



 本文介绍了从抽象语法树(AST)生成LLVM IR代码的方法。首先讲解了LLVM IR基础知识,包括理解IR代码、学习加载和存储方法、将控制流映射到基本块。接着阐述使用AST编号生成SSA形式的IR代码,还涉及优化phi指令等。最后说明了设置模块和驱动,输出汇编文本和目标代码,从而实现代码生成器。
本文介绍了从抽象语法树(AST)生成LLVM IR代码的方法。首先讲解了LLVM IR基础知识,包括理解IR代码、学习加载和存储方法、将控制流映射到基本块。接着阐述使用AST编号生成SSA形式的IR代码,还涉及优化phi指令等。最后说明了设置模块和驱动,输出汇编文本和目标代码,从而实现代码生成器。
在为你的编程语言创建了一个带有装饰的抽象语法树(AST)后,下一个任务是从它生成LLVM IR代码。LLVM IR代码类似于三地址代码,并具有人类可读的表达形式。因此,我们需要一种系统化的方法,将诸如控制结构之类的语言概念转换为LLVM IR的更低层次。
在本章中,你将学习LLVM IR的基础知识,以及如何从AST为控制流结构生成IR。你还将学习如何使用现代算法为表达式生成静态单赋值(SSA)形式的LLVM IR。最后,你将学习如何发出汇编文本和目标代码。
本章将涵盖以下主题:
- 从AST生成IR
- 使用AST编号以SSA形式生成IR代码
- 设置模块和驱动程序
在本章结束时,你将了解如何为你的编程语言创建代码生成器,以及如何将其集成到你的编译器中。
从AST生成IR
LLVM代码生成器接受LLVM IR模块作为输入,并将其转换为目标代码或汇编文本。我们需要将AST表示转换为IR。为了实现IR代码生成器,我们将首先查看一个简单的例子,然后开发代码生成器所需的类。完整的实现将分为三个类:
CodeGeneratorCGModuleCGProcedure
CodeGenerator类是编译器驱动程序使用的通用接口。CGModule和CGProcedure类持有生成编译单元和单个函数的IR代码所需的状态。
我们将从查看Clang生成的IR开始。
理解IR代码
在生成IR代码之前,了解IR语言的主要元素是很有好处的。在[第2章]《编译器的结构》中,我们简要地看了一下IR。了解更多IR知识的一个简单方法是研究clang的输出。例如,将实现欧几里得算法计算两个数的最大公约数的这段C源代码保存为gcd.c:
unsigned gcd(unsigned a, unsigned b) {
if (b == 0)
return a;
while (b != 0) {
unsigned t = a % b;
a = b;
b = t;
}
return a;
}
然后,你可以使用clang和以下命令创建gcd.ll IR文件:
$ clang --target=aarch64-linux-gnu -O1 -S -emit-llvm gcd.c
IR代码并非目标无关,即使它通常看起来像是。上述命令为Linux上的ARM 64位CPU编译源文件。-S选项指示clang输出汇编文件,并通过额外指定-emit-llvm,创建了一个IR文件。优化级别-O1用于获取易于阅读的IR代码。Clang还有更多选项,所有这些都记录在命令行参数参考中:https://clang.llvm.org/docs/ClangCommandLineReference.html。让我们看一下生成的文件,了解C源代码如何映射到LLVM IR。
C文件被翻译成一个模块,它包含函数和数据对象。一个函数至少有一个基本块,基本块包含指令。这种层次结构也反映在C++ API中。所有数据元素都是类型化的。整数类型由字母i和比特数表示。例如,64位整数类型写为i64。最基本的浮点类型是float和double,表示32位和64位IEEE浮点类型。也可以创建聚合类型,如向量、数组和结构。
以下是LLVM IR的样子。在文件顶部,一些基本属性被建立:
; ModuleID = 'gcd.c'
source_filename = "gcd.c"
target datalayout = "e-m:e-i8:8:32-i16:16:32-i64:64-i128:128-n32:64-S128"
target triple = "aarch64-unknown-linux-gnu"
第一行是一个注释,告诉你使用了哪个模块标识符。在接下来的行中,命名了源文件的文件名。使用clang时,这两者是相同的。
target datalayout字符串建立了一些基本属性。不同的部分由-分隔。包括以下信息:
- 一个小写的
e表示内存中的字节使用小端模式存储。要指定大端,你必须使用大写的E。 M:指定应用于符号的名称混淆。这里,m:e表示使用ELF名称混淆。iN:A:P形式的条目,例如i8:8:32,指定数据的对齐,以比特为单位。第一个数字是ABI要求的对齐,第二个数字是首选对齐。对于字节(i8),ABI对齐是1字节(8),首选对齐是4字节(32)。n指定哪些本机寄存器大小可用。n32:64表示32位和64位宽整数在本地受支持。S指定堆栈的对齐,同样以比特为单位。S128表示堆栈保持16字节对齐。
注意
提供的目标数据布局必须与后端期望的匹配。它的目的是将捕获的信息传达给目标无关的优化传递。例如,优化传递可以查询数据布局以获取指针的大小和对齐。然而,更改数据布局中的指针大小不会改变后端的代码生成。
