




 从单体架构转向微服务架构需要进程间通信(IPC)。本文探讨了四种流行的IPC机制:REST、GraphQL、gRPC和消息传递,分析了它们的同步/异步、点对点/多点、消息格式特点,并对比了各自的API,如REST的简单接口和HTTP兼容性,GraphQL的数据精确获取,gRPC的高性能和语言无关性,以及消息传递在处理大量数据和高吞吐量场景的优势。选择适合的IPC依赖于服务交互方式、消息类型、消息大小以及团队的技术背景。
从单体架构转向微服务架构需要进程间通信(IPC)。本文探讨了四种流行的IPC机制:REST、GraphQL、gRPC和消息传递,分析了它们的同步/异步、点对点/多点、消息格式特点,并对比了各自的API,如REST的简单接口和HTTP兼容性,GraphQL的数据精确获取,gRPC的高性能和语言无关性,以及消息传递在处理大量数据和高吞吐量场景的优势。选择适合的IPC依赖于服务交互方式、消息类型、消息大小以及团队的技术背景。
从单体架构到微服务的转变需要构成应用程序的不同服务之间的通信。服务实例通常是需要以某种方式相互通信的进程,这就是进程间通信(IPC)--有时称为服务间通信(ISC)--的作用。
人们往往想到的IPC机制是RESTful APIs,因为这仍然是使用最广泛的,但其他选择已经出现,可能更适合特定的使用案例。在这篇文章中,除了REST,我们还考虑了其他三种流行的选择:GraphQL、gRPC和Messaging。但是,在确定哪种通信类型最适合你时,有几个类别需要考虑。
同步或异步
同步通信意味着微服务或客户端在等待对请求的响应时被阻塞,而异步通信在收到响应之前能够继续进行(可能稍后或永远不会收到)。
点对点或多点
服务要1:1通信(称为点对点),其中每个请求由一个其他服务处理?那么可以选择同步的请求/响应通信,或者只是简单的异步单向通知。
如果请求要到达多个其他服务(1:n,又称多点),那么异步发布/订阅交互会更好。这些通常使用消息代理来实现:这样,一个请求仍然只需要发送一次就可以被多个服务处理。流行的开源代理选项包括RabbitMQ和Apache Kafka,而主要的供应商产品包括IBM的古老的MQ,最初于1993年推出,以及TIBCO的基于JMS的企业消息服务。
消息格式
如果发送的数据将被人们检查,你可能想选择一种他们可以阅读的消息格式(如JSON或XML)。否则,二进制格式(如协议缓冲区或Apache Avro)会更有效。
API的作用
API通常作为服务之间或服务与客户之间的契约。对于内部微服务之间的通信,建议通常不使用同步(因此是阻塞)协议,但这仍然是面向公众或客户的API的标准。
根据架构和微服务之间的预期交互,有不同的机制可供选择。纵观进程间通信的选项,每一种都有自己的优点和缺点,并有不同的最佳使用情况。下面是微服务架构中IPC选项的一些例子。

REST
RESTful APIs是与服务进行通信的事实上的行业标准。它们由三个部分定义:URI、标准的HTTP方法(如GET和PUT)以及媒体类型。数据用资源表示--例如,客户或其他业务对象。
使用REST有几个优点:
- 简单的接口,容易上手
- 众所周知的,成熟的
- 防火墙友好(因为它使用HTTP/S端口)
- 用浏览器或简单的curl命令测试
有一些缺点:
- 通常是同步的请求/响应互动
→ 替代方法:消息传递 - URI必须由客户知道-需要服务发现
- 端点是由资源定义的,因此很难在一个请求中从多个资源中获得数据,这可能导致类似的请求:
GET /customers/customer_id?expand=orders当试图同时获得客户和订单资源时。
→ 替代方案:GraphQL - 对HTTP动词的依赖会导致更复杂的URI端点结构(例如,更新请求很难映射到PUT,因为更新不是等价的)
→ 替代方案:gRPC - 没有中间缓冲区,所以请求和响应服务都需要在交换期间运行
(如果你在手机上查看这篇博文,你可以下载 以下表格的PDF ,以方便阅读。)

GraphQL
与REST不同,GraphQL查询确切地定义了他们想要的数据,并且只接收这些数据。
他们不只是针对每个请求的一个资源,而是遵循它们之间的引用,以便通过单个请求实现更快的数据检索。这是通过使用类型和字段而不是多个资源端点来实现的。
GraphQL最初是由Facebook在2012年发明和使用的,然后在2015年成为开放源代码。类似的项目大约在同一时间共同发展,包括Netflix的Falcor,但没有看到那么多的采用,而Netflix本身已经开始转向GraphQL。其他已经采用GraphQL的大公司包括Airbnb、Coursera和GitHub。GraphQL 通过HTTP工作,但像REST一样,也可以使用其他协议,包括RSocket。
