




目录
- Index API
- 1、创建索引
- 2、获取索引
- 3、更新索引
- 4、删除索引
- 5、判断索引是否存在
- 6、索引别名
- 7、打开/关闭索引(_open/_close)
- 8、收缩/拆分索引(_shrink/_split)
- 9、清理索引缓存(_cache/clear)
- 10、刷新索引(_refresh、_flush)
- 11、强制合并(_forcemerge)
- 12、冻结/解冻索引(_freeze/_unfreeze)
- 13、索引克隆(_clone)
- 14、索引统计(_stats)
- 15、索引分片(_segments)
- 16、索引恢复(_recovery)
- 17、索引分片存储(_shard_stores)
- 18、索引映射
- 19、索引模板(_template)
- 20、索引设置(_setting)
- 21、滚动索引(_rollover)
Index API
索引API是用于管理单个索引、索引设置、别名、映射和索引模 板等功能的接口。
1、创建索引
创 建 索 引 API 用 于 在 Elasticsearch 中 手 动 创 建 索 引 。 Elasticsearch中的所有文档都存储在某一个索引中。
//语法
PUT /<index>
最基本的形式如下:
PUT twitter
它创建了名为twitter的索引,搜索设置都采用默认值。索引名称 有一些限制,原则是尽可能采用全小写的英文。限制如下:
- 仅小写字母
- 不能包括
\、/、*、?、"、<、>、|、``(空格字符)、,、 #等 - 7.0版之前的索引可能包含冒号(
:),但已弃用,7.0版中 不支持它 - 不能以
-、_、+开头 - 不能是
.或.. - 不能长于255字节(请注意,它是字节数,因此多字节字符 将更快计数到255限制)
1.1、索引设置
创建的每个索引都可以具有与之关联的特定设置,这些设置在正 文中定义,示例如下:
PUT twitter
{
"settings": {
"number_of_shards": 3,
"number_of_replicas": 2
}
}
1.2、映射
映射(mapping)的功能是完成字段的定义,包括数据类型、存 储属性、分析器等。示例如下:
PUT twitter
{
"settings": {
"number_of_shards": 3,
"number_of_replicas": 2
},
"mappings": {
"properties": {
"field1": {
"type": "text"
}
}
}
}
2、获取索引
获取一个或多个索引信息:
//语法
GET /<index>
示例:
//获取单个索引
GET /twitter
//获取多个索引
GET /twitter,twitter2
//匹配
GET /twitter*
//获取所有索引
GET /_all
返回:
{
"bank" : {
"aliases" : { },
"mappings" : {
"properties" : {
"account_number" : {
"type" : "long"
},
"address" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"age" : {
"type" : "long"
},
"balance" : {
"type" : "long"
},
"city" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"email" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"employer" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"firstname" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"gender" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"lastname" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"state" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
}
}
},
"settings" : {
"index" : {
"routing" : {
"allocation" : {
"include" : {
"_tier_preference" : "data_content"
}
}
},
"number_of_shards" : "1",
"provided_name" : "bank",
"creation_date" : "1697003938876",
"number_of_replicas" : "1",
"uuid" : "1Ny9g32eTSutDG8gfLzQZg",
"version" : {
"created" : "7160099"
}
}
}
}
}
3、更新索引
//语法
PUT /<index>/_settings
示例:
PUT /twitter/_settings
{
"index" : {
"number_of_replicas" : 2
}
}
4、删除索引
删除索引非常简单,但同时也会把索引数据一起删除,不可恢 复。
//语法
DELETE /<index>
示例:
//删除单个索引
DELETE /twitter
//删除多个索引
DELETE /twitter,twitter2
//匹配
DELETE /twitter*
//删除所有索引
DELETE /_all
5、判断索引是否存在
顾名思义,就是判断一个索引是否已存在。
//语法
HEAD /<index>
示例:
HEAD test
返回:
200 - OK
6、索引别名
别名就是索引另外的名称,可以用来实现跨索引查询、无缝切换 等功能。每个索引可以有若干的别名,不同的索引也可以使用相同的别名。
6.1、创建索引别名
//语法
PUT /<index>/_alias/<alias>
POST /<index>/_alias/<alias>
PUT /<index>/_aliases/<alias>
POST /<index>/_aliases/<alias>
查询参数:
master_timeout: (可选,时间单位)连接到主节点的等待超时时间。如果在超时时间已过之前没有响应, 则返回错误。 默认是值 30s。timeout: (可选,时间单位) 等待超时时间。如果在超时时间已过之前没有响应, 则返回错误。 默认是值 30s。
Request Body:
filter:(Required, query object) . 筛选查询(Filter query) 用来限制索引别名, 使用该别名时只返回符合过滤条件的文档。(这个应该是有body的时候才是必填的, 没有body就不用填写了)routing: (Optional, string) 用于将操作路由到特定分片的自定义路由。
6.1.1、基于时间(time-based)的别名
比如给索引logs_20302801创建一个别名2030:
PUT /logs_20302801/_alias/2030
6.1.2、基于用户(user-based)的别名
创建索引users, 它有一个字段user_id, 然后给个别名user_12, 限制user_id=12的文档:
PUT /users
{
"mappings": {
"properties": {
"user_id":{"type": "integer"}
}
}
}
# 插入几个文档
POST /users/_doc/10
{
"user_id": 10
}
POST /users/_doc/11
{
"user_id": 11
}
POST /users/_doc/12
{
"user_id": 12
}
# 查询, 能看到所有的文档
GET /users/_search
# 给个别名`user_12`, 限制user_id=12的文档:
PUT /users/_alias/user_12
{
"routing": "12",
"filter":{
"term":{
"user_id": 12
}
}
}
# 查询别名, 只能看到 user_id=12的文档
GET /user_12/_search
6.1.3、创建索引时添加别名
建立索引 logs_20302801, 同时添加别名 2030、current_day
PUT /logs_20302801
{
"mappings" : {
"properties" : {
"year" : {"type" : "integer"}
}
},
"aliases" : {
"current_day" : {},
"2030" : {
"filter" : {
"term" : {"year" : 2030 }
}
}
}
}
6.2、删除索引别名
//语法
DELETE /<index>/_alias/<alias>
DELETE /<index>/_aliases/<alias>
路径参数:
<index>:
支持多个索引以英文逗号分割, 支持通配符表达式。要匹配所有索引,可以使用 _all 或者 *。
//删除多个索引的别名
DELETE /twitter,users,orders/_alias/<alias>
//删除所有索引的别名 ---这个比较危险, 请勿随意测试
DELETE /_all/_alias/<alias>
DELETE /*/_alias/<alias>
<alias>:
支持多个索引以英文逗号分割, 支持通配符表达式。要匹配所有索引别名,可以使用 _all 或者 *。
//删除指定索引的多个别名
DELETE /<index>/_alias/alias1,alias2,alias3
//按通配符删除指定索引的别名
DELETE /<index>/_alias/ab*
//删除指定索引的所有别名
DELETE /<index>/_alias/*
查询参数:
master_timeout: (可选,时间单位)连接到主节点的等待超时时间。如果在超时时间已过之前没有响应, 则返回错误。 默认是值 30s。timeout: (可选,时间单位) 等待超时时间。如果在超时时间已过之前没有响应, 则返回错误。 默认是值 30s。
示例:删除twitter索引的alias1别名
DELETE /twitter/_alias/alias1
6.3、获取索引别名
//语法
GET /_alias
GET /_alias/<alias>
GET /<index>/_alias/<alias>
路径参数:
<index>:支持多个索引以英文逗号分割, 支持通配符表达式。要匹配所有索引别名,可以使用 _all 或者 *。<index>:支持多个索引以英文逗号分割,支持通配符表达式。
查询参数:
allow_no_indices:默认true。如果设置为true, 则当全部使用通配符*、_all只检索不存在(missing)或者已关闭(closed)的索引时,不会抛出错误。
这个是和参数 expand_wildcards 一起使用时的描述。如果只用通配符去检索expand_wildcards=all的别名, 则无论如何不会抛出错误。但是这里的missing条件怎么理解呢 ??
//只是通配符检索别名: 不存在user2开头的别名, 不会报错(返回状态200, 空json)
GET /_alias/user2*?allow_no_indices=false
//检索不存在的user2, 以及user2开头的别名时, 一定会报错(404 + 错误信息json)
GET /_alias/user2?allow_no_indices=true
GET /_alias/user2,user2*?allow_no_indices=true
//会报错 - 这个才是符合描述的(条件 expand_wildcards=closed)
GET /_alias/user2*?allow_no_indices=false&expand_wildcards=closed
expand_wildcards:通配符查询时的范围限制. 支持多个条件的逗号分割.all:默认, 匹配open和closed的索引, 包括隐藏的.open:表示只查询开放中的索引closed:只匹配closed的hidden:隐藏的(hidden)索引, 必须和open/closed联合使用.none:不接受通配符.
ignore_unavailable: (可选, bool) 如果有索引不存在时是否忽略。默认false,就是返回404并抛出错误信息。查询时只要有一个索引不存在,则都抛出错误。local:是否仅从本地节点获取信息,默认false, 表示从master节点获取信息。如果设置为true, 则表示只从本地节点获取.
6.3.1、获取当前集群下的所有别名
返回所有索引, 无别名的显示空json:
GET /_alias
GET /_all/_alias
GET /*/_alias
6.3.2、获取所有索引中有指定别名的
多个别名以英文逗号分割。
只要有一个别名不存在时抛出错误, 返回404状态, 以及能匹配到的部分索引
比如: 存在别名 user_12 和 2030, 不存在别名user_13
GET /_alias/user_13
返回:
{
"error" : "alias [user_13] missing",
"status" : 404
}
GET /_alias/user_12,user_13,2030
返回:
{
"error" : "alias [user_13] missing",
"status" : 404,
"logs_20302801" : {
"aliases" : {
"2030" : {
"filter" : {
"term" : {
"year" : 2030
}
}
}
}
},
"users" : {
"aliases" : {
"user_12" : {
"filter" : {
"term" : {
"user_id" : 12
}
},
"index_routing" : "12",
"search_routing" : "12"
}
}
}
}
6.3.3、通配符匹配指定的索引别名
没有数据时返回空json
//查询所有索引的所有以ab开头的别名
GET /_alias/ab*
//查询索引user的所有别名
GET /users/_alias/*
//查询索引user的所有以ab开头的别名
GET /users/_alias/ab*
6.4、检查索引别名是否存在
检查一个或多个索引别名是否存在
//语法
HEAD /_alias/<alias>
HEAD /<index>/_alias/<alias>
路径参数:
同上…
查询参数:
同上…
示例:
HEAD /_alias/2030
HEAD /_alias/20*
HEAD /logs_20302801/_alias/*
HEAD /_alias/alias1
返回:
{"statusCode":404,"error":"Not Found","message":"404 - Not Found"}
HEAD /_alias/user_12
返回:
200 - OK
6.5、更新索引别名
添加或删除索引别名。
//语法
POST /_aliases
查询参数:
同上…
Request body:
actions: (必填, json数组对象) 要执行的一系列操作, 可用的action(json的key)包括:add给索引添加一个别名remove从指定的索引移除一个别名remove_index删除一个索引或索引别名, 类似删除索引api- 这些action的属性可以为空. 可用的属性包括:
index:带通配符的表达式. 当参数indices没有指定时必填.indices:索引名称数组. 当参数index没有指定时必填.alias:逗号分割的多个别名, 或通配符表达式. 当参数aliases没有指定时必填.aliases:索引别名的数组. 当参数alias没有指定时必填.filter:使用Filter query过滤别名.is_hidden:如果设置为true, 默认将从通配符表达式中排除别名,除非在请求中使用expand_wildcards参数重写别名,类似于hidden indices。对于共享一个别名的素有索引来说, 这个属性必须设置成相同的值。默认是false。is_write_index:如果为true,则将此索引指定为该别名下的写索引。 默认值为false。一个别名同时只能存在一个写索引。routing:用于将操作路由到特定分片的自定义路由值。index_routing:用于别名索引操作的自定义路由值。search_routing:用于别名搜索操作的自定义路由值。
6.5.1、添加别名
POST /_aliases
{
"actions":[
{
"add":{
"index": "my_index",
"alias": "my_index_alias1"
}
}
]
}
6.5.2、移除别名
POST /_aliases
{
"actions":[
{
"remove":{
"index": "my_index",
"alias": "my_index_alias1"
}
}
]
}
6.5.3、重命名别名
Rename = Remove + Add
重命名实际上是两个操作: 先删除, 后添加, 可以一起操作. 而且这是一个原子操作, 不会出现短时间内别名无法使用的情况
# 别名重命名: 删除 + 添加
POST /_aliases
{
"actions":[
{
"remove":{
"index": "my_index",
"alias": "my_index_alias1"
}
},
{
"add":{
"index": "my_index",
"alias": "my_index_alias_1"
}
}
]
}
6.5.4、同时给多个索引添加别名
同时给多个索引添加不同的别名:
//同时给多个索引添加不同的别名(这个写法也支持添加相同的别名)
POST /_aliases
{
"actions":[
{
"add": {
"index": "my_index",
"alias": "my_index_alias1"
}
},
{
"add":{
"index": "my_index2",
"alias": "my_index2_alias1"
}
}
]
}
同时给多个索引添加相同的别名:
//同时给多个索引添加相同的别名
POST /_aliases
{
"actions":[
{
"add":{
"index": "my_index",
"alias": "alias1"
}
},
{
"add":{
"index": "my_index2",
"alias": "alias1"
}
}
]
}
同时给多个索引添加相同的别名时, 可以直接设置一个indices数组以取代多个add操作:
//同时给多个索引添加相同的别名, 可以使用indices数组以取代多个add操作
POST /_aliases
{
"actions":[
{
"add":{
"indices": ["test1", "test2"],
"alias": "alias1"
}
}
]
}
也可以对index使用通配符来同时给一批索引添加同一个别名:
//添加多个索引
PUT /test1
PUT /test2
PUT /test3
//查看索引
GET /test*
//批量添加别名
POST /_aliases
{
"actions":[
{
"add":{
"index": "test*",
"alias": "all_test_indices"
}
}
]
}
//查看索引, 我们会看到这三个以test开头的索引都有一个相同的别名
GET /test*
我们还可以交换(swap)一个索引和一个索引别名的名字, 而且是一个原子操作, 这不会出现短时间内别名无法使用的情况.
