



 本文对比了四种不同工具(Filebeat+ingestnode、Logstash、Apache Nifi 和 Streamsets Data Collector)处理Apache日志及复杂JSON数据(Twitter)的性能。通过三次重复测试,评估了各方案的通用性、易开发性、易管理和高性能特性。
本文对比了四种不同工具(Filebeat+ingestnode、Logstash、Apache Nifi 和 Streamsets Data Collector)处理Apache日志及复杂JSON数据(Twitter)的性能。通过三次重复测试,评估了各方案的通用性、易开发性、易管理和高性能特性。
随着ELK技术的普及,Elasticsearch所提供的强大搜索、分析功能给大家处理各种类型的海量数据提供了可能。随之而来的是如何将各种类型的海量数据以一种通用、便捷、高效的方式进入到ES供其使用。传统的logstash具备这方面的能力,但由于其固有的缺陷无法避免,导致其处理性能较低,难于开发调试。
\\我们迫切需要一种通用的数据处理方式,实现从数据源到ES的全流程处理,最终需要达到:
\\- 通用性:接口丰富、有流程控制、数据类型转换、数据加工\\t
- 易开发:便于快速开发调试\\t
- 易管理:容易发现数据问题,性能瓶颈,清晰的流程\\t
- 高性能:对数据处理有较高的吞吐量,较低的资源消耗\
当然我们可以开发特定的Spark Streaming应用来实现数据到ES的流转,但从通用性、易用性方面来看,由于条件所限,这种方法代价较高,周期长,且性能、稳定性较难保证。
\\因此我们选用几种数据通用处理方法进行测试,对比各自的优缺点,发现他们所适应的场景:
\\- filebeat+ingest node\\t
- logstash\\t
- Apache Nifi\\t
- Streamsets Data Collector(SDC)\
- 测试简单Apache日志,普适于一般日志数据解析\
a) 使用同一份Apache access log数据作为测试样本
\\b) 进行简单数据模式匹配,使用统一的COMBINEDAPACHELOG grok pattern对数据进行解析,将结果输入ES
\\- 测试复杂json结构的Twitter数据,对其字段进行转换、计算、筛选等处理,应对复杂、大结构的数据处理\
a) 使用同一份Twitter的json数据作为测试样本
\\b) 由于原始的Twitter数据为非标准json数据,因此在对nifi进行处理之前先将其处理为标准的json array数据,生成数据文件tweet.nifi.json
\\- 每个测试重复三次,记录完成时间及相关运行指标\\t
- 对于ES的性能数据收集采用kibana中自带的monitoring模块监控对应的index\\t
- 对于操作系统的性能数据收集采用metricbeat,然后采用其自带的template在kibana中展现\
3.1. 软硬件环境
\\- 虚拟机VMware® Workstation 10.0.1 build-1379776\\t
- Ubuntu 16.04.1 LTS Linux version 4.4.0-59-generic\\t
- 2 CPU/10G MEM\\t
- ELK 6.2.2 + xpack + 2 nodes\\t
