



 本文是中国计算机学会学术报告中清华大学朱军教授关于深度生成模型的讲解,涵盖生成对抗网络(GAN)、生成模型的基本概念、深度生成模型(Deep Generative Models)及其在半监督学习中的应用。朱军教授探讨了模型的表示学习能力,并介绍了其团队在条件生成、半监督学习方面的工作,如Triple Generative Adversarial Nets(Triple GAN)。
本文是中国计算机学会学术报告中清华大学朱军教授关于深度生成模型的讲解,涵盖生成对抗网络(GAN)、生成模型的基本概念、深度生成模型(Deep Generative Models)及其在半监督学习中的应用。朱军教授探讨了模型的表示学习能力,并介绍了其团队在条件生成、半监督学习方面的工作,如Triple Generative Adversarial Nets(Triple GAN)。

前言
生成对抗网络(GAN)是深度生成模型(DeepGenerative Model)中的一种方式。下面介绍一下相关的算法。现在很多场景下的深度学习,我们在机器学习里面跟准确的说法是,判别式的机器学习,或者判别式的深度学习。目标是想学一个从输入到输出的一个映射函数。通常情况下可以把F定义成一个可以求导的光滑的函数,所以可以用反向传播(Gradientback-propagation)的算法来进行训练它。现在大家用的很多的网络基本上都是符合,图中是最早的卷积网络的原形。

今天主要围绕产生式模型(Generative Modeling )进行介绍。

产生式模型(Generative Modeling )的不同之处是:
数据服从某种分布,但是真实世界里面的分布我们是不知道的,真实分布在真实世界里面分布的非常复杂。我们能拿到一些样本,也是一些数据,比如看到的图片,看到文本,或者看到一些社交网络等等的结构,这都是我们看到的数据。我们希望去学一个模型,这个模型也用一个分布来描述。我们叫?model,我们希望 ?model的分布和数据的分布是比较吻合的,或者说在某种意义上比较相似。如果这个前提达成的话。希望从模型里面生成很多新的数据,可以去泛化,可以去举一反三,图片中是一个简单的例子,手写体字符里面可以训练出一个模型,可以生成出一些在新的在训练集里面没有看到的样本。这是生成模型一个主要目标。
生成模型在机器学习中有很多的作用,首先是可以做无监督的模型。比如现在判决式神经网络需要有大量的标注数据去训练。比如ImageNet。广义上来说有很多的没有标准的原始数据。我们有更多的没有标注的原始数据。对于这种数据可以用生成模型去学习它的一个表示,就是深度的生成模型。他可以发挥应用的场景,具体我们可以做无监督的学习,你可以做简单的密度估计、生成新的样本、可以做一些聚类、可以做一些特征提取,甚至做降维等这都是无监督的一些任务。
有监督和无监督之间有一种混合的叫半监督的学习,半监督的学习就是我们希望用大量的五无标注的数据帮助我们做有监督的学习任务,能够提升分类的效果。这些是学习任务,还有一些应用场景,比武我们可以做所谓的条件生成,你的输入是一种模态的数据,然后生成另外一种模态的数据,比如合成一些声音,输入文本生成语音。例如做翻译本身也是一个条件生成的任务,你输入一直语言,然后生成另外一种语言,或者image captuer 现在我输入的是图片,生成的是文本。还有很多很多的任务可以定义成条件生成。

内容纲要:
Basics of Generative Models
Deep Generative Models
Semi-supervised Learning
1.Basics of Generative Models
生成模型在人工智能、数据挖掘的每个任务里面,基本上都能看得到,这是一个非常简单的例子,大家要做文本的分析,我们最简单的统计模型叫 unigram language model ,文本会描述成bag-of-words的向量。我们会用一个简单的概率模型刻画单词出现的概率。这是一个非常的简单的language model .



我们会有一个topic去描述每个单词在这个语料库里出现的概率,这个概率本身是我们自己不知道的,我们需要通过学习去估计,这里用的工具也是最基本的,对于这种常用模型是比较容易去计算的,对于like model我们有解析,对于这种一般的高速数据我们也解析,这个问题相对简单,也是最常见的生成模型。更进一步,我们希望考虑更复杂的模型,我们可以对这种复杂的数据去挖掘背后的隐藏结构。如图的例子,我把数据放到二维空间里面,这每一个点对应一个文本,大家从数据里面很清楚的就能看到这个数据分布不是一致的。我们看到数据背后有些结构,有些数据在一个group,另有些数据在另一个group,分这个结构。如果去看这个文本的话,我们会发现有些文本是关于信息检索的。这背后就隐藏了一些机构,这就是我们后面要引入的Deep Generative Models 的最基本的思想,我们能否做一个有隐变量的模型尽量挖掘数据隐含的这种结构。

假设我告诉你这两类文章都是从哪里来的,告诉你有两类,不过两类都是隐含的,告诉你两类从哪里来,这是可以用最简单的Generative models 去描述它,我们每一个都可以用一个language去刻画它。但是这两个类别的划分是未知的,所以我们会用一个隐含变量的概率模型与刻画。

比如我们用一个Z变量去指示(indicate)到底属于哪一个类别。构造这样一个简单的概率模型,因为我们的Z是没有观察到的,我们用一个先验概率去表述。假定Z值已经取定的话我们的X可以用一个Generative models 去描述。这样放在一起的话就是一个联合概率模型。这是一个常见的模型。

现在包括Generative models 里面都用这种思想去建模数据。这里面因为Z是没有观察到的。我们看到的只有X,这里很重要的任务就是做推断(infer)去发现这个隐含的Z,因为它揭示了这个数据到底属于哪个类别的变量。这个对我们数据做理解是非常重要的。这种情况下我们通常用的贝叶斯公式,最常用的推理的framework。假设模型给你,你可以做后验的推断,但这里面还有问题。

这个模型从哪里来,我们也需要从数据里面去学,比如最常用的我们有函数的话,我们可以用最大估计,对于有隐变量这种,我们通常用EM algorithm ,这也是一个非常经典的算法,做迭代是两步,第一步去猜数据属于哪一类,第二步是优化。假设已经知道的话,就可以不断的去优化这个模型,这是EM algorithm 的一个迭代算法。以上是一些基本概念,我们为什么要在实际的场景下考虑隐变量,我们是怎么考虑的,用什么工具去做的。
为了让模型理解表示在给定训练数据中的大千世界,训练具有隐藏单元的生成 模型是一种有力方法。通过学习模型 pmodel(x) 和表示 pmodel(h|x),生成模型可以 解答 x 输入变量之间关系的许多推断问题。并且可以在层次的不同层,对h求期望,来提供表示x的许多不同方式,生成模型为AI系统提供它们需要理解的,有所不同的直观的框架。让它们有能力在面对不确定性的情况下推理。——《深度学习》
2.Deep Generative Models
在Deep Generative Models 里面,可以把网络的层次加深,让模型变得更复杂、更灵活。Deep Generative Models 有两种方式去构建,一种叫做传统的方法,一种是非传统的方法。