//我们先建了一个索引`log`, 但是这个是错误的
PUT /log
//现在建立了正确的索引`log_001`, 但是我现在想把那个索引名称`log`给这个当别名
PUT /log_001
//我们可以使用如下的原子操作, 保证服务不会中断
POST /_aliases
{
"actions":[
{
"add": {
"index": "log_001", "alias": "log"
}
},
{
"remove_index":{
"index": "log"
}
}
]
}
//查看索引/别名, 我们我们会发现别名log也指向了log_001
GET /log_001,log
6.5.5、过滤别名(Filter aliases)
带过滤器的别名提供了一种简单的创建一个索引的不同“视图”的方法。 该过滤器可以使用Query DSL定义,并应用于使用此别名的所有搜索、计数、按查询删除等操作。
我们先创建一个索引, 然后使用filter条件建立一个索引别名
//创建一个索引, 包含字段 user
PUT /test1
{
"mappings": {
"properties": {
"user":{
"type": "keyword"
}
}
}
}
//然后我们对字段user建"视图": 使用条件 user="kimchy" 的全匹配, 添加过滤别名
POST /_aliases
{
"actions":[
{
"add":{
"index": "test1",
"alias": "test1_kimchy",
"filter":{
"term":{
"user": "kimchy"
}
}
}
}
]
}
//如果我们查询索引别名test1_kimchy, 则只显示test1中 user="kimchy" 的文档
GET /test1_kimchy/_search
6.5.6、路由(Routing)
可以将路由值(routing values)与别名关联起来, 还可以与过滤别名(filter aliases)一起使用以减少不必要的分片操作.
我们给索引test建一个别名alias1, 定义这个别名的操作都自动指向路由值为"1"的分片.
POST /_aliases
{
"actions":[
{
"add":{
"index": "test",
"alias": "alias1",
"routing": "1"
}
}
]
}
也可以按操作区分搜索(searching)和索引(indexing)分别指向不同的路由:
POST /_aliases
{
"actions":[
{
"add":{
"index": "test",
"alias": "alias1",
"search_routing": "1,2",
"index_routing": "1"
}
}
]
}
上面的例子中,搜索路由包含多个用逗号分隔的值,索引路由只包含一个值。
如果使用路由别名的搜索操作也有路由参数,则使用搜索别名路由和参数中指定的路由的交集。 例如,下面的命令将使用"2"作为路由值:
GET /alias2/_search?q=user:kimchy&routing=2,3
alias2的search_routing是"1,2", 而上面的搜索命令中指定"2,3", 他们的交集是 “2”
6.5.7、写索引(Write index)
可以关联设置别名所指向的索引为写索引。 指定后,指向多个索引的别名的所有索引(index, 动词)和更新(update)请求将尝试解析到那个写索引。 每次只能为每个别名分配一个索引作为写索引。 如果没有指定写索引,并且别名引用了多个索引,则不允许写。
可以使用aliases API和创建索引API将与别名关联的索引指定为写索引。
通过别名来设置一个索引为写索引会影响在Rollover期间如何操作别名
POST /_aliases
{
"actions":[
{
"add":{
"index": "test",
"alias": "alias1",
"is_write_index": true
}
},
{
"add":{
"index": "test2",
"alias": "alias1"
}
}
]
}
这个例子中, 我们把别名alias1同时执行索引test和test2, 但是只指定索引test为写索引.
PUT /alias1/_doc/1
{
"foo": "bar"
}
然后通过别名alias1的写和索引操作将指向索引test, 上面的代码会把id=1的文档写入索引test中:
GET /test/_doc/1
要在一个别名所指向的多个索引之间交换写索引的设置, 可以利用Aliases API来执行原子交换。 交换不依赖于操作的顺序。
POST /_aliases
{
"actions":[
{
"add": {
"index": "test",
"alias": "alias1",
"is_write_index": false
}
},
{
"add": {
"index": "test2",
"alias": "alias1",
"is_write_index": true
}
}
]
}
7、打开/关闭索引(_open/_close)
允许关闭索引,稍后再打开索引。关闭索引在集群上几乎没有开 销(除了维护其元数据),并且被阻塞于读/写操作。
7.1、打开索引(_open)
//语法
POST /<index>/_open
打开一个关闭的索引:
POST /bank/_open
返回:
{
"acknowledged" : true,
"shards_acknowledged" : true
}
7.2、关闭索引(_close)
//语法
POST /<index>/_close
关闭一个索引:
POST /bank/_close
返回:
{
"acknowledged" : true,
"shards_acknowledged" : true,
"indices" : {
"bank" : {
"closed" : true
}
}
}
8、收缩/拆分索引(_shrink/_split)
在Elasticsearch集群部署的初期我们可能评估不到位,导致分配的主分片数量太少,单分片的数据量太大,导致搜索时性能下降,这时我们可以使用Elasticsearch提供的Split功能对当前的分片进行拆分,拆分到具有更多主分片的新索引。
而相反的,在数据规模比较大的集群中,可能存在一个数据量很小,但是分片数量非常庞大的索引,而分片的管理依赖于Master节点,一旦分片数量太大,将会降低集群的整体性能,故障恢复也更慢,这时候可以使用Elasticsearch提供的Shrink API降低分片数量。
8.1、拆分索引(_split)
//语法
POST /<index>/_split/<target-index>
PUT /<index>/_split/<target-index>
要完成整个Split的操作需要满足以下条件:
- 索引必须是只读的。
- 集群的状态必须是green。
- 目标索引的主分片数量必须大于源索引的主分片数量。
- 处理索引拆分的节点必须有足够的空闲磁盘空间来容纳现有索引的第二个副本。
以下API请求可以将索引设置为只读:
PUT /my_source_index/_settings
{
"settings": {
"index.blocks.write": true
}
}
如果当前索引是是一个data stream的写索引,则不允许进行索引拆分,需要对data stream进行回滚,创建一个新的写索引,才可以对当前索引进行拆分。
示例:
POST /my-index-000001/_split/split-my-index-000001
{
"settings": {
"index.number_of_shards": 2
},
"aliases": {
"my_alias":{}
}
}
index.number_of_shards指定的主分片的数量 必须是源分片数量的倍数。
索引拆分可以拆分的分片的数量由参数index.number_of_routing_shards决定,路由分片的数量指定哈希空间,该空间在内部用于以一致性哈希的形式在各个 shard 之间分发文档。 例如,将 number_of_routing_shards 设置为30(5 x 2 x 3)的具有5个分片的索引可以拆分为 以2倍 或 3倍的形式进行拆分。换句话说,可以如下拆分:
- 5→10→30(拆分依次为2和3)
- 5→15→30(拆分依次为3和2)
- 5→30(拆分6)
index.number_of_routing_shards 是一个静态配置,可以在创建索引的时候指定,也可以在关闭的索引上设置。其默认值取决于原始索引中主分片的数量,默认情况下,允许按2的倍数分割最多1024个分片。但是,必须考虑主碎片的原始数量。例如,使用5个主碎片创建的索引可以被分割为10、20、40、80、160、320,或最多640个碎片。
如果源索引只有一个主分片,那么可以被拆分成为任意数量的主分片。
索引拆分的工作过程:
- 创建一个与源索引定义一样的目标索引,并且具有更多的主分片。(注意,是创建了一个新的索引,而并不是在源索引上扩大分片)
- 将段(segment)从源索引硬链接到目标索引。(如果文件系统不支持硬链接,那么所有的段都会被复制到新的索引中,这是一个非常耗时的过程。)
- 对所有的文档进行重新散列。
- 目标索引进行Recover。
8.2、收缩索引(_shrink)
