2:
mono_channels = stereo_sound.split_to_mono()
left_channel = mono_channels[0]
right_channel = mono_channels[1]
# 仅让左声道响度增加3dB
# new_left = left_channel + 3
# re_combined_stereo = AudioSegment.from_mono_audiosegments(new_left, right_channel)
# 将左声道降低6dB,右声道增加2dB
balanced_sound = stereo_sound.apply_gain_stereo(-6, +2)
# 将声音向右摇摄30%
panned_right_30_percent = stereo_sound.pan(+0.3)
# 将声音完全摇到左边
panned_hard_left = stereo_sound.pan(-1.0)
3.7 音频效果 (Effects)
Pydub 提供了一些内置效果,更多效果位于 pydub.effects 模块。
-
fade(to_gain=0, from_gain=0, start=None, end=None, duration=None): 通用淡化效果。to_gain: 淡化结束时的目标增益 (dB)。from_gain: 淡化开始时的起始增益 (dB)。- 可以指定
start和end(毫秒),或start/end之一配合duration(毫秒)。
-
fade_in(duration)/fade_out(duration): 便捷的从静音淡入或淡出到静音。内部调用fade()。-120dB通常被认为是静音。song = AudioSegment.from_file("audio/my_track.mp3") # 5秒淡入 song_faded_in = song.fade_in(duration=5000) # 最后10秒淡出 song_faded_out = song.fade_out(duration=10000) # 注意:这里是修改整个片段使其尾部淡出 # 更复杂的淡化:从第5秒开始,用3秒时间,将音量从当前提升到 +6dB # complex_fade = song.fade(to_gain=6.0, start=5000, duration=3000) -
reverse(): 反转音频,使其倒放。reversed_sound = sound.reverse() -
invert_phase(): 反转音频信号的相位。可用于产生反相波以进行噪声抑制或抵消(需要精确对齐)。antiphase_sound = sound.invert_phase() -
pydub.effects.normalize(audio_segment, headroom=0.1): 标准化音量,使音频峰值达到某个目标水平(默认略低于 0dBFS,headroom控制这个余量)。from pydub.effects import normalize normalized_sound = normalize(sound)
3.8 静音处理 (Silence Utilities - pydub.silence)
pydub.silence 模块提供了一些检测和处理音频中静音部分的实用函数。
-
detect_silence(audio_segment, min_silence_len=1000, silence_thresh=-16, seek_step=1):- 检测音频中的静音段。返回一个列表,每个元素是
[start_ms, end_ms]表示静音段的起止时间。 min_silence_len: 静音段的最小长度 (毫秒)。silence_thresh: 静音的 dBFS 阈值。低于此值的视为静音。seek_step: 检测步长 (毫秒)。越小越精确,但越慢。
- 检测音频中的静音段。返回一个列表,每个元素是
-
detect_nonsilent(audio_segment, ...): 与detect_silence相反,检测非静音段。参数相同。 -
split_on_silence(audio_segment, min_silence_len=1000, silence_thresh=-16, keep_silence=100, seek_step=1):- 根据静音段分割音频。返回一个
AudioSegment对象列表。 keep_silence: (毫秒或布尔值) 在分割出的片段前后保留多少静音。True保留所有,False不保留。数字表示保留时长。
- 根据静音段分割音频。返回一个
-
detect_leading_silence(audio_segment, silence_thresh=-50, chunk_size=10):- 检测并返回音频开头静音部分的结束时间点 (毫秒)。
from pydub import AudioSegment, silence
speech = AudioSegment.from_file("audio/long_speech_with_pauses.mp3")
# 检测超过2秒,响度低于-40dBFS的静音段
silent_parts = silence.detect_silence(speech, min_silence_len=2000, silence_thresh=-40)
# silent_parts might be: [[5200, 7500], [12300, 15000]]
# 根据静音分割语音,保留每段前后200ms的静音
speech_segments = silence.split_on_silence(
speech,
min_silence_len=500, # 至少0.5秒的静音才分割
silence_thresh=-35, # 低于-35dBFS算静音
keep_silence=200 # 保留200ms静音
)
# for i, segment in enumerate(speech_segments):
# segment.export(f"output/speech_segment_{i}.mp3", format="mp3")
# 移除开头的静音 (直到响度高于-45dBFS)
trimmed_speech = speech[silence.detect_leading_silence(speech, silence_thresh=-45):]
3.9 高级:获取与处理原始样本数据
get_array_of_samples(): 返回一个array.array对象,包含原始的数字采样点。如果音频是多声道的,采样点会交错排列,例如立体声:[L1, R1, L2, R2, ...]。这主要用于自定义效果或与其他需要数字样本数组的库(如 NumPy/SciPy)集成。_spawn(data_array): (通常是内部方法)用新的样本数组创建一个新的AudioSegment对象,其他参数(如帧率、声道数)与原对象相同。
import array
import numpy as np
sound = AudioSegment.from_file("audio/some_sound.wav")
samples = sound.get_array_of_samples() # array.array object
# 示例:将所有采样值减半 (音量减小,可能引入量化噪声)
# 注意:这是一个非常简化的例子,实际音量处理应在dBFS域进行
# modified_samples_list = [s // 2 for s in samples]
# modified_samples = array.array(sound.array_type, modified_samples_list)
# new_sound_half_volume = sound._spawn(modified_samples)
# 与 NumPy 集成 (更复杂,但更强大)
# 将 Pydub samples 转为 NumPy array
numpy_samples = np.array(samples)