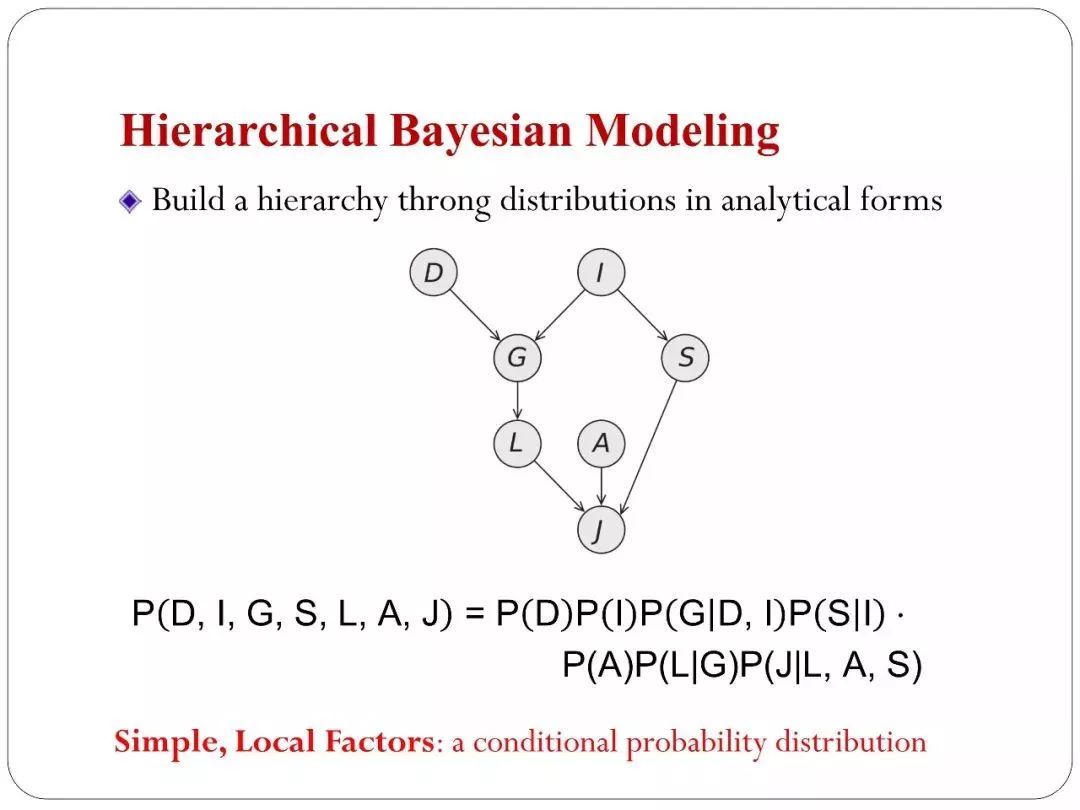
传统的方法主要是从贝叶斯学习而来,贝叶斯有一种技术是长期以来都在用的,叫层次的贝叶斯,可以在一层层叠加先验,它本身就是一个深度的模型,模型可以达到无穷深。非传统的方法是用了深度神经网络来帮助我们生成模型。下图是一个传统的方法。
用层次贝叶斯的思路,我有一堆变量,这一堆变量可以定义成多种层次的依赖关系,这些变量之间会用一个联合概率来刻画。用贝叶斯网络理论可以写一些简单的分布层。这是贝叶斯网络里面告诉你的。这种描述概率分布和它语义是完全相符的。图中每一个factor分解之后每一个乘积项都像是一个非常简单的概率分布,如果是离散的话,我们用多项式、连续的可能用高斯等你等这些常见的分布区描述。
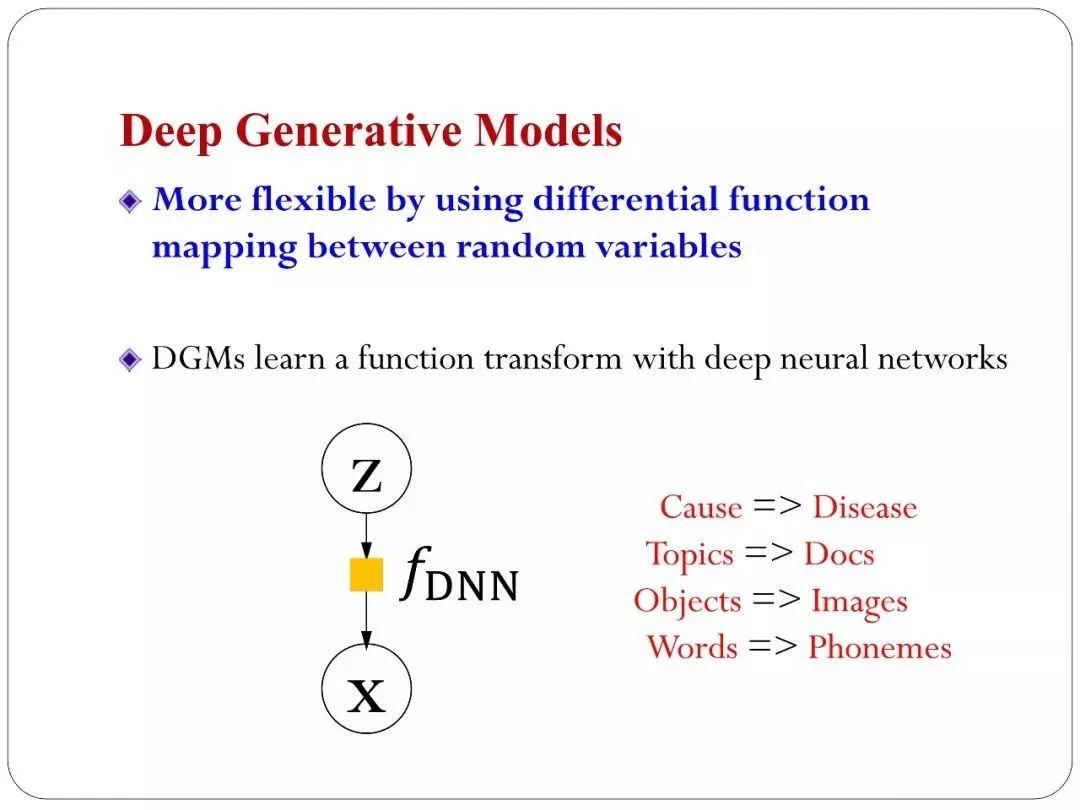
大家从14年开始,更熟悉的是深度神经网络,卷及网络里面大家从2011年,2012年有很多应用上的性能的显著提升。在深度生成模型里面显著提升实在14年以后,里程碑意义的事情是,大家找到更好的昂视去学这个网络。首先看一下这个网络灵活在什么地方。用了学科里面最基本的trick。统计里面有一个简单的分布——均匀分布,零一之间均匀分布的变量。如果有一个函数对这个变量做一个变换。会得到另一个随机变量。这个随机变量他的概率分布和函数变化是有关系的,如果用简单的函数变化会得到相对简单的Y变量。如果用复杂的话,它的分布就变得更复杂。一般情况下,如果F解析形式告诉你他可以得到解析解,这是我们在概率统计里面学到的。如果大家对贝叶斯概率熟悉,这种trick——假设对分布做一个采样,我们都在用这种trick。比如要从高斯采样,从均匀的变量开始,通过函数变化得到想要目标的变量。这是传统的经典方法。

