




2023年4月份时(插本在校状态),初步接触并学习了Protobuf2,但那会只是学过,知道有这个也给东西,也没有真正使用过,自己也只是对他一知半解;
如今,再次工作后,慢慢地觉得在网络传输,能有一种数据结构可以更加轻巧的用于传输是多么的重要;虽然现在也能使用json结构用于网络传输,但是相对于Protobuf来说,json的效率还是不如的。在一些需要高速传输的场景,还是更加推荐使用Protobuf。
Protobuf使用的二进制数据方式,在表达相同的数据情况下,Protobuf对比json,体积可以减少60% - 70%;在网络同步情况下可以大大减少带宽的占用和流量消耗;并且是跨平台可用,跨语言可用等。
目录
3.1 protobuf中的数据类型 和 C++ 数据类型对照表
1 下载Protobuf3
https://github.com/protocolbuffers/protobuf/releases
点击链接跳转GitHub下载 3.21.12 版本;
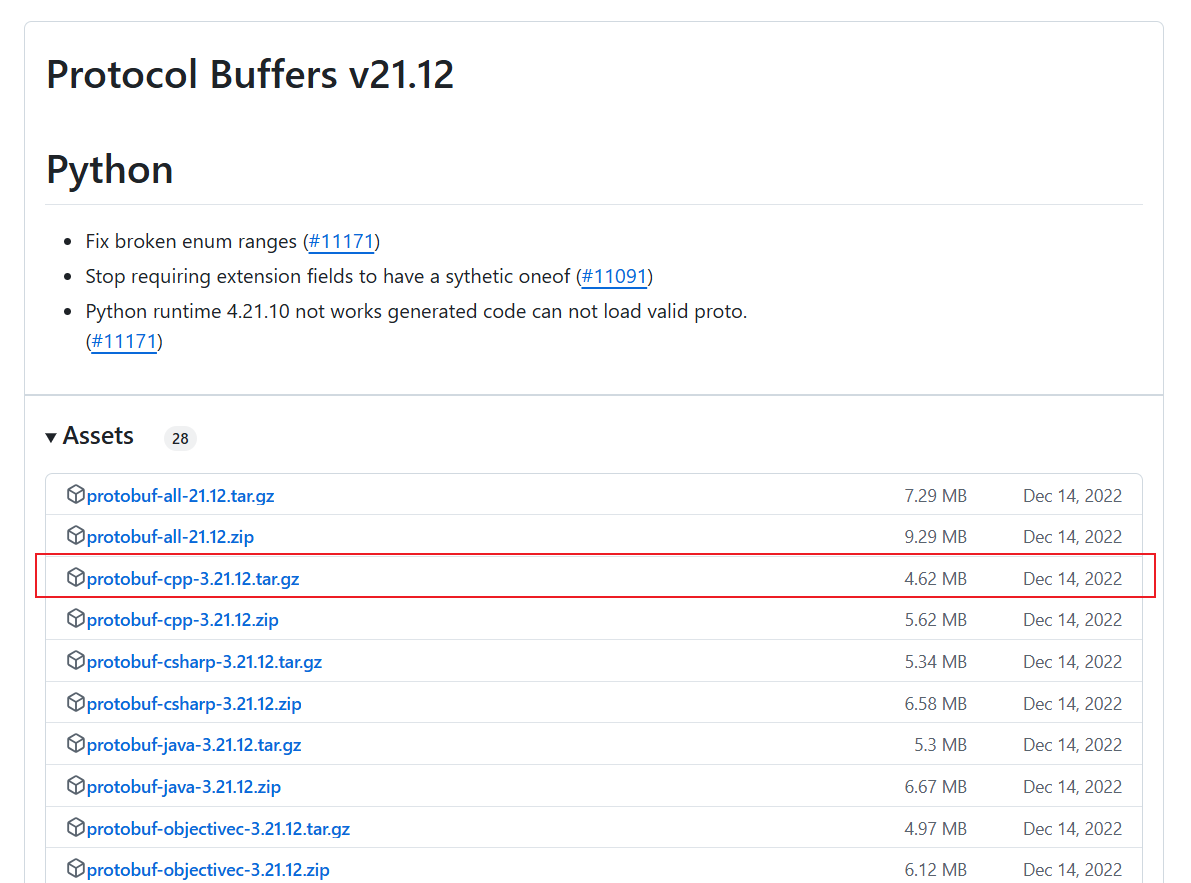
选择protobuf-cpp-3.21.12.tar.gz下载!
如果没有科学上网,可以点击下方gitee链接下载,我已经下载好上传了:
https://gitee.com/ygt777/protobuf3_-study.git
下载后,这个压缩包里面的源码,是Linux和Window环境通过的,均可以正常编译成库使用。
2 安装Protobuf3
2.1 Linux
注意:请使用 <= 3.21.12版本的源码进行安装,如果大于,下面安装方式无效!
# 解压缩
tar -zxvf protobuf-cpp-3.21.12.tar.gz
# 进入到解压目录
cd protobuf-3.21.12/
# 构建并安装
sudo ./configure # 检查安装环境, 生成 makefile
sudo make -j4 # 编译
sudo make install # 安装然后在 /etc/ld.so.conf 文件末尾加上 /usr/local/lib (库默认安装在此路径)
sudo vi /etc/ld.so.conf
然后使用命令:sudo ldconfig 更新系统动态链接库缓存。
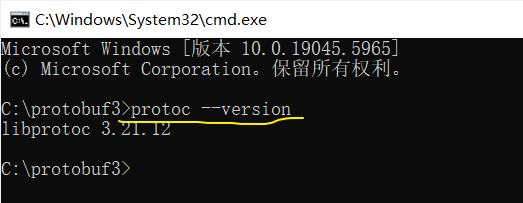
然后可以使用如下命令查看protobuf安装的版本:protoc --version
不出意外的话,应该会出现protobuf的版本号,表示已经源码安装成功了:

注意,上面提到的 /usr/local/lib 路径是默认安装路径,如果你的protobuf库没有安装在此路径,那么可以通过命令 sudo find / -name libprotobuf.so 查找出来的路径,就是你安装的路径,将路径按照如上步骤操作即可。
安装完成后,可以顺带将CMake给安装了:
2.2 Window
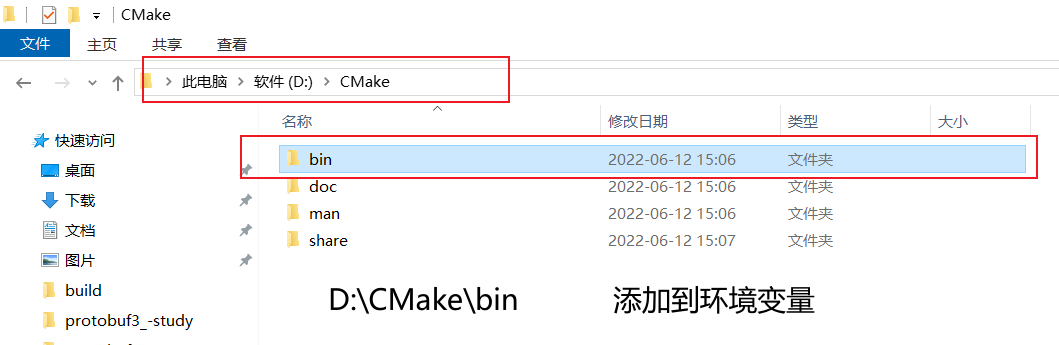
2.2.1 安装CMake
自行网上下载安装,安装后记得添加环境变量;
2.2.2 编译
直接右键解压到当前文件夹;
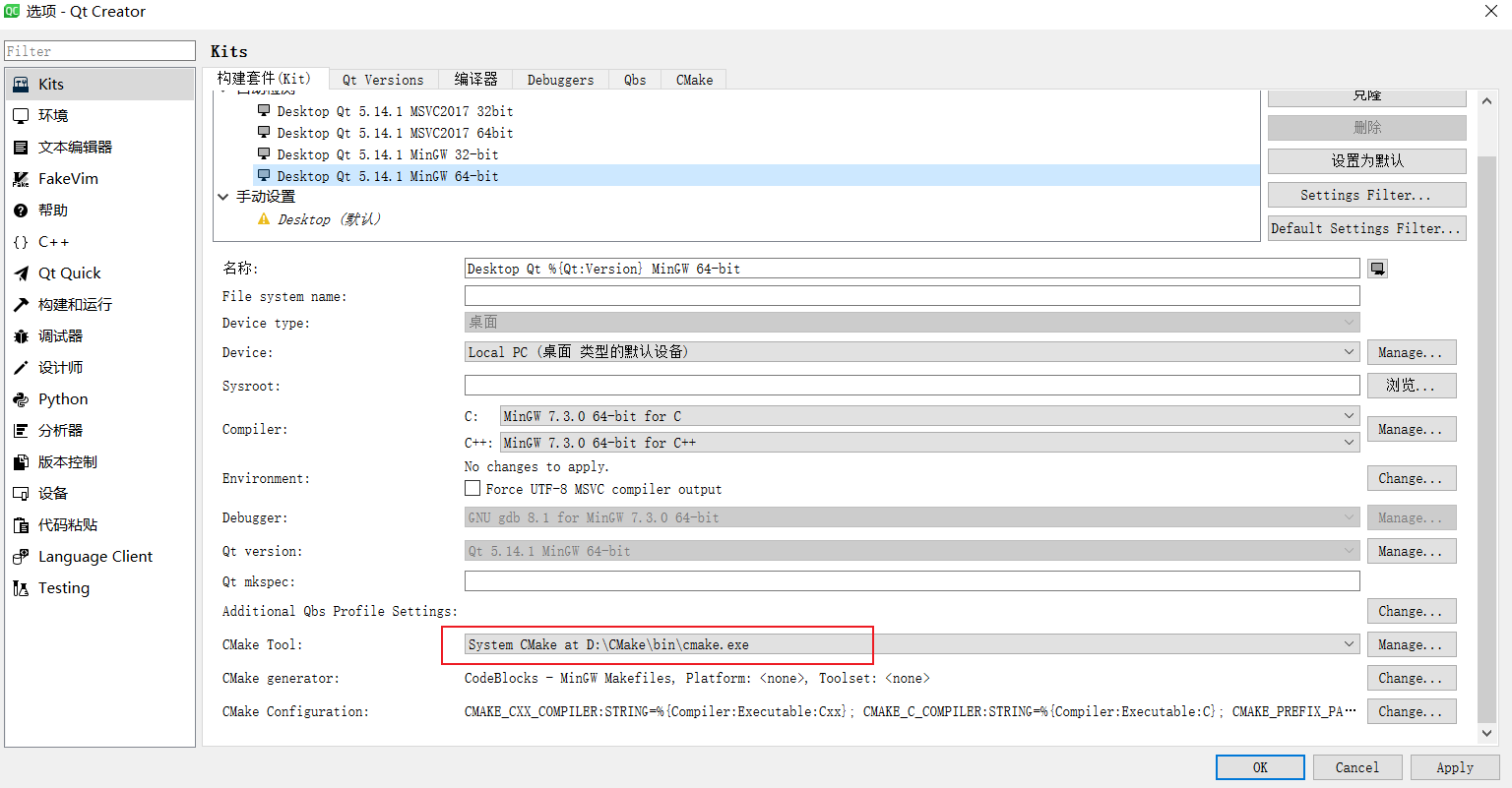
另外,请自行安装好QtCreator。安装QT5即可,例如我安装的是QT5.14。安装的时候需要添加上Mingw64编辑器安装,因为我们这里不搞msvc那一套,所以就使用mingw作为编译器了。
安装好QT后,配置好CMake:
然后使用QT打开文件夹内的CMakeLists.txt文件,如下:
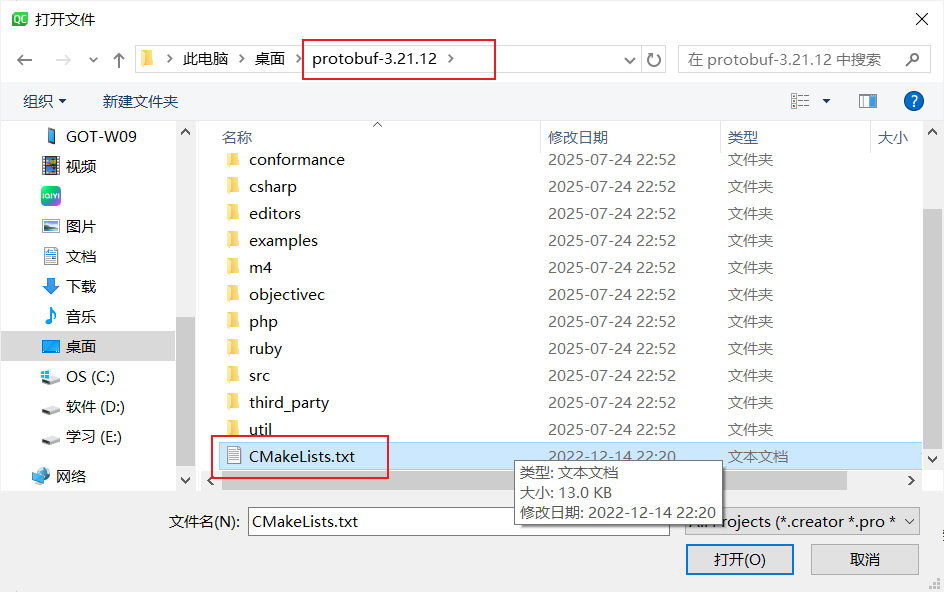
点击打开按钮后,会跳转到编译器选择,这里选择MinGW64作为编辑器:
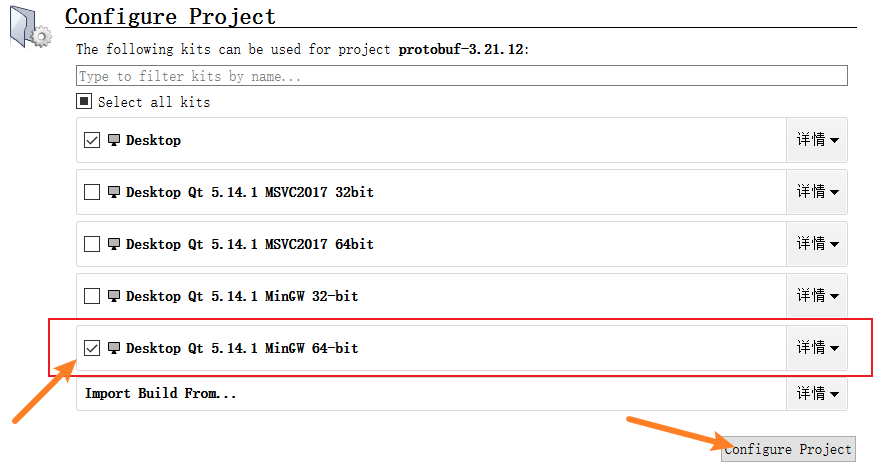
然后点击左侧菜单栏的"项目"按钮,对CMake做一些配置;
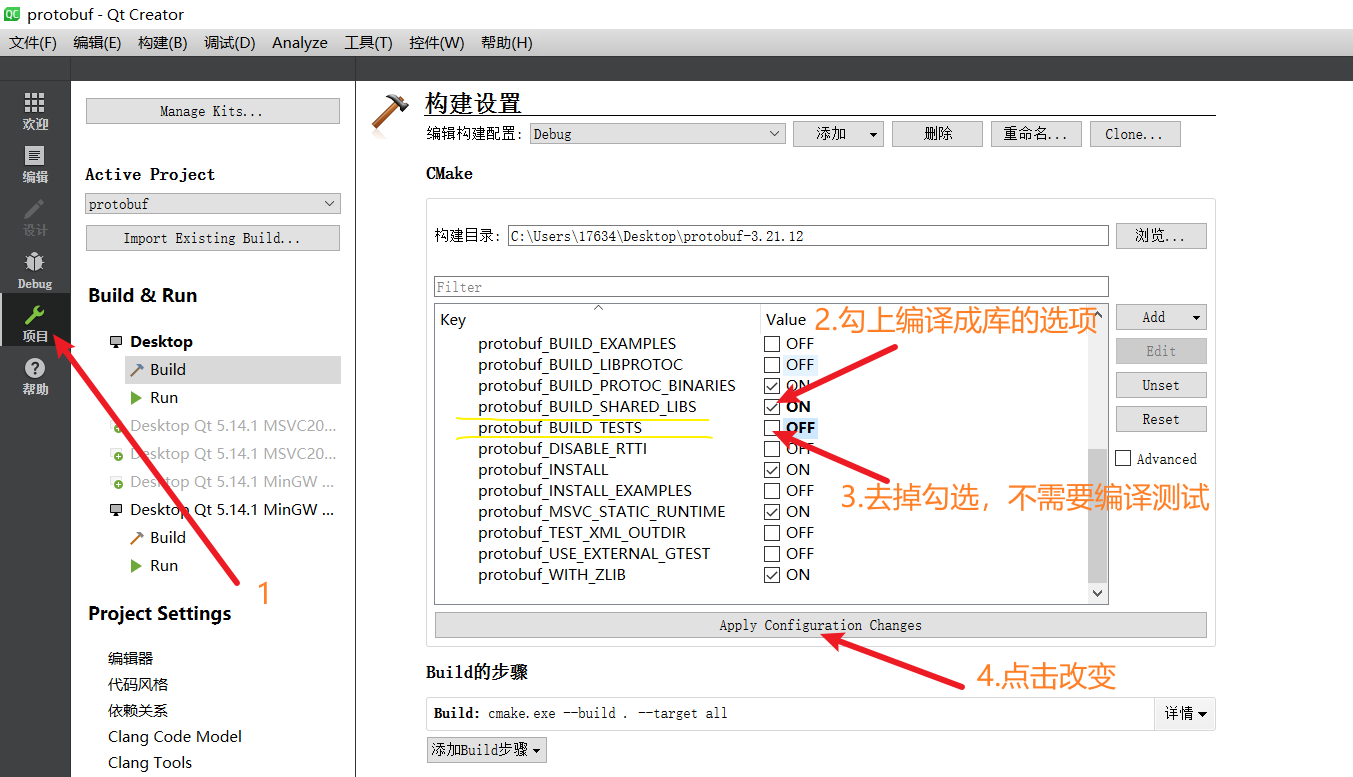
将编译成动态库选项勾上,将编译测试案例取消勾选,然后点击改变按钮,如下图:
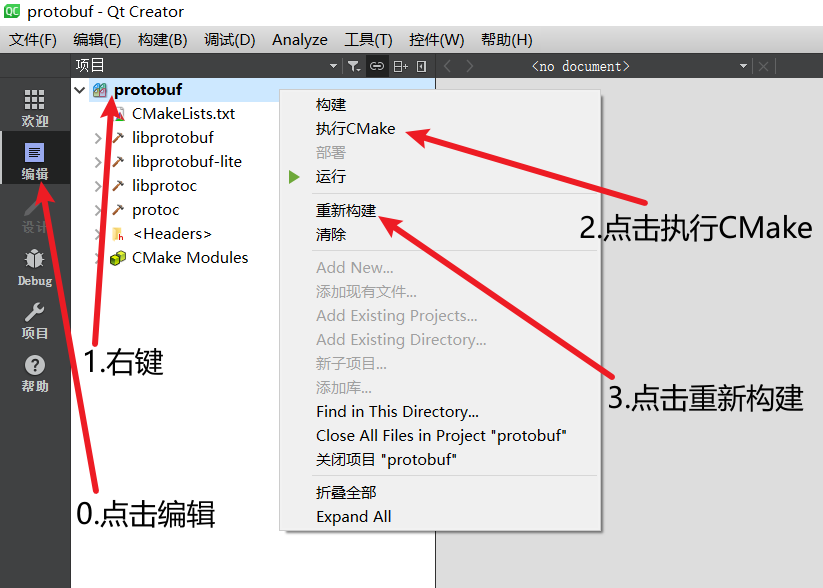
然后回到编辑页面,开始使用CMake编译动态库:
2.2.3 报错解决
如果你的报错与我下图一样,那么你可以接着往下看,如果不是,那么请自行解决报错:
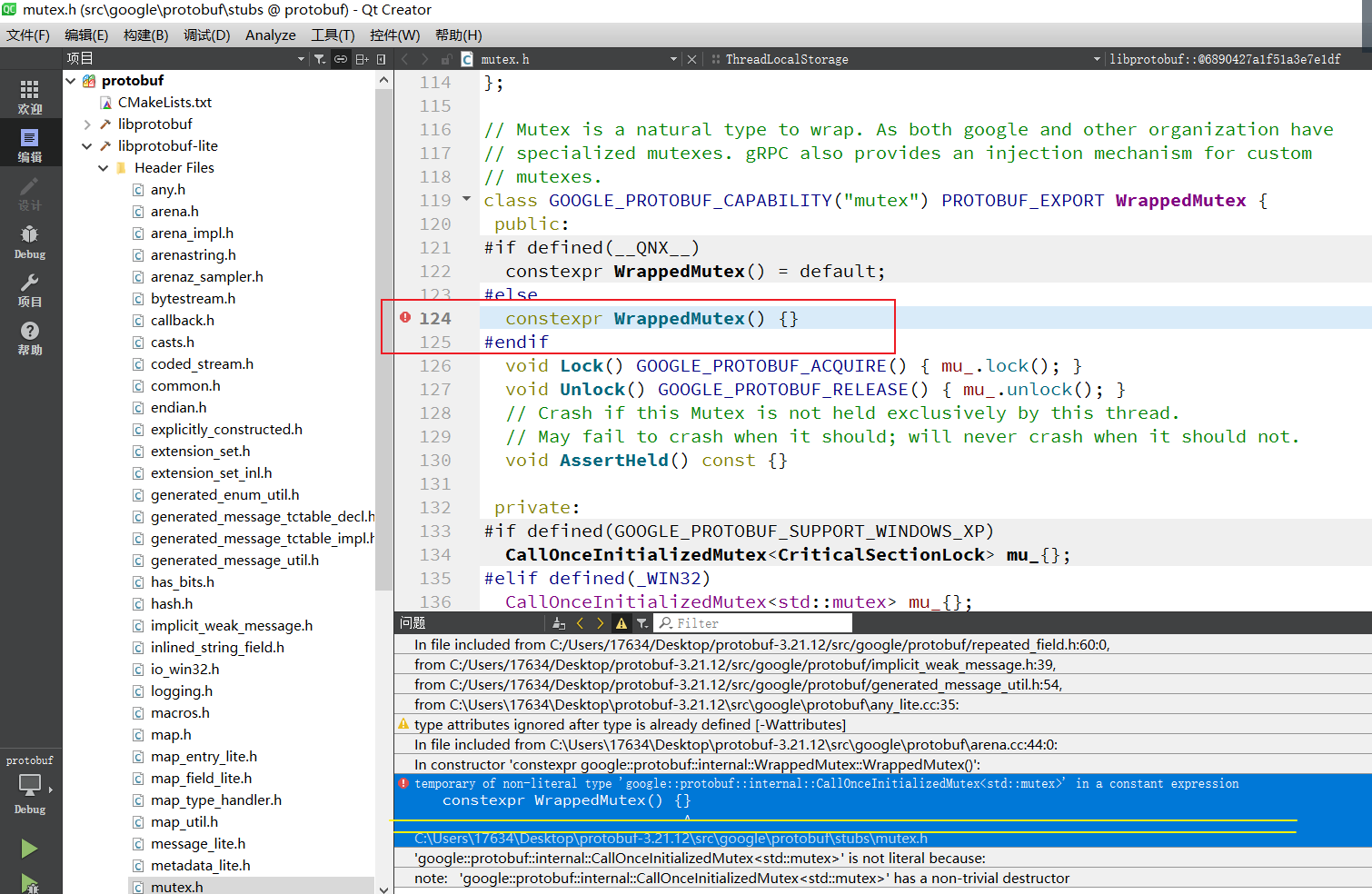
这个报错很好解决,将其改成与上面一样的就好,如下:
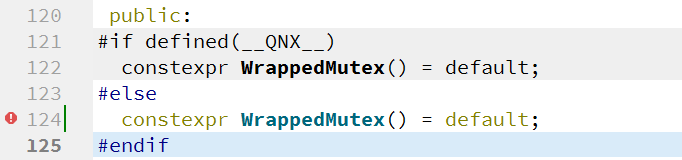
然后再次右键,点击重新构建即可!稍等片刻,即可编译成功。
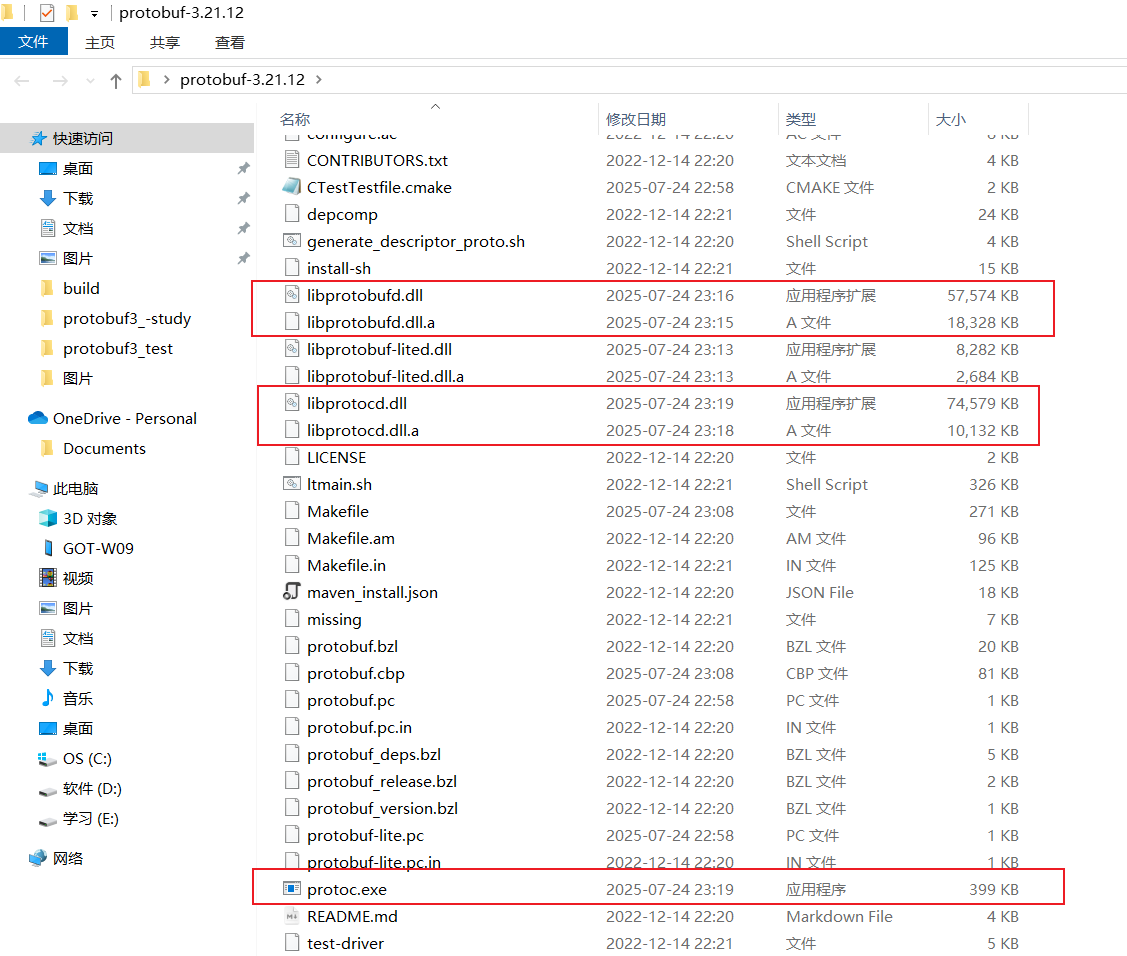
编译成功后,库就在文件夹内:
2.2.4 添加环境变量
我的话是在C盘新建了一个文件protobuf3,然后文件内部新建bin文件和lib文件夹;
bin文件夹存储protoc.exe可执行程序;lib文件夹存储.dll和.a库;