可以将现有索引收缩为具有较少主分片的新索引。目标索引中请 求的主分片数量必须是源索引中分片数量的一个因子。例如,具有8 个主分片的索引可以收缩为4个、2个或1个主分片,或者具有15个主 分片的索引可以收缩为5个、3个或1个主分片。如果索引中的分片数 量是质数,则只能收缩为单个主分片。在收缩之前,索引中每个分片 的(主或副本)副本必须存在于同一节点上。
//语法
POST /<index>/_shrink/<target-index>
PUT /<index>/_shrink/<target-index>
一个索引要能够被shrink进行缩小,需要满足以下三个条件:
- 索引是可读的
- 索引中每个分片的副本必须位于同一个节点上。(注意,“所有分片副本”不是指索引的全部分片,无论主分片还是副分片,满足任意一个就可以,分配器也不允许将主副分片分配到同一节点。所以可以是删除了所有的副本分片,也可以是把所有的副本分片全部放在同一个节点上。)
- 索引的状态必须为green
收缩索引时,首先准备一个索引:
PUT /my_source_index
PUT /my_source_index/_settings
{
"settings": {
//强制将每个碎片的副本重新定位到名为shrink_node_name的节点。有关
"index.routing.allocation.require._name": "shrink_node_name",
//禁止对此索引执行写入操作,同时仍允许对元数据进行更改(如删除索引)。
"index.blocks.write": true
}
}
收缩索引示例如下:
POST /my_source_index/_shrink/my_target_index
{
"settings": {
"index.routing.allocation.require._name": null,
"index.blocks.write": null
}
}
9、清理索引缓存(_cache/clear)
清除缓存API允许清除与一个或多个索引相关联的所有缓存和特定缓存。
//语法
POST /<index>/_cache/clear
POST /_cache/clear
默认情况下,API会清除所有缓存。可以通过设置query、fielddata或者request来显示清除特定高速缓存。
//只清理fields缓存
POST /twitter/_cache/clear?fielddata=true
//只清理query缓存
POST /twitter/_cache/clear?query=true
//只清理request缓存
POST /twitter/_cache/clear?request=true
与特定字段相关的所有高速缓存也可以通过使用逗号分隔符的相关字段列表指定fields参数来清除。
POST /twitter/_cache/clear?fields=foo,bar
清除缓存API可以通过单个调用应用于多个索引,甚至可以应用于_all索引。
POST /kimchy,elasticsearch/_cache/clear
//清理所有
POST /_cache/clear
10、刷新索引(_refresh、_flush)
Refresh 及 Flush:
乍一看,Refresh 和 Flush 操作的通用目的似乎是相同的。 两者都用于使文档在索引操作后立即可供搜索。 在 Elasticsearch 中添加新文档时,我们可以对索引调用 _refresh 或 _flush 操作,以使新文档可用于搜索。 要了解这些操作的工作方式,你必须熟悉 Lucene中的 Segments,Reopen 和 Commits。Apache Lucene 是 Elasticsearch 中的基础查询引擎。
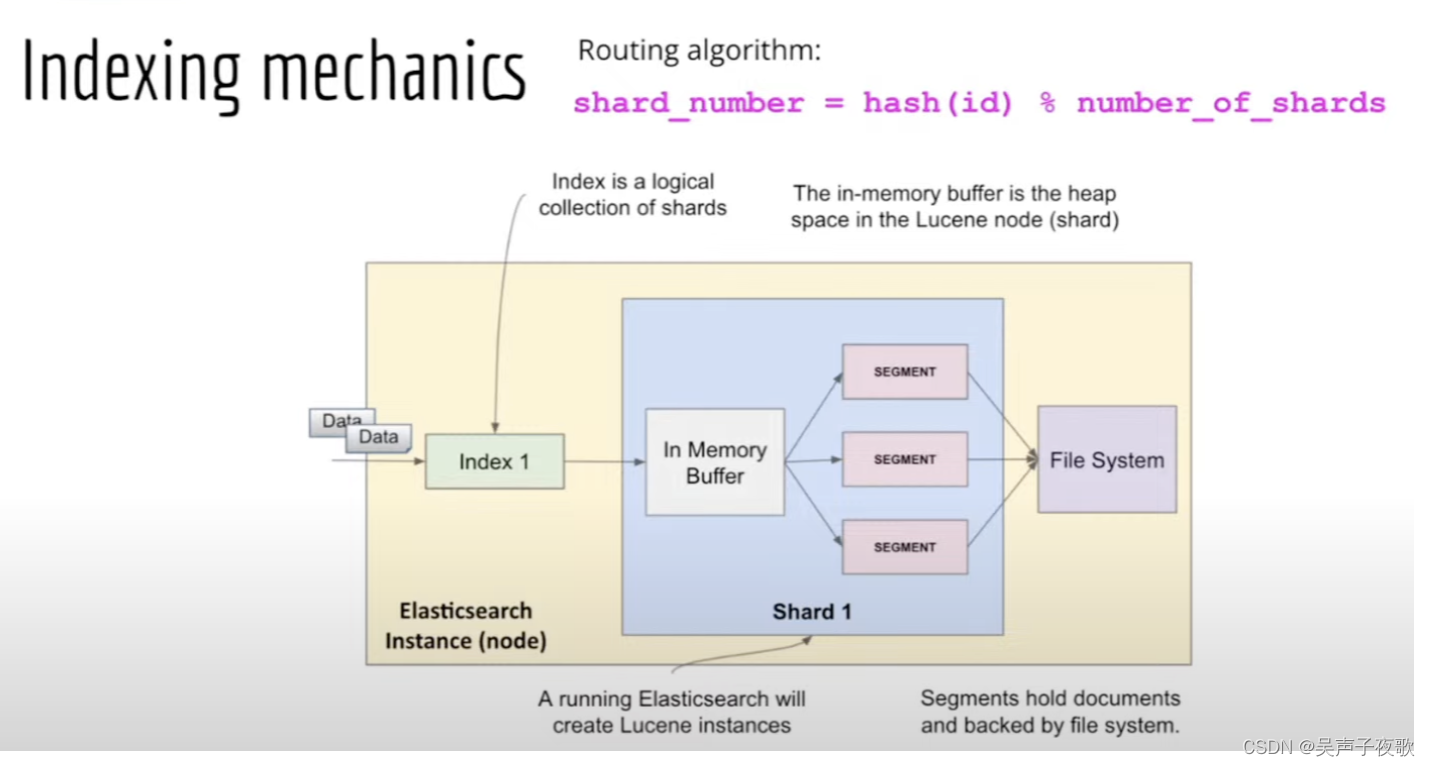
Lucene 中的 Segments:
在 Elasticsearch 中,最基本的数据存储单位是 shard。 但是,通过 Lucene 镜头看,情况会有所不同。 在这里,每个 Elasticsearch 分片都是一个 Lucene 索引 (index),每个 Lucene 索引都包含几个 Lucene segments。 一个 Segment 包含映射到文档里的所有术语(terms) 一个反向索引 (inverted index)。
下图显示了段的概念及其如何应用于 Elasticsearch 索引及其分片:
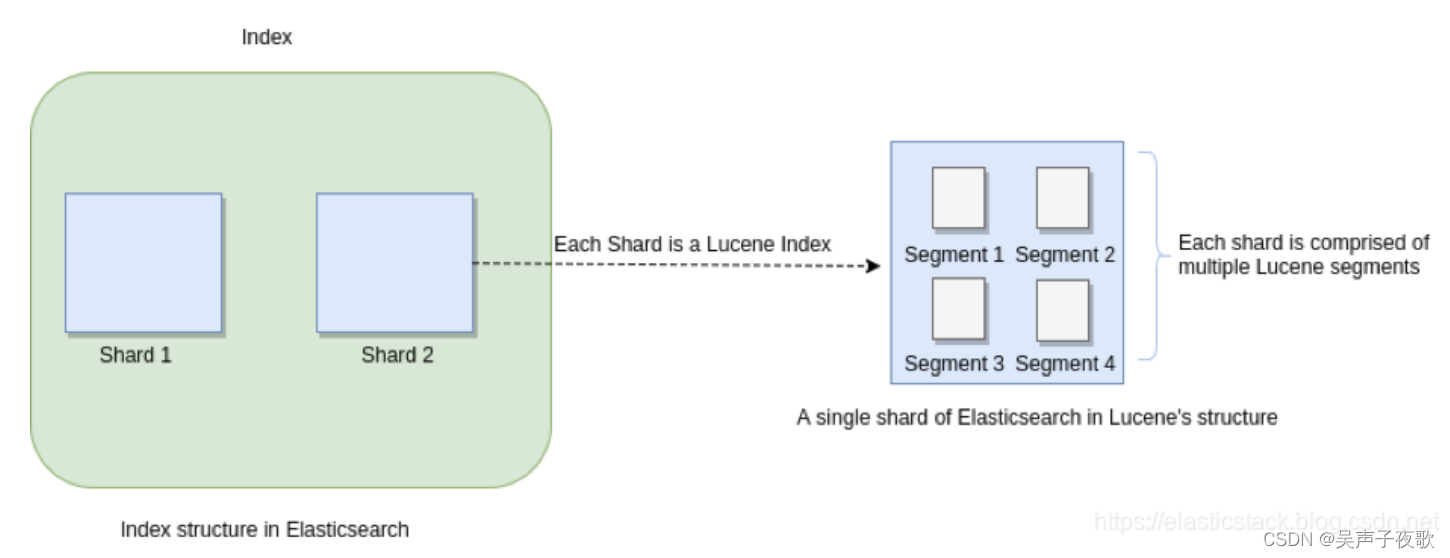
这种分 Segment 的概念是,每当创建新文档时,它们就会被写入新的 Segment 中。 每当创建新文档时,它们都属于一个新的 Segment,并且无需修改前一个 Segment。 如果必须删除文档,则在其原始 Segment 中将其标记为已删除。 这意味着它永远不会从 Segement 中物理删除。
与更新相同:文档的先前版本在上一个 Segment 中被标记为已删除,更新后的版本保留在当前 Segment 中的同一文档 ID下。
Lucene 中的 Reopen:
当调用 Lucene Reopen 时,将使累积的数据可用于搜索。 尽管可以搜索最新数据,但这不能保证数据的持久性或未将其写入磁盘。 我们可以调用 n 次重新打开功能,并使最新数据可搜索,但不能确定磁盘上是否存在数据。
Lucene 中的 Commits:
Lucene 提交使数据安全。 对于每次提交,来自不同段的数据将合并并推送到磁盘,从而使数据持久化。 尽管提交是持久保存数据的理想方法,但问题是每个提交操作都占用大量资源。 每个提交操作都有其自己的内部 I/O 操作以及与其相关的读/写周期。 这就是为什么我们希望在基于 Lucene 的系统中一次又一次地重新使用重新打开功能以使新数据可搜索的确切原因。
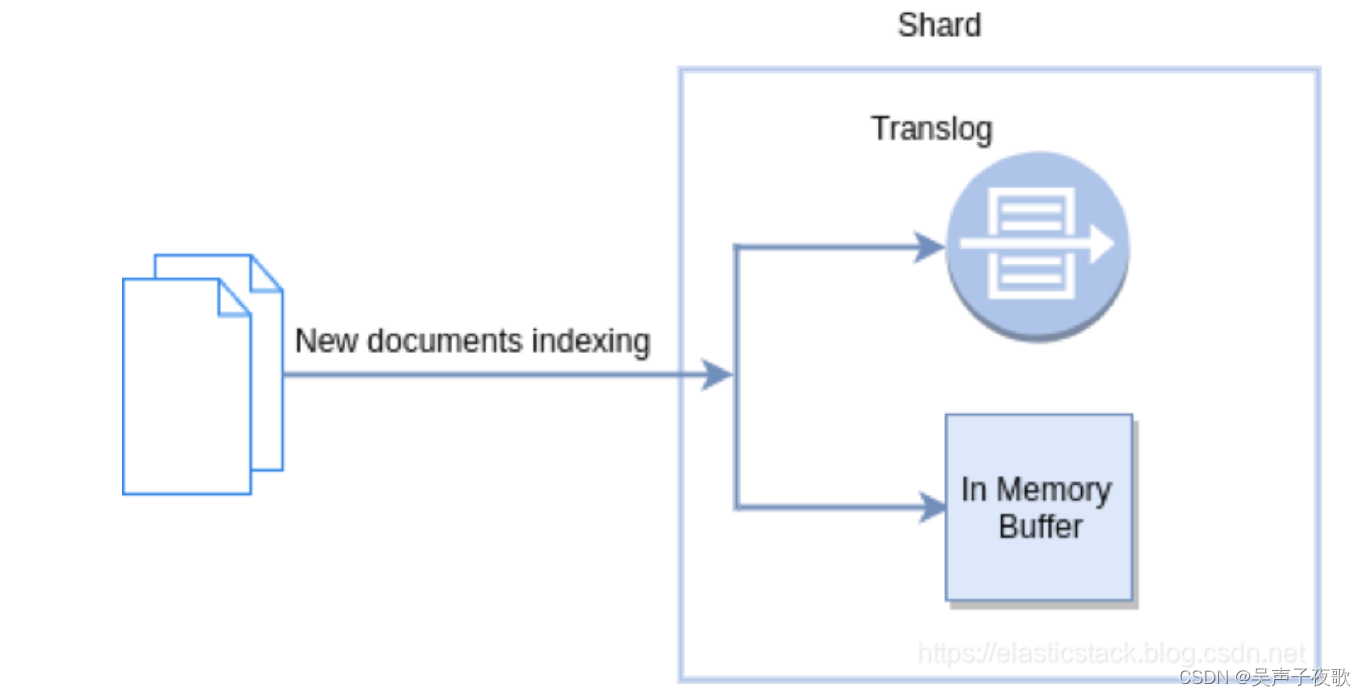
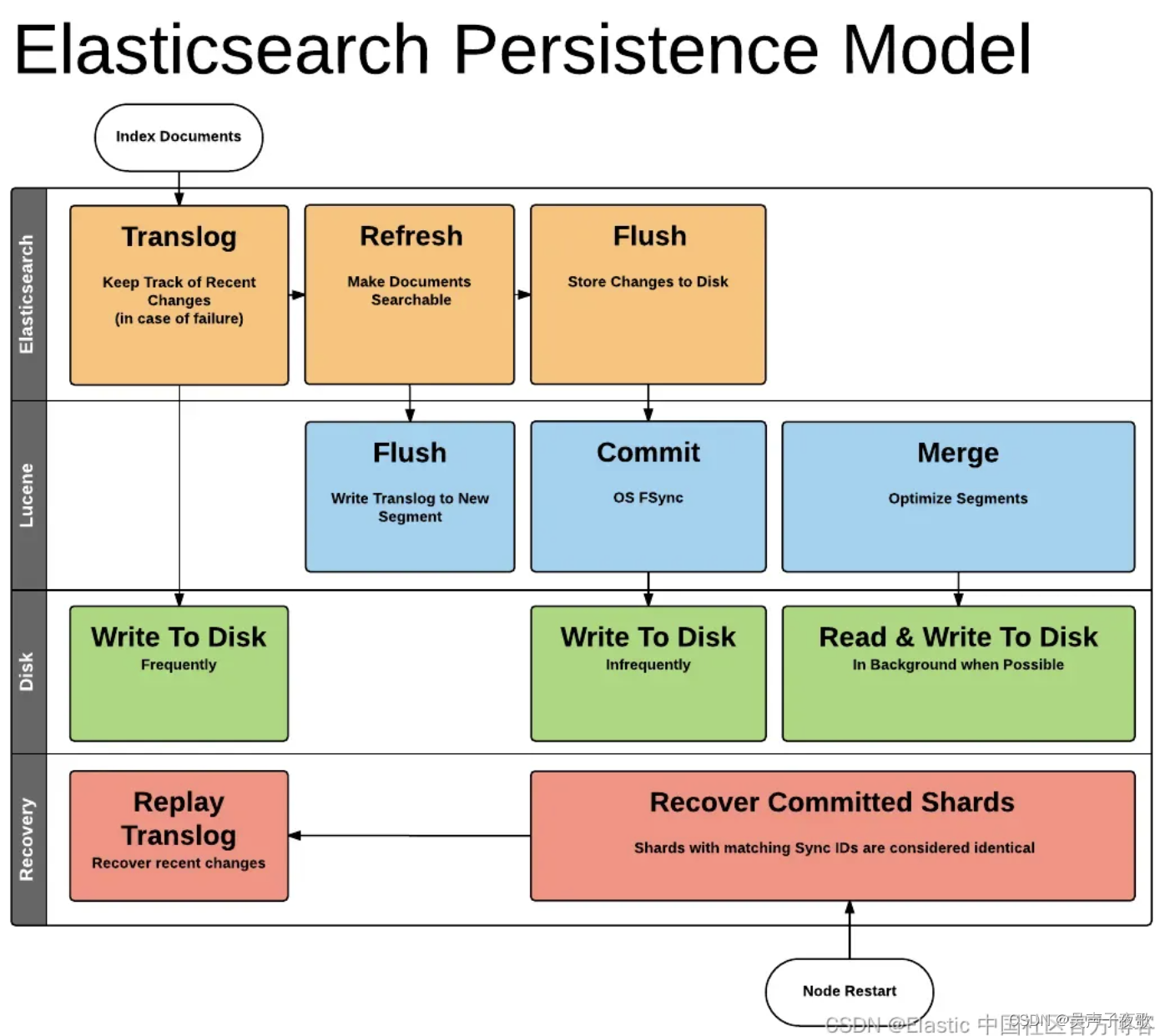
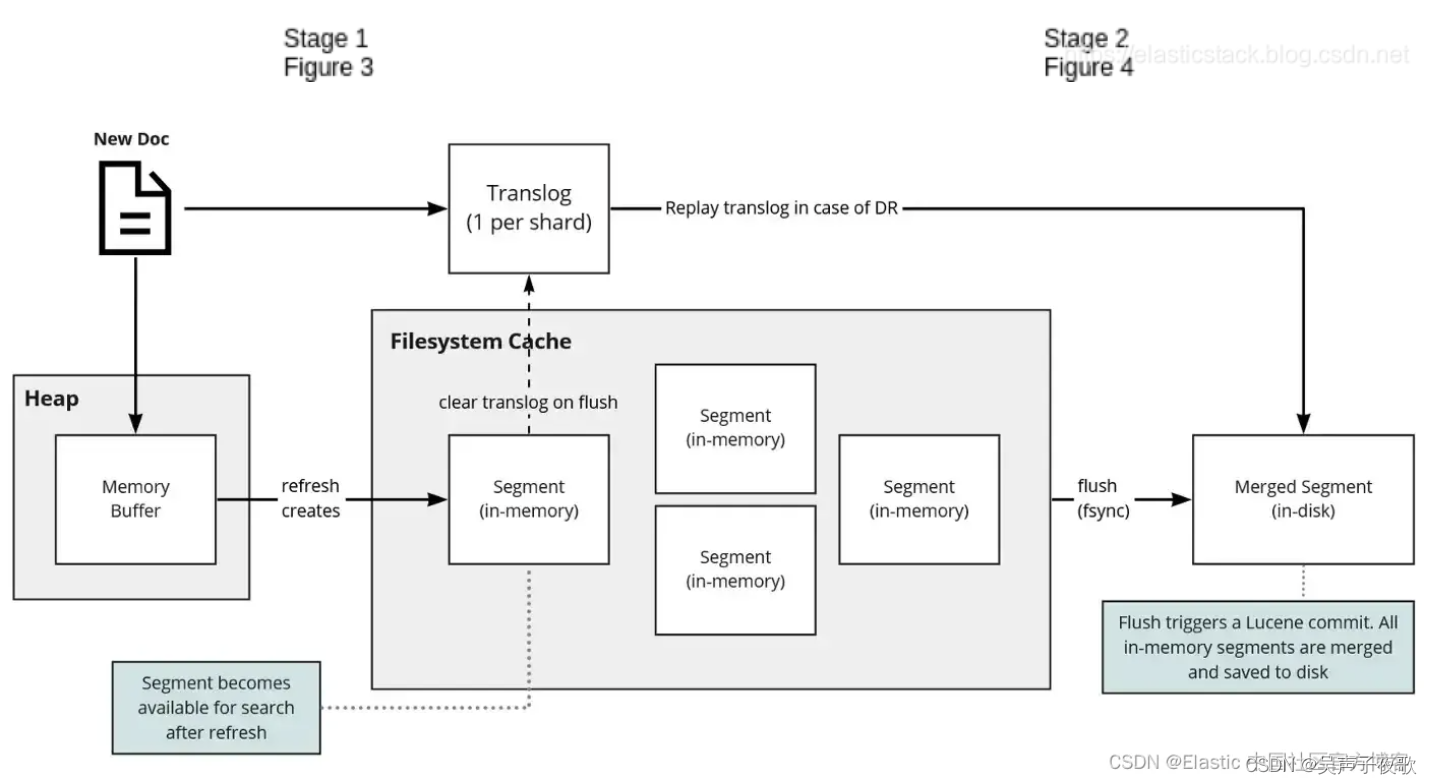
Elasticsearch 中的 Translog:
Elasticsearch 采用另一种方法来解决持久性问题。 它在每个分片中引入一个事务日志(transaction log)。 已建立索引的新文档将传递到此事务日志和内存缓冲区中。 下图显示了此过程:
Elasticsearch 中的 refresh:
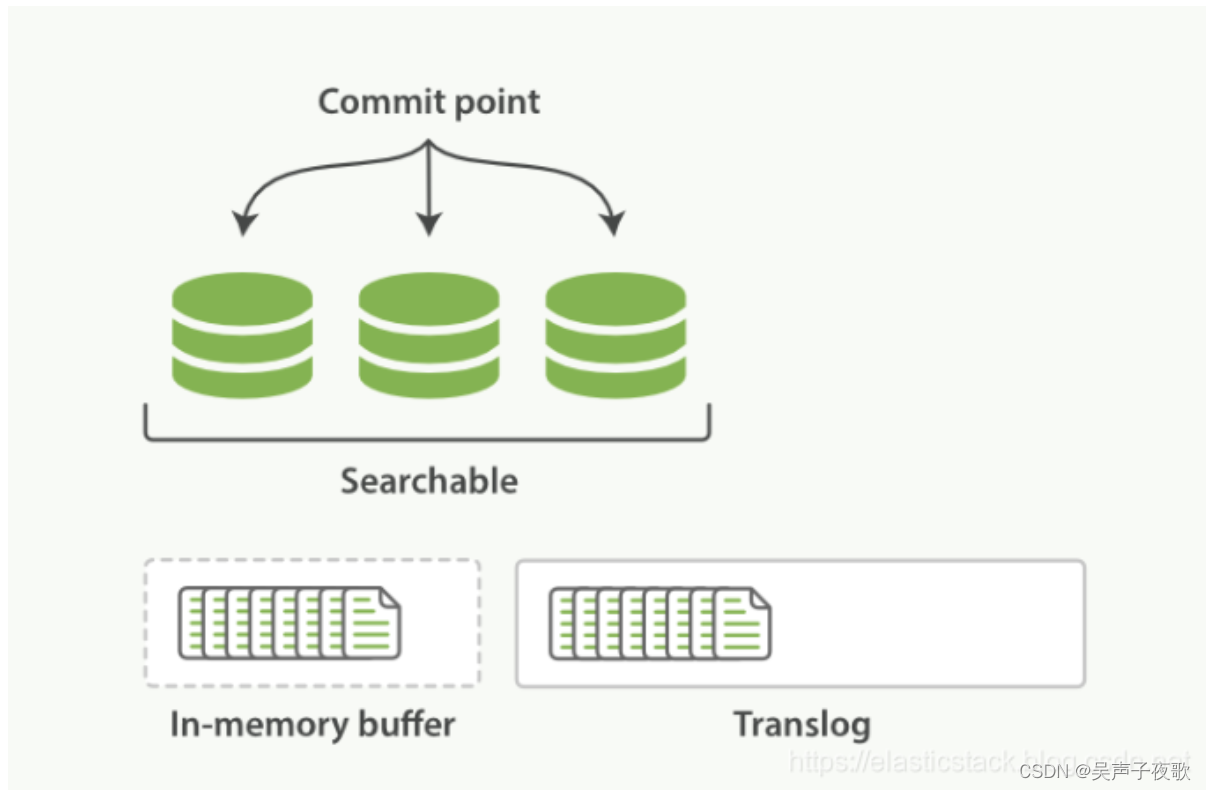
当我们把一条数据写入到 Elasticsearch 中后,它并不能马上被用于搜索。新增的索引必须写入到 Segment 后才能被搜索到,因此我们把数据写入到内存缓冲区之后并不能被搜索到。新增了一条记录时,Elasticsearch 会把数据写到 translog 和 in-memory buffer (内存缓存区)中,如下图所示:
在此期间,该文档不能被搜索,但是我们还是可以通过 ID 使用 GET 来获得该文档。如果希望该文档能立刻被搜索,需要手动调用 refresh 操作。在 Elasticsearch 中,默认情况下 _refresh 操作设置为每秒执行一次。 在此操作期间,内存中缓冲区的内容将复制到内存中新创建的 Segment 中,如下图所示。 结果,新数据可用于搜索。
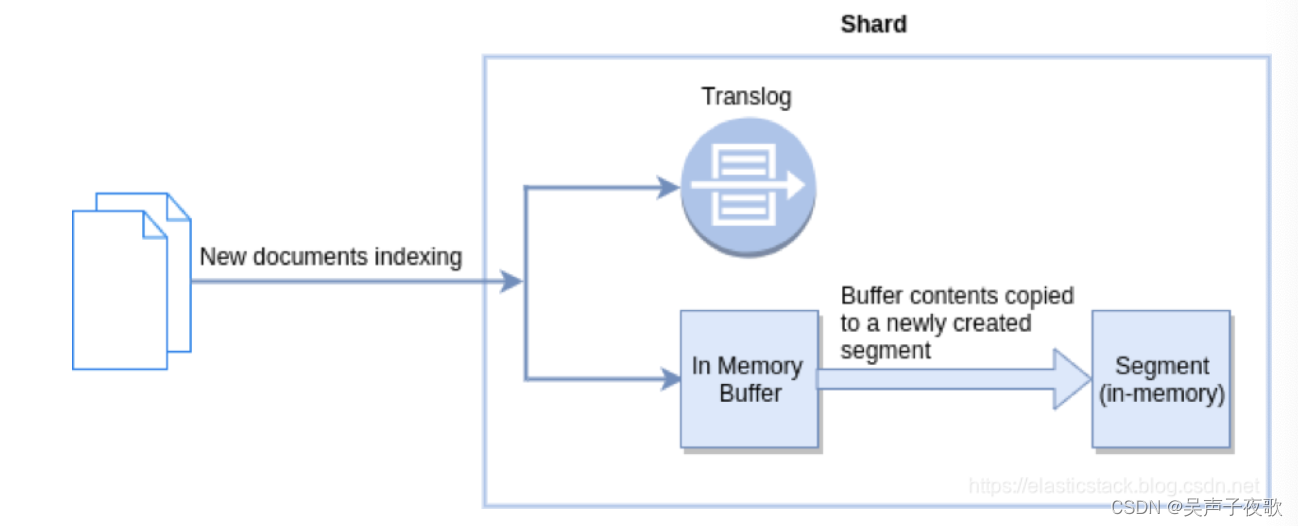
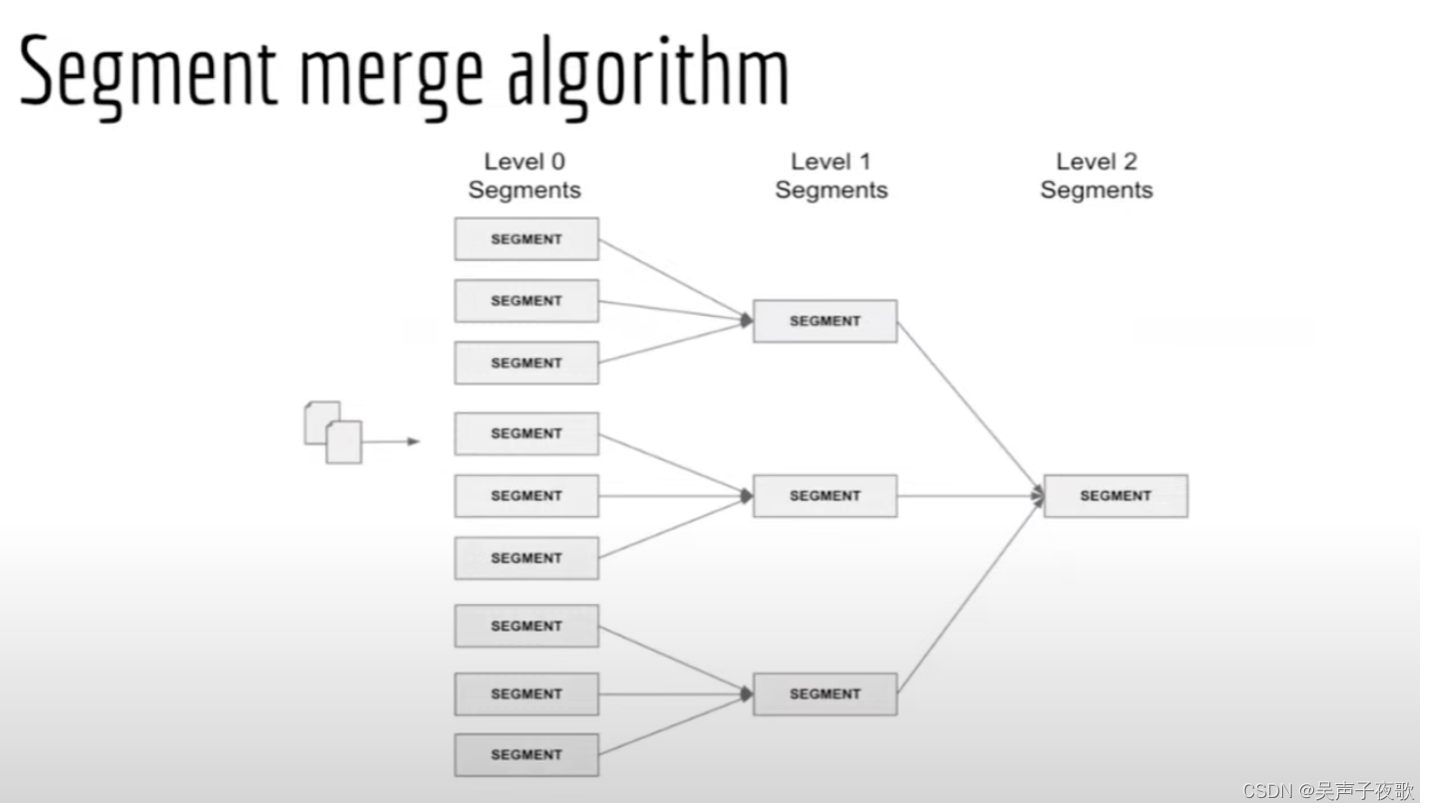
这个 refresh 的时间间隔可以由 index 设置中 index.refresh_interval 来定义。只有在 buffer 的内容写入到 Segement 后,这个被写入的文档才变为可以搜索的文档。通常 buffer 里的内容被写入到 Segment 里去,有三个条件:
- 由索引中的设置所指定的 refresh_interval 启动的周期性的 refresh。在默认的情况下为 1s。这使对索引的最近更改可见以进行搜索。 默认为 1s。 可以设置为 -1 以禁用刷新。 在 Elasticsearch 7.0 发布之后,如果未明确设置此设置,则至少在 index.search.idle.after 秒之后仍未看到搜索流量的分片在收到搜索请求之前将不会接收后台刷新。 命中空闲分片的搜索将等待下一次后台刷新(在1秒内)。 此行为旨在在不执行搜索时在默认情况下自动优化批量索引。 为了退出此行为,应将显式值 1s 设置为刷新间隔。
- 在导入文档时强制 refresh:PUT twitter/_doc/1?refresh=true
- 当 In Memory Buffer 满了,在默认的情况下为 node Heap 的 10%
这个过程会产生一个叫 Lucene flush 的操作,也会生产一个 segment。执行完 refresh 后的结果如下:
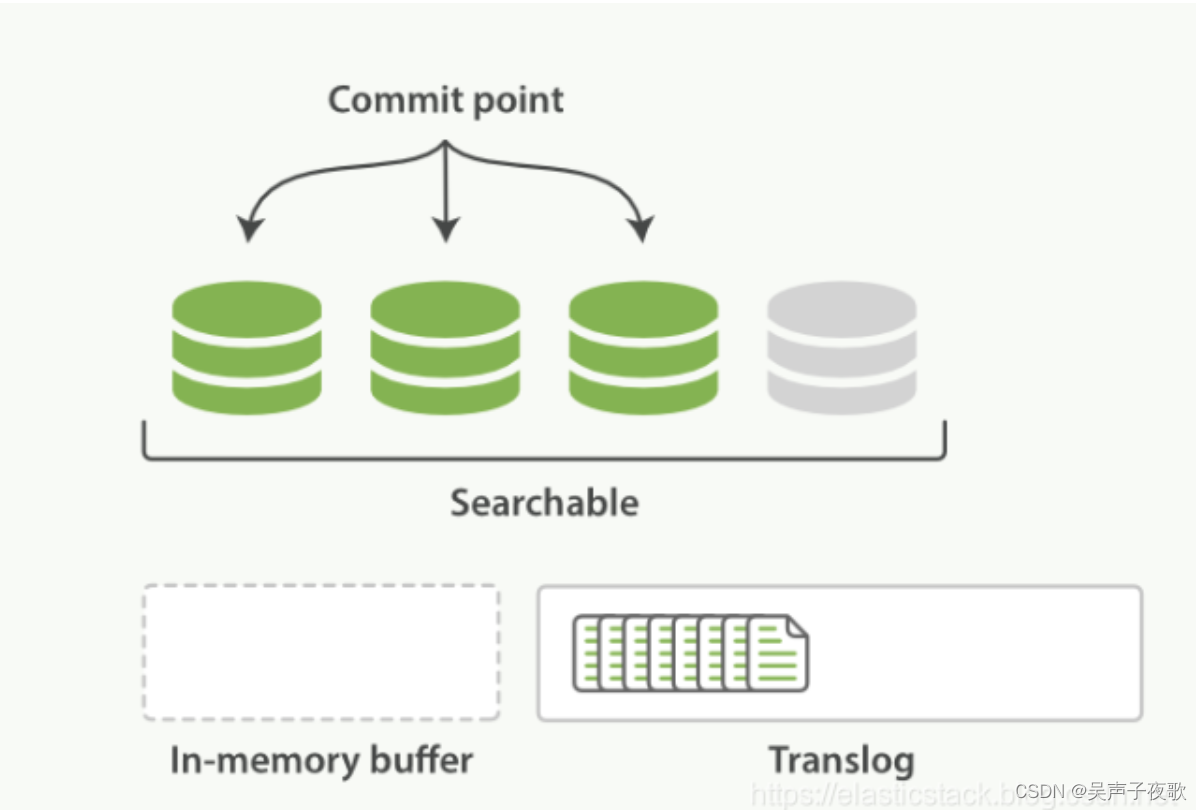
我们可以看出来,在 In-meomory buffer 中,现在所有的东西都是空的,但是 Translog 里还是有东西的。
refresh 的开销比较大,我在自己环境上测试 10W 条记录的场景下 refresh 一次大概要 14ms,因此在批量构建索引时可以把 refresh 间隔设置成 -1 来临时关闭 refresh, 等到索引都提交完成之后再打开 refresh, 可以通过如下接口修改这个参数:
PUT /test/_settings
{
"index" : {
"refresh_interval" : "-1"
}
}'