那现在的方法是什么呢,把函数变化变成深度神经网络,这个深度神经网络是可以学习的。不再是一个解析的形式。我们可能写不出来它的解析形式,但是可以通过数据去学习。学到符合数据分布的最有的函数(网络)出来。这就是深度神经网络和深度模型的特点。
再看几个例子:
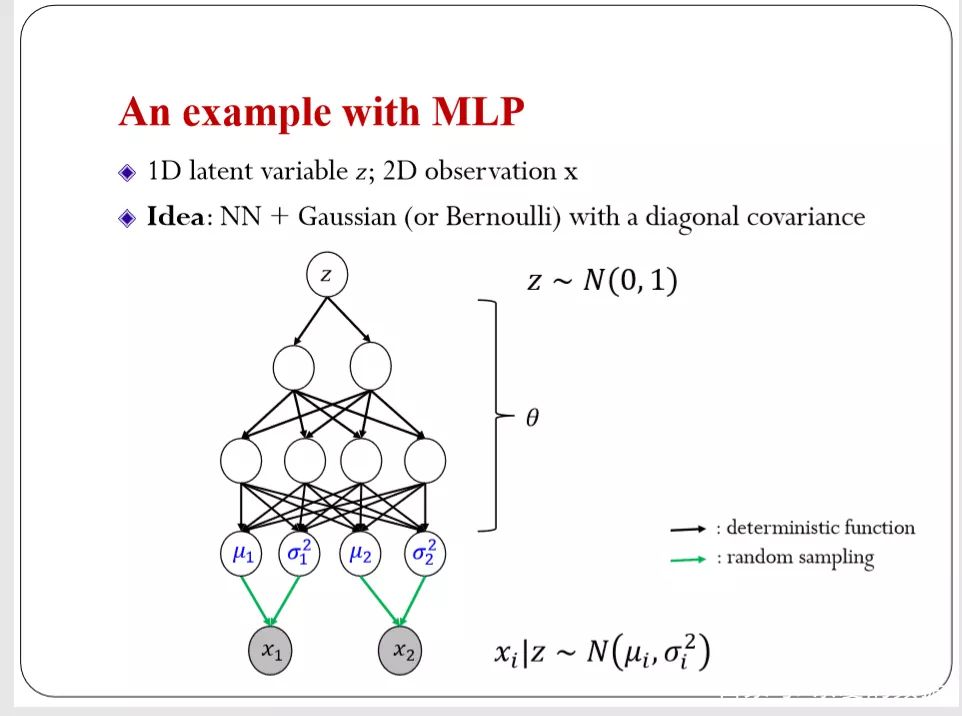
用一个全连接的MLP网络来做变换,最上层是一个最简单的标准高斯的随机变量,采样出来经过两层的一个全连接网络。输出后有四个。这个和一般的神经网络不太一样。我这里面的输出值是作为另外一个分布的参数来定义的。前面的四个输出单元(output unit)定义成两维高斯的均值和方差。这和我们一般的分类网络不一样。所以有了高斯之后,可以描述数据的分布。这种模型非常灵活。因为Z是连续的,在连续的空间里随便采样。假设这个网络是固定的。你用不同的Z得到的高斯是不一样的。所以每一个Z的具体取值就等到一个对应的高斯。基本上是把无穷多个高斯混合在一起。从分布的表达能力上来说,是很强大的网络。但是这则模型也有一个局限。你必须要设定生成数据的噪声模型,这里用的是高斯,如果离散的话,可以运用伯努利分布。
在机器学习里还有另外一种非常灵活的方法:
它的灵活在于去掉产生数据的噪声模型的假设。我不再假设高斯或者其他的,只有一个随机过程,就是给初始条件。可能会有约束条件,比如边界的约束条件参数,有些条件下是可以参数化的,给一个输入的初始条件,就给你一个样本。比如给一个初始的高斯白噪声值,经过这个网路之后给你生成一个图片。

神奇之处在于,这个网络本质上没有假设任何的数据分布的形式。通过网络做的变化。把标准高斯的变量可以变成复杂分布的变量。能够直接描述数据。这个在统计里面实际上研究了很多年——Implicit Models 。对比GAN,也是一个深度的Implicit Models,所谓的deep就是这里面的function的变化过程,用一个深度的神经网络来刻画。我这里面可以变成一个可以学习的深度神经网络。非常灵活。
遵循这种思路,我们有一个非常简单的白噪声,也是Z变量。通过一个可以学习的深度神经网络变换。最后可以生成我们看到的漂亮的图片效果。这是一些内容。包括像GAN或者其他网络里面大家能够找到的很多例子。现在也有很多的应用。
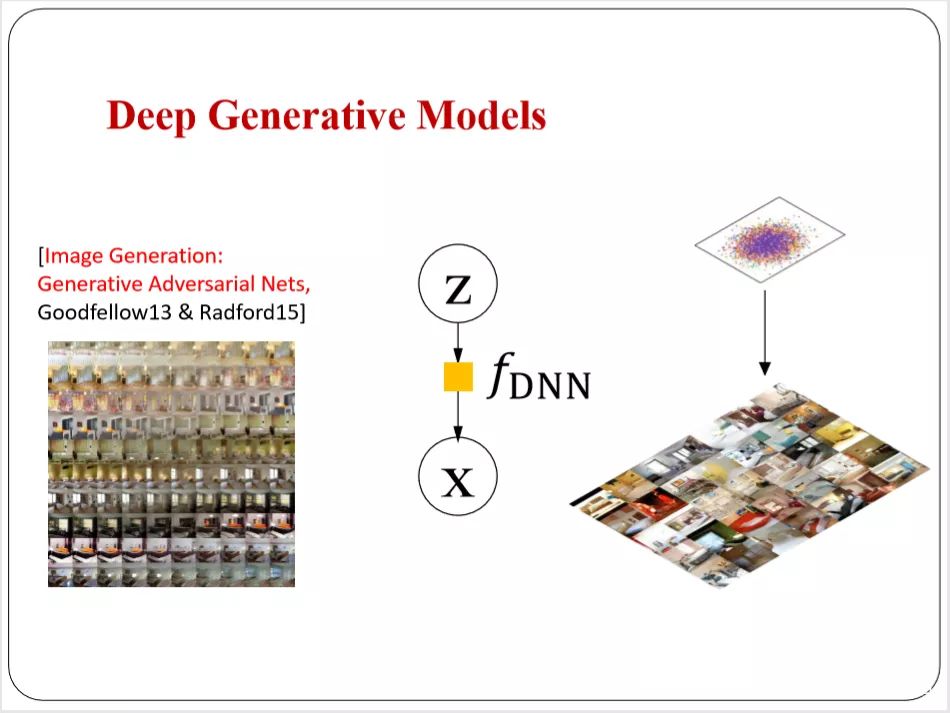
如果能够学习的话,可以做辅助学习或者其他的任务。
网络是非常灵活的。如果有一个很强大的神经网络,可以把白噪声掰扯非常漂亮的图片。听起来很强大,问题是我们怎么找到这个网络。难度在于怎么去找到这个网络,怎么去找到最优的神经网络。你要在一个非常灵活的、非常大的空间里面来进行搜索。搜索到一个好的神经网络。而且要有一个准字告诉你哪个网络更好,这里面的准则是,前面我们讲的任务,我们有的数据有自己的分布,希望找到模型是一个红色的线。它的密度函数的曲线是红色的。
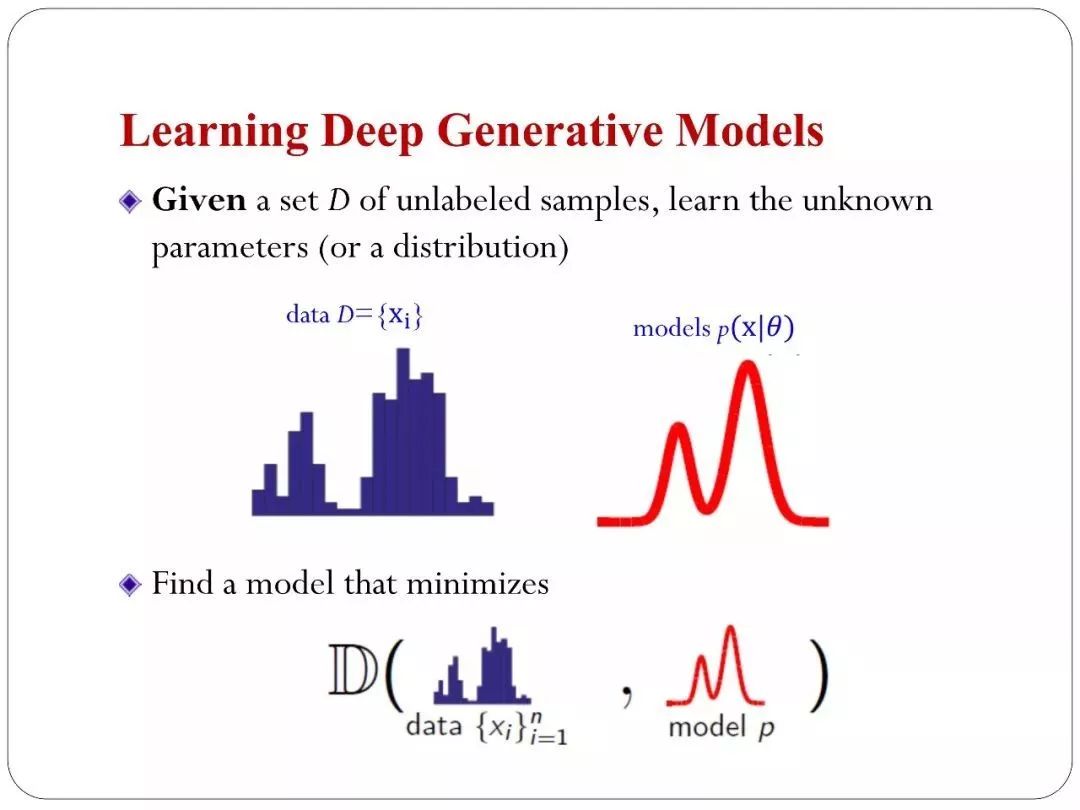
我们希望这两个分布是比较近的。我们学习的目的是希望模型可以调参数。模型的分布和数据分布接近。就用某种距离度量。我的距离的度量是千差万别的选择。假如我们有数据生成的模型的话,可以用最经典的最大似然估计(MLE),这里面必须有显示的似然函数,但有些模型不符合这种条件,比如隐式的模型。隐式的模型怎么学?答案这里就引出了GAN,GAN本质上以一个Minimaxobjective 优化的问题。但是GAN通常的解释两个玩家对抗的游戏。除了GAN统计里面有很多其他的方法,例如,Moment-matching:,在统计的历史上比极大似然估计方法(Maximum Likelihood Estimate,MLE)还要早。早期,大家做一个高斯估计实际上用了Moment-matching,现在我们也可以用Moment-matching去估计Implicit 概率模型。