将编译好的.exe和库文件拷贝到相应的bin和lib路径后,添加到系统环境遍历中;
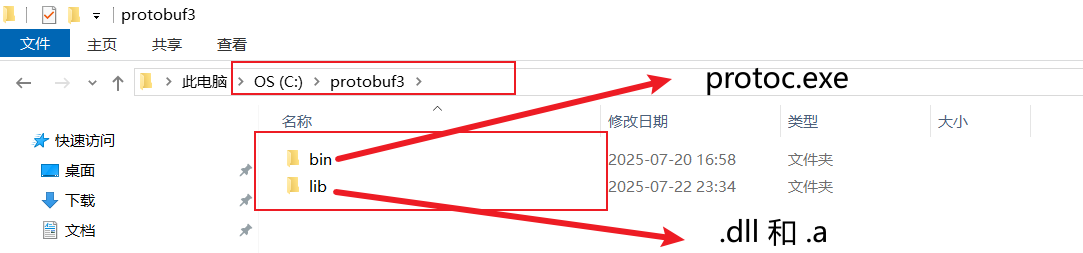
然后将bin文件夹路径和lib文件夹路径都添加到系统环境遍历中:

最后在cmd命令窗口输入命令 protoc --version 即可查看自己安装的protobuf版本了:
3 Protobuf3使用介绍
3.1 protobuf中的数据类型 和 C++ 数据类型对照表
| Protobuf 类型 | C++ 类型 | 备注 |
|---|---|---|
| double | double | 64位浮点数 |
| float | float | 32位浮点数 |
| int32 | int | 32位整数 |
| int64 | long | 64位整数 |
| uint32 | unsigned int | 32位无符号整数 |
| uint64 | unsigned int | 64位无符号整数 |
| sint32 | signed int | 32位整数,处理负数效率比int32更高 |
| sint64 | signed long | 64位整数,处理负数效率比int64更高 |
| fixed32 | unsigned int (32位) | 总是4个字节。如果数值总是比228大,这个类型会比uint32高效 |
| fixed64 | unsigned long (64位) | 总是8个字节。如果数值总是比256大,这个类型会比uint64高效 |
| sfixed32 | int (32位) | 总是4个字节 |
| sfixed64 | long (64位) | 总是8个字节 |
| bool | bool | 布尔类型 |
| string | string | 字符串必须是UTF-8编码 或者 7-bit ASCLL编码的文本 |
| bytes | string | 处理多字节的语言字符,如中文。建议protobuf中字符串类型使用 bytes |
| enum | enum | 枚举 |
| message | object 或者 class | 自定义的消息类型(在protobuf中,最终定义的类型都是在message包裹中的) |
橙色标识为常用类型。
3.2 语法
3.2.1 基本语法
编写按照如下格式去编写:
message 名字
{
类型 变量名 = 1;
类型 变量名 = 2;
类型 变量名 = 3;
}message是固定的,开头需要写上;
后面赋值的 1, 2, 3,根据顺序赋值,从1开始,自增赋值即可!
