



 本文以Java Web项目为例,介绍buildr这一自动化构建工具如何简化软件开发流程,包括依赖管理、测试自动化、环境配置等,提高开发效率。
本文以Java Web项目为例,介绍buildr这一自动化构建工具如何简化软件开发流程,包括依赖管理、测试自动化、环境配置等,提高开发效率。
自动化脚本之于软件开发,犹如地基之于建筑。
\在软件开发过程中,缺乏一个好的自动化脚本,与之相伴的往往是日常的开发工作举步维艰:
\- 只有少数人能够把整个软件构建起来,因为构建所需的那些东西不太容易弄全。\
- 为了能在自己机器上写代码,开发人员要花大量时间把工程在IDE上配出来。\
- 提交代码之前,开发人员总是忘了在验证。\
在本文中, 我们将以一个Java的web项目为例,展示一个好的“地基”应具备的一些基本素质。在这里,用做自动化的工具是buildr。
\buildr是一种构建工具,它专为基于Java的应用而设计,也包括了对Scala、Groovy等JVM语言的支持。相比于ant和maven这些Java世界的“老人”,buildr算是小字辈,也正是因为年轻,它有着“老人”们不具备的优势:
\- 相比于ant,遵循着Convention over Configuration原则的buildr,让“编译、测试、打包”之类简单的事做起来很容易。\
- 相比于maven,我们无需理解强大且复杂的模型,而采用Ruby/Rake作为脚本的基础,也让我们可以定制属于自己的脚本。\
简而言之,它满足了我们选择工具的基本原则:“易者易为,难者可为”。
\请注意:下面所有的内容并不只是buildr的独家专利,而是每个构建工程都应该具备的,差异只在于,选择不同的工具,实现的难度略有差异而已。
\易者易为
\让我们从一个简单的buildfile——buildr的脚本——起步:
\\GUAVA = 'com.google.guava:guava:jar:r09'\define 'killer' do\ project.version = '0.0.1'\ define 'domain' do\ compile.with GUAVA\ package :jar\ end\ define 'web' do\ DOMAIN = project('killer:domain').packages\ compile.with DOMAIN\ package(:war).with(:libs=\u0026gt;DOMAIN)\ end\end \
我们先来看看从这个简单的buildfile中,我们可以得到什么。
\分模块项目
\这个项目里有两个子项目:domain和web。从架构的角度来看,一个项目从一开始就划分出这样的模块是有好处的:
\- 给未来扩展留下接口,比如要提供一个Web Service,可以从domain部分开始即可。\
- 给开发人员一个好的规划,有助于引导他们思考程序的模块化,降低代码的耦合度。\
使用buildr划分模块是非常简单的,只要在buildfile里声明模块,项目的根目录下同名的子目录就是对应的模块。
\文件布局
\虽然在buildfile没有直接体现出来,但这里有个缺省的文件布局。一个统一的规则省去了我们从头规划的苦恼。遵循缺省的布局规则,buildr自己就会找到相应的文件,进行处理。
\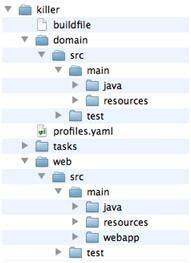
这个布局规则实际上就是Maven的布局规则,如图所示,两个子项目都拥有自己的目录,其结构基本一致:
\- src/main/java,源代码文件目录\
- src/main/resources,资源文件目录\
- src/test/java,测试代码目录\
- src/main/webapp,web相关文件目录\
此外,这里还有稍后会提及的:
\- profiles.yaml,环境相关的配置\
- tasks,自定义任务的目录\
这就是所谓的Convention over Configuration。当然,buildr是支持自定义文件布局的,详情请参见文档。
\基本命令
\有了这个基本的buildfile,我们就可以开展日常的工作了。buildr自身支持很多命令,比如:
\- buildr compile,编译项目\
- buildr package,项目打包\
- buildr test,运行测试\
想要了解更多的命令,可以运行下面的命令:
\\buildr -T\
测试
\在这个不测试都不好意思自称程序员的年代,测试,尤其实现级别的测试,诸如单元测试、集成测试,已经成了程序员的常规武器。
\诚如上面所见,src/test/java就是我们的测试文件存放的目录。对于Java项目,JUnit是缺省的配置,只要在这个目录下的Java类继承自junit.framework.TestCase(JUnit 3),或是,在类上标记了org.junit.runner.RunWith,抑或在方法上标记了org.junit.Test(JUnit 4)。buildr就会找到它们,并帮我们料理好编译运行等事宜。约定的力量让我们无需操心这一切。
\依赖管理
\依赖管理一直是一项令人头疼的问题,也是让许多开发人员搭建纠结于开发环境搭建的一个重要因素。
\各种语言的社区分别给出了自己的依赖管理解决方案,对于Java社区而言,一种比较成熟的解决方案来自于Maven。它按照一定规则建立起一个庞大的中央仓库,成熟的Java库都会在其中有一席之地。
\于是,很多新兴的构建工具都会建立在这个仓库的基础之上,buildr也不例外。在前面的例子里面,domain依赖了Guava这个库。当我们开始构建应用时,buildr会自动从中央仓库下载我们缺失的依赖。
\不仅仅是依赖,我们还可以拿到对应的文档和源码:
\- buildr artifacts,下载依赖\
- buildr artifacts:javadoc,下载javadoc\
- buildr artifacts:sources,下载源码\
如果不知道如何在buildfile里编写依赖,那mvnrepository.com是个不错的去处,那里针对不同的构建工具都给出了相应的依赖写法。
\与IDE集成
\除非这个工程是用IDE创建出来的,否则把工程集成到一个IDE里通常要花费很大的力气。所幸,buildr替我们把这些工作做好了。我们只要键入一个命令即可,比如与IntelliJ IDEA集成,运行下面的命令:
\\buildr idea\
它会生成一个IDEA的工程文件,我们要做的只是用IDEA打开它。同样的,还有一个为Eclipse准备的命令:
