





 超级会员免费看
超级会员免费看

 本文详细介绍了Hive中的分区表和分桶表。分区表通过分区概念提高查询效率,支持单分区和多分区,动态和静态加载。分桶表则是通过字段分桶优化查询,降低全表扫描,提升JOIN效率。文章通过实例演示了创建、操作和使用这两种表的方法及优点。
本文详细介绍了Hive中的分区表和分桶表。分区表通过分区概念提高查询效率,支持单分区和多分区,动态和静态加载。分桶表则是通过字段分桶优化查询,降低全表扫描,提升JOIN效率。文章通过实例演示了创建、操作和使用这两种表的方法及优点。
目录
一、分区概念产生背景
使用hive对表进行查询时,比如:select * from t_user where name =' lihua' ,hive执行这条sql的时候,一般会扫描整个表的数据,我们知道全表扫描的效率是很低的,尤其是对于hive这种最终数据的查询要走hdfs文件全表扫描效率就更低了。
事实上,在很多情况下,业务中需要查询的数据并不需要全表扫描,而是能够预知查询的数据在一定的区域中,基于这个前提,hive在建表的时候就引入了partition(分区)的概念。对应建表语法树位置如下:
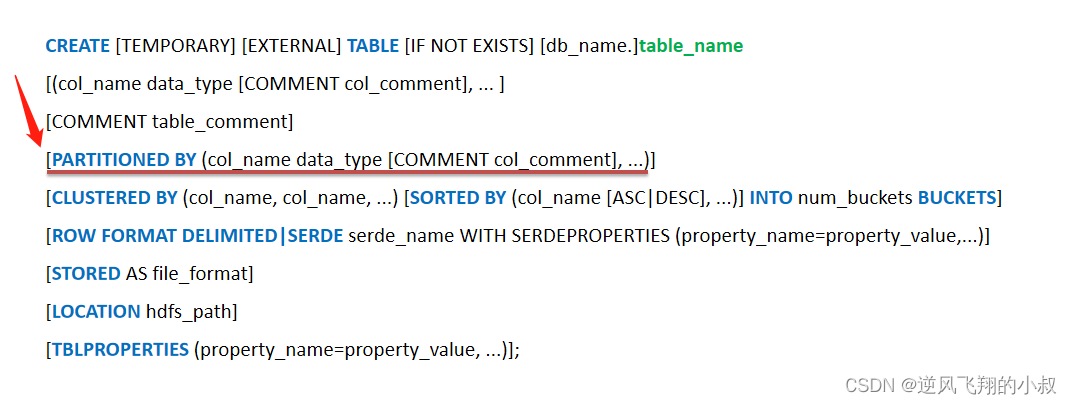
二、分区表特点
分区表指的是在创建表时指定的partition的分区空间,如果需要创建有分区的表,需要在create表的时候调用可选参数partitioned by;
-
一个表可以拥有一个或者多个分区,每个分区以文件夹的形式单独存在表文件夹的目录下;
</

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 3577
3577

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