另外当你在做批量索引时,可以考虑把副本数设置成0,因为 document 从主分片 (primary shard) 复制到从分片 (replica shard) 时,从分片也要执行相同的分析、索引和合并过程,这样的开销比较大,你可以在构建索引之后再开启副本,这样只需要把数据从主分片拷贝到从分片:
PUT /my_index/_settings
{
"index" : {
"number_of_replicas" : 0
}
}'
执行完批量索引之后,把刷新间隔改回来:
PUT /my_index/_settings
{
"index" : {
"refresh_interval" : "1s"
}
}'
你还可以强制执行一次 refresh 以及索引分段的合并:
POST /my_index/_refresh
POST /my_index/_forcemerge?max_num_segments=5
Translog 及持久化存储:
但是,translog 如何解决持久性问题? 每个 Shard 中都存在一个 translog,这意味着它与物理磁盘内存有关。 它是同步且安全的,因此即使对于尚未提交的文档,你也可以获得持久性和持久性。 如果发生问题,可以还原事务日志。 同样,在每个设置的时间间隔内,或在成功完成请求(索引,批量,删除或更新)后,将事务日志提交到磁盘。
Elasticsearch 中的 Flush:
Flush 实质上意味着将内存缓冲区中的所有文档都写入新的 Lucene Segment,如下面的图所示。 这些连同所有现有的内存段一起被提交到磁盘,该磁盘清除事务日志(参见图4)。 此提交本质上是 Lucene 提交(commit)。
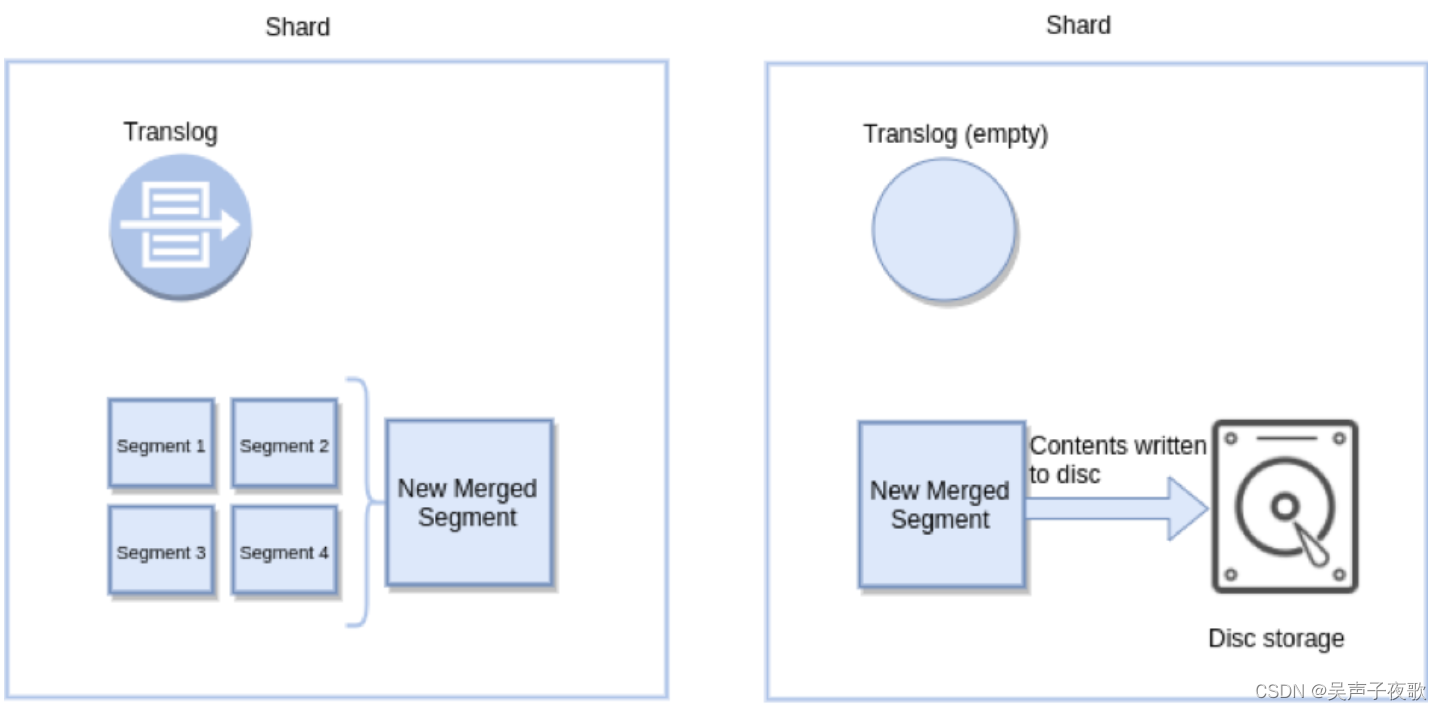
Flush 会定期触发,也可以在 Translog 达到特定大小时触发。 这些设置可以防止 Lucene 提交带来的不必要的费用。
结论:简而言之,_refresh 用于使新文档可见以进行搜索。 而 _flush 用于将内存中的段保留在硬盘上。 _flush 不会影响 Elasticsearch 中文档的可见性,因为搜索是在内存段中进行的,而不是硬盘。 _refresh 会影响其可见性。
10.1、Refresh(重新加载)
重新加载API允许显式刷新一个或多个索引,让自上次重新加载后执行的操作可以用于搜索。(近)实时能力取决于使用的索引引擎。例如,一个内部请求调用重新加载,但是默认情况下回周期性地调度重新加载。
默认情况下,Elasticsearch每秒定期刷新索引,但仅针对在过去30秒内收到一个或多个搜索请求的索引。您可以使用index.refresh_interval设置更改此默认间隔。
//语法
POST <index>/_refresh
GET <index>/_refresh
POST /_refresh
GET /_refresh
刷新API可以通过一次调用应用于一个或多个索引,甚至应用于_all索引。
POST kimchy,elasticsearch/_refresh
//清理所有
POST _refresh
10.2、Flush(刷新)
刷新API允许通过API刷新一个或多个索引。索引的刷新过程基本上通过将数据刷新到索引存储、清除内部事务日志来释放索引的内存。默认情况下,Elasticsearch使用内存启发式方式,以便根据需要自动触发刷新操作,以清理内存。
刷新索引是确保当前仅存储在事务日志中的任何数据也永久存储在Lucene索引中的过程。重新启动时,Elasticsearch将事务日志中任何未刷新的操作重放到Lucene索引中,使其恢复到重新启动前的状态。Elasticsearch根据需要自动触发刷新,使用启发式方法来权衡未刷新事务日志的大小和执行每次刷新的成本。
一旦每个操作都被刷新,它就会被永久存储在Lucene索引中。这可能意味着不需要在事务日志中维护它的额外副本,除非出于其他原因保留它。事务日志由多个文件组成,称为生成,一旦不再需要任何生成文件,Elasticsearch就会删除这些文件,从而释放磁盘空间。
//语法
POST /<index>/_flush
GET /<index>/_flush
POST /_flush
GET /_flush
示例:
//刷新单个索引
POST /kimchy/_flush
//刷新多个索引
POST /kimchy,elasticsearch/_flush
//刷新所有
POST /_flush
11、强制合并(_forcemerge)
强制合并API允许通过API强制合并一个或多个索引。合并依赖于Lucene索引在每个分片中保存的分段数。强制合并操作允许通过合并分段来减少他们的数量。
此调用会阻塞,直到合并完成。如果http连接丢失,请求将在后台继续,并且任何新的请求都会阻塞,直到前面的强制合并完成。
//语法
POST /<index>/_forcemerge
POST /_forcemerge
查询参数:
max_num_segments:要合并的分段数量。要完全合并索引需要设置为1.默认为简单地检查合并是否需要执行,如果需要,则执行。only_expunge_deletes:合并过程中是否只清除其中被删除的分段。在Lucene中,一个文档不会从分段中删除,只是标记为已删除。在这个分段的合并过程中,会创建没有那些删除文档的新分段。此标志仅允许合并已删除的段,默认为false。请注意,这不会覆盖 index.merge.policy.expunge_deletes_allowed的阀值。flush:是否在强制合并后执行flush。默认为true。
示例:
//合并单个索引
POST /twitter/_forcemerge
//合并多个索引
POST /kimchy,elasticsearch/_forcemerge
//合并全部
POST /_forcemerge
12、冻结/解冻索引(_freeze/_unfreeze)
Elasticsearch为了能够实现高效快速搜索,在内存中维护了一些数据结构,当索引的数量越来越多,那么这些数据结构所占用的内存也会越来越大,这是一个不可忽视的损耗。
在实际的业务开展过程中,我们会发现,有些索引的数据是“热”数据,经常被查询,这些索引对应的数据结构维护在内存中以提供快速查询是非常正确的,而有些“温”数据(例如随时时间推移的历史数据),可能很久才需要被查询到,这时候一直维持在内存中就有些得不偿失了。
为了解决这种情况,Elasticsearch提出了freeze index冻结索引的功能。一个被冻结的索引的每个shard在被搜索时,Elasticsearch会创建一个临时的数据结构,一旦搜索完成将会立刻丢掉这个数据结构,由于不长期维持这些临时数据结构在内存,冻结索引比正常索引消耗更少的堆内存,在集群的性能表现上更好。
总结来说索引的冻结是Elasticsearch提供的一个用于减少内存开销的操作,这个功能在7.14版本中被标记为Deprecated,在Version 8以后,已经对堆内存的使用进行了改进,冻结和解冻的功能不再适用,但在Version 8以前的版本中不失为一个可行的优化方案。
12.1、冻结索引(_freeze)
索引冻结以后除了保存一些必要的元数据信息意外,将不再占用系统负载,索引将会变成只读,不再提供写入的能力,类似force merge等操作也将无法执行。
注意,当前正在写的索引不能被冻结,并且执行了冻结操作以后,会将索引先进行close,然后再open,在这段时间内,可能导致主分片没有被分配,集群可能短暂出现red状态,open结束后恢复。
//语法
POST /<index>/_freeze
示例:
POST /my_index/_freeze
12.2、解冻索引(_unfreeze)
需求解冻的过程中,同样会将索引先进行close,然后再open,在这段时间内,索引不可查询,集群可能短暂出现red状态,open结束后恢复。
//语法
POST /<index>/_unfreeze
示例:
POST /my_index/_unfreeze
特别注意,在再次冻结索引之前,一定要运行“force_merge”,以确保最佳性能。
13、索引克隆(_clone)
克隆一个索引,使用克隆索引API将现有索引克隆到一个新索引中,其中每个原主分片都克隆到新索引中的新主分片中。
若要克隆索引,该索引必须标记为只读(read_only),并且群集运行状况状态为绿色(green)。
克隆过程:
- 首先,它创建一个与源索引定义相同的新目标索引。
- 然后,它将源索引中的分段硬链接到目标索引中。(如果文件系统不支持硬链接,那么所有段都会复制到新索引中,这是一个非常耗时的过程。)
- 最后,它恢复目标索引,就好像它是一个刚刚重新打开的封闭索引一样。
注意:_clone API类似于创建索引API,接受目标索引的设置和别名参数,与_reindex不同。
//语法
POST /<index>/_clone/<target-index>
PUT /<index>/_clone/<target-index>
Request body:
aliases:(可选,别名对象)目标索引的别名配置选项。settings:(可选,索引设置对象)目标索引的配置选项。
例如,以下请求阻止对my_source_index执行写操作,以便对其进行克隆。元数据更改(如删除索引)仍然是允许的。
PUT /my_source_index/_settings
{
"settings": {
"index.blocks.write": true
}
}
示例:无请求体,新索引接受源索引的别名和设置