当使用HTTP时,你可以使用各种工具来查询GraphQL API,例如:
curl -X POST-H "Content-Type: application/json"-data '{ "query":" { hero { name friends { name } }}"}'<GraphQL端点>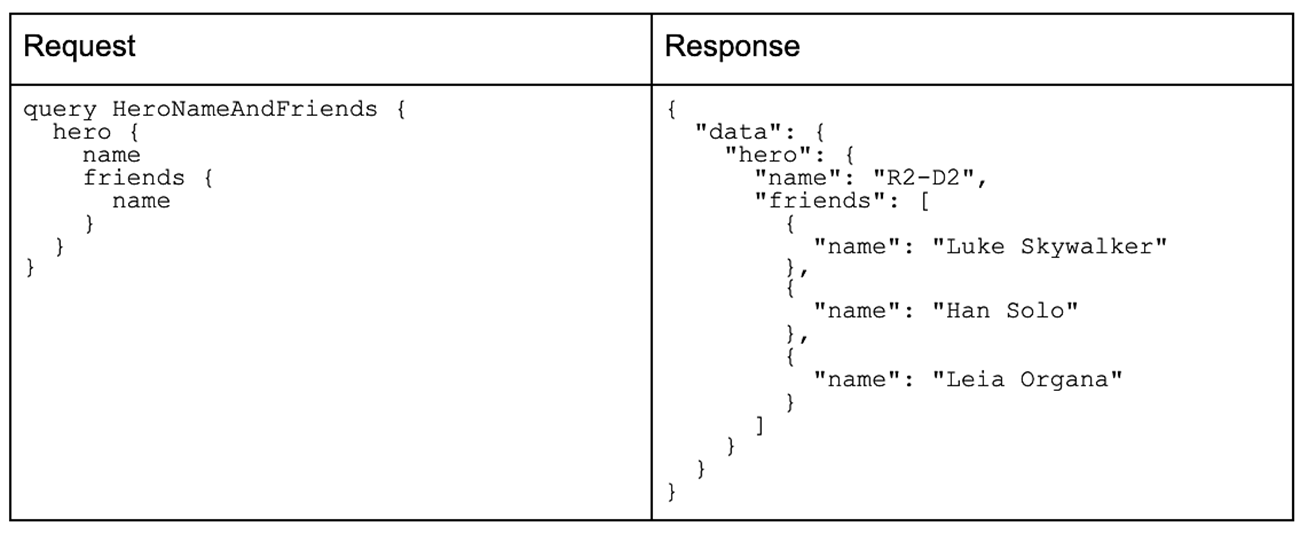
(如果你在手机上查看这篇博文,你可以下载 上述表格的PDF格式 ,以便于阅读。)
GraphQL通过比REST需要更少的请求和只传输请求的数据而不传输其他字段来降低请求的复杂性。它还使用一个单一的端点,所以服务发现是不必要的。如果一个单一的图变得过于复杂和单一,可以用Apollo Federation把图的实现分成多个可组合的服务。
多个来源可以聚合成一个,作为消费者驱动的API网关,增加功能或向消费者隐藏复杂性。
GraphQL提供了一个替代方案,通过增加或废除字段来解决API版本的困难,但这也带来了自己的挑战。Netflix有一个完整的模式工作组和一个数据架构师来监督对图形的任何改变。
查询语言的结构也会引起一些问题。例如,缓存在REST中更有效,错误处理和GraphQL特定资源增加了复杂性,速率限制也更难实现。
GraphQL的一些功能也可以由REST完成,但需要使用字段和库进行一些额外的工作。
GraphQL的典型用例是带宽非常低的架构,或者需要快速和精确的响应,只接收所要求的数据。使用GraphQL的另一个很好的理由是,当你需要结合多个数据源时,例如其他API终端和数据库。
gRPC
gRPC是一个开源的、高性能的远程过程调用(RPC)框架,最初于2015年在谷歌开发,被广泛用于微服务基础设施。它使用HTTP/2应用协议进行传输,性能是REST的25倍。
你可以通过gRPC获得四种类型的API:
- 单一(类似于REST的请求和响应方式)
- 服务器流
- 客户流
- 双向流
在HTTP/1.1中,你的每个请求都会打开一个新的TCP连接。HTTP/2允许的多路复用是能够在同一个TCP连接上发出多个请求。它在你的系统中提供了一个较低的资源消耗的通信解决方案。gRPC利用的HTTP/2功能的其他亮点:服务器推送、头压缩和二进制数据格式。
gRPC在请求中发送的数据被转换为二进制。这导致在你的微服务之间发送更小尺寸的数据。机器可以理解二进制,因此它在机器层面的工作成本较低(资源方面)。
与REST和GraphQL一样,gRPC与语言无关:Java微服务可以与Python微服务通信,然后与Go微服务通信,后者可以与Node.js微服务通信,等等
。协议缓冲区解决了大型扩展系统上不断变化的数据结构。随着越来越多的微服务被添加到系统中,数据将不断发展,一些系统可能变得无法维护。
协议缓冲区为不断发展的微服务式架构中使用的数据结构提供了可靠性。
协议缓冲区也是强类型的,这导致了数据的接口更加一致。协议缓冲区旨在帮助实现向前和向后的兼容性。服务可以定义他们想如何接收数据和什么格式,而想与该服务接触的服务必须坚持所需的格式。
优点和缺点
使用gRPC API的优点:
- 语言无关:你可以用几乎所有用于创建微服务的流行语言编写gRPC API。
- 使用协议缓冲区并将数据序列化为二进制数据,因此在网络上传输的数据更小(与基于文本的消息系统相比)。
- 强类型的数据结构,导致服务之间的通信结构更稳定。
- 旨在帮助其在服务中的实现向前和向后兼容。
使用gRPC的缺点:
- 学习曲线可能很陡峭。你需要学习协议缓冲区和gRPC。
- 因为所有的数据都被转换为二进制格式,所以可能更难调试。
- 你必须使用生成器来生成你的gRPC代码。
单元(请求和响应)gRPC API
协议缓冲区的例子:
syntax = "proto3";
package heroes;
option go_package=" 。/heroes/heroespb";
message Friend {
string name = 1;
}
message Hero {
string name = 1;
repeat Friend friends = 2;
}
message HeroRequest {
message HeroResponse {
Hero hero = 1;
service HeroService{
rpc Hero(HeroRequest) returns (HeroResponse) {};
