






银行会员流水为例:
create table hive_sum(
id string COMMENT '会员ID',
bank_name string COMMENT '银行名称',
create_time string COMMENT '交易时间',
amount double COMMENT '交易金额')
COMMENT 'hive_sum顶级应用'ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'LINES TERMINATED BY '\n';
load data local inpath '/data/tmp/tqc/hive_sum.txt' overwrite into table tmp.hive_sum;
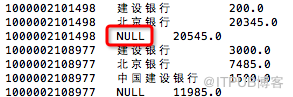
partition by一个字段时,等于聚合函数sum(默认配置不生效)
*
select id,bank_name,create_time,amount,sum(amount) over(partition by id) amount_all
from tmp.hive_sum order by id,bank_name,create_time;
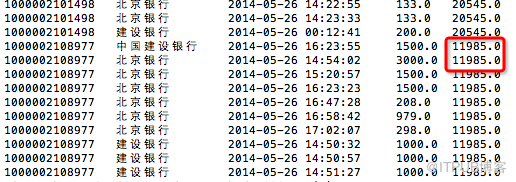
实际上,期望数据如下:
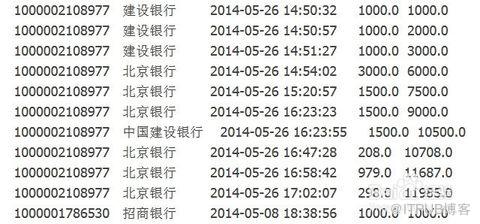
两个以上字段分组
select id,bank_name,sum(amount) amount_all
from tmp.hive_sum
group by id,bank_name
with rollup
order by id, bank_name desc ;
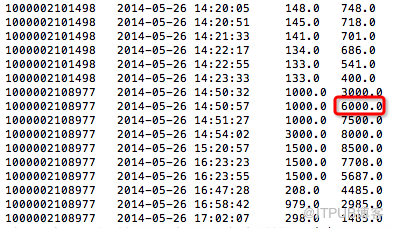
获取分组后当前行前后两条
select id,create_time, amount,sum(amount) over(partition by id order by create_time asc rows between 2 preceding and 2 following ) amount_all
from tmp.hive_sum
order by id, create_time asc;
最后,数据 丢给分析师使用
create table hive_sum(
id string COMMENT '会员ID',
bank_name string COMMENT '银行名称',
create_time string COMMENT '交易时间',
amount double COMMENT '交易金额')
COMMENT 'hive_sum顶级应用'ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'LINES TERMINATED BY '\n';
load data local inpath '/data/tmp/tqc/hive_sum.txt' overwrite into table tmp.hive_sum;
partition by一个字段时,等于聚合函数sum(默认配置不生效)
*
order by的默认窗口总是从结果集的第一行开始到它分组的最后一行。
而partiton by的默认窗口总是从分区的第一行开始
select id,bank_name,create_time,amount,sum(amount) over(partition by id) amount_all
from tmp.hive_sum order by id,bank_name,create_time;

实际上,期望数据如下:

两个以上字段分组
select id,bank_name,sum(amount) amount_all
from tmp.hive_sum
group by id,bank_name
with rollup
order by id, bank_name desc ;

获取分组后当前行前后两条
select id,create_time, amount,sum(amount) over(partition by id order by create_time asc rows between 2 preceding and 2 following ) amount_all
from tmp.hive_sum
order by id, create_time asc;

最后,数据 丢给分析师使用
来自 “ ITPUB博客 ” ,链接:http://blog.itpub.net/29665621/viewspace-2078912/,如需转载,请注明出处,否则将追究法律责任。
转载于:http://blog.itpub.net/29665621/viewspace-2078912/


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