POST /my_source_index/_clone/my_target_index
示例:新索引使用请求体的别名和设置
POST /my_source_index/_clone/my_target_index
{
"settings": {
"index.number_of_shards": 5
},
"aliases": {
"my_search_indices": {}
}
}
14、索引统计(_stats)
索引统计接口提供索引中不同内容的统计数据(其中的大多数统计数据也可以从节点级别范围取得)。
//语法
GET /<index>/_stats/<index-metric>
GET /<index>/_stats
GET /_stats
路径参数:
<index>:(可选,字符串)用于限制请求的索引名称的逗号分隔列表或通配符表达式。要检索所有索引的统计信息,请使用_all或*值或省略此参数。<index-metric>:(可选,字符串)用逗号分隔的用于限制请求的度量列表。支持的指标包括:- _all
- completion
- docs
- fielddata
- flush
- get
- indexing
- merge
- query_cache
- refresh
- request_cache
- search
- segments
- store
- suggest
- translog
- warmer
示例:
//统计多个索引
GET /index1,index2/_stats
//统计所有索引
GET /_stats
//指定统计指标
GET /_stats/merge,refresh
返回信息:
- docs - 文档数量
- store - 索引存储大小
- indexing - 索引操作统计信息
- get - 索引get统计信息
- search - 索引search统计信息
- segments - 段的内存使用情况
- completion - 自动提示统计信息
- fielddata - 统计信息
- flush - 刷新到磁盘的统计信息
- merge - 合并统计信息
- refresh - 统计信息
- request_cache - 统计信息
- warmer - 分片预热统计信息
- translog - 统计信息
- recovery - 恢复的统计信息
15、索引分片(_segments)
提供索引的副本分片的存储信息。存储信息包括了:哪些节点存储分片副本,分片副本分配的ID,每个分片的唯一标识符以及打开分片索引时甚至更早期的引擎异常。
默认情况下,只有至少一个未分配的副本分片的列表存储信息。当集群健康状态为yellow时,将列出具有至少一个未分配副本分片的存储信息。当集群健康状态为red时,将列出具有未分配主分片的存储信息。
//语法
GET /<index>/_segments
GET /_segments
示例:
//单个索引
GET /test/_segments
//多个索引
GET /test1,test2/_segments
//全部索引
GET /_segments
返回:
{
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"indices" : {
"bank" : {
"shards" : {
"0" : [
{
"routing" : {
"state" : "STARTED",
"primary" : true,
"node" : "Cc6ARDA6TY-poOdtxvsA6g"
},
"num_committed_segments" : 3,
"num_search_segments" : 3,
"segments" : {
"_0" : {
"generation" : 0,
"num_docs" : 998,
"deleted_docs" : 2,
"size_in_bytes" : 386550,
"memory_in_bytes" : 5260,
"committed" : true,
"search" : true,
"version" : "8.10.1",
"compound" : true,
"attributes" : {
"Lucene87StoredFieldsFormat.mode" : "BEST_SPEED"
}
},
"_1" : {
"generation" : 1,
"num_docs" : 1,
"deleted_docs" : 0,
"size_in_bytes" : 8936,
"memory_in_bytes" : 5084,
"committed" : true,
"search" : true,
"version" : "8.10.1",
"compound" : true,
"attributes" : {
"Lucene87StoredFieldsFormat.mode" : "BEST_SPEED"
}
},
"_3" : {
"generation" : 3,
"num_docs" : 1,
"deleted_docs" : 0,
"size_in_bytes" : 8813,
"memory_in_bytes" : 4948,
"committed" : true,
"search" : true,
"version" : "8.10.1",
"compound" : true,
"attributes" : {
"Lucene87StoredFieldsFormat.mode" : "BEST_SPEED"
}
}
}
}
]
}
}
}
}
_0:JSON文档的键名,代表分片的名称。这个名称用来生成文档名:分片目录中所有以分片名开头的文档属于这个分片generation:需啊哟写新的分片时生成的一个数字,基本上是递增的。分片名从这个生成的数字派生出来num_docs:存储在分片中没有被删除的文档数量deleted_docs:存储在分片中被删除的文档数量。如果这个数字大于0也是没有问题的,磁盘空间会在分片融合的时候被回收size_in_bytes:用字节表示分片使用的磁盘空间数量memory_inbytes:分片需要在内存中存储一些数据使搜索性能更加高效。这个数字表示用于这个目的的字节数量。如果返回的值为-1,表示Elasticsearch无法计算这个值committed:表示分片在磁盘上是否同步。提交的分片会在硬重启中存活下来。如果值为false也不需要担心,未提交的分片数据也会存储在事务日志中,在Elasticsearch下一次启动时可以重做修改search:分片是否可以进行搜索。如果值为false,可能意味着分片已经被写入磁盘但是没有经过刷新使之可以进行搜索version:用来写这个分片的Lucene版本compound:分片是否存储在符合文件中。如果值为true,意味着Lucene将分片中的所有文档融合为一个用来保存文档的描述符
16、索引恢复(_recovery)
索引恢复API提供观察正在恢复的索引分片的功能。可以针对特定的索引或者集群范围报告恢复的状态。
//语法
GET /<index>/_recovery
GET /_recovery
示例:
//单个索引
GET /test/_recovery?human
//多个索引
GET index1,index2/_recovery?human
//全部索引
GET /_recovery?human
返回:
{
"bank" : {
"shards" : [
{
"id" : 0,
"type" : "EXISTING_STORE",
"stage" : "DONE",
"primary" : true,
"start_time" : "2023-10-18T05:43:22.019Z",
"start_time_in_millis" : 1697607802019,
"stop_time" : "2023-10-18T05:43:22.048Z",
"stop_time_in_millis" : 1697607802048,
"total_time" : "29ms",
"total_time_in_millis" : 29,
"source" : {
"bootstrap_new_history_uuid" : false
},
"target" : {
"id" : "Cc6ARDA6TY-poOdtxvsA6g",
"host" : "127.0.0.1",
"transport_address" : "127.0.0.1:9300",
"ip" : "127.0.0.1",
"name" : "zhangchenglongdeMacBook-Pro.local"
},
"index" : {
"size" : {
"total" : "395.3kb",
"total_in_bytes" : 404857,
"reused" : "395.3kb",
"reused_in_bytes" : 404857,
"recovered" : "0b",
"recovered_in_bytes" : 0,
"recovered_from_snapshot" : "0b",
"recovered_from_snapshot_in_bytes" : 0,
"percent" : "100.0%"
},
"files" : {
"total" : 13,
"reused" : 13,
"recovered" : 0,
"percent" : "100.0%"
},
"total_time" : "2ms",