- Apache Nifi 1.5.0\\t
- SDC 3.1.0.0\
3.2. 数据准备
\\1、测试所用Apache日志数据来源于http://www.secrepo.com
\\也可以使用日志生成器来生成数据:
\\https://github.com/kiritbasu/Fake-Apache-Log-Generator
\\2、测试所用Twitter数据来源于Twitter官网,通过Python脚本下载
\\| \\t\t\t 详见: \\\t\t\thttps://github.com/zhan-yl/ELK-inputprocess-test/tree/master/log_tools \\\t\t\t使用方式: \\\t\t\tpython2.7 tweet.py @realDonaldTrump \\\t\t\tpython2.7 tweet.py @BBCWorld \\\t\t\tpython2.7 tweet.py @BBCBreaking \\\t\t\tpython2.7 tweet.py @TIME \\\t\t\tpython2.7 tweet.py @PDChina \\\t\t\tpython2.7 tweet.py @CNN \\\t\t\tpython2.7 tweet.py @CBSNews \\\t\t\tpython2.7 tweet.py @elastic \\\t\t\tpython2.7 tweet.py @golang \\\t\t\tpython2.7 tweet.py @Docker \\\t\t\tpython2.7 tweet.py @streamsets \\\t\t\t生成的日志文件为: \\\t\t\t-rw-rw-r-- 1 zhanyl zhanyl 277508582 4月 2 10:11 tweet.json \\\t\t\t-rw-rw-r-- 1 zhanyl zhanyl 277561344 4月 2 15:56 tweet.nifi.json \\t\t\t |
3.3. 环境配置
\\3.3.1. Apache日志测试
\\3.3.1.1. Filebeat+ingest node
\\- 建立ingest的pipeline\
- Filebeat配置文件\
3.3.1.2. Logstash
\\1、 建立配置文件
\\3.3.1.3. Apache nifi
\\1、 导入template
\\详见:
\\https://github.com/zhan-yl/ELK-inputprocess-test/tree/master/nifi_config
\\2、 说明
\\为了避免OutOfMemoryError和同时打开大量的文件,在流程里面采用了多个split text串联的方式予以解决。
\\同时在流程中未加入对于geo的地址解析。
\\在NIFI中对于Java heap和文件句柄的使用是一个需要谨慎处理的问题。
\\3.3.1.4. SDC
\\1、 导入pipeline
\\详见:
\\https://github.com/zhan-yl/ELK-inputprocess-test/tree/master/sdc_config
\\3.3.2. Twitter日志测试
\\3.3.2.1. Filebaet+ingest node
