




目录
1.系统环境:
ORACLE 19C RAC+DG+LINUX7.9
备份在DG上备份,减少主库压力
2.问题现象:
一朋友下午直接给我说,今天数据库备份一天都成功,是不是昨天表空间在dg库没有加起呢?
我想想,昨天晚上对方报UNDO表空间满了,因此,加了一个数据文件,按理,备库应该自动同步,但没有检查,这个是有可能的导致备库不同步,然后让备份失败:
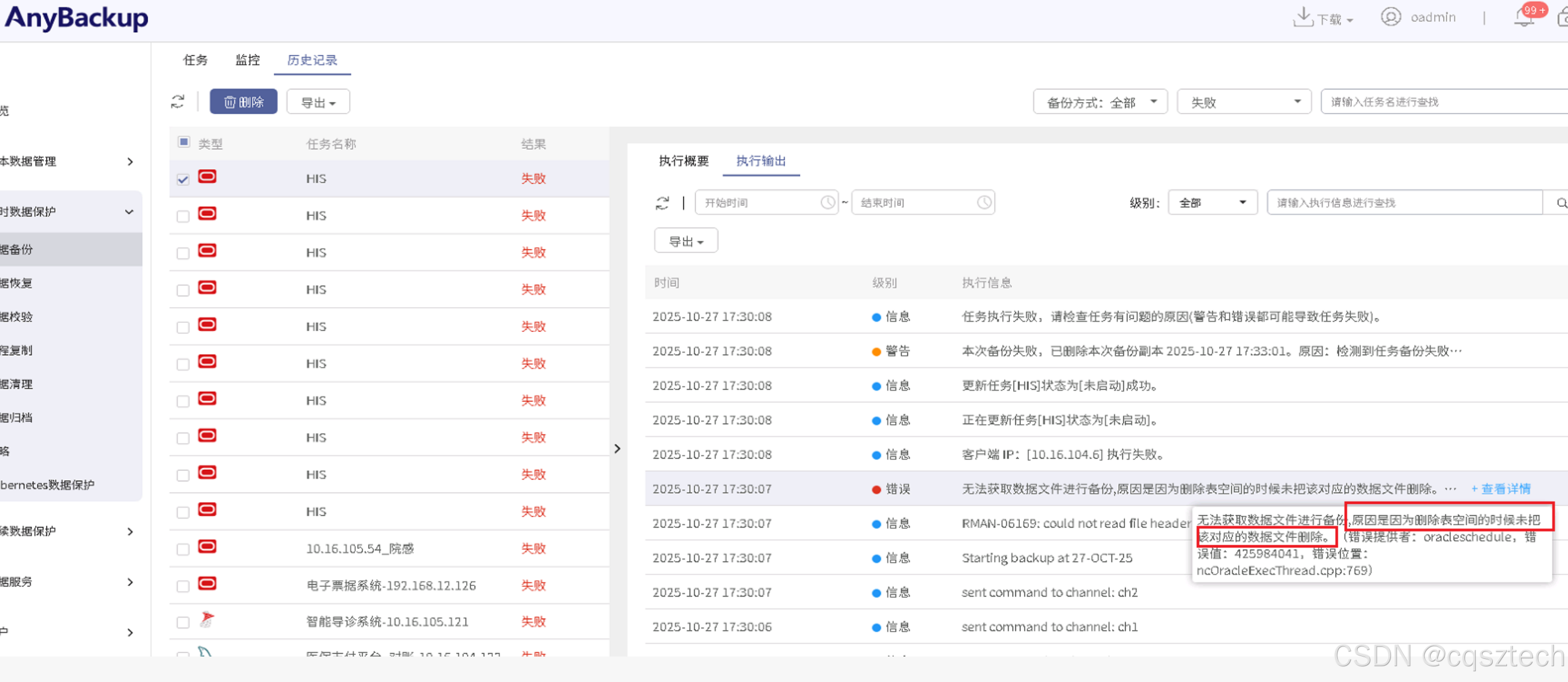
3.问题分析及处理过程:
看到备份失败中,有无法读取文件 ,RMAN-06169 等信息,凭直觉,发现有文件读不出来有关,于是赶紧进入备库去看。
首先看备库状态:
select open_mode from v$database;
open_mode
----------------------------
open read only
有点奇怪,怎么变成只读了呢,但只读不影响备份呀!