也可以不按顺序,但注意不要重复,否则会出问题。
例如:(这里不一定是结构体,只是用结构体打比方)
// C++ 结构体:
strcut Person {
int id;
std::string name;
std::string sex;
}
// Protobuf:
message Person {
int32 id = 1;
bytes name = 2;
bytes sex = 3;
}3.2.2 repeated限定修饰符
如果说,需要设置数组类型或者说是容器类型,那么就需要使用repeated去修饰,表明该值是一个可以存储多个数据的变量;
// C++ 结构体:
strcut Person {
int id;
std::string name[5];
std::vector<std::string> sex;
}
// Protobuf:
message Person {
int32 id = 1;
repeated bytes name = 2;
repeated bytes sex = 3;
}使用repeated修饰后,其就变成了动态数据,可以根据插入的元素自动新增内存空间。
另外简单说一下,required和optional是protobuf2中的修饰,在protobuf3中已经被移除:
- required:表示该值是必须要设置的;
- optional:消息格式中该字段可以有0个或1个值(不超过1个);即可以不用设置它;
3.3 编写.proto文件
protobuf最重要的一环就是编写.proto文件了,需要使用到该文件去生成相应的处理类。
开头一定要写上:syntax = "proto3";
注意,所有类型一定是要在message中包裹着的。
3.3.1 单个message
syntax = "proto3";
message Person {
int32 id = 1;
bytes name = 2;
bytes sex = 3;
int32 age = 4;
}3.3.2 多个message
syntax = "proto3";
message Address {
int32 num = 1;
bytes addr = 2;
}
# message 内嵌套了 message
message Person {
int32 id = 1;
bytes name = 2;
bytes sex = 3;
int32 age = 4;
Address addr = 5;
}3.3.3 存在多个元素的message
syntax = "proto3";
message Address {
int32 num = 1;
bytes addr = 2;
}
message Person {
int32 id = 1;
repeated bytes name = 2; # 相当于数组
bytes sex = 3;
int32 age = 4;
# 相当于数组
repeated Address addr = 5;
}3.4 编译.proto文件
编译语法:
protoc -I=$SRC_DIR --cpp_out=$DST_DIR xxx.proto
SRC_DIR 表示proto文件所在的目录,cpp_out指定了生成的代码的路径, xxx.proto指proto文件名。例如:
protoc -I=./ --cpp_out=./ Person.proto这样在当前目录生成了Person.pb.cc和Person.pb.h两个文件。
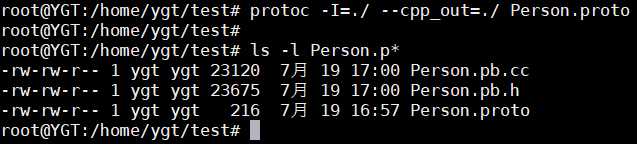
这里编译的是3.3.3编写的.proto文件。
固定格式的函数:
- clear_变量名():清空(初始化)私有成员变量的值;
- 变量名():获取私有成员变量的值;
- set_变量名(参数):设置私有成员变量的值;
- mutable_变量名():获得私有成员变量的地址,可以通过地址去修改值;
如果这个私有成员变量是数组类型:
- 变量名_size():获得数组的元素个数;
- add_变量名():给数组添加一个元素(添加一块存储元素的内存),并返回这个元素的指针;
- add_变量名(参数):给数组添加一个元素(添加一块存储元素的内存);
一般来说,常用的只有上面提到的这些。
以3.3.3中的id为例,以下是Person.pb.h头文件的部分函数声明源码:
public:
// int32 id = 1;
void clear_id(); // 清除值
int32_t id() const; // 获得值
void set_id(int32_t value); // 设置值
private:
int32_t _internal_id() const;
void _internal_set_id(int32_t value);以3.3.3中的name为例,以下是Person.pb.h头文件的部分函数声明源码:
public:
// repeated bytes name = 2;
int name_size() const; // 获得数组元素个数
private:
int _internal_name_size() const;
public:
void clear_name(); // 清空数组
const std::string& name(int index) const; // 获得数组指定索引中的值
std::string* mutable_name(int index); // 获得数组指定索引中得值的指针
void set_name(int index, const std::string& value); // 设置数组指定索引位置的值,注意越界
void set_name(int index, std::string&& value);
void set_name(int index, const char* value);
void set_name(int index, const void* value, size_t size);
std::string* add_name(); // 给数组添加一个元素,返回的指针可直接修改值
void add_name(const std::string& value); // 给数组添加一个元素
void add_name(std::string&& value);
void add_name(const char* value);
void add_name(const void* value, size_t size);
const ::PROTOBUF_NAMESPACE_ID::RepeatedPtrField<std::string>& name() const;
::PROTOBUF_NAMESPACE_ID::RepeatedPtrField<std::string>* mutable_name();
private:
const std::string& _internal_name(int index) const;
std::string* _internal_add_name();4 代码使用
先提前知道一下序列化和反序列的函数:
SerializeToString 函数用于序列化,参数需要传std::string的地址
ParseFromString 函数用于反序列化,参数需要传需要反序列化的二进制数据提前准备CMakeLists.txt文件
cmake_minimum_required(VERSION 3.5.2)
project(Test)
set(CMAKE_CXX_STANDARD 11)
# 搜索当前路径下的所有文件赋值给SRC
aux_source_directory(. SRC)
# 生成名为 Test 的可执行程序
ADD_EXECUTABLE(Test ${SRC})
# 链接protobuf库
TARGET_LINK_LIBRARIES(Test protobuf)4.1 针对单个message的代码应用
注意,这里对应的是3.3.1中的Person.proto文件!
编译命令:protoc -I=./ --cpp_out=./ Person.proto
编写代码,main.cpp
#include "MyTest.h"
#include "Person.pb.h"
int main(int argc, char **argv) {
// 序列化
Person p;
p.set_id(1);
p.set_name("小明");
p.set_sex("man");
p.set_age(26);
std::string output = "";
// 序列化对象,最终得到一个二进制字符串
p.SerializeToString(&output);
//////////////////////////////////////////////////////////////////////////////////////////////////////////////////////
// 反序列化
Person pp;
pp.ParseFromString(output);
std::cout << "id = " << pp.id() << std::endl;
std::cout << "name = " << pp.name() << std::endl;
std::cout << "age = " << pp.age() << std::endl;
std::cout << "sex = " << pp.sex() << std::endl;
return 0;
}通过定义Person对象,然后使用公共函数对私有成员变量进行设置值;然后通过SerializeToString函数进行序列化,得到二进制数据;
反序列化则需要再定义一个Person对象,通过函数ParseFromString对二进制数据进行反序列化,反序列化的结构存储在Person对象中,通过对象去调用函数获取值即可;
编译运行测试:
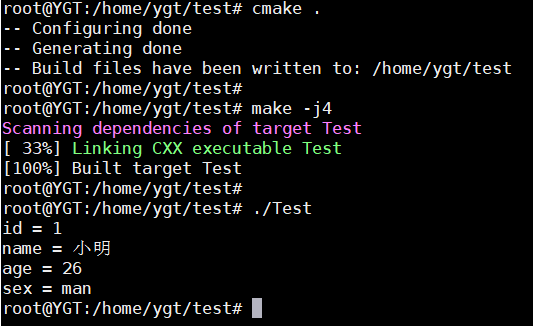
运行结果与设置的一样!
4.2 针对多个message的代码应用
注意,这里对应的是3.3.2中的Person.proto文件!
编译命令:protoc -I=./ --cpp_out=./ Person.proto
编写代码,main.cpp
#include <iostream>
#include <string>
#include "Person.pb.h"
int main(int argc, char **argv) {
// 序列化
Person p;
p.set_id(1);
p.set_name("小明");
p.set_sex("man");
p.set_age(26);
// 通过mutable_addr函数获得私有成员变量地址后,再通过地址去设置数据
Address *mAddr = p.mutable_addr();
mAddr->set_num(111);
mAddr->set_addr("广东省广州市");
std::string output = "";
// 序列化对象,最终得到一个二进制字符串
p.SerializeToString(&output);
//////////////////////////////////////////////////////////////////////////////////////////////////////////////////////
// 反序列化
Person pp;
pp.ParseFromString(output);
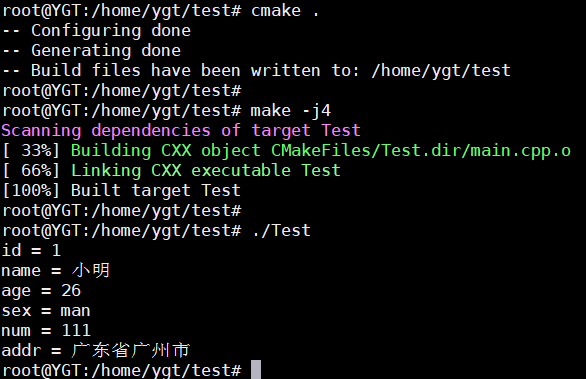
std::cout << "id = " << pp.id() << std::endl;
std::cout << "name = " << pp.name() << std::endl;
std::cout << "age = " << pp.age() << std::endl;
std::cout << "sex = " << pp.sex() << std::endl;
// 可通过addr函数结构,再进行下一步的获取值
const Address &tmpAddr = pp.addr();
std::cout << "num = " << tmpAddr.num() << std::endl;
std::cout << "addr = " << tmpAddr.addr() << std::endl;
return 0;
}
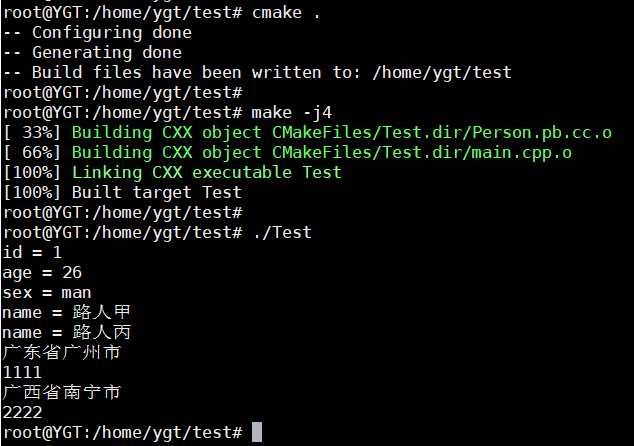
4.3 针对存在多个元素的message的代码应用
注意,这里对应的是3.3.3中的Person.proto文件!
编译命令:protoc -I=./ --cpp_out=./ Person.proto
编写代码,main.cpp
#include <iostream>
#include <string>
#include "Person.pb.h"
int main(int argc, char **argv) {
// 序列化
Person p;
p.set_id(1);
p.set_sex("man");
p.set_age(26);
// name是一个动态数组了
// 方式一:
// p.add_name(); // 首先需要给数组新增一个元素
// p.set_name(0, "路人甲"); // 通过索引给第一个元素设置值
// p.add_name();
// p.set_name(1, "路人乙"); // 通过索引给第二个元素设置值
// 注意,如果索引越界会触发段错误
// p.set_name(2, "段错误"); // 因为没有调用p.add_name();给数组新增一个元素,所以这里会触发段错误
// 方式二:
p.add_name("路人甲");
p.add_name("路人丙");
Address *addre = p.add_addr(); // 新增一个元素
addre->set_addr("广东省广州市");
addre->set_num(1111);
addre = p.add_addr(); // 新增一个元素
addre->set_addr("广西省南宁市");
addre->set_num(2222);
std::string output = "";
// 序列化对象,最终得到一个二进制字符串
p.SerializeToString(&output);
//////////////////////////////////////////////////////////////////////////////////////////////////////////////////////
// 反序列化
Person pp;
pp.ParseFromString(output);
std::cout << "id = " << pp.id() << std::endl;
std::cout << "age = " << pp.age() << std::endl;
std::cout << "sex = " << pp.sex() << std::endl;
int size = pp.name_size(); // 获得数组的个数
for (int i = 0; i < size; ++i) {
std::cout << "name = " << pp.name(i) << std::endl;
}
int addressSize = pp.addr_size();
for (int i = 0; i < addressSize; ++i) {
const ::Address &tmpAddr = pp.addr(i);
std::cout << tmpAddr.addr() << std::endl;
std::cout << tmpAddr.num() << std::endl;
}
return 0;
}
如果不知道有什么函数可以调用,就去看看编译出来的Person.pb.h文件,.cpp文件可不用理会。
5. 序列化和反序列化
5.1 序列化
序列化是指将数据结构或对象转换为可以在储存或传输中使用的二进制格式的过程。在计算机科学中,序列化通常用于将内存中的对象持久化存储到磁盘上,或者在分布式系统中进行数据传输和通信。
Protobuf 中为我们提供了相关的用于数据序列化的 API,如下所示:
// 头文件目录: google\protobuf\message_lite.h
// --- 将序列化的数据 数据保存到内存中
// 将类对象中的数据序列化为字符串, c++ 风格的字符串, 参数是一个传出参数
bool SerializeToString(std::string* output) const;
// 将类对象中的数据序列化为字符串, c 风格的字符串, 参数 data 是一个传出参数
bool SerializeToArray(void* data, int size) const;
// ------ 写磁盘文件, 只需要调用这个函数, 数据自动被写入到磁盘文件中
// -- 需要提供流对象/文件描述符关联一个磁盘文件
// 将数据序列化写入到磁盘文件中, c++ 风格
// ostream 子类 ofstream -> 写文件
bool SerializeToOstream(std::ostream* output) const;
// 将数据序列化写入到磁盘文件中, c 风格
bool SerializeToFileDescriptor(int file_descriptor) const;5.2 反序列化
反序列化是指将序列化后的二进制数据重新转换为原始的数据结构或对象的过程。通过反序列化,我们可以将之前序列化的数据重新还原为其原始的形式,以便进行数据的读取、操作和处理。
Protobuf 中为我们提供了相关的用于数据序列化的 API,如下所示:
// 头文件目录: google\protobuf\message_lite.h
bool ParseFromString(const std::string& data) ;
bool ParseFromArray(const void* data, int size);
// istream -> 子类 ifstream -> 读操作
// wo ri
// w->写 o: ofstream , r->读 i: ifstream
bool ParseFromIstream(std::istream* input);
bool ParseFromFileDescriptor(int file_descriptor);6 Protobuf3中的枚举
protobuf中的枚举定义,跟C++中的一样!