# 假设做了一些 NumPy 操作...
# shifted_samples_np = np.right_shift(numpy_samples, 1) # 示例操作
# 将 NumPy array 转回 Pydub array.array
# modified_samples_back_to_array = array.array(sound.array_type, shifted_samples_np)
# new_sound_numpy_processed = sound._spawn(modified_samples_back_to_array)
# 更专业的 Pydub -> NumPy float32 转换 (适用于信号处理)
# if sound.channels > 1:
# channel_sounds = sound.split_to_mono()
# samples_per_channel = [s.get_array_of_samples() for s in channel_sounds]
# fp_arr = np.array(samples_per_channel).T.astype(np.float32)
# else: # Mono
# fp_arr = np.array(sound.get_array_of_samples()).astype(np.float32)
# fp_arr /= np.iinfo(samples[0].typecode).max # Normalize to [-1.0, 1.0] range
# NumPy float32 -> Pydub (通过WAV IO)
# import io
# import scipy.io.wavfile
# wav_io = io.BytesIO()
# scipy.io.wavfile.write(wav_io, sound.frame_rate, (fp_arr * np.iinfo(samples[0].typecode).max).astype(samples[0].typecode))
# wav_io.seek(0)
# sound_from_numpy = AudioSegment.from_wav(wav_io)
注意: 直接操作样本数组需要对数字信号处理有一定了解,否则很容易产生不期望的结果或失真。对于常见任务,优先使用 Pydub 内建的方法。
4. Pydub 实用指南与最佳实践
- 环境配置:
pip install pydub- 安装 FFmpeg 或 Libav:这是最关键的一步。确保它们已安装并且其可执行文件路径在系统的
PATH环境变量中。- Windows: 下载预编译包,解压并将
bin目录添加到 PATH。 - macOS:
brew install ffmpeg - Linux:
sudo apt-get install ffmpeg或sudo yum install ffmpeg
- Windows: 下载预编译包,解压并将
- 性能考虑:
- Pydub 为了易用性牺牲了一部分性能。对于超大规模或实时性要求极高的处理,可能需要更底层的库。
- 涉及 FFmpeg 的操作(如非 WAV/RAW 的加载导出、一些效果)会有额外的进程调用开销。
- 内存使用:
AudioSegment对象将整个音频数据加载到内存中。处理非常长的音频文件时要注意内存消耗。可以考虑分块处理。 - 不可变性的好处与处理:由于
AudioSegment不可变,链式操作非常安全:
final_sound = sound.fade_in(1000).apply_gain(-3).overlay(another_sound).fade_out(2000) - 何时选择 Pydub:
- 适合:快速脚本、音频格式转换、基本剪辑、音量调整、简单效果、Web 后端音频预处理。
- 可能不是最佳选择:复杂的实时音频分析、精确的频域操作(虽然可以通过
get_array_of_samples配合 NumPy/SciPy 实现,但 Pydub 本身不直接提供这些工具)、低延迟音频流处理。
5. Pydub 背景与渊源
Pydub 由 James Robert 从 2011 年左右开始开发,旨在提供一种简单直观的方式来处理音频,而无需深入了解 FFmpeg 的复杂命令行或底层音频编码细节。它的出现极大地降低了 Python 开发者进行音频处理的门槛,让许多原本需要复杂工具或专业知识的任务变得触手可及。Pydub 很好地体现了 Python “batteries included” 和追求简洁优雅的哲学。
6. 总结与关键点回顾
Pydub 是一个强大且易用的 Python 音频处理库,它通过简洁的 API 封装了复杂的底层操作。
核心要点:
AudioSegment是核心:所有操作围绕这个不可变对象进行。- FFmpeg/Libav 是强大后盾:处理 WAV/RAW 以外的大多数格式依赖它们。务必正确安装。
- 易用性优先:Pythonic 的接口,链式操作,参数自动匹配。
- 常用操作覆盖全面:加载、导出、剪辑、拼接、音量调整、淡入淡出、叠加、格式转换等一应俱全。
- 适用于快速开发和常见任务:是音频处理入门和完成日常任务的绝佳选择。
一句话总结:Pydub 让你用写 Python 代码的流畅感,轻松实现对音频的各种“魔法”操作。
不过现在这个pydub库也没有继续维护了,不知道现在业界更加流行和高可用的库是什么,如果有的话,请万能的道友留言指点一二,祝好!