\\由于对数据的加工处理较为复杂,不对该类型进行测试
\\3.3.2.2. Logstash
\\虽然可以通过filter plugin进行相关类似的操作,但由于操作复杂、调试困难,不对该类型进行测试
\\3.3.2.3. Apache nifi
\\1. 导入template
\\详见:
\\https://github.com/zhan-yl/ELK-inputprocess-test/tree/master/nifi_config
\\2. 说明
\\由于下载的Twitter数据非标准json格式,因此在测试之前使用sed首先将其转换为标准json array数据,便于数据分割。
\\同时在流程中未加入对于geo的地址解析。
\\3.3.2.3. SDC
\\1. 导入pipeline
\\详见:
\\https://github.com/zhan-yl/ELK-inputprocess-test/tree/master/sdc_config
\\\\4.1. Apache日志测试
\\4.1.1. Filebeat+ingest node
\\4.1.1.1. 执行命令
\\| \\t\t\t 初始化文件信息,便于重复执行 \\\t\t\trm /var/lib/filebeat/registry \\\t\t\t启动: \\\t\t\t/usr/share/filebeat/bin/filebeat -c /etc/filebeat/filebeat_secrepo.yml -path.home /usr/share/filebeat -path.config /etc/filebeat -path.data /var/lib/filebeat -path.logs /var/log/filebeat \\t\t\t |
4.1.1.2. 数据监控
\\1、 数据总量
\\897123
\\2、 完成时间
\\| \\t\t\t 开始时间 \\t\t\t | \\t\t\t 结束时间 \\t\t\t | \\t\t\t 耗时(单位:分钟) \\t\t\t | |
| \\t\t\t 1 \\t\t\t | \\t\t\t 10:20 \\t\t\t | \\t\t\t 10:40 \\t\t\t | \\t\t\t 20 \\t\t\t |
| \\t\t\t 2 \\t\t\t | \\t\t\t 10:45 \\t\t\t | \\t\t\t 11:03 \\t\t\t | \\t\t\t 18 \\t\t\t |
| \\t\t\t 3 \\t\t\t | \\t\t\t 11:05 \\t\t\t | \\t\t\t 11:24 \\t\t\t | \\t\t\t 19 \\t\t\t |
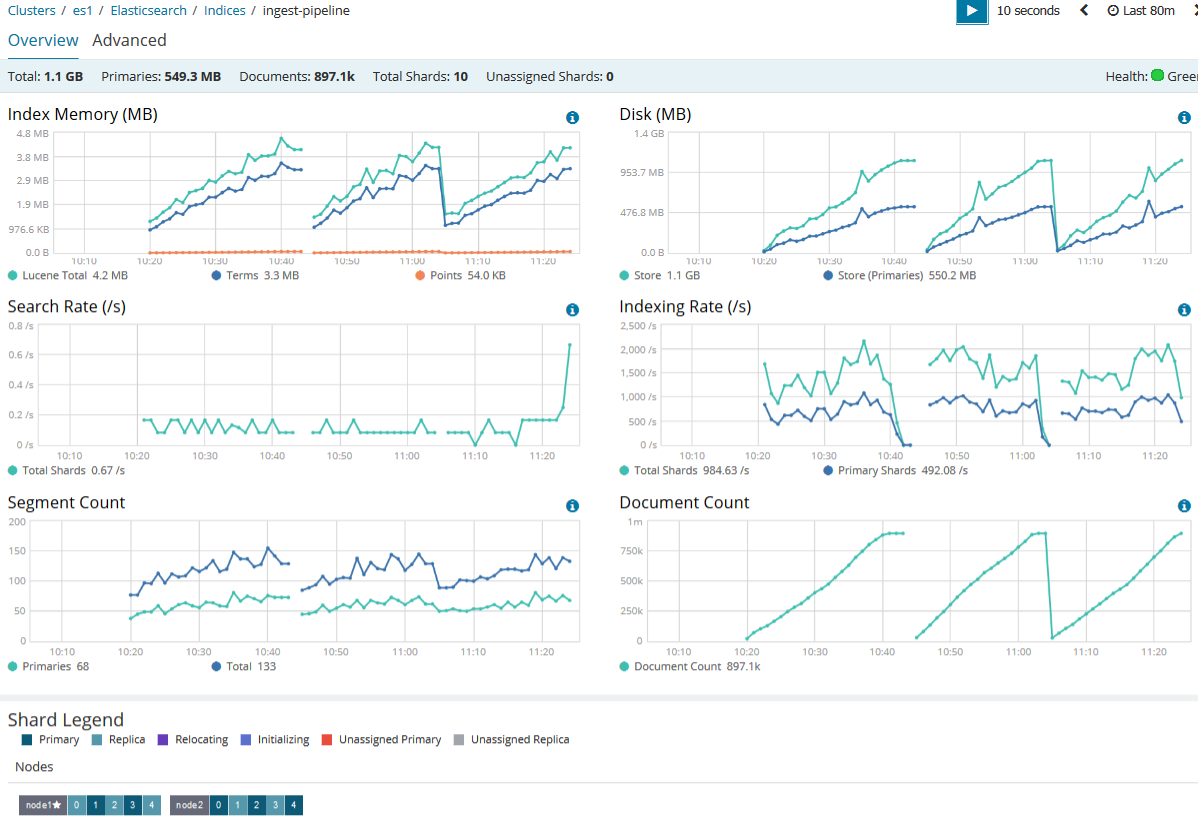
3、 性能图表
\\a) ES性能
\\
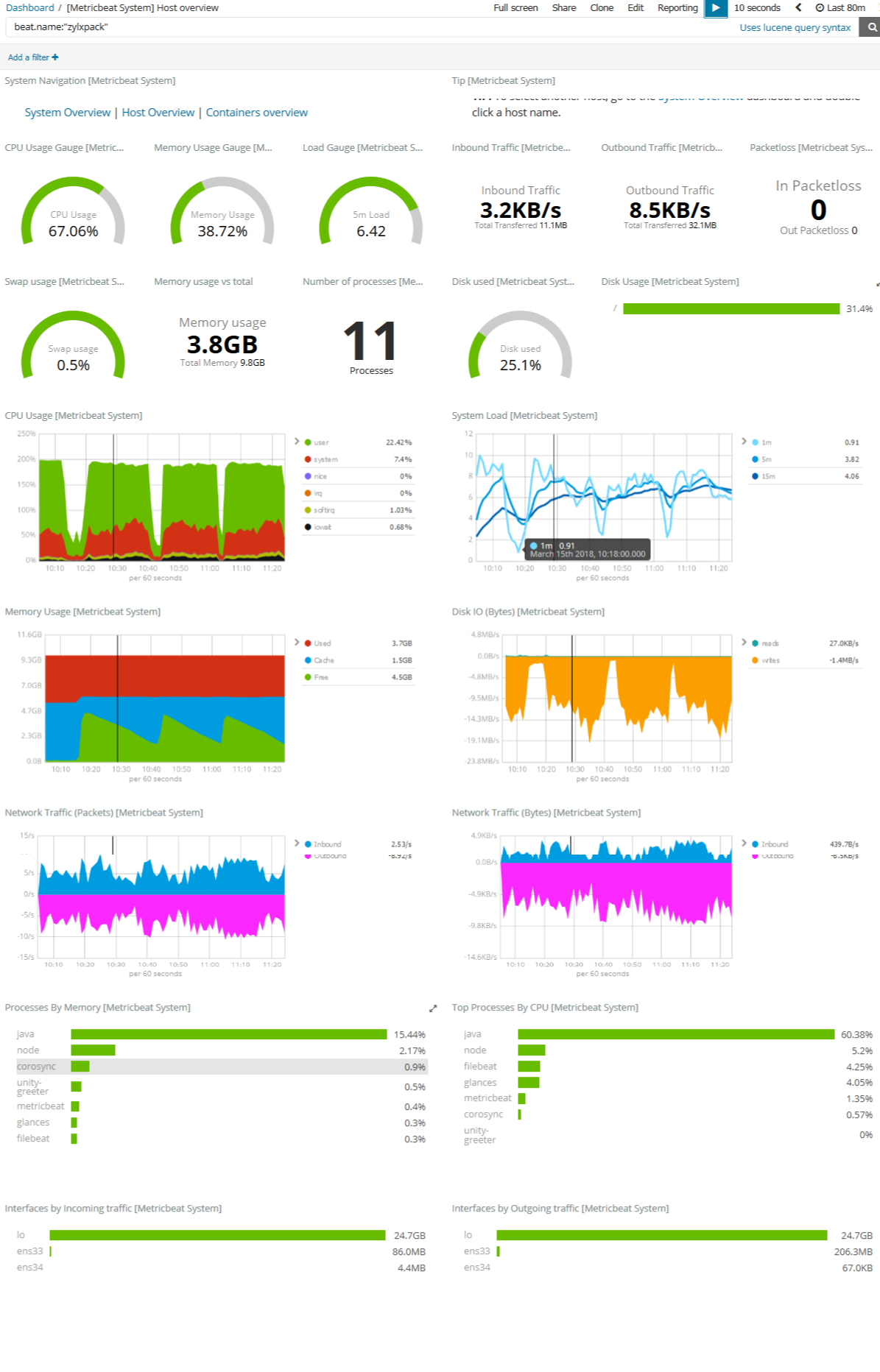
b) 操作系统性能
\\
c) ES数据样本
\\\{\ \"_index\": \"ingest-pipeline\

















 438
438

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