但是,Protobuf的枚举元素之间使用分号间隔 ';',并且需要注意一点proto3 中的第一个枚举值必须为 0,第一个元素以外的元素值可以随意指定。
并且,每个元素必须设置默认值!!!
例如:
// C++枚举:
enum KeyBoard {
A = 0,
B,
C,
D = 100
}
// Protobuf枚举:
enum KeyBoard {
A = 0;
B = 1;
C = 2;
D = 100;
}6.1 编写测试枚举的Address.proto文件
syntax = "proto3";
// 定义枚举
enum KeyBoard {
A = 0;
B = 1;
C = 2;
D = 100;
}
message Address {
int32 num = 1;
bytes addr = 2;
KeyBoard key = 3;
}编译命令:protoc -I=./ --cpp_out=./ Address.proto
编译后,可以查看枚举有什么接口:
public:
// .KeyBoard key = 3;
void clear_key();
::KeyBoard key() const;
void set_key(::KeyBoard value);
private:
::KeyBoard _internal_key() const;
void _internal_set_key(::KeyBoard value);只有三个函数,clear_key()清除 和 key()获取 和 set_key()设置!
6.2 修改main函数使用
#include <iostream>
#include <string>
#include "Address.pb.h"
int main(int argc, char **argv) {
// 序列化
Address addre;
addre.set_addr("广东省广州市");
addre.set_num(1111);
addre.set_key(KeyBoard::C);
std::string output = "";
// 序列化对象,最终得到一个二进制字符串
addre.SerializeToString(&output);
//////////////////////////////////////////////////////////////////////////////////////////////////////////////////////
// 反序列化
Address tmpAddre;
tmpAddre.ParseFromString(output);
std::cout << "num = " << tmpAddre.num() << std::endl;
std::cout << "addr = " << tmpAddre.addr() << std::endl;
std::cout << "key = " << tmpAddre.key() << std::endl;
return 0;
}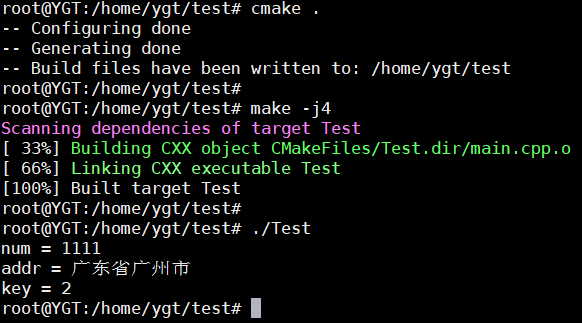
我们设置的枚举是KeyBoard::C,值为2;打印输出的key也是2,这是对的。
7 在.proto文件导入另一个.proto文件
如果说,多个message写入到一个.proto文件内觉得很臃肿,那么就可以将其拆分成多个.proto文件,然后再通过
导入到一个.proto文件去使用即可。
7.1 导入.proto文件
语法:
improt "xxx.proto";
# 如果是别的路径,需要指定具体路径"
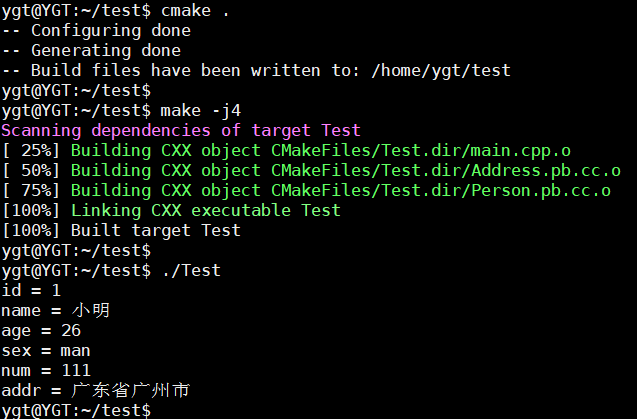
improt "abc/def/xxx.proto";首先准备两个.proto文件;
Person.proto
syntax = "proto3";
// 导入.proto文件
import "Address.proto";
message Person {
int32 id = 1;
bytes name = 2;
bytes sex = 3;
int32 age = 4;
Address addr = 5;
}Address.proto
syntax = "proto3";
message Address {
int32 num = 1;
bytes addr = 2;
}在Person.proto文件中,导入了Address.proto文件,并且使用了其内部定义的Address;
注意,所有.proto文件均要在开头写上:syntax = "proto3";
7.2 编译两个.proto文件
使用命令分别编译即可:
protoc -I=./ --cpp_out=./ Person.proto
protoc -I=./ --cpp_out=./ Address.proto这样就会生成:Person.pb.h 和 Person.proto 和 Address.pb.h 和 Address.pb.cc 四个文件。
7.3 修改main函数使用
只需要包含 Person.pb.h 头文件即可,因为在Person.proto文件中导入了Address.proto文件,所以生成出来的Person.pb.h头文件中已经包含了Person.pb.h头文件。
#include <iostream>
#include <string>
#include "Person.pb.h"
int main(int argc, char **argv) {
// 序列化
Person p;
p.set_id(1);
p.set_name("小明");
p.set_sex("man");
p.set_age(26);
// 通过mutable_addr函数获得私有成员变量地址后,再通过地址去设置数据
Address *mAddr = p.mutable_addr();
mAddr->set_num(111);
mAddr->set_addr("广东省广州市");
std::string output = "";
// 序列化对象,最终得到一个二进制字符串
p.SerializeToString(&output);
//////////////////////////////////////////////////////////////////////////////////////////////////////////////////////
// 反序列化
Person pp;
pp.ParseFromString(output);
std::cout << "id = " << pp.id() << std::endl;
std::cout << "name = " << pp.name() << std::endl;
std::cout << "age = " << pp.age() << std::endl;
std::cout << "sex = " << pp.sex() << std::endl;
// 可通过addr函数结构,再进行下一步的获取值
const Address &tmpAddr = pp.addr();
std::cout << "num = " << tmpAddr.num() << std::endl;
std::cout << "addr = " << tmpAddr.addr() << std::endl;
return 0;
}
8 Protobuf3包的使用 (命名空间)
在C++中,如果有两个类名相同了,为了区分,就得使用命名空间(namespace)去区分;对应到protobuf中,是没有命名空间的概念的,但是有包的概念,其实也可以理解成命名空间。
8.1 给.proto定义命名空间
格式:
package 写上自定义包名字;编写Address.proto文件,并定义包名为MyAddress:
syntax = "proto3";
// 定义包名
package MyAddress;
// 定义枚举
enum KeyBoard {
A = 0;
B = 1;
C = 2;
D = 100;
}
message Address {
int32 num = 1;
bytes addr = 2;
KeyBoard key = 3;
}编写Person.proto文件,并定义包名为MyPerson,然后导入Address.proto:
syntax = "proto3";
// 定义包名
package MyPerson;
// 导入.proto文件
import "Address.proto";
message Person {
int32 id = 1;
bytes name = 2;
bytes sex = 3;
int32 age = 4;
// 使用时需要写上命名空间
MyAddress.Address addr = 5;
}8.2 编译两个.proto文件
使用命令分别编译即可:
protoc -I=./ --cpp_out=./ Person.proto
protoc -I=./ --cpp_out=./ Address.proto这样就会生成:Person.pb.h 和 Person.proto 和 Address.pb.h 和 Address.pb.cc 四个文件。
可以查看下Person.pb.h头文件部分内容:
namespace MyPerson {
class Person;
struct PersonDefaultTypeInternal;
extern PersonDefaultTypeInternal _Person_default_instance_;
} // namespace MyPerson可以看出,内部确实是使用到了命名空间去包裹着了。
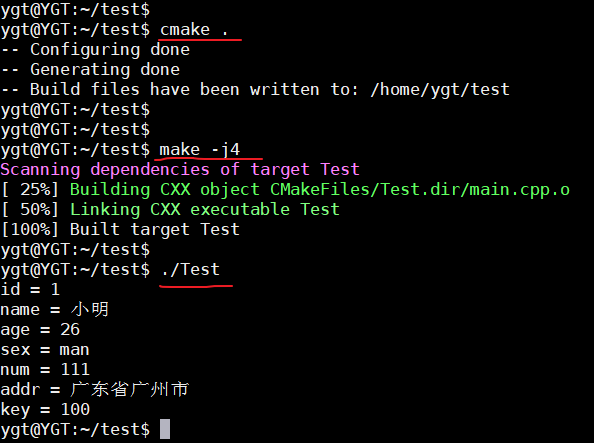
8.3 修改main函数使用
在使用Person类和Address类和KeyBord枚举时,都需要加上命名空间了,否则会报错的。
建议在使用类时,直接在类前面添加上命名空间去修饰,不要使用 using namespace 。
#include <iostream>
#include <string>
#include "Person.pb.h"
// 添加命名空间,或者直接在定义类对象时加上命名空间
// using namespace MyPerson;
// using namespace MyAddress;
int main(int argc, char **argv) {
// 序列化
MyPerson::Person p; // 定义时需要加上命名空间
p.set_id(1);
p.set_name("小明");
p.set_sex("man");
p.set_age(26);
// 通过mutable_addr函数获得私有成员变量地址后,再通过地址去设置数据
MyAddress::Address *mAddr = p.mutable_addr();
mAddr->set_num(111);
mAddr->set_addr("广东省广州市");
mAddr->set_key(MyAddress::KeyBoard::D); // 使用枚举也需要加上指定的命名空间
std::string output = "";
// 序列化对象,最终得到一个二进制字符串
p.SerializeToString(&output);
//////////////////////////////////////////////////////////////////////////////////////////////////////////////////////
// 反序列化
MyPerson::Person pp;
pp.ParseFromString(output);
std::cout << "id = " << pp.id() << std::endl;
std::cout << "name = " << pp.name() << std::endl;
std::cout << "age = " << pp.age() << std::endl;
std::cout << "sex = " << pp.sex() << std::endl;
// 可通过addr函数结构,再进行下一步的获取值
const MyAddress::Address &tmpAddr = pp.addr();
std::cout << "num = " << tmpAddr.num() << std::endl;
std::cout << "addr = " << tmpAddr.addr() << std::endl;
std::cout << "key = " << tmpAddr.key() << std::endl;
return 0;
}
9 Window环境使用Protobuf3
用法与上面提到的完全一样!