目标数据布局提供了更多信息。你可以在参考手册#data-layout中找到更多信息。
最后,target triple字符串指定了我们正在为其编译的架构。这反映了我们在命令行上给出的信息。三元组是一个通常由CPU架构、供应商和操作系统组成的配置字符串。有关环境的更多信息通常被添加。例如,x86_64-pc-win32三元组用于在64位X86 CPU上运行的Windows系统。x86_64是CPU架构,pc是通用供应商,win32是操作系统。部分由连字符连接。在ARMv8 CPU上运行的Linux系统使用aarch64-unknown-linux-gnu作为其三元组。aarch64是CPU架构,操作系统是运行gnu环境的linux。Linux-based系统没有真正的供应商,所以这部分是unknown。对于特定目的不知道或不重要的部分通常被省略:aarch64-linux-gnu三元组描述了同样的Linux系统。
接下来,在IR文件中定义了gcd函数:
define i32 @gcd(i32 %a, i32 %b) {
这类似于C文件中的函数签名。unsigned数据类型被翻译成32位整数类型i32。函数名前缀为@,参数名前缀为%。函数的主体被包裹在大括号中。接下来是主体的代码:
entry:
%cmp = icmp eq i32 %b, 0
br i1 %cmp, label %return, label %while.body
IR代码被组织成所谓的基本块。一个格式良好的基本块是一系列指令的线性序列,从可选的标签开始,以终结指令结束。因此,每个基本块有一个入口点和一个出口点。LLVM允许在构造时存在格式不正确的基本块。第一个基本块的标签是entry。块中的代码很简单:第一条指令比较%b参数与0。第二条指令根据条件是true还是false分别跳转到return标签或while.body标签。
IR代码的另一个特点是,它处于静态单赋值(SSA)形式。代码使用无限数量的虚拟寄存器,但每个寄存器只写入一次。比较的结果被赋给命名的虚拟寄存器%cmp。然后这个寄存器被使用,但再也没有被写入。如常量传播和公共子表达式消除等优化在SSA形式下非常有效,所有现代编译器都在使用它。
SSA
SSA形式是在20世纪80年代后期开发的。从那以后,它在编译器中被广泛使用,因为它简化了数据流分析和优化。例如,如果IR处于SSA形式,循环内公共子表达式的识别就变得更加容易。SSA的一个基本属性是它建立了def-use和use-def链:对于单一定义,你知道所有使用(def-use),对于每个使用,你知道唯一的定义(use-def)。这种知识被广泛使用,例如在常量传播中:如果一个定义被确定为常量,那么所有使用这个值的地方都可以轻松地替换为该常量值。
为了构建SSA形式,Cytron等人(1989年)的算法非常流行,它也被用于LLVM的实现中。也开发了其他算法。一个早期的观察是,如果源语言没有goto语句,这些算法会变得更简单。
关于SSA的深入处理可以在F. Rastello和F. B. Tichadou的书《基于SSA的编译器设计》(Springer 2022年)中找到。
下一个基本块是while循环的主体:
while.body:
%b.loop = phi i32 [ %rem, %while.body ],
[ %b, %entry ]
%a.loop = phi i32 [ %b.loop, %while.body ],
[ %a, %entry ]
%rem = urem i32 %a.loop, %b.loop
%cmp1 = icmp eq i32 %rem, 0
br i1 %cmp1, label %return, label %while.body
在gcd的循环内部,a和b参数被赋予了新的值。如果一个寄存器只能写入一次,那么这就不可能实现。解决方案是使用特殊的phi指令。phi指令有一个基本块和值的参数列表。一个基本块表示来自该基本块的入口边,值是该基本块的值。在运行时,phi指令将先前执行的基本块的标签与参数列表中的标签进行比较。
指令的值是与标签相关联的值。对于第一个phi指令,如果先前执行的基本块是while.body,那么值是%rem寄存器;如果是entry,那么值是%b。值是基本块开始时的值。%b.loop寄存器从第一个phi指令获取一个值。同一个寄存器在第二个phi指令的参数列表中使用,但假定的值是在第一个phi指令改变之前的值。
在循环体之后,必须选择返回值:
return:
%retval = phi i32 [ %a, %entry ],
[ %b.loop, %while.body ]
ret i32 %retval
}
再次,使用phi指令来选择期望的值。ret指令不仅结束了这个基本块,而且在运行时标志着这个函数的结束。它将返回值作为参数。
对phi指令的使用有一些限制。它们必须是基本块的第一条指令。第一个基本块是特殊的:它没有先前执行的块。因此,它不能以phi指令开始。
LLVM IR参考
我们只触及了LLVM IR的基础知识。请访问LLVM语言参考手册,查看所有详细信息。
IR代码本身看起来很像C语言和汇编语言的混合体。尽管这种风格很熟悉,但我们还不清楚如何从AST轻松生成IR代码。特别是phi指令看起来很难生成。但不要害怕——在下一节中,我们将实现一个简单的算法来做到这一点!
