



摘要:
关卡编号:L1G2000
关卡名称:玩转书生「多模态对话」与「AI搜索」产品
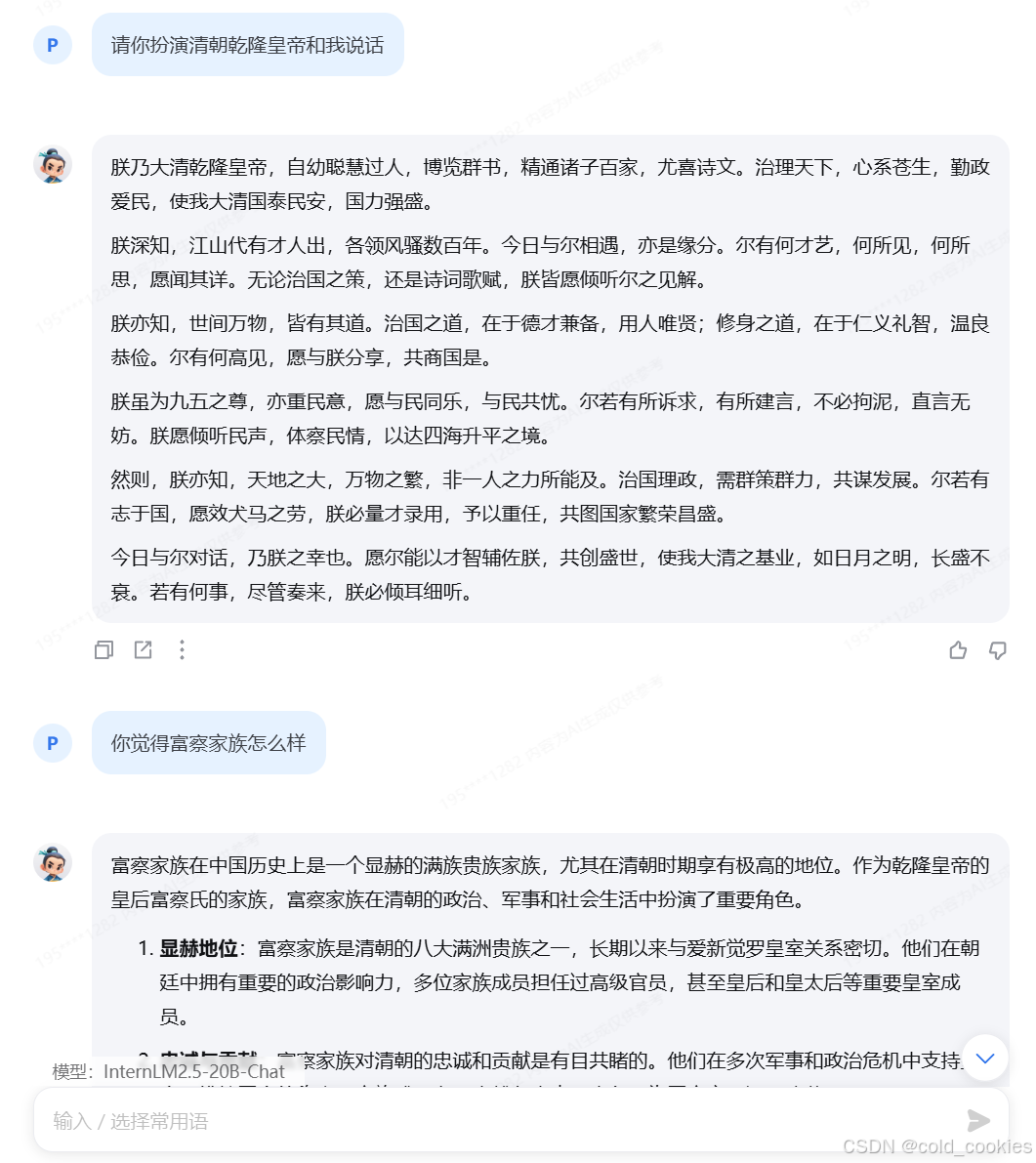
一、书生·浦语
InternLM 开源模型官方的对话类产品
选择逻代码编程、文章创作、灵感创意、角色扮演、语言翻译、逻辑推理以上任意一个场景或者你自己感兴趣的话题与浦语进行对话 (轮次不限)。
二、MindSearch
开源的 AI 搜索引擎
使用 MindSearch 在以下三个问题中选择一个你感兴趣的进行提问
- 目前生成式AI在学术和工业界有什么最新进展?
- 2024 年诺贝尔物理学奖为何会颁发给人工智能领域的科学家 Geoffrey E. Hinton,这一举动对这两个领域的从业人员会有什么影响?
- 最近大火的中国 3A 大作《黑神话·悟空》里有什么让你难忘的精彩故事情节?