Server example in Go:
:"package mainimport ("context""fmt""log""net""github.com/cariza/grpc-example/eroes/eroespb""google.golang.org/grpc"
)type server struct {
}func (*server) Hero(ctx context.Context, req *heroespb.HeroRequest) ( *heroespb.HeroResponse, error) {fmt.Printf("Requesting hero data")res := &heroespb.HeroResponse{Hero: &heroespb.Hero{Name:"R2-D2",朋友:[]*heroespb.Friend{{Name: "天行者"}:"Luke Skywalker"},{Name:"汉-索罗"},{名字:"莱娅-奥加纳"}, {名字
汉-索罗}"Leia Organa"},},},}return res, nil
}func main() {lis, err := net.Listen("tcp", "0.0.0.0:50051")if err != nil {log.Fatalf("Failed to listen: %v", err)}s := grpc.NewServer()heroespb.RegisterHeroServiceServer(s, &server{})if err := s.Serve(lis); err != nil{log.Fatalf("Failed to server: %v", err)}
Go中的客户端例子:
package main
import (
"context"
"log"
"github.com/cariza/grpc-example/eroes/eroespb"
"google.golang.org/grpc"
)
func main() {
cc, err := grpc.Dial("localhost:50051", grpc.WithInsecure()
if err != nil {
log.Fatalf(" Could not connect: %v", err)
}
defer cc.Close()
c := heroespb.NewHeroServiceClient(cc)
doUnary(c)
}
func doUnary(c heroespb.HeroServiceClient) {
req := &heroespb.HeroRequest{}
res, err := c.Hero(context.background(), req)
if err != nil {
log.Fatalf("Error while calling Greet RPC: %v", err)
}
log.Printf("Response from Greet: %v", res.Hero)
(如果你在手机上查看这篇博文,你可以下载 以下表格的PDF格式 ,以便于阅读。)

消息传递
REST和RPC在处理大量数据和高吞吐量时并不出色,这就是消息传递的作用。
通过异步消息进行通信的服务通常在内部使用消息代理,如RabbitMQ或Apache Kafka。经纪人允许服务和消息缓冲之间更松散的耦合,但他们也可能成为性能瓶颈和单点故障。
使用多个队列和分片可以帮助避免这种情况。
另一个选择是无代理通信(如ZeroMQ),每个服务直接与其他服务对话。虽然不需要管理经纪商更简单,但无经纪商要求两个服务同时可用,并有一种服务发现机制(因为服务不与经纪商提供的单点对话)。
消息可以只是文本,对其他服务的命令,或事件。根据微服务,这些都是关于服务应该如何反应的指令。
Apache Kafka 是一个流式平台,旨在实现大量的数据和高吞吐量,同时将消息存储很长一段时间。这对于重新发送事件或分析流媒体是非常好的,无论是历史的还是实时的,当需要为审计目的保留数据时,也是一个不错的选择。
最初的用例是用于跟踪网站活动,如页面浏览、搜索、上传或其他用户互动。Apache Kafka只支持1:n通信,但这可以通过只让一个服务订阅一个主题(相当于消息队列的一部分)来适应1:1。
RabbitMQ 是一个开源的消息代理,它与AMQP、MQTT或STOMP等不同协议一起工作,提供了一种创建用于发送和接收消息的队列的简单方法。
RabbitMQ很容易与不同的编程语言一起使用,例如,Java和许多其他JVM语言、.