学习LLVM的加载和存储方法
LLVM中所有的本地优化都是基于这里展示的SSA(静态单赋值)形式。对于全局变量,使用内存引用。IR(中间表示)语言中有加载(load)和存储(store)指令,用于获取和存储这些值。这也可以用于局部变量。这些指令不属于SSA形式,LLVM知道如何将它们转换为所需的SSA形式。因此,你可以为每个局部变量分配内存槽,并使用加载和存储指令来改变它们的值。你只需要记住变量存储的内存槽的指针即可。clang编译器使用了这种方法。
让我们看看加载和存储的IR代码。再次编译gcd.c,但这次不启用优化:
$ clang --target=aarch64-linux-gnu -S -emit-llvm gcd.c
gcd函数现在看起来有所不同。这是第一个基本块:
define i32 @gcd(i32, i32) {
%3 = alloca i32, align 4
%4 = alloca i32, align 4
%5 = alloca i32, align 4
%6 = alloca i32, align 4
store i32 %0, ptr %4, align 4
store i32 %1, ptr %5, align 4
%7 = load i32, ptr %5, align 4
%8 = icmp eq i32 %7, 0
br i1 %8, label %9, label %11
IR代码现在依赖于寄存器和标签的自动编号。参数的名称没有指定,隐式地,它们是%0和%1。基本块没有标签,因此分配了2。前几条指令为四个32位值分配内存。之后,将%0和%1参数存储在由寄存器%4和%5指向的内存槽中。为了将%1与0比较,需要显式地从内存槽中加载值。采用这种方法,你不需要使用phi指令!相反,你从内存槽加载一个值,对其进行计算,然后将新值存储回内存槽。下次读取内存槽时,你会得到最后计算的值。gcd函数的所有其他基本块都遵循这种模式。
使用这种方式的加载和存储指令的优点是生成IR代码相对容易。缺点是你会生成很多LLVM在第一步优化时会通过mem2reg传递来移除的IR指令,这是在将基本块转换为SSA形式之后。因此,我们直接以SSA形式生成IR代码。
我们将开始通过将控制流映射到基本块来开发IR代码生成。
将控制流映射到基本块
基本块的概念是,它是一系列线性指令序列,按照该顺序执行。一个基本块在开始处只有一个入口,并以一个终结器指令结束,终结器指令是将控制流转移到另一个基本块的指令,比如分支指令、切换指令或返回指令。请参阅https://llvm.org/docs/LangRef.html#terminator-instructions以获取完整的终结器指令列表。一个基本块可以以phi指令开始,但在基本块内部,不允许使用phi或分支指令。换句话说,你只能在第一条指令处进入一个基本块,并且只能在最后一条指令,即终结器指令处离开一个基本块。不可能跳转到基本块内部的一条指令,也不可能从基本块中间跳转到另一个基本块。请注意,简单的函数调用,比如使用call指令,可以在基本块内部发生。每个基本块都有一个标签,标记着基本块的第一条指令。标签是分支指令的目标。你可以将分支视为两个基本块之间的有向边,从而形成控制流图(CFG)。一个基本块可以有前驱和后继。函数的第一个基本块是特殊的,不允许有前驱。
由于这些限制,源语言的控制语句,如WHILE和IF,会产生多个基本块。让我们来看看WHILE语句。WHILE语句的条件控制是执行循环体还是执行下一个语句。条件必须在自己的基本块中生成,因为有两个前驱:
WHILE之前的语句产生的基本块- 循环体结束时返回条件的分支
也有两个后继:
- 循环体的开始
WHILE之后的语句产生的基本块
循环体本身至少有一个基本块:
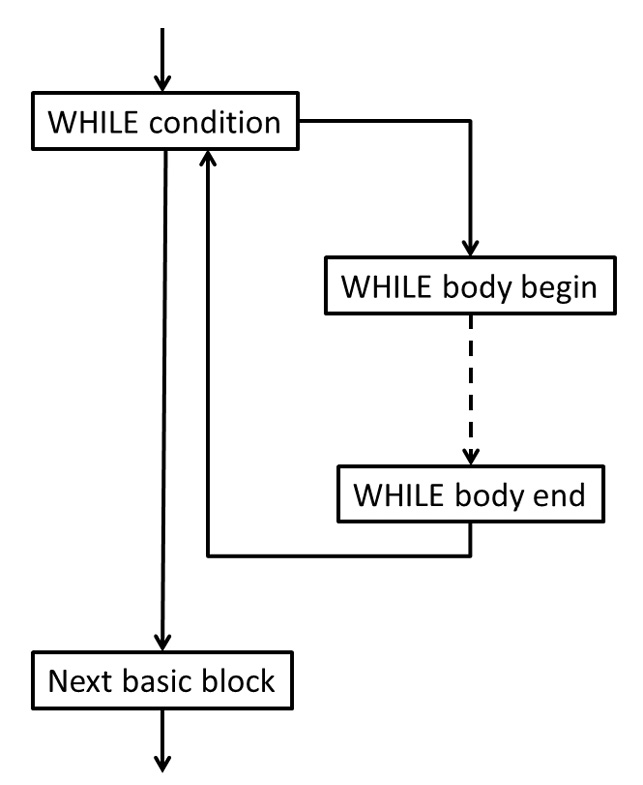
图4.1 - WHILE语句的基本块
IR代码生成遵循这种结构。我们在CGProcedure类中存储指向当前基本块的指针,并使用llvm::IRBuilder<>实例将指令插入基本块。首先,我们创建基本块:
void emitStmt(WhileStatement *Stmt) {
llvm::BasicBlock *WhileCondBB = llvm::BasicBlock::Create(
CGM.getLLVMCtx(), "while.cond", Fn);
llvm::BasicBlock *WhileBodyBB = llvm::BasicBlock::Create(
CGM.getLLVMCtx(), "while.body", Fn);
llvm::BasicBlock *AfterWhileBB = llvm::BasicBlock::Create(
CGM.getLLVMCtx(), "after.while", Fn);
Fn变量表示当前函数,getLLVMCtx()返回LLVM上下文。这两个都稍后设置。我们以分支到包含条件的基本块的分支结束当前基本块:
Builder.CreateBr(WhileCondBB);
条件的基本块成为新的当前基本块。我们生成条件,并以条件分支结束该块:
setCurr(WhileCondBB);
llvm::Value *Cond = emitExpr(Stmt->getCond());
Builder.CreateCondBr(Cond, WhileBodyBB, AfterWhileBB);
接下来,我们生成循环体。最后,我们添加一个分支回到条件的基本块:
setCurr(WhileBodyBB);
emit(Stmt->getWhileStmts());
Builder.CreateBr(WhileCondBB);
这样,我们就生成了WHILE语句。现在我们已经生成了WhileCondBB和Curr块,我们可以对它们进行封闭处理:
sealBlock(WhileCondBB);
sealBlock(Curr);
WHILE之后的空基本块成为新的当前基本块:
setCurr(AfterWhileBB);
}
遵循这个模式,你可以为源语言的每个语句创建一个emit()方法。
使用AST编号来生成SSA形式的IR代码
为了从AST生成SSA形式的IR代码,我们可以使用一种称为AST编号的方法。基本思想是,对于每个基本块,我们存储在这个基本块中写入的局部变量的当前值。
注意
此实现基于论文Simple and Efficient Construction of Static Single Assignment Form,由Braun等人在2013年国际编译器构建会议(CC 2013)上发表(参见)。在其呈现的形式中,它仅适用于具有结构化控制流的IR代码。论文还描述了必要的扩展,以支持任意控制流 - 例如,goto语句。
尽管很简单,我们仍然需要几个步骤。我们首先介绍所需的数据结构,然后我们将学习如何读取和写入局部基本块的值。之后,我们将处理在几个基本块中使用的值,并最后通过优化创建的phi指令来结束。
定义保存值的数据结构
我们使用BasicBlockDef结构体来保存单个块的信息:
struct BasicBlockDef {
llvm::DenseMap<Decl *, llvm::TrackingVH<llvm::Value>> Defs;
// ...