9.1 编译.proto文件
在命令提示符窗口(cmd),输入如下命令:(与Linux的一致)
protoc -I=./ --cpp_out=./ Person.proto
protoc -I=./ --cpp_out=./ Address.protoPerson.proto
syntax = "proto3";
// 定义包名
package MyPerson;
// 导入.proto文件
import "Address.proto";
message Person {
int32 id = 1;
bytes name = 2;
bytes sex = 3;
int32 age = 4;
// 使用时需要写上命名空间
MyAddress.Address addr = 5;
}Address.proto
syntax = "proto3";
// 定义包名
package MyAddress;
// 定义枚举
enum KeyBoard {
A = 0;
B = 1;
C = 2;
D = 100;
}
message Address {
int32 num = 1;
bytes addr = 2;
KeyBoard key = 3;
}9.2 通过CMake编译项目
如下目录结构:
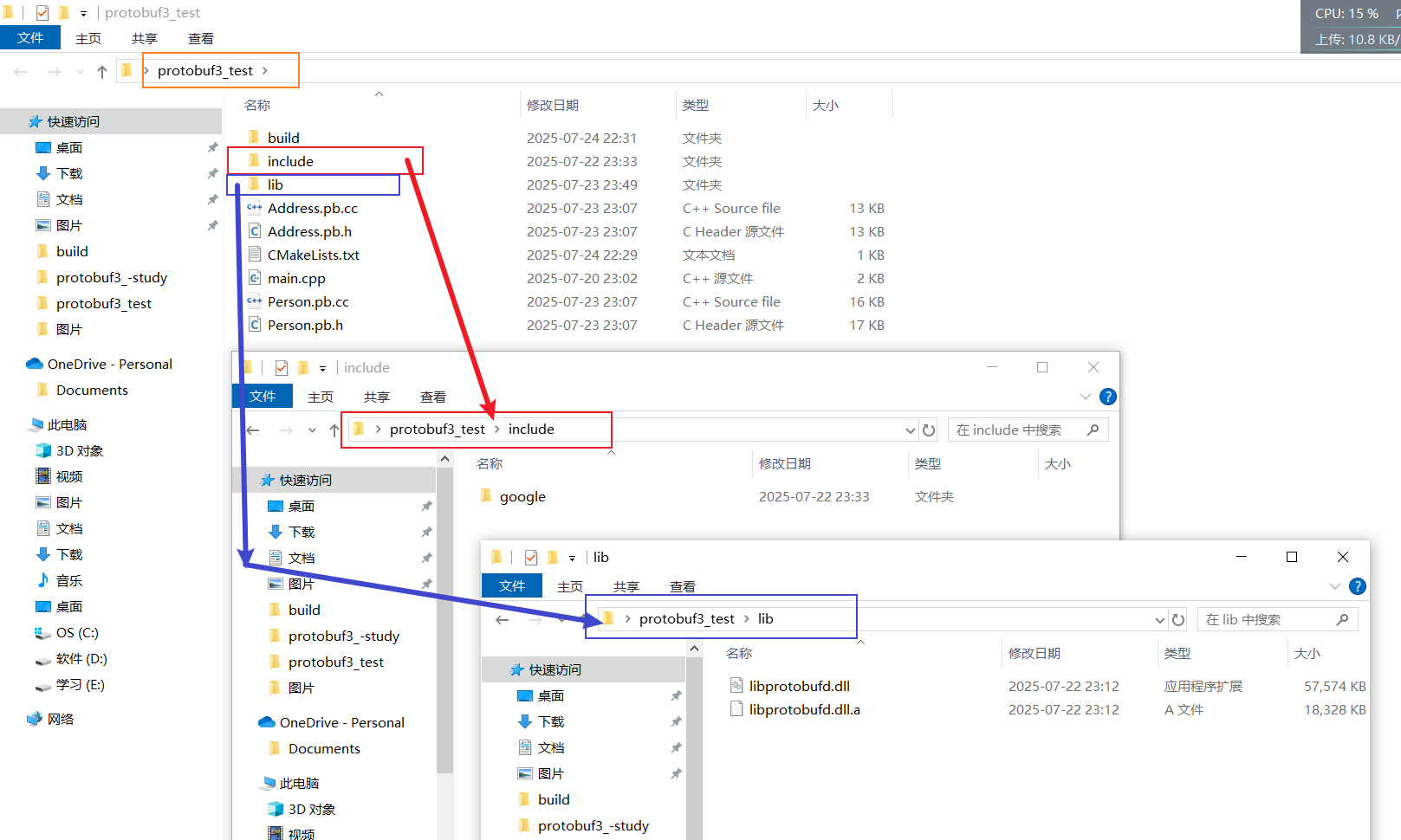
注意,include内的google文件夹是protubuf所需的头文件,是在下载的protobuf源码中的src文件夹内的,将其拷贝过来即可:
main.cpp
#include <iostream>
#include <string>
#include "Person.pb.h"
int main(int argc, char *argv[])
{
// 序列化
MyPerson::Person p;
p.set_id(1);
p.set_name("小明");
p.set_sex("man");
p.set_age(26);
// 通过mutable_addr函数获得私有成员变量地址后,再通过地址去设置数据
MyAddress::Address *mAddr = p.mutable_addr();
mAddr->set_num(111);
mAddr->set_addr("广东省广州市");
mAddr->set_key(MyAddress::KeyBoard::D);
std::string output = "";
// 序列化对象,最终得到一个二进制字符串
p.SerializeToString(&output);
//////////////////////////////////////////////////////////////////////////////////////////////////////////////////////
// 反序列化
MyPerson::Person pp;
pp.ParseFromString(output);
std::cout << "id = " << pp.id() << std::endl;
std::cout << "name = " << pp.name() << std::endl;
std::cout << "age = " << pp.age() << std::endl;
std::cout << "sex = " << pp.sex() << std::endl;
// 可通过addr函数结构,再进行下一步的获取值
const MyAddress::Address &tmpAddr = pp.addr();
std::cout << "num = " << tmpAddr.num() << std::endl;
std::cout << "addr = " << tmpAddr.addr() << std::endl;
std::cout << "key = " << tmpAddr.key() << std::endl;
return 0;
}CMakeLists.txt
cmake_minimum_required(VERSION 3.5.2)
project(protobuf3_test)
SET(CMAKE_CXX_STANDARD 11)
# 搜索当前路径下的所有文件赋值给SRC
AUX_SOURCE_DIRECTORY(. SRC)
# 生成名为 Test 的可执行程序
ADD_EXECUTABLE(Test ${SRC})
# 指定链接头文件路径
INCLUDE_DIRECTORIES(${PROJECT_SOURCE_DIR}/include)
# 指定链接库路径
TARGET_LINK_DIRECTORIES(Test PRIVATE ${PROJECT_SOURCE_DIR}/lib)
# 链接 libprotobufd.dll 库到 Test 可执行文件
TARGET_LINK_LIBRARIES(Test protobufd)到此,代码准备工作已经做完了,可以使用CMake编译项目了;
进入到build文件夹,在命令提示符窗口(cmd),执行如下命令:
编译命令:
# 指定使用MinWG编译器编译生成Makefile文件
cmake -G "MinGW Makefiles" ..
# 使用mingw的make工具编译Makefile文件,生成可执行程序
mingw32-make -j4
# 运行可执行程序
Test.exe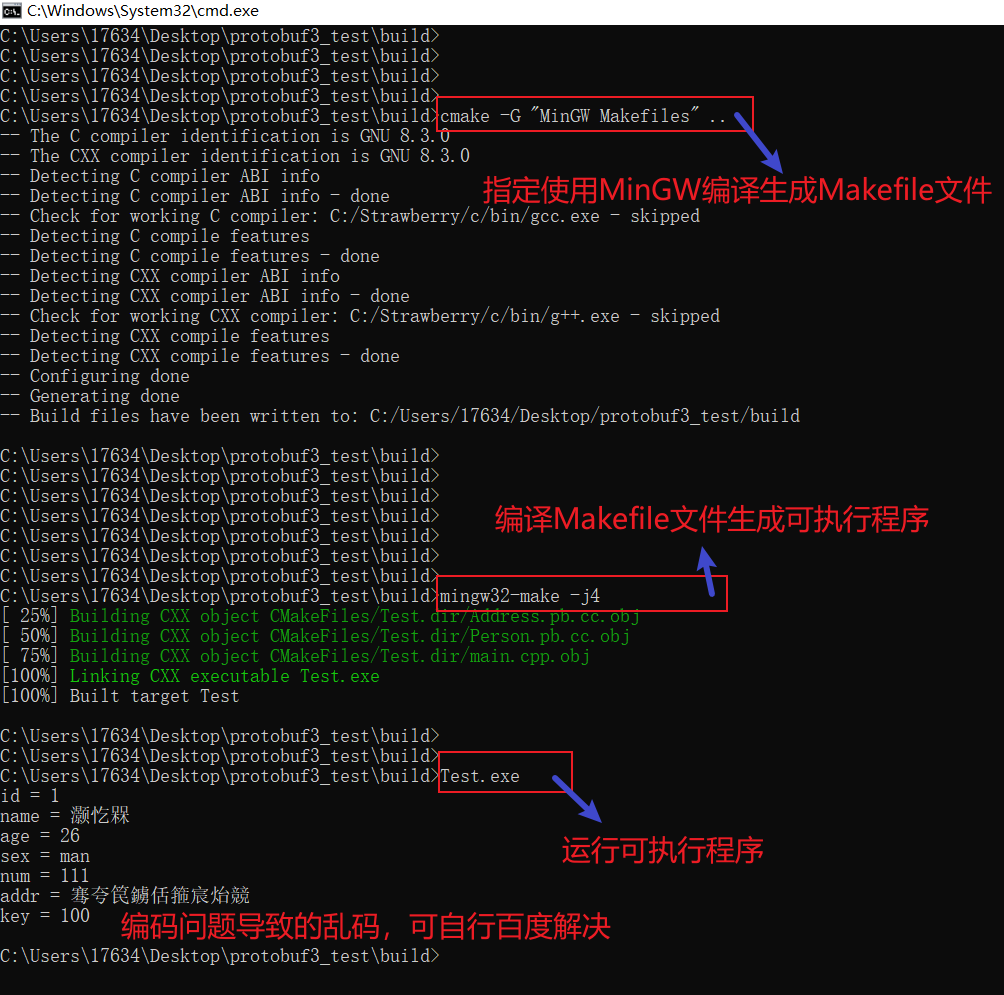
10 QtCreator配置Protoc工具
什么意思?