"total_time_in_millis" : 2,
"source_throttle_time" : "-1",
"source_throttle_time_in_millis" : 0,
"target_throttle_time" : "-1",
"target_throttle_time_in_millis" : 0
},
"translog" : {
"recovered" : 0,
"total" : 0,
"percent" : "100.0%",
"total_on_start" : 0,
"total_time" : "22ms",
"total_time_in_millis" : 22
},
"verify_index" : {
"check_index_time" : "0s",
"check_index_time_in_millis" : 0,
"total_time" : "0s",
"total_time_in_millis" : 0
}
}
]
}
}
id:分片IDtype:恢复类型:存储、快照、复制、迁移stage:恢复阶段:- 初始化:恢复没有开始
- 索引:读取索引元字段并且从源到目的地复制字节
- 开始:启动恢复,开启使用的索引
- 事务日志:重做事务日志
- 完成:清理
- 结束
source:恢复源:如果从快照中恢复,描述备份仓库;其他情况,描述源节点target:目标节点index:物理索引恢复的统计数据translog:事务日志恢复的统计数据start:打开和启动索引的时间统计数据
17、索引分片存储(_shard_stores)
提供索引的副本分片的存储信息。存储信息包括了:哪些节点存储分片副本,分片副本分配的ID,每个分片的唯一标识符以及打开分片索引时甚至更早期的引擎异常。
默认情况下,只有至少一个未分配的副本分片的列表存储信息。当集群健康状态为yellow时,将列出具有至少一个未分配副本分片的存储信息。当集群健康状态为red时,将列出具有未分配主分片的存储信息。
//语法
GET /<index>/_shard_stores
GET /_shard_stores
示例:
//单个索引
GET /test/_shard_stores
//多个索引
GET /test1,test2/_shard_stores
//全部索引
GET /_shard_stores
返回:
{
"indices" : {
"bank" : {
"shards" : {
"0" : {
"stores" : [
{
"Cc6ARDA6TY-poOdtxvsA6g" : {
"name" : "zhangchenglongdeMacBook-Pro.local",
"ephemeral_id" : "A35WaqpHSEKAnd1dsdOV2A",
"transport_address" : "127.0.0.1:9300",
"attributes" : {
"ml.machine_memory" : "17179869184",
"xpack.installed" : "true",
"transform.node" : "true",
"ml.max_open_jobs" : "512",
"ml.max_jvm_size" : "1037959168"
},
"roles" : [
"data",
"data_cold",
"data_content",
"data_frozen",
"data_hot",
"data_warm",
"ingest",
"master",
"ml",
"remote_cluster_client",
"transform"
]
},
"allocation_id" : "gV8DGW0jSimf4qCoPg4MDQ",
"allocation" : "primary"
}
]
}
}
}
}
}
0:存储信息对应的shard idstores:碎片的所有副本的存储信息列表Cc6ARDA6TY-poOdtxvsA6g:托管存储副本的节点信息,该值是唯一的节点id。allocation_id:存储副本的分配idallocation:存储副本的状态,无论它是用作主副本、副本还是根本没有使用
18、索引映射
18.1、获取索引映射
//语法
GET /_mapping
GET /<index>/_mapping
示例:
//指定索引
GET /twitter,kimchy/_mapping
//获取所有
GET /_all/_mapping
GET /_mapping
返回:
{
"bank" : {
"mappings" : {
"properties" : {
"account_number" : {
"type" : "long"
},
"address" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"age" : {
"type" : "long"
},
"balance" : {
"type" : "long"
},
"city" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"email" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"employer" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"firstname" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"gender" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"lastname" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"state" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
}
}
}
}
}
18.2、获取字段映射
//语法
GET /_mapping/field/<field>
GET /<index>/_mapping/field/<field>
示例:
PUT /publications
{
"mappings": {
"properties": {
"id": { "type": "text" },
"title": { "type": "text"},
"abstract": { "type": "text"},
"author": {
"properties": {
"id": { "type": "text" },
"name": { "type": "text" }
}
}
}
}
}
GET publications/_mapping/field/title
返回:
{
"publications" : {
"mappings" : {
"title" : {
"full_name" : "title",
"mapping" : {
"title" : {
"type" : "text"
}
}
}
}
}
}
获取多个字段:
GET publications/_mapping/field/author.id,abstract,name
匹配:
GET publications/_mapping/field/a*
18.3、提交映射
提交映射允许提交自定义的类型映射至一个新的索引,或者增加一个新的类型至一个存在的索引,或者增加某个存在类型的字段。
PUT /<index>/_mapping
PUT /_mapping
示例:put映射API需要一个现有索引。以下创建索引API请求创建不带映射的发布索引。
PUT /publications
PUT /publications/_mapping
{
"properties": {
"title": { "type": "text"}
}
}
示例:多索引
PUT /twitter-1
PUT /twitter-2
PUT /twitter-1,twitter-2/_mapping
{
"properties": {
"user_name": {
"type": "text"
}
}
}
示例:向现有索引映射添加新的
PUT /my_index
{
"mappings": {
"properties": {
"name": {
"properties": {
"first": {
"type": "text"
}
}
}
}
}
}
PUT /my_index/_mapping
{
"properties": {
"name": {
"properties": {
"last": {
"type": "text"
}
}
}
}
}
GET /my_index/_mapping
示例:多字段映射
PUT /my_index
{
"mappings": {
"properties": {
"city": {
"type": "text"
}
}
}
}
PUT /my_index/_mapping
{
"properties": {
"city": {
"type": "text",
"fields": {
"raw": {
"type": "keyword"
}
}
}
}
}
GET /my_index/_mapping
示例:修改已经映射配置
PUT /my_index
{
"mappings": {
"properties": {
"user_id": {
"type": "keyword",
