




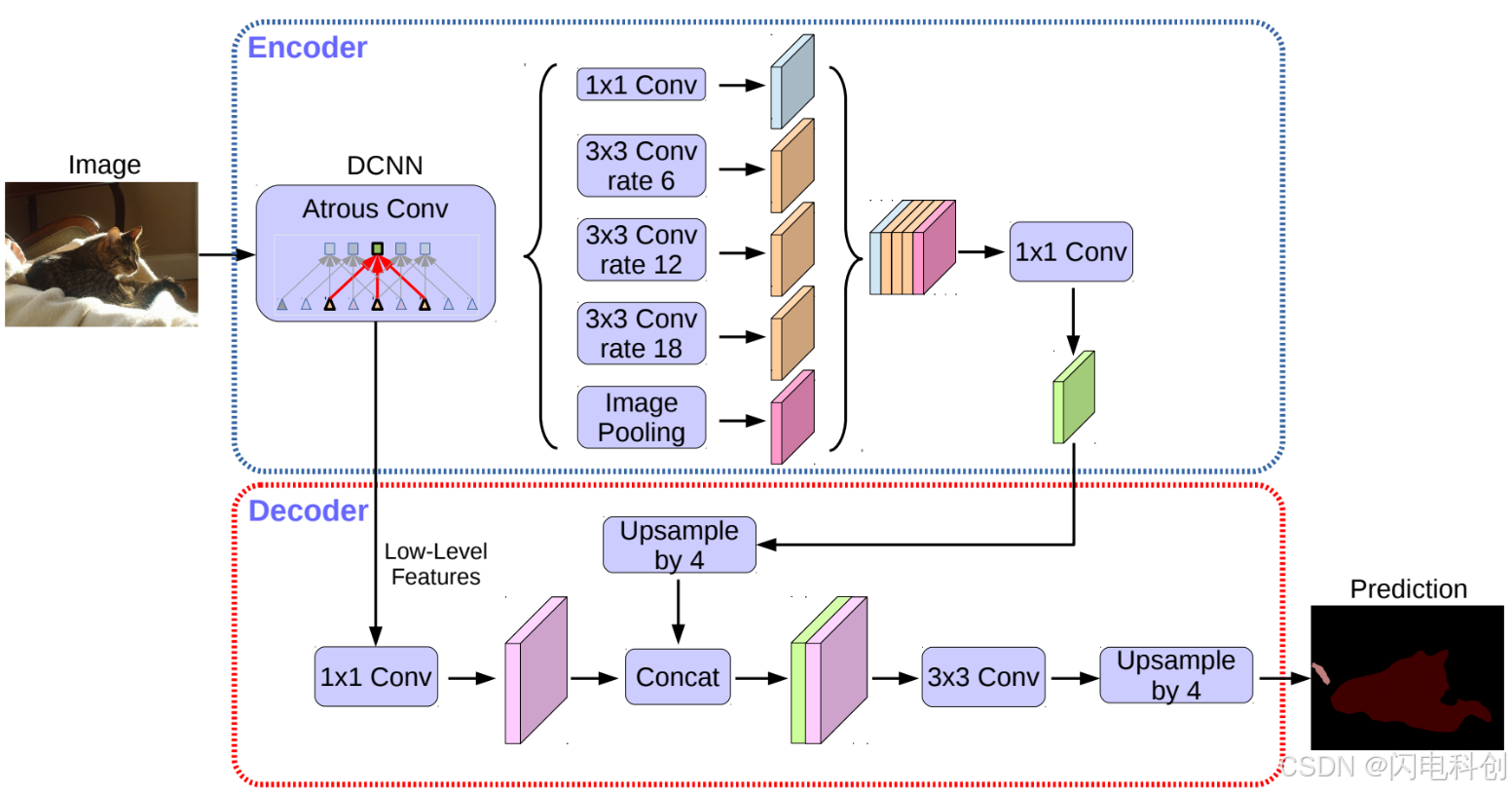
DeepLabV3+ 分割算法的改进思路
DeepLabV3+ 是一款基于深度学习的语义图像分割算法,是 DeepLab 系列的最新版本。该算法由 Google Research 提出,主要用于解决图像中的像素级别的分类问题,如人脸、物体、场景等的分割。相较于以前的版本,DeepLabV3+ 在多个方面进行了创新和改进,尤其在处理高分辨率图像和复杂场景时,取得了显著的效果提升。以下将从多个方面详细介绍 DeepLabV3+ 的改进思路和核心思想。
1. 引入空洞卷积(Dilated Convolution)
空洞卷积是 DeepLab 系列算法中的核心组件,尤其在 DeepLabV3 和 DeepLabV3+ 中得到了进一步的优化。空洞卷积(也叫扩张卷积)通过在卷积核中插入空洞(即不连接的像素点)来增加感受野,而不增加计算量。这一机制对于提升卷积神经网络的空间感知能力非常重要,尤其在图像分割中,空洞卷积能够让模型更好地捕捉到图像中的长距离上下文信息。
在传统卷积中,卷积核是连续的,感受野受到卷积核大小的限制。而在空洞卷积中,通过空洞的引入,感受野可以显著扩大,这使得网络能够处理更大范围的图像信息,从而获得更多的上下文信息,这对于图像分割任务至关重要,因为分割任务通常需要根据较大的区域来推测每个像素的类别。
DeepLabV3+ 在此基础上使用了 空洞空间金字塔池化(ASPP),这种技术结合了不同大小的空洞卷积来增强不同尺度的特征提取能力。ASPP 使用了多种不同的空洞率,这使得网络能够有效地处理不同尺寸的物体,提升了模型对复杂场景和物体的分割能力。
2. 引入编码器-解码器结构
DeepLabV3+ 的另一个显著改进是引入了 编码器-解码器结构
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1892
1892

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