简单来说,如果.proto文件被修改了,那么又得去窗口通过命令去生成新的.h和.cpp文件,比较麻烦,所以通过工具去直接编译生成就方便很多了。
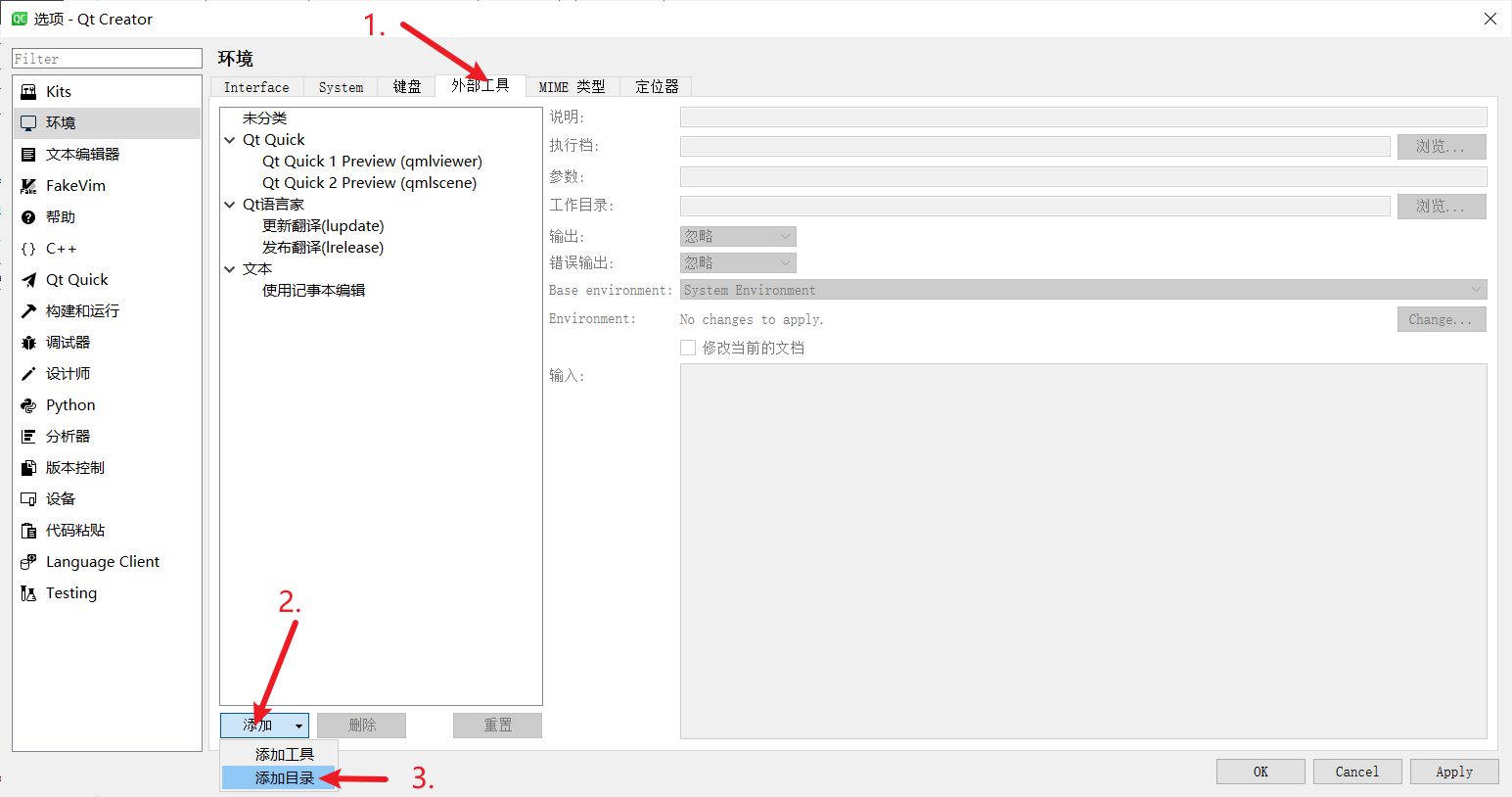
打开QtCreator,然后依次点击 工具 - 外部 - Configure...(配置...)
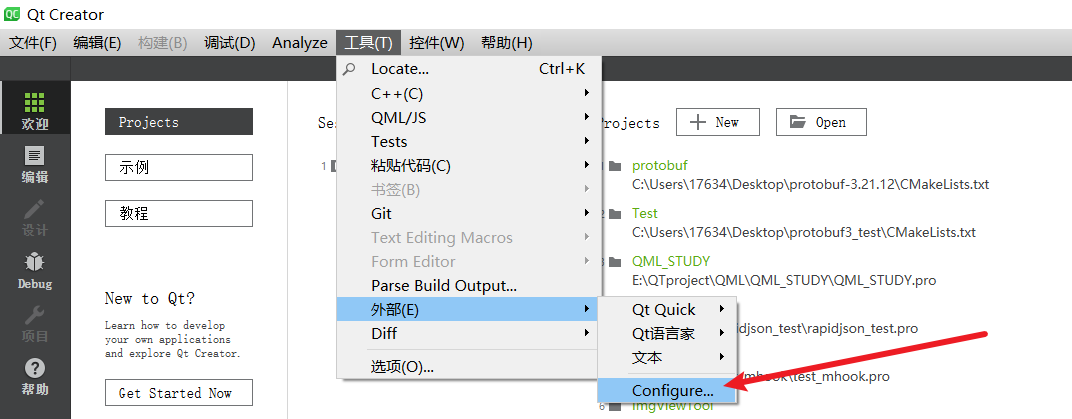
然后就会打开一个配置窗口,在配置窗口中配置protoc编译工具;
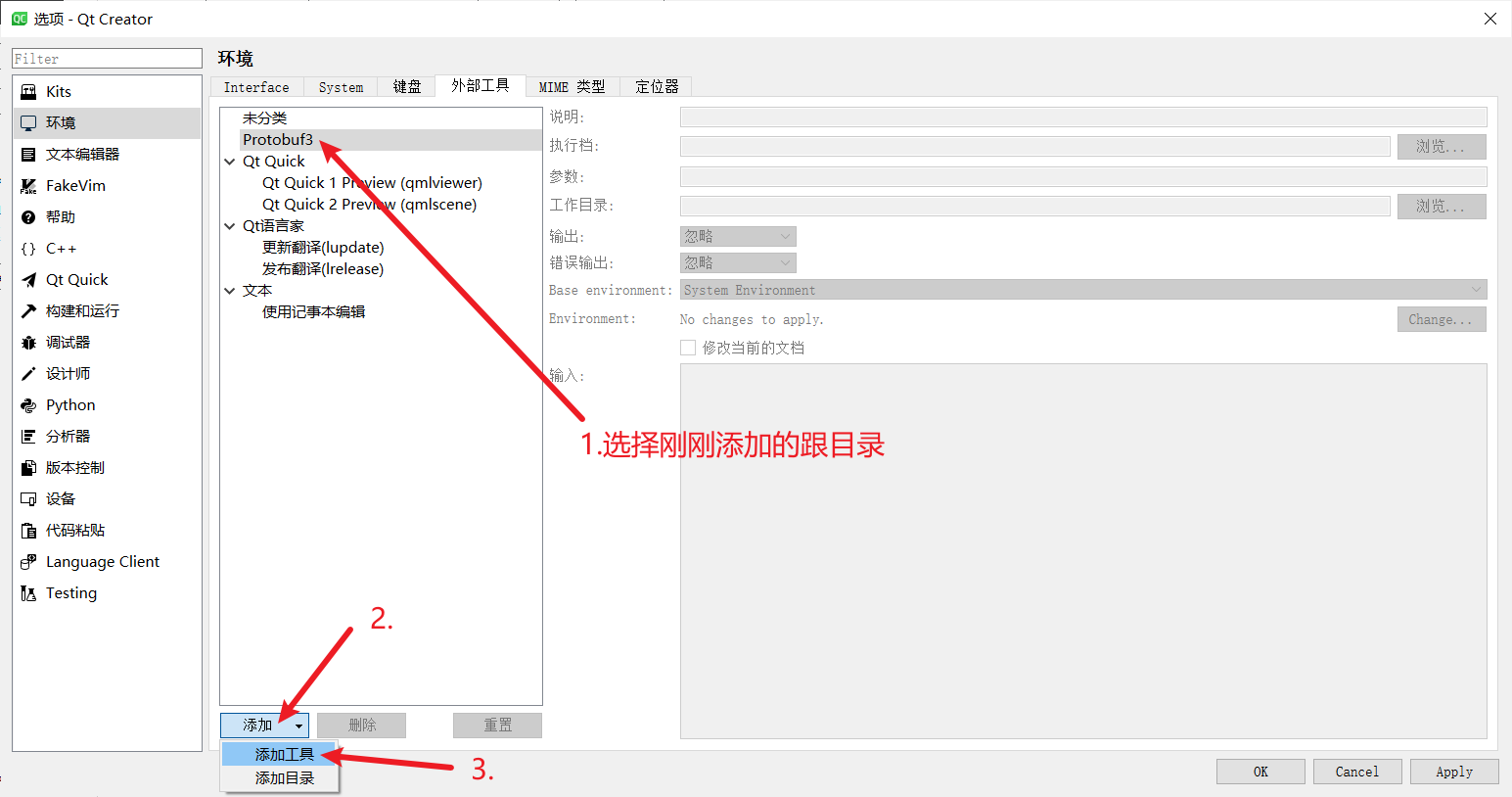
首先添加一个跟目录,命名为Protobuf3:
然后选中Protobuf3根目录,并添加工具:
最后,命名工具名为protoc,添加上编译工具的路径,并且添加上编译参数:
编译参数:
-I %{CurrentDocument:Path} --cpp_out=%{CurrentDocument:Path} %{CurrentDocument:FilePath}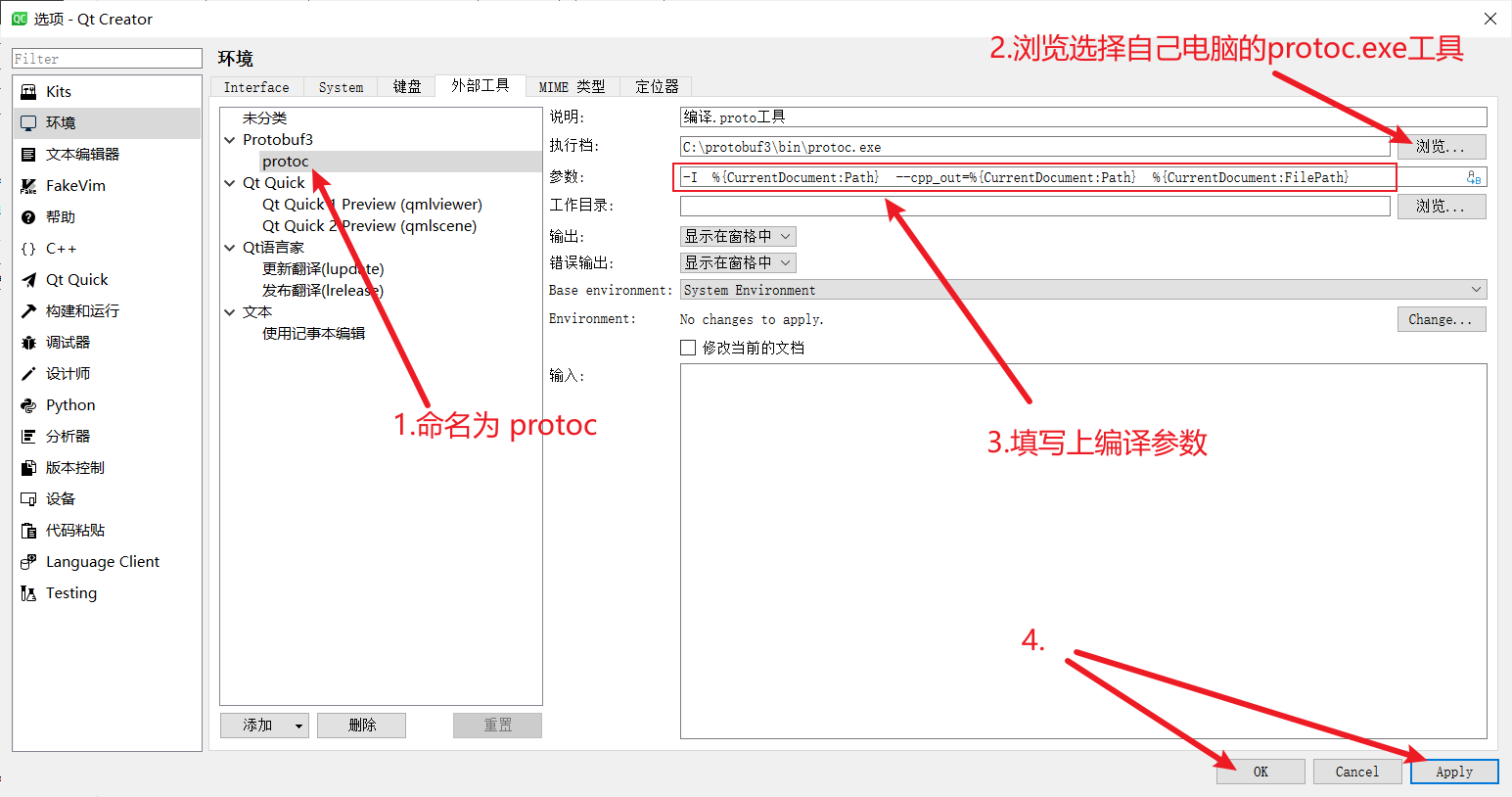
然后,在QtCreator打开一个.proto文件,即可执行编译:(一定要在当前打开的.proto文件进行编译,否则会编译失败)
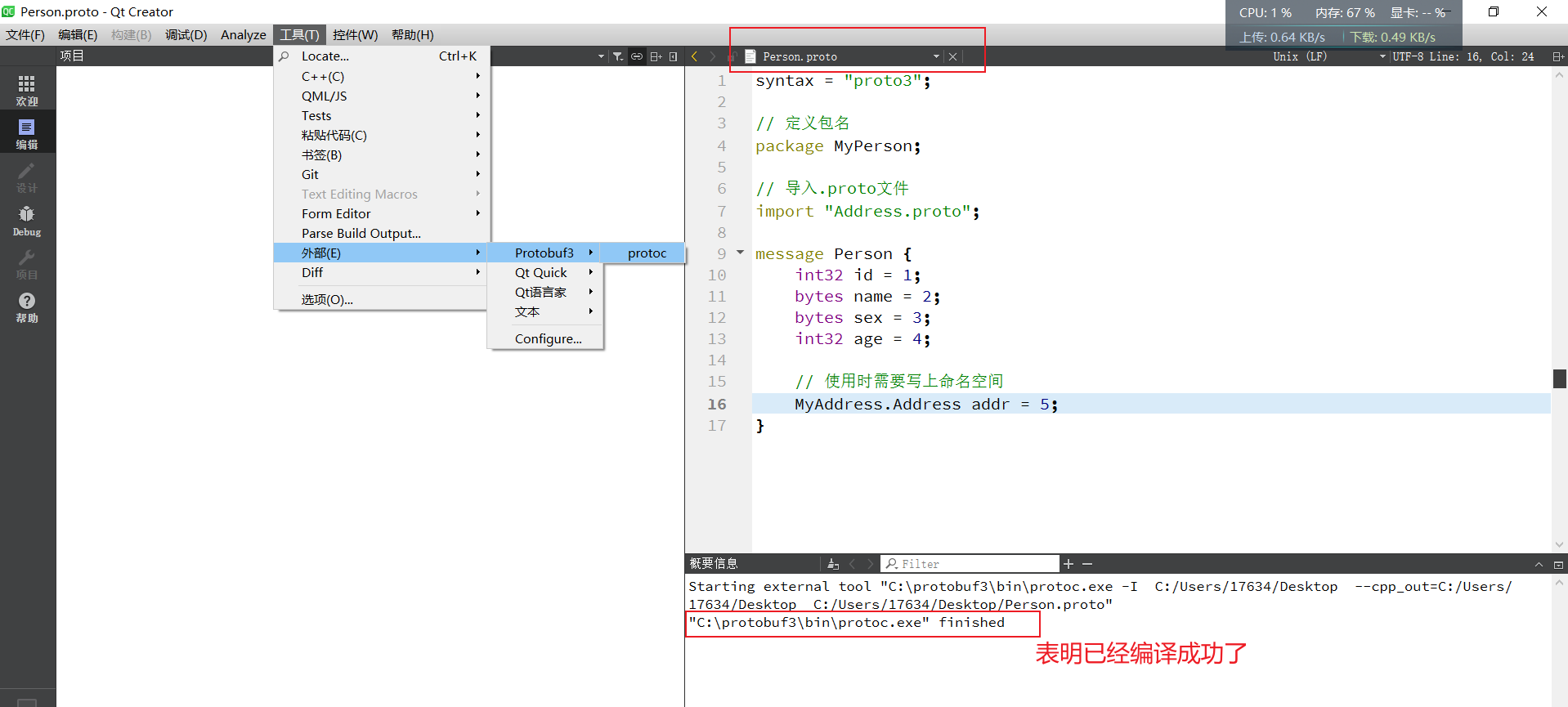
然后在.proto文件相同路径,就会有.h和.cpp文件了:
11 Protobuf与Json互转
其实可以将Protobuf对象的内容转换为Json字符串的,这样就可以更加直观的看到里面的内容,方便调试。
需要包含头文件:
// MessageToJsonString JsonStringToMessage
#include <google/protobuf/util/json_util.h>11.1 Protobuf转Json
函数原型:
util::Status MessageToJsonString(const Message& message,
std::string* output,
const JsonOptions& options);- 参数一:Protobuf对象
- 参数二:输出的字符串指针
- 参数三:可用于美化字符串格式;可忽略
实现代码:
// 序列化
MyPerson::Person p;
p.set_id(1);
p.set_name("小明");
p.set_sex("man");
p.set_age(26);
// 通过mutable_addr函数获得私有成员变量地址后,再通过地址去设置数据
MyAddress::Address *mAddr = p.mutable_addr();
mAddr->set_num(111);
mAddr->set_addr("广东省广州市");
mAddr->set_key(MyAddress::KeyBoard::D);
/// Protobuf转Json
std::string outputJson = "";
using google::protobuf::util::Status;
google::protobuf::util::JsonPrintOptions json_options;
json_options.add_whitespace = true; // 可选,美化输出
Status status1 = google::protobuf::util::MessageToJsonString(p, &outputJson, json_options);
if (status1.ok()) {
std::cout << outputJson << std::endl;
} else {
std::cerr << "Failed to parse protobuf to JSON string message: " << status1.message() << std::endl;
}11.2 Json转Protobuf
函数原型:
util::Status JsonStringToMessage(StringPiece input,
Message* message,
const JsonParseOptions& options);- 参数一:json字符串
- 参数二:输出的Protobuf对象
- 参数三:可忽略
实现代码:
/// Json转Protobuf
MyPerson::Person jToP;
std::string jsonStr = R"({
"id": 1,
"name": "Jtom",
"sex": "男",
"age": 26,
"addr": {
"num": 111,
"addr": "广东省深圳市",
"key": "D"
}
})";
using google::protobuf::util::Status;
Status status2 = google::protobuf::util::JsonStringToMessage(jsonStr, &jToP);
if (status2.ok()) {
std::cout << "id = " << jToP.id() << std::endl;
std::cout << "name = " << jToP.name() << std::endl;
std::cout << "age = " << jToP.age() << std::endl;
std::cout << "sex = " << jToP.sex() << std::endl;
// 可通过addr函数结构,再进行下一步的获取值
const MyAddress::Address &tmpAddr = jToP.addr();