赶紧看日志,发现日志中,报警归档失败:
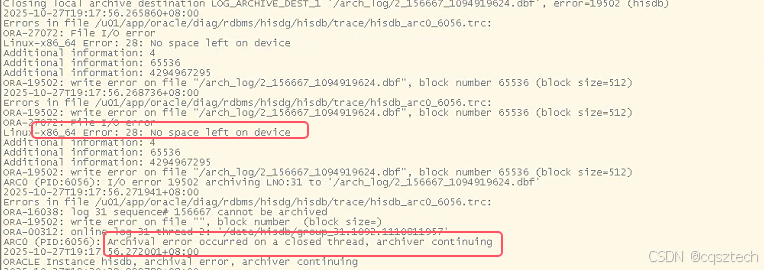
没有空间了,赶紧看磁盘
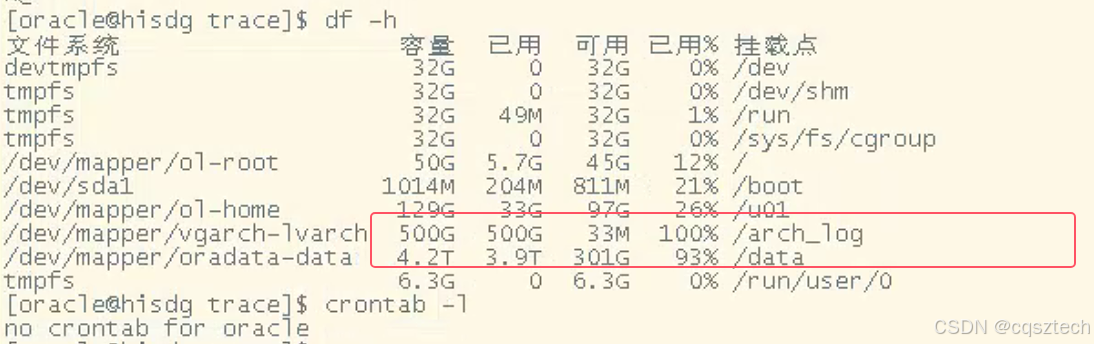
发现归档日志 /arch_log 挂载空间使用 100%
看来没有备份成功,导致归档日志没有成功删除,最后,把归档日志空间也撑爆了。
那要不加磁盘空间,要不删除部分日志。
马上加空间,有点来不及,看能否可以删除日志。
如何确定删哪些日志呢,不要删错了。
1.先看看归档日志最早时间是多久?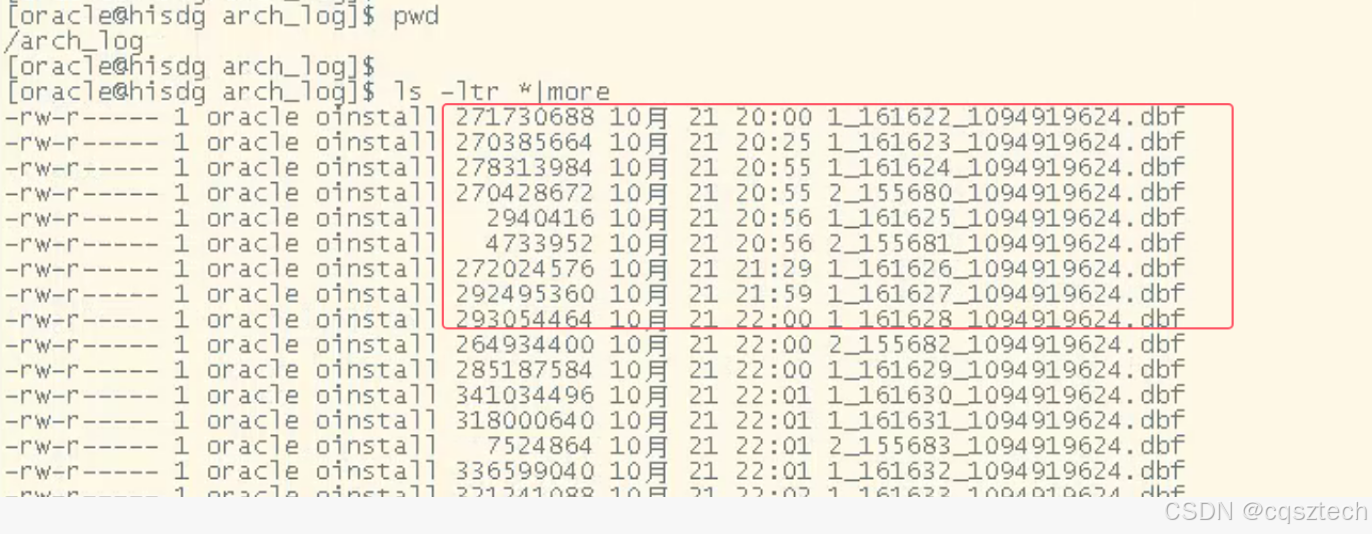
看来是21日
2.那日志应用最近的时间是多久呢?
SQL> select sequence#,applied,to_char(first_time,'yyyy-mm-dd hh24:mi:ss') from v$archived_log where first_time>sysdate-1 order by 3;
SEQUENCE# APPLIED TO_CHAR(FIRST_TIME,
---------- --------- -------------------
162854 YES 2025-10-26 22:59:26
156646 YES 2025-10-26 22:59:31
162855 YES 2025-10-26 23:00:27
162856 YES 2025-10-26 23:01:27
162857 YES 2025-10-26 23:02:30
156647 YES 2025-10-26 23:02:31
162858 YES 2025-10-26 23:03:33
162859 YES 2025-10-26 23:04:36
162860 YES 2025-10-26 23:05:36
156648 YES 2025-10-26 23:05:37
162861 YES 2025-10-26 23:06:39
SEQUENCE# APPLIED TO_CHAR(FIRST_TIME,
---------- --------- -------------------
162862 YES 2025-10-26 23:07:42
162863 YES 2025-10-26 23:08:45
156649 YES 2025-10-26 23:08:46
162864 YES 2025-10-26 23:09:51
162865 YES 2025-10-26 23:10:45
162866 YES 2025-10-26 23:11:48
156650 YES 2025-10-26 23:11:49
162867 YES 2025-10-26 23:13:12
162868 YES 2025-10-26 23:14:27
162869 YES 2025-10-26 23:15:42
156651 YES 2025-10-26 23:15:43
SEQUENCE# APPLIED TO_CHAR(FIRST_TIME,
---------- --------- -------------------
162870 YES 2025-10-26 23:16:57
162871 YES 2025-10-26 23:18:16
162872 YES 2025-10-26 23:19:34
156652 YES 2025-10-26 23:19:34
162873 YES 2025-10-26 23:20:49
162874 NO 2025-10-26 23:22:07
...