NET、Ruby、Python、JavaScript/Node。在启动 RabbitMQ 服务器后,Python 中
的这些代码片段可让您从一个进程向另一个进程发送消息:
send.py
#!/usr/bin/env python3
import pikaconnection = pika.。
blockingConnection(pika.ConnectionParameters(host="localhost"))channel = connection.channel ()channel.queue_declare(queue="hello")channel.basic_publish(change="", routing_key="hello", body="Hello World!")print(" [x] Sent 'Hello World!'")connection.close()receive.py
#! /usr/bin/env python3import pika
connection = pika.BlockingConnection(pika.ConnectionParameters(host="localhost")channel = connection.annel()channel。queue_declare(queue="hello")print(" [*] Waiting for messages. To exit press Ctrl+C")def callback(ch, method, properties, body): print(" [x] Received %r" % body)channel.basic_consume(queue="hello", on_message_callback=callback)channel.start_consuming()除了简单的 1:1 队列(其中一个生产者服务通过队列将消息传递给消费者服务)外,RabbitMQ 还支持更高级的模式,包括复杂的 RPC 仿真或主题,其中消息是根据模式接收的。这些模式使 RabbitMQ 特别适合于更复杂的路由用例,而 Kafka 在没有额外工作的情况下不会给你这些。通常情况下,消息传递被视为一种 "火力全开 "的通信类型,但在您需要回复或确认的用例中,您很可能需要添加自定义逻辑来处理,从而使其更加复杂。
常见的用例是网络商店的订单处理,或者只是简单的通信,其中消息顺序和保留并不重要。RabbitMQ还允许通过特定的队列来确定消息的优先级,而Kafka事件则按照接收的顺序到达。
结论
哪种IPC适合特定的微服务组,取决于服务需要如何交互,传输什么样的消息,它们有多大,当然,这些微服务中使用的语言支持哪些SDK。
在面向公众的服务和内部服务之间选择通信类型,往往归结为可用性与速度。另一个因素是学习曲线;有时为了节省时间,从团队中每个人都能接受的东西开始,效果会更好。
本文所讨论的每一种机制都有其优势,至少可以部分地被其他机制所模仿,但对于他们自己的用例来说,表现得最好。
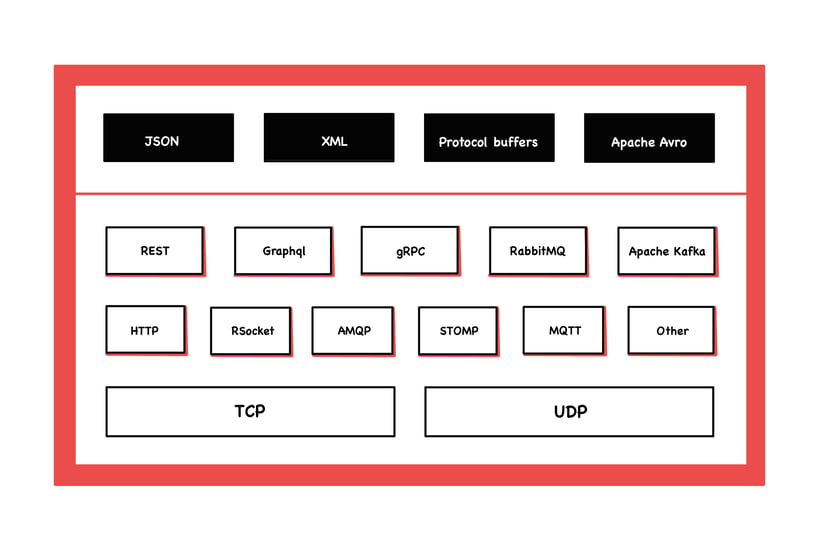
第一行显示了消息的不同序列化格式,从人类可读到二进制。下面几行显示了有哪些通信类型,以及它们是基于什么应用和传输协议的。
为一个给定的架构选择正确的IPC并不是一件小事。希望你现在对何时使用哪一种有了更好的理解。



















 4995
4995

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









