




canal 1.1.5 版本
先有一个整体的认识,canal分为如下三个独立运行的项目。
canal.deployer 实现数据从binlog日志解析到提供数据给其他组件消费。以下简称canal
canal.admin-web 是canal的管理平台,能够实现canal的动态配置,动态启停,知道canal是否运行,查看canal运行日志,以下简称canal-admin,在eclipse中运行需要配置-javaagent:/ebean-agent-11.41.1.jar
client-adapter.launcher canal提供了数据接口,具体数据如何消费则用具体应用自己去实现,为了降低实现门槛及有相当大一部分需求是共通的,比如同步到es等等。为此建立了一个client-adapter,提供了多种案例,我们可以基于这些案例去写自己的client-adapter实现或者进一步改动满足自己的需求。
canal-admin作为canal运维平台。以前canal都是基于配置文件进行维护,现在可以基于canal-admin进行配置维护,canal目前启动只需要极少的一些必须配置项即可启动,其他配置信息皆来自于canal-admin。

canal-admin
canal 通过CanalAdminWithNetty 提供接口给canal-admin进行远程调用,进而对canal进行管理。
canal-admin 内部对于状态是实时去canal查询的,比如server是否启动,instance是否启动,所以会比较慢。内部通过SimpleAdminConnector包装通讯协议。
canal
canal 生产过程讲解:
canal 内部支持解析本地binlog日志文件以及模拟mysql slave向服务器发起dump请求获取binlog日志。为了保证能够重启后可以正常工作,需要在重启后知道应该加载binlog日志的parse position解析位点 ,canal通过CanalLogPositionManager 记录解析位点 ,通过解析日志形成event,为了保证事物完整性特性,canal将一个事物的数据都存储到EventTransactionBuffer,在遇到事物操作数据比较大,超过buffer容量后,将会分几个批次进行flush,或者如果遇到事物的begin、commit都会进行flush。否则将解析的数据存储在buffer即可。当flush调用CanalEventSink.sink到达store时; 会被CanalEventDownStreamHandler集合处理,在这里我们可以定义自己的CanalEventDownStreamHandler对数据进行转换处理等等。 数据流继续eventStore.tryPut 尝试放入store,如果放入成功则会更新解析位点,到目前为止整个过程都运行在解析线程中, 解析 -> 事物数据汇聚buffer -> CanalEventDownStreamHandler 转换 -> store put --> logPositionManager.persistLogPosition 更新解析位点 运行与同一个线程,如此反复进行。 现在store只有MemoryEventStoreWithBuffer 基于内存的实现,故如果store满了,store put将会被阻塞,消费者的消费能力对于同步也是一个很大的影响点。因为store目前只能选择基于内存的,故可不保留解析位点,下一次 canal 启动时直接依赖 CanalMetaManager 记录的最后一次消费成功的位点即可. (最后一次ack提交的数据位点)。也就是CanalLogPositionManager 选择 MetaLogPositionManager实现。这样可以保证数据不丢失。
canal消费过程讲解:
CanalServerWithEmbedded
前面数据已经产生到store,需要提供接口给消费者去消费数据。CanalServerWithEmbedded实现了CanalService,支持如下功能:
//订阅
void subscribe(ClientIdentity clientIdentity)
//取消订阅
void unsubscribe(ClientIdentity clientIdentity)
//获取下一个批次的数据,内部会记录获取获取位置,达到分页效果。而且是自动确认,就是内部在获取数据的同时也进行了 ack,内部使用tryGet获取数据,不管是否有数据,都是即时返回。
Message get(ClientIdentity clientIdentity, int batchSize)
//和上面get一样,但是多了timeout时间控制。
* 几种case:
* a. 如果timeout为null,则采用tryGet方式,即时获取 就是上面那个get方法的效果。
* b. 如果timeout不为null
* 1. timeout<=0,则采用get阻塞方式,获取数据,不设置超时,直到有足够的batchSize数据才返回
* 2. timeout不为0,则采用get+timeout方式,获取数据,超时还没有batchSize足够的数据,有多少返回多少
Message get(ClientIdentity clientIdentity, int batchSize, Long timeout, TimeUnit unit)
//对方法get去除自动ack的功能,需要客户端自己调用ack进行确认
Message getWithoutAck(ClientIdentity clientIdentity, int batchSize)
//对应上面的get+timeout方法去除自动ack功能。
Message getWithoutAck(ClientIdentity clientIdentity, int batchSize, Long timeout, TimeUnit unit)
//进行反馈时必须按照batchId的顺序进行ack(需有客户端保证)
void ack(ClientIdentity clientIdentity, long batchId)
//回滚到未进行 {@link #ack} 的地方,下次fetch的时候,可以从最后一个没有 {@link #ack} 的地方开始拿
void rollback(ClientIdentity clientIdentity)
//回滚到指定的批次,需要保证此批次是未提交批次中最小的批次,否则异常。然后没有看到可以重新拉取此批次数据的实现,故v1.1.5版本前不要使用这个接口
void rollback(ClientIdentity clientIdentity, Long batchId)
CanalServerWithEmbedded 主要实现对外提供消费的能力,通过对应canal instance 的CanalMetaManager记录消费者的订阅、消费位点信息,并将具体请求的get及ack/rollback交给对应canal instance的Store处理。
CanalServerWithNetty:
CanalServerWithEmbedded 具备了业务处理能力,如果想要将自己的业务消费需求和canal 运行在一个项目中,则可以直接在内部调用CanalServerWithEmbedded 对应的方法即可让整个项目运行在一起。如果想要rpc调用,运行在不同项目中,则通过CanalServerWithNetty提供的通讯协议发起远程调用,其内部消费逻辑委托给CanalServerWithEmbedded 实现,CanalServerWithNetty只处理通讯相关业务。
canal通过netty自定义通讯协议实现了消费接口,为了方便使用消费接口,以及有大多相同的业务需求,故而提供了client-adapter 来让我们的消费端更容易实现。
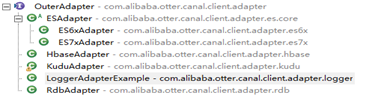
如果我们还有别的需求,比如同步redis等等可以基于上面的一些实现进行改造。

















 772
772

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