\\buildr eclipse\
不知道你是否有这样的经验,初到一个项目组,开始为一个项目贡献代码之前,先需要花几天时间,在不同的人的协助之下把环境搭出来,为的只是在自己的机器上能够把应用构建出来。
\而现在,有了这样的自动化脚本,一个项目组新人的行为模式就变成了:
\- 初入一个项目组,他从源码管理系统上得到检出代码库。\
- 调用buildr artifacts,其所依赖的文件就会下载到本机。\
- 调用buildr idea:generate(或是buildr eclipse),生成IDE工程。\
- 打开工程,开始干活。\
迄今为止,我们看到的只是一个基本的buildfile,这些命令也是buildr内置的一些基本能力,也就是所谓的“易者易为”。
\难者可为
\接下来,我们将超越基础,做一些“难者可为”的东西。
\不同的环境
\在实际的开发中,我们经常会遇到不同的环境,比如,在开发环境下,数据库和应用服务器是在同一台机器上,而在生产环境下,二者会部署到机器上。这里所列举的配置功能,只是最简单的例子,而实际情况下,不同的环境下,会有各种差异,甚至需要执行不同的代码。
\一种解决方案是为数不少的“直觉式”设计采用的方案,在代码里根据条件进行判断,可想而知,无处不在的if..else很快就会把代码变成一团浆糊,更糟糕的是,这些信息散落在各处。
\另一种方案是在自动化脚本中支持,buildr让这个工作变得很简单。
\配置信息
\使用buildr,配置信息可以放到一个名为profile.yaml的文件里,下面是一个例子:
\development:\ db:\ url: jdbc:mysql://localhost/killer_development\ driver: com.mysql.jdbc.Driver\ username: root\ password:\ jar: mysql:mysql-connector-java:jar:5.1.14\production:\ db:\ url: jdbc:mysql://deployment.env/killer_production\ driver: com.mysql.jdbc.Driver\ username: root\ password: ki1152\ jar: mysql:mysql-connector-java:jar:5.1.14\
我们看到,针对不同的环境,有不同的数据库配置,在buildfile里可以这样引用这些配置:
\\db_settings = Buildr.settings.profile['db']\
随后,我们就可以使用这个配置,比如生成一个配置文件:
\\task :config do\ CONFIG_PROPERTIES = \u0026lt;\u0026lt;EOF\ jdbc.driverClassName= #{db_settings['driver']}\ jdbc.url=#{db_settings['url']}\ jdbc.username=#{db_settings['username']}\ jdbc.password=#{db_settings['password']}\ EOF\ File.open('config.properties'), \"w\") do |f|\ f.write config\ end\end \
有了这样的基础,只要我们指定不同的环境就会产生不同的配置。
\系统组件
\在buildr里,有一个叫做ENV['BUILDR_ENV']的变量,这是buildr内置的一个变量,通过它,我们可以获得当前环境的名字,在这个例子里,它可以是development或是production。
\有了这个变量,我们可以进行更加深度的配置,比如,在测试环境下,我们可以采用一些假的实现,让整个系统运行的更快。
\下面是一个例子,有一个搜索组件的配置文件,在生产环境下,它会采用真实的搜索引擎实现,而在开发环境时,它只是一个简单内存实现。我们把不同环境的实现放到不同的配置文件里。
\\\u0026lt;beans xmlns=\"http://www.springframework.org/schema/beans\"\xmlns:xsi=\"http://www.w3.org/2001/XMLSchema-instance\"\xsi:schemaLocation=\"http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd\"\u0026gt;\ \u0026lt;bean id=\"searcher\" class=\"com.killer.SuperSearcher\"/\u0026gt;\\u0026lt;/beans\u0026gt;\
(searcher.production.xml)
\\\u0026lt;beans xmlns=\"http://www.springframework.org/schema/beans\"\xmlns:xsi=\"http://www.w3.org/2001/XMLSchema-instance\"\xsi:schemaLocation=\"http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd\"\u0026gt;\ \u0026lt;bean id=\"searcher\" class=\"com.killer.InMemorySearcher\"/\u0026gt;\\u0026lt;/beans\u0026gt;\
(searcher.development.xml)
\要使用这个组件只要引用searcher.xml,把searcher拿过来用就好了:
\\\u0026lt;import resource=\"searcher-context.xml\"/\u0026gt;\ ...\\u0026lt;property name=\"searcher\" ref=\"searcher\"/\u0026gt;\
接下来,用一个task就可以处理这些差异:
\\task :searcher do\ cp \"searcher.#{ENV['BUILDR_ENV']}.xml\

















 3408
3408

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