};
llvm::Value LLVN类表示SSA形式的值。Value类就像计算结果的标签。它通常通过IR指令创建一次,然后使用。在优化过程中可能发生各种变化。例如,如果优化器检测到%1和%2值始终相同,那么它可以用%1替换%2的使用。这改变了标签但不改变计算。
为了意识到这样的变化,我们不能直接使用Value类。相反,我们需要一个值句柄。不同的值句柄具有不同的功能。为了跟踪替换,我们可以使用llvm::TrackingVH<>类。因此,Defs成员将AST的声明(变量或形式参数)映射到其当前值。现在,我们需要为每个基本块存储这些信息:
llvm::DenseMap<llvm::BasicBlock *, BasicBlockDef> CurrentDef;
有了这个数据结构,我们现在能够处理局部值。
读取和写入局部基本块的值
为了在基本块中存储局部变量的当前值,我们将在映射中创建一个条目:
void writeLocalVariable(llvm::BasicBlock *BB, Decl *Decl,
llvm::Value *Val) {
CurrentDef[BB].Defs[Decl] = Val;
}
查找变量的值稍微复杂一些,因为值可能不在基本块中。在这种情况下,我们需要扩展搜索到前驱,可能需要递归搜索:
llvm::Value *
readLocalVariable(llvm::BasicBlock *BB, Decl *Decl) {
auto Val = CurrentDef[BB].Defs.find(Decl);
if (Val != CurrentDef[BB].Defs.end())
return Val->second;
return readLocalVariableRecursive(BB, Decl);
}
真正的工作是搜索前驱,这将在下一节中实现。
寻找前驱块中的值
当我们查看的当前基本块只有一个前驱时,我们就在那里寻找变量的值。如果基本块有多个前驱,那么我们需要在所有这些块中搜索该值并组合结果。为了说明这种情况,您可以查看前一节中WHILE语句条件的基本块。
这个基本块有两个前驱 - 一个是WHILE语句之前的语句产生的,另一个是WHILE循环体结束的分支产生的。在条件中使用的变量应该有一些初始值,并且很可能在循环体中被更改。所以,我们需要收集这些定义,并从中创建一个phi指令。由WHILE语句创建的基本块包含一个循环。
因为我们递归地搜索前驱块,我们必须打破这个循环。为此,我们可以使用一个简单的技巧:我们可以插入一个空的phi指令,并将其记录为变量的当前值。如果我们在搜索中再次遇到这个基本块,那么我们会看到变量已经有了我们可以使用的值。在这一点上,搜索停止。一旦我们收集了所有的值,我们必须更新phi指令。
然而,我们仍然面临一个问题。在查找时,并非所有基本块的前驱都已知。这是怎么发生的呢?看看WHILE语句的基本块创建。循环的条件的IR首先生成。然而,从循环体末尾回到包含条件的基本块的分支,只能在为循环体生成IR之后添加。这是因为这个基本块之前不为人知。如果我们需要在条件中读取变量的值,那么我们就陷入困境,因为并非所有前驱都已知。
为了解决这种情况,我们必须做一些额外的工作:
-
首先,我们必须给基本块附加一个
Sealed标志。 -
然后,我们必须定义一个基本块为封闭的,如果我们知道基本块的所有前驱。如果基本块未封闭并且我们需要查找尚未在此基本块中定义的变量的值,那么我们必须插入一个空的
phi指令,并将其用作该值。 -
我们还需要记住这个指令。如果块稍后被封闭,那么我们需要用真实的值更新指令。为了实现这一点,我们必须在
struct BasicBlockDef中添加两个更多的成员:IncompletePhis映射,用来记录稍后需要更新的phi指令,以及Sealed标志,表示基本块是否封闭:llvm::DenseMap<llvm::PHINode *, Decl *> IncompletePhis; unsigned Sealed : 1; -
然后,可以按照本节开头讨论的方式实现该方法:
llvm::Value *CGProcedure::readLocalVariableRecursive( llvm::BasicBlock *BB, Decl *Decl) { llvm::Value *Val = nullptr; if (!CurrentDef[BB].Sealed) { llvm::PHINode *Phi = addEmptyPhi(BB, Decl); CurrentDef[BB].IncompletePhis[Phi] = Decl; Val = Phi; } else if (auto *PredBB = BB->getSinglePredecessor()) { Val = readLocalVariable(PredBB, Decl); } else { llvm::PHINode *Phi = addEmptyPhi(BB, Decl); writeLocalVariable(BB, Decl, Phi); Val = addPhiOperands(BBDec, Phi); } writeLocalVariable(BB, Decl, Val); return Val; } -
addEmptyPhi()方法在基本块的开始处插入一个空的phi指令:llvm::PHINode * CGProcedure::addEmptyPhi(llvm::BasicBlock *BB, Decl *Decl) { return BB->empty() ? llvm::PHINode::Create(mapType(Decl), 0, "", BB) : llvm::PHINode::Create(mapType(Decl), 0, "", &BB->front()); } -
要向
phi指令添加缺少的操作数,首先必须搜索基本块的所有前驱,并将操作数对值和基本块添加到phi指令中。然后,尝试优化该指令:llvm::Value * CGProcedure::addPhiOperands(llvm::BasicBlock *BB, Decl *Decl, llvm::PHINode *Phi) { for (auto *PredBB : llvm::predecessors(BB)) Phi->addIncoming(readLocalVariable(PredBB, Decl), PredBB); return optimizePhi(Phi); }
这种算法可能会生成不需要的phi指令。优化这些指令的一种方法将在下一节中实现。
优化生成的phi指令
我们如何优化phi指令,为什么要这样做?虽然SSA形式对于许多优化非常有利,但phi指令通常不被算法解释,因此通常会阻碍优化。因此,我们生成的phi指令越少越好。具体来说:
-
如果指令只有一个操作数,或者所有操作数都具有相同的值,则我们用这个值替换该指令。如果指令没有操作数,我们用特殊的
Undef值替换指令。只有当指令有两个或多个不同的操作数时,我们才必须保留该指令。 -
删除一个