看来是从主库加文件后,不再同步
那可以把26日之前的日志进行删除
使用rman进行删除
rman target /
delete archivelog all until time 'sysdate-3';
删除后,有空间了,再去启动数据库日志应用,依然无法应用,
检查日志,发现以下错误:
。。。
2025-10-27T19:37:41.441777+08:00
Errors in file /u01/app/oracle/diag/rdbms/hisdg/hisdb/trace/hisdb_mz00_4844.trc:
ORA-01110: data file 228: '/u01/app/oracle/product/19.0.0/db_1/dbs/UNNAMED00228'
ORA-01565: error in identifying file '/u01/app/oracle/product/19.0.0/db_1/dbs/UNNAMED00228'
ORA-27037: unable to obtain file status
Linux-x86_64 Error: 2: No such file or directory
Additional information: 7
看来昨天加的日志文件没有过来。
到备库,对应文件变成了 /u01/app/oracle/product/19.0.0/db_1/dbs/UNNAMED00228
当然,无法备份。
看参数CONVERT

有这个参数,但我昨天加文件时,使用的是
alter tablespace undotbs1 add datafile '+data' size 1g autoextend on;
应该是路径有问题,再看db_create_file_dest;

有参数的,那应该没有问题才对,再看最开始报错时的日志:
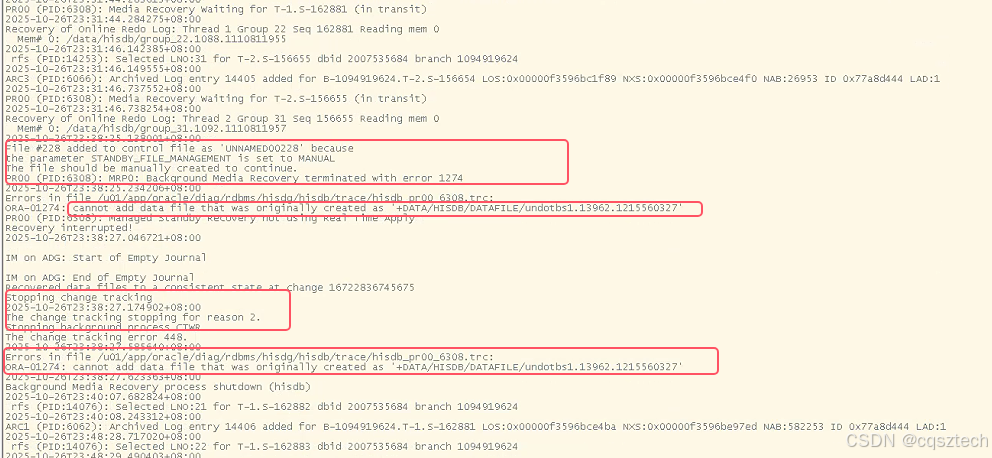
可以看到,是因为standby_file_management=manual,导致文件需要手工添加,但备库是文件系统,没有ASM,所以+DATA这种文件无法添加,同时,因为这个原因,导致备库的实时恢复也停了,而且块改变跟踪也停了,爱数备份,在DG备库,依赖块改变跟踪,所以,也可以解释通了,备份无法备份的原因了。