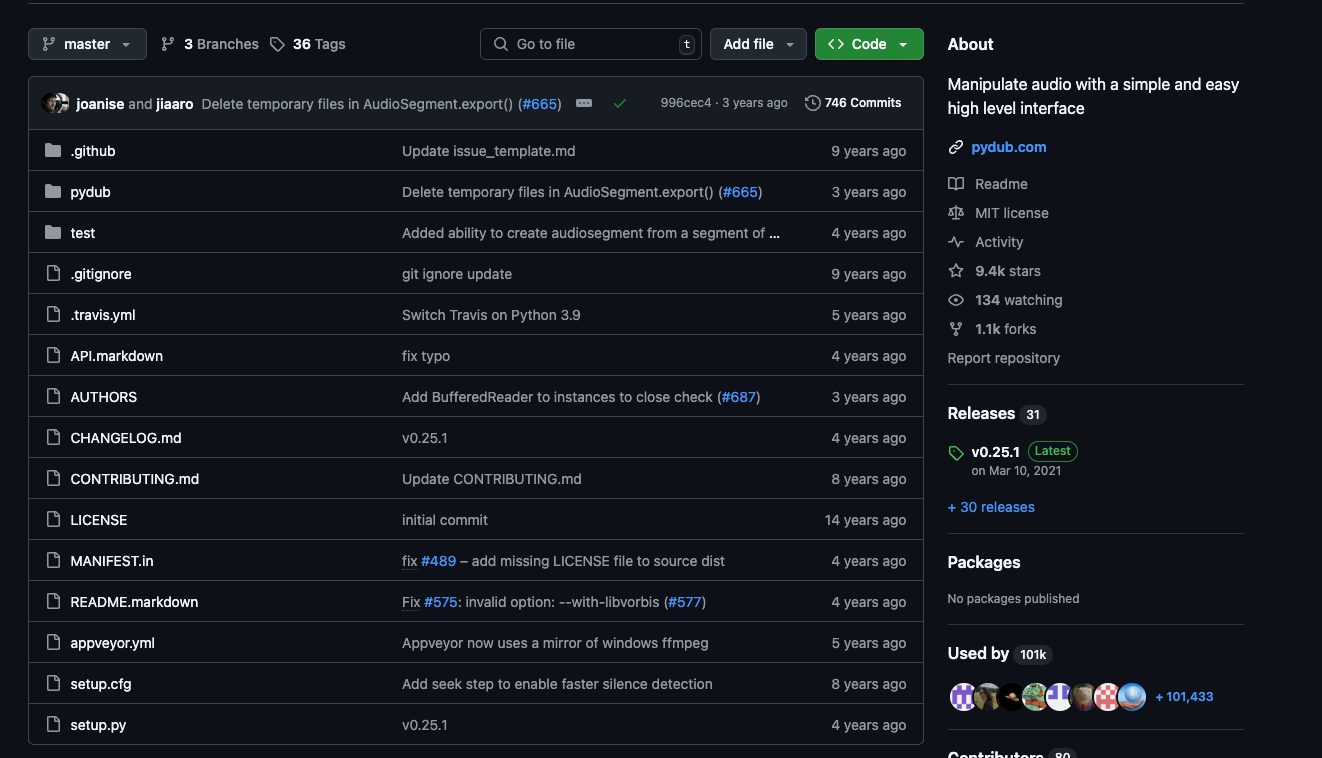
维护记录都是几年前的了


















 4834
4834

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









