




 本文探讨报表自动化中事实、维度和指标的存放、依赖关系及其设计。介绍强ETL和弱ETL方案,强调避免跨层调用以保持数据仓库的层次清晰。同时讨论了维度和指标的分层,以及如何在设计阶段建立良好的基础以减少后期重构成本。
本文探讨报表自动化中事实、维度和指标的存放、依赖关系及其设计。介绍强ETL和弱ETL方案,强调避免跨层调用以保持数据仓库的层次清晰。同时讨论了维度和指标的分层,以及如何在设计阶段建立良好的基础以减少后期重构成本。
前面的《报表自动化: 没有压力的维度建模》以及《报表自动化: 薅出数字背后的价值》两篇文章分别提及了维度建模中的事实、维度,以及指标三种表,那么他们之间具体有什么关系呢?前面都零星提到了一些,现在让我们来具象化的了解一下这个关系。
存放在哪
继续上之前手残画的图:
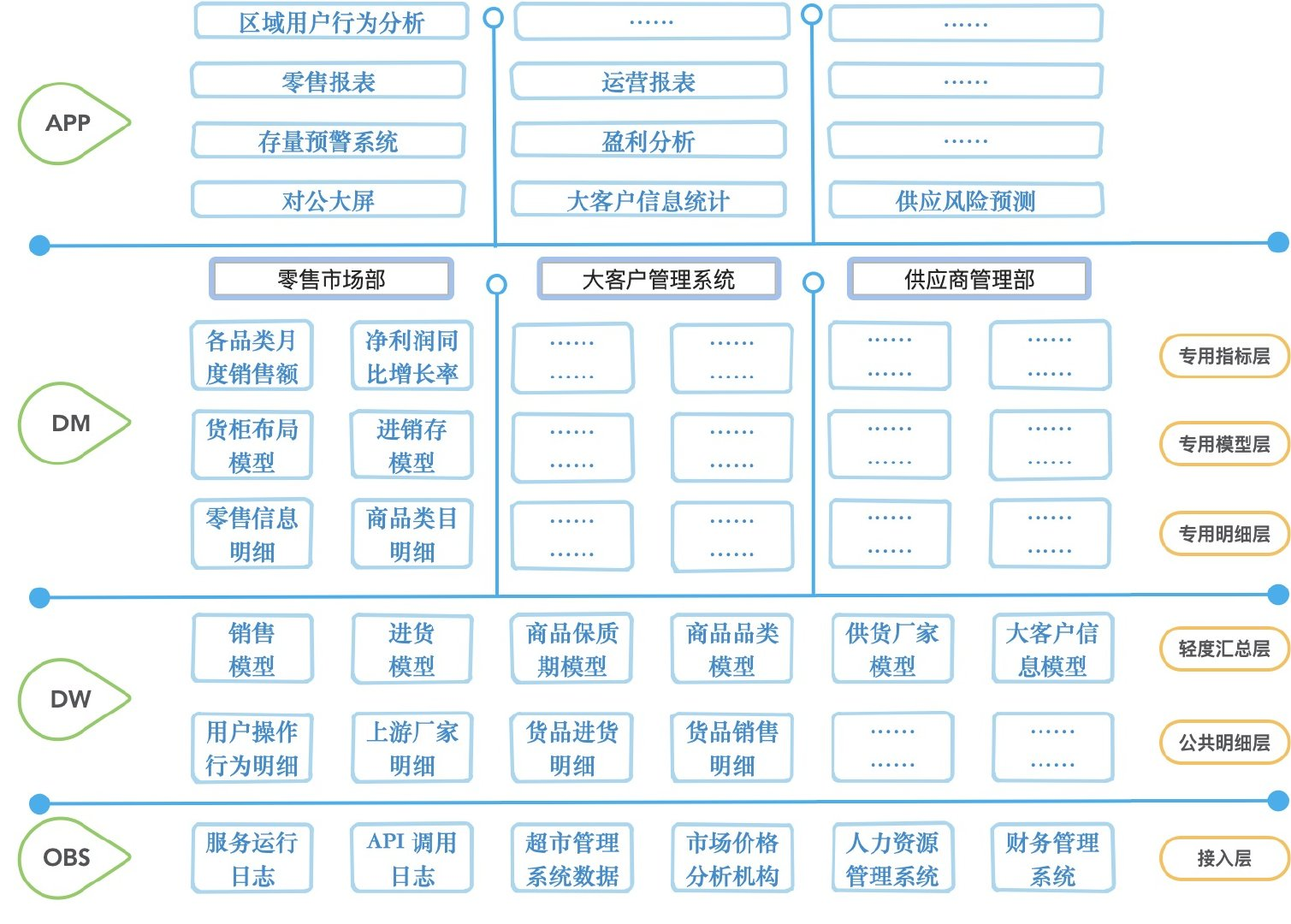
其中模型,在维度建模中就是事实和维度了,为这张图已经直观的展示出了三者放在那里了:
- 简单的情况:DW 库存放事实和维度,DM 库存放指标
- 复杂的情况:DW 存放事实和维度,同时存放不同团队、业务、产品公用的通用指标;DM 各个业务、产品的仓库拉取需要用到的 DW 库里的模型以及通用指标,并构建一定的专用模型以及大量的自己的专用指标
- 极简的情况:也许根本就没有区分 DW、DM 两层数据库,一个库里搞定了
上面提到了通用、公用的概念,这就类似于 JAVA 代码或者说是我们常规的后端服务开发代码里面的抽取重复代码了,但是在数仓里面的抽取要注意:逐层下沉,满足复用需要即可
依赖关系
上面只显示了各层数据库要如何存放,那么他们是如何构建成这个层次分明的金字塔呢?
强 ETL 方案
先来展示一种在流程上来说简单的依赖方式,这种方案里的 ETL 工
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 10万+
10万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