比如我有一个数据的训练集,模型里面可以采样出来一个训练集。现在做一个检验。这两个数据集是不是符合同样的分布。如果符合同样的分布,就说明我的数据分布和模型的分布是一致的。如果不符合两个就是有差别的。我们可以把差别来做一种距离的度量。来指导我们优化网络找到一个更好的。这里面叫MMD。可以保证到最后得到的是我们想要的一致的解。这是深度生成模型里面一些基本的任务和相关的问题。这里面大概列了我们团队从2014年开始做的:

关键点一:根据算法,怎么样构造一个好的学习准则来帮我们训练网络。
关键点二:怎么用深度神经网络模型帮助我们更好的去训练。
Moment-Matching DGMs
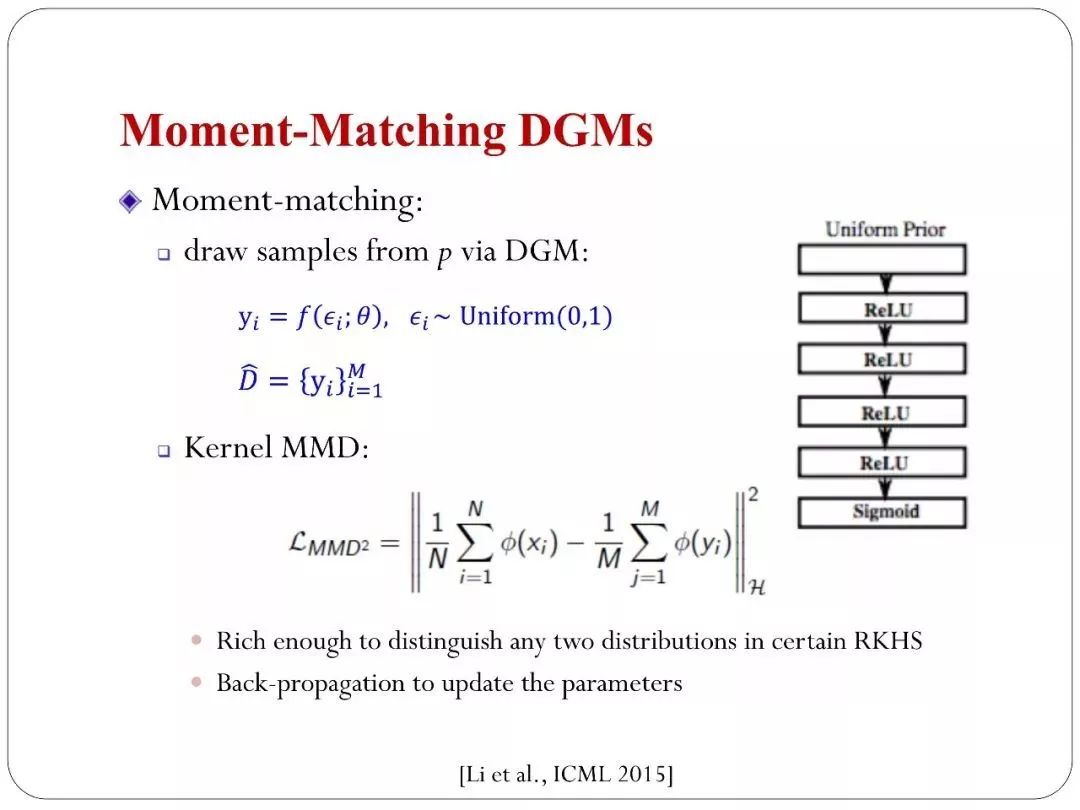
我们在学习implicit模型的时候GAN不是唯一的方法。我们还有Moment-matching这一经典方法。一个简单的变量通过神经网络。可以用relu这种卷积网络或者用其他网络。经过变化之后可以达到你生成数据的目的。有了这个网络,假如参数给你了。你可以采样先验分布。当天有一组参数,实际上可以通过采样先验分布得到无穷的训练样本。从模型里面生成无穷多的样本。这个样本和训练集做比较。我们可以定一个Kernel MMD的准则,这个是在泛函空间(希尔伯特)里面得到定义。
如果你Kernel 表达能力很强,你可以保证这个距离等于零的话,这两个分布是一样的。你的模型分布和数据分布是一样的。这是一个基本条件。在这种条件下,就可以不断优化,找到更优的深度神经网络、这里面因为是生成的模型,你也可以用来计算梯度。
原来的技术都可以扩展到这个里面。这是团队2015年的一些工作。
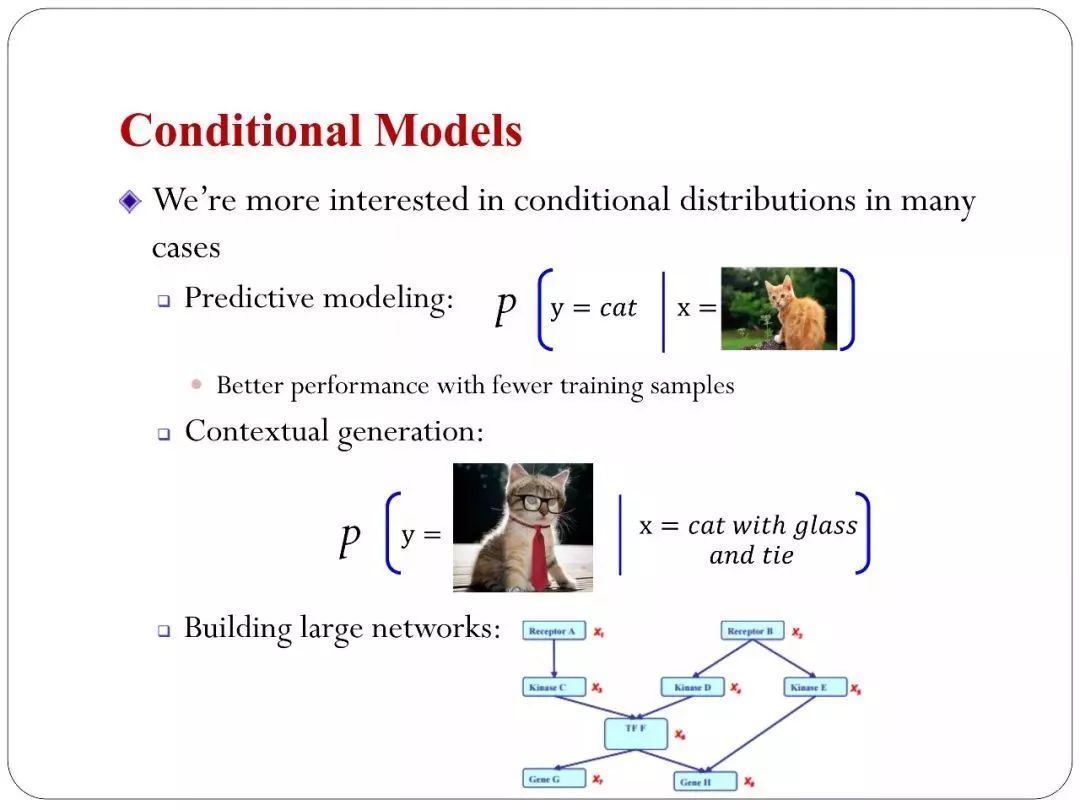
可以帮UMLD来做条件模型,也就是条件概率的估计。因为条件概率我们在很多场景下是受关心的,比如要做预测,预测就是给你一个输入再算一个条件概率。另外你可以做Conditional Models,比如你做image capture,你输入的是一个图片生成的一个文本。或者反过来。这是条件的生成。更可以用Conditional 的分布构造一个大的网络比如贝叶斯网络。本质上就是条件分布祖海在一起。所以如果你能够估计这种条件模型的话。对于有图结构的模型都可以去估计。我们做了基本的Conditional 的去估计。

