



文章目录
前言
一、线程池的作用
为什么会有线程池,到底解决了什么问题?
- 减少线程的创建与销毁(线程的角度)
- 异步解耦的作用(设计的角度)
线程池的异步处理使用场景
以日志为例,在写日志loginfo(“xxx”),与日志落盘,是两码事,它们两之间应该是异步的。那么异步解耦就是将日志当作一个任务task,将这个任务抛给线程池去处理,由线程池去负责日志落盘。对于应用程序而言,就可以提升落盘的效率。
以nginx为例,一秒几万的请求,速度很快。如果在其中加一个日志,那么qps一下子就掉下来了,因为每请求一次就需要落盘一次,那么整个服务器的性能就下降。我们可以引入一个线程池,把日志这个任务抛给线程池,对于主循环来说,就只抛任务即可,这样就可以大大提升主线程的效率。这就是线程池异步解耦的作用
不仅仅是日志落盘,还有很多地方都可以用线程池,比较耗时的操作如数据库操作,io处理等,都可以用线程池。
二、线程池工作原理
1.框架图
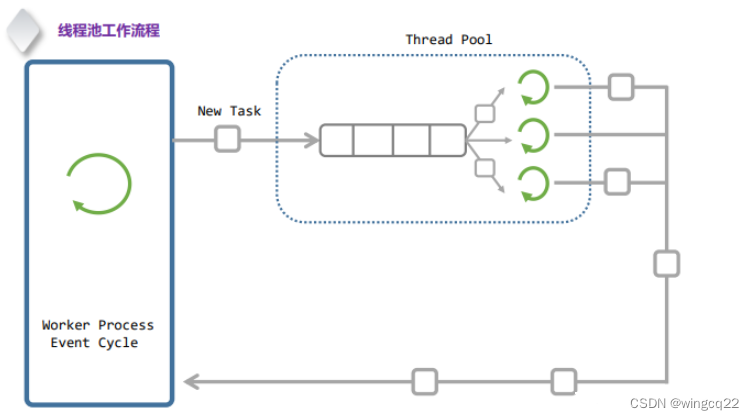
2. 工作原理:
- 任务提交:将任务提交给线程池。任务通常以函数指针、可调用对象或某种形式的任务对象表示。
- 任务队列:线程池维护一个任务队列,将提交的任务放入队列中等待执行。
- 工作线程:线程池中预先创建一组工作线程,这些线程不断从任务队列中取出任务执行。
- 任务执行:工作线程从任务队列中取出任务并执行,当任务执行完毕后,线程返回任务队列继续取下一个任务执行。
- 线程复用:线程池中的线程被复用,避免了频繁创建和销毁线程的开销。
3. 主要组件:
- 任务队列:用于存储等待执行的任务。常用的数据结构是队列。
- 工作线程:负责执行任务的线程。它们从任务队列中取出任务并执行。
- 线程池管理器:负责管理任务队列和工作线程,并提供接口给外部提交任务。
4. 线程池的使用场景
线程池适用于以下场景:
- 服务器应用:如 Web 服务器,处理多个并发请求。
- 批处理任务:处理大量独立的任务,如图像处理、数据分析。
- 并发计算:如并行算法,将计算任务分发到多个线程执行。
三、代码实现
#include <pthread.h>
#include <stdatomic.h>
#include <stdint.h>
#include <stdlib.h>
#include "thrd_pool.h"
#include "spinlock.h"
/**
* shell: gcc thrd_pool.c -c -fPIC
* shell: gcc -shared thrd_pool.o -o libthrd_pool.so -I./ -L./ -lpthread
* usage: include thrd_pool.h & link libthrd_pool.so
*/
typedef struct spinlock spinlock_t;
typedef struct task_s {
void *next; // 连接下一个任务
handler_pt func; // 任务执行
void *arg; // 上下文
} task_t;
typedef struct task_queue_s {
void *head;
void **tail;
int block;
spinlock_t lock;
pthread_mutex_t mutex;
pthread_cond_t cond;
} task_queue_t;
struct thrdpool_s {
task_queue_t *task_queue; // 任务队列
atomic_int quit; // 标记线程池退出,原子变量-具备原子性-线程安全的
int thrd_count; // 线程数
pthread_t *threads; // 管理线程
};
// 对称
// 资源的创建 回滚式编程
// 业务逻辑 防御式编程
static task_queue_t *
__taskqueue_create() {
int ret;
task_queue_t *queue = (task_queue_t *)malloc(sizeof(task_queue_t));
if (queue) {
ret = pthread_mutex_init(&queue->mutex, NULL);
if (ret == 0) {
ret = pthread_cond_init(&queue->cond, NULL);
if (ret == 0) {
spinlock_init(&queue->lock); // 肯定会成功,因为是在用户态的行为
queue->head = NULL;
queue->tail = &queue->head;
queue->block = 1;
return queue;
}
pthread_mutex_destroy(&queue->mutex);
}
free(queue); // 创建锁资源失败 -> 回滚操作,释放资源
}
return NULL;
}
static void
__nonblock(task_queue_t *queue) {
pthread_mutex_lock(&queue->mutex);
queue->block = 0;
pthread_mutex_unlock(&queue->mutex);
pthread_cond_broadcast(&queue->cond);
}
static inline void
__add_task(task_queue_t *queue, void *task) {
// 不限定任务类型,只要该任务的结构起始内存是一个用于链接下一个节点的指针
void **link = (void**)task;
*link = NULL;
spinlock_lock(&queue->lock);
*queue->tail /* 等价于 queue->tail->next */ = link; // 解引用后是next指针
queue->tail = link;
spinlock_unlock(&queue->lock);
pthread_cond_signal(&queue->cond);
}
static inline void *
__pop_task(task_queue_t *queue) {
spinlock_lock(&queue->lock);
if (queue->head == NULL) {
spinlock_unlock(&queue->lock);
return NULL;
}
task_t *task;
task = queue->head;
void **link = (void**)task;
queue->head = *link;
if (queue->head == NULL) {
queue->tail = &queue->head;
}
spinlock_unlock(&queue->lock);
return task;
}
static inline void *
__get_task(task_queue_t *queue) {
task_t *task;
// 虚假唤醒