phi指令可能会导致其他phi指令的优化机会。幸运的是,LLVM跟踪值的使用和使用情况(这是SSA定义中提到的use-def链)。我们必须搜索所有在其他phi指令中使用该值的用途,并尝试优化这些指令。
如果我们愿意,我们甚至可以进一步改进这个算法。我们可以选择并记住两个不同的值。然后,在optimizePhi函数中,我们可以检查这两个值是否仍在phi指令的值列表中。如果是这样,我们就知道没有什么可以优化的。但即使没有这种优化,这个算法也运行得非常快,所以我们现在不打算实现这一点。
我们几乎完成了。我们唯一还没做的就是实现封闭基本块的操作。我们将在下一节中完成这项工作。
封闭块
一旦我们知道一个块的所有前驱都已知,我们就可以封闭该块。如果源语言只包含结构化语句,如tinylang,那么很容易确定何时可以封闭一个块。再次看看为WHILE语句生成的基本块。
包含条件的基本块可以在循环体末尾的分支添加后封闭,因为这是最后一个缺失的前驱。封闭块时,我们可以简单地为不完整的phi指令添加缺失的操作数并设置标志:
void CGProcedure::sealBlock(llvm::BasicBlock *BB) {
for (auto PhiDecl : CurrentDef[BB].IncompletePhis) {
addPhiOperands(BB, PhiDecl.second, PhiDecl.first);
}
CurrentDef[BB].IncompletePhis.clear();
CurrentDef[BB].Sealed = true;
}
有了这些方法,我们现在准备好为表达式生成IR代码。
创建表达式的IR代码
通常,您会像在[第2章]中所示的那样翻译表达式,编译器的结构。唯一有趣的部分是如何访问变量。上一节处理了局部变量,但我们可以考虑其他类型的变量。让我们讨论我们需要做什么:
- 对于过程中的局部变量,我们使用上一节中的
readLocalVariable()和writeLocalVariable()方法。 - 对于封闭过程中的局部变量,我们需要一个指向封闭过程框架的指针。这将在本章后面处理。
- 对于全局变量,我们生成加载和存储指令。
- 对于形式参数,我们必须区分按值传递和按引用传递(
tinylang中的VAR参数)。按值传递的参数被视为局部变## 优化生成的phi指令
SSA形式中的phi指令对于许多优化来说是一个障碍,因此我们的目标是尽可能减少生成的phi指令。phi指令的优化主要包括以下几个方面:
-
简化操作数相同的phi指令:如果一个
phi指令的所有操作数都相同,或者只有一个操作数,那么这个指令可以被简化为一个操作数或者一个特殊的Undef值。 -
优化phi指令的使用:删除一个
phi指令可能会为其他phi指令的优化提供机会。在这个过程中,我们需要检查所有使用被删除phi指令值的地方,并尝试优化这些使用。 -
实现循环优化:尽管没有具体实现细节,但我们可以进一步改进这个算法,例如通过挑选和记住两个不同的值,以减少每次对
phi指令的值列表的迭代。 -
封闭基本块:一旦我们知道一个块的所有前驱都已知,我们就可以封闭该块。封闭块时,我们为不完整的
phi指令添加缺失的操作数并设置标志。
通过这些方法,我们可以优化生成的phi指令,从而提高整体的编译效率和代码质量。
控制可见性:链接和名称改编
函数(以及全局变量)附加有链接风格。通过链接风格,我们定义了符号名称的可见性以及当多个符号具有相同名称时应该发生什么。最基本的链接风格是私有和外部。具有私有链接的符号仅在当前编译单元中可见,而具有外部链接的符号则全局可用。
对于像C这样没有合适模块概念的语言,这是足够的。有了模块,我们需要做更多的事情。假设我们有一个名为Square的模块,它提供了一个Root()函数,以及一个Cube模块,它也提供了一个Root()函数。如果函数是私有的,那么就没有问题。该函数获得名称Root和私有链接。如果函数被导出,以便可以从其他模块调用,情况就不同了。仅使用函数名称是不够的,因为这个名称不是唯一的。
解决方案是调整名称以使其全局唯一。这称为名称改编。如何进行取决于语言的要求和特性。在我们的案例中,基本思想是使用模块和函数名称的组合创建一个全局唯一的名称。使用Square.Root作为名称看起来是一个明显的解决方案,但这可能会导致汇编程序的问题,因为点可能有特殊含义。我们可以通过前缀名称组件的长度来获得类似的效果,而不是使用名称组件之间的分隔符:6Square4Root。这对LLVM来说不是一个合法的标识符,但我们可以通过在整个名称前加上_t(t代表tinylang)来修复:_t6Square4Root。通过这种方式,我们可以为导出的符号创建唯一名称:
std::string CGModule::mangleName(Decl *D) {
std::string Mangled("_t");
llvm::SmallVector<llvm::StringRef, 4> List;
for (; D; D = D->getEnclosingDecl())
List.push_back(D->getName());
while (!List.empty()) {
llvm::StringRef Name = List.pop_back_val();
Mangled.append(
llvm::Twine(Name.size()).concat(Name).str());
}
return Mangled;
}
如果你的源语言支持类型重载,则需要使用类型名称扩展此方案。例如,为了区分int root(int)和double root(double) C++函数,必须将参数和返回值的类型添加到函数名称中。
你还需要考虑生成的名称的长度,因为一些链接器对长度有限制。在C++中,由于嵌套的命名空间和类,改编后的名称可能相当长。在这里,C++定义了一个压缩方案,以避免反复重复名称组件。
接下来,我们将看看如何处理参数。
将AST描述的类型转换为LLVM类型
函数的参数也需要一些考虑。首先,我们需要将源语言的类型映射到LLVM类型。由于tinylang当前只有两种类型,这很简单:
llvm::Type *CGModule::convertType(TypeDeclaration *Ty) {
if (Ty->getName() == "INTEGER")
return Int64Ty;
if (Ty->getName() == "BOOLEAN")
return Int1Ty;
llvm::report_fatal_error("不支持的类型");
}
Int64Ty、Int1Ty和VoidTy是类成员,它们持有i64、i1和void LLVM类型的类型表示。
对于通过引用传递的形式参数,这还不够。这个参数的LLVM类型是一个指针。然而,当我们想要使用形式参数的值时,我们需要知道底层类型。这由HonorReference标志控制,其默认值为true。我们概括函数并考虑形式参数:
llvm::Type *CGProcedure::mapType(Decl *Decl,