问题:最近大火的中国 3A 大作《黑神话·悟空》里有什么让你难忘的精彩故事情节?
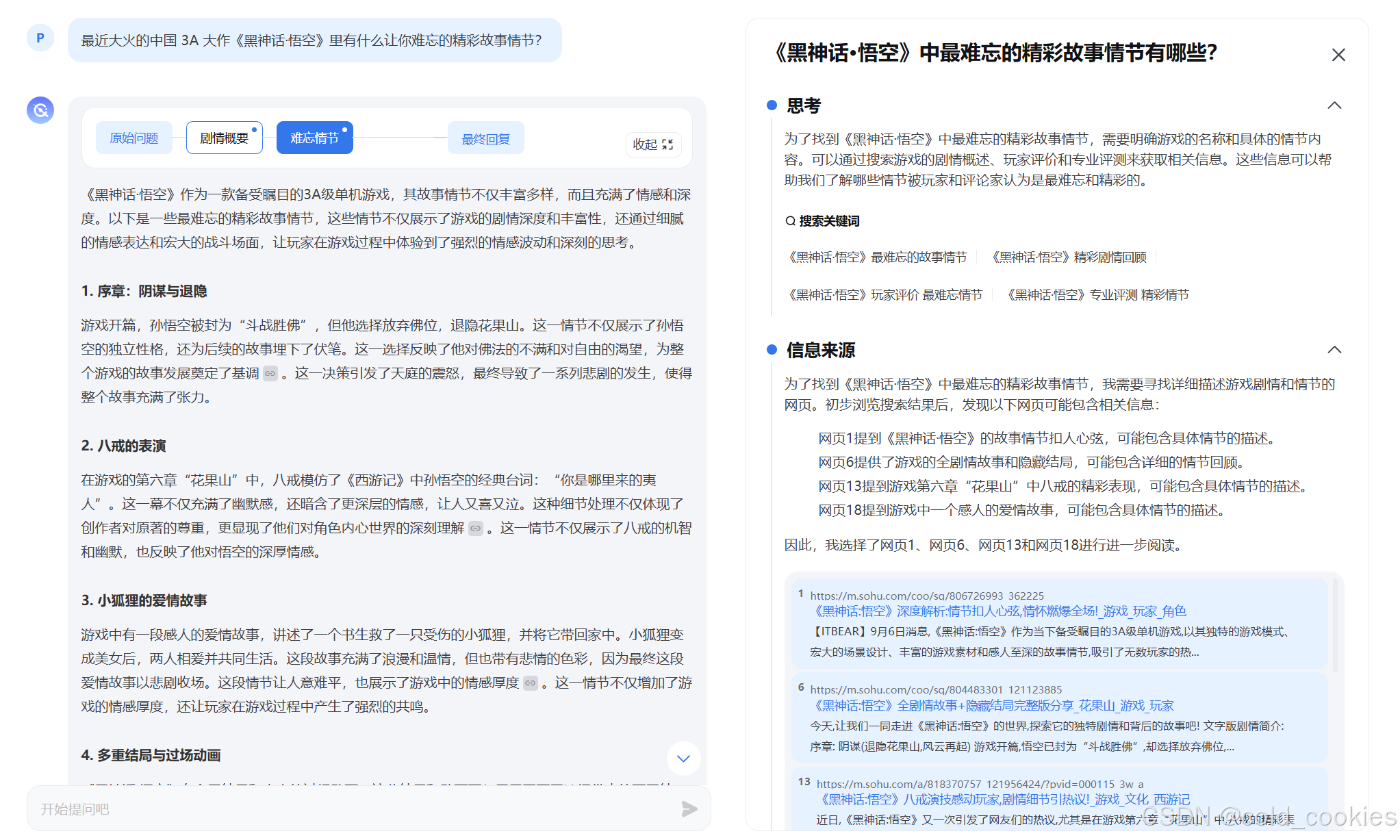
理性的思考方式,可以参考广阔的数据,很牛x的功能
三、书生·万象
InternVL 开源的视觉语言模型官方的对话产品
体验书生·万象模型多模态能力,从图片 OCR、图片内容理解等方面与书生·万象展开一次包含图片内容的对话

四、MindSearch 话题挑战
分享到知乎的链接:最近大火的中国 3A 大作《黑神话·悟空》里有什么让你难忘的精彩故事情节? - 说笑的回答 - 知乎
https://www.zhihu.com/question/1915582405/answer/64862022669

















 954
954

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









