



 本文探讨了在JAVA中并发访问Synchronized时,JVM如何采用重量级锁及线程状态的变化。深入研究了jstack命令的工作原理,包括如何通过threaddump命令触发线程dump并分析线程状态。
本文探讨了在JAVA中并发访问Synchronized时,JVM如何采用重量级锁及线程状态的变化。深入研究了jstack命令的工作原理,包括如何通过threaddump命令触发线程dump并分析线程状态。
JVM线程dump Bug描述
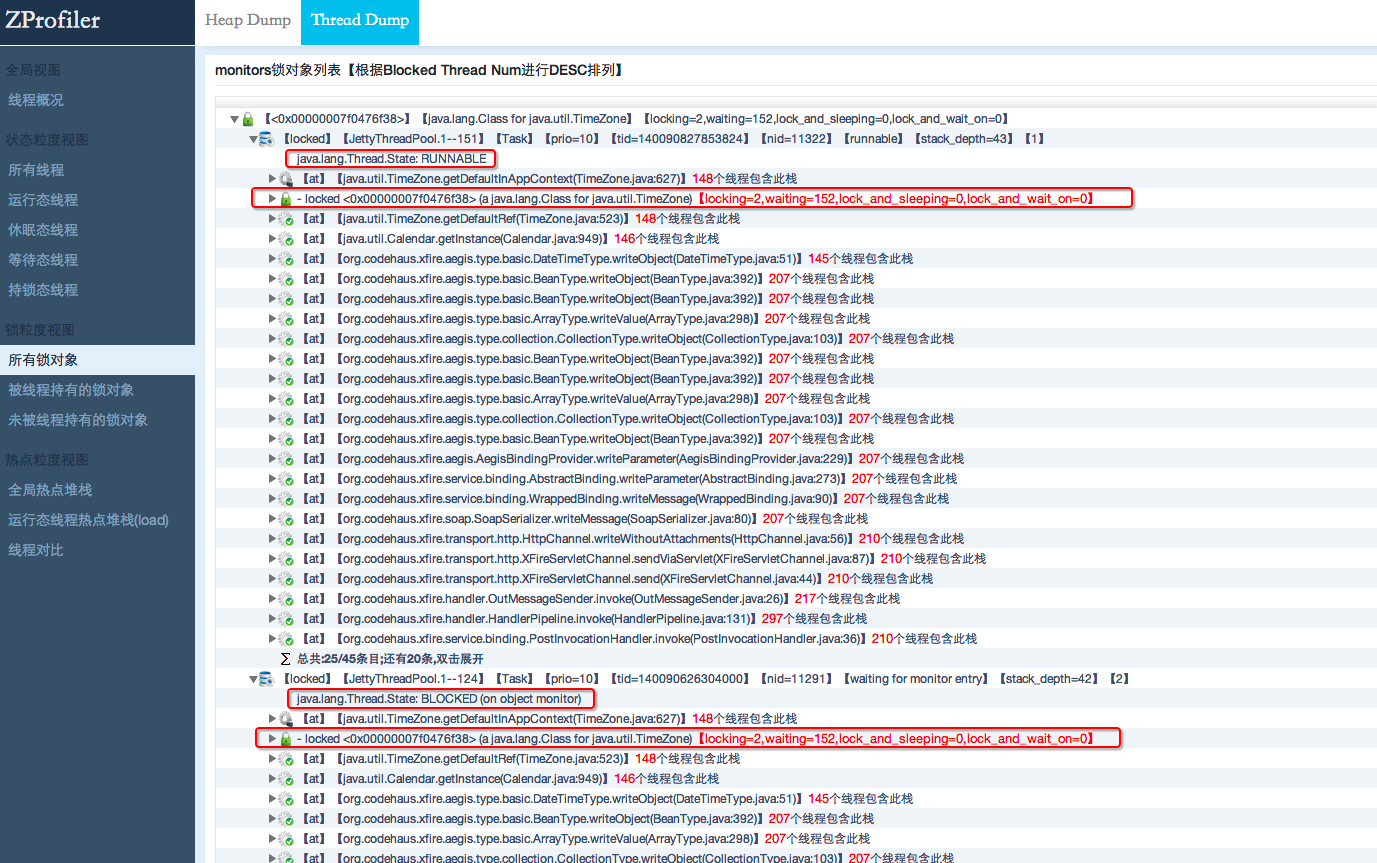
\在JAVA语言中,当同步块(Synchronized)被多个线程并发访问时,JVM中会采用基于互斥实现的重量级锁。JVM最多只允许一个线程持有这把锁,如果其它线程想要获得这把锁就必须处于等待状态,也就是说在同步块被并发访问时,最多只会有一个处于RUNNABLE状态的线程持有某把锁,而另外的线程因为竞争不到这把锁而都处于BLOCKED状态。然而有些时候我们会发现处于BLOCKED状态的线程,它的最上面那一帧在打印其正在等待的锁对象时,居然也会出现-locked的信息,这个信息和持有该锁的线程打印出来的结果是一样的(请看下图),但是对比其他BLOCKED态的线程却并没有都出现这种情况。当我们再次dump线程时又可能出现不一样的结果。测试表明这可能是一个偶发的情况,本文就是针对这种情况对JVM内部的实现做了一个研究以寻找其根源。
\
jstack命令的整个过程
\上面提到了线程dump,那么就不得不提执行线程dump的工具---jstack,这个工具是Java自带的工具,和Java处于同一个目录下,主要是用来dump线程的,或许大家也有使用kill -3的命令来dump线程,但这两者最明显的一个区别是,前者的dump内容是由jstack这个进程来输出的,目标JVM进程将dump内容发给jstack进程(注意这是没有加-m参数的场景,指定-m参数就有点不一样了,它使用的是serviceability agent的api来实现的,底层通过ptrace的方式来获取目标进程的内容,执行过程可能会比正常模式更长点),这意味着可以做文件重定向,将线程dump内容输出到指定文件里;而后者是由目标进程输出的,只会产生在目标进程的标准输出文件里,如果正巧标准输出里本身就有内容的话,看起来会比较乱,比如想通过一些分析工具去分析的话,要是该工具没有做过滤操作,很可能无法分析。因此一般情况我们尽量使用jstack,另外jstack还有很多实用的参数,比如jstack pid \u0026gt;thread_dump.log,该命令会将指定pid的进程的线程dump到当前目录的thread_dump.log文件里。
\jstack是使用Java实现的,它通过给目标JVM进程发送一个threaddump的命令,目标JVM的监听线程(attachListener)会实时监听传过来的命令(其实attachListener线程并不是一启动就创建的,它是lazy创建启动的),当attachListener收到threaddump命令时会调用thread_dump的方法来处理dump操作(方法在attachListener.cpp里)。
\\static jint thread_dump(AttachOperation* op, outputStream* out) {\ bool print_concurrent_locks = false;\ if (op-\u0026gt;arg(0) != NULL \u0026amp;\u0026amp; strcmp(op-\u0026gt;arg(0), \"-l\") == 0) {\ print_concurrent_locks = true;\ }\\ // thread stacks\ VM_PrintThreads op1(out, print_concurrent_locks);\ VMThread::execute(\u0026amp;op1);\\ // JNI global handles\ VM_PrintJNI op2(out);\ VMThread::execute(\u0026amp;op2);\\ // Deadlock detection\ VM_FindDeadlocks op3(out);\ VMThread::execute(\u0026amp;op3);\\ return JNI_OK;\}\\从上面的方法可以看到,jstack命令执行了三个操作:
\- VM_PrintThreads:打印线程栈\
- VM_PrintJNI:打印JNI\
- VM_FindDeadlocks:打印死锁\