"ignore_above": 20
}
}
}
}
PUT /my_index/_mapping
{
"properties": {
"user_id": {
"type": "keyword",
"ignore_above": 100
}
}
}
GET /my_index/_mapping
示例:重命名字段
PUT /my_index
{
"mappings": {
"properties": {
"user_identifier": {
"type": "keyword"
}
}
}
}
PUT /my_index/_mapping
{
"properties": {
"user_id": {
"type": "alias",
"path": "user_identifier"
}
}
}
GET /my_index/_mapping
19、索引模板(_template)
索引模板就是创建好一个索引参数设置(settings)和映射(mapping)的模板,在创建新索引的时候指定模板名称就可以使用模板定义好的参数设置和映射。
19.1、创建/更新索引模板
//语法
PUT /_template/<index-template>
示例:使用te*来匹配索引名,分片数量为1,在索引创建过程中,别名中的{index}占位符将替换为模板所应用的实际索引名称。
PUT _template/template_1
{
"index_patterns" : ["te*"],
"settings" : {
"number_of_shards" : 1
},
"aliases" : {
"alias1" : {},
"alias2" : {
"filter" : {
"term" : {"user" : "kimchy" }
},
"routing" : "kimchy"
},
"{index}-alias" : {}
}
}
示例:与多个模板匹配的索引
多个索引模板可能会匹配一个索引,在这种情况下,设置和映射都会合并到索引的最终配置中。可以使用order参数控制合并的顺序,先应用较低的顺序,然后覆盖较高的顺序。
PUT /_template/template_1
{
"index_patterns" : ["*"],
"order" : 0,
"settings" : {
"number_of_shards" : 1
},
"mappings" : {
"_source" : { "enabled" : false }
}
}
PUT /_template/template_2
{
"index_patterns" : ["te*"],
"order" : 1,
"settings" : {
"number_of_shards" : 1
},
"mappings" : {
"_source" : { "enabled" : true }
}
}
以上操作将禁用存储_source,但对于以te*开头的索引,_source仍将启用。请注意,对于映射,合并是“深度”的,这意味着特定的基于对象/属性的映射可以很容易地在高阶模板上添加/覆盖,而低阶模板提供了基础。
示例:版本控制,可以使用version参数向索引模板添加可选的版本号。外部系统可以使用这些版本号来简化模板管理。若要取消设置版本,请替换模板而不指定版本。
PUT /_template/template_1
{
"index_patterns" : ["*"],
"order" : 0,
"settings" : {
"number_of_shards" : 1
},
"version": 123
}
GET /_template/template_1?filter_path=*.version
//返回
{
"template_1" : {
"version" : 123
}
}
19.2、检测索引模板是否存在
//语法
HEAD /_template/<index-template>
示例:
HEAD /_template/template_1
19.3、获取索引模板
//语法
GET /_template/<index-template>
示例:
//指定索引
GET /_template/template_1,template_2
//匹配索引
GET /_template/temp*
//所有索引
GET /_template
返回:
{
"template_1" : {
"order" : 0,
"index_patterns" : [
"*"
],
"settings" : {
"index" : {
"number_of_shards" : "1"
}
},
"mappings" : {
"_source" : {
"enabled" : false
}
},
"aliases" : { }
}
}
19.4、删除索引模板
//语法
DELETE /_template/<index-template>
示例:
DELETE /_template/template_2
返回:
{
"acknowledged" : true
}
20、索引设置(_setting)
20.1、获取索引设置
//语法
GET /<index>/_settings
GET /<index>/_settings/<setting>
示例:
//多个索引
GET /twitter,kimchy/_settings
//所有索引
GET /_all/_settings
//匹配索引
GET /log_2013_*/_settings
示例:过滤setting字段
GET /bank/_settings/index.number_*
返回:
{
"bank" : {
"settings" : {
"index" : {
"number_of_shards" : "1",
"number_of_replicas" : "1"
}
}
}
}
20.2、更新索引设置
实时更新
//语法
PUT /<index>/_settings
示例:
PUT /twitter/_settings
{
"index" : {
"refresh_interval" : null
}
}
示例:更新别名
POST /twitter/_close
PUT /twitter/_settings
{
"analysis" : {
"analyzer":{
"content":{
"type":"custom",
"tokenizer":"whitespace"
}
}
}
}
POST /twitter/_open
21、滚动索引(_rollover)
滚动索引的作用防止索引过大或过旧时,滚动索引API会将别名滚动到新的索引。别名指向到新的索引后,旧的索引就无法查询到。
rollover API 使你可以根据索引大小,文档数或使用期限自动过渡到新索引。 当 rollover 触发后,将创建新索引,写别名(write alias) 将更新为指向新索引,所有后续更新都将写入新索引。
对于基于时间的 rollover 来说,基于大小,文档数或使用期限过渡至新索引是比较适合的。 在任意时间 rollover 通常会导致许多小的索引,这可能会对性能和资源使用产生负面影响。
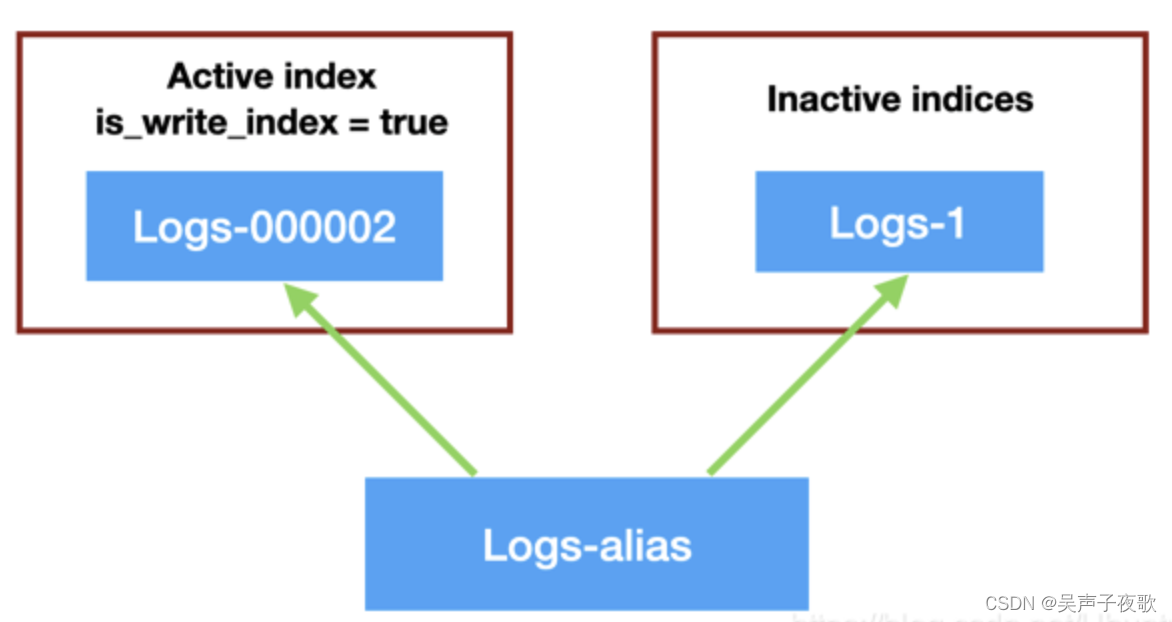
就像上面的图片看到的那样,我们定义了一个叫做 logs-alias 的alias,对于写操作来说,它总是会自动指向最新的可以用于写入index 的一个索引。针对我们上面的情况,它指向 logs-000002。如果新的 rollover 发生后,新的 logs-000003 将被生成,并对于写操作来说,它自动指向最新生产的 logs-000003 索引。而对于读写操作来说,它将同时指向最先的 logs-1,logs-000002 及 logs-000003。在这里我们需要注意的是:在我们最早设定 index 名字时,最后的一个字符必须是数字,比如我们上面显示的 logs-1。否则,自动生产 index 将会失败。
注意:尾随后缀(如000001)是一个正数,Elasticsearch 希望用它创建索引。弹性搜索只能从正数开始递增;起始号码是多少并不重要。只要我们有一个正整数,Elasticsearch就会递增数字并向前移动。例如,如果我们提供 my-index-04 或 my-index-0004,下一个滚动索引将是 myindex-000005。Elasticsearch会自动用零填充后缀。
如果指定的别名指向单个索引,则滚动请求:
- 创建新索引
- 将别名添加到新索引
- 从原始索引中删除别名
如果指定的别名指向多个索引,则其中一个索引必须将is_write_index设置为true。在这种情况下,展期请求:
- 创建新索引
- 将新索引的is_write_index设置为true
- 将原始索引的is_write_index设置为false
//语法
POST /<alias>/_rollover/<target-index>
POST /<alias>/_rollover/
Request body:
aliases:(可选,别名对象)对包含索引的别名设置。conditions:(必需,对象)索引别名的现有索引必须满足一组条件才能进行回滚。参数包括:max_age:(可选,时间单位)索引的保存时间。max_docs:(可选,integer)索引中的最大文档数。自上次刷新后添加的文档不包括在文档计数中。文档计数不包括副本碎片中的文档。max_size:(可选,字节单位)最大索引大小。这是索引中所有主碎片的总大小。副本不计入最大索引大小。