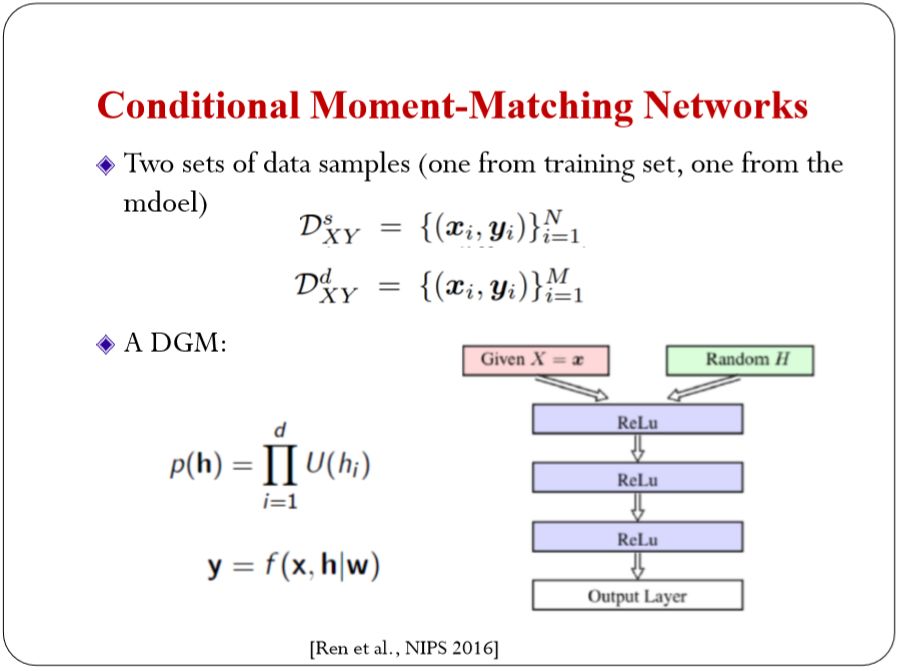
这个思想和前文中提到的, Moment-Matching的思想是一样的。可以定一个条件的生成模型。你的输入是有一个随机噪声。另外加上其他条件,比如条件文本或者是图片。后面经过神经网络变化得到输出的样本。这是我们从模型里面生成的XY的变量。训练集里面的担忧XY。现在就是定一个准则来去评判两个数据集到蒂是不是符合同一个分布。这里面我们定义(We define conditional max-min discrepancy (CMMD):),如下图:

在泛函空间里面定义。它可以保证当你的kernel足够强大的时候,距离等于零的时候,两个分布严格一致。这个可以用来做估计。
细节做不展开:

里有一些结论可以和原来没有conditional有一些泛化。如果原来MMD可以用举证写出来。这里有单位是一的矩阵。当一矩阵变成C1, C2, C3,C1, C2, C3表示了你属于条件变量的信息,所以从这个一上很直观的看出来你要考虑条件,反映了条件变量的影响。最终你的模型是更加灵活。
算法就不详细介绍了主要是BP to compute the gradients。

这是结果,做预测分类,在2016年的时候单个模型和最好的模型比也是有竞争力的。
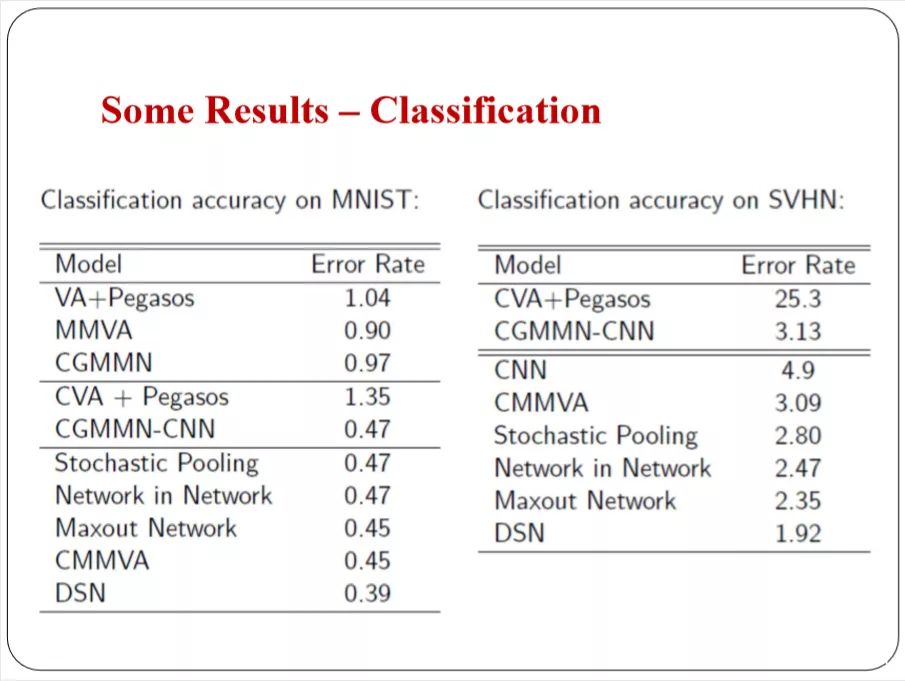
你可以做条件的生成。 
有一个比较有意思的是 Dark Knowledge ,从一个大的网络里面提取一些信息。
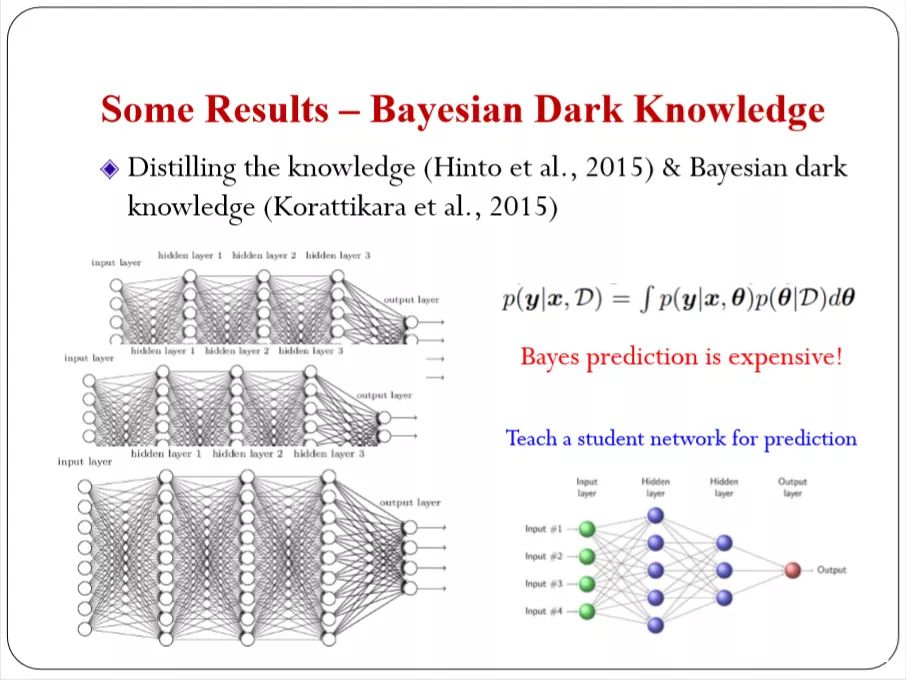
这里面可能有很多个大模型。我们用贝叶斯的观点来看,将很多个大模型平均起来,很难,所有一个Bayesian Dark Knowledge ,就是我不显示运算。我可以学习一个模型去近似贝叶斯的运算。原来非常复杂我用一个简单网络而去模拟它,来做输入输出的映射。
这样,对于运算,和我们之前讲的conditional model是一致的。可以用前面讲的准则去实现这个任务。和完全贝叶斯推断得到的结果。你学一个简单的网络的话。你可以逼近它,因为精度基本上没有太多损失。下图是一个任务。