三个操作都是交给VMThread线程去执行的,VMThread线程在整个JAVA进程有且只会有一个。可以想象一下VMThread线程的简单执行过程:不断地轮询某个任务列表并在有任务时依次执行任务。任务执行时,它会根据具体的任务决定是否会暂停整个应用,也就是stop the world,这是不是让我们联想到了我们熟悉的GC过程?是的,我们的ygc以及cmsgc的两个暂停应用的阶段(init_mark和remark)都是由这个线程来执行的,并且都要求暂停整个应用。其实上面的三个操作都是要求暂停整个应用的,也就是说jstack触发的线程dump过程也是会暂停应用的,只是这个过程一般很快就结束,不会有明显的感觉。另外内存dump的jmap命令,也是会暂停整个应用的,如果使用了-F的参数,其底层也是使用serviceability agent的api来dump的,但是dump内存的速度会明显慢很多。
\VMThread执行任务的过程
\VMThread执行的任务称为vm_opration,在JVM中存在两种vm_opration,一种是需要在安全点内执行的(所谓安全点,就是系统处于一个安全的状态,除了VMThread这个线程可以正常运行之外,其他的线程都必须暂停执行,在这种情况下就可以放心执行当前的一系列vm_opration了),另外一种是不需要在安全点内执行的。而这次我们讨论的线程dump是需要在安全点内执行的。
\以下是VMThread轮询的逻辑:
\\void VMThread::loop() {\ assert(_cur_vm_operation == NULL, \"no current one should be executing\");\\ while(true) {\ ...\ //已经获取了一个vm_operation\ if (_cur_vm_operation-\u0026gt;evaluate_at_safepoint()) {\ //如果该vm_operation需要在安全点内执行\ _vm_queue-\u0026gt;set_drain_list(safepoint_ops); \ SafepointSynchronize::begin();//进入安全点\ evaluate_operation(_cur_vm_operation);\ do {\ _cur_vm_operation = safepoint_ops;\ if (_cur_vm_operation != NULL) {\ do {\ VM_Operation* next = _cur_vm_operation-\u0026gt;next();\ _vm_queue-\u0026gt;set_drain_list(next);\ evaluate_operation(_cur_vm_operation);\ _cur_vm_operation = next;\ if (PrintSafepointStatistics) {\ SafepointSynchronize::inc_vmop_coalesced_count();\ }\ } while (_cur_vm_operation != NULL);\ }\ if (_vm_queue-\u0026gt;peek_at_safepoint_priority()) {\ MutexLockerEx mu_queue(VMOperationQueue_lock,\ Mutex::_no_safepoint_check_flag);\ safepoint_ops = _vm_queue-\u0026gt;drain_at_safepoint_priority();\ } else {\ safepoint_ops = NULL;\ }\ } while(safepoint_ops != NULL);\ _vm_queue-\u0026gt;set_drain_list(NULL);\ SafepointSynchronize::end();//退出安全点\ } else { // not a safepoint operation\ if (TraceLongCompiles) {\ elapsedTimer t;\ t.start();\ evaluate_operation(_cur_vm_operation);\ t.stop();\ double secs = t.seconds();\ if (secs * 1e3 \u0026gt; LongCompileThreshold) {\ tty-\u0026gt;print_cr(\"vm %s: %3.7f secs]\
















 1233
1233

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