同时,这里看到文件没有在备份加的原因,就是 STANDBY_FILE_MANAGEMTN的原因。
看看当前该参数的值:
SQL> show parameter standby_file
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
standby_file_management string MANUAL
SQL>
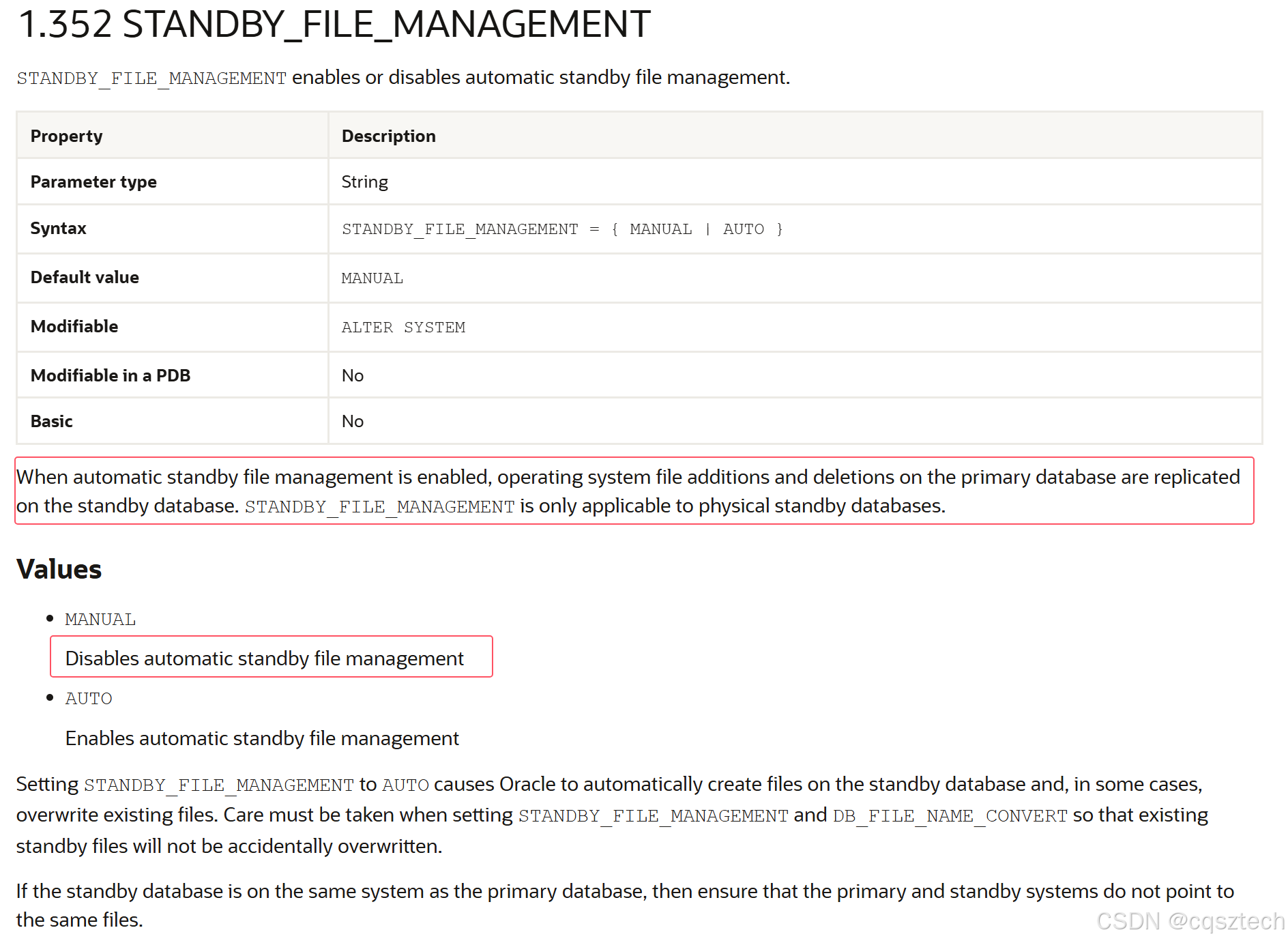
看来打错已经造成,赶紧处理这个unname文件
解决办法:
alter database create datafile '/u01/app/oracle/product/19.0.0/db_1/dbs/UNNAMED00228' as '/data/hisdb/datafile/undotbs1.13962.1215560327';
select name ,file# from v$datafile where file#=228;
NAME FILE#
-------------------------------------------------------------------------------- -------
/data/hisdb/datafile/undotbs1.13962.1215560327
select file#,name ,status from v$datafile where status='RECOVER';
FILE# NAME status
---------- -------------------------------------------------------------------------------------------------------
228 /u01/app/oracle/product/19.0.0/db_1/dbs/UNNAMED00228 RECOVER
执行日志恢复即可:
alter database recover managed standby database using current logfile disconnect from session;
之后,就正常了。