这是关于怎么去应用深度生成模型。
3.Semi-supervised Learning
先定义GAN。

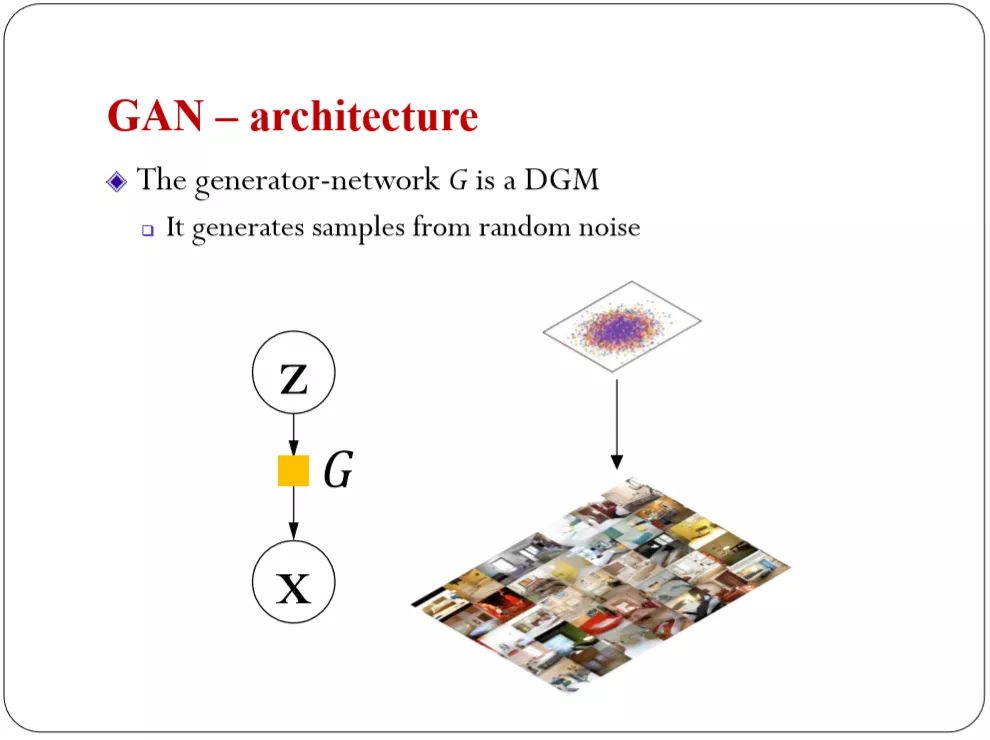
我们有一个生成网络,一个判别网络,两个网络的对抗。生成网络就是从白噪声通过神经网络来变换,得到真实的数据。判别网络从机器学习的角度来说是一个最简单的分类器——二分类。如果我们的数据从训练集里来的,那我就标注成1,如果是模型来的就标注成0,如果告诉你的话。大家都会做到。
GAN对于判别器来说,是有监督的学习。因为知道真实的数据是哪些。
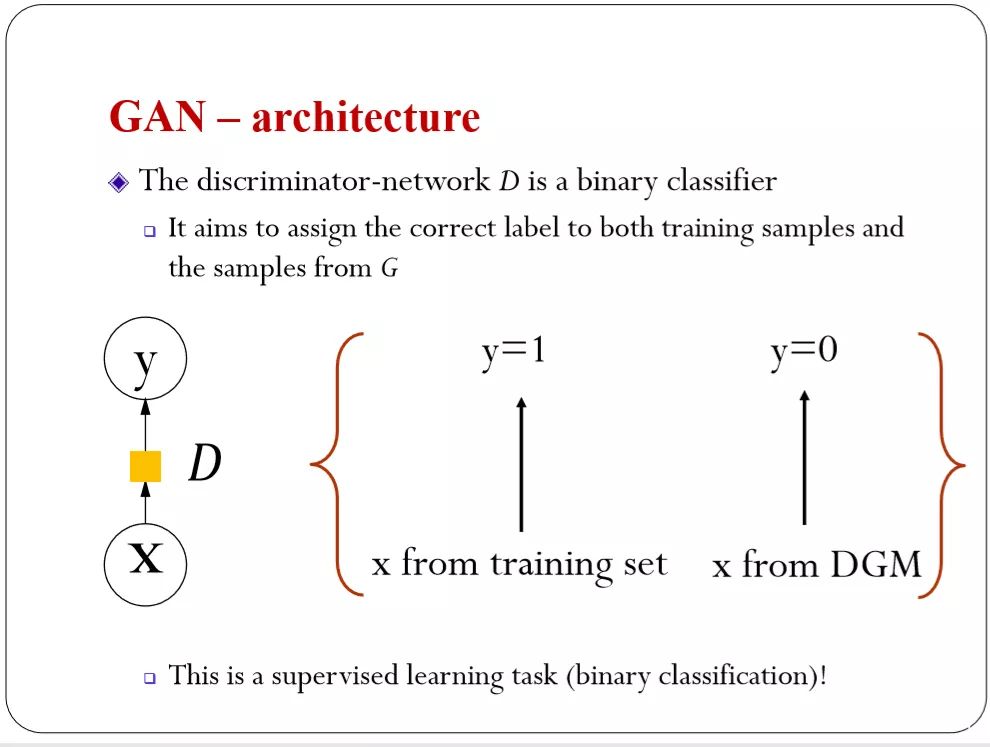
目标函数是对判别模型最大似然估计,如果你的数据标注成1,是的输出1的概率最高,如果标注成0就是零的概率最高。可以用 cross-entropy ,但是从分类的角度可以西环城很多loss.

我可以定义不同的GAN。
对于生成模型主要意图是去欺骗,使得生成的数据尽量能够被分成1。最大化分成1的概率。所以放在一起就是一个想去分类,一个想去欺骗分类。


所以就是Minimax objective function。它有些结果,你可以分析它的最优解(Optimum)。也可以得到所谓的Max均衡。
如何应用到Semi-supervised Learning中呢?
主要目的是我标注的数据很少。比如我给你一个红色的一个蓝色的你可能会告诉我最优分离超平面是在中间。