std::cout << "num = " << tmpAddr.num() << std::endl;
std::cout << "addr = " << tmpAddr.addr() << std::endl;
std::cout << "key = " << tmpAddr.key() << std::endl;
} else {
std::cerr << "Failed to parse JSON string to protobuf message: " << status2.message() << std::endl;
}11.3 代码汇总
#include <iostream>
#include <string>
#include "Person.pb.h"
#include <google/protobuf/util/json_util.h> // MessageToJsonString JsonStringToMessage
int main(int argc, char *argv[])
{
// 序列化
MyPerson::Person p;
p.set_id(1);
p.set_name("小明");
p.set_sex("man");
p.set_age(26);
// 通过mutable_addr函数获得私有成员变量地址后,再通过地址去设置数据
MyAddress::Address *mAddr = p.mutable_addr();
mAddr->set_num(111);
mAddr->set_addr("广东省广州市");
mAddr->set_key(MyAddress::KeyBoard::D);
/// Protobuf转Json
std::string outputJson = "";
using google::protobuf::util::Status;
google::protobuf::util::JsonPrintOptions json_options;
json_options.add_whitespace = true; // 可选,美化输出
Status status1 = google::protobuf::util::MessageToJsonString(p, &outputJson, json_options);
if (status1.ok()) {
std::cout << outputJson << std::endl;
} else {
std::cerr << "Failed to parse protobuf to JSON string message: " << status1.message() << std::endl;
}
/// Json转Protobuf
MyPerson::Person jToP;
std::string jsonStr = R"({
"id": 1,
"name": "Jtom",
"sex": "男",
"age": 26,
"addr": {
"num": 111,
"addr": "广东省深圳市",
"key": "D"
}
})";
using google::protobuf::util::Status;
Status status2 = google::protobuf::util::JsonStringToMessage(jsonStr, &jToP);
if (status2.ok()) {
std::cout << "id = " << jToP.id() << std::endl;
std::cout << "name = " << jToP.name() << std::endl;
std::cout << "age = " << jToP.age() << std::endl;
std::cout << "sex = " << jToP.sex() << std::endl;
// 可通过addr函数结构,再进行下一步的获取值
const MyAddress::Address &tmpAddr = jToP.addr();
std::cout << "num = " << tmpAddr.num() << std::endl;
std::cout << "addr = " << tmpAddr.addr() << std::endl;
std::cout << "key = " << tmpAddr.key() << std::endl;
} else {
std::cerr << "Failed to parse JSON string to protobuf message: " << status2.message() << std::endl;
}
return 0;
}运行截图:
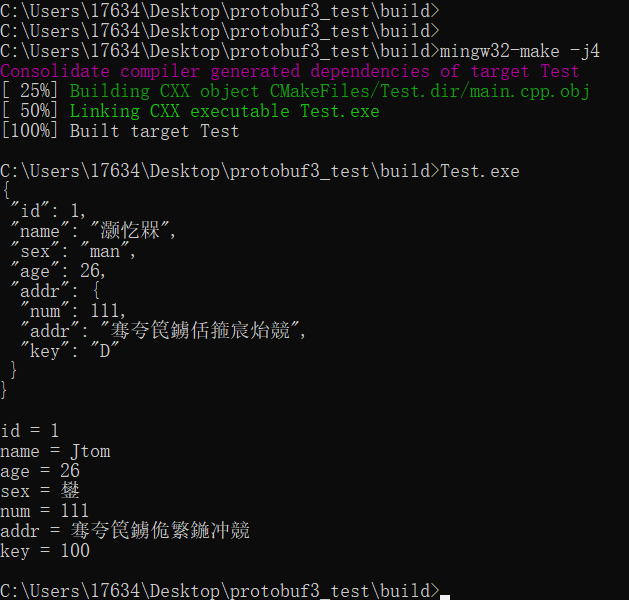
中文乱码问题,在Windows环境会出现,应该是Windows的编码不是utf8导致的,需要转换一下编码应该就可以显示处正常的中文了;
Linux环境是没有中文乱码问题的。
12 总结
到此,Protbuf3在Linux和Windows环境用法已经介绍完毕,相信跟着文章去学习应该可以入门,后续自己在项目中用到了,接触多了,也就会有更深入的了解了。
然后,本篇博客也是参考 Protobuf | 爱编程的大丙 去学习的,内容还是挺不错的,推荐大家也去看看!
最后,官方文档也可以去看看,介绍的挺全面的:Language Guide (proto 3) | Protocol Buffers Documentation


















 3170
3170

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