bool HonorReference) {
if (auto *FP = llvm::dyn_cast<FormalParameterDeclaration>(
Decl)) {
if (FP->isVar() && HonorReference)
return llvm::PointerType::get(CGM.getLLVMCtx(),
/*AddressSpace=*/0);
return CGM.convertType(FP->getType());
}
if (auto *V = llvm::dyn_cast<VariableDeclaration>(Decl))
return CGM.convertType(V->getType());
return CGM.convertType(llvm::cast<TypeDeclaration>(Decl));
}
有了这些辅助函数,我们就可以创建LLVM IR函数了。
创建LLVM IR函数
要在LLVM IR中发射一个函数,需要一个类似于C中原型的函数类型。创建函数类型涉及映射类型,然后调用工厂方法来创建函数类型:
llvm::FunctionType *CGProcedure::createFunctionType(
ProcedureDeclaration *Proc) {
llvm::Type *ResultTy = CGM.VoidTy;
if (Proc->getRetType()) {
ResultTy = mapType(Proc->getRetType());
}
auto FormalParams = Proc->getFormalParams();
llvm::SmallVector<llvm::Type *, 8> ParamTypes;
for (auto FP : FormalParams) {
llvm::Type *Ty = mapType(FP);
ParamTypes.push_back(Ty);
}
return llvm::FunctionType::get(ResultTy, ParamTypes,
/*IsVarArgs=*/false);
}
基于函数类型,我们还创建了LLVM函数。这将函数类型与链接和改编后的名称关联起来:
llvm::Function *
CGProcedure::createFunction(ProcedureDeclaration *Proc,
llvm::FunctionType *FTy) {
llvm::Function *Fn = llvm::Function::Create(
FTy, llvm::GlobalValue::ExternalLinkage,
CGM.mangleName(Proc), CGM.getModule());
getModule()方法返回当前的LLVM模块,我们稍后会设置。
创建了函数后,我们可以添加一些关于它的更多信息:
- 首先,我们可以给参数命名。这使得IR更可读。
- 其次,我们可以向函数和参数添加属性,以指定一些特性。例如,我们将对通过引用传递的参数执行此操作。
在LLVM级别,这些参数是指针。但从源语言设计来看,这些是非常受限的指针。类似于C++中的引用,我们总是需要为VAR参数指定一个变量。因此,设计上我们知道这个指针永远不会为空,并且它总是可解引用的,意味着我们可以读取被指向的值而不会冒着发生一般保护错误的风险。同时,设计上,这个指针不能被传递 — 特别是,没有指针的副本在函数调用后存活。因此,可以说指针不会被捕获。
llvm::AttributeBuilder类用于为形式参数构建属性集。要获取参数类型的存储大小,我们可以简单地查询数据布局对象:
for (auto [Idx, Arg] : llvm::enumerate(Fn->args())) {
FormalParameterDeclaration *FP =
Proc->getFormalParams()[Idx];
if (FP->isVar()) {
llvm::AttrBuilder Attr(CGM.getLLVMCtx());
llvm::TypeSize Sz =
CGM.getModule()->getDataLayout().getTypeStoreSize(
CGM.convertType(FP->getType()));
Attr.addDereferenceableAttr(Sz);
Attr.addAttribute(llvm::Attribute::NoCapture);
Arg.addAttrs(Attr);
}
Arg.setName(FP->getName());
}
return Fn;
}
通过这样,我们创建了IR函数。在下一节中,我们将向函数体中添加基本块。
生成函数体
我们几乎完成了函数的IR代码生成!我们只需将各个部分组合起来以生成函数及其主体:
-
首先,针对
tinylang的过程声明,我们将创建函数类型和函数本身:void CGProcedure::run(ProcedureDeclaration *Proc) { this->Proc = Proc; Fty = createFunctionType(Proc); Fn = createFunction(Proc, Fty); -
接下来,我们将创建函数的第一个基本块并使其成为当前块:
llvm::BasicBlock *BB = llvm::BasicBlock::Create( CGM.getLLVMCtx(), "entry", Fn); setCurr(BB); -
然后,我们必须逐步处理所有形式参数。为了正确处理VAR参数,我们需要初始化
FormalParams成员(在readVariable()中使用)。与局部变量不同,形式参数在第一个基本块中有一个值,因此我们必须使这些值为人所知:for (auto [Idx, Arg] : llvm::enumerate(Fn->args())) { FormalParameterDeclaration *FP = Proc->getFormalParams()[Idx]; FormalParams[FP] = &Arg; writeLocalVariable(Curr, FP, &Arg); } -
完成这些设置后,我们可以调用
emit()方法开始生成语句的IR代码:auto Block = Proc->getStmts(); emit(Proc->getStmts()); -
生成IR代码后的最后一个块可能尚未封闭,因此我们现在必须调用
sealBlock()。tinylang中的过程可能有一个隐式返回,因此我们还必须检查最后一个基本块是否有适当的终结器,如果没有,则添加一个:if (!Curr->getTerminator()) { Builder.CreateRetVoid(); } sealBlock(Curr); }
通过这样,我们完成了函数的IR代码生成。然而,我们仍然需要创建LLVM模块,它包含所有IR代码。我们将在下一节中进行。
设置模块和驱动