如果是这种分布你可能会怀疑原来那个分离面是不是最优的。你可能会说下图的更好。这是一个非常直观的例子,未标注的数据可能包含一些信息。对我们做分类是有用的。怎么样抽取未标准数据的信息,帮助我们来做半监督学习。
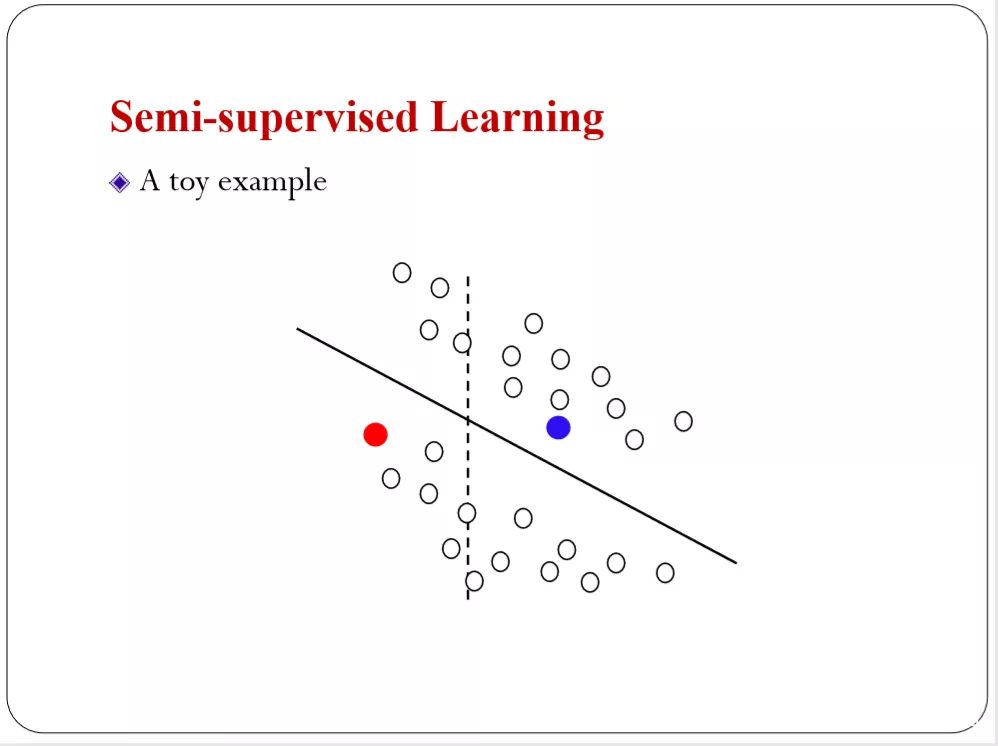
现在深度学习的进展,解决了表示的问题。在半监督学习里表示也很重要。你用不同的表述会得到不同的分类结果。如下图,所以怎么样去学习一个表示在这种半监督的场景下。

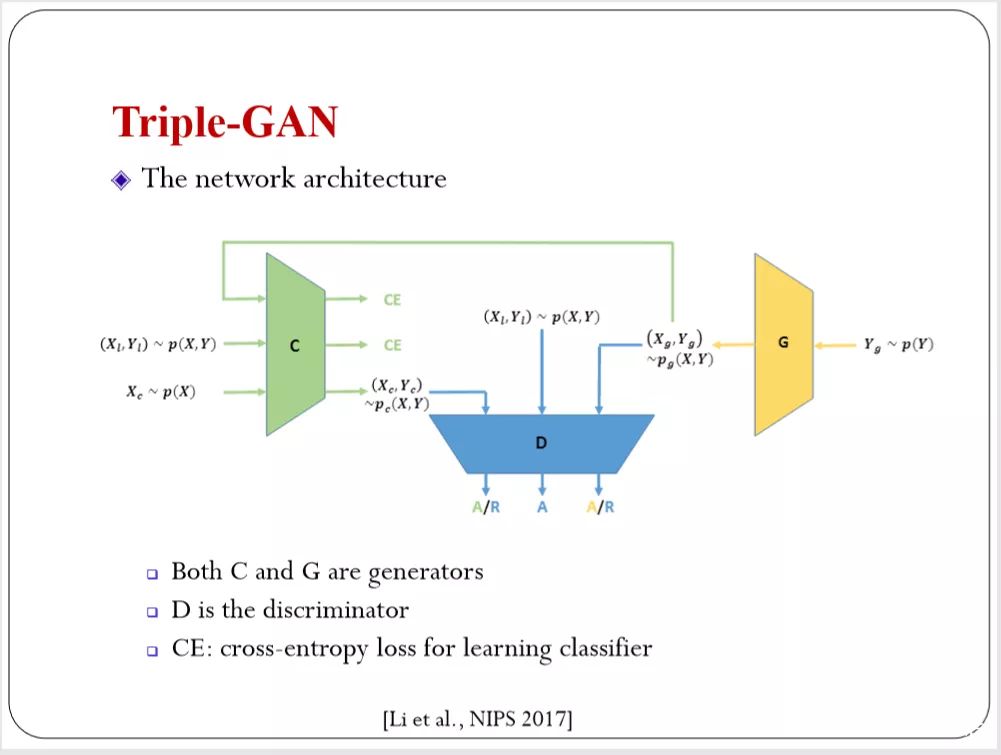
下图是团队去年的工作,叫Triple Generative AdversarialNets,想法也很直观,GAN是无监督学习。去估计数据密度是不是和模型密度一样。我有XY有输入输出,但大部分情况Y不知道,所以要考虑Y的概率分布。我们的目的就是要学??,?有没有联合分布。和GAN的目标一样。希望数据和联合分布的数据是一致的。两个达到平衡的时候是相等的。
这是我们的目标,我们的目标定义清楚之后如何实现?两个变量联合分布,我们可以用两种变量来分解它。这是两种分解形式,下图中标红的条件分布,他的物理含义有所不同。分类器,你给我一个输入,我告诉你输出的概率。
class conditional generation,你给我一个类别,我生成这一类的图片。这两个条件分布都有物理含义。我们都希望能够估计出来。这样的话我们用一个对抗网络。就有两种方式生成p(x, y),用生成的和真实的,就可以做对抗的训练。

这样我们有两个生成器(Both C and G are generators )。有一个判别器(D is the discriminator ),这是讲GAN的基本框架。C和G,C是从X开始,这个X可以从训练数据里面取样,这样就有生成器来得到Y。对于G先采样Y,如果类别是均衡的。我们就用均匀PY生成Y。
有了Y再用 conditionalgeneration生成X,同样的得到p(x, y),两条通道都是生成。中间会有真实的数据在里面。你用对抗网络就可以判断哪个是生成的,哪个是真实的。结构简单。和之前大家做半监督的GAN有很多的扩展。之前大家存在inconsistent的问题。会把一个判别器定义成多种任务。这样,从理论上来看,达不到纳什均衡。所以不能保证你能收敛到真实的联合分布。
A minimax game理论和GAN是一样的。

理论上保证,纳什均衡和目标完全是一样的。估计出来的分布和我们真实的分布是一样的。而且有意思的结果。有意思的是,他有两个generator,这两个genernator你可以用任意方式去combine。用某种combine的weight一般情况下用二分之一。你可以用0.3,或者0.7或者0.2 与0.8的权重去组合它。得到的结果都是consistent的,你可以根据具体的问题调整。从理论上上来看可以严格保证我们的最终目标是能够达到的。

但是半监督学习里面,真实场景下面有标注的数据太少。只可能有几个,或者几十个。实际上这是非常有挑战的。数据很少,数据分布很难精确描述。数据实在太少了,如果数据质量足够高,可以把生成的虚假的数据当成我标注的数据,做成Pseudolabeled data。