select file#,name ,status from v$datafile where ; file#=228
FILE# NAME status
---------- -------------------------------------------------------------------------------------------------------
228 /u01/app/oracle/product/19.0.0/db_1/dbs/UNNAMED00228 ONLINE
之后,这个文件就可以用了。
避免下次再遇到这种不同步的问题,赶紧修改这个参数
alter system set standby_file_management=auto;
后面,就看到日志开始同步了。
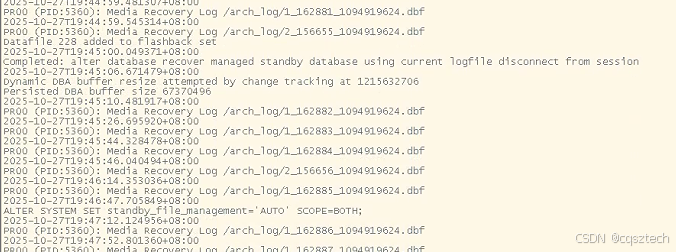
恢复完毕后,重新打开数据库,发现,老是报临时文件有问题:
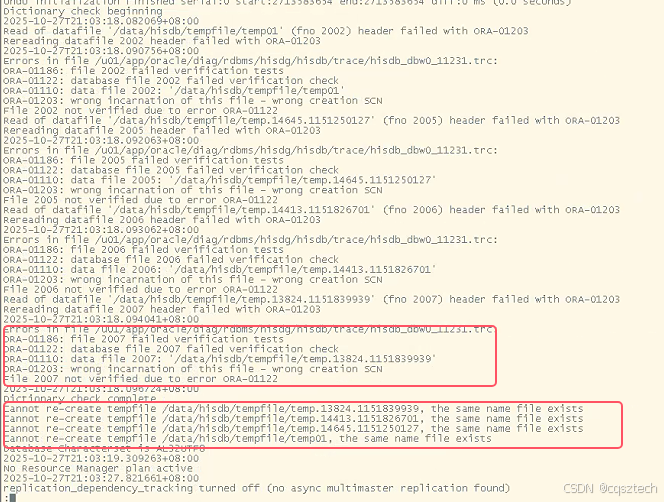
简单的办法,把这些临时文件全部删除,再次OPEN 时,会自动创建。
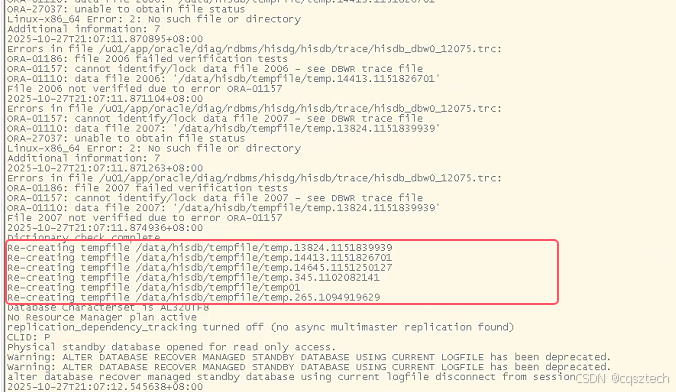
后面再重启,就不再报错。
到此,问题全部解决。让备份的同事测试一下备份,已经没有问题。
4.总结
1.本次的问题,就是备库参数standby_file_management 被人修改为MANUAL,忘了修改回AUTO,导致主库增加了文件,备份CONVERT,DB_CREATE_FILE_dest不起作用,需要找和主库一样的路径导致,而备库是文件系统,因此,最后变成了 unnamed228,同时导致备份同步停止,块改变跟踪也停了。
2.爱数备份在备份依赖块改变跟踪,所以,备份也停了,由于归档日志依赖备份的成功执行,自动删除7天前的日志,但备份没有执行,所以归档也没有执行,导致把归档的磁盘空间也撑爆,所以,主库日志也过不来了,最后手工解决。
5.联系
最后,想一起交流,加我微信吧 zq24803366,我拉你进微信群:水煮数据库 ,一个有温度的数据库免费交流群。

















 7462
7462

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