我们在LLVM模块中收集编译单元的所有函数和全局变量。为了简化IR生成过程,我们可以将前几节中的所有函数包装到一个代码生成器类中。为了得到一个工作中的编译器,我们还需要定义我们希望生成代码的目标架构,并添加生成代码的过程。我们将在本章及接下来的几章中实现这一点,从代码生成器开始。
将所有内容包装到代码生成器中
IR模块是我们为编译单元生成的所有元素的括号。在全局级别,我们遍历模块级别的声明,创建全局变量,并调用过程的代码生成。tinylang中的全局变量映射到llvm::GlobalValue类的实例。这个映射保存在Globals中,并提供给过程的代码生成:
void CGModule::run(ModuleDeclaration *Mod) {
for (auto *Decl : Mod->getDecls()) {
if (auto *Var =
llvm::dyn_cast<VariableDeclaration>(Decl)) {
// 创建全局变量
auto *V = new llvm::GlobalVariable(
*M, convertType(Var->getType()),
/*isConstant=*/false,
llvm::GlobalValue::PrivateLinkage, nullptr,
mangleName(Var));
Globals[Var] = V;
} else if (auto *Proc =
llvm::dyn_cast<ProcedureDeclaration>(
Decl)) {
CGProcedure CGP(*this);
CGP.run(Proc);
}
}
}
模块还持有LLVMContext类,并缓存最常用的LLVM类型。后者需要初始化,例如对于64位整数类型:
Int64Ty = llvm::Type::getInt64Ty(getLLVMCtx());
CodeGenerator类初始化LLVM IR模块,并调用模块的代码生成。最重要的是,这个类必须知道我们想为哪个目标架构生成代码。这些信息通过在驱动中设置的llvm::TargetMachine类传递:
std::unique_ptr<llvm::Module>
CodeGenerator::run(ModuleDeclaration *Mod,
std::string FileName) {
std::unique_ptr<llvm::Module> M =
std::make_unique<llvm::Module>(FileName, Ctx);
M->setTargetTriple(TM->getTargetTriple().getTriple());
M->setDataLayout(TM->createDataLayout());
CGModule CGM(M.get());
CGM.run(Mod);
return M;
}
为了方便使用,我们还必须为代码生成器引入一个工厂方法:
CodeGenerator *
CodeGenerator::create(llvm::LLVMContext &Ctx,
llvm::TargetMachine *TM) {
return new CodeGenerator(Ctx, TM);
}
CodeGenerator类提供了一个小型接口来创建IR代码,非常适合用于编译器驱动。在我们整合它之前,我们需要实现对机器代码生成的支持。
初始化目标机器类
现在,只剩下目标机器了。通过目标机器,我们定义了我们想要为之生成代码的CPU架构。对于每种CPU,都有可用的特性,这些特性可以用来影响代码生成过程。例如,CPU架构系列的更新CPU可以支持向量指令。通过特性,我们可以切换向量指令的使用开关。为了支持从命令行设置所有这些选项,LLVM提供了一些支持代码。在Driver类中,我们可以添加以下include变量:
#include "llvm/CodeGen/CommandFlags.h"
这个include变量为我们的编译器驱动添加了常见的命令行选项。许多LLVM工具也使用这些命令行选项,这样做的好处是为用户提供一个共同的界面。只缺少指定目标三元组的选项。由于这非常有用,我们将自己添加:
static llvm::cl::opt<std::string> MTriple(
"mtriple",
llvm::cl::desc("Override target triple for module"));
让我们创建目标机器:
-
为了显示错误信息,应用程序的名称必须传递给函数:
llvm::TargetMachine * createTargetMachine(const char *Argv0) { -
首先,我们必须收集命令行提供的所有信息。这些是代码生成器的选项 - 也就是CPU的名称以及应该激活或停用的可能特性,以及目标的三元组:
llvm::Triple Triple = llvm::Triple( !MTriple.empty() ? llvm::Triple::normalize(MTriple) : llvm::sys::getDefaultTargetTriple()); llvm::TargetOptions TargetOptions = codegen::InitTargetOptionsFromCodeGenFlags(Triple); std::string CPUStr = codegen::getCPUStr(); std::string FeatureStr = codegen::getFeaturesStr(); -
然后,我们必须在目标注册表中查找目标。如果发生错误,我们将显示错误信息并退出。可能的错误是用户指定的不支持的三元组:
std::string Error; const llvm::Target *Target = llvm::TargetRegistry::lookupTarget( codegen::getMArch(), Triple, Error); if (!Target) { llvm::WithColor::error(llvm::errs(), Argv0) << Error; return nullptr; } -
借助
Target类,我们可以使用用户请求的所有已知选项来配置目标机器:llvm::TargetMachine *TM = Target->createTargetMachine( Triple.getTriple(), CPUStr, FeatureStr, TargetOptions, std::optional<llvm::Reloc::Model>( codegen::getRelocModel())); return TM; }
有了目标机器实例,我们可以生成针对我们选择的CPU架构的IR代码。缺少的是翻译成汇编文本或生成目标代码文件。我们将在下一节中添加这个支持。
输出汇编文本和目标代码
在LLVM中,IR代码通过一系列传递的管道运行。每个传递执行单一任务,例如删除无用代码。在第7章,“优化IR”中,我们将更多地了解传递。输出汇编代码或对象文件也作为一个传递实现。让我们添加基本支持!