while ((task = __pop_task(queue)) == NULL) {
pthread_mutex_lock(&queue->mutex);
if (queue->block == 0) {
pthread_mutex_unlock(&queue->mutex);
return NULL;
}
// 1. 先 unlock(&mtx)
// 2. 在 cond 休眠
// --- __add_task 时唤醒
// 3. 在 cond 唤醒
// 4. 加上 lock(&mtx);
pthread_cond_wait(&queue->cond, &queue->mutex);
pthread_mutex_unlock(&queue->mutex);
}
return task;
}
static void
__taskqueue_destroy(task_queue_t *queue) {
task_t *task;
while ((task = __pop_task(queue))) {
free(task);
}
spinlock_destroy(&queue->lock);
pthread_cond_destroy(&queue->cond);
pthread_mutex_destroy(&queue->mutex);
free(queue);
}
static void *
__thrdpool_worker(void *arg) {
thrdpool_t *pool = (thrdpool_t*) arg;
task_t *task;
void *ctx;
while (atomic_load(&pool->quit) == 0) {
task = (task_t*)__get_task(pool->task_queue);
if (!task) break;
handler_pt func = task->func;
ctx = task->arg;
free(task);
func(ctx);
}
return NULL;
}
static void
__threads_terminate(thrdpool_t * pool) {
atomic_store(&pool->quit, 1);
__nonblock(pool->task_queue);
int i;
for (i=0; i<pool->thrd_count; i++) {
pthread_join(pool->threads[i], NULL);
}
}
static int
__threads_create(thrdpool_t *pool, size_t thrd_count) {
pthread_attr_t attr;
int ret;
ret = pthread_attr_init(&attr);
if (ret == 0) {
pool->threads = (pthread_t *)malloc(sizeof(pthread_t) * thrd_count);
if (pool->threads) {
int i = 0;
for (; i < thrd_count; i++) {
if (pthread_create(&pool->threads[i], &attr, __thrdpool_worker, pool) != 0) {
break;
}
}
pool->thrd_count = i;
pthread_attr_destroy(&attr);
if (i == thrd_count)
return 0;
__threads_terminate(pool);
free(pool->threads);
}
ret = -1;
}
return ret;
}
void
thrdpool_terminate(thrdpool_t * pool) {
atomic_store(&pool->quit, 1);
__nonblock(pool->task_queue);
}
thrdpool_t *
thrdpool_create(int thrd_count) {
thrdpool_t *pool;
pool = (thrdpool_t*)malloc(sizeof(*pool));
if (pool) {
task_queue_t *queue = __taskqueue_create();
if (queue) {
pool->task_queue = queue;
atomic_init(&pool->quit, 0);
if (__threads_create(pool, thrd_count) == 0)
return pool;
__taskqueue_destroy(queue);
}
free(pool);
}
return NULL;
}
int
thrdpool_post(thrdpool_t *pool, handler_pt func, void *arg) {
if (atomic_load(&pool->quit) == 1)
return -1;
task_t *task = (task_t*) malloc(sizeof(task_t));
if (!task) return -1;
task->func = func;
task->arg = arg;
__add_task(pool->task_queue, task);
return 0;
}
void
thrdpool_waitdone(thrdpool_t *pool) {
int i;
for (i=0; i<pool->thrd_count; i++) {
pthread_join(pool->threads[i], NULL);
}
__taskqueue_destroy(pool->task_queue);
free(pool->threads);
free(pool);
}
四、其他问题
1. 线程数量的抉择
线程到底初始化多少呢?如果是计算密集型就不用太多的线程,如果是任务密集型可以多几个。以下是经验值,不一定一定按照这个来。
计算密集型:强计算,计算时间较长,线程数量与cpu核心数成比例即可,如1:1。
任务密集型:处理任务,io操作。可以开多一点,如cpu核心数的2倍。
2. 线程池的动态扩缩
随着任务越来越多,线程不够用怎么办?我们可以开一个监控线程,设n=running线程 / 总线程。当n>上水位时,监控线程创建几个线程;当n<下水位时,监控线程销毁几个线程。可以设置30%和70%。
3. 回滚式编程和防御式编程
- 回滚式编程是一种确保在操作失败时能够恢复到先前状态的方法,主要应用于事务处理系统中,如数据库操作。其核心思想是在执行可能失败的操作前保存当前状态,若操作失败则回滚到之前的状态,以确保系统的一致性。
- 防御式编程是一种编程方法,旨在通过在代码中加入大量的检查和验证,防止错误和意外情况的发生,从而提高程序的健壮性和可靠性。其核心思想是“预防胜于治疗”,通过防御性的代码来捕获潜在问题。

















 9489
9489

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