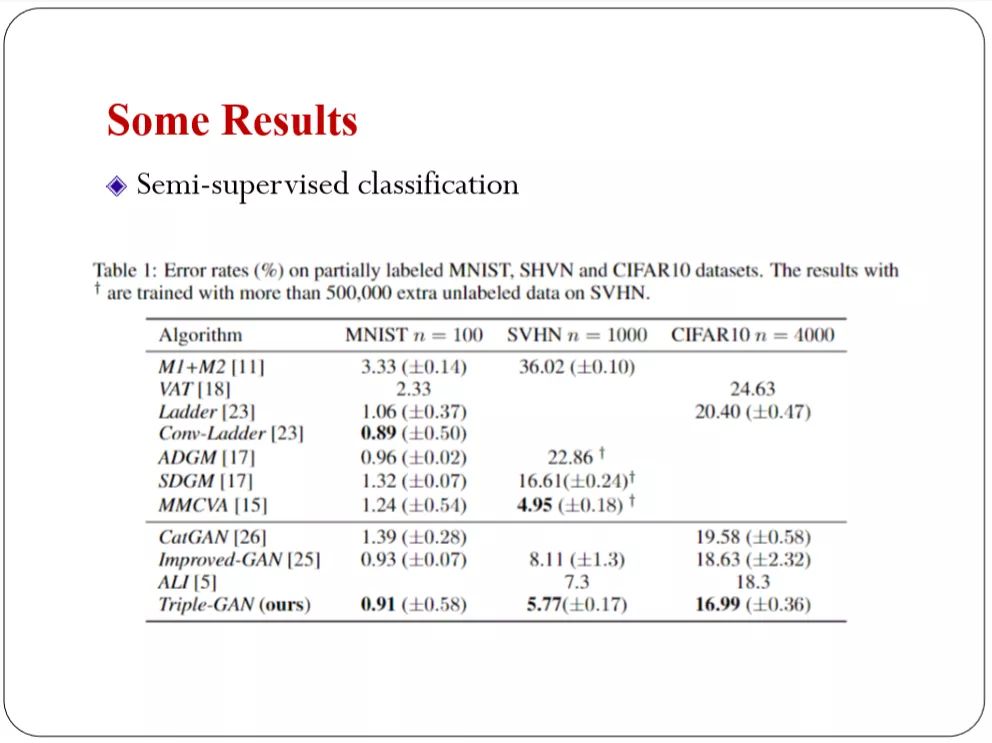
这是去年的结果,在所有的GAN里面,在半监督的做好的结果里我们是最好的。
这是生成的Class-conditional generation,生成自然图片。

Disentangle class and style,矩阵的形式,每一行固定一个类别,每一列变换风格,变换隐含变量的具体值。会得到同一类别不同风格的图片。左边是手写体,右边是自然图片,同样的道理。

还可以在隐含的表示空间里面做差值。右边是目标,生成比较光滑的变换。逐渐变换成风格的生成结果。

自然图片的复杂场景下的应用。你可以看到风格的变换。

Latent space interpolation on SVHN

以上都是triple GAN的功劳。
下面是去年NIPS的工作。把tripleGAN的工作又向前一步。triple GAN主要是做生产,没有推导的功能。你给我一个X我就推导出后验分布。这也是隐式模型的局限。名为Structured就是帮你引入更多的结构。可以推导出Y和Z的后验分布。有推导的能力之后就用某种方式引导Y和Z。前面把类别和风格(style)区别开,这里就可以做的更好。用一些技术加强分解的功能。
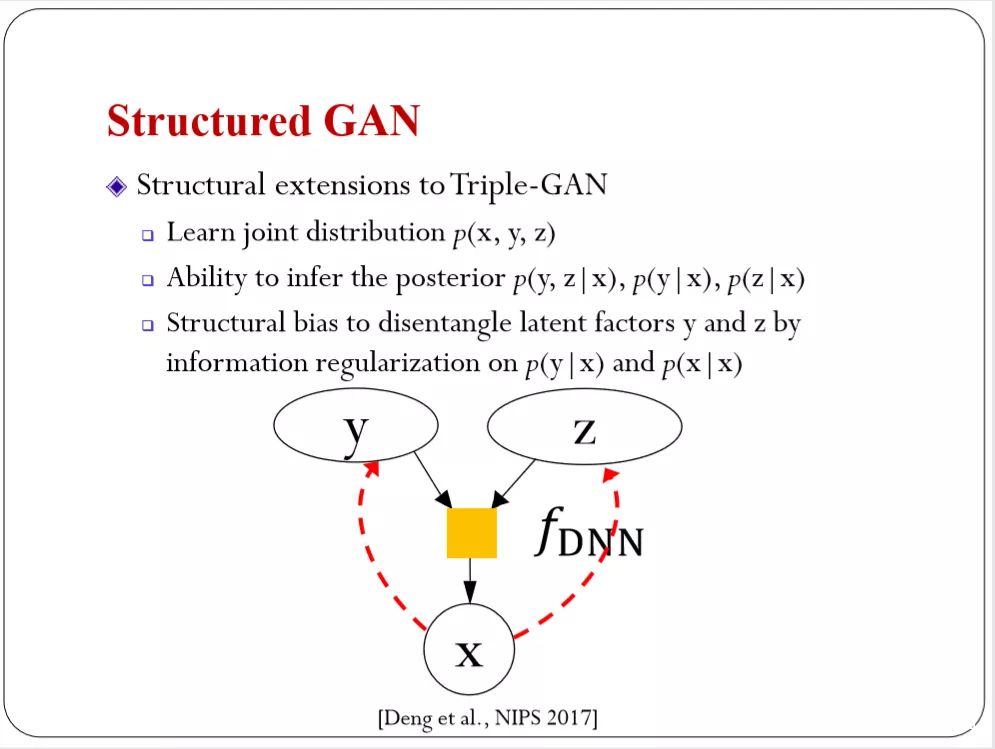
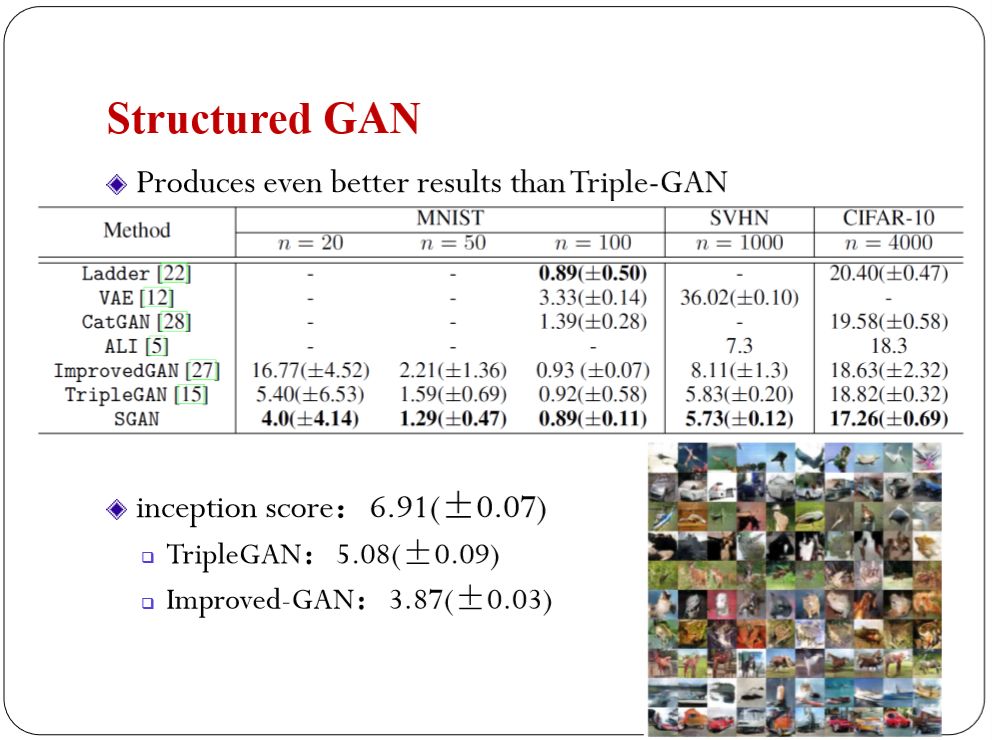
结果如下。比Triple GAN的还要好一些。生成我的图片的质量也会更高。把类别和风格(style)区分的更准确。
(完)
朱军介绍
师从张钹教授,获得清华大学计算机科学专业博士学位。[在卡内基梅隆大学机器学习系与Eric P.Xing教授合作完成博士后工作。 他当前的研究工作涉及统计学习,包括概率隐变量模型的理论与算法,高维稀疏学习,贝叶斯无参模型,大间距学习,统计分析在社会网络分析中的应用,数据挖掘,多媒体数据分析等。
国家优秀青年科学基金获得者(2013);
IEEE Intelligent Systems杂志评选的“AI’s 10 to Watch”(2013);
清华大学221基础研究计划入选者(2012);
中国计算机学会优秀博士论文奖获得者(2009)。


出品:谭婧
美编:陈泓宇


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