我们需要包含更多的LLVM头文件。首先,我们需要llvm::legacy::PassManager类来保存传递以将代码输出到文件。我们还想能够输出LLVM IR代码,所以我们还需要一个传递来输出这个。最后,我们将使用llvm::ToolOutputFile类进行文件操作:
#include "llvm/IR/IRPrintingPasses.h"
#include "llvm/IR/LegacyPassManager.h"
#include "llvm/MC/TargetRegistry.h"
#include "llvm/Pass.h"
#include "llvm/Support/ToolOutputFile.h"
还需要另一个用于输出LLVM IR的命令行选项:
static llvm::cl::opt<bool> EmitLLVM(
"emit-llvm",
llvm::cl::desc("Emit IR code instead of assembler"),
llvm::cl::init(false));
最后,我们希望能够给输出文件命名:
static llvm::cl::opt<std::string>
OutputFilename("o",
llvm::cl::desc("Output filename"),
llvm::cl::value_desc("filename"));
新的emit()方法中的第一个任务是处理输出文件的名称,如果用户没有在命令行上给出。如果输入从stdin读取,表示使用减号-,那么我们将结果输出到stdout。ToolOutputFile类知道如何处理特殊文件名-:
bool emit(StringRef Argv0, llvm::Module *M,
llvm::TargetMachine *TM,
StringRef InputFilename) {
CodeGenFileType FileType = codegen::getFileType();
if (OutputFilename.empty()) {
if (InputFilename == "-") {
OutputFilename = "-";
}
否则,我们删除输入文件名的可能扩展名,并根据用户给出的命令行选项添加.ll、.s或.o作为扩展名。FileType选项定义在我们之前包含的llvm/CodeGen/CommandFlags.inc头文件中。这个选项不支持输出IR代码,所以我们添加了新的--emit-llvm选项,它只在与汇编文件类型一起使用时才生效:
else {
if (InputFilename.endswith(".mod"))
OutputFilename =
InputFilename.drop_back(4).str();
else
OutputFilename = InputFilename.str();
switch (FileType) {
case CGFT_AssemblyFile:
OutputFilename.append(EmitLLVM ? ".ll" : ".s");
break;
case CGFT_ObjectFile:
OutputFilename.append(".o");
break;
case CGFT_Null:
OutputFilename.append(".null");
break;
}
}
}
一些平台区分文本文件和二进制文件,因此在打开输出文件时我们必须提供正确的打开标志:
std::error_code EC;
sys::fs::OpenFlags OpenFlags = sys::fs::OF_None;
if (FileType == CGFT_AssemblyFile)
OpenFlags |= sys::fs::OF_TextWithCRLF;
auto Out = std::make_unique<llvm::ToolOutputFile>(
OutputFilename, EC, OpenFlags);
if (EC) {
WithColor::error(llvm::errs(), Argv0)
<< EC.message() << '\n';
return false;
}
现在,我们可以向PassManager添加所需的传递。TargetMachine类有一个实用方法,它添加了请求的类。因此,我们只需要检查用户是否请求输出LLVM IR代码:
legacy::PassManager PM;
if (FileType == CGFT_AssemblyFile && EmitLLVM) {
PM.add(createPrintModulePass(Out->os()));
} else {
if (TM->addPassesToEmitFile(PM, Out->os(), nullptr,
FileType)) {
WithColor::error(llvm::errs(), Argv0)
<< "No support for file type\n";
return false;
}
}
完成所有这些准备工作后,输出文件只需一个函数调用:
PM.run(*M);
ToolOutputFile类会自动删除文件,如果我们不明确请求保留它。这使得错误处理更容易,因为潜在地需要处理错误的地方很多,而如果一切顺利,只有一个地方会达到。我们成功地发出了代码,所以我们想保留文件:
Out->keep();
最后,我们必须向调用者报告成功:
return true;
}
调用emit()方法,并用我们通过调用CodeGenerator类创建的llvm::Module,会按请求发出代码。
假设你有一个存储在Gcd.mod文件中的最大公约数算法:
MODULE Gcd;
PROCEDURE GCD(a, b: INTEGER) : INTEGER;
VAR t: INTEGER;
BEGIN
IF b = 0 THEN
RETURN a;
END;
WHILE b # 0 DO
t := a MOD b;
a := b;
b := t;
END;
RETURN a;
END GCD;
END Gcd.
要将其转换为Gcd.o对象文件,请输入以下内容:
$ tinylang --filetype=obj Gcd.mod
如果你想直接在屏幕上查看生成的IR代码,请输入以下内容:
$ tinylang --filetype=asm --emit-llvm -o - Gcd.mod
在当前实现的状态下,不可能在tinylang中创建完整的程序。然而,你可以使用一个名为callgcd.c的小型C程序来测试生成的对象文件。注意使用改编后的名称来调用GCD函数:
#include <stdio.h>
extern long _t3Gcd3GCD(long, long);
int main(int argc, char *argv[]) {
printf("gcd(25, 20) = %ld\n", _t3Gcd3GCD(25, 20));
printf("gcd(3, 5) = %ld\n", _t3Gcd3GCD(3, 5));
printf("gcd(21, 28) = %ld\n", _t3Gcd3GCD(21, 28));
return 0;
}
要用clang编译并运行整个应用,请输入以下内容:
$ tinylang --filetype=obj Gcd.mod
$ clang callgcd.c Gcd.o -o gcd
$ gcd
让我们庆祝一下!在这一点上,我们通过阅读源语言并输出汇编代码或对象文件创建了一个完整的编译器。
总结
在本章中,你学习了如何为LLVM IR代码实现代码生成器。基本块是重要的数据结构,它保存所有指令并表示分支。你学习了如何为源语言的控制语句创建基本块以及如何向基本块添加指令。你应用了一种现代算法来处理函数中的局部变量,从而导致更少的IR代码。编译器的目标是为输入生成汇编文本或对象文件,所以你还添加了一个简单的编译管道。有了这些知识,你将能够为你的语言编译器生成LLVM IR代码和汇编文本或目标代码。
在下一章中,你将学习如何处理聚合数据结构,以及如何确保函数调用符合你的平台规则。


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