mappings:(可选,映射对象)索引中字段的映射。settings:(可选,索引设置对象)索引的配置选项。
示例:保存7天,文档数大于1000,索引大小大于5gb就发生滚动
PUT /logs-000001
{
"aliases": {
"logs_write": {}
}
}
POST /logs_write/_rollover
{
"conditions": {
"max_age": "7d",
"max_docs": 1000,
"max_size": "5gb"
}
}
21.1、完整示例
首先我们定义一个 mylog-alias 的 alias,必须为写索引:
// 编码mylogs-2023.10.18-1
PUT /%3Cmylogs-%7Bnow%2Fd%7D-1%3E
{
"aliases": {
"my_alias": {
"is_write_index": true
}
}
}
返回:
{
"acknowledged" : true,
"shards_acknowledged" : true,
"index" : "mylogs-2023.10.18-1"
}
准备数据:
//共有14074个文档
GET _cat/indices/kibana_sample_data_logs
//迁移到my_alias中
POST _reindex
{
"source": {
"index": "kibana_sample_data_logs"
},
"dest": {
"index": "my_alias"
}
}
显然,我们已经复制到所有的数据。那么接下来,我们来运行如下的一个指令:
POST /my_alias/_rollover?dry_run
{
"conditions": {
"max_age": "7d",
"max_docs": 14000,
"max_size": "5gb"
}
}
返回:
{
"acknowledged" : false,
"shards_acknowledged" : false,
"old_index" : "mylogs-2023.10.18-1",
"new_index" : "mylogs-2023.10.18-000002",
"rolled_over" : false,
"dry_run" : true,
"conditions" : {
"[max_docs: 14000]" : false,
"[max_size: 5gb]" : false,
"[max_age: 7d]" : false
}
}
根据目前我们的条件,我们的 mylogs-2023.10.18-1文档数已经超过 14000 个了,所以会生产新的索引mylogs-2023.10.18-000002。因为我使用了 dry_run,也就是演习,所以显示的 rolled_over 是 false。
为了能真正地 rollover,我们运行如下的命令:
POST /my_alias/_rollover
{
"conditions": {
"max_age": "7d",
"max_docs": 1400,
"max_size": "5gb"
}
}
返回:
{
"acknowledged" : true,
"shards_acknowledged" : true,
"old_index" : "mylogs-2023.10.18-1",
"new_index" : "mylogs-2023.10.18-000002",
"rolled_over" : true,
"dry_run" : false,
"conditions" : {
"[max_docs: 1400]" : true,
"[max_size: 5gb]" : false,
"[max_age: 7d]" : false
}
}
说明它已经 rolled_ovder了。我们可以通过如下写的命令来检查:
GET _cat/indices/mylogs-2023*
返回:

如果我们这个时候直接再想 my_alias 写入文档的话:
POST my_alias/_doc
{
"agent": "Mozilla/5.0 (X11; Linux x86_64; rv:6.0a1) Gecko/20110421 Firefox/6.0a1",
"bytes": 6219,
"clientip": "223.87.60.27",
"extension": "deb",
"geo": {
"srcdest": "IN:US",
"src": "IN",
"dest": "US",
"coordinates": {
"lat": 39.41042861,
"lon": -88.8454325
}
},
"host": "artifacts.elastic.co",
"index": "kibana_sample_data_logs",
"ip": "223.87.60.27",
"machine": {
"ram": 8589934592,
"os": "win 8"
},
"memory": null,
"message": """
223.87.60.27 - - [2018-07-22T00:39:02.912Z] "GET /elasticsearch/elasticsearch-6.3.2.deb_1 HTTP/1.1" 200 6219 "-" "Mozilla/5.0 (X11; Linux x86_64; rv:6.0a1) Gecko/20110421 Firefox/6.0a1"
""",
"phpmemory": null,
"referer": "http://twitter.com/success/wendy-lawrence",
"request": "/elasticsearch/elasticsearch-6.3.2.deb",
"response": 200,
"tags": [
"success",
"info"
],
"timestamp": "2019-10-13T00:39:02.912Z",
"url": "https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-6.3.2.deb_1",
"utc_time": "2019-10-13T00:39:02.912Z"
}
返回:
{
"_index" : "mylogs-2023.10.18-000002",
"_type" : "_doc",
"_id" : "XEYcQosBUKjt0bDlTgD5",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 0,
"_primary_term" : 1
}
显然它写入的是mylogs-2023.10.18-000002索引。我们再次查询 log_alias 的总共文档数:
GET my_alias/_count
返回:
{
"count" : 14075,
"_shards" : {
"total" : 2,
"successful" : 2,
"skipped" : 0,
"failed" : 0
}
}
显然它和之前的 14074 个文档多增加了一个文档,也就是说 my_alias 是同时指向 mylogs-2023.10.18-1 及 mylogs-2023.10.18-000002。
21.2、配合ILM使用
Rollover 在实战中,我们可以配合 ILM 一起使用。我们可以定义如下的一个 ILM policy:
PUT _ilm/policy/50gb_30d_delete_90d_policy
{
"policy": {
"phases": {
"hot": {
"actions": {
"rollover": {
"max_size": "50GB",
"max_age": "30d",
"max_docs": 10000
}
}
},
"delete": {
"min_age": "90d",
"actions": {
"delete": {}
}
}
}
}
}
在上面,我们定义了如下的一个 policy:
- 当一个索引的文档数超过 10000,或者文档的时间超过 30 天,或者索引的大小超过 50G,之后摄入的文档就会自动 rollover
- 文档超过 90 天,就会被自动删除
我们接着就定义如下的 index template:
PUT _index_template/timeseries_template
{
"index_patterns": [
"myindex-*"
],
"data_stream": {},
"template": {
"settings": {
"number_of_shards": 1,
"number_of_replicas": 1,
"index.lifecycle.name": "50gb_30d_delete_90d_policy"
}
}
}
之后,所有新创建的以 myindex- 为开头的索引将会自动采纳 50gb_30d_delete_90d_policy 策略,也就是该索引将会根据 50gb_30d_delete_90d_policy 所定义的条件自动 rollover。针对上面的 data_stream,我们可以采用如下的方式来创建索引:
PUT _data_stream/myindex-ds

















 2072
2072

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









